Webページがブラウザに表示されるまでに何が起こるのか?
Webの用語を100秒で解説するチャンネルを作りました!
よかったらチェックしてみてください!
この記事では、ブラウザのアドレスバーにURLを打ちこんで、Enterを押したとき何が起こるのか? を理解することを目標にします。
※ 記事の中で例として使ってるURL https://client.sharefull.com/ は 自社で開発してるシェアフルというサービスです。
URLを解読する
ユーザーがURLを入力してEnterを押すと、ブラウザはまず入力されたURLの解読を始めます。
URLを分解して、「プロトコル」と「ドメイン名」と「パス名」が何であるかを調べます。
https://client.sharefull.com/
上記のURLの場合、https がプロトコル、client.sharefull.comがドメイン名、/がパス名となります。
もしプロトコルの記述がなかったり有効なドメインではなかった場合、ブラウザは入力されたテキストをブラウザのデフォルトの検索エンジンに渡します。
HSTSリストを調べる
HSTS ( HTTP Strict Transport Security ) とは、超簡単にいうとユーザーが http でアクセスしようとしてきたとき、ブラウザが自動で https に置き換えてアクセスしてくれる機能のことです。
http でアクセスしてきたユーザーを中間者攻撃から守るための仕組みになります。
HSTSリストを調べる流れについて詳しく知りたい方は、「HTTP Strict Transport Security(HSTS)とは?」 の記事でけっこう頑張って書いたので、こちらをご覧ください( ‘-‘ )ง
DNSでIPアドレスを取得する
DNS ( Domain Name System ) は、IPアドレスとドメイン名の対応づけを行うシステムです。
インターネットに接続している機器 ( PC、スマホ、サーバ、ルーターなど ) には、必ず1つ1つに固有の番号が振られています。この番号を IPアドレス と呼びます。
電話をかけるときは、相手の番号を指定して電話をかけます。
それと同様に、インターネットで通信をするときも IPアドレスで相手を指定して通信を行います。
IPアドレスは、「10.11.12.13」のようにドットで区切られた数字になっています。
人間は「10.11.12.13」というような数字の羅列を覚えるのが苦手なので、ドメイン名を入力すれば対応するIPアドレスが何かを教えてくれる仕組みを作りました。それが DNS という仕組みになります。
ブラウザのキャッシュを調べる
まずブラウザは、自分がIPアドレスを既に知ってるかどうか調べるために、自分自身のキャッシュを見に行きます。アクセスしたのが最近だった場合、IPアドレスがキャッシュに残っているかもしれないからです。
もし使っているブラウザが Google Chromeであれば、以下からキャッシュされたDNS情報の確認ができます。
chrome://net-internals/#dns
もしキャッシュに残っていれば、名前解決のプロセスはこれで終わりです。
hostsファイルを調べる
ブラウザにキャッシュが残っていなかったら、今度は hostsファイル を調べに行きます。
hostsファイルとは、OSの設定ファイルの一つで、TCP/IPネットワーク上のIPアドレスとホスト名の対応を記述するテキストファイルのことです。
