Gemini API で少数ショット学習を利用し、定点カメラの画像を判定してみる実験
以前、スキャンした表などからスプレッドシートを作るスクリプトを作ったときに以下のようなことを書きました。
また、今回はフォーマットの変換などを主に試しましたが、画像の内容をトリガーとした自動化などにも応用できそうだと感じました。
その後、少数ショット学習などを用いた画像判定を試したところ、以下のようなことが実現できました。
| Date | Image | Answer | Page |
|---|---|---|---|
| 2024-02-01 |  |
富士山は見えない | https://www.pref.shizuoka.jp/fujisanview/365.html?date=20240201gotenba |
| 2024-02-02 |  |
富士山は見えない | https://www.pref.shizuoka.jp/fujisanview/365.html?date=20240202gotenba |
| 2024-02-03 |  |
富士山は見えます。 | https://www.pref.shizuoka.jp/fujisanview/365.html?date=20240203gotenba |
これに関連して、この記事では以下のようなことを記述します。
- 少数ショット学習とは
- どの程度の効果がありそうか
- 考慮点など
少数ショット学習とは
「少数ショット学習」は時期や文脈によって若干異なる意味を持つようですが[1]、ここでは「簡単な例(法則)をプロンプトへ含めることにより、より良い返答を引き出す」ことを指しています。
少数ショットのプロンプト例:
食事の種類について、「洋食」「和食」のどちらかに分類してください。返答は分類の結果のみ表示してください。
ハンバーグ: 洋食
寿司: 和食
ステーキ: 洋食
天ぷら: 和食うな重:
返答:
和食
このような感じで例を含めておくことにより、返答の内容がより良く、また予想しやすい範囲へ収まるようになります。
また Google AI Studio では Structured Prompt を使うことで上記のようなプロンプトをスプレッドシート風に管理できます。ただし、残念なことに Gemini 1.0 Pro Vision(画像を扱えるモデル)では利用できないようです。
図 1-1 上記例を Structured Prompt として記述
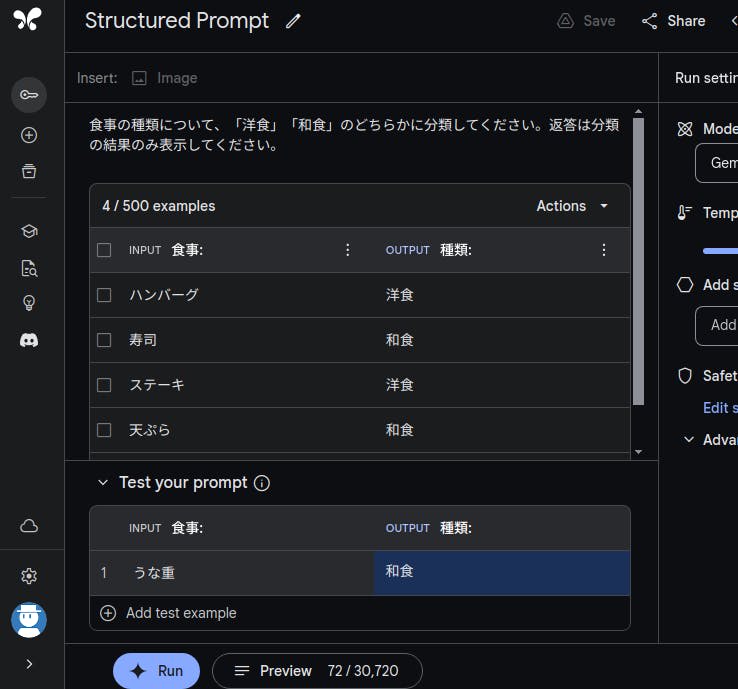
画像を少数ショット学習の例として扱う方法
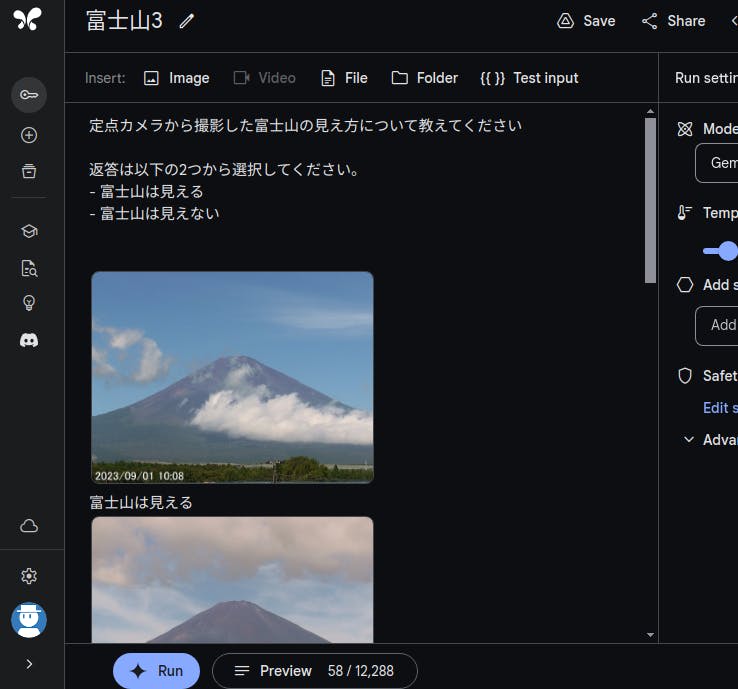
Structured Prompt が利用できなかったので少し悩んだのですが、普通に「画像の下にテキストで説明を記述する」を繰り返すことでそれらしい結果が得られました。Gemini が「例になる画像を入力してるな」と判断する状況を作ればそれで良いようです。
図 2-1 Free form Prompt で画像の下に説明を記述
例にする画像の準備ができたら、最後に判定したい画像を貼り付けて Run すると結果が表示されます。
図 2-2 Run した結果
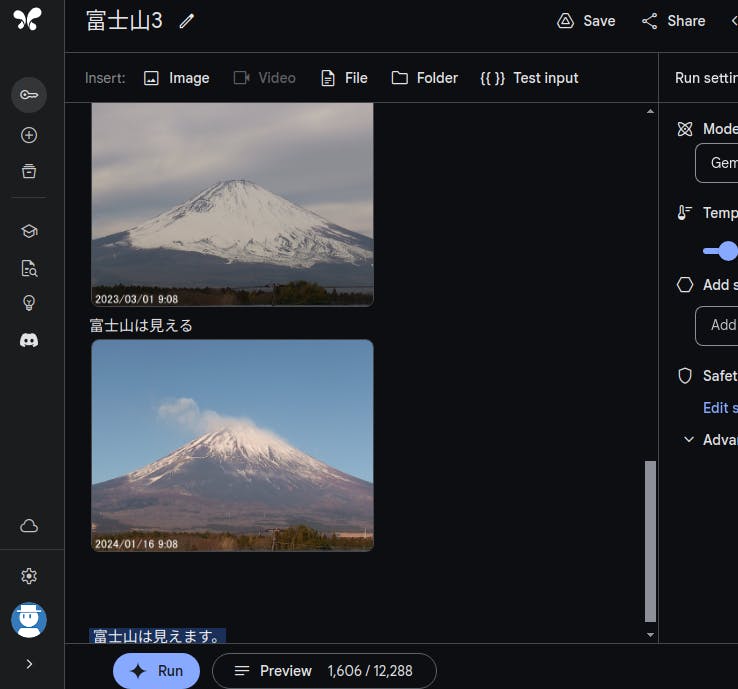
おおむね良い感じなのですが、返答の内容が指定したものではなく「富士山は見えます」となってしまいます。ここをきっちりさせることは少し大変そうなので、今回は表記のゆれを許容することにしています。
