BigQuery のデータクリーンルームに入門しました
はじめに
こんにちは、クラウドエース データ ML ディビジョン所属の工藤です。
クラウドエースの IT エンジニアリングを担うシステム開発部の中で、特にデータ基盤構築・分析基盤構築からデータ分析までを含む一貫したデータ課題の解決を専門とするのがデータ ML ディビジョンです。
データ ML ディビジョンでは活動の一環として、毎週 Google Cloud の新規リリースを調査・発表し、データ領域のプロダクトのキャッチアップをしています。その中でも重要と考えるリリースを本ページ含め記事として公開しています。
今回紹介するリリースは、Data clean rooms(以降、データクリーンルーム)についてです。データクリーンルームは、BigQuery の Analytics Hub に新しく追加された機能になります。データクリーンルームを使うことで、プライバシーを重視した形で BigQuery のデータを組織間で共有できるようになりました。なお、この機能はプレビュー段階になります。
Analytics Hub とは
Analytics Hub は、組織間でデータと分析情報を大規模に共有できる BigQuery を基盤とするデータ交換プラットフォームです。詳細は、公式ドキュメントをご確認ください。
今回紹介するデータクリーンルームは、Analytics Hub に追加された機能になります。
今回のリリースについて
今回ご紹介するのは、2023 年 8 月 29 日付に発表されたリリースの一つであるデータクリーンルームについてです。
該当リリースノート:BigQuery release notes
データクリーンルームとは
データクリーンルームは、プライバシーを重視した組織間のデータ共有を実現する環境のことです。小売店企業の POS データを日用品企業と共有する場合、この環境を利用することで高セキュリティ下でのデータ共有が可能となります。データクリーンルームでは、データのコピー・エクスポート等が制限されるため、情報の安全性が確保されます。
データクリーンルームは、以下の 3 つの役割があります。
-
データクリーンルームのオーナー
データクリーンルームのオーナーは、プロジェクト内の 1 つ以上のデータクリーンルームの権限、可視性、およびメンバーシップを管理するユーザーです。 -
