本記事は Google Cloud Japan Advent Calendar 2023 の 入門編 17 日目の記事です。
皆様、いかがお過ごしでしょうか?
Google Cloud パートナーエンジニアの山中です。
昨年も以下の記事で Analytics Hub を取り上げたのですが、今年は 2023 年にあった Analytics Hub のアップデートをまとめたいと思います。
Analytics Hub とは
Analytics Hub は組織間でデータを効率よく安全に共有可能とする BigQuery を基盤としたデータシェアリング サービスです。データを共有することに主眼をおいたサービスとなっており、例えばグループ会社間でのデータ共有やオープンデータの公開などのユースケースに適用できます。
詳細については 前回の記事 に記載しているので、そちらをご覧ください。
2023 年にあった Analytics Hub のアップデート
ここからは今年アップデートがあった機能を簡単に紹介していきたいと思いますが、以前、「Google Cloud のアップデート情報っていくつかあるんだけど、どんな感じで使い分ければいいの?」と質問を受けたことがあるので、簡単に Google Cloud のアップデート情報のキャッチアップ方法についてご紹介します。
Google Cloud Update 情報
-
Google Cloud release notes
いち早く情報をキャッチしたい方々はこちらをご確認ください。合わせて、弊社エンジニアが注目機能に関しては X 等で少し具体的に紹介していたりしますので、そちらも合わせてフォローいただけると理解度が増すと思います。 -
Google Cloud blog
全てではないですが、注目すべき大型のアップデートなどがある場合は blog で取り上げるケースが多いです。基本的に英語が先にリリースされますので、こちらも合わせてご利用ください。 -
Google Cloud アップデート(speakerdeck)
PDF の形で日本語化したものを月 2 回のタイミングでアップロードしています。元ネタは上述した Google Cloud release notes になりますが、一部必要に応じて情報を補足してわかりやすくしています。資料としてもまとまっているものになりますので、社内勉強会資料のベースなどにご利用いただけます。 -
Google Cloud UPDATESセッション
弊社のエンジニアがある程度のまとまったタイミングでアップデートを開設するオンライン セッションになります。情報の内容としては細かくわかりやすいものになっていますが、実施タイミングが上述したものと比較すると遅くなりますので、一定の間隔(3ヶ月)で情報をまとめてアップデートしたい方などにはおすすめです。
前置きが長くなりましたが、ここから 2023 年のアップデートに触れていきたいと思います。
パブリック データセットの拡充
Analytics Hub から利用できるパブリック データセットは日々拡充されております。
10 月には Google Cloud Blockchain Analytics データアセットを公開しており、リスティング検索画面からご確認いただけるようになりました。
- Google Cloud's Tron Mainnet data
- Google Cloud's Optimism Mainnet data
- Google Cloud's Avalanche Contract Chain data
- Google Cloud's Fantom Opera data
- Google Cloud's Ethereum Mainnet data
- Google Cloud's Arbitrum One Chain data
- Google Cloud's Cronos Mainnet Chain data
また、各企業におけるデータ公開も加速しており、過去の 天気情報の 1km メッシュ データ のデータセットなども Weathernews社 が公開(サンプルは 1 日分のみ)しました。小売業界など天候等の相関分析等に利用されております。
ぜひ皆様も使えそうなデータがないか、探してみてください!
