ワシントン大学/Kotoba Technologiesの釜堀です。専門は機械学習システムで、LLMなどの推論を効率化する技術を研究・開発しています。
現代のLLMは莫大な計算・メモリを要するため、LLMを使ったサービスを提供する際には推論の効率性が非常に重要です。この分野はここ数年活発に研究されていて、vLLMやSGLangなど非常に高性能なOSSも出てきています。LLMのservingは、コンピュータサイエンスの知見を総動員させて最適化されている奥深い世界ですが、一方で中身を理解するには多くの前提知識が必要です。
そこでこの記事ではTransformerモデルを中心に、LLMのserving system(多数のクライアントにLLM推論を提供するシステム)でどのようなテクニックが使われているのかについて体系的に解説していきます。
構成としては、LLM servingで最も重要な概念である「バッチ推論」と「KVキャッシュマネジメント」について、現代のserving systemの基礎となっている技術を紹介します。さらに、「実装の工夫」「アルゴリズムの工夫」「モデルアーキテクチャの工夫」「分散処理」という4つの軸で、より細かく様々な技術について見ていきます。面白そうなところだけでもつまみ食いしていただければと思います。
この記事がきっかけで、より多くの方にこの分野に興味を持ってもらえると嬉しいです。
1. 前提知識
この記事では、「Transformerの大まかな仕組み(attentionやMLP)」「LLMの推論の仕組み(自己回帰推論、prefillとdecodeの違い)」「KVキャッシュとは何か」といった内容は前提知識とします。このあたりを理解するためには以下の記事がおすすめです。
- 30分で完全理解するTransformerの世界
- LLM テクニックの習得: 推論の最適化
- LLM推論に関する技術メモ
- LLM Inference Series: 2. The two-phase process behind LLMs’ responses
- LLM Inference Series: 3. KV caching explained
2. バッチ推論
LLM servingにおいて最も重要な概念がバッチ処理(複数のリクエストの処理を同時に行うこと)です。というのも、LLM推論は基本的にバッチサイズが大きいほど効率がよくなるからです。
2.1. なぜバッチ処理をしたいのか
コンピュータの計算は一般に「データアクセス」と「アクセスしたデータに対する計算」の2つの要素があり、ある処理にかかる時間はこの2つのうち長い方がボトルネックになります。
このことを説明したのがRooflineモデルです。これは横軸に演算密度(1回のデータアクセスあたり何回の計算をするか)を、縦軸に計算効率(FLOPS)をとったグラフで、「達成可能な最大の計算速度は、演算密度によって決まる」ということを示しています。
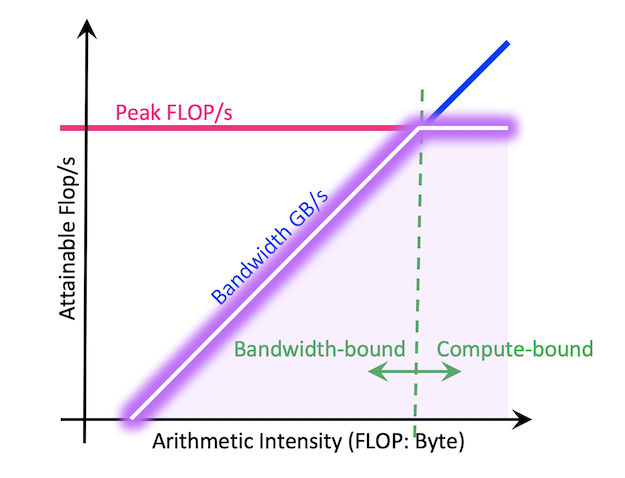
https://docs.nersc.gov/tools/performance/roofline/
計算密度が高い、つまり1つのデータあたり多くの計算をするとき、計算時間がボトルネックとなり、ハードウェアの限界近くまで計算能力を発揮できます(compute-bound)。
逆に計算密度が低い、つまり1つの計算あたり多くのデータにアクセスする必要があるとき、メモリアクセス時間がボトルネックとなり、計算能力はあまり発揮できません(memory-bound)。
LLMに話を戻します。リクエストが1つしかないとき、LLMの大部分を占める線形層(self-attentionのquery/key/value/out projection、MLPのup/down/gate layer)でのdecodeフェーズにおける計算は、hidden sizeを
- 必要なメモリアクセス量:
d + dn - 必要な計算量:
dn 1 \times n d
なので、
では、リクエストが2つある場合はどうでしょうか。この時、メモリアクセス量は
ここで、リクエストの数(=バッチサイズ)が2倍になったら、FLOPSも(ほぼ)2倍になりました。つまり、必要な計算量は2倍になりましたが、計算効率も(ほぼ)2倍になるので、この処理にかかる時間はほぼ一定のままです。リクエスト数を1から2に増やすのは時間的にはノーコストということです。
演算密度はバッチサイズと正の相関があるので、memory-boundの領域にいる限りは、バッチサイズを増やすほど計算効率は良くなります。現代のGPUとLLMの組み合わせではバッチサイズがだいたい数百程度でcompute-boundになるので、そこまでバッチサイズを増やすことがserving systemの目標となります。
(ここではdecode フェーズを考えましたが、prefill フェーズでは1リクエストに対しても複数トークンを同時に処理するためcompute-boundになり得ます。LLMの文脈ではバッチサイズ=合計トークン数と考えるとシンプルです。)