データ投稿者
データ投稿者は、データクリーンルームにデータを公開することができるユーザーです。 -
サブスクライバー
サブスクライバーは、データクリーンルームに公開されているデータにクエリを発行することができるユーザーです。
それぞれの役割で必要な権限は、公式ドキュメントを参照ください。
構成
データクリーンルームには、3 つの役割以外に 6 つの構成要素が存在します。
公式ドキュメントに公開されている図を参考に、構成要素を説明していきます。
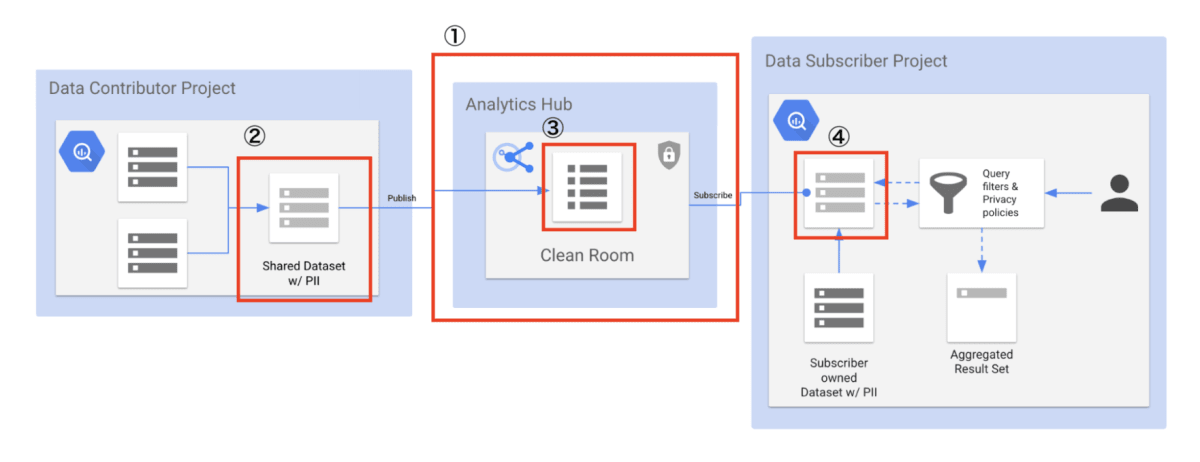
-
Data clean room(上の画像の①)
プライバシーを重視した組織間のデータ共有を実現する環境を指します。 -
Shared datasets(上の画像の②)
共有したいデータが格納されているデータセットを指します。 -
Listings(上の画像の③)
サブスクライバーが購読することができるデータセットを指し、リスティングと呼びます。データクリーンルームに公開されているデータセットがリスティングにあたります。 -
Linked datasets(上の画像の④)
サブスクライバーが自分のプロジェクトに購読したリスティングを指します。この記事ではリンクされたデータセットと呼ぶことにします。サブスクライバーは、このリンクされたデータセットに対してクエリを発行します。 -
Privacy policies
リスティングに含まれるビューに対して設定できるポリシーになります。プライバシーポリシーを使うことで、ビューで参照しているデータに直接アクセスすることを制限できます。データクリーンルームは、Aggregation threshold privacy policy をサポートしており、この機能によりサブスクライバーは集計クエリを用いてのみ、リンクされたデータセットを分析することが可能となります。 -
Data egress controls
このコントロールは、サブスクライバーがクエリ結果をコピーしたりエクスポートすることを制限でき、意図的なデータ流出を防ぐことができるものです。リンクされたデータセット内のデータをコピーしたりエクスポートすることはできなくなっており、クエリ結果のコピーとエクスポートは任意で制限できます。このコントロールは、クリーンルームにリスティングを追加する時に設定できます。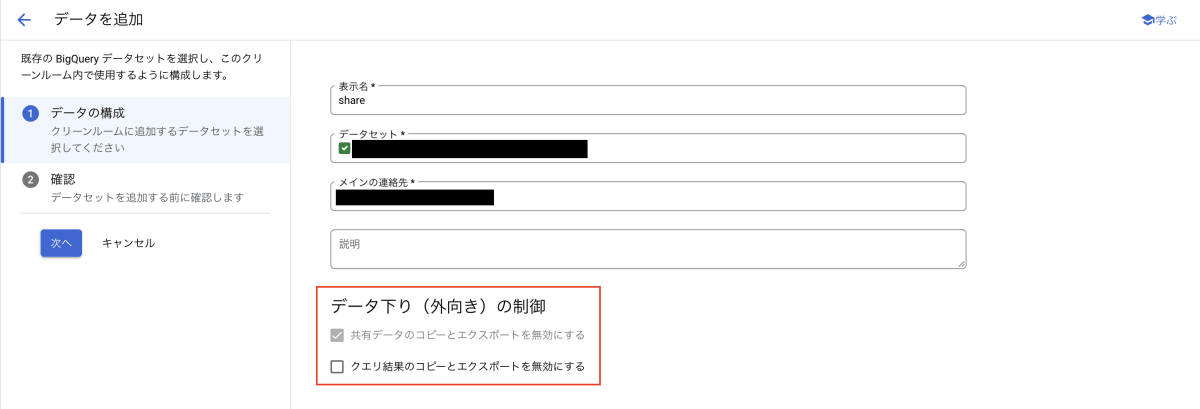
