Analytics Hub でリンクされたデータセットでルーティンの使用がサポートになりました
要約
- Analytics Hub でリンクされたデータセットでルーティンの使用がサポートになった。
- 実際に使ってみた。
- 考えられるユースケース
1. はじめに
こんにちは、クラウドエース データML ディビジョン所属の泉澤です。
クラウドエースのITエンジニアリングを担うシステム開発部の中で、特にデータ基盤構築・分析基盤構築からデータ分析までを含む一貫したデータ課題の解決を専門とするのがデータML ディビジョンです。
データML ディビジョンでは活動の一環として、毎週 Google Cloud の新規リリースを調査・発表し、データ領域のプロダクトのキャッチアップをしています。その中でも重要と考えるリリースを本ページ含め記事として公開しています。
2. 概要
今回紹介する リリース notes は、Analytics Hub で公開した共有データセットで BigQuery の ルーティン が使えるようになったことについてです。
この機能は8/7にプレビューとなりました。
まず初めに、今回のリリースに関わる Analytics Hub と BigQuery のルーティンについて紹介します。
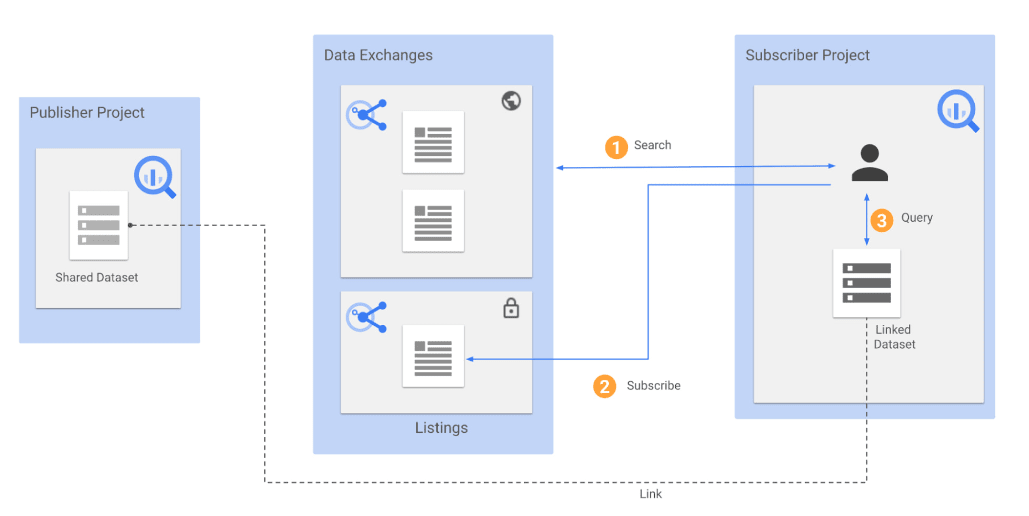
2.1. Analytics Hubとは?
Analytics Hub ※は、組織間でデータと分析情報を大規模に共有できる BigQuery を基盤とするデータ交換プラットフォームです。
※ 2023年9月22日現在、日本語版公式ドキュメントが更新されていないため、英語版を読むことを推奨します。
データの共有をする際、データの実体はパブリッシャー側にだけにあり、サブスクライバーはパブリッシャー側にあるデータを見に行くという形をとります。そのため、大規模なデータをコピーなしで素早く見れたり、コスト面でのメリットがあります(Analytics Hub 自体は無料で、BigQuery のストレージ料金はパブリッシャー側に、分析料金はサブスクライバー側にかかります[参考])。
