私は雰囲気でブラウザを使っています。
ブラウザの基礎知識がほしいのでそれっぽい記事を読んでいくだけのスクラップ
まずざっくり流れを把握
- URLを解読する
- HSTSリストを調べる
- DNSでIPアドレスを取得する
- ポート番号の指定
- HTTPリクエストの送信
- ロードバランサー通過
- HTTPレスポンスの送信
- HTMLのレンダリング
- JSONデータの取得
メインの参考資料はこれみたい
参考資料リスト
What happens when...
ウェブサイトが表示されるまでにブラウザはどういった仕事を行っているのか?
ネットワークはなぜつながるのか
Webフロントエンド ハイパフォーマンスチューニング
Webサイト表示の流れをざっくりとまとめた。 | ただ屋ぁのブログ
What happens when you type a URL in the browser and press enter?
日経XTECH DNSの歴史(第1回 「HOSTSファイルの崩壊」)
知っておきたいロードバランサーの基礎技術
参考資料と比較してもわかりやすそう
URLを解読する
URLを分解して、「プロトコル」と「ドメイン名」と「パス名」が何であるかを調べます。
もしプロトコルの記述がなかったり有効なドメインではなかった場合、ブラウザは入力されたテキストをブラウザのデフォルトの検索エンジンに渡します。
HSTSリストを調べる
HSTS ( HTTP Strict Transport Security ) とは、超簡単にいうとユーザーが http でアクセスしようとしてきたとき、ブラウザが自動で https に置き換えてアクセスしてくれる機能のことです。
同じ作者の方が別の記事で詳述している
DNSでIPアドレスを取得する
といってもすぐにDNSに問い合わせるわけではなく、近いところから順番に探しに行く。
- ブラウザのキャッシュ
- hostsファイル
- キャッシュDNSサーバ(スタブリゾルバからの問い合わせ)
- ネームサーバ(キャッシュDNSサーバからの問い合わせ)
HOSTS.TXTが使われていた当時 ( 1970年代 ) では、わずか数百台のホストしかなかったので、ネット上の全てのホスト情報の記載が可能でした。
しかし、インターネットが普及していくにつれてHOSTS.TXTは肥大化していき、1983年には、ホスト数はおよそ数万台になりました。もはやHOSTS.TXTによる名前解決は不可能となったので、現在のようなDNSサーバを設置して名前解決する仕組みが生み出された、という流れです。
おもろい
もしキャッシュDNSサーバに client.sharefull.com の問い合わせ結果のキャッシュがなかったら、キャッシュDNSサーバは、スタブリゾルバの代わりに 「ルートネームサーバ」 → 「.comのネームサーバ」 → 「sharefull.comのネームサーバ」 へと順に問い合わせを行います
