動機
一見全く別のトピックに見えるこれらの記事は
vLLM等を用いたローカルLLMサーバの構築・検証経験があり
以下の開発でコンテキストエンジニアリングの重要性を痛感した私には地続きの内容に見えます
コンテキストエンジニアリングを極めようとすると
どうしてもLLM特有のKVキャッシュの概念理解が必要になります
逆に舞台裏を知ることで、Anthropicが考えていることも大体分かるようになります
そうした切り口の記事がなかったので書きました(表を除き、生成AIは使ってません)
※研究室の論文輪講での発表内容を基に作成したため
適宜、折り畳みフィールド内で論文リストも共有しておきます
論文大別
①コンテキストエンジニアリング
②vLLM関連
③LMcache
④DeepSeek系列
1. コンテキストエンジニアリングとは
1.1. 概要
コンテキストエンジニアリングという言葉は2025年夏頃にトレンド化しましたが
その発端は、Vibe Cordingという言葉をバズらせたAndrej Karpathy氏が
Shopify CEOのtobi lutke氏の投稿へ行ったリプでした
トレンドになった直後は、様々な人が反応し各自の解釈で作成された図が入り乱れ
その曖昧さも相まって定義がふわふわでした
それからしばらく経った2025/09/29にAnthropicが出した以下の記事が
明確かつ具体的にコンテキストエンジニアリングの概念を図示してくれています
簡単に言うと以下の通りです
- 余分なツールやプロンプトを与えずコンテキスト汚染を防ぐ
- そのために適切な粒度でエージェントを分割
- プロンプト:過度に具体↔抽象に寄りすぎない(✖手順をハードコード)

この公式ブログを読まずとも
「伝言ゲーム」で作成された投稿や記事を目にしたことがあれば
コンテキストエンジニアリングが良さげなことは分かります
では、なぜAnthropicはコンテキストエンジニアリングを再提示したのでしょうか?
結論から言うと、コンテキストエンジニアリングが進まないと
必要なGPU数が減らずAnthropicが破産するからです
1.2. 記事の目的
この記事はプロンプト/エージェント/フレームワークの設計やローカルLLM推論を行う方を対象に
「KVキャッシュへの無知が、コスト増を招く」ことを理解して頂くことが主な目的ですが
モデルのアーキテクチャ自体でKVキャッシュを削減しようという試みの果てに
DeepSeekはMLAという構造にたどり着いたことなども
「KVキャッシュ最適化」という一貫したストーリーで伝えたいと思います
1.3. サーベイ論文
サーベイ論文
A Survey of Context Engineering for Large Language Models
(arXiv 2025年7月)はアブストに
1,400本の論文の"systematic analysis"を通じて
…とあるので、さすがにLLMを利用しつつ体系的に分析したものと思われます
そのぐらい「コンテキストエンジニアリング」が多くのLLM研究と関連し