2.2. BigQuery におけるルーティンとは?
BigQuery におけるルーティンというのは、「ストアドプロシージャ」、「リモート関数を含むユーザー定義関数」、「テーブル関数」※を含むリソースタイプのことです。
これらを使用することによって、BigQuery 上で作成したユーザー定義関数(以下、UDF)をデータセット内に保存して再利用したり、複雑な分析が可能となります。
ルーティンの作成の仕方についてはドキュメントを参照してください。
※ サポート対象になったのは SQL または Javascript UDFs で書かれた UDF と、テーブル関数のみです。ストアドプロシージャとリモート関数は共有データセット内で使用できません[参考]。
今回のリリースによって、Analytics Hub の共有データセット内にルーティンを含めることが可能となりました。サブスクライブしたサブスクライバーは、共有データセットの内のルーティンをそのまま使用できます。
3. 試してみた
Analytics Hub を使ってデータの公開から利用を実際に行います。
その際、ルーティンオブジェクト(UDF・テーブル関数・ストアドプロシージャ)を共有データセットに含めてみたいと思います。
ストアドプロシージャはサポートされていませんが、共有データセットに含めた時にどのようになるか見てみたいと思います。
3.1. 事前に必要なもの
- Google Cloud アカウント
- Google Cloud プロジェクト X 2
- 任意のテーブルデータ
3.2. データの公開(パブリッシャー側)
3.2.1. 共有データセットの準備
一つ目の Google Cloud プロジェクトを用いて公開用の共有データセットを作成します。
-
データセットの作成
BigQuery のコンソールに移動し、任意のプロジェクト内にデータセットを作成します。
一つ注意点ですが、Analytics Hub では顧客管理の暗号鍵(CMEK)は使用できないため、詳細オプションの暗号化が「Google が管理する暗号鍵」となっていることを確認してください。 -
テーブルの作成
作成したデータセット内にテーブルを作成します。
今回は以下のような CSV ファイルを作成し、BigQuery にアップロードしました。
start_time,end_time,menu,place