初期のインターネットでは、hostsファイルの原型である「HOSTS.TXT」というテキストファイルを用いて、ドメイン名をIPアドレスに変換する処理を行っていました。
どういうことかというと、インターネット上にある全てのホストとIPアドレスの対応付けが、たった1枚のHOSTS.TXTというファイルに記載されていて、他のホストと通信する際は、自分のPC内にあるこのファイルを参照して通信をしていました。
hostsファイルは、その名残と言えるファイルです。
以下のコマンドで中身の確認ができます。
$ sudo vi /private/etc/hosts
こんなかんじで出できます。
##
# Host Database
#
# localhost is used to configure the loopback interface
# when the system is booting. Do not change this entry.
##
127.0.0.1 localhost
上記で「127.0.0.1 localhost」とあるように、[IPアドレス] [ホスト名]というフォーマットで書かれます。
HOSTS.TXTが使われていた当時 ( 1970年代 ) では、わずか数百台のホストしかなかったので、ネット上の全てのホスト情報の記載が可能でした。
しかし、インターネットが普及していくにつれてHOSTS.TXTは肥大化していき、1983年には、ホスト数はおよそ数万台になりました。もはやHOSTS.TXTによる名前解決は不可能となったので、現在のようなDNSサーバを設置して名前解決する仕組みが生み出された、という流れです。
名残のhostsファイルは現在も使われてます。
名前解決でDNSサーバに問い合わせる前に、ブラウザはhostsファイルを見に行きます。もしファイル内に対象のホスト名があれば、そこで名前解決のプロセスは終了です。
スタブリゾルバを呼び出す
もしhostsファイルに対象の client.sharefull.com のIPアドレスがなかったら、DNSサーバに問い合わせます。
ブラウザはまず スタブリゾルバ というものを呼び出します。
スタブリゾルバとは、クライアントのPCの中にOSとして備わっている機能のことです。呼び出されたスタブリゾルバは、キャッシュDNSサーバに対して「client.sharefull.comのIPアドレス知ってる?」と問い合わせを行います。
キャッシュDNSサーバにキャッシュがあったら
キャッシュDNSサーバ は名前の通り、各問い合わせの結果を一定期間キャッシュに保存しておいて、後で同じ問い合わせがきた場合は、その結果を再利用して返します。
そのため、以前にスタブリゾルバから「client.sharefull.comのIPアドレス知ってる?」という問い合わせを受けていたら、キャッシュに保存されているはずなので、その問い合わせ結果をスタブリゾルバに返します。
スタブリゾルバは、受け取った結果からIPアドレスを取り出して、ブラウザから指定されているメモリー領域に書き込みます。これで、名前解決のプロセスは終了です。
キャッシュDNSサーバにキャッシュがなかったら
もしキャッシュDNSサーバに client.sharefull.com の問い合わせ結果のキャッシュがなかったら、キャッシュDNSサーバは、スタブリゾルバの代わりに 「ルートネームサーバ」 → 「.comのネームサーバ」 → 「sharefull.comのネームサーバ」 へと順に問い合わせを行います。