2.2. Continuous Batching
もうひとつ、バッチ推論に関して重要なアイデアがContinuous Batching(In-flight Batchingとも)です。
LLM推論の特徴として、リクエストごとに入出力のトークン数にばらつきがあることです。単純なバッチ推論の実装では、
- 決まったバッチサイズの分のリクエストが来るまで待ち、
- それらの処理を同時に開始し、
- 全ての処理が終わったら次のバッチの処理を開始する
といった形になります。しかし、リクエストによって推論を何サイクル回すか(=何トークン出力するか)が異なるため、効率的とは言えません。
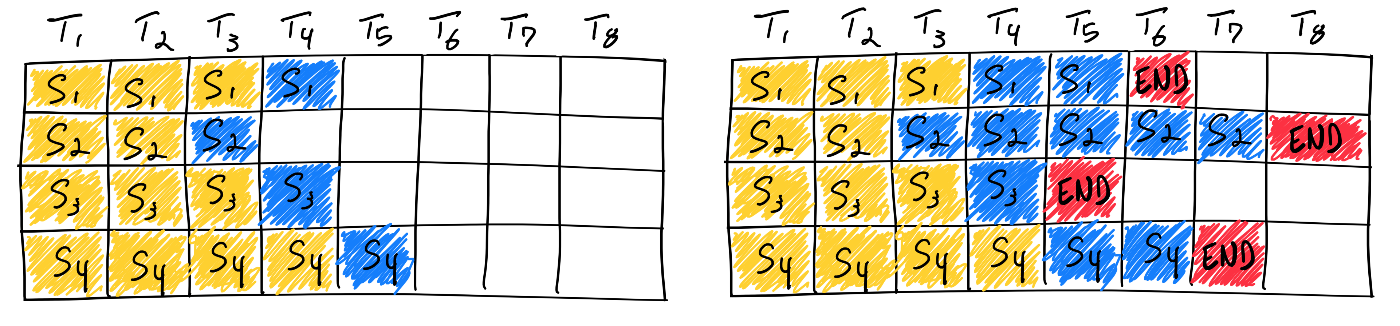
https://www.anyscale.com/blog/continuous-batching-llm-inference
上の図の例を考えてみます。黄色がprefillのトークン、青色がdecodeのトークン、赤色が終了を表すトークンで、バッチサイズ4で推論します。推論のためのスロットが4つあると考えます。
S1〜S4の4のリクエストが揃ったところで処理を開始し、それぞれ1つずつトークンをデコードしていきます(左)。数サイクル後、各リクエストが終了トークンを出力するタイミングは異なるため、終盤では計算効率は下がってしまいます(右)。例えばS3は2サイクル目で終わっていても、最も長くかかるS2が終わるまでは6サイクルかかるため、その間の4サイクルの間、S3のために用意されていたスロットは無駄になってしまいます。

https://www.anyscale.com/blog/continuous-batching-llm-inference
これに対してcontinuous batchingでは、バッチ内の全てのリクエストが終わるのを待つことなく、バッチに空きが出るたびに新しいリクエストを割り当てていきます。図の例で言うと、S3の処理が終わったタイミングで、S2を待つことなく新たなリクエストS5の処理を開始します。
こうすることで、continuous batchingはリクエストごとに入出力長にばらつきがあっても、GPUの利用率を常に高めることができます。
3. KVキャッシュマネジメント
さて、先ほど見たようにバッチサイズを増やすことが基本戦略となるわけですが、そのためには一つの障壁があります。それはKVキャッシュのメモリ消費量です。
上記のcontinuous batchingによってバッチ内のスロットが無駄になることはなくなりましたが、実現可能な最大バッチサイズにはメモリ容量の制限があります。前述の通りLLMの入出力トークン数は一定ではないので、各リクエストのためにどれだけのKVキャッシュを用意すればいいのか事前には分かりません。
ナイーブな実装では新しいリクエストが来るたびにモデルの最大コンテクスト長までKVキャッシュ用のメモリを確保することになりますが、全てのリクエストがそれだけのメモリを必要とするわけではないので、無駄が発生し、バッチサイズが制限されてしまいます。例えばLlama 2 7Bモデルでは[1]、1トークンあたりのKVキャッシュのサイズは精度16ビットで、
32 (layer) x 4096 (hidden size) x 2 (K/V) x 2 (byte/parameter) = 512KB
で、最大コンテクスト長は4096のため、本当に必要とするトークン数によらず、1リクエストあたり512KB x 4096 = 2GBものメモリが必要です。これは例えば80GBメモリを持つH100であっても、30リクエストほどしか同時に処理できない計算になります[2][3]。より最近のモデルではコンテクスト長が数十万以上になり、この実装は非現実的です。
3.1. PagedAttention
この問題を改善したのが、vLLMの元論文で提案されたPagedAttentionです。これは古典的なOSにおけるページングに着想を得て、KVキャッシュを仮想アドレス空間と物理アドレス空間に分ける手法です。
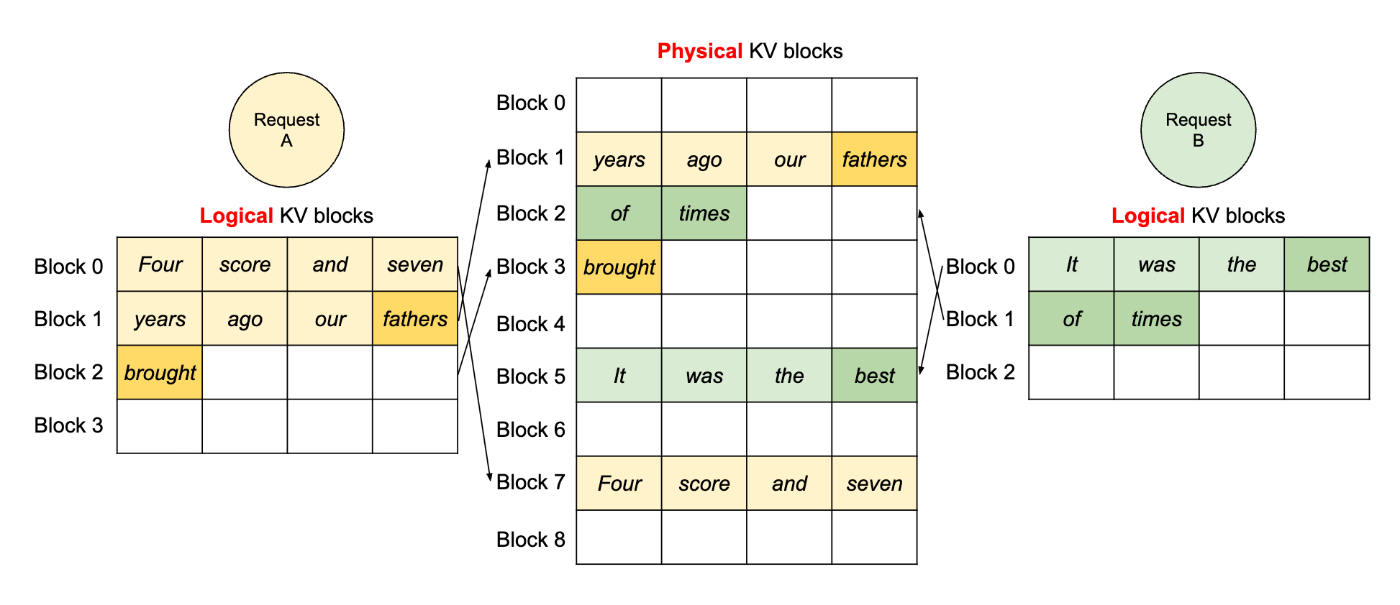
https://arxiv.org/pdf/2309.06180
上図中央にある物理 KV ブロックはあらかじめ固定サイズに分割されたバッファです。この例では、リクエストAが3個の、リクエストBが2個のブロックを必要としています。各リクエストには論理ブロックとして連続しているように見えていますが、実際にはバラバラの領域に保存されています。たとえばリクエストAは物理ブロックの1、7、3を、Bは5、2を使っています。実際にメモリアクセスが発生した際は、仮想アドレスから物理アドレスへ変換されます。
リクエストが終了した際は、そのリクエストが保有していた物理ブロックが解放され、他のリクエストが使うことができるようになります。そのためメモリのフラグメンテーションが発生せず、バッチサイズを最大まで増やして推論効率を上げることができます。
3.2. Prefixキャッシュ