制限
データクリーンルームを利用するときは、以下 3 つの制限事項がありますのでご注意ください。
-
データクリーンルームには Analytics Hub の制限事項が適用されます。詳しくは、公式ドキュメントを参照ください。
-
データクリーンルームを利用できるのは、Analytics Hub がサポートされているリージョンのみになります。
-
データのプライバシー保護を強制するには、共有するデータセットにプライバシーポリシーが設定された承認済みビューのみを含んでいる必要があります。承認済みビュー以外を共有データセットに含めた場合、サブスクライバーはそのデータセット内のデータに直接アクセスできてしまいます。また、テーブルにはプライバシーポリシーを設定することができないため、原則としてテーブルは共有するデータセットに含めないようにしましょう。これらを踏まえると、データクリーンルームを利用して安全にデータを共有するには、データセットを以下のように複数用意する方が良さそうです。
| データセット名 | 用途 |
|---|---|
| データセット A | プライバシーポリシーが設定された承認済みビューを格納する |
| データセット B | データセット A に含まれるビューが参照するデータを格納する |
料金
データ投稿者側のプロジェクトは、データを格納しているストレージ料金が発生します。一方でサブスクライバー側のプロジェクトは、クエリ実行時のコンピュート料金が発生します。
また、サブスクライバー側のプロジェクトは、BigQuery editions の Enterprise Plus edition を設定している必要があります。BigQuery editions については、公式ドキュメントを参照ください。
検証
データクリーンルームのオーナー、データ投稿者、サブスクライバーごとに使ってみます。それぞれの役割でやることは以下のとおりです。
-
データクリーンルームのオーナー
1.1 クリーンルームの作成
-
データ投稿者
2.1 共有するデータの準備
2.2 データの追加
-
サブスクライバー
3.1 データの購読
3.2 クエリの発行
またこの検証では、以下のようにプロジェクトを 2 つ利用します。