総合格闘技の様相を呈していると言えます
・第4章 基礎的な要素
§4.1 コンテキスト生成と検索(例:CoT, ReAct, RAG, ...)
§4.2 コンテキスト処理 (Mamba, FlashAttention, ...)
・第5章 実装
・第6章 評価(WebArena)
・第7章 指針と革新への試み
§7.1 基礎研究(Scaling Laws)
§7.2 技術革新(GraphRAG)
§7.3 プロトコル(MCP, A2A, ...)
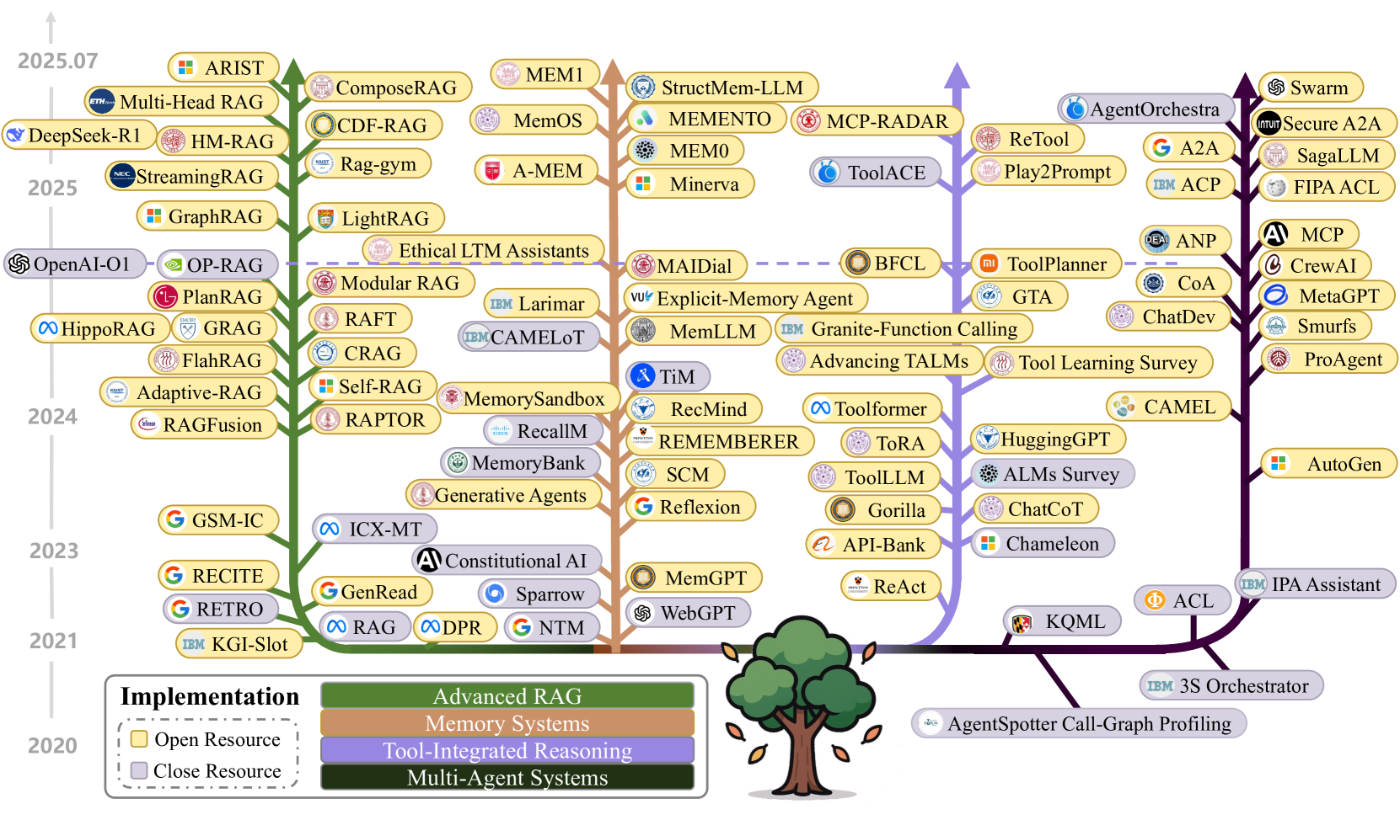
第5章の「実装」は上図のように4つに分類されています
- RAG(例:Self-RAG)
- Memory Systems(MemGPT)
- Tool統合型 Reasoning(ReAct)
- マルチエージェント(AutoGen)
個人的にはMemory Systemsに属する研究は
ほとんど目にしたことが無かったので
今後、alphaXivの日本語Blog形式で
主要どころは抑えて行きたいです
1.4. コンテキストが顕著に絡む例 ICL: In-Context Learning
あまりにも膨大なサーベイ論文の内容を全て紹介する訳にも行かないので
コンテキストエンジニアリングと密接な関係にあると個人的に考える
ICL: In-Context Learningというプロンプトエンジニアリング手法について触れます
これは「問題と解答」のペアを例示し、最後に本題を提示して出力の精度向上を期待する手法です
与える例の数によって
- One-Shot ICL(1例)
- Few-Shot ICL(2~例)
- Many-Shot ICL(~数百例)
等と呼ばれます
Many-Shot ICLの論文
原著は (NeurIPS 2024) 被引用数:180
Many-Shot In-Context Learning
実際On Many-Shot In-Context Learning for Long-Context Evaluation(ACL 2025)
という論文でMany-Shot ICLの効果は
「モデル」と「分野」依存であることが示されています

Many-Shot数と性能の相関(分野別)
数学は多数の例が逆効果。要約や分類等のタスクではMany-Shot ICLの効果が高い

マルチモーダルでも同様
長いコンテキストでの性能はモデル依存
Gemini 1.5 Proのみが多数の画像を入力する
Many-shot ICLで効果を発揮した例
被引用数:54

これ以上は本題と逸れるので取り上げませんが
重要なのはコンテキストエンジニアリングは、あらゆるLLM研究と関連を持たせることができ
関連研究全てを把握することなど到底不可能だということです
しかしコンテキストエンジニアリングの「実態」ではなく「目的」を知ることで
「完全に理解した」という感覚を得ることは可能です
ずばりコンテキストエンジニアリングの真の目的は
KVキャッシュ最適化によるコスト削減です!
