Vertex AI Gemini ProとLangChainで実現するMultimodal RAG
はじめに
この記事は、Google Cloud Champion Innovators Advent Calendar 2023 18日目の記事です。
機械学習エンジニアをしています、原です。Google Cloud Champion Innovators(AI/ML)として選出いただき、活動しています。Google Cloud Innovatorsは、Google Cloud開発者/技術者のためのメンバーシッププログラムです。誰でも参加可能ですので、Google Cloudユーザーの方はぜひ参加をおすすめします!
先日、下記のような記事を公開し、Vertex AIにおけるGemini APIの概要と簡易的な実装例を紹介しました。
今回は少し実践寄りで、Vertex AIでのGemini APIとLangChainを組み合わせて、MultimodalなRAGを構築する一例を紹介します。実現するためのサンプルコードも添えて紹介しますので、ご参考になれば幸いです。
Multimodal RAGとは
まずはじめに、今回実現するMultimodal RAGを説明します。
RAG(Retrieval Augmented Generation)とは、LLMと外部のナレッジベースを組み合わせたアプローチです。質問に関連する外部データをコンテキストとしてプロンプトに埋め込むことによって、LLMが外部知識に基づいて回答します。これにより、回答の精度向上やハルシネーションの低減が期待できます。詳細に関しては、このアプローチが発表された下記の論文をご参照ください。
そして、今回のメイントピックであるMultimodal RAGとは、テキストデータのみならず、画像や表など様々なコンテンツをナレッジベースとしたRAGです。LangChainの公式ブログ「Multi-Vector Retriever for RAG on tables, text, and images」にまとめられています。LangChainでは、MultiVectorRetrieverとMultimodal LLM(Gemini Pro VisionやGPT-4-Vなど)やMultimodal Embeddingを組み合わせることで、実装できます。
先述のLangChainのブログでは、具体的な実現方法として3つのアプローチが紹介されています。
実現アプローチ1
このアプローチでは、Multimodal Embeddingを活用してテキストと画像を同一のベクトル空間に埋め込みます。Google Cloudでは、multimodalembeddingの名称で提供されています。取得されたベクトルはVector Storeへと格納されます。そして、回答生成時にはRetrieverがベクトルをもとにテキストと画像を検索します。取得されたデータはコンテキストとして、GeminiやGPT-4-Vなどのmultimodal LLMへと入力され、回答の生成が行われます。
実現アプローチ2
こちらではまず、GeminiやGPT-4-Vなどのmultimodal LLMに画像を入力し、画像の説明をテキストとして抽出します。そして、Text Embeddingモデル(Google Cloudでは、textembedding-geckoまたはtextembedding-gecko-multilingual)が説明文章とテキストデータをベクトル化します。のちに、1つ目のアプローチと同様にVector Storeへと格納、Retrieverが画像の説明とテキストデータを検索し、LLMにて回答を生成します。1つ目との大きな差異は、画像が説明文として扱われる点です。そのため、回答生成時にMultimodal LLMを使う必要がなく、PaLM2やGPT-3.5のようなテキストデータのみを扱うLLMを使用することができます。
実現アプローチ3
2つ目と同様にMultimodal LLMを活用して画像説明の生成をします。そして、Text Embeddingモデルでベクトルを取得、Vector Storeに格納します。ここまでは同じです。しかし、Retrieverでの取得処理は少し異なり、画像の説明を取得するのではなく、画像説明のベクトルに紐づけられている元の画像を取得します。そして、画像とテキストデータをMultimodal LLMに入力することで回答を生成します。
このように、Multimodal RAGの構築には様々なアプローチが考えられます。今回は、Gemini Pro Visonの画像認識精度を十分に活かすために、3つ目のアプローチを採用し、実装を行いました。
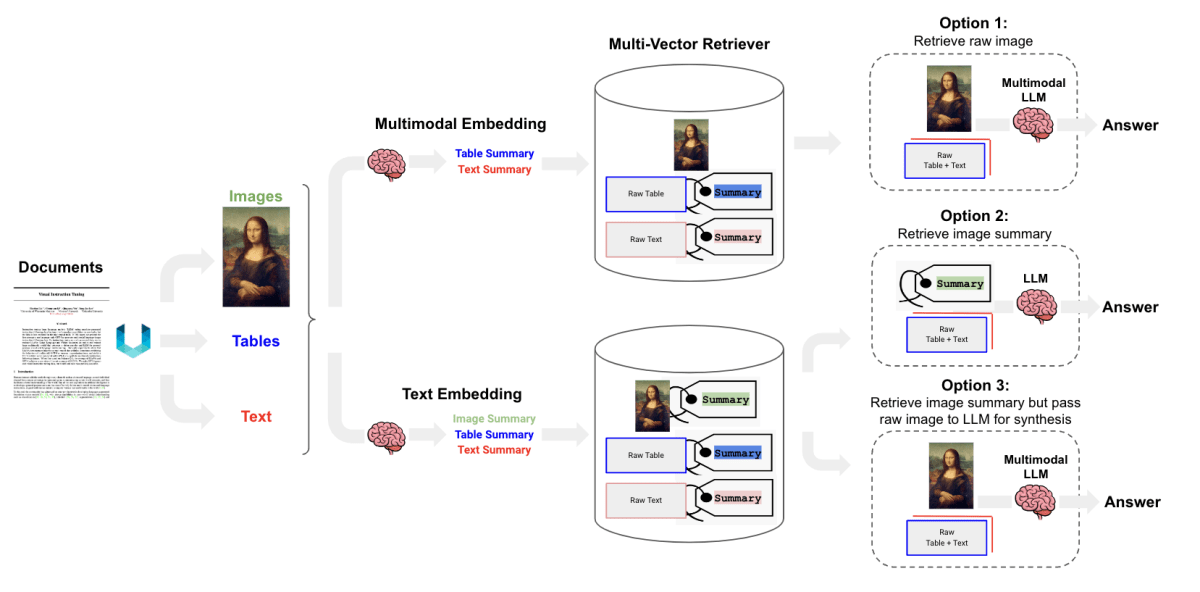
LangChainブログより引用
実装ガイド
