Hogetic Lab の喜久里です。8月1, 2日に Google Cloud Next Tokyo '24 に参加しました。大きなイベントのため参加された方も多いかと思いますが、自分が拝聴したセッションについてレポートをまとめたいと思います。
Google Cloud Next Tokyo '24 について
Google Cloud Next Tokyo '24 は、Google Cloud が主催するカンファレンスで、エンジニアやビジネスリーダー向けに基調講演、テクニカルセッション、ハンズオンラボなどが行われ、最新技術や事例、ベストプラクティスが紹介されます。例年、クラウドインフラ、データ、アプリ開発、セキュリティなどの広いトピックが扱われますが、今年は明らかに生成 AI のセッションが多かったように感じられます。また、コロナ期間にはオンラインで開催もされていましたが、今年は基調講演のみ YouTube 配信されているものの、他のセッションは基本的にオフラインの開催になっていました。
筆者は、いくつかのセッションに参加しましたが、その中でも印象に残った下記のセッションについてレポートをまとめます。
- AI エージェントは分析作業の(悪)夢を見るか?
- ドメイン特化型マルチモーダル生成 AI の学習プロセス
- Google Cloud の AI Hypercomputer で学習を加速させる
各セッションのレポート
AI エージェントは分析作業の(悪)夢を見るか?
Innovators Stage LT での岡安優氏(株式会社unerry)による発表で、unerry社における AI エージェントを活用した分析の取り組みが紹介されました。unerry社では、分析プロセスを以下の3つのフェーズに分け、各フェーズで gemini-1.5-pro を活用して分析の自動的を試みています。
- 要件定義フェーズ:
議事録の内容を元に、LLM が分析仮説を抽出 - データ抽出・集計フェーズ:
抽出された仮説に基づいて、LLM がデータを加工 - 分析・インサイト抽出フェーズ:
加工されたデータを元に、Google 検索の結果も含むグラウンディングも併用しながら LLM が分析結果を出力
このようなAIエージェントによる分析プロセスの自動化が実現すると、人間の分析者がより重要な業務プロセスに集中できることが期待されます。
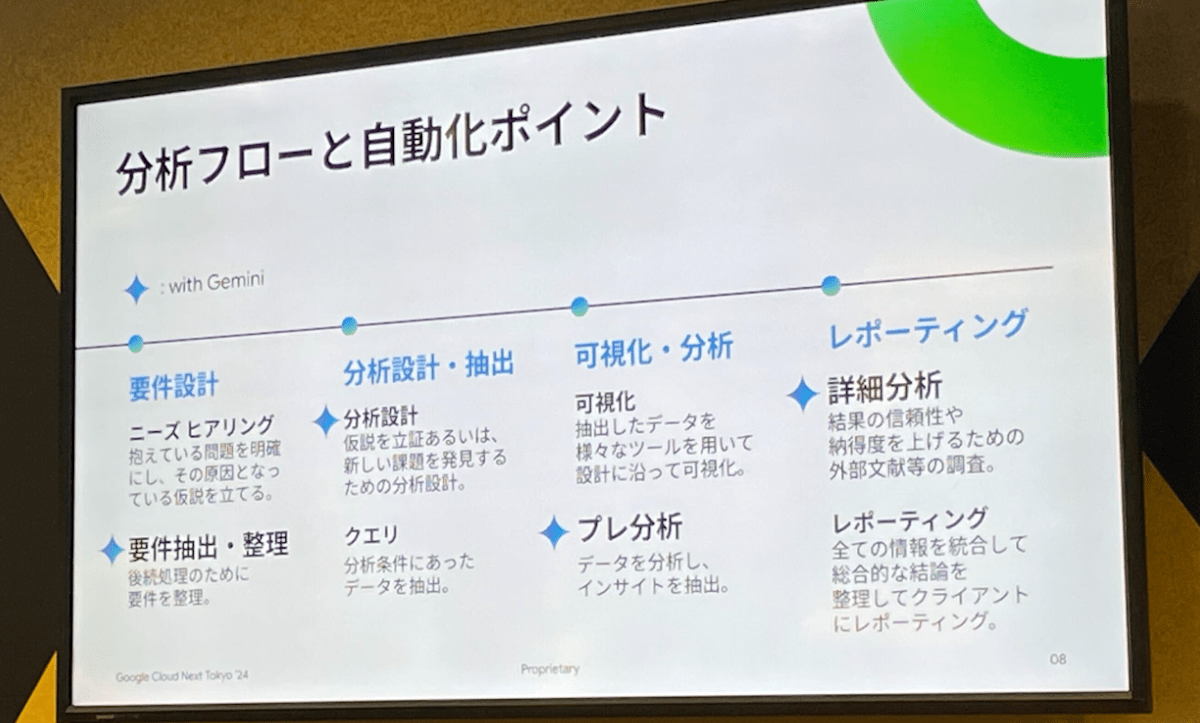
分析フローと自動化ポイント
ドメイン特化型マルチモーダル生成 AI の学習プロセス
Turing株式会社の山口祐氏によるセッションでは、自動運転に利用するための VLM(Vision and Language Model)について紹介されました。VLM の概要や、その構成をカスタマイズしやすくするための OSS ライブラリ Heron、VLM の評価を行う Heron Bench、VLM の学習のためのシステム構築について説明されていました。
LLM(Large Language Model)や VLM の分散学習では、GPU の処理時間だけでなく、ストレージ I/O や GPU 間の通信がボトルネックになりやすいですが、これらの課題に対し、ストレージ I/O を高速化する Lustre on Compute Engine や、分散学習の環境を自動的に構築するための HPC Tool が紹介されました。
日頃の業務では VLM 自体を学習する機会は多くありませんが、既存の LLM ベンダーの API ではフィルターが厳しいと感じることがあります。そのため、特定の要件下では、今回紹介されたようなツールの利用も検討する価値があると感じました。特に、カスタマイズ性や image-to-text の評価ベンチマークの仕組みは、実際のプロジェクトで有用だと考えられます。

