本記事は Google Cloud Japan Advent Calendar 2022 の 通常版 22 日目の記事です。
皆様、いかがお過ごしでしょうか?
Google Cloud パートナーエンジニアの山中です。
本記事では Google Cloud Next'22 で一般利用(GA)としてアナウンスされました Analytics Hub を用いたデータ共有方法についてご紹介します。
Analytics Hub とは
Analytics Hub は組織間でデータを効率よく安全に共有可能とする BigQuery を基盤としたデータシェアリング サービスです。データを共有することに主眼をおいたサービスとなっており、例えばグループ会社間でのデータ共有やオープンデータの公開などのユースケースに適用できます。
Analytics Hubの 仕組み
Analytics Hub の仕組みは非常にシンプルで、Publisher(データ提供したい組織)とSubscriber(データを利用したい組織)という 2 つのアクターを繋ぐ役割を担います。
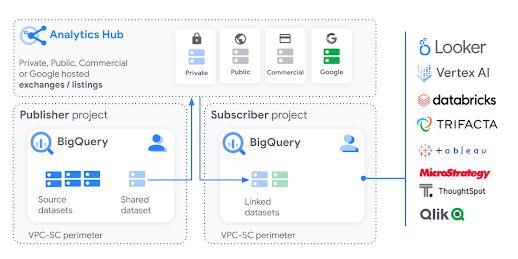
分かりやすくするため、仮の事例に例えて説明したいと思います。
<事例>
スーパー A は各メーカーから仕入れた食品を販売しています。今回、売り上げを最適化するために商品の売り上げ情報と棚割りの情報を各メーカーに共有したいと考えています。
各メーカーはそのデータを分析し、他スーパーとの売り上げ差異を踏まえ、地域特性や棚割りの最適化をスーパー A に提案します。
上記の例を踏まえた上で、先ほどの概念を説明すると
-
Publisher
データを提供する側(スーパー A) -
Subscriber
データを利用する側(メーカー)
という形になります。
この「提供したい」「利用したい」という2つを繋ぐ役割を担うのが Analytics Hub になります。
2 つの基本的な概念が分かったところで、もう少し詳細に見ていきます。
以下の図は Publisher と Subscriber の関連を詳細に表している図になります。
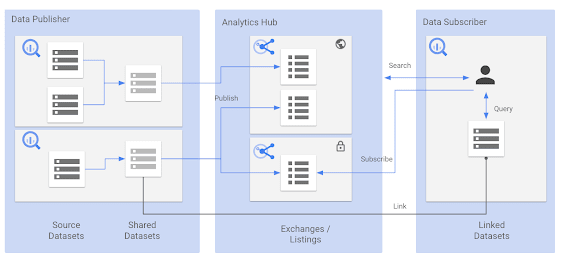
Publisher とSubscriber の間に Analytics Hub があり、構成要素として新しく以下の概念が登場します。
-
Source Datasets
共有したいデータのソースが格納されているデータセット。(スーパーAの売上データが格納されているテーブルそのもの) -
Shared Datasets
共有したいデータが格納されているデータセット。(Source Datasets から共有に不必要なデータを削除・マスキングした承認済みビューなど) -
Exchanges
データ共有の一番上の概念。Listing を複数まとめる箱の様なイメージ。(スーパーA公開データ) -
Listings
Subscriber が検索可能な共有データセット。(売上棚割りデータ) -
Linked Datasets
共有データセットへのシンボリックリンクとして機能する「読み取り専用」のデータセット。(売上・棚割りデータ)
後ほどフローで詳しく説明するので、ざっくり理解してもらえれば結構です。
ここでのポイントは「Linked Datasets」の名称通り、Analaytics Hub でデータ共有を実施しても、データそのものがコピーされることはなく、あくまでデータは Publisher 側に格納されているデータを見に行く点です。
これによりデータのサイロ化を防ぎ、無駄なコストを省くことができます。これらは基盤とする BigQuery がデータを保管するストレージ層とデータを処理するコンピューティング層を分離している仕組みであるため、実現可能なアーキテクチャとなります。
料金
Analytics Hub を利用に関する追加料金はかかりません。BigQuery の料金体系と同様の考えで費用が発生します。例えば今回のケースでは、Publisher(スーパーA)は共有したデータストレージの費用が課金されます。一方で Subscriber(メーカー)はデータストレージの費用はかからず(データ自体は Publisher 側にあるので)、データを利用する際に実行したクエリに対して費用が発生します。これは Subscriber の契約形態(オンデマンド or フラットレート)に基づいて決定されます。
サポートされるリージョン
サポートされるリージョンは 公式ドキュメント に記載がありますが、日本でいうと東京・大阪双方でご利用いただくことが可能です。
制限事項
いくつか制限事項がございますので、一度 公式ドキュメント に目を通していただくことをお勧めします。
よくお問い合わせを受けるのが、顧客管理の暗号鍵(CMEK)を利用することができないのか、という点です。こちらは現在利用できず、Google が管理する暗号化鍵でテーブルやデータセットを作成する必要があります。
CMEKは 2024年1月 のタイミングで利用できるようになりました。
使ってみる
それでは早速、データ共有から利用までの流れを実施してみたいと思います。
データを公開する(Publisher 側)
以下のステップで実施します。
- Shared Datasets を準備する
- Exchanges を作成する
- Listings を作成する