もう一点、KVキャッシュについて重要な点が、KVキャッシュのprefixは再利用可能だということです。LLMはcausal attentionを用い、KVキャッシュの依存関係は過去→未来(左→右)にのみ存在するため、プロンプトのprefixが共通であればそれに対応するKVキャッシュは変わらないという性質があります。


https://arxiv.org/pdf/2312.07104v1
これは例えば、上図のようにLLMのシステムプロンプトを使う場合や、長い文章を読ませてそれに対する複数の質問をする場合、チャットボットで複数ターンの会話をする場合などに、prefillに要する計算量を減らしつつ、KVキャッシュに必要なメモリ容量も減らすことができます。
https://arxiv.org/pdf/2312.07104v1
SGLangの元論文では、KVキャッシュの再利用をradix treeとして整理したRadixAttentionというフレームワークを提案しています。さらにGPUメモリを効率的に使うために、LRUエビクション等を実装し、servingの性能を向上させています。
4. 実装の工夫
これまでLLM servingの土台となるアイデアをいくつか見てきましたが、実際に効率的なシステムを実装するためにはあらゆるレイヤで効率性を意識する必要があります。
4.1. CUDAカーネル
カーネルとはGPUで実行されるプログラムの単位のことです。通常GPUアプリケーションは多数のカーネルを呼び出しますが、カーネルの起動には無視できないほどのオーバーヘッドが発生します。
カーネル融合 (kernel fusion)
カーネル融合 (kernel fusion) とは複数のカーネルを一つにまとめ、そのオーバーヘッドを小さくする手法です。例えば「行列乗算→ReLU関数」のような計算をするとき、通常はまず行列乗算用のカーネルを起動し、その結果を GPU のグローバルメモリに書き戻してから、次にそのデータを再び読み込む形で ReLU カーネルを起動します。ReLUは実際にはelement-wiseの単純な計算であるにもかかわらず、全てのデータを読み書きする必要があるため、これは非効率です。
カーネル融合を適用すると、行列乗算の出力を一度もメモリに戻さず、乗算の結果にそのまま ReLU を適用する1つのカーネルにまとめられます。これにより、メモリ転送回数が減少して帯域幅の消費や実行時間が大幅に低減されます。torch.compileなどのコンパイラの内部ではカーネル融合の最適化が多く行われます。
FlashAttention
Transformerにおいて最も重要なカーネル融合はFlashAttentionです。
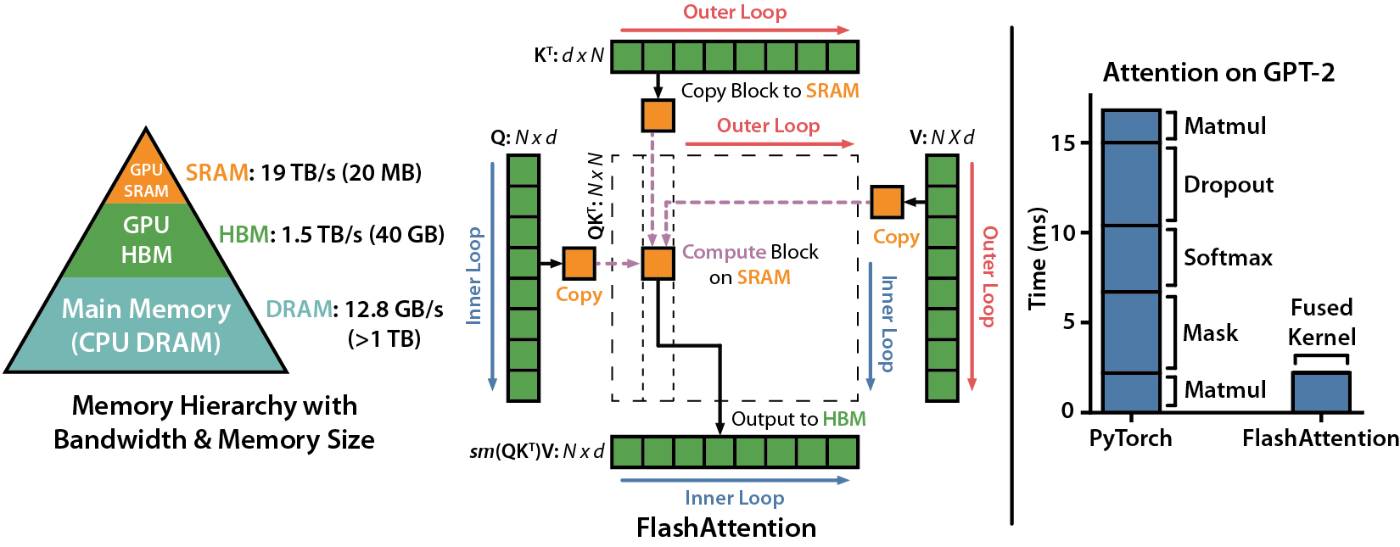
https://github.com/Dao-AILab/flash-attention
FlashAttention は、attention計算におけるメモリアクセスを最適化する手法です。カーネル融合をしない実装では、クエリ(Q)とキー(K)の内積を取って得られるattentionスコア行列を一度GPUのメモリに書き出し、再読み込みしてからソフトマックス処理とバリュー(V)との乗算を行います。ここでattentionスコア行列の大きさは入力トークン数の2乗に比例するため、長系列を扱う場合は特に、この実装ではメモリアクセスが非効率です。
FlashAttention では、これら「QK計算→ソフトマックス→Vとの乗算」の流れを一つのCUDAカーネルにまとめ、GPUのキャッシュ内でタイル単位に処理を完結させることで、メモリへの不要な読み書きをほぼゼロに抑えています。これにより、メモリ帯域幅の使用量が大幅に削減され、長系列でもattentionを効率よく計算することができます。
後続のFlashAttention-2やFlashAttention-3では、最新のGPUアーキテクチャでのパフォーマンスをさらに上げるため、作業分割の最適化や計算とデータ転送を並行化などの最適化をしています。
FlashInfer
FlashInferは、FlashAttentionや先述のPagedAttentionなど様々なテクニックを実装した高性能なCUDAカーネルライブラリです。Pythonから使いやすいようにインターフェースも提供され、多くのserving systemでattentionのバックエンドとして使われています。
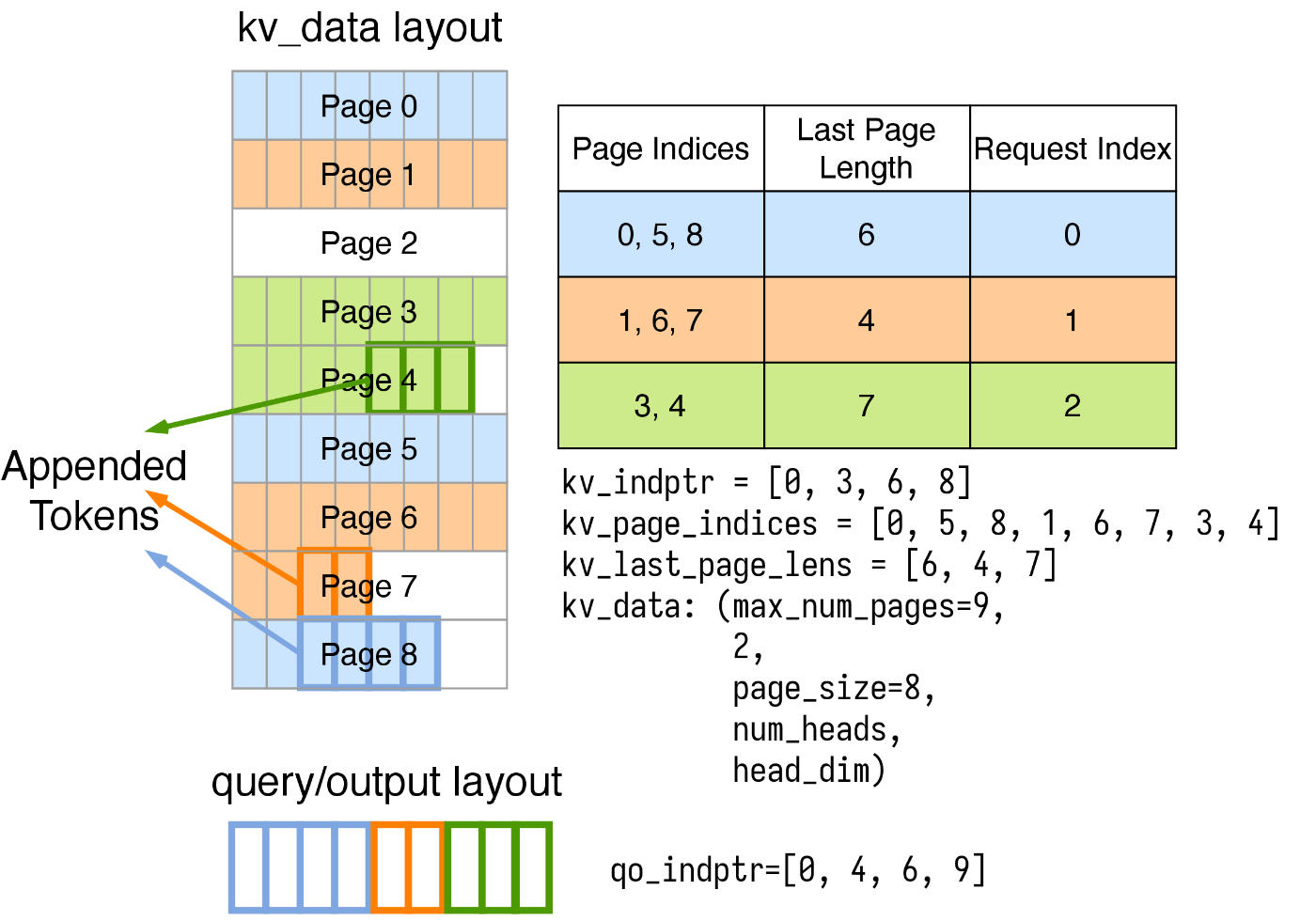
https://docs.flashinfer.ai/tutorials/kv_layout.html
FlashInferではLLMで必要とされる様々なattentionのワークロードに対応するため、KV キャッシュをCSR形式の疎行列として表現します。
実際に使う際は、KVキャッシュはユーザ側で確保・管理され、FlashInferはprefillまたはdecode用のattention wrapperを提供します。推論を回す前にplan関数で入力のバッチサイズや系列長を指定し、FlashInferはGPUのコア間のロードバランシングなどを考慮した実行プランを用意します。その後、run関数にクエリとKVキャッシュを入力することで実際の計算が行われます。