2023-09-11 12:03:00,2023-09-11 13:03:00,hamburger steak,home
2023-09-12 12:33:00,2023-09-12 13:33:00,curry,office
2023-09-13 11:55:00,2023-09-13 12:45:00,soba,convenience store
2023-09-14 12:45:00,2023-09-14 13:42:00,soba,convenience store
2023-09-15 12:17:00,2023-09-15 13:20:00,omlet rice,home
2023-09-16 13:02:00,2023-09-16 13:42:00,curry,home
2023-09-17 12:56:00,2023-09-17 13:59:00,ramen,restaurant
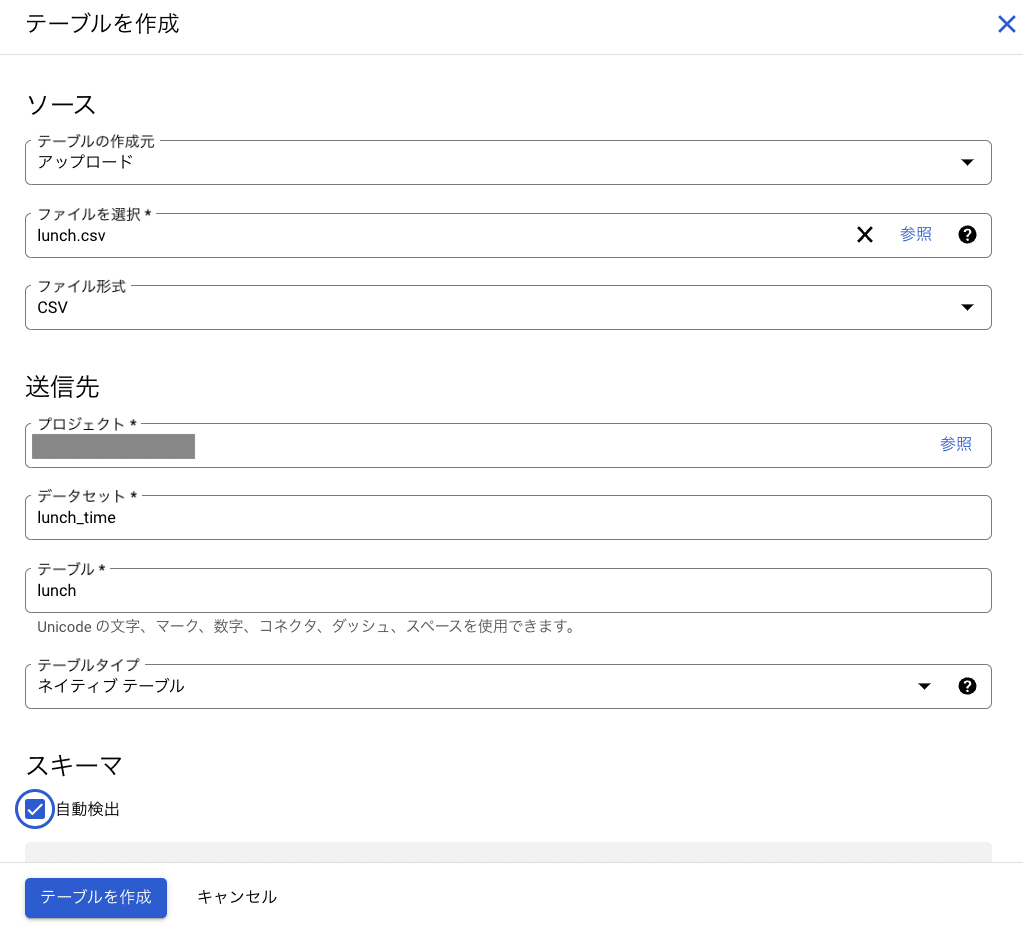
テーブルの作成元を「アップロード」とし、アップロードしたい CSV ファイルを選択します。送信先のテーブルには任意のテーブル名を入力します。最後にスキーマの自動検出のチェックボックスにチェックを入れ、[テーブルを作成]をクリックします。
- ルーティンオブジェクトの作成
続いて、本ページの本題となるルーティンを作成します。
以下のように適当なデータ定義言語 (DDL) を書いて UDF・テーブル関数・ストアドプロシージャを作成しました。
- ユーザー定義関数(UDF)
CREATE FUNCTION
lunch_time.UDF(x date)
RETURNS string AS (CAST(x AS string format "DAY"))
- テーブル関数
CREATE TABLE
FUNCTION lunch_time.table_function() AS (
SELECT
*,
TIMESTAMP_DIFF(end_time, start_time, minute) AS duration
FROM
lunch_time.lunch
- ストアドプロシージャ
CREATE PROCEDURE lunch_time.stored_procedure(menu_name STRING, result_table STRING)