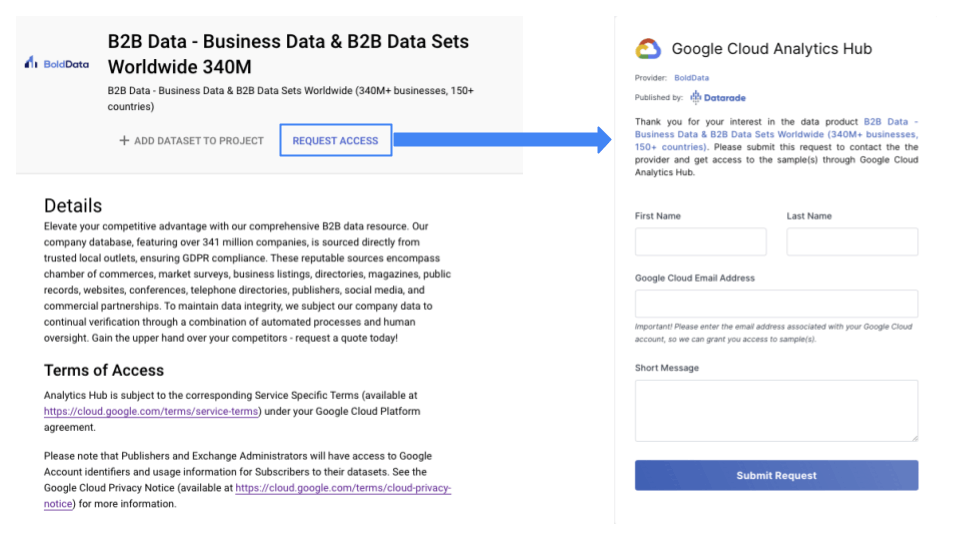
なおデータセットには無償のデータセットと有償のデータセットがあり、有償の場合は以下の図のように提供元にリクエストを送付し、個別に契約後、権限付与される形となります。
Data Clean Rooms(Preview)
2023 年で一番大きかったアップデートだと思います。
Data Clean Rooms の機能を使うことにより、プライバシーを保護しながら機密データを安全に共有、結合、分析が実現できるようになりました。
プライバシーを保護しながら、顧客データと他社データを組み合わせてたいようなニーズにフィットします。
想定ユースケース
-
キャンペーンのプランニングとオーディエンス分析
2 つの当事者(販売者と購入者など)がファーストパーティ データを組み合わせて、プライバシーを重視した方法でデータ拡充を改善できるようにします。 -
測定とアトリビューション
顧客とメディアのパフォーマンス データを照合することで、マーケティング活動の効果を詳細に把握し、十分な情報に基づくビジネス上の意思決定を行うことができます。 -
アクティベーション
顧客データと他社のデータを組み合わせて顧客に対する理解を深め、セグメンテーション機能の向上と効果的なメディア アクティベーションを可能にします。 -
小売、日用品(CPG)
小売業者の POS データと日用品企業のマーケティング データを組み合わせることで、マーケティング活動とプロモーション活動を最適化します。 -
金融サービス
他の金融機関や政府機関の機密データを組み合わせて、不正行為の検出を改善します。複数の銀行の顧客データを集計して、信用リスクのスコアリングを構築します。 -
医療
医師と製薬研究者の間でデータを共有すると、患者に対する治療の効果を把握できます。 -
サプライ チェーン、物流、輸送
サプライヤーとマーケターからのデータを組み合わせて、ライフサイクル全体を通じた商品のパフォーマンスの全体像を把握します。
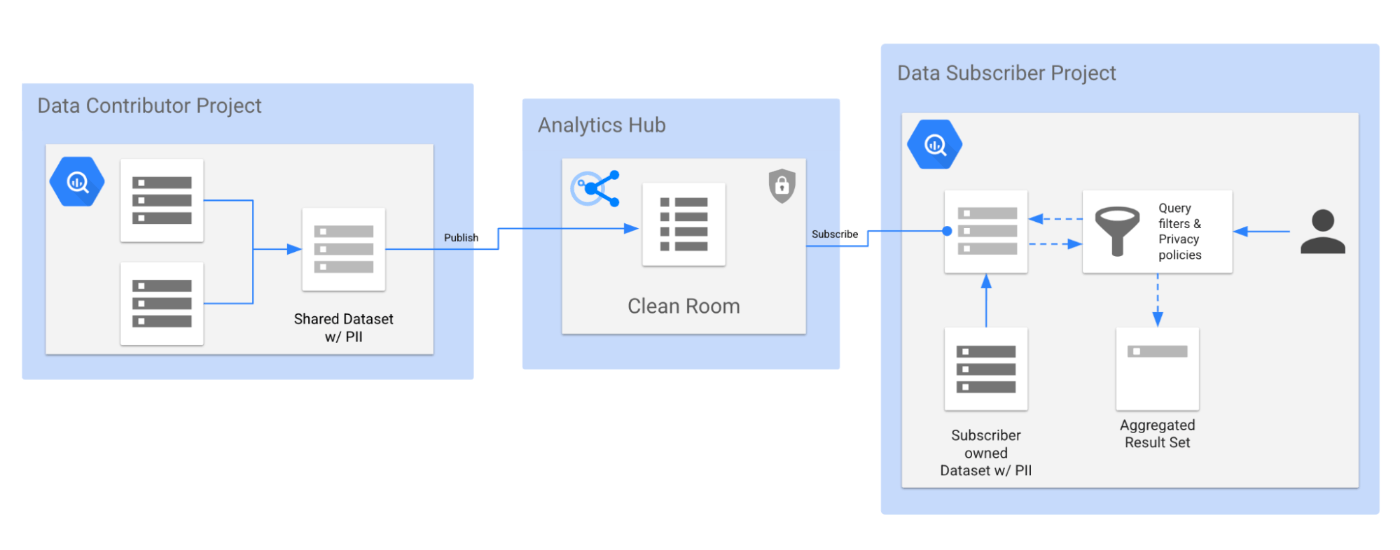
アーキテクチャ
Data Clean Rooms はデータ共有という特性上、Analytics Hub の仕組みの上に構築されております。