そして、IPアドレスが分かったら、スタブリゾルバに「IPアドレスわかったよ〜」という問い合わせ結果を返します。スタブリゾルバは、問い合わせ結果からIPアドレスを取り出して、ブラウザから指定されているメモリー領域に書き込みます。
これでブラウザは client.sharefull.com のIPアドレスをゲットできたので、名前解決のプロセスは終了です。IPアドレスを利用するときは、このメモリー領域からIPアドレスを抜き出してWebサーバにリクエストを送るという流れになります。
Amazon Route 53
Amazon Route 53 というのは、AWSが提供するクラウド上のDNSサービスのことです。
シェアフルでは、このAmazon Route 53というのを使って、ネームサーバの運用をしています。
なので、先ほど出した図では、⑤で「sharefull.com のネームサーバにきいて」と書きましたが、実際には「Route 53 のネームサーバにきいて」となります。

問い合わせを受けた Route 53 は client.sharefull.com のドメイン名に対応するIPアドレスを検索して、結果をキャッシュDNSサーバに返します。そのあとは、先程書いた流れと同様です。
もし見つからなかったら
IPアドレスを探し回って、それでも見つからなかったらエラーが返されます。

ユーザーはこのような画面を見ることになると思います(´∵`)
ポート番号
ポート番号 とは、TCP/IPにおいて、同じコンピュータ内で動作する複数のソフトウェアのうち、どれと通信するのか指定するための番号のことです。
IPアドレスを「電話番号」と例えるならば、ポート番号番号は電話をかけたときに「○○さんをお願いしたいのですが」と言って、話す相手を呼び出すような仕組みです。
この「○○さんをお願いしたいのですが」というのは、URLのドメイン名の 末尾 にコロン (:) と決められたポート番号を指定すれば、相手の指定ができます。
たとえば http://example.com/ の場合は、http://example.com:80/というような感じです。80というのは、HTTPだからです。
client.sharefull.com の場合は、HTTPSなのでhttps://client.sharefull.com:443/と指定します。
私たちがブラウザでURLにポート番号を入力しなくてもWebサイトにアクセスできるのは、スキームを見て「http:」だったら80番、「https」だったら443番というように、自動的にポートを割り当てているからです。
HTTPリクエストの送信
次はWebサーバに送信するHTTPリクエストについてです。
HTTPリクエスト とは、ブラウザからWebサーバへ送信される要求のことです。
ブラウザがどのようにHTTPリクエストを送信するのか見ていきたいと思います。
「urlを解読する」でドメイン名とパス名が判明したので、ブラウザはそれを元にHTTPリクエストを作成します。
HTTPリクエストは「リクエストライン」と「ヘッダー」と「メッセージボディ」というフォーマットで作成されるらしいですが、そんなことを言われてもよく分からないので、実際にどんなリクエストが送信されているのかコマンドを叩いて確認してみたいと思います。
使用したのは以下のコマンドです。
curl -v https://client.sharefull.com/
出力されたHTTPリクエストの中身。
GET / HTTP/2
Host: client.sharefull.com
User-Agent: curl/7.64.1
Accept: */*
実際にはこのリクエストのあとに、レスポンス内容も続けて出力されているのですが、それは次の「HTTPレスポンスの送信」で触れることにします。
リクエストの構成をわかりやすいように図で表すと、以下のようになります。

この中で、一番大事なのは1行目の リクエストライン です。
GET / HTTP/2 は、左端からそれぞれ「HTTPメソッド」「リクエスト先のURI」「HTTPのバージョン」のことを指します。
GET は最も一般的に使用されるメソッドで、ブラウザがWebサーバに対してページの取得を要求することを表しています。どのページを要求しているかというのは、左から2番目に書かれた / のことです。これはURLの中に埋め込まれているパス名からそのまま書き写されます。
また、フォーマットが「リクエストライン」と「ヘッダー」と「メッセージボディ」であるのに対して、実際のリクエストではメッセージボディが存在しないのは、HTTPメソッドが GET だからです。GET の場合は、メソッドとURLだけでWebサーバは何をすべきか判断できるので、メッセージボディに何かを書く必要は無いからです。
ロードバランサー
ロードバランサー とは、Webサーバにかかる負荷を複数に分散させるための装置です。「負荷分散装置」とも呼ばれます。
Webサービスにおいて、1台のサーバのみで運用するとアクセス集中でサーバがダウンしたときなど、サービス停止に追い込まれてしまうので、複数サーバを用意するのが一般的です。
ロードバランサーは、これら複数台のWebサーバを束ねて、Webサーバに来たリクエストをバランス良く振り分ける装置のことを言います。

ロードバランサーの有能な機能として、サーバの状態を把握する ヘルスチェック と、同じクライアントのリクエストを継続的に同一のサーバに振り当てる セッション維持 というのがあります。
ヘルスチェック
配下にあるWebサーバが正常に稼働しているかどうかを常にチェックする機能です。
もし正常に応答を返さなかったら「異常」だと判断して、そのサーバに対してはリクエストを割り振らず、別の正常なサーバに割り振ります。
セッション維持
同一ユーザーからのアクセスは同じサーバに振り分ける機能です。
これがないと、ログインをしても、その次の通信でロードバランサーが別のサーバにリクエストを飛ばしてしまったときに、サーバは前の通信状態を知らないので、「あなた誰ですか?」となります。

