Gemini API を使いスマホでスキャンした表やグラフから自動的にスプレッドシートを作ってみる
Gemini API を少し触ってみて、画像関連でいくつか応用できそうに思えました。
そこで、Google Drive でスキャンした画像(PDF)から自動的にスプレッドシートを作成するような GAS 用スクリプトを試作してみました。
どのようなスクリプト?
Google Drive で以下のような画像をアップロード(スキャン)しておくと Gemini API を利用してスプレッドシートを作成します。
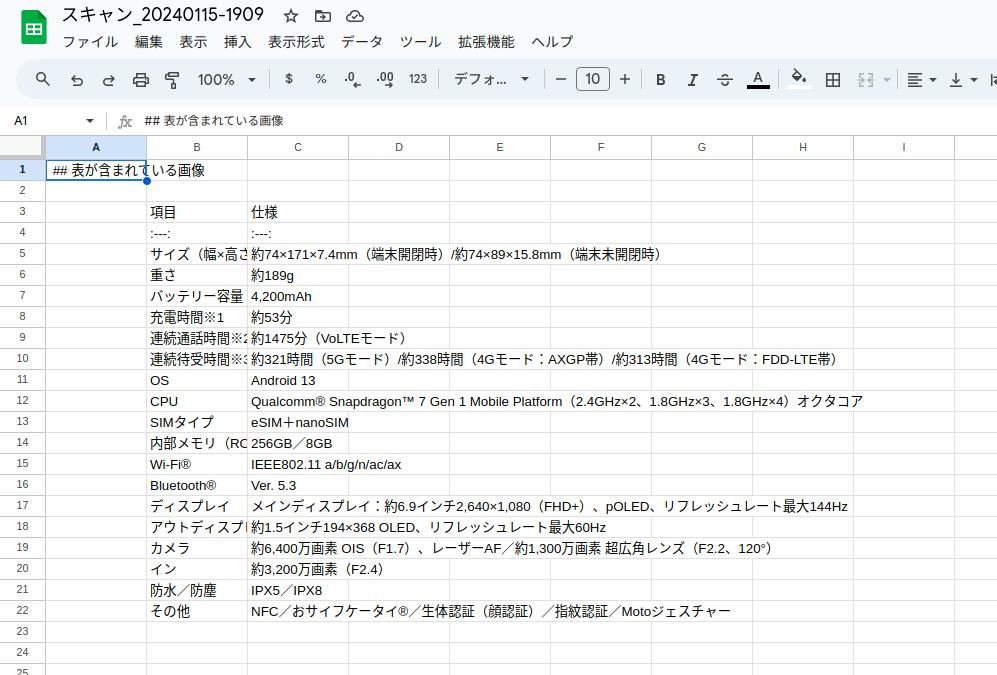
図 1-1 紙の表をスキャンしたファイル

図 1-2 紙の表から作成したスプレッドシート
また、スキャン元の画像にはグラフも利用できます。ただし、グラフ内に値が表示されていないと多くの場合で正確な値にはなりません。
図 1-3 画面に表示されているグラフをスキャンしたファイル
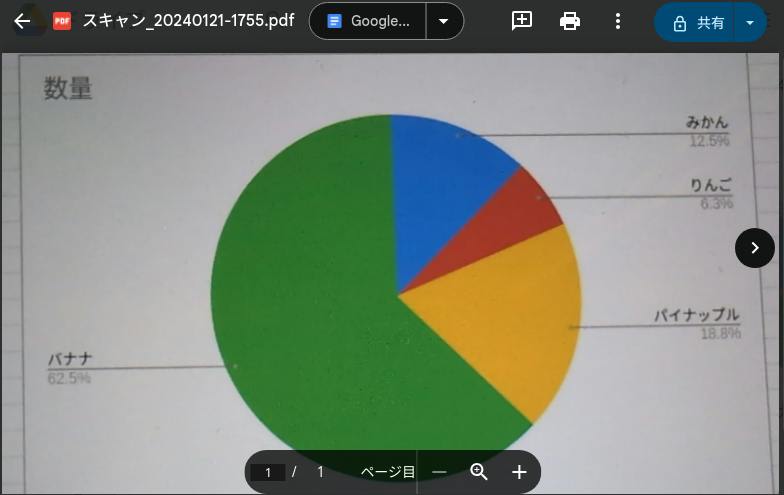
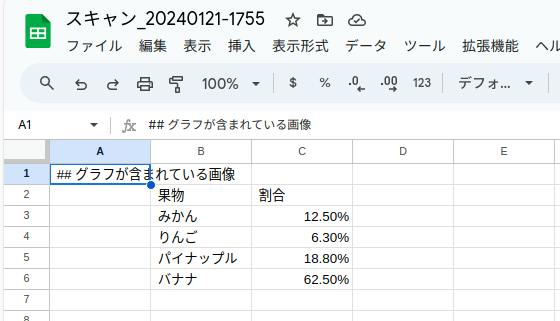
図 1-4 グラフから作成したスプレッドシート
表として取り込む仕組み(プロンプト)
基本的にはドキュメントに従って画像を含むマルチモーダル用クエリーを POST しているだけですが、テキストプロンプトを以下のようにしています。
リスト 2-1 画像の種類別に情報を取りだすプロンプト
画像の内容について。
以下の中から最も適切な方法で説明してください。
## 表が含まれている画像の場会
返答の最初に「## 表が含まれている画像」と記述したあと、表の内容をマークダウン形式で記述してください。
## グラフが含まれている画像の場合
返答の最初に「## グラフが含まれている画像」と記述したあと、グラフの内容をマークダウンの表として記述してください。