Data Clean Rooms という安全に分析ができる箱を作り、そこにデータを投入できる人、データを使って分析できる人、といった形で権限を与えて管理する形となります。
実際に触ってみた記事はパートナー企業が post してくれているものがございましたらので、そちらをご覧ください。
プライバシー ポリシー
Data Clean Rooms で併用する仕組みがこのプライバシー ポリシーというものになります。
プライバシー ポリシーは BigQuery にて プライバシーを重視した分析を可能とする仕組み です。
例えば、先の医療系のユースケースの場合、各医療機関で共同の研究を行うため関連するデータを出し合いますが、患者様の詳細情報などを他社に知られたくないシチュエーションなどが想定されます。
通常のテーブルやビューを共有した場合、全項目を集計なしで抽出すると、当然ですがデータをマスキングをしていない場合は顧客情報(顧客名や性別、ID等)が他社に見えてしまいます。
このようなケースにおいて、プライバシー ポリシーを設定するとサポートされた集計関数でのみ検索を行うよう制御をかけることができます。利用できる集計関数は こちら をご確認ください。
やってみる
挙動を少し確認してみましょう。
ドキュメントに良いサンプルが掲載されていたので、それを実際に試してみます。
まずはテーブルを作ります。
CREATE OR REPLACE TABLE mydataset.results_exam AS (
SELECT "Hansen" AS last_name, "P91" AS test_id, 510 AS test_score UNION ALL
SELECT "Wang", "U25", 500 UNION ALL
SELECT "Wang", "C83", 520 UNION ALL
SELECT "Wang", "U25", 460 UNION ALL
SELECT "Hansen", "C83", 420 UNION ALL
SELECT "Hansen", "C83", 560 UNION ALL
SELECT "Devi", "U25", 580 UNION ALL
SELECT "Devi", "P91", 480 UNION ALL
SELECT "Ivanov", "U25", 490 UNION ALL