2. KVキャッシュとは
2.1. LLMが遅い原因
LLMは2種類の層を正規化を挟み交互に数十層重ねたモデル構造をしています
- 知識を蓄えたFFN層(通常の機械学習のMLP層)
Y=f(AW+B) f - 文脈の意味を反映するAttention層
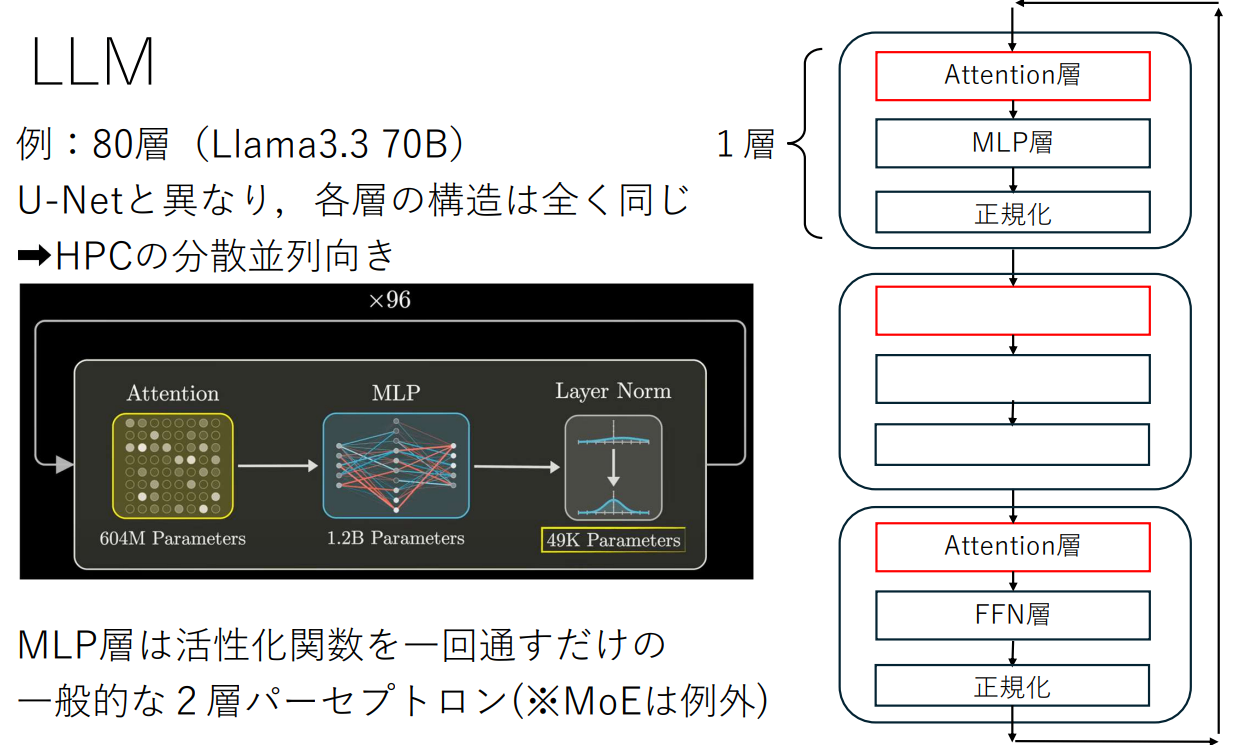
より詳しいアニメーションでの解説
この動画シリーズでSelf-Attentionを視覚的に理解する道を選択した場合
以下の記事と照らし合わせることで、KVキャッシュと紐づけることもできます
次の1トークンを出力(Decode)するために全ての層を通過する必要があります
計算量が

画像は https://www.youtube.com/watch?v=0VLAoVGf_74 より引用
2.2. KVキャッシュを無効にするアンチパターン
AIエージェント「Manus」のブログより引用した下図のように
1トークンでも違えば、それ以降のKVキャッシュが無効になります
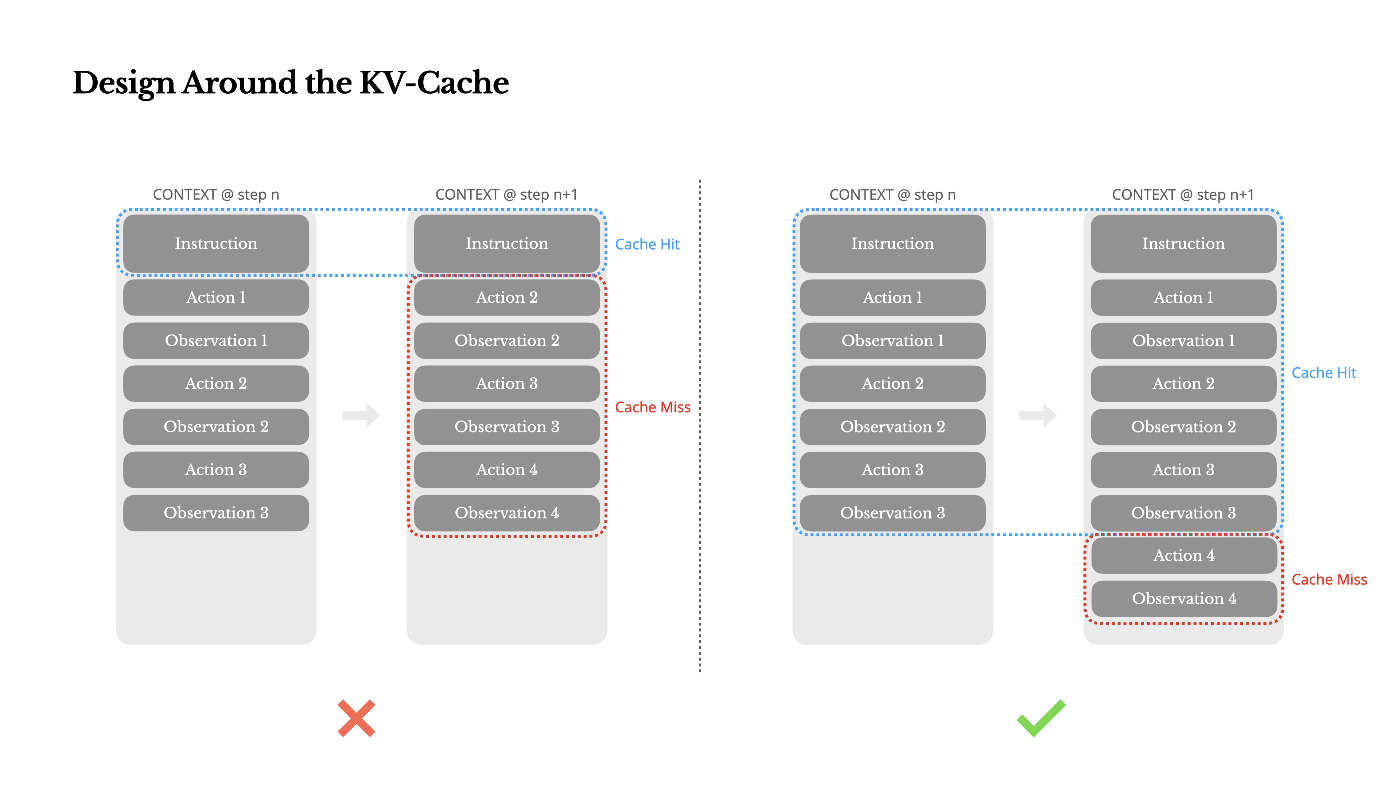 システムプロンプトの先頭にタイムスタンプを入れるのが
システムプロンプトの先頭にタイムスタンプを入れるのが
よくある間違いとして挙げられていました
APIは、出力される文面だけ見ればステートレス呼び出しですが
(履歴のjsonl全体を全て投げるイメージ)
コストはサーバ側のKVキャッシュの状態によって左右されます
コスト={計算量・VRAM占有時間・応答時間・費用...}
2.3. KVキャッシュサイズの計算式
KVキャッシュサイズの計算式

ただし型は8bit(FP8)の場合をx1とするのでBF16の場合はx2となります
例)Llama3.3 70B (BF16) 128Kトークンの 1リクエストのKVキャッシュサイズは
参考文献↓
3. KVキャッシュを意識したコスト削減
3.1. Claude Codeの裏側のAPIを読み解く
ではこれらを知った上で、どうコンテキストエンジニアリングを実践すれば良いのでしょうか
一番手軽なのはClaude CodeのようにKVキャッシュ管理を搭載したツールを使用することです
実はClaudeをAPI経由で使用すると、一度だけ少し高い額を払って明示的にCacheを書きこまないとKVキャッシュが働きません
キャッシュヒットしたトークンは1/10の費用で使用でき、レスポンス速度も向上します
保存期間は2通りで、期限内に後続リクエストを返さないとKVキャッシュは消失します
-
5分(書き込み費用:通常レート×1.25倍) -
1時間(書き込み費用:通常レート×2倍)
Claude Codeのコンテキストは
homeディレクトリ(ユーザ名/直下など)以下の
/.claude/projects/{起動したパスの英数字以外を-に置換した文字列}/{session_id}.jsonl
に追加されていくのですが
ある行の"usage"をパースすると以下の項目が確認でき
-
cache_creation_input_tokens(キャッシュ書きこみ) -
cache_read_input_tokens(キャッシュヒット)
5分のKVキャッシュがデフォルトで有効化されているのが分かります
"usage":{
"input_tokens":6,
"cache_creation_input_tokens":1236,
"cache_read_input_tokens":62840,
"cache_creation":{
"ephemeral_5m_input_tokens":1236,
"ephemeral_1h_input_tokens":0
},
"output_tokens":370,
"service_tier":"standard"
}
※Claude Code v2.0.8 --dangerously-skip-permissionsの履歴で確認
3.2. MCPコンテキスト削減
またMCPツールに関してもKVキャッシュを意識した仕様があります