それではいよいよ、Gemini ProとLangChainを組み合わせて、Multimodal RAGを構築していきます。下記のステップで実装します。
- 環境構築
- unstructuredでPDFから要素抽出
- Gemini Pro Visionで画像の説明を取得
- Gemini Proでテーブルの説明を取得
- Gemini Proでテキストデータに対する想定質問を取得
- Vector Storeを作成・ベクトルを保存
- RAGを実行
1. 環境構築
今回は下記の環境で実装を行いました。
python = "3.11.5"
poetry = "1.6.1"
google-cloud-aiplatform = "1.38.1"
langchain = "0.0.351"
unstructured = {extras = ["all-docs"], version = "^0.11.6"}
matplotlib = "^3.8.2"
chromadb = "^0.4.20"
Pythonライブラリのgoogle-cloud-aiplatformはGemini APIの使用のために、langchainはRAGの構築のために使用します。
また、unstructuredは、PDFやWordなどの非構造化データの前処理を行うライブラリです。今回はPDFからテキスト、画像、テーブルを分離するために使用します。LangChainのデータローダーの1つであるUnstructuredFileLoaderからも利用可能ですが、今回は、各処理を詳細に設定するためにLangChainを介さずに使用しています。
matplotlibはRetrieverによって取得された画像データを表示するために使用します。Vector Storeには、chromadbを使用しました。採用理由は、LangChainから容易に使用でき、解説を簡潔化できるためです。しかし、本番導入の際には、ハイパフォーマンスなVertex AI Vector Searchなどを使用するとよいでしょう。私が執筆した過去の記事でも解説していますので、興味のある方はぜひご覧ください。
注意点として、unstructuredはpipなどでインストールするだけでは使用できません。
少し苦戦したので、私がPDFを読み取るために行った構築手順を記載しておきます。macOSでの構築となりますので、LinuxやWindowsで構築する方はこちらの公式ドキュメントを参考にしてください。
-
unstructuredのPythonライブラリをインストールする
まず、下記のコマンドでPythonのライブラリをインストールします。all-docsとオプションを付けることで、対応している全ドキュメントタイプの処理機能がインストールできます。poetry add "unstructured[all-docs]" -
popplerをインストールする
popplerはPDFレンダリングのためのライブラリです。Homebrewでインストールすることができます。brew install poppler -
Tesseractをインストールする
TesseractはOCRエンジンです。Homebrewでインストールしてから、Pythonラッパーであるpytesseractをインストールしましょう。brew install tesseract poetry add pytesseract
2. unstructuredでPDFから要素抽出
環境構築ができたので、unstructuredを使ってPDFからテキスト、画像、テーブルを分割しましょう。下記のようなコードとなります。partition_pdfの各種パラメータに関してはこちらを参照ください。チャンクサイズなどを指定することができます。
今回は「Attention Is All You Need」の論文を入力PDFとして試しました。実行すると、PDFから抽出されたテキストデータとテーブルが、それぞれリストとして取得されます。画像に関しては、指定したdataset_dir配下のimagesにjpegで保存されます。
import os
from typing import List, Tuple
from unstructured.partition.pdf import partition_pdf
def partition_pdf_by_element_type(
dataset_dir: str, pdf_file_name: str
) -> Tuple[List[str], List[str]]:
loaded_pdf = partition_pdf(
filename=os.path.join(dataset_dir, pdf_file_name),
extract_images_in_pdf=True,
infer_table_structure=True,