SELECT "Ivanov", "P91", 540 UNION ALL
SELECT "Silva", "U25", 550);
/*--results
+-----------+---------+------------+
| last_name | test_id | test_score |
+-----------+---------+------------+
| Wang | C83 | 520 |
| Hansen | C83 | 560 |
| Hansen | C83 | 420 |
| Devi | P91 | 480 |
| Hansen | P91 | 510 |
| Ivanov | P91 | 540 |
| Devi | U25 | 580 |
| Silva | U25 | 550 |
| Ivanov | U25 | 490 |
| Wang | U25 | 500 |
| Wang | U25 | 460 |
+-----------+---------+------------+
*/
次に データ クリーンルームで公開する view を作成します。
本来であれば公開するデータセットを先に作成しますが、そこは割愛します。
CREATE OR REPLACE VIEW clean_test_tokyo.results_exam_view
OPTIONS(
privacy_policy= '{"aggregation_threshold_policy": {"threshold": 3, "privacy_unit_columns": "last_name"}}'
)
AS ( SELECT * FROM mydataset.results_exam );
これでプライバシー ポリシーを適用した view が作成されました。
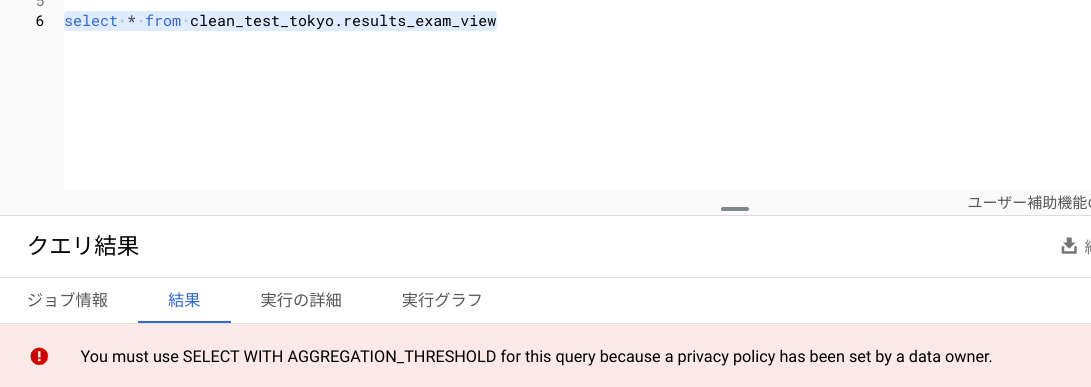
試しにクエリしてみます。
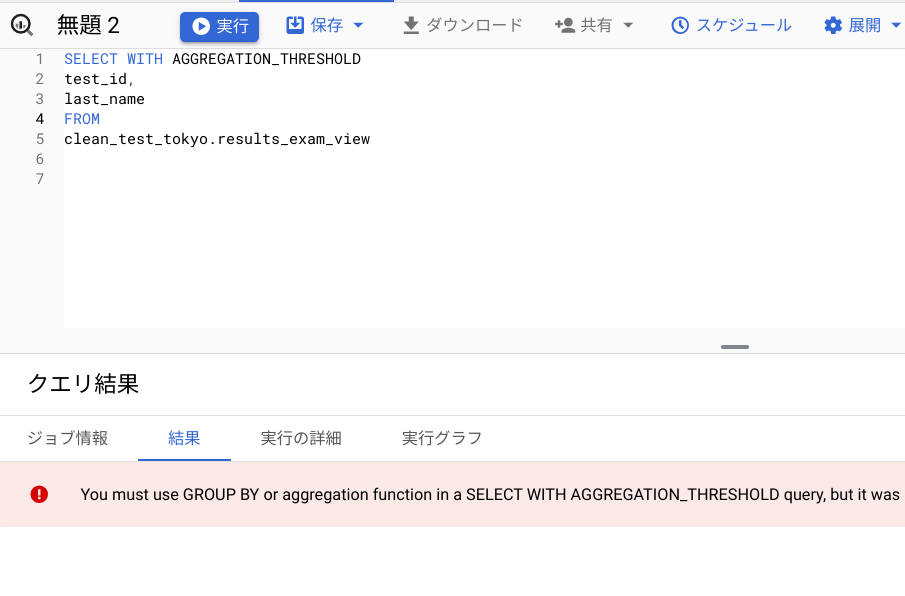
プライバシー ポリシーを適用した view を検索する場合、WITH AGGREGATION_THRESHOLD句が必要となります。
これを指定しないと以下のようにエラーとなります。
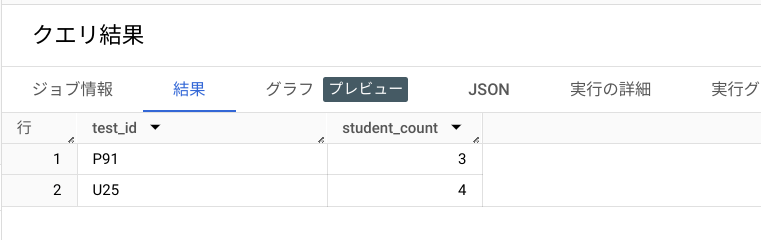