BIGIN
DECLARE query STRING;
DECLARE COUNT INT64;
SET query = FORMAT("""
SELECT COUNT(*) AS count
FOMR lunch_time.lunch
WHERE menu = '%s'
""", menu_name);
EXECUTE IMMEDIATE query INTO count;
SET query = FORMAT("""
CREATE OR REPLACE TABLE '%s'
AS SELECT '%s' as menu, %d as count
""", result_table, menu_name, count);
EXECUTE IMMEDIATE query;
END
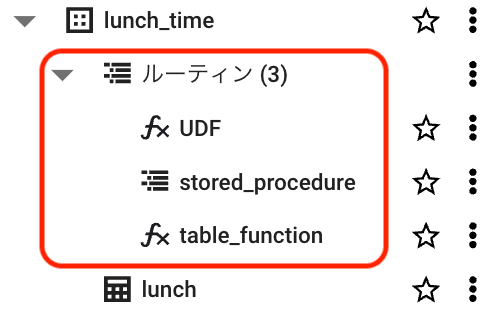
ルーティンを作成すると画像のようにデータセット内にルーティンがまとめられた形で表示されます。
3.2.2. エクスチェンジの作成
エクスチェンジというのはセルフサービスでのデータ共有を可能にするコンテナのことです。
まず Analytics Hub のコンソール画面に移動し、[+エクスチェンジの作成]をクリックします。
プロジェクトに共有データセットを作成したプロジェクトを指定します。表示名は任意のものでかまいません(ここでは「とある週の昼食」としました)。
ロケーションは共有データセットを作成した時のロケーションに合わせる必要があります。
3.2.3. リスティングの作成
リスティングというのはエクスチェンジに掲載する共有データセットへの参照情報を指します。
先ほど作成したエクスチェンジ(とある週の昼食)を選択し[+リスティングを作成]をクリックします。
表示名に任意の表示名(ここでは「ランチタイム」としました)を入れ、共有データセットに先ほど作成したデータセットを指定します。
他にもオプションがありますが、今回はデフォルトで構いません。必要に応じてパブリッシャーや連絡先、説明などを加えてみてください。
続いて、[操作]の縦三点リーダーより[権限を設定]をクリックし、リスティングの権限を編集します。
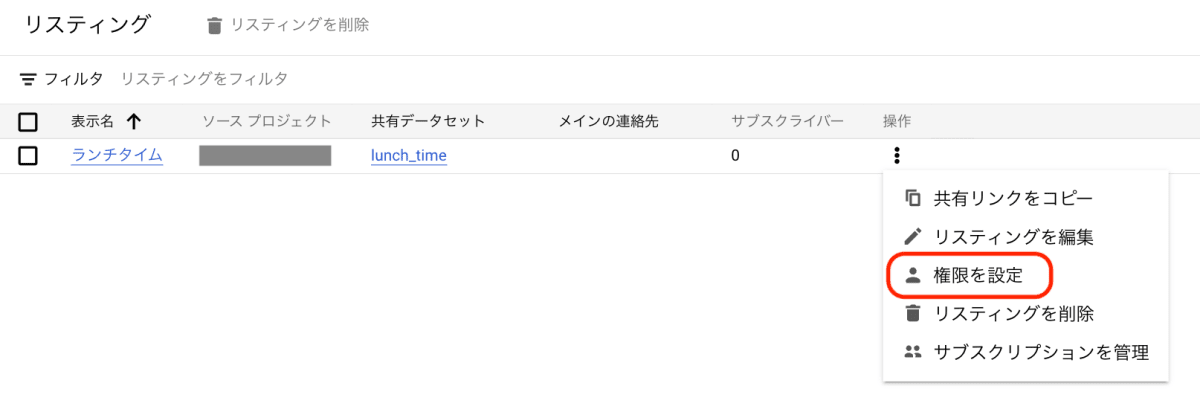