chunking_strategy="by_title",
max_characters=4000,
new_after_n_chars=3800,
combine_text_under_n_chars=2000,
image_output_dir_path=os.path.join(dataset_dir, "images"),
)
# テーブルとテキストをリストに格納する
tables, texts = [], []
for element in loaded_pdf:
if "unstructured.documents.elements.Table" in str(type(element)):
tables.append(str(element))
elif "unstructured.documents.elements.CompositeElement" in str(
type(element)
):
texts.append(str(element))
return tables, texts
if __name__ == "__main__":
dataset_dir = os.path.join(
os.path.dirname(os.path.abspath(__file__)), "datasets"
)
pdf_file_path = "pdf/attention.pdf"
tables, texts = partition_pdf(
dataset_dir=dataset_dir, pdf_file_name=pdf_file_path
)
3. Gemini Pro Visionで画像の説明を取得
画像を抽出できたので、次はGemini Pro Visionを使用して、抽出された画像から説明を取得します。これにより、画像データをText Embedding可能なテキストデータに変換します。下記のようなコードとプロンプトになります。
実行すると、画像がbase64エンコードされた文字列と、Gemini Pro Visionによる説明の2種類のデータが保持されたdictが取得できます。base64エンコードをしたのは、のちに説明文のベクトルと紐づけ、Retrieverが元の画像を検索できるようにするためです。
import base64
import os
from typing import Any, Dict, List
from langchain.chat_models import ChatVertexAI
from langchain.schema.messages import HumanMessage
# 画像ファイルをBase64エンコードされた文字列に変換
def image_to_base64(image_path: str) -> str:
with open(image_path, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode("utf-8")
return encoded_string
# Gemini Pro Visionにて画像の説明を行い、説明結果とbase64を返却する
def summarize_images_with_gemini(image_dir: str) -> Dict[str, List[Any]]:
image_base64_list = []
image_summaries_list = []
image_summary_prompt = """
入力された画像の内容を詳細に説明してください。
基本的には日本語で回答してほしいですが、専門用語や固有名詞を用いて説明をする際には英語のままで構いません。
"""
for image_file_name in sorted(os.listdir(image_dir)):
if image_file_name.endswith(".jpg"):
image_file_path = os.path.join(image_dir, image_file_name)
# encodeを行い、base64をリストに格納する
image_base64 = image_to_base64(image_file_path)
image_base64_list.append(image_base64)
# Geminiで画像の説明を行い、結果をリストに格納する
summarize_model_name = "gemini-pro-vision"
summarize_model = ChatVertexAI(
model_name=summarize_model_name,
max_output_tokens=2048,
temperature=0.4,
top_p=1,
top_k=32,
)