Shared Datasets を準備する
公開用のデータセットを準備します。今回はあくまで流れを把握することを目的としているので、共有したいデータを含んだテーブルそのものを格納します。
-
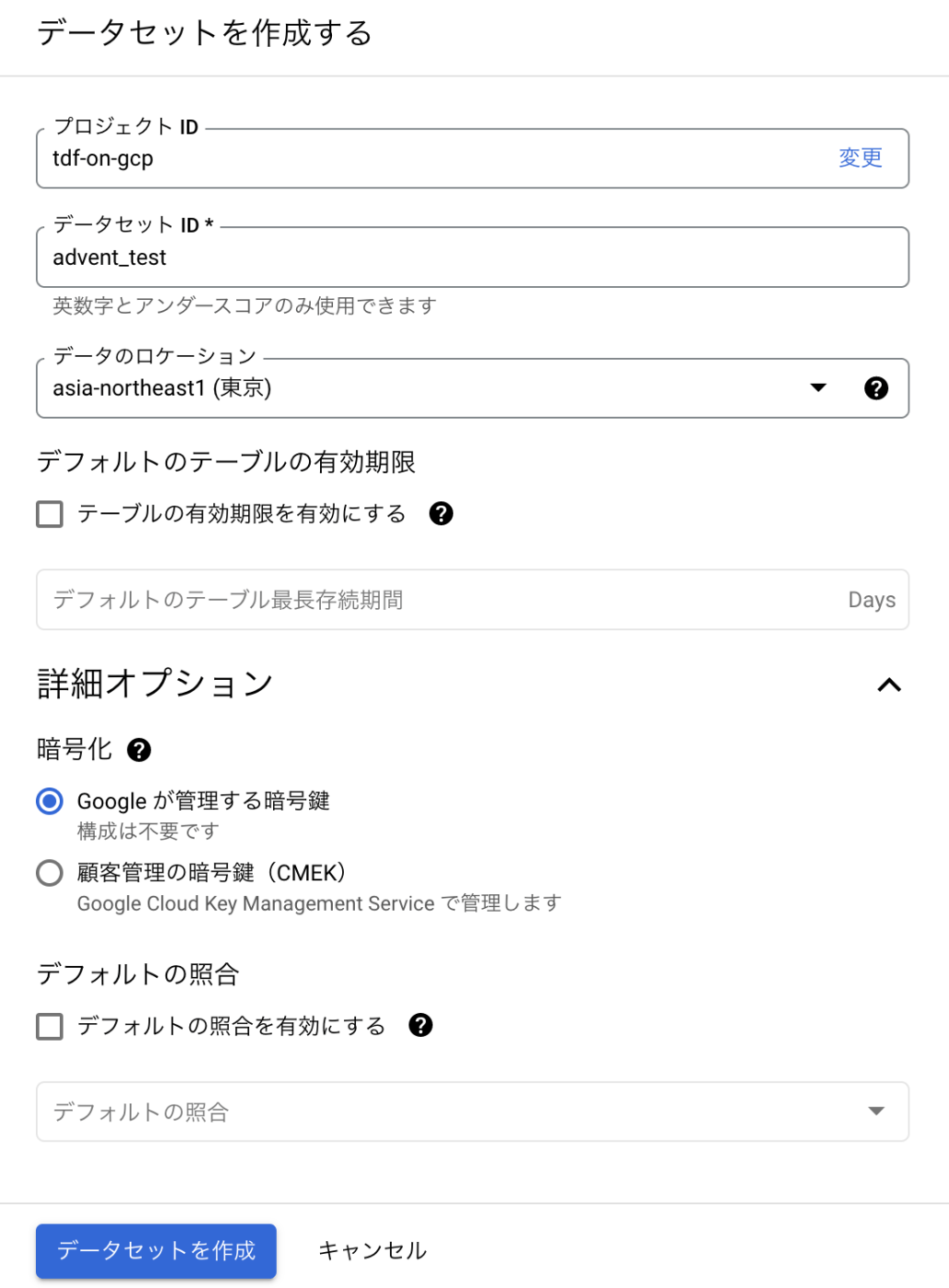
データセットの作成
BigQuery のコンソールで任意のプロジェクトを選択し、データセットを作成します。