少数ショット学習の効果を確認してみる
プロンプトの骨格ができたので、ある程度の枚数を判定することにより効果を試してみます。
このような場合、定点カメラで撮影された画像が良いだろうと考えて探してみると、静岡県公式ホームページのライブカメラ富士山ビューでは過去 1 年分の写真画像が公開されていました。 (ライセンスは CC BY-NC 4.0 DEED です)
今回はこちらの画像から「富士山は見える or 見えない」を判定するスクリプトを作成し、「少数ショット学習なし(プロンプトに例を含めない)」「少数ショット学習あり」それぞれの結果を表にしました。
判定結果のサンプル:
| Date | Image | Answer | Page |
|---|---|---|---|
| 2024-02-01 | |
富士山は見えない | https://www.pref.shizuoka.jp/fujisanview/365.html?date=20240201gotenba |
| 2024-02-02 | |
富士山は見えない | https://www.pref.shizuoka.jp/fujisanview/365.html?date=20240202gotenba |
| 2024-02-03 | |
富士山は見えます。 | https://www.pref.shizuoka.jp/fujisanview/365.html?date=20240203gotenba |
リポジトリ(スクリプトと判定結果などが含まれています):
少数ショット学習なしの場合
ざっと見た感じでは、それなりに判定できているのですが、「見えないと思える画像」に対して見える判定しているのが少し目立ちました。
たとえば 2023 年 8 月分 の場合だと、似たような画像なのですが何故か 5 日だけが見える判定になっています(8 月だけでなく他の月でも同じような傾向です)。
| Date | Image | Answer | Page |
|---|---|---|---|
| 2023-08-04 |  |
富士山は見えない | https://www.pref.shizuoka.jp/fujisanview/365.html?date=20230804gotenba |
| 2023-08-05 |  |
富士山は見えます。 | https://www.pref.shizuoka.jp/fujisanview/365.html?date=20230805gotenba |
| 2023-08-06 |  |
富士山は見えない | https://www.pref.shizuoka.jp/fujisanview/365.html?date=20230806gotenba |
ここで、本来なら誤判定しているものをカウントしたいところですが、以下のような微妙なものあるので今回はあきらめました。
| Date | Image | Answer | Page |
|---|---|---|---|
| 2023-08-11 |  |
富士山は見えます。 | https://www.pref.shizuoka.jp/fujisanview/365.html?date=20230811gotenba |
| 2023-08-12 |  |
富士山は見えます。 | https://www.pref.shizuoka.jp/fujisanview/365.html?date=20230812gotenba |
少数ショット学習ありの場合
例には以下の画像を使っています。
長いの折りたたんいます。