| プロジェクト | 用途 |
|---|---|
| プロジェクト A | データクリーンルームの作成、データクリーンルームに共有するデータの作成などを行う。データクリーンルームのオーナーとデータ投稿者の操作で使用する。 |
| プロジェクト B | プロジェクト A のデータクリーンルームのデータを購読する。サブスクライバーの操作で使用する。 |
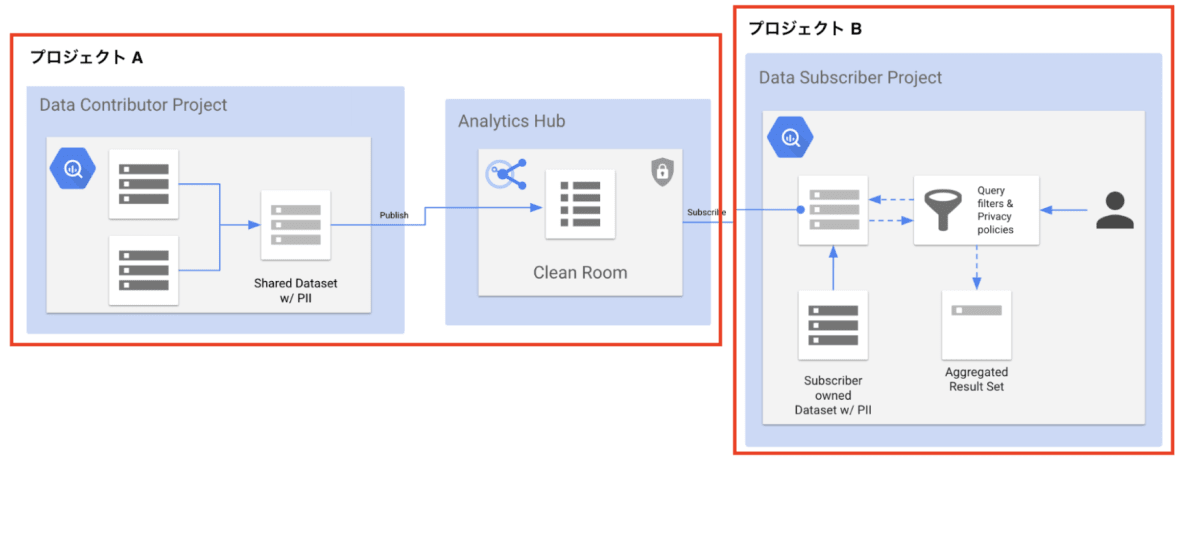
1. データクリーンルームのオーナー
データクリーンルームのオーナーは、クリーンルームの管理とユーザに対する権限の管理を主に行います。以降の操作は、プロジェクト A で行います。
1.1 クリーンルームの作成
それではクリーンルームを作成します。Analytics Hub のページを開き、「データ クリーン ルームを作成(プレビュー)」を押下します。
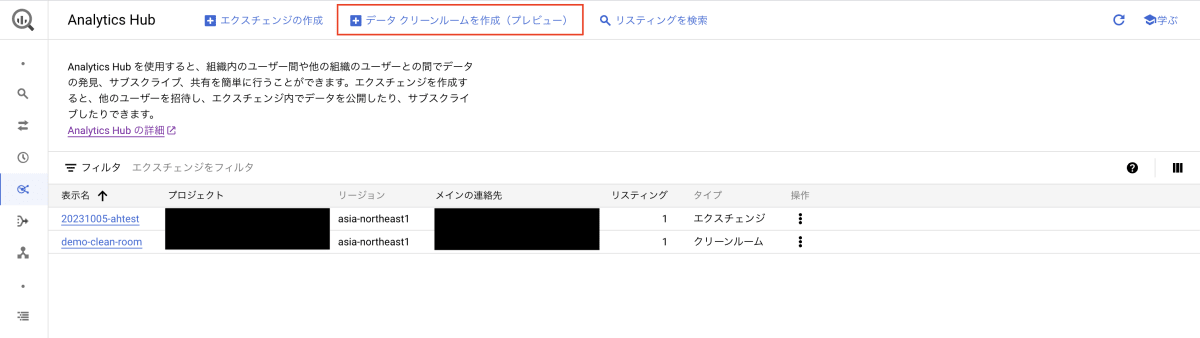
すると、データクリーンルームの作成画面が出てきます。
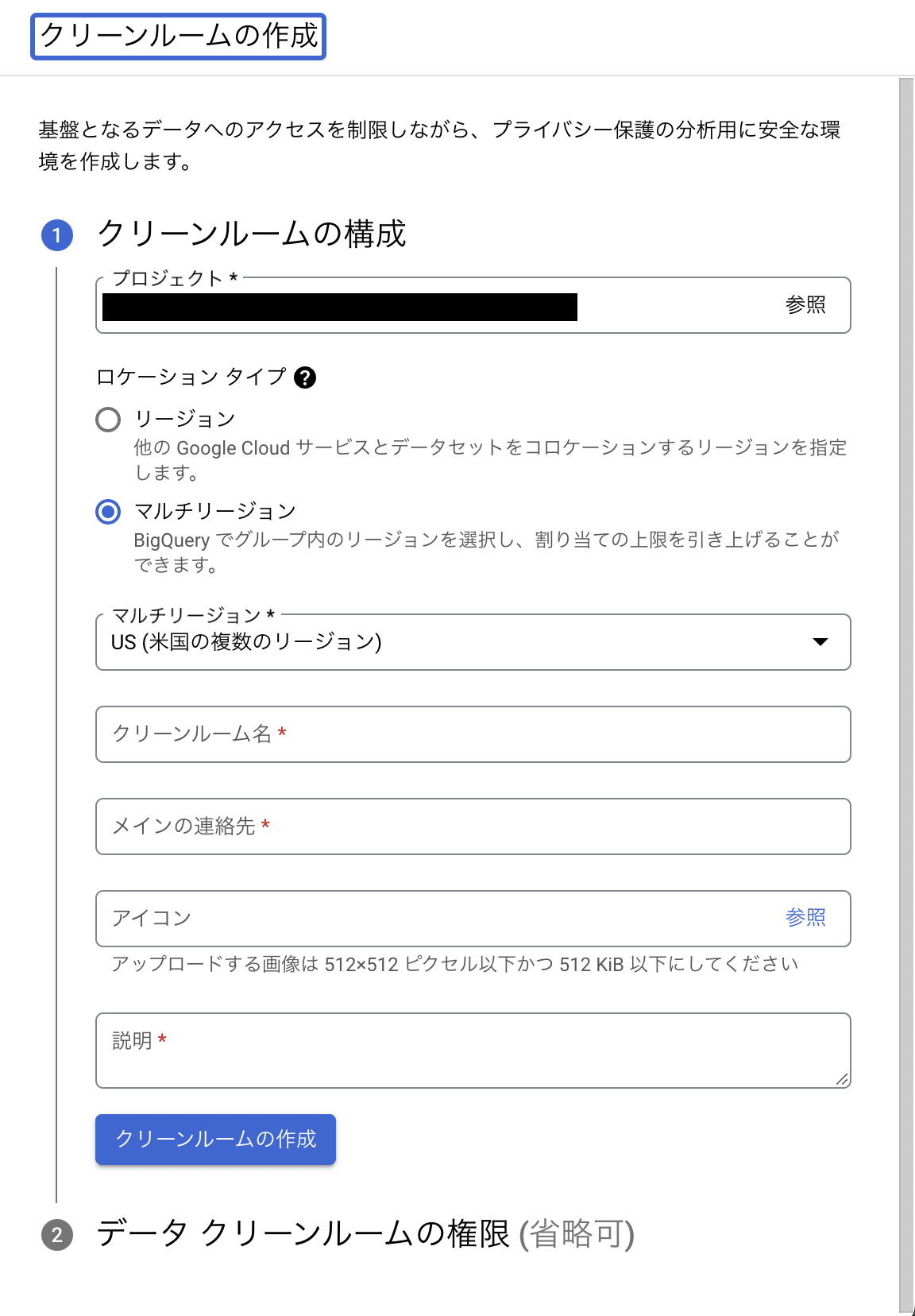
ここで必要な情報を記入し、「クリーンルームの作成」を押下します。記入する情報は以下のとおりです。
| 項目 | 設定値 |
|---|---|
| プロジェクト | クリーンルームを作成するプロジェクト |
| ロケーション タイプ | 使用するロケーション タイプ(今回はリージョンを選択しました) |
| リージョン(ロケーションタイプをリージョンにした場合) | 使用するリージョン |
| クリーンルーム名 | クリーンルームの表示名 |
| メインの連絡先 | メールアドレスなどの連絡先 |
| アイコン | アイコンとして使用する画像ファイル |
| 説明 | 任意のコメント(今回は用途を書きました) |
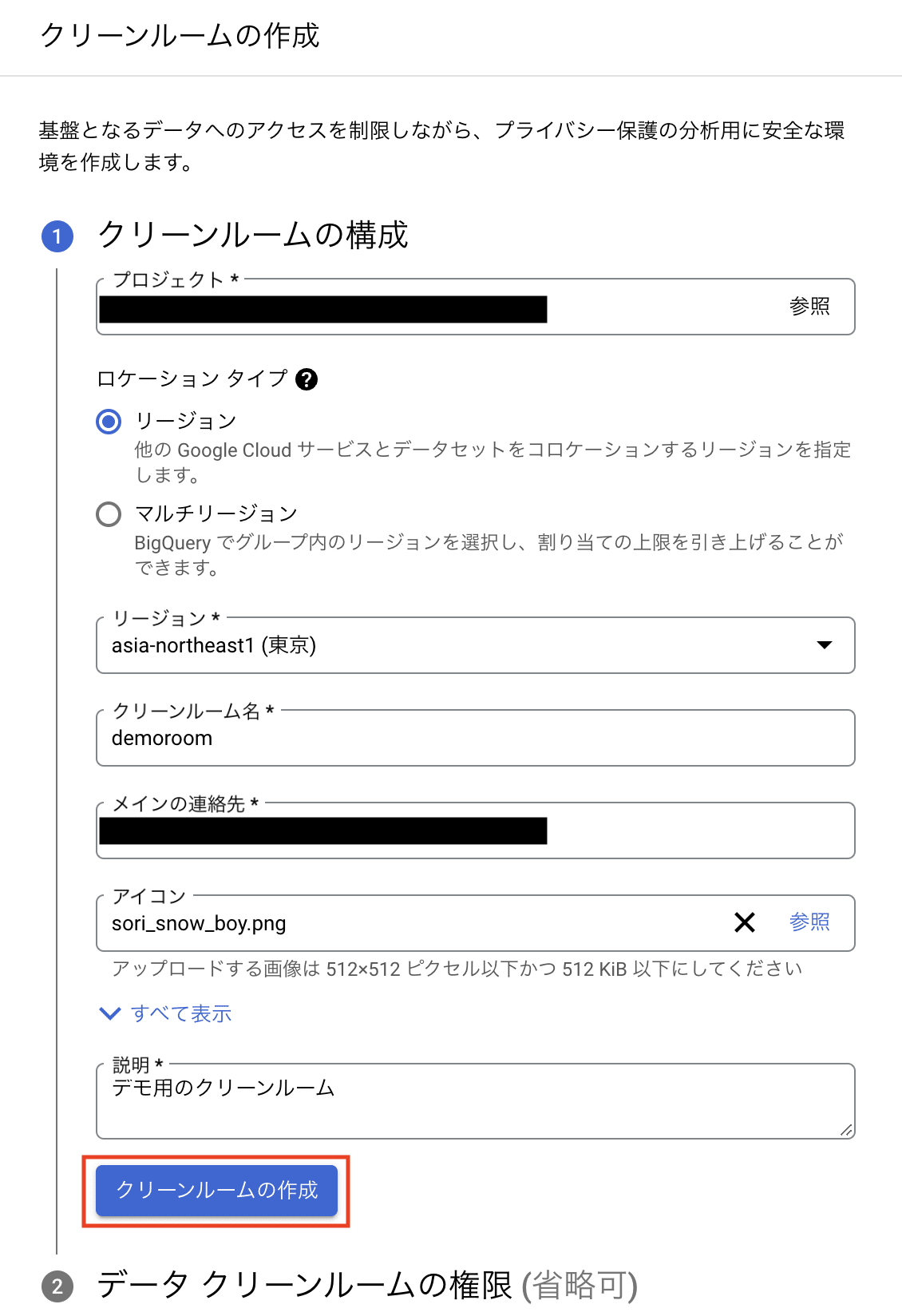
「クリーンルームの作成」を押下すると、「demoroom」という名前のクリーンルームが作成されます。
次に作成するクリーンルームの権限を設定できる画面に遷移します。データクリーンルームのオーナーやデータ投稿者などの権限は、クリーンルームごとに設定します。クリーンルームの作成者はすでにデータクリーンルームのオーナーとして追加されているので、他のユーザと共同で使用する場合は、ここで権限を追加することができます(なお、後からでも権限の設定は可能です)。ここでは「スキップ」を押下します。