## テキスト(文章または簡単な説明文など)が含まれている画像の場合
返答の最初に「## テキストが含まれている画像」と記述したあと、テキストの内容を記述してください。
## その他の画像の場合
返答の最初に「## その他の画像」と記述したあと、画像の説明を記述してください。
このようにしておくと、返答の 1 行目を調べることで画像が表へ変換されているか判定できます。また、表は Markdown のテーブル風に返答されます。これによりスプレッドシートへの変換処理などを追加しやすくなります。
Gemini API を GAS で利用
Google Spreadsheets と Drive 関連の処理なので今回は GAS でスクリプトを作成します。
しかし、GAS には Gemini サービスなどはないので、次の記事を参考に REST API を利用します(API キーの取得についても同記事が参考になります)。
実装してみる
スキャン用のスクリプト(ライブラリー)作成
ライブラリーとして再利用しやすくするために、以下のようなスタンドアローンスクリプトを作成します。
リスト 4-1 Gemini で画像をスキャンするスクリプト(ScanImageWithGemini )
処理的に難しいことはしていませんが、送信サイズを小さくするためにファイルのサムネイルを利用しています。また、サムネイルを利用することで通常の画像以外のファイルも利用が容易になっています(画像以外のファイルについては後で少し触れます)。
フォルダー内のファイルをスキャンする
ライブラリーを作成できたので、スフォルダーに保存されている画像から自動的にスプレッドシートを作成してみます。
前準備として、Google Drive に以下のフォルダーを作成し ID を控えておきます。
- スキャン(アップロード)により画像が保存されるフォルダー
- スプレッドシートを作成するフォルダー
図 4-1 スキャン用とシート作成用フォルダー

以下のようなスタンドアローンスクリプトを作成し、上記ライブラリーを追加します。
リスト 4-2 フォルダー内のファイルを処理するスクリプト