Claude Codeの会話途中で以下のような強制コマンド実行でMCPサーバを追加して
!claude mcp add desktop-commander -- npx -y @wonderwhy-er/desktop-commander
/mcpで確認しても認識されずexitでClaude Codeを再起動するまで有効化されません
再起動後/contextでコンテキストを可視化すると

必ずClaude Code自体の共通Systemプロンプトの次に
MCP toolsのLLM向け説明文:
MCPサーバの各ツールごとの{name, 引数のスキーマ, description}
が絶対に来る仕様が確認できます
なぜ、そう縛るかというとMCPサーバのプロンプトは
直近で同一のMCPのユーザがいて推論クラスタのどこかにKVキャッシュが存在する確率があるからです
もし下記のコンテキスト蓄積順を逸脱した
☑ Claude Code自体のSystemプロンプト
✅ MCP toolsが内包するプロンプト
✖ユーザプロンプト
以下のような順序を許すと
KVキャッシュが他リクエストと共有できる割合が下がり推論コストが増えます
☑Claude Code自体のSystemプロンプト
✖ユーザプロンプト
✖MCP toolsが内包するプロンプト
✖ユーザプロンプト(続き)
このDesktop Commander MCPサーバは人気ですが、十数個のツールを内包しオプションも多いため
MCP tool使用法プロンプトが23.8Kトークンもあります(Desktop Commander MCP v0.2.19で確認)
これとClaude CodeのSystemプロンプトを合わせた40KB近いKVキャッシュが共有できる場合
後に紹介するvLLMサーバでは、よりスケール性が活きます
ちなみにこのMCPコンテキスト肥大化問題に対する
Anthropicの対策が2025/10/17に登場した「Claude Skills」です
こちらの記事で解説されています
このSkillsもClaude Code Pluginsという枠組みに追加されました
Pluginsのフォーマットに沿ってエージェントを作成することで
自然とコンテキストエンジニアリングの要件が達成されるので
「Claude Code Plugins化できるか」が今後、コンテキストエンジニアリングの
1つの基準となり得ると個人的には思っています
Plugins化したい手持ちのフレームワークが2つあるので実践したら記事にします
3.3. ローカルLLMでのKVキャッシュ有効化
vLLMではV1(v0.8.0~)を使用すればデフォルトで
enable_prefix_caching=True
となり、リクエスト間を超えてKVキャッシュの再利用が有効化されPrefillを短縮できます
vLLMは元のPagedAttentionの論文が強いことに加え、様々な研究を取り込んで成長していった点が他のプラットフォームと差をつけた理由だと思われます
PagedAttentionを軽く説明すると
当時の既存研究Orca(Continuous Batching)推論エンジンはKVキャッシュを固定長で確保していた
➡そこでGPU内に「OSのメモリ変換テーブル」に似たKVキャッシュ管理機能を実装

その結果GPUメモリの内部/外部断片化や他の予約領域等が削減され
限られたGPUメモリでより多くのリクエストを同時に捌けるようになった
同時リクエスト数に対するスループット[token/s]のスケール性も確認されたという話でした

実装を取り込んだ研究の論文リスト一部
Efficient Memory Management for Large Language Model Serving with PagedAttention, (SOSP 2023) 被引用数:3543
Continuous Batching (OSDI 2022) ➡ EOFを出力⇒間髪入れずBatch投入
