はじめに
こんにちは。SREホールディングス株式会社の西野です。SREでは主に画像認識案件のPLを担当しています。
最近、かなり出遅れ気味でLLMのプロジェクトに関わり始めたので、キャッチアップのために勉強している最中なのですが、その際にKVキャッシュについて”完全に理解した”ので、その内容をまとめて紹介したいと思います。(”何も分からない”の領域を目指して、キャッチアップに邁進しています)
併せて、簡単に生成AI(transformer)の基礎的な部分にも触れたいと考えています。
対象読者
- LLM関連プロダクト/プロジェクトに関わっているがKVキャッシュを知らない、もしくは説明できない人
- KVってなに?
- KVは知っているけど、なぜQはキャッシュ対象ではない?
- KVキャッシュはどのタイミングで利用される?
前提
- transformerの基本知識にも触れたいとは思いますが、以下の神動画があまりに分かりやすい(それこそ、”完全に理解した”という気にさせてくれる)ので、まずはそちらをご覧頂くと良いと思います(1本につき20~25分程度ありますが、タイパは良いです)
- この神動画前提の補足説明にとどまります
- テキスト生成、対話AI等で利用されるSelf Attentionに限定して解説します(翻訳タスク等で利用されるCross AttentionにおけるKVキャッシュについては対象外)
- 筆者の理解を整理したものをまとめています。正確性に努めていますが、誤りや不十分な点が含まれるかもしれません。もしお気づきの点があればコメントなどで教えていただけると助かります。
KVキャッシュ(key-value cache)とは
生成AIの基盤であるTransformerにおける推論処理を高速化する仕組みです。
「キャッシュ」という名前のとおり、高速化のために利用されています。
本記事では次の点を中心に解説します。
- Transformerではそもそもどのような計算をしているのか
- なぜKVをキャッシュすると効率化できるのか
- KV以外はキャッシュされないのか
生成AI(transformer)の基礎
(上記動画を視聴済みであることを前提に)KVキャッシュの説明に必要な部分のみ少し復習していきます。
まず、ポイントは以下でした。
- 自己回帰的に次々と単語(トークン)を生成する
- 周囲のトークンの意味を取り込みつつ、各トークンの意味を更新する
- 最新のトークン(前のステップで生成したトークン)の意味を更新したうえで、次の単語を予測する
この「周囲の単語の意味をどのように取り込むか」を実現するのがAttention機構であり、そこでQuery, Key, Valueが登場します。
Attention機構で実現したいこと