なので、送信元のIPアドレスをチェックするなどの方法で、同じユーザーからのアクセスは、同じサーバに振り分けます。
また、同じクッキーを持つ通信は必ず同じWebサーバに振り分けるクッキーによるセッション維持の方法もあります。
HTTPレスポンスの送信
リクエストを送ると、Webサーバからはレスポンスが返ってきます。
「HTTPリクエストの送信」で省略していたHTTPレスポンスの中身は、以下のとおりです。
HTTP/2 200
etag: "de7-OJQMWJz+xf8wsmQufuQRjAHeH+c"
content-type: text/html; charset=utf-8
accept-ranges: none
vary: Accept-Encoding
x-cloud-trace-context: 0a770f14325a57bd2fca0a614fd11841;o=1
date: Mon, 08 Mar 2021 15:17:31 GMT
server: Google Frontend
content-length: 3559
<!doctype html>
<html >
<head >
<title>シェアフル | 管理画面</title><meta data-n-head="1" charset="utf-8"><meta data-n-head="1" name="viewport" content="width=device-width,initial-scale=1"><meta data-n-head="1" data-hid="description" name="description" content="Nuxt.js project"><meta data-n-head="1" http-equiv="cache-control" content="no-store" property=""><meta data-n-head="1" http-equiv="cache-control" content="no-cache" property=""><meta data-n-head="1" http-equiv="pragma" content="no-cache" property=""><meta data-n-head="1" http-equiv="pragma" content="no-cache" property=""><meta data-n-head="1" http-equiv="expires" content="0" property=""><meta data-n-head="1" name="robots" content="noindex, nofollow"><link data-n-head="1" rel="icon" type="image/x-icon" href="/favicon.ico"><link data-n-head="1" rel="stylesheet" type="text/css" href="https://fonts.googleapis.com/icon?family=Material+Icons"><link data-n-head="1" rel="apple-touch-icon" sizes="180x180" href="/apple-touch-icon.png"><link data-n-head="1" rel="icon" type="image/png" sizes="192x192" href="/android-touch-icon.png"><script data-n-head="1" src="https://cdn.polyfill.io/v2/polyfill.js?features=fetch,es5,es6,es2016,es2017|gated&flags=gated&unknown=polyfill&callback=onPolyfillsLoad"></script><link rel="preload" href="/_nuxt/fb2a8a9.js" as="script"><link rel="preload" href="/_nuxt/ada7401.js" as="script"><link rel="preload" href="/_nuxt/40032be.js" as="script"><link rel="preload" href="/_nuxt/f8b7c5e.js" as="script">
</head>
<body >
<div id="__nuxt"><style>#nuxt-loading { background: white; visibility: hidden; opacity: 0; position: absolute; left: 0; right: 0; top: 0; bottom: 0; display: flex; justify-content: center; align-items: center; flex-direction: column; animation: nuxtLoadingIn 10s ease; -webkit-animation: nuxtLoadingIn 10s ease; animation-fill-mode: forwards; overflow: hidden;}@keyframes nuxtLoadingIn { 0% {visibility: hidden;opacity: 0; } 20% {visibility: visible;opacity: 0; } 100% {visibility: visible;opacity: 1; }}@-webkit-keyframes nuxtLoadingIn { 0% {visibility: hidden;opacity: 0; } 20% {visibility: visible;opacity: 0; } 100% {visibility: visible;opacity: 1; }}#nuxt-loading>div,#nuxt-loading>div:after { border-radius: 50%; width: 5rem; height: 5rem;}#nuxt-loading>div { font-size: 10px; position: relative; text-indent: -9999em; border: .5rem solid #F5F5F5; border-left: .5rem solid #3B8070; -webkit-transform: translateZ(0); -ms-transform: translateZ(0); transform: translateZ(0); -webkit-animation: nuxtLoading 1.1s infinite linear; animation: nuxtLoading 1.1s infinite linear;}#nuxt-loading.error>div { border-left: .5rem solid #ff4500; animation-duration: 5s;}@-webkit-keyframes nuxtLoading { 0% {-webkit-transform: rotate(0deg);transform: rotate(0deg); } 100% {-webkit-transform: rotate(360deg);transform: rotate(360deg); }}@keyframes nuxtLoading { 0% {-webkit-transform: rotate(0deg);transform: rotate(0deg); } 100% {-webkit-transform: rotate(360deg);transform: rotate(360deg); }}</style><script>window.addEventListener('error', function () { var e = document.getElementById('nuxt-loading'); if (e) {e.className += ' error'; }});</script><div id="nuxt-loading" aria-live="polite" role="status"><div>Loading...</div></div></div><script>window.__NUXT__={config:{}}</script>
<script src="/_nuxt/fb2a8a9.js"></script><script src="/_nuxt/ada7401.js"></script><script src="/_nuxt/40032be.js"></script><script src="/_nuxt/f8b7c5e.js"></script></body>
</html>
この構成を図で表すと、以下のようになります。