Orca: A Distributed Serving System for Transformer-Based Generative Models
Chunked Prefill (OSDI 2024) ➡ 細かいPrefillで1サイクルを長引かせない
Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve
Speculative Decoding (※↓サーベイ 2024 ACL) ➡小型モデルが候補を出し高速化
Unlocking Efficiency in Large Language Model Inference:A Comprehensive Survey of Speculative Decoding
FlashAttention (NeurIPS 2022~) ➡ループ融合等でボトルネックHBMへのアクセスを最小化
Fast and Memory-Efficient Exact Attention with IO-Awareness
A100 FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning(arXiv 2023)
H100 FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision(arXiv 2024)
他にもMegatronのような学習フレームワークで有名な以下の分散並列にも対応
- Pipeline並列(Pipelineバブルが無いので学習よりはシンプル)
- Tensor並列(行列積の分散)
- Expert並列(MoE)
4. 大規模・多ユーザ環境で要注目なKVキャッシュのソリューション
4.1. vLLM V0→V1の違い
PrefillとDecodeに対する戦略が違います
V0の典型的な挙動ではPrefill➡Decodeフェーズは排他的ですが
V1はフェーズを統合しDecodeを止めず、メモリと演算器の両方を遊ばせないことで
スループットを高める方向性に舵を切りました
| フェーズ | 特徴 | ボトルネック |
|---|---|---|
| Prefill | KVキャッシュを再利用することで削減可能 | 計算バウンド |
| Decode | 次の1トークンを出力する段階 | メモリバウンド |
4.2. 依存関係の図
今から紹介するLMCache・llm-d・Nvidia Dynamoの関係だけ先に図示しておきます

4.3. LMCacheとは
vLLMのKVキャッシュをSSD等の2次記憶装置にオフロードする目的で開発されてきたプラグインに相当するプロジェクトがLMCacheです
vLLM V1への刷新時にCPUメモリへのオフロードオプションも廃止され、LMCacheがHBM(VRAM)よりもGPUカーネルから遠いメモリ・記憶デバイス全般を担当するようになり、存在感が増しています
一方でvLLM V1に対して以下のような議論もあるようです
- CPUオフロードはV0までと同様にvLLMの引数で有効化可能にすべき
- LMCacheを試した際はバグで困った
論文リスト
Cachegen: Kv cache compression and streaming for fast large language model serving (ACM SIGCOMM 2024) ※arXiv2025年版ではNIXL等の最新の実装を説明している
CacheBlend: Fast Large Language Model Serving for
RAG with Cached Knowledge Fusion (EuroSys 2025) https://dl.acm.org/doi/10.1145/3689031.3696098
【関係】
llm-dはLMCacheを利用します
NvidiaはLMCacheの競合となるKVBMをRust言語で開発し、LLMライブラリ拡充によるGPUのベンダーロックインに拍車をかける一方で、KVBMをオプションとして内包するDynamoではWrapperとして「LMCacheに対応」と宣伝するあたり立ち回りが上手いな…と感じます