図1 出典:YouTube GPT解説2 アテンションの仕組み (Attention, Transformer) | Chapter6, 深層学習
- Attentionは「あるトークンの意味を、関連する他のトークンの情報を反映して更新する」ための仕組みです
- この図がAttention機構で実現したいことを端的に表していると思います
- (図の右の部分)creatureというトークンに対して、それに関連する周囲のトークン(fluffy)の意味を理解し、creatureのトークンのベクトルを更新したい(”fluffy creature” の意味をもつトークンに更新したい)
- そのようにトークンのベクトルを更新するには、どのようなベクトルを足すべきか??それがValueベクトルです
- この例では、あくまで(creatureではなく)fluffyのValueベクトルなので、厳密には”fluffy” トークン目線で語るのが正しく、「もし自分(fluffy)が他のトークン(creature)の意味の調整に関連するのであれば、その別のトークン(creature)のベクトルに、何を足せばそれを反映できるだろうか?」というものが(fluffyの)Valueベクトルになります
- そして、そのfluffyのValueベクトルを、creatureに対して、どれだけ足すのか(どれだけ関連するのか)を決めるのがAttention Patternになります
- creatureトークンにはfluffyだけでなく、それ以外のトークンのValueベクトルの重み付き和が足されることになります(下図)
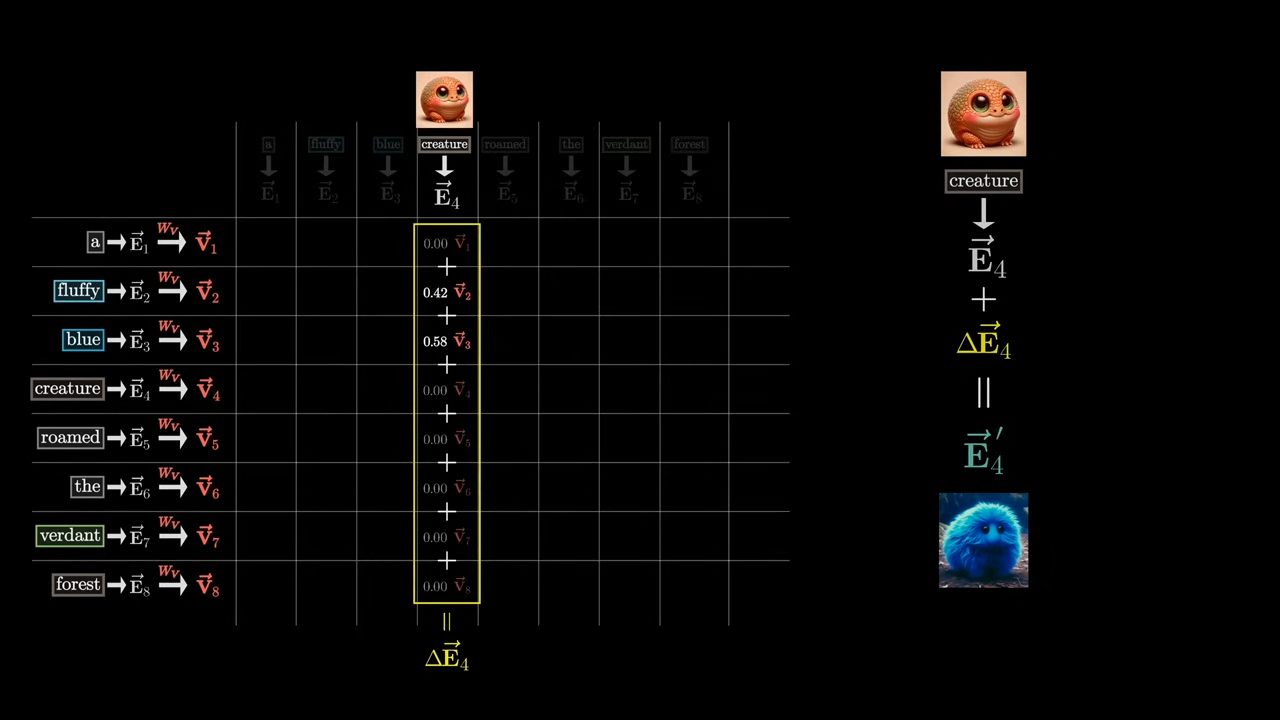
図2 出典:YouTube GPT解説2 アテンションの仕組み (Attention, Transformer) | Chapter6, 深層学習
Masked Self Attention