ドメイン特化学習の実施例
Google Cloud の AI Hypercomputer で学習を加速させる
Google Cloud の片岡義雅氏と東京工業大学の藤井一喜氏によるセッションで、前半では大規模分散学習のための Google Cloud サービス群の紹介、後半は Geniac プロジェクトにおける172Bのモデルの学習を通じての各サービスの利点などが紹介されていました。セッション内容を通して初耳のサービスや知見が多く、例えば、前セクションで紹介したセッションと同様にストレージI/Oが分散学習のボトルネックになることが言及されていましたが、その課題を解決するサービスとして Hyperdisk ML というサービスが紹介されていましたが、前出の Lustre on Compute Engine との使い分けなどを自身で深堀りして理解する必要がありそうです。
また、「他のスパコンと比べて、Google CloudのサービスはGPUの故障率の低さの点でかなり優れている」という点が興味深かったです。
筆者も過去の業務でスパコンを利用することがあったのですが、環境やジョブスケジューラ、ライブラリなどの構築・整備はベンダーさんと密に連携して行うものという印象が強かったため、一般の利用者がスクリプトを通して手軽に環境構築できるのは利用当時からすると信じられない進歩だと感じました。
Google Cloudの片岡義雅氏と東京工業大学の藤井一喜氏によるセッションでは、前半では Google Cloudの大規模分散学習向けサービス群の紹介、後半では、GENIAC プロジェクトをにおける 172B パラメータのモデル学習の事例を通じて、各サービスの利点が説明されました。また、前セクションの発表と同様に、分散学習におけるストレージ I/O のボトルネックが言及され、この課題を解決するサービスとして、Hyperdisk ML が紹介されました。前出の Lustre on Compute Engine との使い分けなどを今後さらに調べて理解する必要がありそうです。藤井氏は様々な企業や研究機関に所属して LLM / VLM の開発に携わるとのことですが、そのご経験から「他のスパコンと比べて、Google Cloud のサービスは GPU の故障率の低さの点でかなり優れている」点が興味深かったです。
筆者も過去の業務でスパコンを利用することがあったのですが、環境やジョブスケジューラ、ライブラリなどの構築・整備はベンダーさんと密に連携して行うものという印象が強かったため、一般の利用者がスクリプトを通して手軽に環境構築できるのは当時からすると信じられない進歩だと感じました。
参考:

AI アクセラレータのポートフォリオ

Hyperdisk ML
おわりに
以上、簡単ではありますが、Google Cloud Next '24 のセッションについてレポートしました。例年より生成AIのセッションが明らかに多かったですが、関連する Google Cloud サービスはもちろん、素晴らしいユースケースや事例を拝聴できました。また、弊社の岩尾の登壇に関する記事も公開されていますので、こちらからご覧いただければと思います。
【登壇後に資料公開】Google Cloud Next Tokyo '24: いでよ、Gemini!そしてデータの力を解き放ちたまえ!!

Discussion