「詳細オプション」内にある暗号化方式に「Googleが管理する暗号鍵」が選択されていることを忘れず確認しましょう。(デフォルトですが、念の為)
-
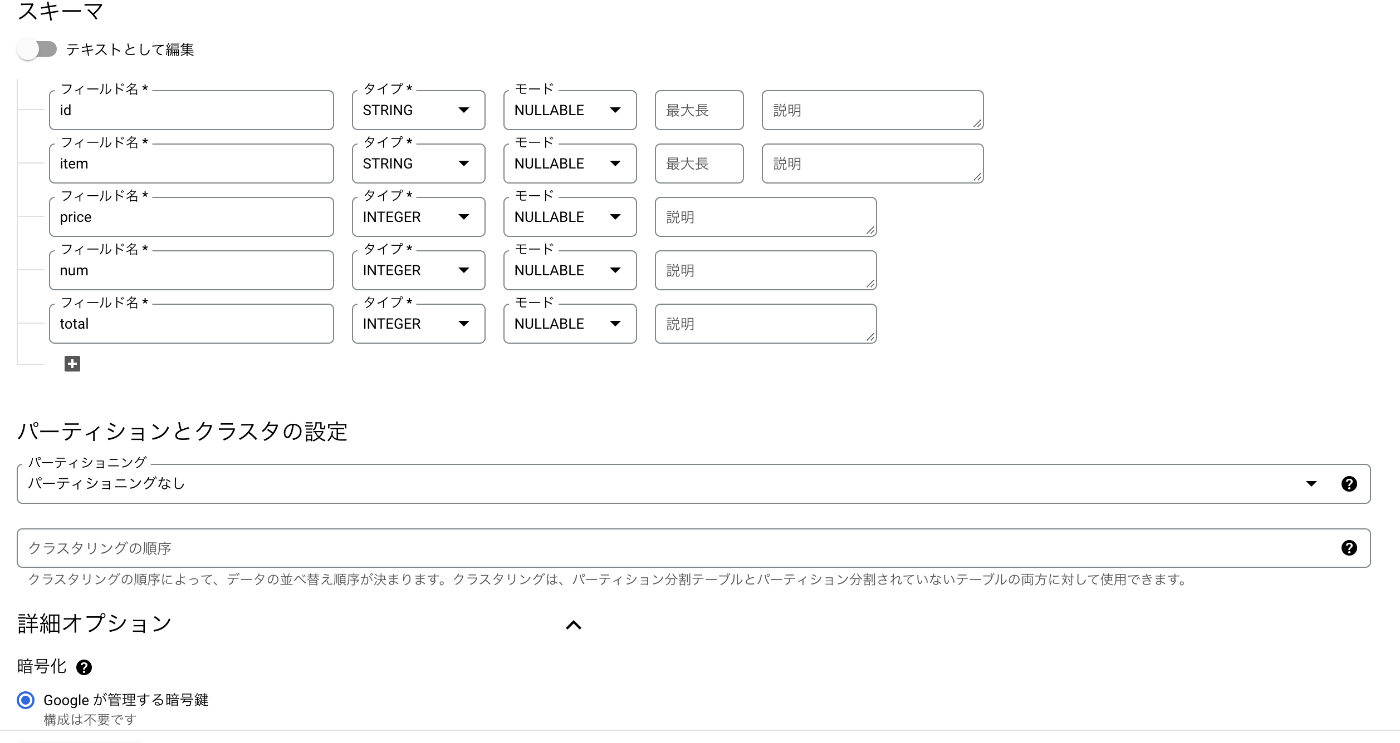
テーブルの作成
データセットの作成が完了したら作成したデータセット内に sales テーブルを作成していきます。
まずは売上テーブルを作成します。