リクエストと違って、レスポンスの1行目は ステータスライン と言います。HTTP/2 200 というのは、それぞれ「HTTPのバージョン」と「ステータスコード」を表しています。
ステータスコード というのは、リクエストが成功したのかエラーが起きたのかを表すコードです。この場合は 200なので、Webサーバの処理が無事成功したことを表しています。
また、ヘッダーの中には content-type: text/html; charset=utf-8 というものが記載されています。メッセージボディに入っているデータが、どのような形式なのかを示すものです。この場合「コンテンツはHTMLファイルであり,その文字コードはUTF-8である」ことを表しています。ブラウザはこれを見て、データをどのように処理するかを判断します。
メッセージボディには、content-typeで記載されたとおり、リクエストしたリソースであるHTMLが格納されます。
レスポンスが返ってきたら、メッセージボディからデータを取り出して、ブラウザに表示させます。
HTMLのレンダリング
ブラウザレンダリングには、大きく分けて4つのフェーズがあります。

最初に行う処理は Loading です。描画に必要なHTML、CSS、JavaScript、画像などのリソースを読み込みます。
このとき一番最初に取得されるリソースは、HTMLファイル です。
ブラウザはこのHTMLファイルを上から順に読み込んでいって、途中でCSSやJavaScriptや画像などの外部のリソースを発見したら、Webサーバにその都度問い合わせてリソースを取得します。
読み込んだリソースは、レンダリングエンジンの内部リソースに変換されます。
HTMLはDOMツリーに、CSSはCSSOMツリーにそれぞれ変換されます。これらは後続のフェーズであるRenderingやPaintingで利用されます。
それが終わったら、今度は Scripting という処理に入ります。
Scriptingでは、字句解析 → 構文解析 → コンパイルという処理が終わって、はじめてJavaScriptのコードが実行されます。
シェアフルではJavaScriptのフレームワークとしてVueを使っているので、JavaScriptのコードが実行されると、Vueが呼び出されます。
Vueの中にAPI呼び出しの処理があった場合、APIサーバにリクエストをしてデータの取得を行います。
JSONデータの取得

例えばシェアフルのWebページでは、画面の右上にログインしているユーザーの名前、所属部署名を表示します。これらのデータは、APIサーバを利用して取得します。
API とは、Application Programming Interface の略で、「プログラム同士をインターフェースを通じで繋げる機能」のことです。APIサーバ は、APIの仕組みを利用してデータを提供するサーバのことを言います。
ブラウザは、エンドポイントに対して、HTTPメソッドやパラメータを指定してリクエストを送ることで、APIサーバにデータを要求します。
シェアフルでは、GraphQLを使っているので、エンドポイントは単一になります。全て/graphqlで、POSTメソッドです。欲しいリソースは、メッセージボディに記載することで指定します。ヘッダーに content-type:application/json と指定して、JSON形式でリクエストを送ります。
APIサーバは、受け取ったリクエスト内容を元にSQL文を発行して、DBサーバに問い合わせ、データを取得します。これをJSON形式に整形してブラウザに返します。基本的に以下のような構造になります。
{
"data": {...},
"errors": [...]
}
data にはクエリ結果、errors にはエラー内容が格納されます。
ブラウザはこの結果を受け取って、描画していきます。
おわり
ブラウザのアドレスバーにURLを打ちこんで、Enterを押したとき何が起こるのか?
という説明はこれで以上になります( ‘-‘ )ง
SPA
ページが表示された後ですが、SPA ( Single Page Application ) についても触れておきたいと思います。
SPA とは、最初に与えられた1枚のHTMLファイルをもとに、差分がある箇所のみ更新していって、複数ページあるように表現するアプリケーションのことです。
従来のWebアプリとSPAでは、どのような違いがあるのか見ていきます。
従来のWebアプリ

- リクエストの送信
- サーバ側でHTMLを生成し、ブラウザに返す
- ブラウザでHTMLを描画
従来のWebアプリでは、上記の流れの繰り返しになります。
ユーザーの操作の度に、ブラウザはページ全体の再読み込みを行います。
SPA
SPAでは、変更があった部分だけ書き換えられます。