正しいクエリを投げると、thresholdで指定した 3 以上の合計値になる行のみ出力されている事がわかります。(test_id:C83 は Hansen と Hansen の 2 になるので、しきい値以下となり、表示されません)
ちなみに集計関数を使わないで実行しようとすると、以下のように怒られます。
サブスクリプションの管理(Preview)
サブスクリプションの管理がより柔軟になりました。
サブスクライバー側にて API コマンドをコールすることによって、特定のプロジェクト、リージョンにおけるサブスクリプションの一覧を取得することができます。
※一部マスクしてます。
{
"subscriptions": [
{
"name": "projects/XXXXXXX/locations/asia-northeast1/subscriptions/sub__1853548bde9_1702733806033",
"creationTime": "2023-12-16T13:36:47.437890633Z",
"lastModifyTime": "2023-12-16T13:36:47.437890633Z",
"organizationId": "YYYYYYYYYY",
"listing": "projects/ZZZZZZZ/locations/asia-northeast1/dataExchanges/a_185354332fa/listings/_1853548bde9",
"state": "STATE_ACTIVE",
"linkedDatasetMap": {
"projects/ZZZZZZZ/locations/asia-northeast1/dataExchanges/a_185354332fa/listings/_1853548bde9": {
"linkedDataset": "projects/XXXXXXX/datasets/tanawari_data"
}
},
"subscriberContact": "AAAAAAAAA",
"organizationDisplayName": "BBBBBBBBB"
}
]
}
パブリッシャー側からもサブスクリプションの管理ができ、所定のサブスクリプションを削除することが可能です。