text_message = {"type": "text", "text": image_summary_prompt}
image_message = {
"type": "image_url",
"image_url": {"url": image_file_path},
}
response = summarize_model(
[HumanMessage(content=[text_message, image_message])]
)
image_summaries_list.append(response.content)
images_dict = {
"image_list": image_base64_list,
"image_summaries": image_summaries_list,
}
return images_dict
if __name__ == "__main__":
dataset_dir = os.path.join(
os.path.dirname(os.path.abspath(__file__)), "datasets"
)
images_dict = summarize_images_with_gemini(
image_dir=os.path.join(dataset_dir, "images")
)
実行例として、対象の画像と生成された説明文の一部を掲載しておきます。

説明対象の画像(Attention Is All You Need Figure 1より)
これはTransformerのモデルの図です。Transformerは、2017年に発表された、機械翻訳や要約などの自然言語処理タスクで最先端の結果を達成したモデルです。
Transformerは、シーケンス間の関係をモデル化するために、アテンションメカニズムを使用しています。(以下省略)
4. Gemini Proでテーブルの説明を取得
画像に続き、テーブルデータの説明をGemini Proにて行います。テキストのみの入力となるので、Visionモデルは使用していません。実装は下記のようなコードとプロンプトになります。2023/12/23現在、LangChainで推奨されているLCELでChainを記述しています。
実行すると、元のテーブルデータと説明がdictとして取得できます。
from typing import Any, Dict, List
from langchain.chat_models import ChatVertexAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
def summarize_tables_with_gemini(
tables_list: List[str],
) -> Dict[str, List[Any]]:
table_summary_prompt_template = """
テーブルが与えられます。
下記に記載されている出力項目に着目して、読み取れることを出力してください。
# 出力項目:
- 何がまとめられているテーブルなのか
- テーブルに記載されているキーワード
- テーブルから読み取ることができる分析結果
# テーブル:
{table}
"""
table_summary_prompt = ChatPromptTemplate.from_template(
table_summary_prompt_template
)
summarize_model_name = "gemini-pro"
summarize_model = ChatVertexAI(
model_name=summarize_model_name,
max_output_tokens=2048,
temperature=0.9,
top_p=1,
)
# LCELでチェーンを記述
summarize_chain = (
{"table": lambda x: x}
| table_summary_prompt
| summarize_model
| StrOutputParser()
)
table_summaries = summarize_chain.batch(
tables_list, config={"max_concurrency": 5}
)
tables_dict = {
"table_list": tables_list,
"table_summaries": table_summaries,
}
return tables_dict
if __name__ == "__main__":
tables_dict = summarize_tables_with_gemini(tables_list=tables)
こちらも画像と同様に対象のテーブルと、生成された説明文の一部を掲載しておきます。
ここでは、説明のためにテーブルの画像を載せていますが、実際はテキスト形式のデータになっています。