デフォルトでは自身のアカウントに Analytics Hub リスティング管理者、オーナー、編集のロールが付与されていると思います。
このままでは自分以外のアカウントからはリスティングを見つけてデータセットを閲覧することはできません。そのため[プリンシパルを追加]からデータを見せたいアカウントにロールを付与する必要があります。
一般公開する際には「allAuthenticatedUsers」をプリンシパルに選択し、適切なロールを付与すればOKです。
今回は、自身で作成した別のプロジェクトからサブスクライブするため、プリンシパルを追加する必要はありません。
3.3. データの利用、ルーティンが利用できるかの確認(サブスクライバー側)
次に、共有されたデータセットからルーティンの利用ができるか試してみたいと思います。
3.3.1. リスティングの検索とデータセットの接続
共有データセットを作成したプロジェクトとは別のプロジェクトに移動し、Analytics Hub のコンソール画面から[リスティングを検索]をクリックします。
先ほど作成したリスティング(ランチタイム)を検索し、選択します。
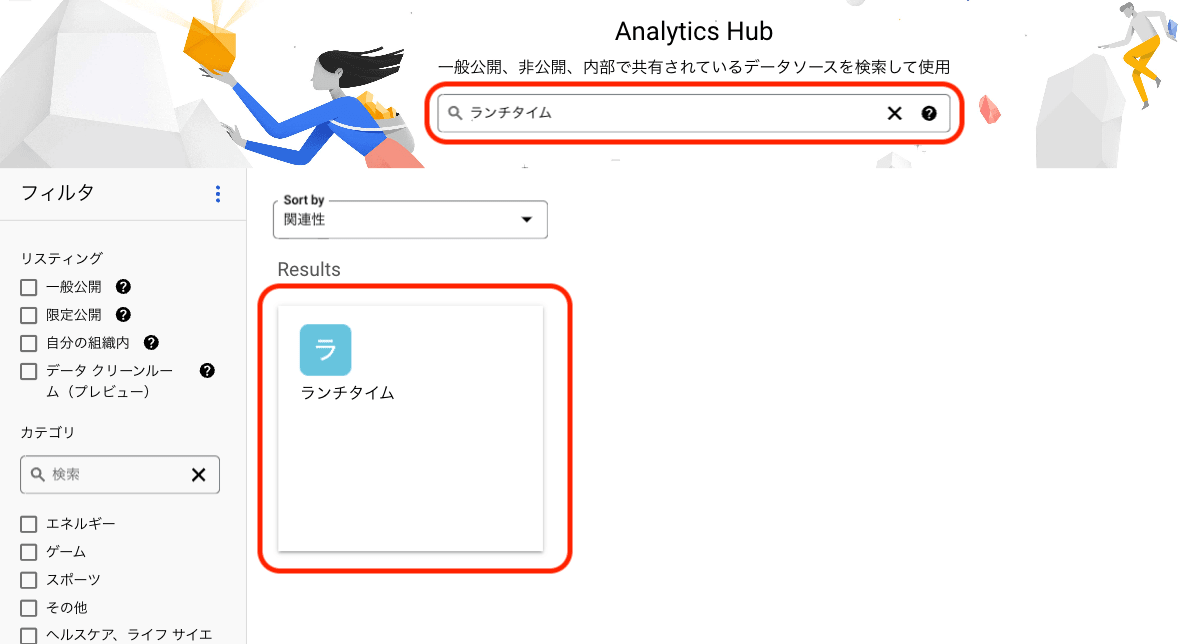
[+データセットをプロジェクトに追加]をクリックします。
以下の画像の「リンク データセット名」には、選択したリスティングの名前がデフォルトで入っているはずです。
しかし、通常のデータセット名と同様に英数字を入れる必要があるため、リスティング名が日本語の場合は変更しなければなりません。
ここでは「lunch_time」としました。
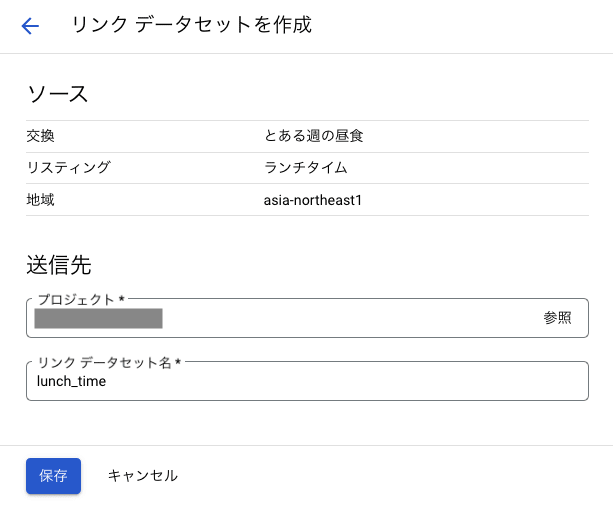
リンク データセットを作成する画面に移るので、そこで保存をクリックすると BigQuery の画面に遷移します。
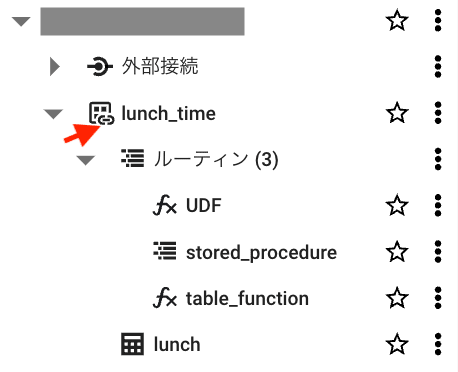
エクスプローラからデータセットがリンクされていることがわかります。リンクマークが Analytics Hub よりリンクされたデータセットであることを示しています。
リンクされたデータセット内のテーブルに対して、通常通りクエリ (DQL: Data Query Language) を書いて実行することができます。しかし、データ定義言語等を用いて、データセット内にオブジェクトを作成したり、データセット内でオブジェクトを更新することはできません。