ちなみにFlashInferは、attention以外にもrejection samplingを利用したTop-K/Top-Pサンプリング用のカーネルなど、LLM servingで使える様々なカーネルを提供しています。
NanoFlow
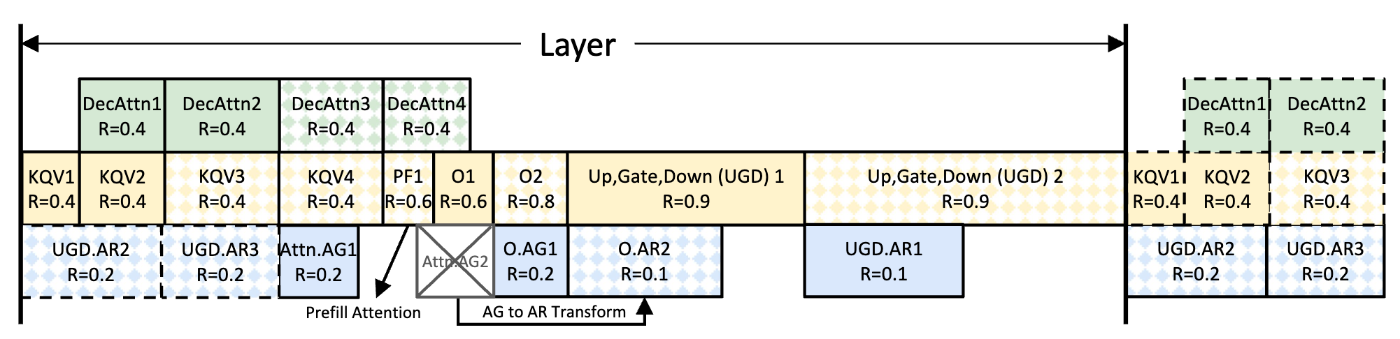
https://arxiv.org/pdf/2408.12757
また、カーネル融合とは少し違いますが、NanoFlowは1つのバッチをさらに小さい単位に分割した上で、memory-boundの計算(decodeのattention)とcompute-boundの計算(prefillのattention、prefill/decodeの線形層)、さらにGPU間のコミュニケーションをうまくオーバーラップさせることで、servingの性能をハードウェアの限界近くまで引き上げるシステムです。
Multi-LoRA
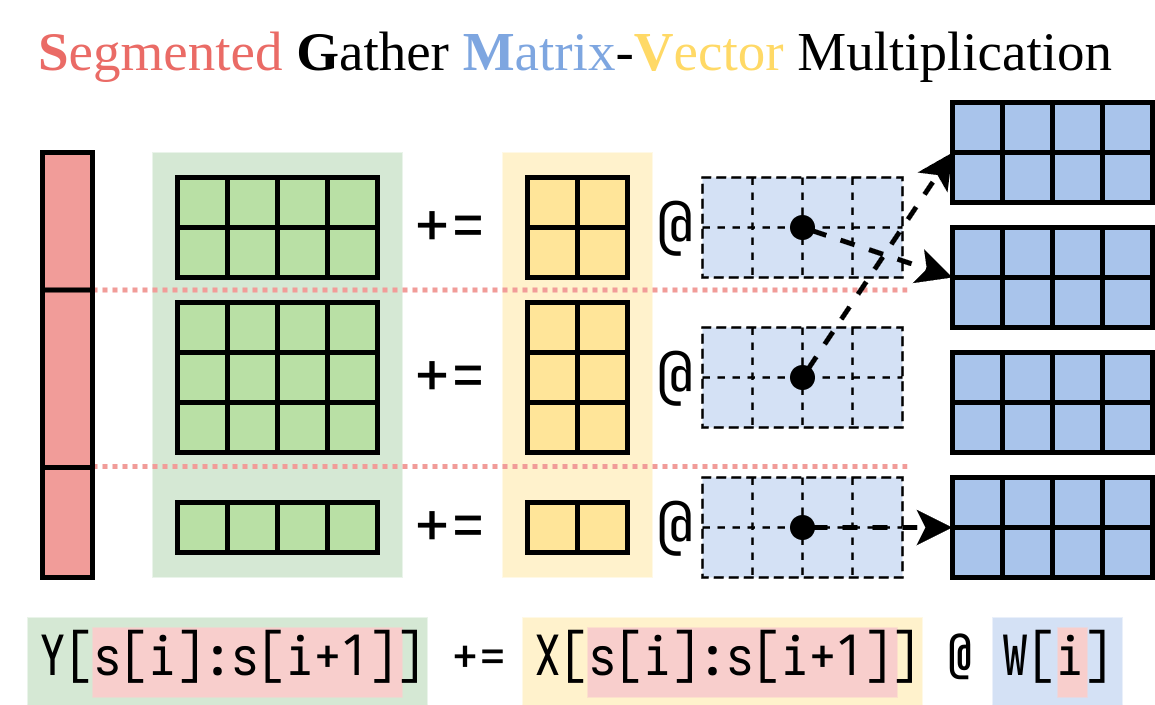
https://github.com/punica-ai/punica
LoRA (Low Rank Adaptation)はLLMのファインチューニングの方法の一つで、低ランクな行列だけを追加で学習することで、モデル本体のパラメータを凍結しつつ少数のパラメータだけを微調整する手法です。推論の観点では、LoRAで追加されるパラメータはもとのモデルよりも小さい(数%程度)ため、1つのベースモデルに対して複数のLoRAを用意しておき、リクエストごとに切り替えることが可能です。
PunicaやS-LoRAはこれを可能にした研究で、上図のようなCUDAカーネルを実装して低ランク行列部分をリクエストごとに選べるようにすることで、複数のLoRA adaptorを同時にservingします。これによって、ユーザそれぞれにチューニングされたモデルでの推論を1つのサーバから提供することが可能になります。
4.2. CPUオーバーヘッドの最適化
GPUの計算がいくら速くなっても、それ以外の部分が遅いとシステム全体のパフォーマンスは良くなりません。何も考えずにPythonでGPUプログラムを書くと、往々にしてCPU側の処理がボトルネックとなってしまうことがあります。
CUDA Graph
それを解決する手段の一つとして、CUDA Graphがあります。CUDA Graph は、多数のカーネル起動やメモリ転送といった操作をあらかじめ「グラフ」として記述し、その後まとめて実行・再利用できる仕組みです。

https://pytorch.org/blog/accelerating-pytorch-with-cuda-graphs/
通常、GPU に対するカーネル呼び出しやデータコピーはそれぞれホスト側から API を呼び出すたびにオーバーヘッドが発生しますが、CUDA Graph ではこれらを一連のノード(演算)とエッジ(依存関係)で表現します。一度このグラフをキャプチャしておけば、以降はホストから、グラフ起動の一回の操作をするだけでで全工程をまとめて走らせられます。これにより、カーネル起動やメモリコピーのオーバーヘッド、CPUでのPythonに起因するオーバーヘッドなどを大幅に削減できます。特にモデルサイズが小さいケースで威力を発揮します。
CUDA GraphはPyTorchのインターフェースから使うのが簡単です。torch.compileの機能の一つとしても実装されています。
CUDA Graphの制約として、入出力のバッファサイズが一定である必要があります。LLM servingにおいては、特にattention層の入出力トークン数はサイクルごとに変わってしまうため、CUDA Graphを使うためには工夫が必要になります。
実装の一例として、vLLMのV1アーキテクチャではattentionとattentionの間の部分のみをCUDA Graphとして用意することでこの問題を解決しています。また起動時に [1, 2, 4, 8, ...] といった特定のバッチサイズのグラフを用意し、実行時には適宜入力をパッドしてグラフを起動します[4]。
それ以外にも、たとえばリクエストあたりのトークン数が固定されているdecodeフェーズに限定するなどして、上述のFlashInferのようなKVキャッシュのバッファが固定されているようなライブラリを使えば、attention層も含めてCUDA Graphにキャプチャすることが可能です。
非同期処理
また、CPUとGPUの処理を非同期的にすることで、CPU側がボトルネックとなることを防げます。
LLM servingの一般的な実行の流れは、
- i サイクル目のLLM推論(GPU)
- i + 1 サイクル目の準備(CPU)
- i + 1 サイクル目のLLM推論(GPU)
- i + 2 サイクル目の準備(CPU)
- ...