スクリプトを作成したらスクリプトプロパティーを設定します。
-
GEMINI_API_KEY: API キー -
SRC_FOLDER: スキャンにより画像が保存されるフォルダーの ID -
DEST_FILDER: スプレッドシートを作成するフォルダーの ID
これで準備ができました。
スキャン用フォルダーに画像を保存し、start 関数を実行するとスプレッドシートが作成されます。また、元ファイルの説明欄にも表(マークダウン形式のテキスト)が追加されます。
図 4-2 スキャンされた画像
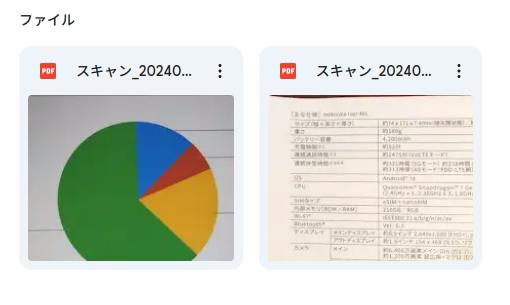
図 4-3 作成されたスプレッドシート

ファイルの内容が表でない場合、スプレッドシートは作成されませんが、ファイルの説明は追加されます。
図 4-4 表でない場合
start 関数を複数回実行した場合、ファイルの説明が空白でないものはスキップされるので、定期実行しておくと自動化ぽい感じになるかと思います。
また、フォルダーとスクリプトを複数用意しておき、それぞれのプロンプトを変更しておくと用途別の結果を得やすくなります。
私は以前に作成した OCR ライブラリーも併用しているので、各フォルダーをスマホのホーム画面へ登録することで使い分けています。
図 4-5 スキャン用フォルダーをホーム画面へ登録
![]()
応用
今回のスクリプトは Google Drive のサムネイルを利用しているので、Gemini が対応していないようなファイルでもサムネイル部分を入力できます[1]。本筋から外れますが、スプレッドシートを UI 代わりにして少し実験してみます。
簡単な UI を作成(スプレッドシートにメニューを追加)
スプレッドシートで「拡張機能 / Apps Script」メニューからスリプトを作成します。
リスト 5-1 メニューを追加するスクリプト
スクリプトに以下を設定します。
- 前述の