4.4. LLM-dとは
こちらはKubernetes(以下K8s)等インフラエンジニア寄りの内容なので軽めの紹介にとどめますが
Red-Hat等の開発者がK8sを用いてクラウド等にデプロイするソリューションです
※便利なHelm Chart経由でもデプロイ可能
 要求スペックが異なる2つのフェーズに対し
要求スペックが異なる2つのフェーズに対し
- Prefillは演算性能が強いクラスタ群
- DecodeはHBMメモリが大きいクラスタ群
などを割り当てて計算機を効率良く使うことを意図して設計されました
Googleの開発者が参加されているだけあってTPU等にも対応しています
大規模なリクエストに対するルーティング(スケジューリング)が強く
例えば以下のような環境変数を設定可能です
| Scorer | 優先するPod |
|---|---|
| Session-aware | Session IDに基づいて、直前にそのセッションを処理したPod |
| Load-aware | Podのリアルタイムな負荷指標を元に過負荷なPodを避ける |
| Prefix-aware | Promptのprefixが過去に処理されているPod |
| KVCache-aware | KVCacheの再利用が見込めるPod |
上記の表は、こちらの方の資料を、ほぼそのまま引用しており、LMCacheやLLM-dの実装詳細を知りたい場合などは必見です
4.5. Nvidia Dynamo (KVBM + Kubernetes)
Dynamoの立ち位置はKVキャッシュオフロード機能をWrappingしたK8sソリューションです。基盤技術としてKVBMを独自開発し、複数のLLM推論Runtime(vLLM, TensorRT, SGLang)をカバーします
SSDを含むデバイスへのKVキャッシュオフロードを統一的に扱うという野心あるプロジェクトです
ユーザ視点では、KVBMが使用する自社API:NIXL(Nvidiaの低レイヤ通信APIセット)依存を許容できるかが焦点になりそうです
KVBMの概要図も載せておきます

4.6. vLLM, Nvidia Dynamo, LLM-d 比較表
主なLLM分散推論サーバ (2025/10)
| vLLM V1 | Nvidia Dynamo | LLM-d (RedHat,Google) | |
|---|---|---|---|
| スケジューリング | PrefillとDecodeの統合 | KVBM | Prefill➡Decode |
| 意図・usage | 計算・メモリ律速の隠蔽 | Wapper | 適所GPU・ルーティング |
| KVキャッシュオフロード | LLM-dでも使用されるLMCache自体NIXLを組み込みV1対応 | KVBM | NIXL等 (高性能, 低遅延のp2p通信ライブラリ) |
| ノード間の分散協調基盤 | Ray | Kubernetes OpenShift AI |
Kubernetes OpenShift AI 3.0+ |
| 推論エンジン | vLLM V1 | vLLM, TensorRT-LLM, SGLang | vLLM V0 |
| 主要開発言語 | Python | Rust >Python>Go>Shell | Shell>Makefile,Python |
4.7. スパコン(HPC)業界視点
HPC研究会に所属しているため(特に国産の)スパコンについても触れたいと思います
RHEL7のようにOSが古めのスパコンではユーザ権限でK8s環境を構築するのは不可能です
そのようなスパコン視点では、KVキャッシュのCPU・SSD等へのオフロードを実現するには
下図のように直接LMCacheを構築するかKVBMを利用するというコスパに優れない選択肢が残ります