といったものになります。次のサイクルの準備では、新しく来たリクエストや終了したリクエストを管理し、生成されたトークンをユーザにストリームし、といったCPU側のスケジューリング処理が必要になります。特にGPU側で推論するモデルが小さい場合などに、このCPUのオーバーヘッドは無視できないものになります。

https://lmsys.org/blog/2024-12-04-sglang-v0-4/
これを解決するため、CPUのスケジューラをGPUと非同期的に動くようにして、CPUが1サイクル先読みして処理することが行われています。具体的には、GPUのiサイクル目の推論が終わる前にCPUがi + 1サイクル目のスケジューリングを行います。もしあるリクエストがiサイクル目で終了トークンを出力した場合、CPU側がそれを知るのはGPUのi + 1サイクル目の推論の途中であるため、i + 2サイクル目のスケジュールからそのリクエストを取り除きます。このように1トークン余計に生成してしまう代わりにCPUスケジューリングがクリティカルパスから外れ、結果として全体の性能は向上します。上図はSGLangのブログのものですが、vLLMでも似たような機能が実装されています。

https://blog.vllm.ai/2025/01/27/v1-alpha-release.html
また、実際にAPIサーバとして使う際は、クライアントとやりとりしトークナイザなどを走らせる部分と、実際にモデル推論を走らせる部分を別プロセスとして建て、それらの間でZeroMQのようなIPCライブラリを使ってデータをやりとりすることで、GPUの使用率を最大化することができます。
4.3. スケジューリング
これまでシステム全体の性能を上げる方法を見てきましたが、実用上はスループット(単位時間あたりに生成できる合計トークン数)だけではなくレイテンシ(あるユーザが体験する遅延時間)も重要です。また、全体として効率が良くても、それが特定のユーザの体験を犠牲にした結果であったとしたら望ましくありません。
LLM servingのSLOとしては、よく以下の二つが使われます。
- Time To First Token (TTFT): ユーザがリクエストを送ってから、最初のトークンが返ってくるまでの時間。Prefill フェーズに相当。
- Time Per Output Token (TPOT): 最初のトークン生成後に、追加で各出力トークンを生成するのに要する平均時間。Decode フェーズに相当。
アプリケーションによって細かい要件は異なりますが、一般にTTFTとTPOTの両方が大きくなりすぎないようにすることが求められます。しかし、スケジューリングのロジックを工夫しないと、両方の要件を満たせなくなる場合があります。
例えば、あるユーザが入力長の非常に長いリクエストを送った場合、単純に「リクエストを来た順に処理する」といったスケジューリングをしていると、そのユーザのprefillのために時間がかかりすぎて、他のユーザのTPOTが大きくなってしまう、といったケースが考えられます。
これを解決するために、以下のような手法が提案されています。
Chunked Prefill

Chunked Prefillとは、入力が長い場合でもPrefillを分割し、一度に処理するトークン数に制限を設けるスケジューリング手法です。これによって推論のサイクル1回あたりにかかる時間が長くなりすぎるのを防ぐことができます。他のリクエストのdecodeをチャンクされたprefillと同時に処理する(ピギーバックする)ことで、TPOTを小さくおさえることができます。
PrefillとDecodeの分離 (disaggregation)
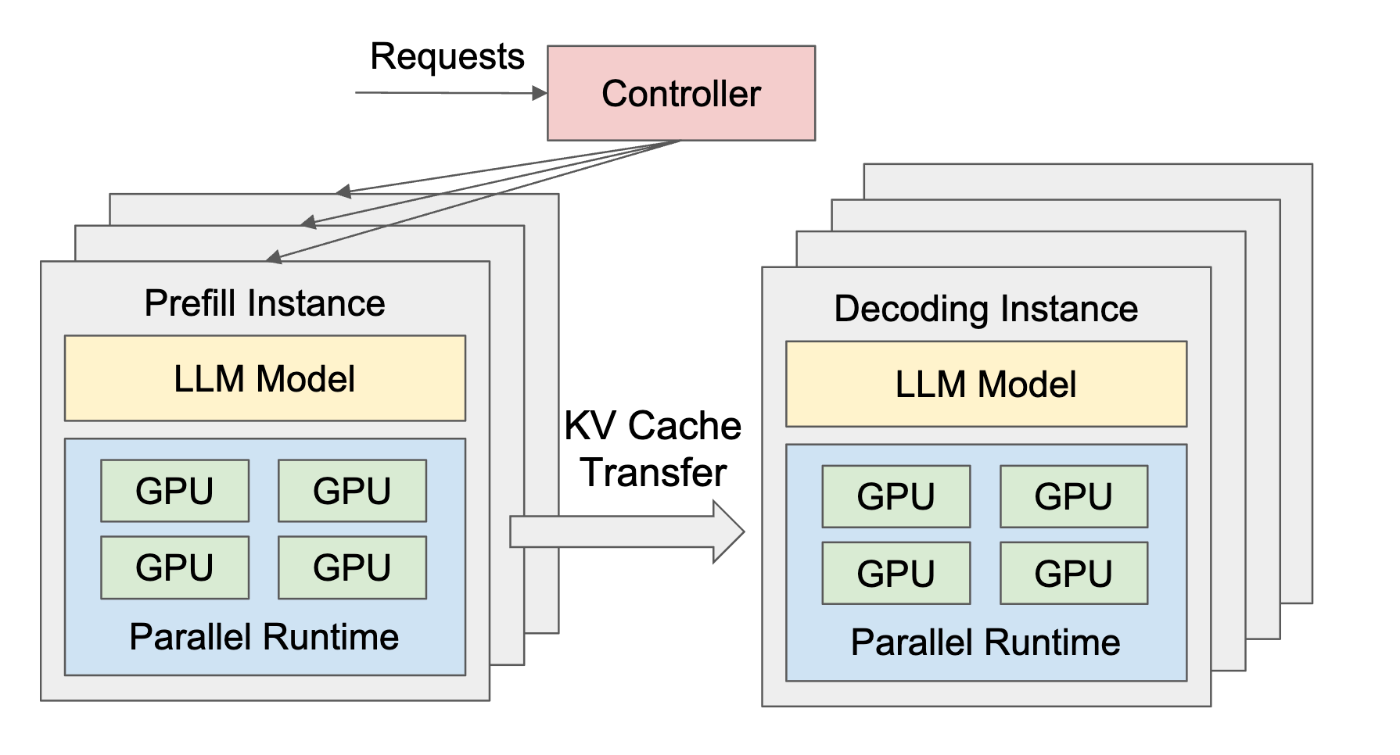
https://arxiv.org/pdf/2401.09670
これまで見てきたように、prefillフェーズとdecodeフェーズでは計算の特性が大きく異なるため、それらを別々のGPUで実行するような手法も提案されています。リクエストはまずprefill用のGPUでプロンプトが処理され、計算されたKVキャッシュがdecode用のGPUに送られ、そちらで残りのトークンが生成されます。
このような構成の利点として、それぞれのフェーズに適応したバッチ戦略などを使うことで、TTFTとTPOTを独立に最適化できます。また、disaggregated computing的な文脈では、prefill用とdecode用のサーバを独立にスケールさせられる点も利点になります。
5. アルゴリズムの工夫
これまで見てきた手法は、モデル本来の計算を保持したまま効率性を高めていくものでしたが、モデルの計算を簡略化して(サボって)効率を上げることもできます。
5.1. 量子化
量子化とはパラメータを表現するのに必要なビット数を削減する手法です。例えばFP16やBF16を使って訓練されたパラメータをINT8やINT4に置き換えることで、必要なメモリ容量を2分の1や4分の1にすることができます。当然推論の精度は下がりますが、LLMではうまく工夫することで精度を維持することができると知られています。
LLM servingの文脈では、大きく2種類の量子化手法があります。
- Weight-only quantization: 重みパラメータのみを量子化する。重みはメモリからロードされた後、16ビットに戻してから計算する。GPTQ、AWQ、GGUFなど。
- Weight-activation quantization: 重みパラメータと入力値(activation)両方を量子化する。低ビットのまま計算する。LLM.int8()、SmoothQuant、Atomなど。