層ごとにリクエストする場所が違う
そして、IPアドレスが分かったら、スタブリゾルバに「IPアドレスわかったよ〜」という問い合わせ結果を返します。スタブリゾルバは、問い合わせ結果からIPアドレスを取り出して、ブラウザから指定されているメモリー領域に書き込みます。
あくまでブラウザはスタブリゾルバとやり取りしているんだな
ポート番号を指定する
ポート番号 とは、TCP/IPにおいて、同じコンピュータ内で動作する複数のソフトウェアのうち、どれと通信するのか指定するための番号のことです。
IPアドレスを「電話番号」と例えるならば、ポート番号番号は電話をかけたときに「○○さんをお願いしたいのですが」と言って、話す相手を呼び出すような仕組みです
わかりやすいたとえ
私たちがブラウザでURLにポート番号を入力しなくてもWebサイトにアクセスできるのは、スキームを見て「http:」だったら80番、「https」だったら443番というように、自動的にポートを割り当てているからです。
HTTPリクエストの送信
さあ盛り上がってまいりました。
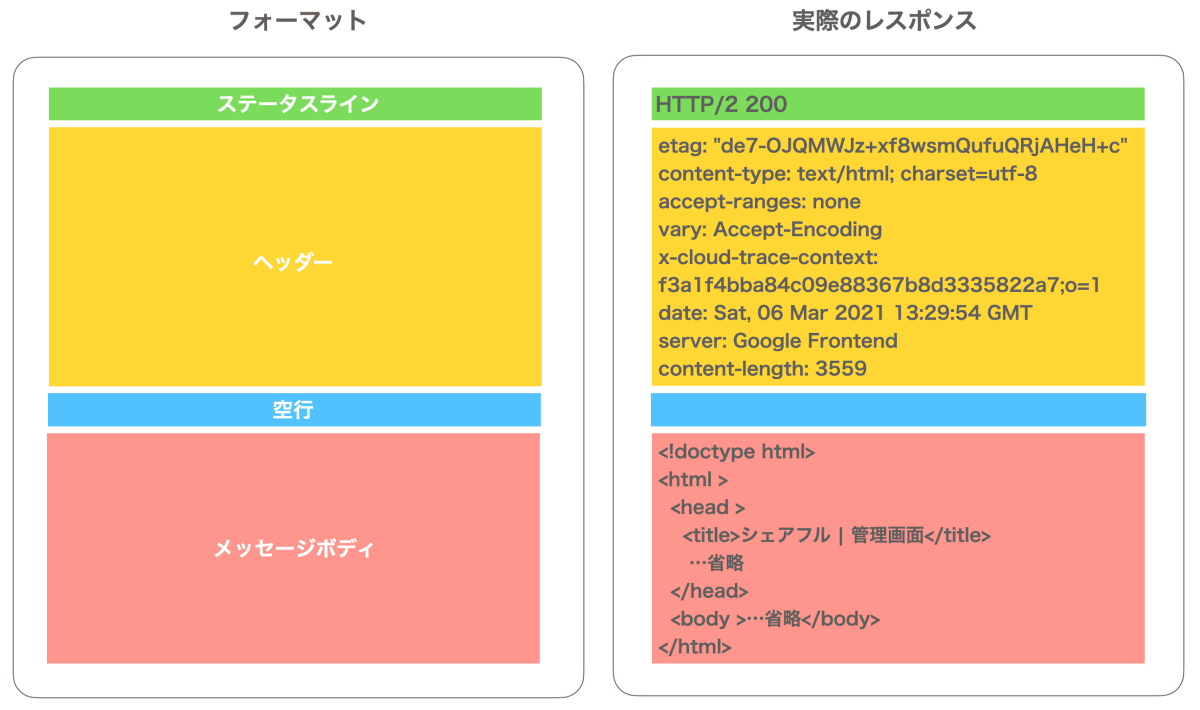
HTTPリクエストは「リクエストライン」と「ヘッダー」と「メッセージボディ」というフォーマットで作成されるらしいです...
リクエストの構成をわかりやすいように図で表すと、以下のようになります。

わかりやすい図
ロードバランサー
Webサービスにおいて、1台のサーバのみで運用するとアクセス集中でサーバがダウンしたときなど、サービス停止に追い込まれてしまうので、複数サーバを用意するのが一般的です。
ロードバランサーは、これら複数台のWebサーバを束ねて、Webサーバに来たリクエストをバランス良く振り分ける装置のことを言います。
ロードバランサーの有能な機能として、サーバの状態を把握する ヘルスチェック と、同じクライアントのリクエストを継続的に同一のサーバに振り当てる セッション維持 というのがあります。
- ヘルスチェック:サーバーの異常を検知し、異常なサーバーを回避して正常なサーバーにリクエストを割り振るようにする
- 同一ユーザーからのアクセスは同じサーバに振り分ける
ログインできるのはロードバランサーのおかげでもあったのかー!
HTTPレスポンスの送信
HTMLのレンダリング
ブラウザレンダリングには、大きく分けて4つのフェーズがあります。
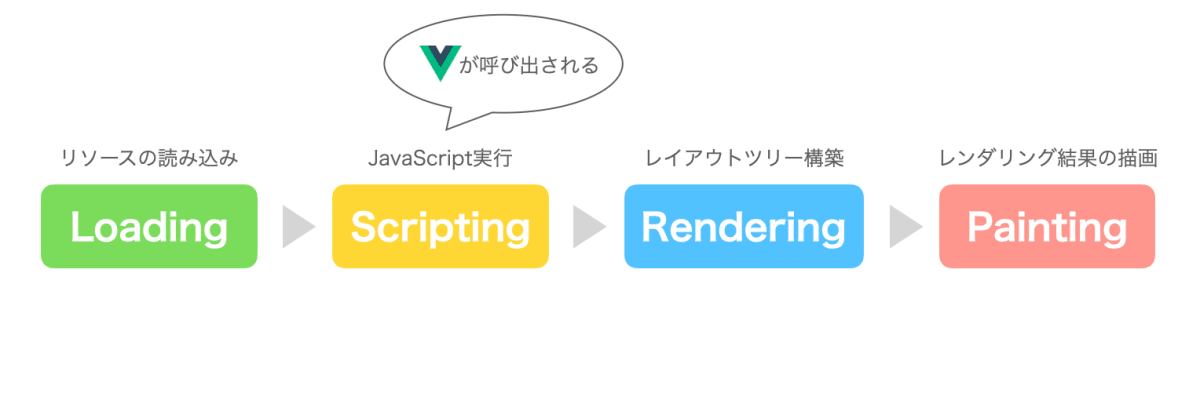
- Loading
- 描画に必要なリソースの読み込み
- 最初にHTMLファイルを上から順に読み込み、途中でCSSやJavaScriptや画像などの外部のリソースを発見するたびにサーバにリクエストする
- 読み込まれたリソースは扱いやすいかたちに変換される(eg. HTMLはDOMツリーに、CSSはCSSOMツリーに)
- Scripting
- 字句解析 → 構文解析 → コンパイル→JS実行