ただV100のようにBF16やFP8に演算器がネイティブ対応していないGPUクラスタ(しかも入れ替え時期が近い)で本格推論サーバを構築しても需要が低いようにも感じるので
先にA100やH100を積んだ新しめのスパコンでK8s環境構築を試みるほうが実用的かもしれません
あとユーザ・プロジェクトをまたいで使用可能にしないとコスパが悪いので
ポイント引き落としシステムとか、そもそもベンダー側と協力しないと実現できない構想もあります
私個人にできるのはKVキャッシュにヒットしたトークン数の検出や
SSDとNFS共有ファイルシステムを併用したKVキャッシュ管理ぐらいでしょうか
5. モデルレベルでのKVキャッシュ削減
5.1. GRPO強化学習アルゴリズム⇒要推論性能
SFT → PPO → DPO → GRPO
PPOやGRPOについて知りたい場合、こちらの記事がおすすめです
DeepSeekMathという論文で提案されたGRPO:Group Relative Policy Optimizationは
1ステップの学習にLLMの出力全体を複数用いるので、推論がボトルネックとなりました
そこでHuggingFaceが提供する有名なライブラリTRL - Transformer Reinforcement Learningは
GRPOTrainerの引数であるGRPOConfigのオプションに
use_vllm=True
vllm_mode="server" #または"colocate"(※トレーニングモデルとGPUメモリ共有時)
を加えてスケール性能が高い推論エンジンvLLMを取り込みました
今やtrl[vllm]はpip経由で様々な学習プラットフォームにインストールされ使われます
5.2. Attention構造内でのKVキャッシュ削減(MLA解説)
MHA → MQA → GQA → MLA
| ATTENTION層のQueryとHead構造 | KVキャッシュ 算出式/token |
KVキャッシュ サイズ/token |
品質 |
|---|---|---|---|
| Multi-Head Attention (MHA) | 4 MB | High | |
| Multi-Query Attention (MQA) | 31 KB | Lower | |
| Grouped-Query Attention (GQA) | 500 KB | Medium | |
| Multi-Head Latent Attention (MLA) | 70 KB | Higher |
MetaのLlama3.3は妥協案に近いGQAを採用しています
一方DeepSeekが開発したMLAはKVキャッシュサイズを57分の1にしながら
フルバージョンのMulti-head Attentionと同等以上の品質を保つことに成功しました
- 潜在(Latent)空間に圧縮する深層学習で有名な手法を取り入れ
- RoPE(トークンの位置埋め込み)を適用する/しない箇所を分ける
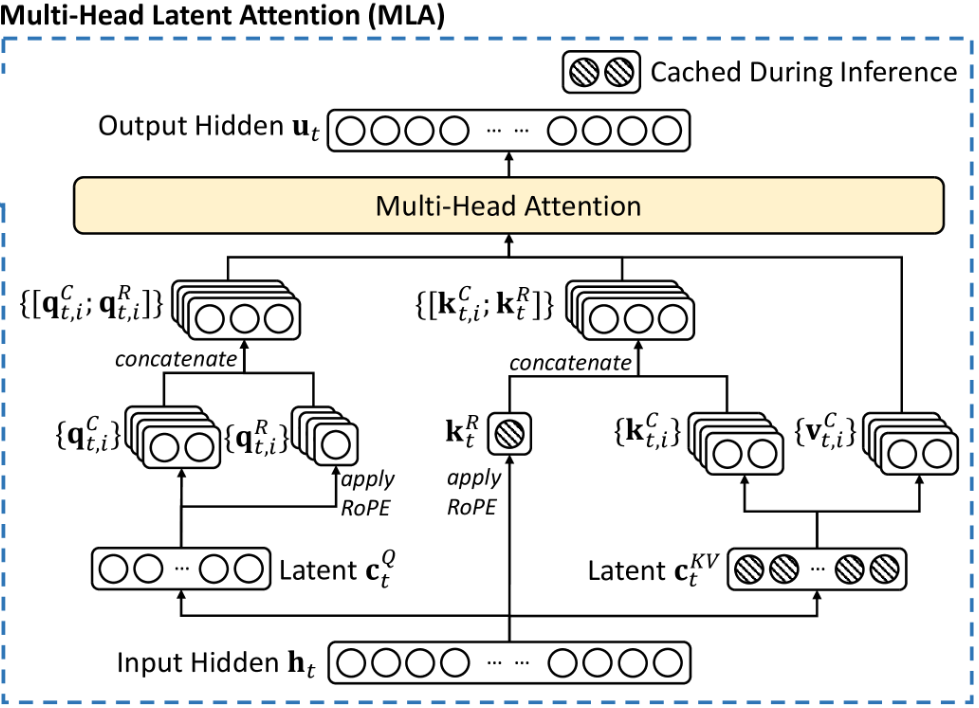
しかし上で示した論文の図はイメージし辛いので以下の動画に沿って補足説明します
推論時モデルの重みが固定されるので以下のように計算を減らせる
という部分を線形代数の行列式の公式と照らし合わせながら解説します

学習時は上図の流れで計算を行いますが推論時は下記のように重みをabsorb(吸収)できることを線形代数の性質から示します

問題を2つに分けます
上部:Q,K行列
下部:V行列
簡単な下部から説明します
※5秒ほど動画再生を推奨
この
となり、行列積の「結合法則」によって成り立ちます
では次に上部の説明ですが
※5秒ほど動画再生を推奨
よって推論時
こうした推論時の重み「absorb(吸収)」はLoraを彷彿とさせますが
むしろ逆のことをしていると感じました(伝われ)
5章を総括すると「推論を見据えたモデル構造」がトレンドと言えるでしょう
=つまりモデル設計・学習をさせる研究者も推論時のスケーラビリティを考える必要がある!