これらは異なる計算特性を持ちます。最初に紹介したRooflineモデルを使って説明できます。
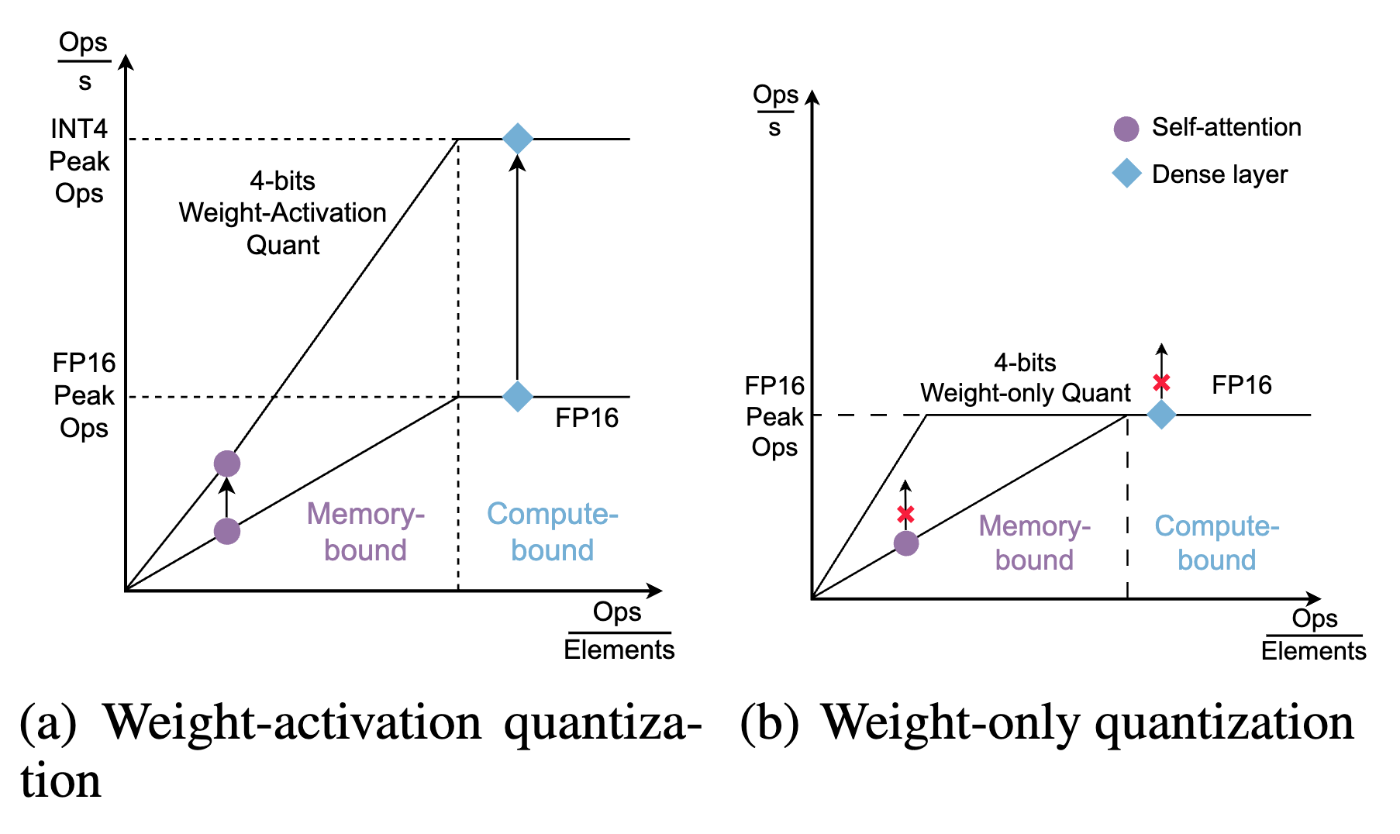
https://arxiv.org/pdf/2310.19102
Weight-onlyの場合(右)、重みが小さくなった分演算密度が上がるため、memory-boundの領域では計算効率が上がります。これはローカルLLMのように小さなバッチサイズで推論をする際には有用ですが、serving systemが大きなバッチサイズで推論する際には効果は限られてしまいます(もちろん、重みによるメモリ消費量が減るためバッチサイズが増やせるという効果はあります)。
一方、activationも量子化すると(左)、低ビットで行列計算を行うため、Tensor Coreなどの低ビット計算に最適化されたハードウェアを使うことができます。そのため、達成可能なFLOPSの最大値が上がり、バッチサイズが多くcompute-boundなケースでも推論のスループットを高めることができます。
いずれの場合も、実用上はたまに存在する外れ値の扱いが重要になります。多くの手法で、外れ値のみは16ビットで保持・計算するといった工夫がなされています。
ちなみに、activationと同様にKVキャッシュを量子化する試みもあります。
5.2. KVキャッシュのスパース化
量子化以外にも、KVキャッシュやパラメータの一部を捨てる(スパースにする)ことで推論効率を高められます。

https://arxiv.org/pdf/2309.17453
代表的な手法の一つにStreamingLLMがあります。これはLLMが訓練時に見たよりも長い系列を生成できるようにするための手法です。単純に過去全てのKVキャッシュを利用したり(Dense Attention)、過去NトークンのみのKVキャッシュを利用していると(Window Attention)、メモリ消費量が増えたり精度が大きく下がってしまいます。この論文では、系列の最初の数トークン(図中の黄色)のKVキャッシュは常に保持しておくようにすることで、精度の劣化を抑え、かつKVキャッシュのメモリ使用量が一定のまま半永久的に生成を続けられるということを提案しました。この手法は、文頭のトークンはたとえ人間的には意味がないものでも、LLM的には重要である(=attentionスコアが高くなる)ことが多いというヒューリスティックスに基づいています。
このように、長系列に対応しメモリ消費を抑えるためには、KVキャッシュのうち重要なものだけを残しそれ以外は捨てることが必要です。これ以外にもH2O、Quest、SeerAttentionなど様々は手法が提案されています。DeepSeekのNSAはこれらの知見をまとめ上げたモデルを訓練しています。
5.3. パラメータのスパース化
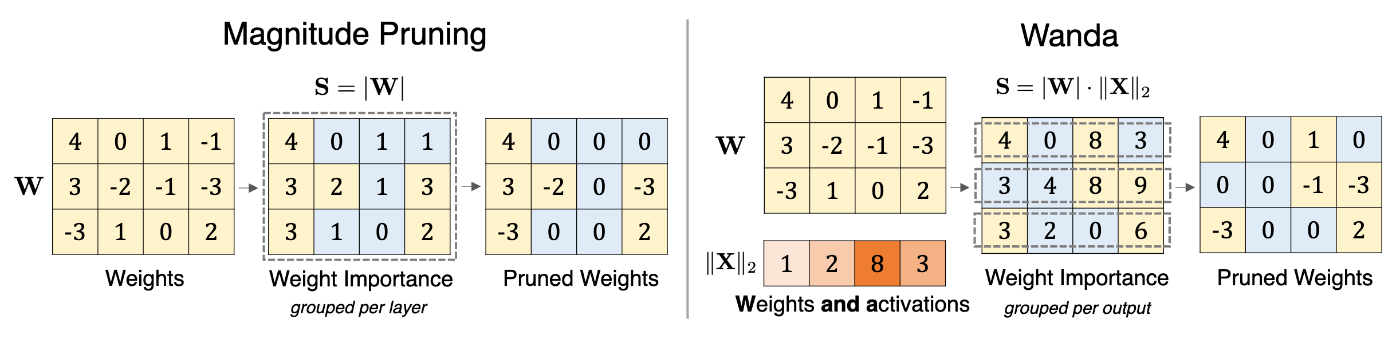
https://arxiv.org/pdf/2306.11695
パラメータそのものをスパースにする手法も提案されています。Wandaは重みと対応するactivationの値の積の絶対値が小さい(=出力に与える影響が小さい)ものをプルーニングし、推論効率を上げています。
また、活性化関数にReLUを使っているモデルでは、その入力が負になりやすい(=出力が0となり計算する必要がない)重みを削ぎ落とす手法も提案されています。
5.4. 投機的デコーディング(Speculative Decoding)

https://arxiv.org/pdf/2211.17192
投機的デコーディングは、大きなLLM(ターゲットモデル)のトークン生成を高速化するため、軽量のドラフトモデルと組み合わせる手法です。推論サイクルごとにドラフトモデルが複数トークンを生成し、ターゲットモデルがそれらを一括で検証することで、(ドラフトの精度が十分高ければ)推論速度を上げることができます。
上図の例だと、緑色がドラフトモデルが提案しターゲットモデルに採用されたトークン、赤色が却下されたトークン、青色がその代わりにターゲットモデルが生成したトークンです。1行がターゲットモデルの推論1サイクルに相当します。約40トークンを生成するのにターゲットモデルは9回しか回されていないことがわかります。
よく使われるアルゴリズムにMedusaやEAGLEがあります。DeepSeek-V3で採用されているMulti-Token Prediction (MTP)も、推論時には投機的デコーディング的な使い方をすることができます。
Serving systemの観点では、投機的デコーディングはユーザが体験するTPOTを下げることはできますが、ドラフトトークンの棄却による無駄な計算は発生するため、全体のスループットは必ずしも向上しません。
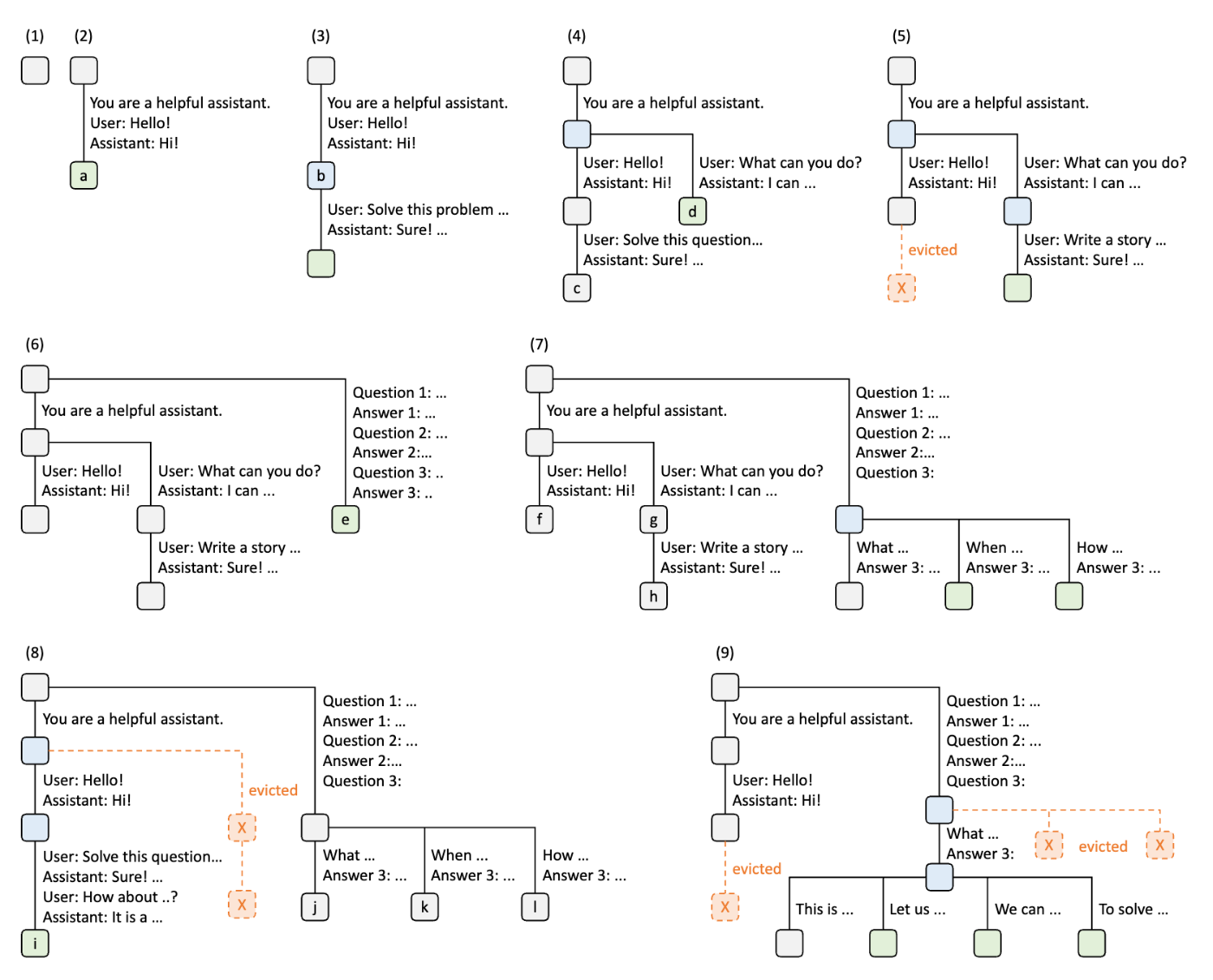
5.5. 構造的デコーディング(Structured Decoding)
構造的デコーディングとはLLMの生成する文章を特定のフォーマットに制限する手法です。例えばOpenAI APIではJSONスキーマを指定して生成することができます。これは、推論時にLLMが出力するlogits(各トークンが選ばれる確率)を操作することで実現でき、正規表現や文脈自由文法で生成を制約できるライブラリが開発されています。

https://lmsys.org/blog/2024-02-05-compressed-fsm/
これを利用した推論の高速化も可能です。制約によって次のトークンが一意に確定する場合は、わざわざLLMに予測させる必要はなく、推論のサイクル数を減らすことができるためです。