富士山は見える

富士山は見える

富士山は見える

富士山は見えない

富士山は見える
以上の例を含めた場合、少数ショット学習なしに比べると「見える」と過剰に判定されていたものは減る結果となりました。
| Date | Image | Answer | Page |
|---|---|---|---|
| 2023-08-04 | |
富士山は見えない | https://www.pref.shizuoka.jp/fujisanview/365.html?date=20230804gotenba |
| 2023-08-05 | |
富士山は見えない | https://www.pref.shizuoka.jp/fujisanview/365.html?date=20230805gotenba |
| 2023-08-06 | |
富士山は見えない | https://www.pref.shizuoka.jp/fujisanview/365.html?date=20230806gotenba |
| 2023-08-11 | |
富士山は見えない | https://www.pref.shizuoka.jp/fujisanview/365.html?date=20230811gotenba |
| 2023-08-12 | |
富士山は見えない | https://www.pref.shizuoka.jp/fujisanview/365.html?date=20230812gotenba |
ただし、逆に「見えているのに見えない」判定することも数件ありました(19 日の方は見えないでも良い気もしますが)。
以下、一部抜粋(これ以外にも数件あります)。
| Date | Image | Answer | Page |
|---|---|---|---|
| 2023-07-15 |  |
富士山は見えない | https://www.pref.shizuoka.jp/fujisanview/365.html?date=20230715gotenba |
| 2023-07-19 |  |
富士山は見えない | https://www.pref.shizuoka.jp/fujisanview/365.html?date=20230719gotenba |
この辺は例にする画像の選定にもよりそうですが、少数ショット学習が判定に影響することは確認できたかと思います。
考慮点
どこまで情報を渡すか
上記の実験後、プロンプトをいくつか試していて気がついたのですが、以下の情報を Gemini API へ送信したのはちょっと失敗だったなと思いました。
- 定点カメラで撮影した写真であるという説明
- 撮影した日時が写真に含まれている
試しにアプリの Gemini(Pro を使っています)に写真を 1 枚だけ入力して確認したところ以下のような返答でした。
長いので折りたたんでいます。
プロンプト(実験のときと少し違います):
定点カメラから撮影した富士山の見え方について教えてください
返答は以下の3つから選択してください。
- 雪が積もっている富士山
- 雪が積もっていない富士山
- 富士山は見えない
写真:

返答:
送信された画像によると、富士山は雪で覆われていません。
画像では、富士山は画面左側に写っており、山頂は茶色で、雪は見られません。山肌は茶色で、ところどころ岩肌が見えています。空は青く、雲はほとんどありません。
画像の撮影日時を確認すると、2023年8月1日午前9時8分となっています。8月は、富士山が雪で覆われていない時期です。
従って、定点カメラから撮影した富士山の見え方は「雪が積もっていない富士山」となります。
なお、富士山の見え方は、天候や時間帯によって変化します。また、カメラの設置場所によっても見え方が異なります。
例えば、静岡県富士市にある「富士山ライブカメラ」では、富士山の頂上付近を常に撮影しています。このカメラの映像では、冬でも雪が積もっていないことがあるのは、頂上付近は風が強く、雪が積もりにくいからです。
一方、山梨県富士吉田市にある「新倉山浅間公園ライブカメラ」では、富士山の全体を撮影しています。このカメラの映像では、冬には富士山が雪で覆われていることが多いのは、この場所からは富士山が遠くに小さく見えるため、頂上付近の雪もよく見えるからです。
定点カメラで撮影したという情報や日時から「この時期だとこうなるはず」という判断が入っています(そして間違えています)。 アプリの方では RAG(検索拡張生成)などがある影響かとは思いますが、API での判定に影響していないとも言い切れないので、ちょっと「うーん」となりました。
写真内のテキストを利用すること自体は有効利用できそうですが、意図せずに使われると影響もありそうなので注意した方が良さそうです。[2]
例になる画像を毎回送信するのは効率が悪い
これに対応する場合、埋め込みの利用を検討することになりそうですが、Gemini API のガイドではテキストについてのみの記述でした。
軽く調べてみた感じだと Vertex AI の機能をを使うことになるかと思いますが、それはそれで少し大変そうなイメージもあります。
あとは、こちらの記事にある「実現アプローチ2」「実現アプローチ3」のような対応になるのかと思います。
たとえば、以下のようなプロンプトで各写真の説明を取得しベクトル化(データベース化)しておく。判定したい写真も同じプロンプトで説明を取得し、そこから検索するといった感じでしょうか。
長いので折りたたんでいます。
プロンプト:
この写真について見えている景色や空模様(雲の多さなど)を詳細に説明してください。
また、撮影された日時も表示してください。
写真 1:

返答 1:
写真には富士山が写っています。富士山は冠雪しており、山頂から噴煙が上がっています。空は快晴で、雲はほとんどありません。写真の左下には、木々が写っています。撮影された日時:2024年1月16日9時08分
写真 2:

返答 2:
これは富士山の写真です。富士山の上半分は雲に覆われていて、その雲は笠のように見えています。笠雲は巻積雲の一種で、上空に強い寒気が入ってきたときに見られる雲です。富士山の下半分は緑に覆われていて、裾野まで見ることができます。空は青く、雲は白く、富士山は緑と白のコントラストが美しいです。撮影された日時:2023年8月11日9時08分
この辺は用途や利用頻度によって使い分けることになるのかなと思っています。
クレジット
この記事内で利用している定点カメラの画像(写真)について。
- 写真の出典: 静岡県(ライブカメラ富士山ビューについて)
- CC BY-NC 4.0 DEED: https://creativecommons.org/licenses/by-nc/4.0/deed.ja
おわりに
Gemini API で画像の少数ショット学習を利用して定点カメラの写真を判定してみました。
今回、ほぼ 1 年分の写真を判定することで以下のことが確認できたかと思います。
- 少数ショット学習は画像でも利用できそう
- 数枚の画像を利用するたけで判定結果を誘導できそう
- ただし、誤判定を完全に排除することは難しい
厳格な用途への適用はまだ難しそうですが、数枚の画像で判定結果を誘導できる(かもしれない)ことから、手軽に試すことができます。
簡単な画像判定装置を手早く用意したいときには選択肢の 1 になりそうかなと思いました。
-
https://atmarkit.itmedia.co.jp/ait/articles/2308/03/news016.html ↩︎
-
フィクションだと「AI が予想外の経路で情報を入手してしまい人類ピンチ」みたいな展開になるよなぁとちょっと思いました。 ↩︎
Discussion