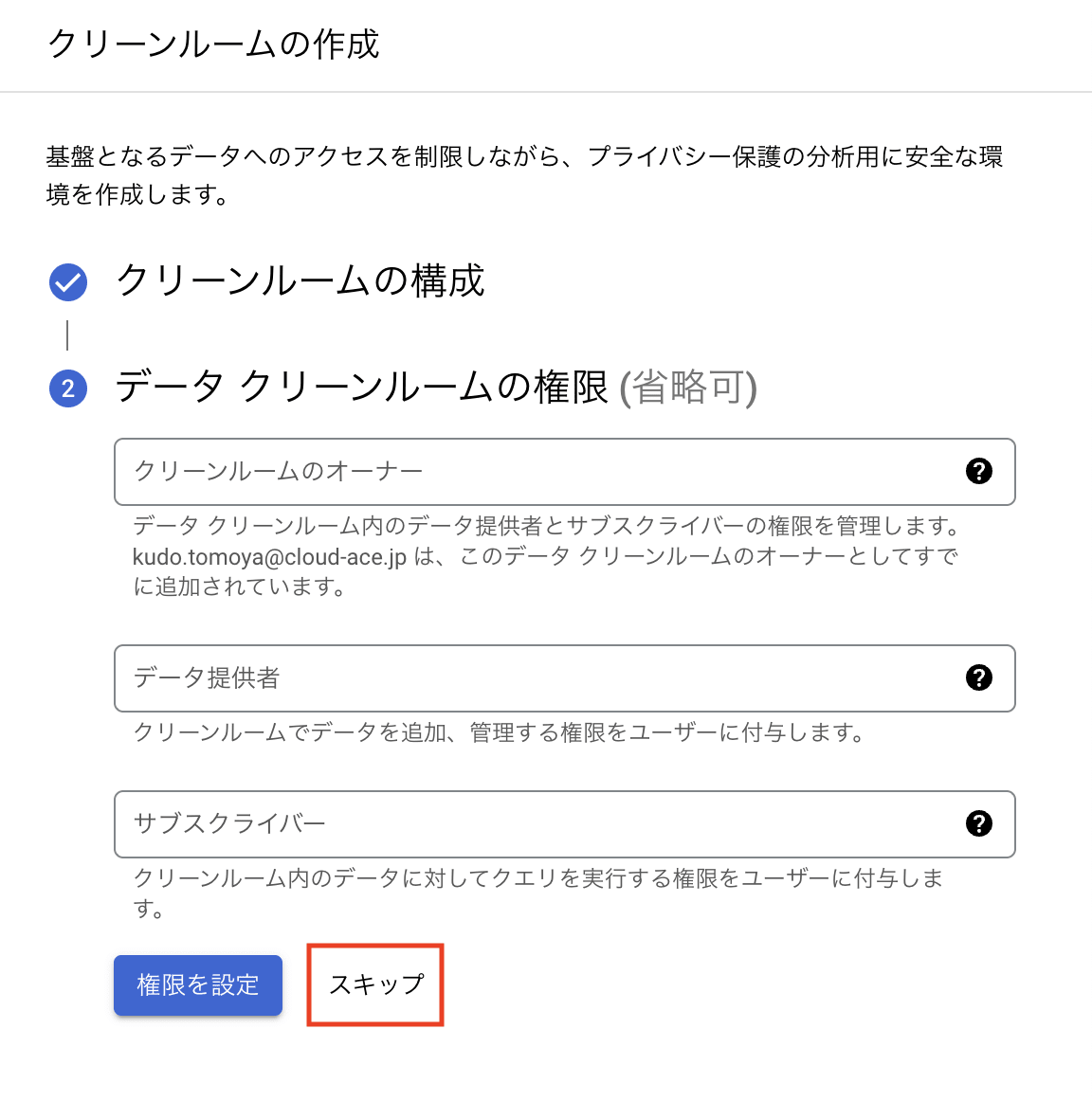
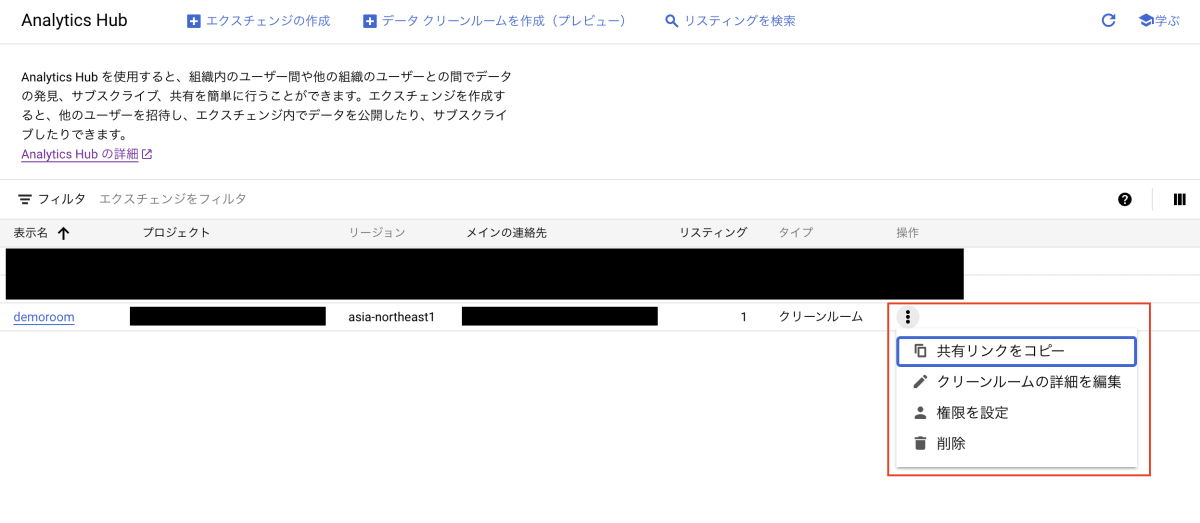
「demoroom」という名前のクリーンルームが作成されていることが確認できます。
三点線を押下すると、クリーンルームの設定を変更できたり、権限の設定ができたりします。
2. データ投稿者
2.1 共有するデータの準備
プロジェクト A にクリーンルームができましたので、次は共有するデータを作成します。共有するデータもプロジェクト A に作成します。今回はデータセットを用途別に 2 つ作成します。
| データセット名 | 用途 |
|---|---|
| dcr_contributor | サブスクライバーに共有するビューを格納する |
| source_dataset | dcr_contributor のビューから参照するデータを格納する |
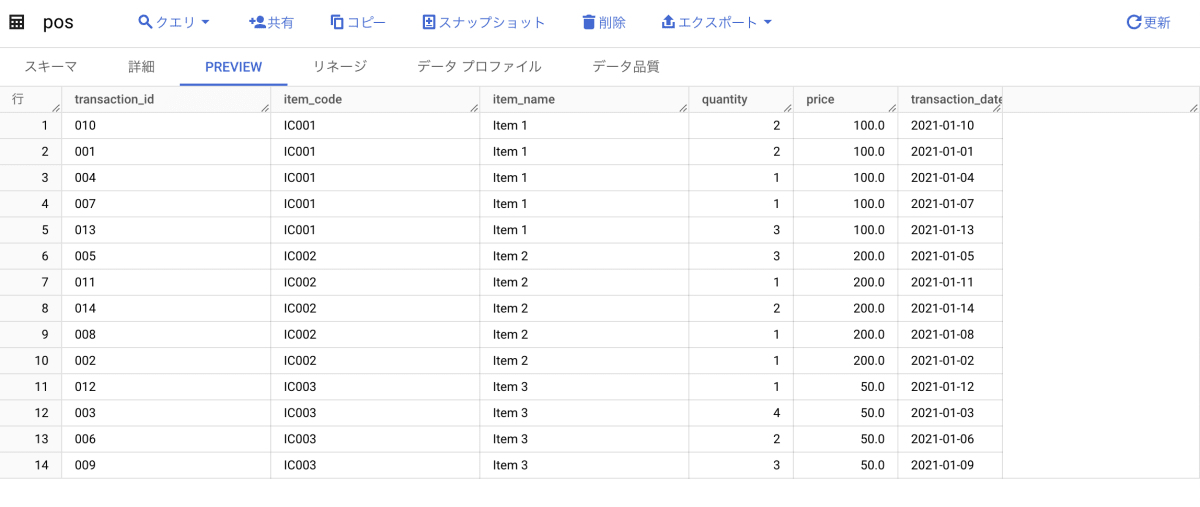
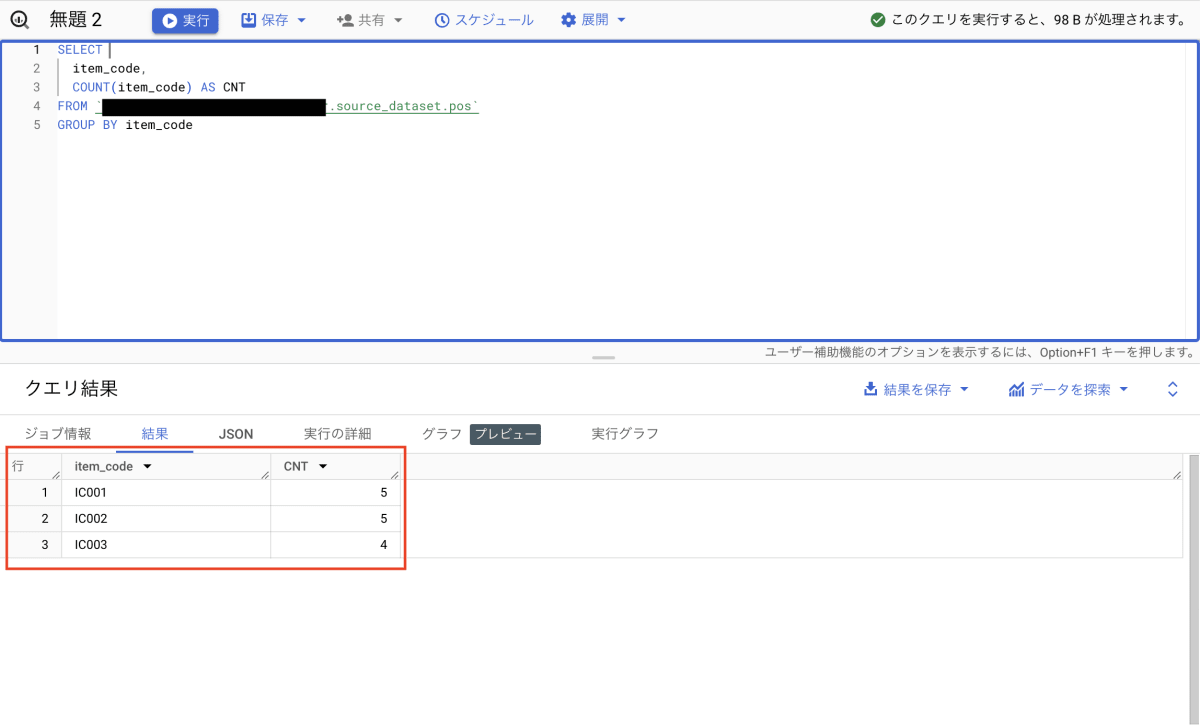
source_dataset データセットに pos という名前のテーブルを作成し、テストデータを挿入します。このとき使用したクエリは省略しますが、テーブルのプレビューは以下のとおりです。
次は以下のクエリで dcr_contributor データセットにクリーンルームで共有するビューを作成します。
CREATE OR REPLACE VIEW `プロジェクトID.dcr_contributor.shared view`
OPTIONS(
privacy_policy= '{"aggregation_threshold_policy": {"threshold": 3, "privacy_unit_columns": "item_code"}}'
)
AS (SELECT * FROM `プロジェクトID.source_dataset.pos`);
上記のクエリは、公式ドキュメントを参考に作成しました。