- プログラムの途中でAPI呼び出しの処理があればサーバにリクエストする
JSONデータの取得

次はこれ
全体像
- HTMLのダウンロード
- HTMLの解析
- CSSのダウンロード
- CSSの解析
- JSのダウンロード
- JSの実行
- レンダーツリーの構築
- Layout
- Painting
HTMLの解析
送られてきたデータを以下の流れでDOMにParseする。
- Content-Typeヘッダーまたはmetaタグで指定された文字コードに基づいて、未加工のバイトから人間が読める文字 ( Characters ) に変換する
- Charactersを一定単位ごとにTokensに変換する
- Tokensからより扱いやすいインターフェイスを持ったNodesに変換する
- NodesをもとにDOMを構築する
CSSの解析
linkタグからcssを見つけたら、HTMLの解析と同じ流れでCSSOMを構築する。
スタイルはカスケードする。ブラウザごとにuser agent stylesheetというデフォルトスタイルの設定がある。
JavaScriptの実行
JSを機械語に落とし込む必要がある。一連の流れ↓
字句解析と構文解析はHTMLのCharacters〜Nodesと大体一緒。JSの場合、抽象構文木はJSONで表現される。このJSONを機械語にコンパイルしていく。
コンパイル方法にはいろいろあるが(要調査)、V8エンジンはJITコンパイラを利用しているらしい。
↓これ読みたい。
JITコンパイラについてもっと知りたい方は、こちらの記事が分かりやすくておすすめです。
A crash course in just-in-time (JIT) compilers
How does JavaScript and JavaScript engine work in the browser and node?
↓は読んだ。この記事で説明されていることの他に、byte codeになったあとにさらにOptimizeしていることがわかった。動的型付けと静的型付けでOptimizeの手間が異なりそう。
また、こちらはJavaScriptエンジンの仕組みを解説した記事です。GIFアニメでとても分かりやすいです。
🚀⚙️ JavaScript Visualized: the JavaScript Engine
レンダーツリーの構築
???: I hove a DOM~
???: I hove a CSSOM~
???: ドッドッ ん’’ーっ!!
???: What a beautiful Render Tree
ということらしい。display: noneされてたりする、レンダリングに不要なものは上手いこと除くのだと。
Compositing
Layoutの計算が行われ、Paintingの順番を決めた後、一定のLayerごとにピクセルを描画していく。