ScanImageWithGeminiライブラリーを追加 - スクリプトプロパティーへ
GEMINI_API_KEYを追加
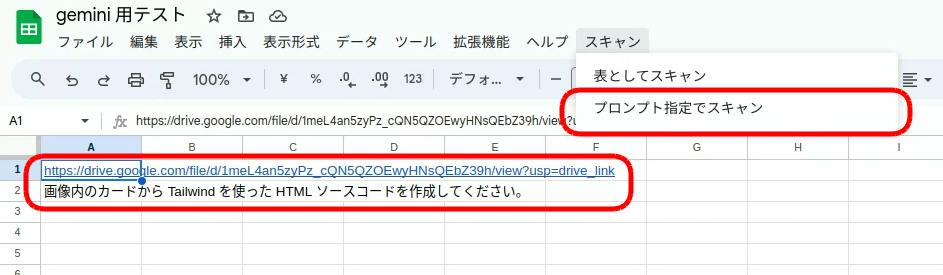
これで、スプレッドシートに「スキャン / プロンプト指定でスキャン」メニューが追加されます。
セルに「ファイルの URL」と「プロンプト」を入力し、メニューから「プロンプト指定でスキャン」を選択すると返答がセル内に転記されます。 (ファイルの URL は共有メニューからコピーしたものが使えます)
図 5-1 ファイルURL とプロンプトを入力しメニューを選択
diagrams.net(draw.io)ファイルを扱う
現行の Bard では少し面倒な処理として diagrams.net(draw.io)ファイルから Tailwind CSS + HTML のソースコードを作成してみます。
図 5-2 diagrams.net でカード的な図を作成
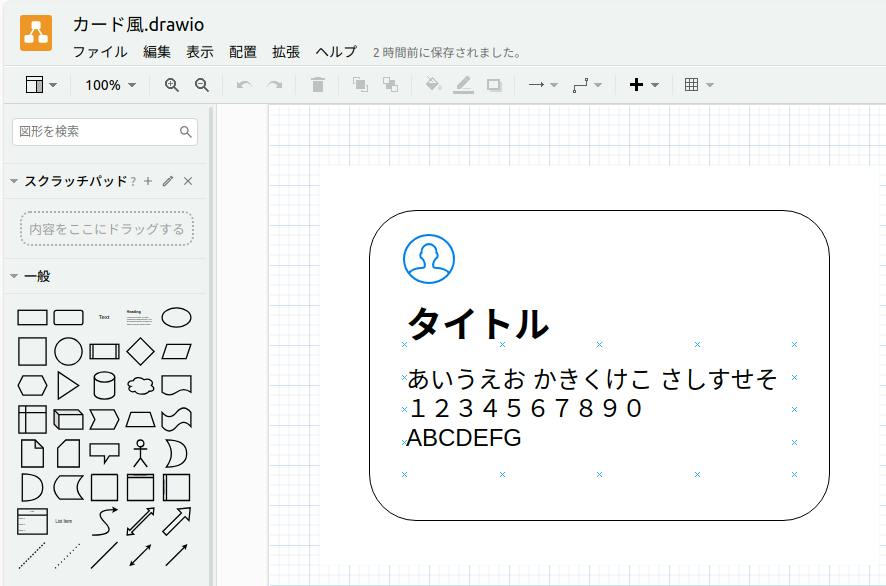
図 5-3 diagrams.net 用ファイルはサムネイルを取得できる
リスト 5-2 ソースコードを作成するプロンプト
画像内のカードから Tailwind を使った HTML ソースコードを作成してください。
図 5-4 プロンプトを指定して HTML ソースを取得
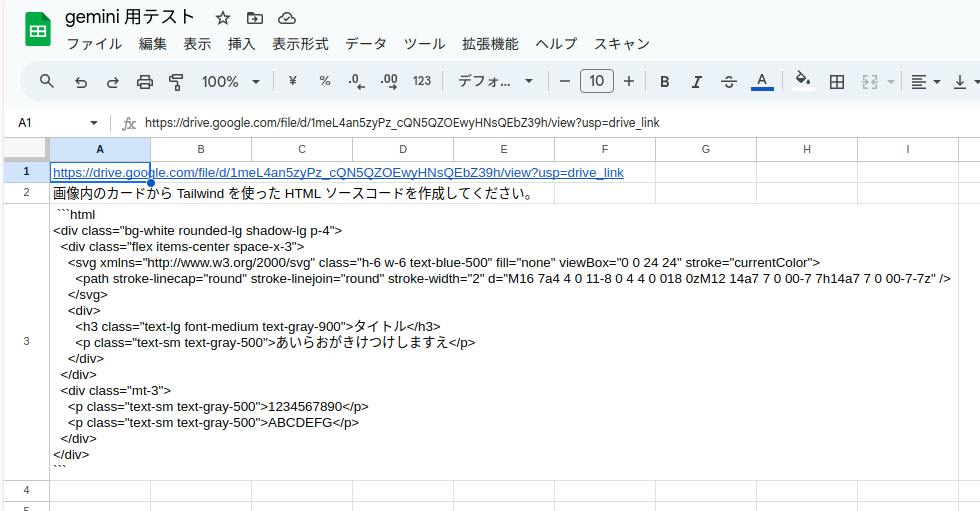
図 5-5 Tailwind Play へコピペしてプレビュー
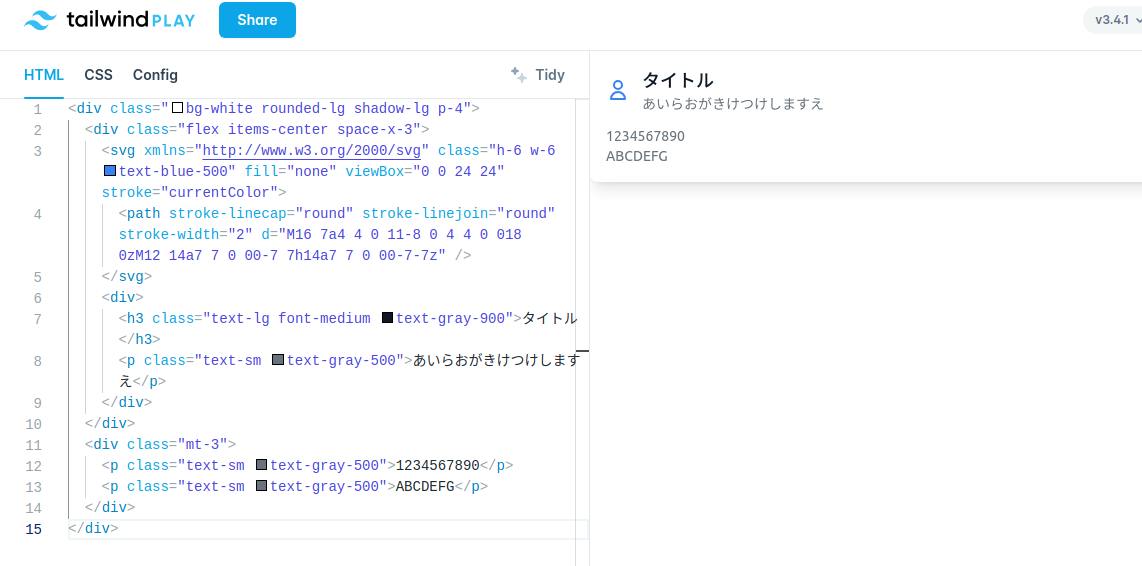
見出しの配置が少し変化していますが、こちらの方が良い感じに見えるので深く考えないことにします。
ここでは、diagrams.net 用ファイルを使いましたが、いろいろなファイルとプロンプトを試して良い感じになったら自動化してみると面白いかと思います。
考慮点
プロンプトと通常ソースコードの構成
今回は画像の種類をプロンプトで特定しておき、通常のソースコード(GAS)で処理を分岐させる方針としました。