上記のクエリで作成したビューには、プライバシーポリシーを設定しています。プライバシーポリシーの中では、 Aggregation threshold privacy policy を設定しています。Aggregation threshold privacy policy の項目の内容を記載します。
| 項目 | 内容 | 設定値 |
|---|---|---|
| threshold | クエリ結果の各行に必要なプライバシーユニットの最小数 | 3 |
| privacy_unit_columns | プライバシーユニット列(1 列のみ指定可能) | item_code |
例えば、item_code が "A" と "B" のデータがあり、"A" のデータが 3 行、"B" のデータが 4 行ある場合、"B" のデータは集計対象になりますが、"A" のデータは集計対象にはなりません。
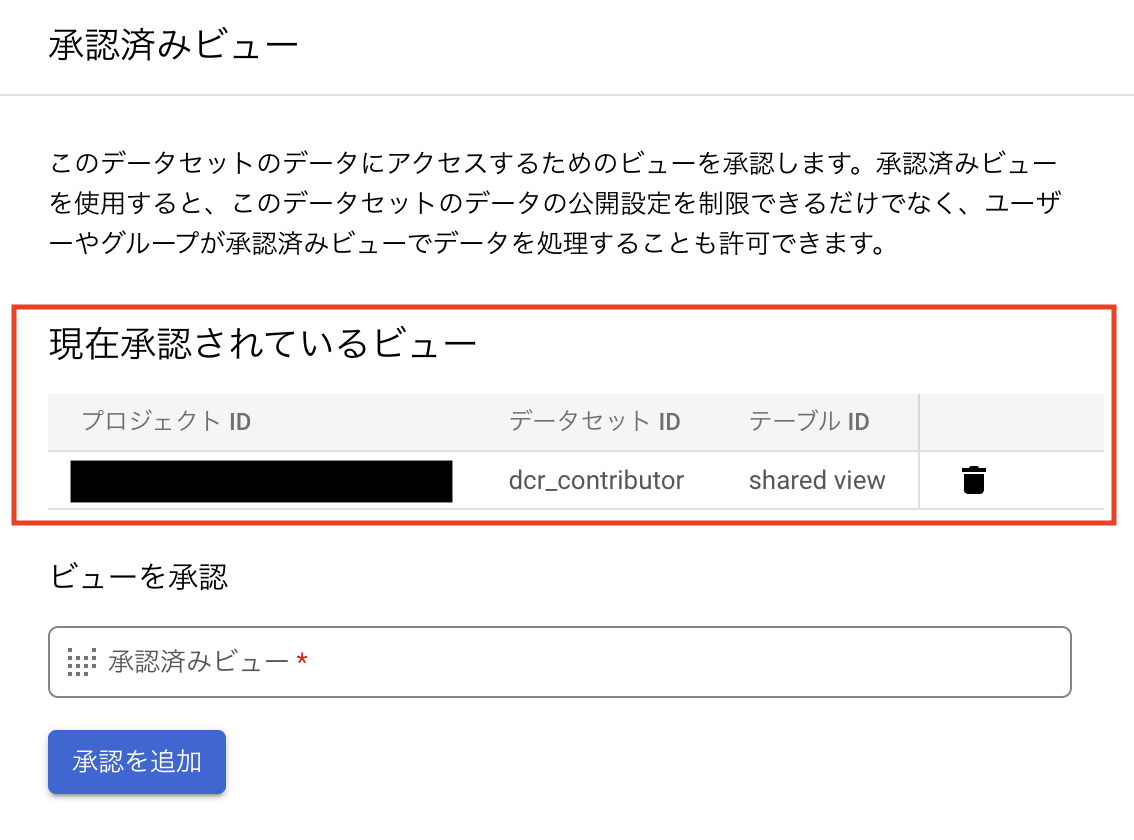
続いて先ほど作成したビューを承認済みビューに設定します。承認済みビューの設定方法は、公式ドキュメントを参照ください。
承認済みビューを設定すると、以下のようになります。
2.2 データの追加
データの準備が終わったので、クリーンルームにデータを追加します。Analytics Hub を開き、先ほど作成した demoroom というクリーンルームを選択します。
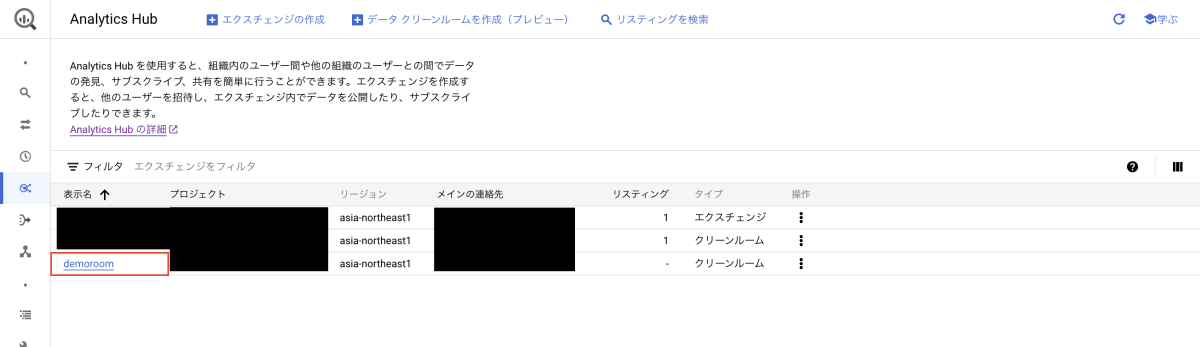
画面上部の「データを追加」を押下します。
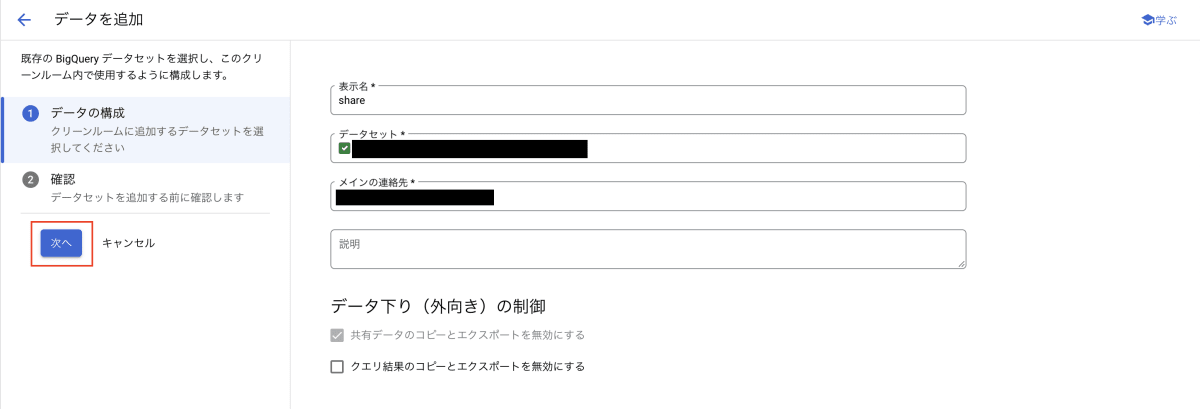
追加するデータを設定できるので、表示名や共有するデータセットを設定します。今回は、表示名を「share」とし、データセットは先ほど作成したビューが含まれている「dcr_contributor」を、メインの連絡先はクリーンルーム作成時と同じものを設定しました。必要な情報を記入したら、「次へ」を押下します。
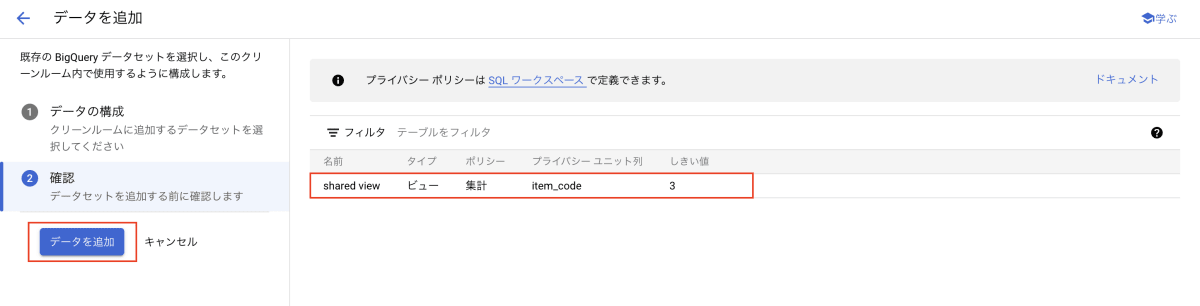
確認画面に遷移し、データセットに含まれているビューが表示されます。「データを追加」を押下することで、クリーンルームにデータが追加されます。
3 サブスクライバー
最後にサブスクライバーとして、クリーンルームで共有されたデータにクエリを発行したいと思います。サブスクライバーの操作は、プロジェクト B で行います。
3.1 データの購読