作成したら適当にデータを入れます。
insert into `tdf-on-gcp.advent_test.sales` values("1","lemon", 100, 5, 500)
insert into `tdf-on-gcp.advent_test.sales` values("2","melon", 600, 2, 1200)
続いて棚割りテーブルを作成します。
今回は試しに Cloud Storage にデータを csv で格納して外部テーブルとして登録してみましょう。
まずは csv データを作成します。
id, item, location
1, lemon, L10F
2, melon, Z11T
上記のデータを任意の Cloud Storage に格納して、外部テーブルを作ります。
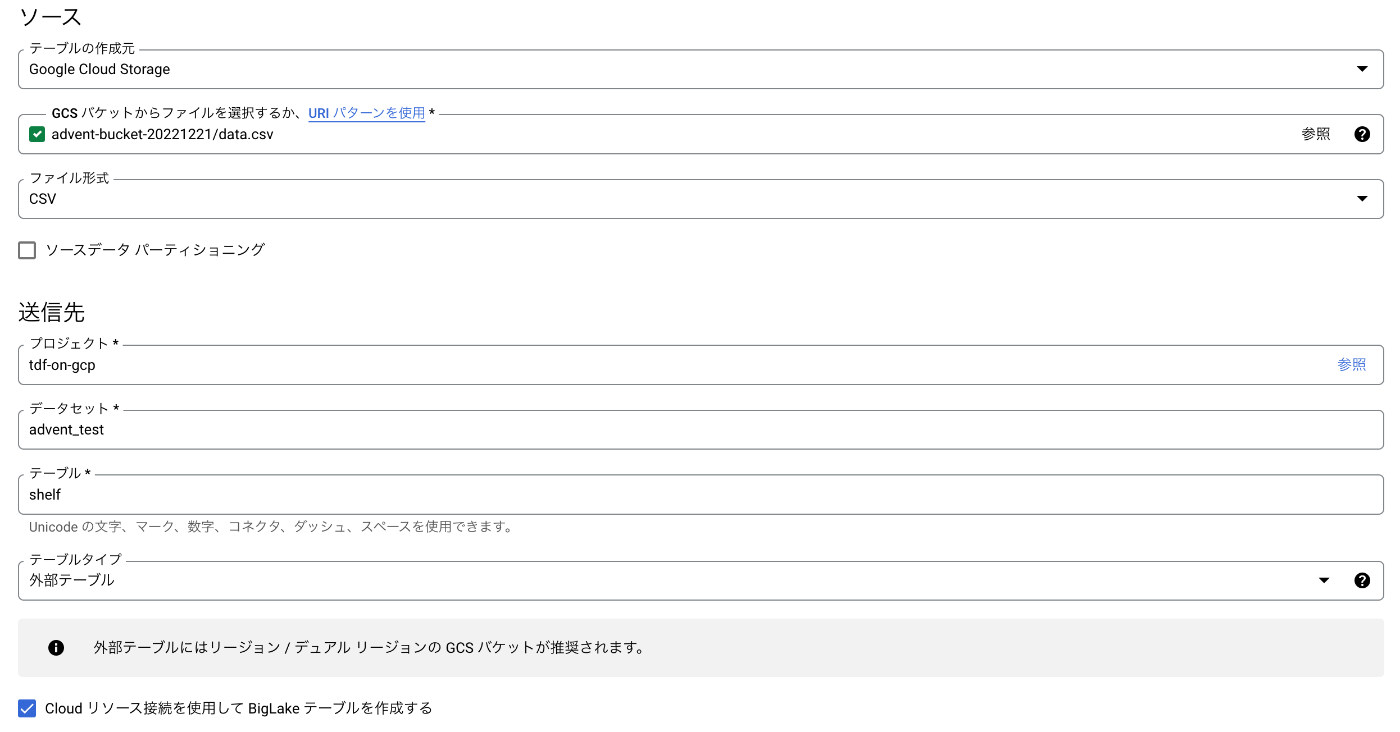
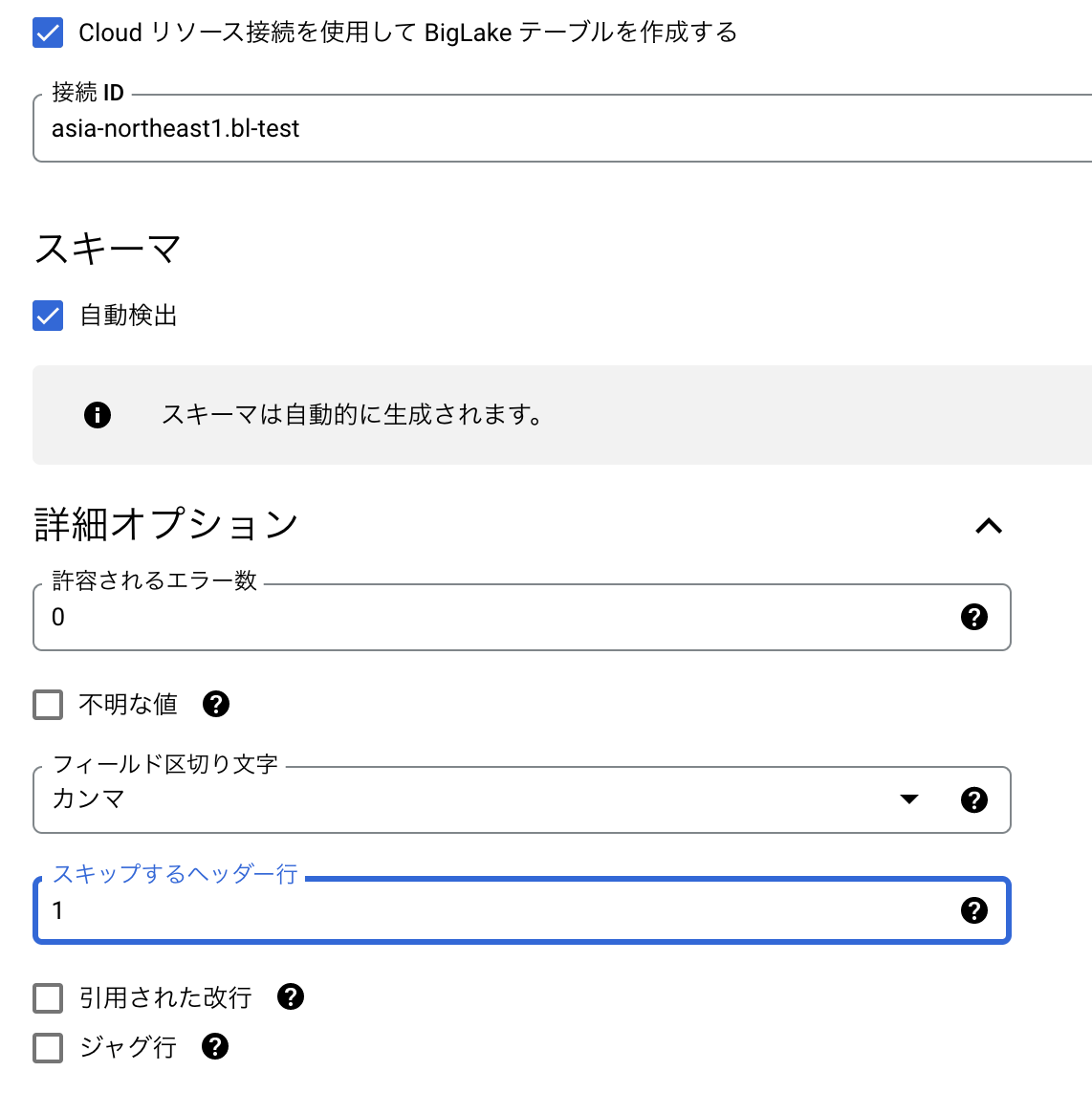
Exchangeを作成する
BigQuery の左ペインから「Analytics Hub」を選択します。