上図の例ではハリーポッターの登場人物の名前・年齢・寮をJSON形式で出力させています。オレンジ色になっているのが、制約によって一意に定まるためLLMに予測させる必要のないトークンです。例えばJSONのキーの部分("name"など)は必要なキーの順番が定まっていれば一意に定まります。寮の名前に関しても、validな名前のリスト(Gryffindor, Hufflepuff, Ravenclaw, Slytherin)をあらかじめ指定しておけば、例えば「G」が生成された時点でGryffindorに確定します。こうすることで、単純に1トークンずつ生成する場合(図の下半分)と比べて、必要な推論サイクル数を大幅に減らすことができます。
5.6. マルチモーダル
また、マルチモーダルのLLMに特化した最適化もいくつか提案されています。例えば音声モデルで使われるエンコーダを低ランク近似するLiteASRや、動画生成モデルのattentionをスパースにするSparse VideoGenなどがあります。
6. モデルアーキテクチャの工夫
システム面だけでなく、モデルアーキテクチャの設計においても、推論効率を意識した工夫もあります。
6.1. MQA, GQA, MLA
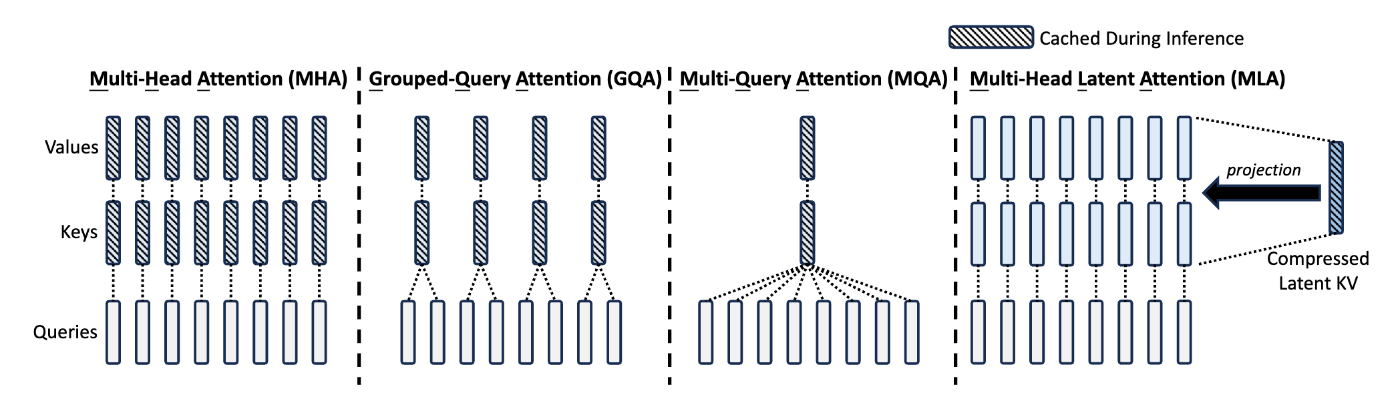
https://arxiv.org/pdf/2405.04434
特にLLM servingの性能に大きく影響するのが、attentionヘッドの構成です。オリジナルのmulti-head attention (MHA)ではクエリ、キー、バリューはそれぞれ同じ数のヘッドを持っていましたが、multi-query attention (MQA)ではキーとバリューのヘッドが1つしかなく、クエリのヘッドはそれらを共有するという構成になっています。間をとったgrouped-query attention (GQA)ではクエリヘッドをグループ化し、各グループあたり1つだけキー・バリューヘッドがある構成になっています。最近のLLMはほとんどがGQAを採用しています。
これらの効果として、1トークンあたり必要なKVキャッシュが小さくなります。例えばクエリヘッドが32個、キー・バリューヘッドが8個のGQAを採用したモデルでは、オリジナルのMHAと比べKVキャッシュの容量が4分の1に減ります。これによって、先述のとおりバッチサイズを4倍に増やすことができます。これは非常に重要で、例えばNanoFlowの論文によると、GPUの性能をもとにスループットを最大化するserving systemを考えたとき、一般的な入出力長のもとではGQAの有無によってmemory-boundかcompute-boundかが切り替わることが示されています。
DeepSeek-V2で提案されたmulti-head latent attention (MLA)はこれらをさらに発展させ、キー・バリューの値をメモリに保存する際に低ランク行列に圧縮することで、KVキャッシュ容量をさらに減らしています。DeepSeek-V3やKimi-K2など最近の大規模モデルで使われています。
6.2. Sliding Window Attention (SWA)

https://mistral.ai/news/announcing-mistral-7b
Sliding Window Attention (SWA)とはattentionの際に過去Nトークンのみを参照するアーキテクチャで、KVキャッシュの大きさを制限することができます。代表的な使用例としてMistral 7Bで使われていました。より最近のモデルでは、レイヤごとに通常のグローバルなattentionとSWAを組み合わせるアーキテクチャが増えています(Gemma 3、Apple Intelligence、Command Aなど)。Mambaに代表されるState Space Model (SSM)も、必要なキャッシュのサイズを固定にするという点で、推論効率の観点からはSWAの類似と捉えることもできると考えられます。
こういったモデルに対するキャッシュのマネジメントとして、JengaはPagedAttentionをより一般化し、SWAやSSMのキャッシュも包括的に扱えるシステムを提案しています。
7. 分散処理
これまで見てきた技術は、基本GPU数の規模に関係なく使われるものです。複数のデバイスを使って分散的に推論する場合、データをどうやりとりするかなどを考える必要があります。
7.1. 並列化の方法
LLMの分散学習と同様に、いわゆる3D Parallelismはserving systemでも使われています。
- データ並列(DP):モデルパラメータを複数のデバイスに複製し、それぞれで独立に推論を回します。デバイス間の通信は必要なく、スループットはデバイス数に比例して上がりますが、レイテンシは下がりません。また、パラメータやKVキャッシュがGPUメモリをオーバーする場合は使えません。
-
パイプライン並列(PP):モデルパラメータを、レイヤごとに別々のデバイスに載せます。デバイス間の通信はレイヤ間のactivationのみで、メモリ消費を減らしスループットも向上しますが、レイテンシは下がりません。
- 学習時とは異なり、backwardの計算は不要なため、パイプラインのバブルは基本発生しません。
-
テンソル並列(TP):モデルの重み行列それぞれを複数のデバイスに分割します。メモリ消費量を減らしスループットが向上しレイテンシも下がりますが、All-Reduceの通信が必要となりデバイス間の通信量は多くなります。
- 通信量を減らすため、レイヤごとに別々の次元で分割します。例えばMLPだと、up/gateは列ごとに分けるが、downは行ごとに分けるといった具合です。Attentionではヘッド次元で分けることが多いです。