図3 出典:YouTube GPT解説2 アテンションの仕組み (Attention, Transformer) | Chapter6, 深層学習
- Attenton PatternはQueryとKey から計算されます
- ここで重要なのは、チャットボットのようなテキスト生成タスクにおいては、Masked Self-Attentionが採用されることです
- これは後ろ(未来)のトークンが前(過去)に影響を与えないようにするためです(もし未来の情報が必要になってしまうと、推論時に「まだ存在しない単語」を参照してしまうことになるからです。)
推論ステップとKVキャッシュ
では、具体的な推論ステップにおける処理と、KVキャッシュについてみていきましょう。
以下のケースにおける計算例を見ていきたいと思います。
- これまでに「a fluffy blue creature 」という文章を生成し、次の単語を生成しようとするステップ
- 直前のステップでcreature という単語を生成したということになります
- creature を現在のトークンと呼び、それ以外を過去のトークンと呼びます
このステップの目的
現在のトークン(生成したばかりのトークン) creature に過去のトークン情報を反映させ、その結果をもとに次の単語を予測することです。
Attention ブロックの計算
- Attentionブロックでは図2のように、creatureベクトルに足すべきベクトルΔE4を算出します
- ΔE4を求めるには、以下のようにQ4、K1~K4、V1~V4の計算が必要に見えますが、実はすべてを計算する必要はありません
- ΔE4を求めるにはV1~V4とAttentionパターンの計算が必要
- Attention パターンを求めるにはQ4とK1~K4の計算が必要
- なぜなら、未来のトークンは過去のトークンに対して影響を与えないようになっているため、K1~K3、V1~V3は1つ前のステップと計算結果が同じになります(新しいトークンが増えたとて、過去のトークンには影響を与えない)
- したがって、このステップで新たに計算する必要があるのは、Q4, K4 , V4 になります
- すなわち、無駄な計算をしないために、過去ステップにおけるK、Vの計算結果を保持しておくのです。これがKVキャッシュになります
- QKVのうちQのキャッシュが不要なのは、そもそもQは現在のトークンにのみ計算すれば良いものだからです
- Multi-head Attention や複数のアテンションブロックがある場合も同様であることはご理解いただけると思います
FFNブロックの計算
FFN層(Feed-ForwardNetwork層。動画ではMultilayer Parceptron層)ではどうでしょうか?
過去トークンにおいては、(FFN層の入力である)アテンション層の出力が過去ステップと変わらないため、FFN層の計算も全く同じになります。したがって計算する意味はなく、現在のトークンのみ計算が行われます。(図の一番右のみ計算される)
過去ステップの計算結果を保持する必要もないため、FFN層はキャッシュの対象とはなりません。
※実装上は中間結果を保持して再利用する場合もありますが、「KVキャッシュ」と呼ばれるのはAttentionにおけるKeyとValueの保存だけです。

図4 出典:YouTube GPT解説2 アテンションの仕組み (Attention, Transformer) | Chapter6, 深層学習
KVキャッシュの利用シーン
メリット・デメリット
メリットはもちろん計算コスト削減による高速化ですが、デメリットとしてはメモリ消費量が挙げられます。LLMのVRAM消費は以下の図の通りで、モデルの重みに次ぐ消費がKVキャッシュになります。
基本的にはコンテキストサイズとKVキャッシュの量子化精度に依存しますが、複数人のリクエストを並列に処理しようとすると、N倍のKVキャッシュが必要になるので要注意です。

図5 出典: Bringing K/V Context Quantisation to Ollama
KVキャッシュ戦略
Hugging Face のTransformersライブラリが提供するKVキャッシュにもいくつか種類があるようなので少し紹介しておきます。
- メモリ効率重視
-
OffloadedCache: CPUにオフロードするなどしてメモリ効率を向上 -
QuantizedCache: KVキャッシュ量子化によるメモリ使用量の削減
-
- 速度最適化重視
-
StaticCache: キャッシュに最大サイズのメモリを割り当て確保する方式
-
利用パターン
最後にKVキャッシュが実際にどのように活用されているかを簡単にまとめます。
私の理解では以下の3つのパターンがあると認識しています。
(これまでの説明は一番上のパターンです)
| 利用タイミング | 具体 |
|---|---|
| 自己回帰的生成における各ステップ(イテレーション) | あるシーケンス内で自己回帰的にトークンを生成する際(一語ずつ生成する際)には基本的にKVキャッシュが利用されている。prefillフェーズではなくdecodeフェーズ |
| 前のシーケンスがおわり、次のシーケンスを処理する際 | チャットボットの過去の会話履歴の利用。チャットボットでは過去のプロンプトをすべて再利用する(長い場合は要約などもしている)その際、計算効率向上のためにKVキャッシュを利用 |
| CAG(Cache-Augmented Generation) | KVキャッシュを外部に保存し、必要に応じて呼び出す方式。通常の「推論中のキャッシュ」とは別のアプローチ |
まとめ
個人的に勉強したKVキャッシュについて、備忘録ついでにまとめてみました。KVキャッシュ自体は知っていても、冒頭の質問にきちんと回答できない方もいらっしゃったのではないでしょうか?
こういった類のものはいろいろな側面で見ることで理解が高まると認識しているため、本記事がその1つの側面となれば幸いです。

Discussion