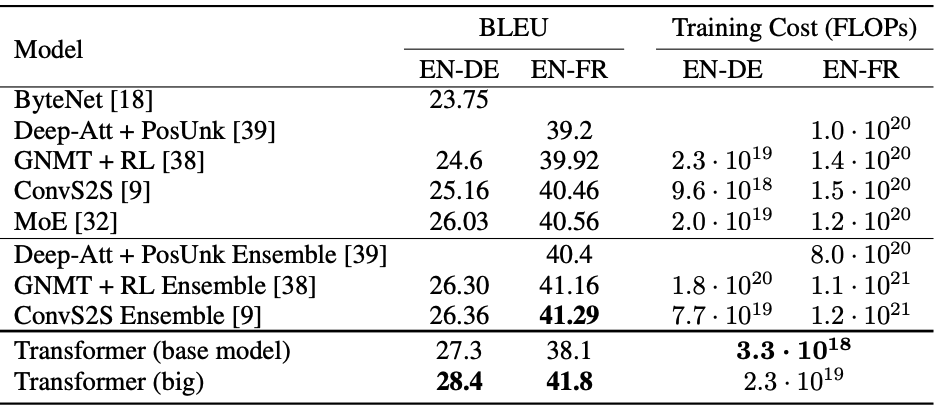
説明対象のテーブル(Attention Is All You Need Table 2より)
何がまとめられているテーブルなのか:
機械翻訳の様々なモデルについて、BLEUスコアとトレーニングコスト(FLOPs)を示したテーブルです。
テーブルに記載されているキーワード:
- BLEU
- FLOPs
- EN-DE
- EN-FR
- ByteNet
- Deep-Att + PosUnk
- GNMT + RL
- ConvS2S
- MoE
- Deep-Att + PosUnk Ensemble
- GNMT + RL Ensemble
- ConvS2S Ensemble
- Transformer (base model)
- Transformer (big)
テーブルから読み取ることが出来る分析結果:
- Transformer (big)モデルは、すべての言語ペアで最高のBLEUスコアを達成しました。
(以下省略)
5. Gemini Proでテキストデータに対する想定質問を取得
次にテキストデータです。こちらでは元のチャンクに加えて、そのチャンクに対しての想定質問を使ってみたいと思います。そのために、Gemini Proを用いてチャンクに対する想定質問を生成します。
from langchain.chat_models import ChatVertexAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
def hypothetical_queries_with_gemini(
texts_list: List[str],
) -> Dict[str, List[Any]]:
text_summary_prompt_template = """
テキストチャンクが与えられます。
そのチャンクに対して、想定される質問を1つ考えてください。
下記の制約条件を厳格に守ってください。
# 制約条件:
- あなたが考えた質問のみを出力してください
- 質問を考える際には、質問例を参考にしてください
- 1つのテキストチャンクに対して、1つの回答を出力してください
# 質問例:
- MultiVectorRetrieverとはどのようなものですか?
- 「Vertex AI(Gemini API)でGemini Proを試す」というブログの著者は誰ですか?
- Vertex AIのGemini APIではどのようなことができますか?
# テキストチャンク:
{text}
"""
text_summary_prompt = ChatPromptTemplate.from_template(
text_summary_prompt_template
)
summarize_model_name = "gemini-pro"
summarize_model = ChatVertexAI(
model_name=summarize_model_name,
max_output_tokens=2048,
temperature=0.9,
top_p=1,
)
# LCELでチェーンを記述
summarize_chain = (
{"text": lambda x: x}
| text_summary_prompt
| summarize_model
| StrOutputParser()
)
text_summaries = summarize_chain.batch(
texts_list, config={"max_concurrency": 5}
)
texts_dict = {
"texts_list": texts_list,
"text_summaries": text_summaries,
}
return texts_dict
if __name__ == "__main__":
texts_dict = hypothetical_queries_with_gemini(texts_list=texts)
実行すると下記のような想定質問が生成されます。
'Attention Is All You Needの論文の著者は誰ですか?'
'Transformerとはどのようなモデルですか?'
'Multi-Head Attentionとはどのようなもので、なぜTransformerで使用されているのですか?'
'Transformerモデルのエンコーダーとデコーダーの各レイヤーにおいて、どのような処理が行われているのでしょうか?'
'Scaled Dot-Product AttentionとAdditive Attentionの違いは何ですか?'
'Transformerモデルで用いられているAttentionの役割は何ですか?'