BigQuery を開き、エクスプローラ ペインの「+ 追加」を押下します。
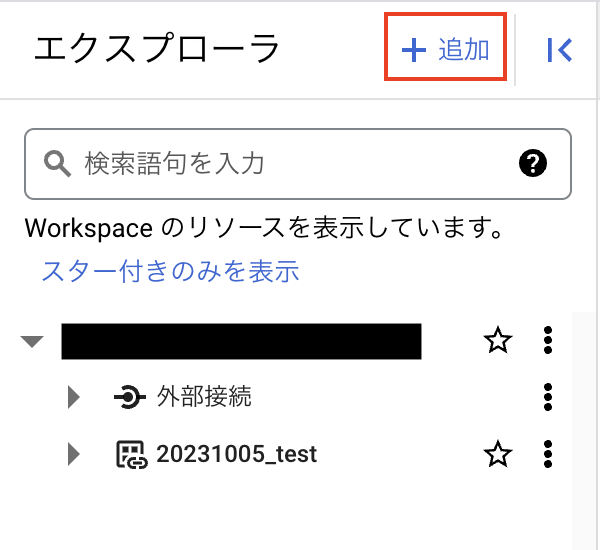
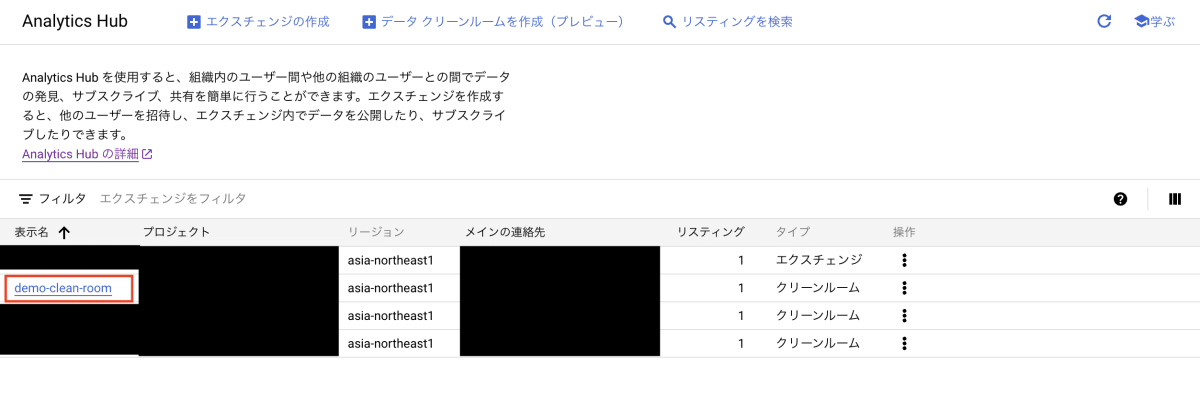
追加するデータを選べる画面に遷移するので、「Analytics Hub」を選択します。
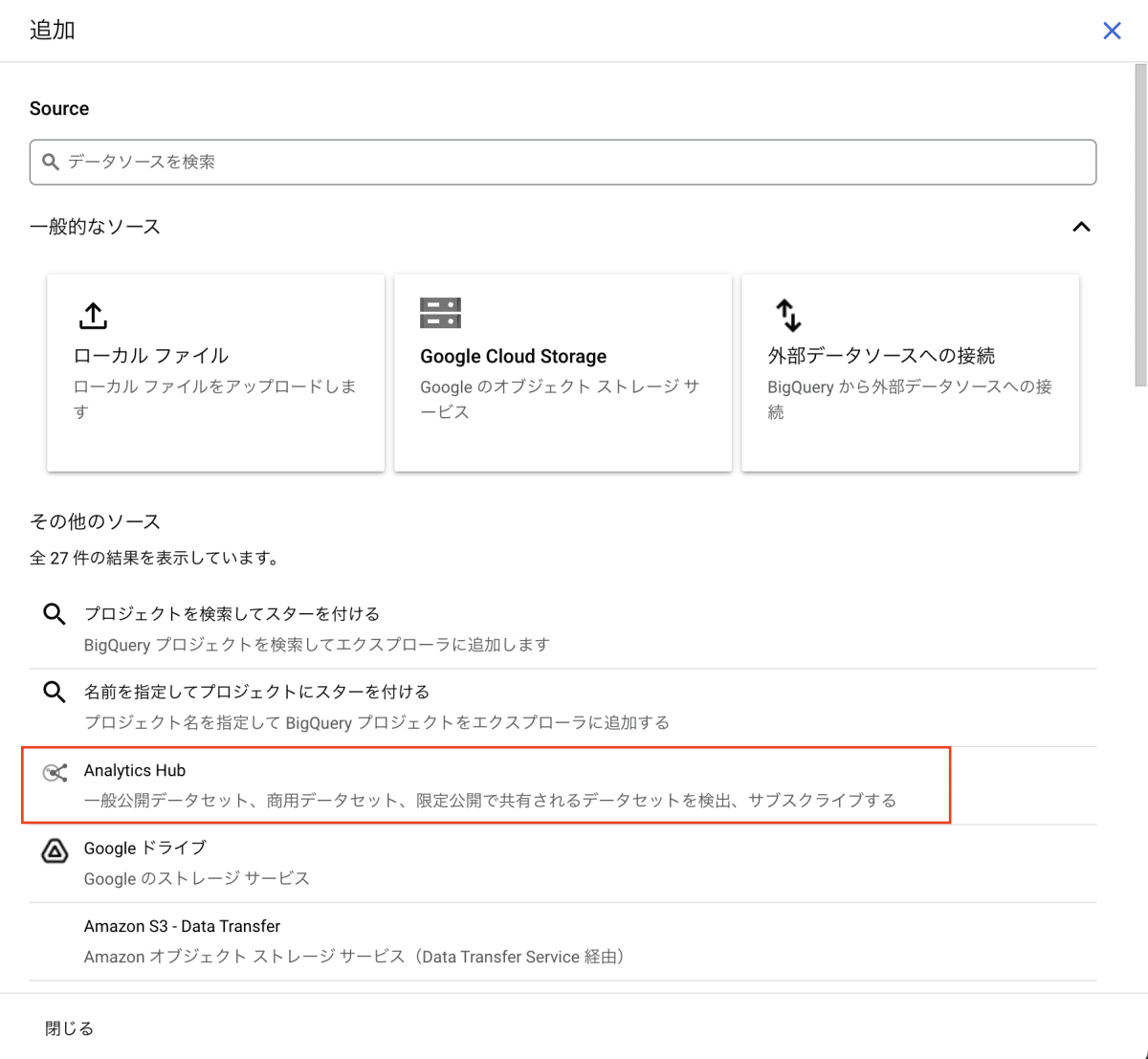
フィルタから「データクリーンルーム(プレビュー)」を選択すると、先ほど作成したクリーンルームを選択します。データクリーンルーム作成時に設定したアイコンは、ここで表示されます。
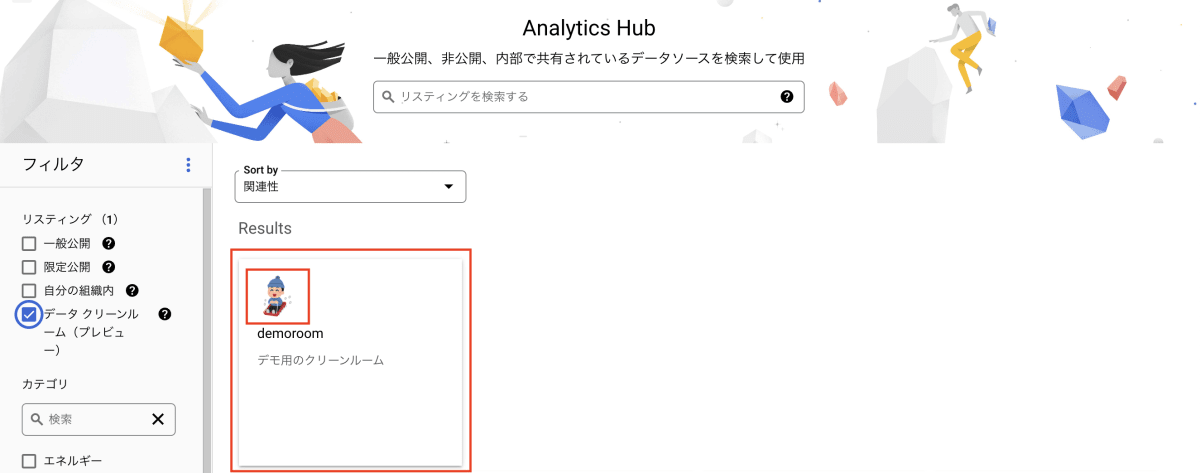
クリーンルームで共有したデータ(リスティング)である share を選択し、「登録」を押下します。
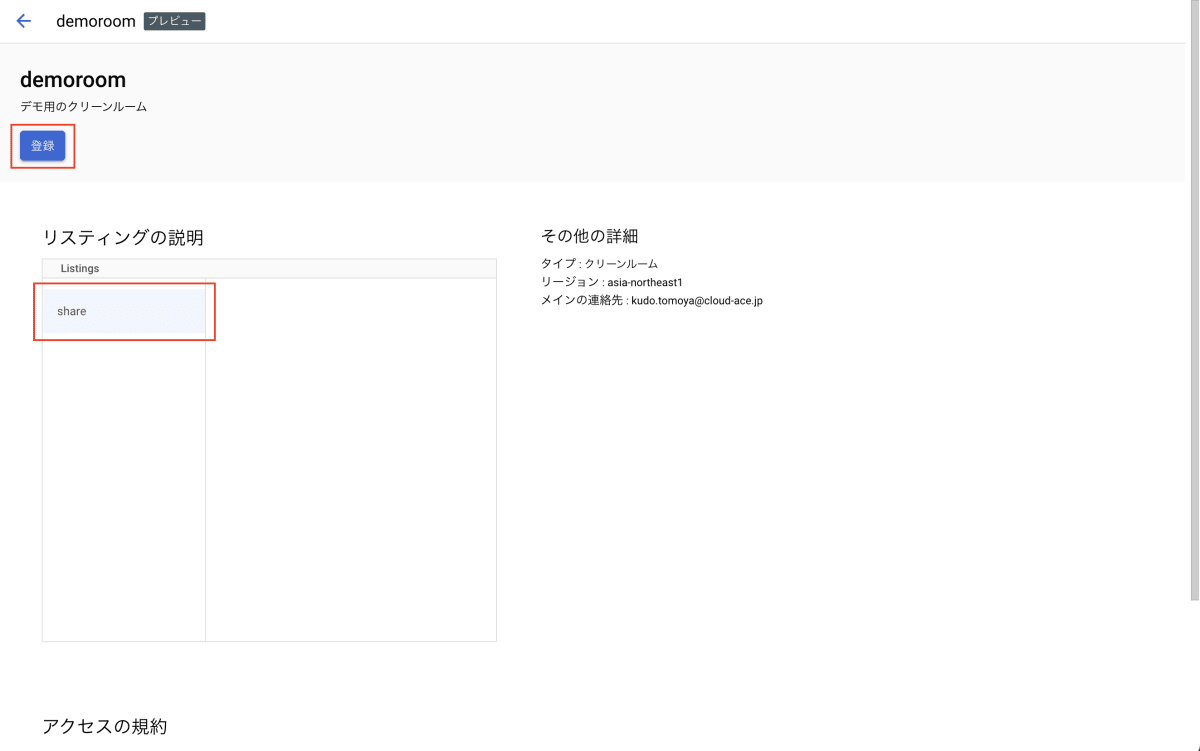
すると、エクスプローラ ペインに共有したデータセットとデータセットに含まれるビューが追加されました。ここで追加されたデータセット名に注目すると、「"クリーンルーム名"_"リスティングの表示名"」になっていることが分かります。
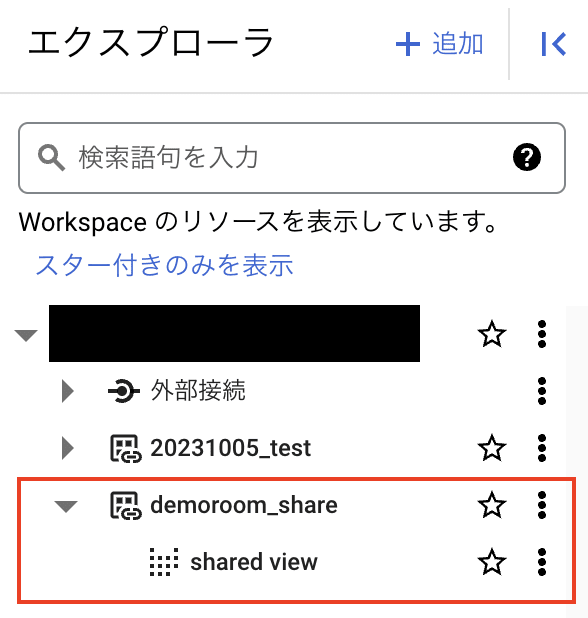
補足
データクリーンルームの名前に「 -(ハイフン)」を含んでいてもデータクリーンルームは作れますが、そのクリーンルーム内のデータをサブスクライバーが購読できない事象が発生しました(以下画像参照)。
これはおそらく、データクリーンルームの名前が「 3.1 データの購読」にて作成される、サブスクライバ側プロジェクトの BigQuery データセット名に使用されるため、と考えられます。BigQuery データセット名には仕様として「 - 」を含めることができません。
そのため、データクリーンルームの名前に「 - 」を含めないようにしましょう。本記事冒頭で述べたようにデータクリーンルームは記事執筆( 10 月 11 日)時点でプレビューであるため、GA になる頃にはデータクリーンルームの名前に「 - 」が入力不可となっているかもしれません。
3.2 クエリの発行
追加されたデータにクエリを発行してみたいと思います。