色々計算の工夫をしながら最終的にはComposite Layersなるものを作成し、そいつをGPUに送ることで画面を描画している。
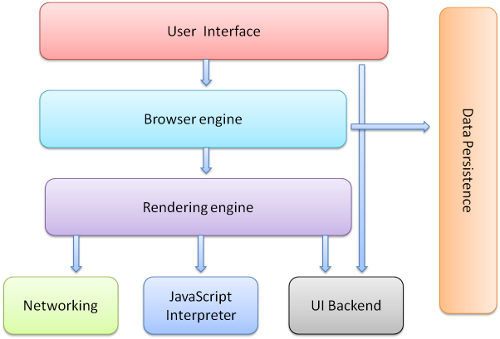
- ブラウザエンジン
- UIとレンダリングエンジンの間の処理を整理
- レンダリングエンジン
- 要求されたコンテンツ(HTMLなど)の表示を担当
④ Painting the render tree
ようやく描画します。
どこに描画するかという配置方法について考えることになります。
大きく分けて、3つに分かれます。通常
オブジェクトはドキュメント内の場所に従って配置されます。つまり、レンダーツリー内の場所はDOMツリー内の場所と同様になり、ボックスの種類や寸法に従ってレイアウトされます。
position:static,relativeフロート
オブジェクトは最初に通常のフローのようにレイアウトされてから、左右のできるだけ遠くに移動されます。
float:right,left絶対
オブジェクトはレンダーツリー内でDOMツリーとは異なる場所に配置されます。
position:absolute,fixed
大枠は上で見てきたこれの話だな。これが基礎知識だったっぽい。
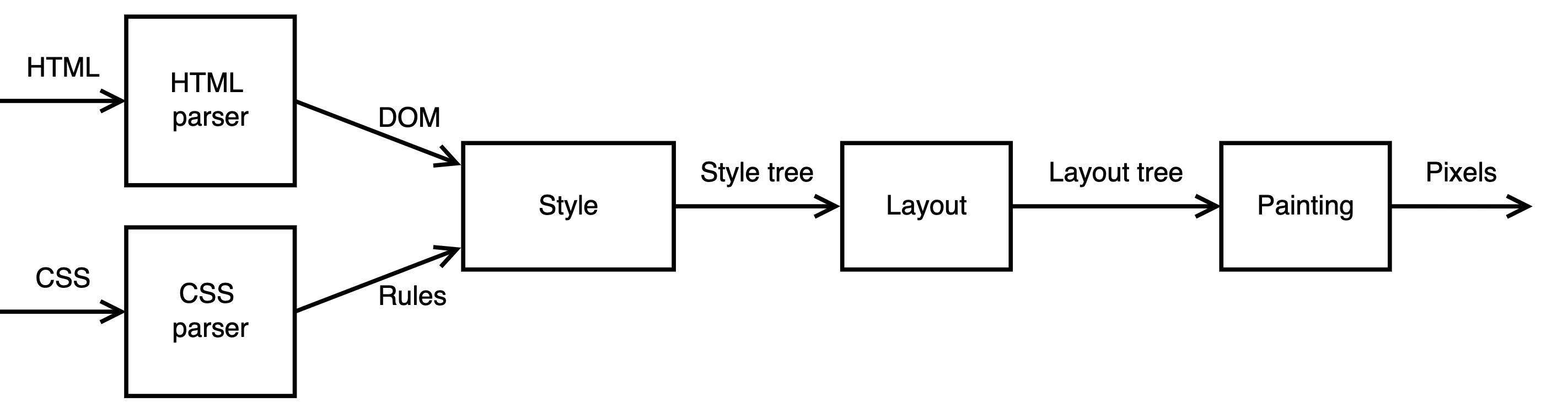
全体像
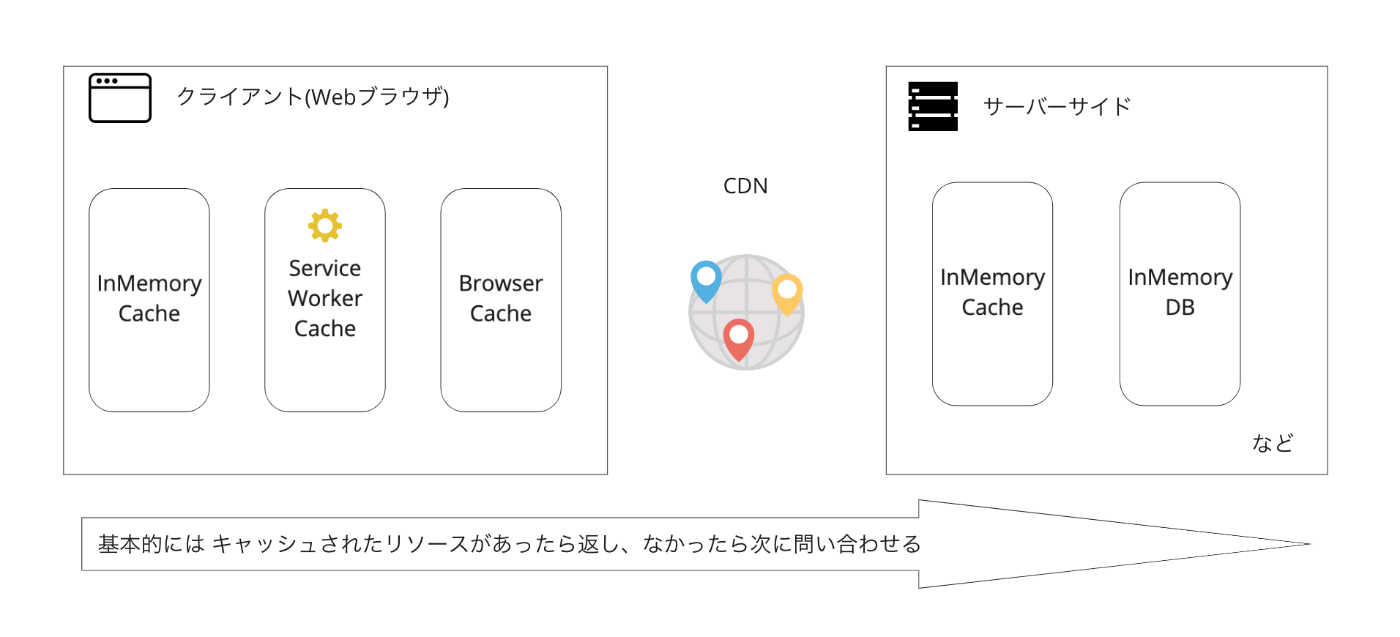
この記事はクライアント側のキャッシュの話をしてくれるらしい。
インメモリキャッシュ
インメモリキャッシュはRAMに保存されるため、書き込みとアクセスが高速になりますが、コンピュータの電源がオフになるか、その他の特定の状況で消去されます。このインメモリキャッシュは、各ブラウザのRendererプロセスに存在しています。
また、LRU方式でキャッシュが削除されていることがわかります
LRU方式ってなんだろうと思って調べた。Least Recently Usedの略らしい。
LRUとは、広さの限られた一時的な保管場所が満杯になったとき何を棄てるか決定する基準の一つで、最も過去に使用されたものから順に破棄する方式。IT分野以外でも書類の整理方法などに応用されている。(IT用語辞典)
余談にはなりますが、Chrome97でも完全に導入されたBack/Forward Cacheも、このインメモリキャッシュにあたります。
Back/Forward Cacheはページ遷移の前後をキャッシュしてくれる機構らしい。
bfcache is an in-memory cache that stores a complete snapshot of a page (including the JavaScript heap) as the user is navigating away. With the entire page in memory, the browser can quickly and easily restore it if the user decides to return.