(以下省略)
これで、PDFに含まれているテキスト、テーブル、画像の3種類をEmbeddingする準備が整いました。
6. Vector Storeを作成・ベクトルを保存
次に、先ほど用意したデータをそれぞれEmbeddingすることでベクトルを取得し、ChromaDBに保存していきます。EmbeddingにはGoogle Cloudの多言語に最適化されたモデルであるtextembedding-gecko-multilingual@001を使用しました。英語のみのデータをEmbeddingする際には、textembedding-gecko@003を使用するとよいでしょう。
Vector Storeを作成できたら、MultiVectorRetrieverを使用して検索可能にします。これによって、用意したデータ(画像/テーブル説明・想定質問)のベクトル、そして元のデータ(画像・テーブル・テキストチャンク)をidで紐づけることができます。プログラム中のmultivector_retriever.docstore.mset(list(zip(img_ids, images_dict["image_list"])))が元のデータと用意したデータを紐づける箇所です。
MultiVectorRetrieverについての補足
MultiVectorRetrieverとはドキュメントごとに複数のベクトルを紐づけるための機能です。
1つのドキュメントに対して、チャンクや要約、想定される質問など、様々なアプローチで作成されたベクトルを紐づけることができます。これにより、Retrieverの精度向上が期待できます。今回のユースケースでは、画像とテーブルは「元の画像↔画像説明のベクトル」、「元のテーブル↔テーブル説明のベクトル」といった1対1の紐づけを行っていますが、複数のベクトルを紐づけることができます。実際に、テキストデータでは「テキストチャンク↔テキストチャンクのベクトル and 想定質問のベクトル」を保持しています。
また、実装コードを見たところ、近傍探索数kは4がデフォルトになっていました。この値はQueryに対して取得するベクトルの数で、親ドキュメントの数ではありません。これにより、複数のベクトルを単一のドキュメントに紐づけた場合、MultiVectorRetrieverが取得するドキュメント数がkの値を下回る可能性があります。
複数のベクトルを紐づける際には、同一の親ドキュメントに紐づくベクトルが検索結果の上位に集中する可能性が高いので、kの値を調整することをおすすめします。今回はテキストデータで、元のテキストのベクトルと想定質問のベクトルの2種類を紐づけているので、デフォルトより多めのk=6を指定しました。
少し補足が長くなりましたが、実装コードは下記の通りです。これでVector Storeが作成され、ベクトルが保存されます。そして、RAGを実現するためのMultiVectorRetrieverを作ることができます。
import uuid
from typing import Any, Dict, List
from langchain.embeddings import VertexAIEmbeddings
from langchain.retrievers.multi_vector import MultiVectorRetriever
from langchain.schema.document import Document
from langchain.storage import InMemoryStore
from langchain.vectorstores import Chroma
from langchain_core.documents import Document
def import_data_to_vector_store(
texts_dict: Dict[str, List[Any]],
tables_dict: Dict[str, List[Any]],
images_dict: Dict[str, List[Any]],
) -> MultiVectorRetriever:
embedding_model_name = "textembedding-gecko-multilingual@001"
# embedding_model_name = "textembedding-gecko@003"
embedding_function = VertexAIEmbeddings(model_name=embedding_model_name)
vectorstore = Chroma(
collection_name="gemini-pro-multi-rag",
embedding_function=embedding_function,
)
# 元の文章を保存するためのストレージ
store = InMemoryStore()
id_key = "doc_id"
# Retrieverの作成
multivector_retriever = MultiVectorRetriever(
vectorstore=vectorstore,
docstore=store,
id_key=id_key,
search_kwargs={"k": 6},
)
# テキストデータをembedding、vectorstoreに格納する
doc_ids = [str(uuid.uuid4()) for _ in texts_dict["texts_list"]]
# チャンクを保存する
for i, s in enumerate(texts_dict["texts_list"]):
if s != "":
multivector_retriever.vectorstore.add_documents(
[Document(page_content=s, metadata={id_key: doc_ids[i]})]
)
# テキストチャンクとidを紐づける
multivector_retriever.docstore.mset(
list(zip(doc_ids, texts_dict["texts_list"]))
)
print("### Text Data Stored! ###")
# 想定質問を保存する
doc_summary_ids = [str(uuid.uuid4()) for _ in texts_dict["texts_list"]]
for i, s in enumerate(texts_dict["text_summaries"]):
if s != "":
multivector_retriever.vectorstore.add_documents(
[
Document(
page_content=s, metadata={id_key: doc_summary_ids[i]}
)
]
)
# テキストチャンクとidを紐づける
multivector_retriever.docstore.mset(
list(zip(doc_summary_ids, texts_dict["texts_list"]))
)
print("### Hypothetical Queries Data Stored! ###")
# テーブルデータの説明をembedding、vectorstoreに格納する
table_ids = [str(uuid.uuid4()) for _ in tables_dict["table_list"]]
# テーブルの説明を保存する
for i, s in enumerate(tables_dict["table_summaries"]):
multivector_retriever.vectorstore.add_documents(
[Document(page_content=s, metadata={id_key: table_ids[i]})]