プライバシーポリシーが設定されているビューに対してクエリを発行するときは、SELECT WITH AGGREGATION_THRESHOLD という構文を使う必要があります。この構文を使うことで、threshold の値でデータをフィルタリングすることができます。この構文については、公式ドキュメントをご参照ください。
今回発行するクエリは、以下の内容です。以下のクエリでは、item_code の種類の数を集計しています。
SELECT WITH AGGREGATION_THRESHOLD
COUNT(DISTINCT item_code)
FROM `プロジェクトID.demoroom_share.shared view`
ビューから参照しているデータには、item_code が 3 種類あり、種類ごとの件数が 4,5 件ですので、上記クエリの実行結果は 3 になる想定です(以下画像)。
上記のクエリを実行した結果は以下のとおりです。
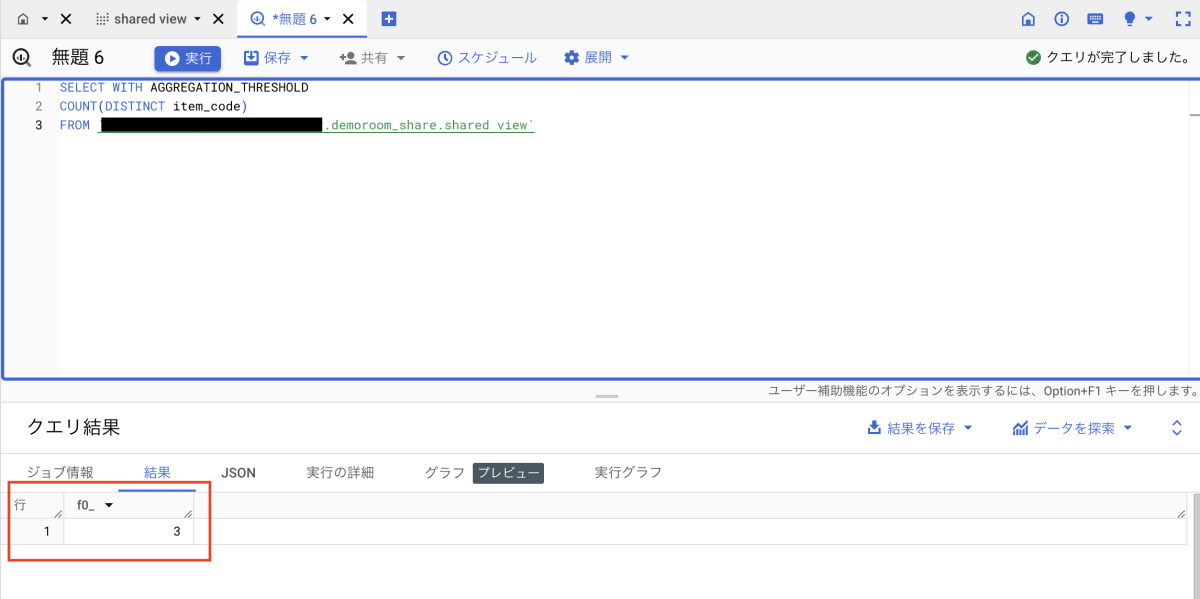
item_code の種類の数が 3 ということで、想定どおりの結果になりました。
LiveRamp によるエンティティ解決
今回の記事では詳しく紹介しませんが、データクリーンルームでは BigQuery のエンティティ解決に LiveRamp を利用することができます。データクリーンルームの利用例として、データ投稿者が共有したデータとサブスクライバが所有するデータを結合する際、各企業のエンティティ ※ が異なる可能性があるという状況があります(例えば、商品 ID など)。同じ商品を扱うデータであるが、商品 ID が企業間で異なることで、企業を横断したデータ分析ができなくなる課題を解決するのが、LiveRamp になります。利用手順などは公式ドキュメントを参照ください。
※エンティティとは、データの中の特定の情報やレコードの実体を指しています。例えば、商品エンティティは商品やサービスの情報を表すレコードであり、商品名や価格などの属性を持ちます。
まとめ
今回の記事では、データクリーンルームについてご紹介しました。
データクリーンルームは、ユーザーの生データへの直接操作とデータのコピーやエクスポートを制限し、特に金融データや医療データなどの機密性の高い情報を組織間で安全に共有するための有効な手段となります。
興味のある方はぜひお試しください。
Discussion