「エクスチェンジの作成」を選択し、必要事項を入力して「エクスチェンジの作成」を選択します。
今回は「スーパーA公開データ」というエクスチェンジを作成しました

Listingを作成する
先ほど作成した「スーパーA公開データ」を選択します。

「リスティングを作成」を選択します。

必要事項を入力していきます。
データセットには先ほど作成したデータセットを指定します。


今回連絡先やドキュメント部分は省略しますが、通常であればここに記載された情報を元にSubscriber はデータの利用可否を検討しますので、データの内容や更新頻度、サンプルクエリなど情報を充実させることをお勧めします。
次に作成した Listing に権限を付与します。
対象の Listing の 3 点アイコンを選択して「権限の設定」を選択します。

右ペインに権限付与の画面が表示されます。
デフォルトだとプライベート公開となり一般のユーザには先ほど登録した Listing は見つけることができません。(検索にも引っかかりません)
一般公開したい場合は「allAuthenticatedUsers」をプリンシパルに追加し、適切な権限を付与することで実現できます。
なお、権限は割と細かく用意されており、サブスクライブができる権限や検索のみできる権限(サブスクライブしたい場合は別途申請を上げたい場合など)が用意されています。
詳細な権限については 公式ドキュメント を参考にしてください。
今回は自分自身でサブスクライブするので、特に追加の権限は付与しません。
データを利用する(Subscriber 側)
データの利用はいたってシンプルです。
以下の STEP で実施します。
- 利用したいデータ(Listings)を検索する
- サブスクライブする
- データに接続する

利用したいデータ(Listings)を検索する
Analytics Hub の画面から「リスティングを検索」を選択します。

利用したいデータを検索ボックスに入力して探していきます。
今回は先ほど作った「売上棚割り」データを使います。
なお、一般公開されているデータセットも選択することができ、Google Cloud Public Datasets も選択することができます。例:Google Community Mobility Reoprts

サブスクライブする
対象の Listing を開いたら「+データセットをプロジェクトに追加」を選択します。

選択するとリンク済みデータセット名を指定する画面になります。日本語はNGなので、英名で入力しなおします。

データに接続する
BigQuery の画面に遷移しデータセットを確認すると先ほど追加したリンク済みデータセットが表示されていることがわかります。アイコンもリンクマークがついているので視認性も結構良いです。

これで通常の BigQuery テーブルと同様に扱え、クエリも問題なく実行できます。
繰り返しになりますが、データ自体はコピーされておらず、Publisher 側のデータを見にいっています。

以上で Analytics Hub の操作は完了です。
まとめ
今回の記事では組織間のデータ共有を容易にするデータシェアリング サービスである Analytics Hub についてご紹介しました。データ共有の観点では非常に良いサービスですし、今後も機能拡張していきますので、ぜひ活用いただければと思います。
また Google Cloud のユーザコミュニティである Jagu'e'r においてデータ利活用分科会というユーザ様・パートナー様が主体となってデータの活用に関して議論するコミュニティがございます。
興味がある場合は是非 こちら から新規会員登録いただいたのち、データ利活用分科会への応募 をお願いします。

Discussion