)
# tablesを保存、とidを紐づける
multivector_retriever.docstore.mset(
list(zip(table_ids, tables_dict["table_list"]))
)
print("### Table Data Stored! ###")
# 画像データの説明をembedding、vectorstoreに格納する
img_ids = [str(uuid.uuid4()) for _ in images_dict["image_list"]]
# 画像の説明を保存する
for i, s in enumerate(images_dict["image_summaries"]):
multivector_retriever.vectorstore.add_documents(
[Document(page_content=s, metadata={id_key: img_ids[i]})]
)
# imagesを保存、とidを紐づける
multivector_retriever.docstore.mset(
list(zip(img_ids, images_dict["image_list"]))
)
print("### Image Data Stored! ###")
return multivector_retriever
if __name__ == "__main__":
multivector_retriever = import_data_to_vector_store(
texts=texts, tables_dict=tables_dict, images_dict=images_dict
)
7. RAGを実行
Vector StoreとRetrieverが準備できたので、最後にRAGを試します。
まず、LangChainのChainで実行する内部関数を定義します。
plt_image_base64は取得された画像を表示するためのものです。generate_promptでプロンプトの生成、split_data_typeで取得したコンテキストを画像とテキストに分類します。また、Retrieverで画像が1枚も取得されなかった時のためにmodel_selectionでモデルを切り替えています。
import base64
import io
from base64 import b64decode
from typing import Any, Dict, List
import matplotlib.pyplot as plt
import numpy as np
from langchain.chat_models import ChatVertexAI
from langchain.schema.messages import BaseMessage, HumanMessage
from PIL import Image
def plt_image_base64(img_base64: str) -> None:
# Base64データをデコードして画像に変換
image_data = base64.b64decode(img_base64)
image = Image.open(io.BytesIO(image_data))
# PILイメージをNumPy配列に変換
image_np = np.array(image)
# 画像を表示
plt.imshow(image_np)
plt.axis("off")
plt.show()
def generate_prompt(data: dict) -> List[HumanMessage]:
prompt_template = f"""
以下のcontext(テキストと表)のみに基づいて質問に答えてください。
入力画像が質問に対して関連しない場合には、画像は無視してください。
質問:
{data["question"]}
context:
{data["context"]["texts"]}
"""
text_message = {"type": "text", "text": prompt_template}
# 画像がRetrivalで取得された場合には画像を追加,エンコードしてmatplotlibで表示する
# 画像が複数取得されている場合には、関連性が最も高いものをモデルへの入力とする
if data["context"]["images"]:
plt_image_base64(data["context"]["images"][0])
image_url = f"data:image/jpeg;base64,{data['context']['images'][0]}"
image_message = {"type": "image_url", "image_url": {"url": image_url}}
return [HumanMessage(content=[text_message, image_message])]
else:
return [HumanMessage(content=[text_message])]
# 画像とテキストを分割する
def split_data_type(docs: List[str]) -> Dict[str, List[str]]:
base64, text = [], []
for doc in docs:
try:
b64decode(doc)
base64.append(doc)
except Exception:
text.append(doc)
return {"images": base64, "texts": text}
# 画像がない場合にはgemini-proを選択する
def model_selection(message: List[BaseMessage]) -> Any:
if len(message[0].content) == 1:
answer_generation_model = "gemini-pro"
else:
answer_generation_model = "gemini-pro-vision"
model = ChatVertexAI(model_name=answer_generation_model)
response = model(message)
return response
次に、定義した内部関数を使用して、LangChainのChainを作成、実行します。
from langchain.retrievers.multi_vector import MultiVectorRetriever
from langchain.schema.output_parser import StrOutputParser
from langchain_core.runnables import RunnableLambda, RunnablePassthrough
# Chainを作成、実行する
def multimodal_rag(retriever: MultiVectorRetriever, question: str) -> str:
chain = (
{
"context": retriever | RunnableLambda(split_data_type),
"question": RunnablePassthrough(),
}
| RunnableLambda(generate_prompt)
| RunnableLambda(model_selection)
| StrOutputParser()
)
answer = chain.invoke(question)
return answer
if __name__ == "__main__":
question_1 = "Attentionの論文の著者は誰ですか?また、所属はどこですか?"