このとき、プロンプトで指定したキーワードを深く考えずに GAS 側で使ってしまったので、扱う画像の種類を増やす時に少し苦労しました。 (実はグラフ関連の処理を後から追加したので「うーん」となりました)
プロンプトもベタ書きするのではなく、配列とテンプレートから組み立てたりといったことを検討した方が良いのかもしれません。
次に作るときはこの辺に気をつけたいなと考えています。
パラメーター(generationConfig)
いくつか文章を取り込んでみた感じでは、前後の文脈からテキストを補完しているような印象です。気が利いていると感じる場合もあるのですが[2]、OCR としてみると少し困った状態でもあります。
パラメーターの変更でランダムさを減らしてみたりはしたのですが、この辺は Google AI Studio も使って調整した方が良かったかなと感じました。
おわりに
Gemini API と GAS を利用して画像をスプレッドシートへ変換するツールを試作してみました。
作ってみたものを利用してみた感触としては「OCR として見ると気を利かせすぎかも」な感じもありますが、ちょっとした表の取り込みは楽になりそうかなと考えています。
また、今回はフォーマットの変換などを主に試しましたが、画像の内容をトリガーとした自動化などにも応用できそうだと感じました。
-
今回のスクリプトでは動画のサムネイルを入力できますが、動画そのものは入力できません。動画は「GoogleのマルチモーダルAI「Gemini Pro Vision」は、動画についてどこまで正しく答えられるか?【イニシャルB】 - INTERNET Watch」などが参考になります。 ↩︎
-
レシートに記載されている「ロールチャン」を「ロールちゃん」にするなどがありました。レシートを見返したときに「ロールチャンとは?」と考え込んでしまったのでありがたいとは思ったのですが、悩ましいところでもあります。 ↩︎
Discussion