- リクエストの送信
- サーバ側でHTMLを生成し、ブラウザに返す
- ブラウザでHTMLを描画
- 差分の更新に必要なデータをリクエストする
- サーバ側でJSONデータを用意して、ブラウザに返す
- JavaScriptのDOM操作で差分を更新する
上記の 1〜3 までは、従来のWebアプリと同じです。初回アクセス時のみHTMLを読み込みます。HTMLの描画後は、ユーザーからの操作に応じて 4〜6の部分を繰り返します。
もし、ヘッダーやフッターが全ページ共通のものであったら、書き換える必要はないので変更せずに置いておき、ページ遷移の際はそれ以外のパーツを変更していきます。
そうすることで、Webサーバへの通信量削減やリロードによる再レンダリングを減らせるため、より高速なページ遷移の実現ができるようになります。
Discussion
中身と関係のない質問で恐縮なのですが、図って何かツールを使って書いてますか?めちゃくちゃきれいだったので気になりました。
ありがとうございます! 図はKeynoteでつくりました!(੭ˊ꒳ˋ)੭
HTMLレンダリングあたりの記述が若干甘いところがあります。例えば
という記述がありますが、この記述だとHTMLが完全に読み込まれた後にJSが走ってしまうと誤解しがちです。実際には、読み込みの途中で、部分的に後続のフェーズが走り、一部が表示されている間に、残りのコンテンツが届いたりしています。
これも気になります。一番最初に取得されるのが必ずしもHTMLファイルだけではなく、他の場合、例えば画像やPDFの場合もあります。というか、ユーザがブラウザを通じてサーバーに要求したリソースが読み込まれるので..
以上ご存知の内容だとは思いますが、ここも「ページを表示するまで」というタイトルである以上、重要かと思いコメントいたしました。
とありますが、ここではJSONデータのみじゃなく、XML等でも利用できますので、「サーバがデータを用意してブラウザに返す」のみの記述でいいのではと思います。
とてもわかり易かったです。ありがとうございます。
細かいところで恐縮ですが、一点だけコメントさせてください。 「httpリクエストの送信」において、curlコマンドの出力を用いてリクエストラインの解説をされている部分についてです。
HTTP/2通信となっているようですが、HTTP/2はリクエストラインを持ちません(Curlは出力上、リクエストライン家のように出力しています。。。)。通信上は、HTTP/1.1におけるリクエストラインに相当する部分は、疑似ヘッダという形でHEADERSフレームに格納されます。ボディはDATAフレームに格納されます。
Wiresharkで確認すると次のとおりです。メソッドやPATHが
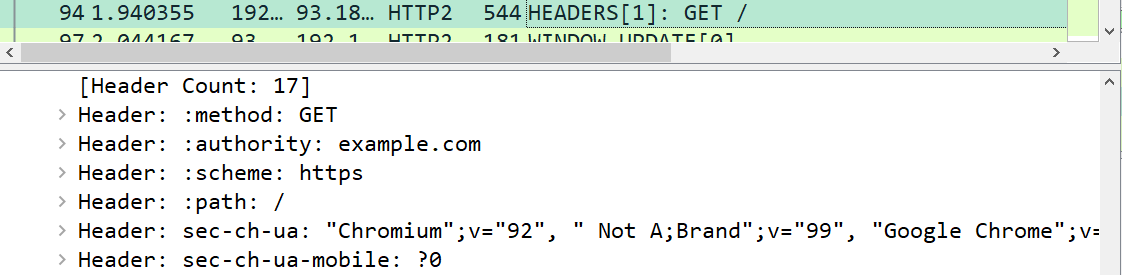
:method,:pathとしてヘッダかのようになっていることが確認できると思います。説明と合致させるために、curlに
--http1.1をするのは如何でしょうか。図も分かりやすく素晴らしい記事でした。
レンダリングガチ勢やTCPチョットワカルな人にもこの題材で記事書いてみてほしい。
絶対面白い。読みたい。