6. まとめ
6.1 要約
KVキャッシュを知らずにコンテキストエンジニアリングは語れない
個人PCや1ノード環境ではGGUFフォーマットやそれに付随する量子化に強いOllamaが
選ばれがちですが、以下の特徴を持つvLLMも要注目という話でした
- マルチノードに対応
- 同時多数のリクエスト時に高スループットを維持
- GRPOアルゴリズムでは学習にも使われている
※vLLM V1とV0では最適化戦略が異なる
スパコンもKubernetes対応しないと…
・llm-dやNvidia Dynamo等の優秀なOSSが使えない(Difyも…)
・RedHat(OpenShift)依存が強まる
学習と推論は表裏一体
6.2 【本題】Claude Codeの話に戻る
AnthropicのモデルやCLIはクローズなので、以下の答えは定かでありません
- vLLM系の推論プラットフォームを使用しているか
- Claudeモデル構造自体にKVキャッシュ削減のために、どのような工夫を施しているか
しかしLLMの自己回帰的な性質およびClaude Codeのクライアント側からKVキャッシュを有効化していることからも、4章で紹介したOSSと類似のフレームワークを使用していることは明らかです
今後、プロンプト→コンテキストエンジニアリングに視野を広げて開発を行う際は、KVキャッシュの存在を意識し、ヒット割合を上げるコンテキストの累積方法やサブエージェントへの分割を心掛けたいと思います
6.3 【疑問1】なぜ定額プランで提供できるのか
またユーザが介入が少ないAgenticな性質もClaude Codeのコスト削減に貢献すると考えます
- KVキャッシュのデフォルトの有効化➡コスト削減
- 人間の応答を待つ必要が減る➡GPUメモリ上からオフロードする前に続きのリクエストが来る
ちなみにClaude Sonnet 4.5 自体は 1Mトークンをサポートしていますが
Claude Codeでの定額使用においては
$200/月のMaxプランのユーザの中でもTier 4以上等のユーザを除き200Kの上限を維持しています
その理由はコンテキスト長に比例してGPU数が必要になるからです
6.4 【疑問2】なぜMulti Tool Useを進めるのか
Claude Code v2.0.9以降
複数Toolの同時使用によるバグが多発し、hooksユーザを中心に大騒動になりました
私もこれにより最新版で実験ができずv2.0.8で固定して何とか凌いだのですが
固定するのも一苦労で時間を食いました
/.claude/settings.jsonに以下を追加するだけでは効果がなく
{
"envs": {
"DISABLE_AUTOUPDATER": "1"
}
}
以下のようにclaude起動直前に環境変数をセットする方法で固定しました
DISABLE_AUTOUPDATER=1 claude ...
そうしたバグがある状態でリリースした一因は
Sonnet 4.5自体が下記のようなコスト削減効果を狙って
Multi Tool Use(複数ツール同時使用)を積極的に学習させたから推測しています
Decord( Tool呼び出しコマンド )➡ユーザの環境に転送してTool実行して結果を返す➡Prefill()➡Decord( Tool呼び出しコマンド )
切り替えのオーバーヘッドが無視できない
6.5 【展望】サブエージェント➡Agentフォークへの期待
またClaude CodeのAgent(サブエージェント機能)もコンテキストエンジニアリングの主軸です
Pluginsの要素の1つです
メインのエージェントと共通のシステムプロンプトとMCP以外の履歴を持たないKVキャッシュ共有率の高いサブエージェントを新規作成します
指定の項目を記入した.mdファイルなのですが、メインのエージェントが必要に応じて起動してくれる点が画期的です
とはいえ、メインエージェントのコンテキストをほぼそのまま流用したいという声もあります
KVキャッシュ最適化という観点からも、そこまでコストに悪影響を及ぼすものではないので
「エージェントの身代わりが一連の処理を行い、異常がなければメインエージェントに戻る」といった使い方やコンテキスト圧縮への貢献をアピールすれば、Agentフォークのような要望が通る気がします
ちなみにOpenAIのCodex CLIの方は、サブエージェント機能のPRは出ているようですが2025/10末時点で承認されていないので発展途上に感じます
今回扱わなかったもの
- GGUF等の量子化モデルと相性の良いOllamaサーバ
- 複数Loraでも性能が落ちないサーバ(例:s-lora, punica)
- PrefillとDecord(P/D)の特性差に注目した研究
P/D論文リスト
Prefillのみサーバで行いDecodeだけ個人のデバイスで行う
P/D-Device(arXiv 2025年8月)
「OverFill」Prefillを大型モデルで行えばDecodeは小型モデルでも性能が落ちにくい
Discussion