その他にも、Mixtur-of-Experts (MoE)モデルではエキスパート並列(EP)も広く使われています。これは異なるエキスパートの重みをそれぞれ別のデバイスに置く方法で、大規模なMoEモデルでは必要不可欠ですが、All-to-Allのコミュニケーションのコストやデバイス間のロードバランシングが課題になります。
さらに、特に長系列のモデルでは系列次元での並列化も提案されています。
実用上は、これらの並列化を組み合わせて運用することが多いです。例えば、マルチノードの推論ではノード間はPPだがノード内はTP、MoEモデルではattentionレイヤはDPだがMoEレイヤはEPといった具合です。
7.2. オフローディング
ユースケースによっては、GPU上のデータや計算の一部をCPUなど他のデバイスにオフロードする手法も提案されています。KVキャッシュの一部をより容量の大きいCPUメモリやストレージにオフロードしたり、GPUのメモリが限られている場合に特定のレイヤやエキスパートをCPUにオフロードしたりといった具合です。
7.3. 強化学習
LLM serving systemは推論を提供するサービスのみならず、強化学習によるLLMの学習時にも使われています。強化学習ではLLMに複数の文章を生成させそれらに報酬を与える必要があるため、訓練システムであっても推論性能が高い必要があります。例えばOpenRLHF、verl、SkyRLなどの強化学習フレームワークはvLLMなどを内部で使っています。
7.4. DeepSeekのインフラ
最後に、DeepSeekが今年2月に公開した推論インフラについて説明します。これは実際の大規模推論システムについて知ることができる貴重な資料で、serving systemにおける金字塔的存在です。

https://lmsys.org/blog/2025-05-05-large-scale-ep/
DeepSeek-V3/R1は総パラメータ数685Bの非常に巨大なモデルで、複数ノードに分散させて推論する必要があります。エキスパート数は全体で256だが、うち推論に使われるのはトークンあたり8個だけと非常にスパースです。そのため推論効率を高めるためにはバッチサイズを非常に大きくする必要があり、メモリ容量の観点から大きなEPで運用する必要があります。実際には、エキスパートレイヤではEP、それ以外(共有エキスパートを含む)ではDPを使っています。

全体の構成として、prefillとdecodeが分離されており、それぞれ異なる並列度(prefillはDP32とEP32、decodeはDP144とEP144)とロードバランサを持っています。2つが分けられているのは、prefillはスループットを最大化することが主な目的となる反面、decodeではレイテンシの制約上バッチサイズを上げすぎることはできないためです。Decodeの方を大きな並列度にすることで、GPUあたりのエキスパート数を減らしてレイテンシを下げ、reasoningモデルのようにdecodeするトークン数が非常に多いケースに対応できるだけのメモリ容量を確保できると考えられます。
32や144といった並列度ではノード間通信が必要(1ノードは普通8GPU)となり、特にEPではAll-to-Allというオーバーヘッドの大きな通信が必要です。そのため、彼らはデータ転送のためのカーネルを実装し、さらにそれを計算時間とオーバーラップさせるために下図のように丁寧に計算パイプラインを設計しています。
Prefill:

Decode:
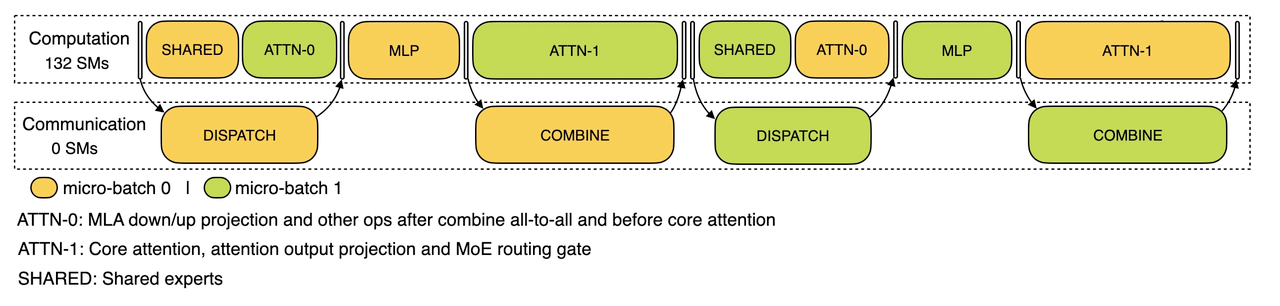
https://github.com/deepseek-ai/profile-data
1つのバッチは2つのミニバッチに分割され、片方が計算をしている間にもう片方がデータ転送(図中のdispatchとcombine)を行います。Prefillではバッチサイズが大きいためデータ転送のオーバーヘッドも大きく、コミュニケーション用に一部のGPUコア(SM)が割り当てられています。一方decodeはそれよりもバッチサイズが小さいためデータ転送のオーバーヘッドも小さくなり、またKVキャッシュアクセスが増えてattentionとMLPにかかる時間の比率も変わるため、attentionを2つに分割しパイプライン構成も一部変えています。
AttentionのDPインスタンス間のロードバランシングもprefillとdecodeで違ったアルゴリズムが必要です。Prefillでは「合計トークン数」と「attentionの計算時間」をなるべく一定にすることを目指しますが、decodeでは「KVキャッシュの使用量」と「リクエスト数(バッチサイズ)」をなるべく一定にすることを目指します。エキスパートに対してもロードバランシングは必要で、各エキスパートがどれだけ使われるかの統計をもとによく使われるエキスパートを複数GPUに複製し、階層的にロードバランシングするアルゴリズムを使っています。
これらに加え、MLAやFP8行列乗算のためのカーネル、KVキャッシュ保存のためのファイルシステムまで公開されています。推論インフラのコードこそ公開されていないものの、上記をもとにしたOSS上の実装はすでに作られています。また、PerplexityによるブログではDeepSeekモデルのserving性能について、異なる並列度の比較や計算・データ転送のオーバーラップの仕方などについて解説されています。
8. 最後に
いかがでしたか?LLM servingの面白さを少しでも感じ取っていただけたら幸いです。
Kotoba Technologiesでは、音声LLM向けに今回紹介したような推論システムを研究開発するエンジニアを募集中です。ご興味のある方はこちらをご参照ください。

Discussion