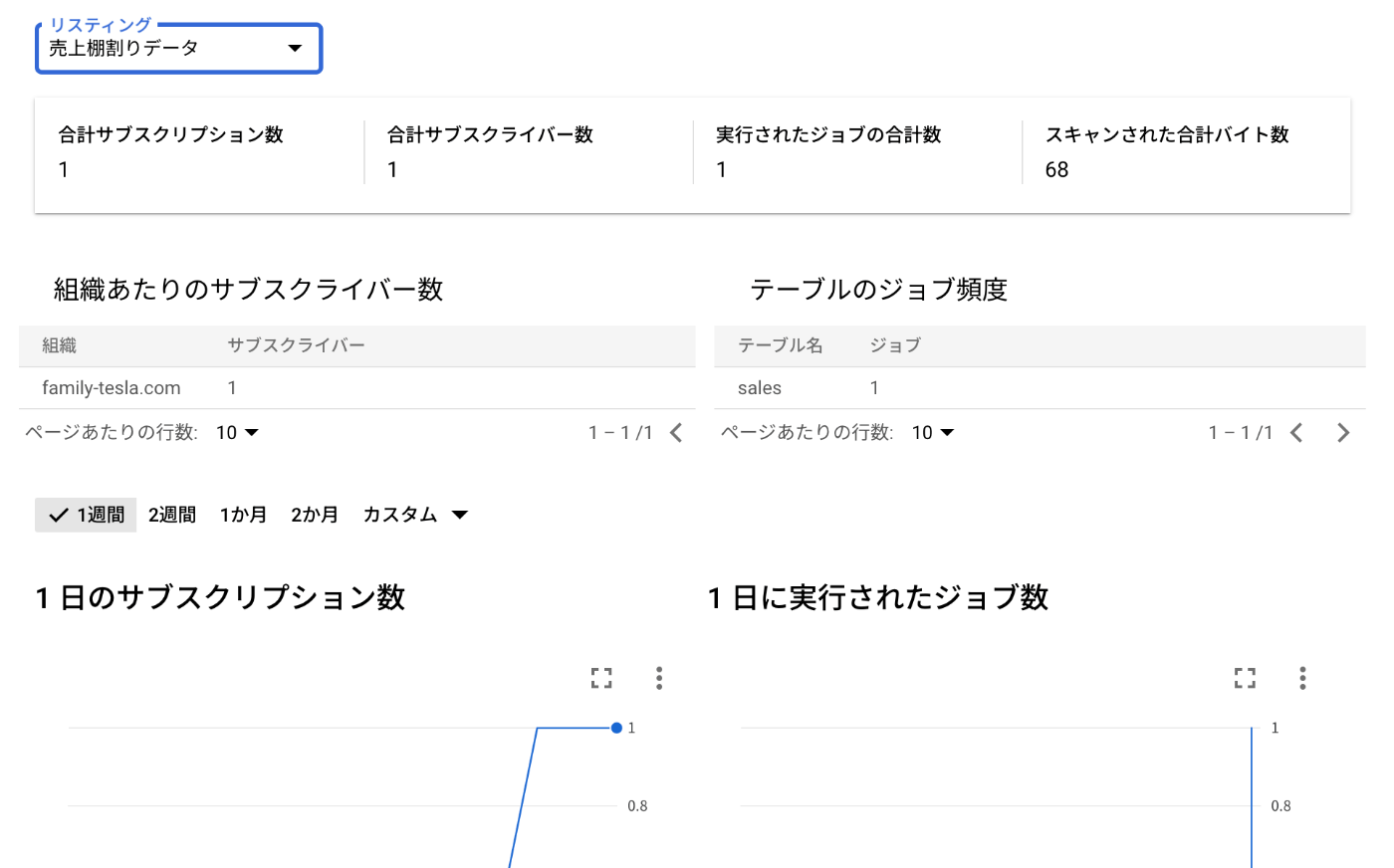
使用状況のモニタリング
これは結構大きいアップデートになりますが、パブリッシャー側から公開しているリスティングの使用常用を確認できるようになりました。
これにより、サブスクリプション数だけでなく、サブスクライバー数やどの程度ジョブで読み込まれているかなどを確認することができ、より柔軟に利用状況を分析できるようになります。
特に商用データ セットの場合、売り上げ予測を行う上で、非常に重要な情報です。
Analytics Hub 画面で表示される ダッシュボード を利用するか、INFORMATION_SCHEMA.SHARED_DATASET_USAGE ビュー を参照し、SQL でより条件を絞ってデータを取得いただくことも可能です。
Egress データ制御(Preview)
こちらもデータ共有の際に課題となる、データの二次利用を防ぐための機能となります。
公開したデータをコピーやエクスポートし、二次利用された場合、データ公開側も安心してデータを共有することができません。
上述した Data Clean Rooms を利用する場合は共有データセットの方は強制的に有効になります。(クエリは任意)
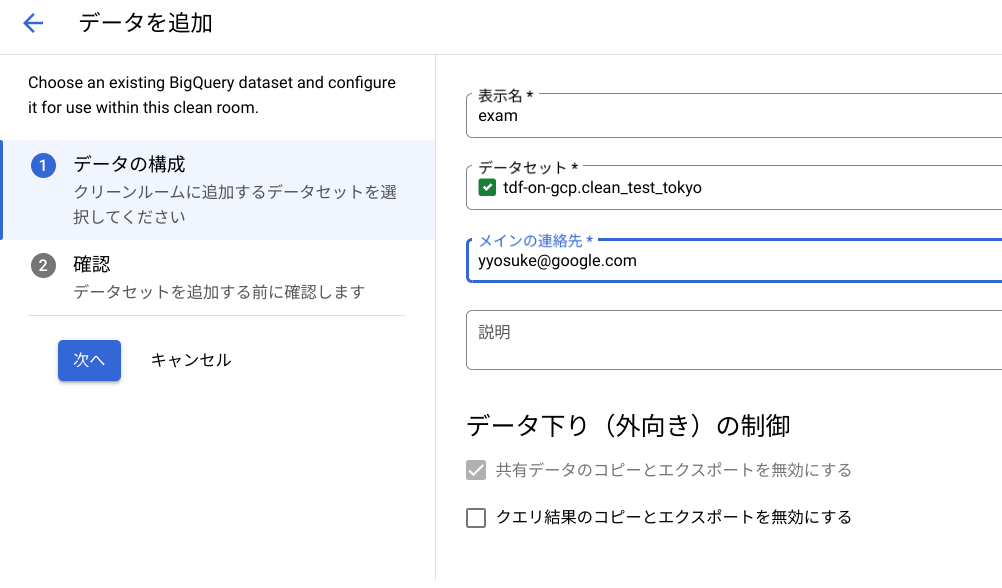
当該機能を利用することにより、共有データセットやクエリ結果に関するコピーやエクスポートに対して制限をかけることができます。
有効化すると 「結果を保存」がグレーアウト され、実行できないようになります。

「コピー」リンクが表示されなく なります。

まとめ
今回の記事では組織間のデータ共有を容易にするデータシェアリング サービスである Analytics Hub について、2023 年のアップデートを中心にご紹介しました。データ共有の観点では非常に良いサービスですし、今後も機能拡張していきますので、ぜひ活用いただければと思います。
また Google Cloud のユーザコミュニティである Jagu'e'r においてデータ利活用分科会というユーザ様・パートナー様が主体となってデータの活用に関して議論するコミュニティがございます。
興味がある場合は是非 こちら から新規会員登録いただいたのち、データ利活用分科会への応募 をお願いします。

Discussion