How many times have you visited a website and clicked a link to go to another page, only to realize it's not what you wanted and click the back button? In that moment, bfcache can make a big difference in how fast the previous page loads:(web.dev)
毎度思うけどアルゴリズムがわかんないと具体的にイメージできない
ServiceWorkerキャッシュ
そしてServiceWorkerは、Cache Storage API もしくは、IndexedDBを用いて、リソースのキャッシュを行います。ServiceWorkerが他のキャッシュと大きく違うのは、HTTPをinterceptして、キャッシュの操作をプログラマブルに行うことができるという点です。
...ServiceWorkerキャッシュは、オフライン時のユーザー体験をより良くすることにのみ利用しています。
PWAの話とつながりそう
ServiceWrokerキャッシュを操作する際には、直接WebAPIを使うことは珍しく、多くの場合はWorkBoxのようなラッパーを利用することが一般的だと思います。
WorkBoxってどっかで見たことあるな...ServiceWrokerのライブラリだったか。
ブラウザキャッシュ
- Browserプロセスに存在している
- (HDDやSSDといった)ストレージに書き込まれるため、半永久的に残る
- 読み取りと書き込みに時間がかかる
RFC7234で定められているらしい
上の方で読んだ記事のおかげで、IPアドレスを取得するまでにも色々キャッシュがあることがわかる。
ついでにPWAもちょっと覗く
PWAとは何かをざっくりと説明すると、ネイティブアプリと Webの良いとこどりしたもので、
より良いUXを提供できるWebアプリケーションを目指しています。
これがPWAの評価基準らしい
これがちょっとアプリっぽいなと思った
オフライン時に専用のオフライン画面が表示されること
PWAバッジってレベルがあったのか!時期によって変わってるんかと思った
A2HS Mini-infobar を実装手順
manifest を設定する
Service Worker を導入する
デプロイ
これはなんとなく知ってる
最近では各種フレームワークが、そのフレームワークに適した Service Worker を作るためのライブラリを用意していることも少なくありません。
Gatsbyだとプラグインが全部やってくれる
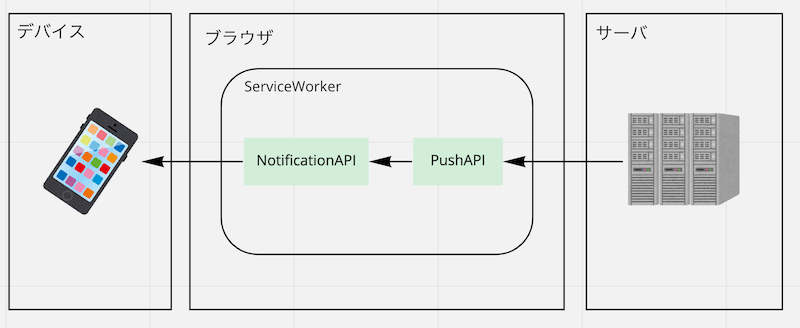
なんでPush通知できるんやろと思ったらサービスワーカーにそういうAPIがあるらしい