answer_1 = multimodal_rag(multivector_retriever, question_1)
print(answer_1)
question_2 = "Transformerのアーキテクチャとはどのようなものですか?"
answer_2 = multimodal_rag(multivector_retriever, question_2)
print(answer_2)
1つ目の質問「Attentionの論文の著者は誰ですか?また、所属はどこですか?」に対する回答は下記の通りです。合っています。また、画像は検索されず、結果には表示されませんでした。著者に関連する画像は文中に含まれていないので、期待通りの動作です。
論文の著者は、Ashish Vaswani、Noam Shazeer、Niki Parmar、Jakob Uszkoreit、Llion Jones、Aidan N. Gomez、Łukasz Kaiser、Illia Polosukhinです。
所属は、Google Brain、Google Research、University of Torontoです。
2つ目の質問「Transformerのアーキテクチャとはどのようなものですか?」に対する回答は下記の通りです。こちらも正しい内容になっています。この回答時には画像が表示され、質問に沿ったアーキテクチャ図が取得できました。回答はこの画像とテキストのcontextを元に生成されています。
Transformerのアーキテクチャは、エンコーダーとデコーダーの2つの主要なコンポーネントで構成されています。エンコーダーは、入力シーケンスを固定長のベクトルに変換します。デコーダーは、エンコーダーの出力ベクトルを使用して、出力シーケンスを生成します。
エンコーダーとデコーダーは、どちらも複数の層で構成されています。各層は、自己注意メカニズムとフィードフォワードネットワークで構成されています。自己注意メカニズムは、シーケンス内の異なる位置間の関係を学習します。フィードフォワードネットワークは、シーケンスの各位置の出力ベクトルを計算します。
Transformerのアーキテクチャは、従来の機械翻訳モデルよりも高速で、精度も高くなっています。Transformerは、言語翻訳、要約、テキスト分類など、さまざまな自然言語処理タスクで使用されています。
表示結果(Attention Is All You Needより)
終わりに
今回は、Vertex AI Gemini ProとLangChainを活用して、Multimodal RAGを構築/解説しました。マルチモーダルモデルの登場によって、画像内容も考慮した回答ができるようになりました。Gemini Pro Visionでも十分な画像説明力があったので、より大規模なGemini Ultraの登場が楽しみです。
また、MultiVectorRetrieverを活用することによって、複数のベクトルを扱う方法も紹介しました。今回は、テキストデータに対する想定質問を扱いましたが、画像やテーブルに対しても様々なベクトルを紐づけ、RAGの精度を高めることができます。ぜひ皆さんもご自身の周りのデータで試してみてください。
参考文献
執筆にあたり下記の記事を参考にさせていただきました。感謝申し上げます。
Discussion
こんにちは、大切な情報をまとめて下さって感謝申し上げます。
2点質問があります。
コメントありがとうございます!
ご返信が遅くなってしまい、申し訳ありません。
質問内容から丁寧に読んでくださったことを感じました。ありがとうございます🙇♂
まず1点目に関してですが、LangChain内部の実装になりますが、そちらの認識であっていると思われます。Vector Store(このブログでのChroma)自体が保持するのは、IDとペアとなっているベクトルです。
2点目に関してですが、おっしゃる通りで「毎回ベクトル化する必要はない」です。
Retrieval対象のデータをVector Storeにベクトルを保持するのは1度の実行で大丈夫です。(ただし、データ自体や、ベクトル化の方法に更新がある場合には、その度に実行して書き換える必要があります)
実際に、このコードを使う際には、手順6までを事前に済ませておき、「7. RAGを実行」をアプリケーション側に実装すればよいと思います。
返信ありがとうございます。
手順6までを事前にやっておいて、「7. RAGを実行」をアプリケーション側に実装すればよいというので安心しました。
初歩的な質問で恐縮です。
・APIの設定などは必要ないのでしょうか?
・このPythonのプログラムはどんな環境で動くことが想定されているんでしょうか。GCPですか?GCPのどのサービスでしょうか?あるいは、ローカルのPC開発環境でしょうか?