これは 2.1. で述べたように共有データセットの実体はパブリッシャー側にしかないからです。
共有データセット内のテーブルをクエリした結果を、自身のデータセット内に保存することは可能です。
3.3.2. ルーティンが利用できるかの確認
共有データセット内に作成したルーティンがあることが確認できました。
次は、これらが使えるかどうか試したいと思います。
まずは UDF です。
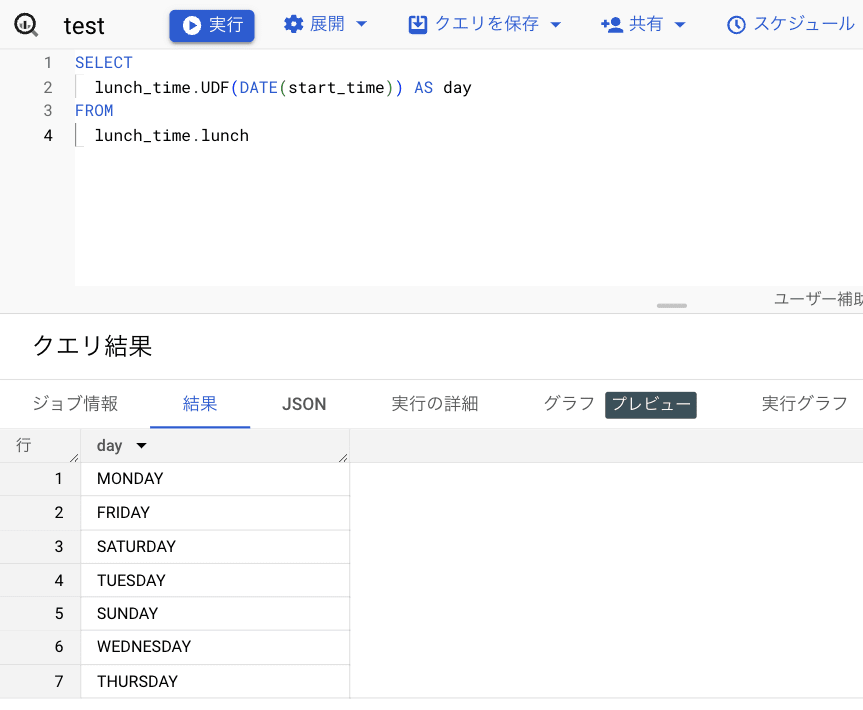
通常通り、UDF を使用することができました。
続いてテーブル関数です。
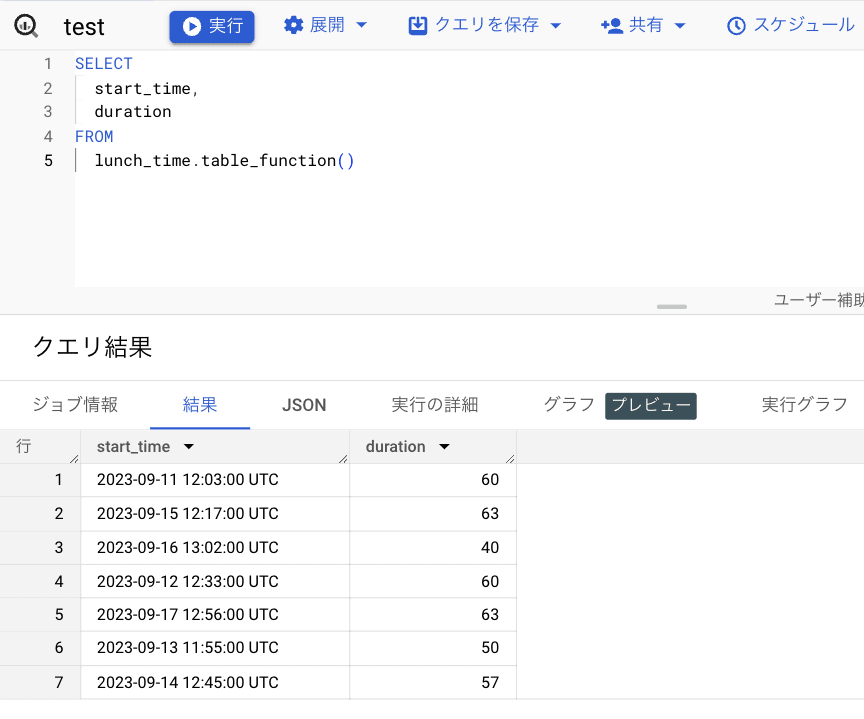
こちらも通常通り使用することができました。
最後にストアドプロシージャです。
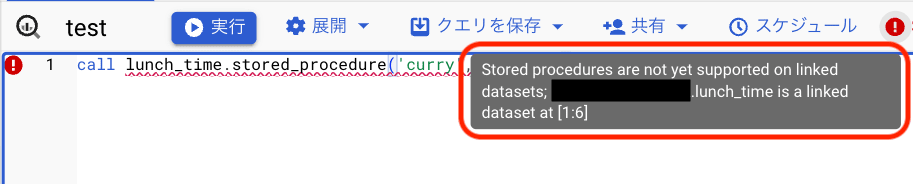
こちらを実行しようとすると、「ストアドプロシージャはリンクされたデータセットではサポートされていないよ」、と怒られてしまいました。
4. 制限と注意点
Analytics Hub でルーティン機能を使用する際には、以下の点を考慮する必要があります。
-
現時点で対応しているのは UDF とテーブル関数のみです。ストアドプロシージャとリモート関数は対応していないため、利用することはできません。
-
3.2.1. で述べたように、ルーティンだけでなく、リンクされたデータセットでオブジェクトを作成・更新することはできません。別の UDF などを試したい場合は、自分のデータセットにテーブルをコピーして使用しましょう。
-
3.2.2.で見たように、ストアドプロシージャのような、まだサポートされていないルーティンも共有データセットに追加し、Analytics Hub に公開することが可能です。ただし、そのルーティンが後にサポートされると、突如として使用可能になることがあります。したがって、データセットにルーティンを追加する際には注意が必要です。
他にも Analytics Hub にはいくつか制限事項があります。
詳細は公式ドキュメントで確認してください。
5. ユースケース
今回のリリースによって公開する共有データセットの中に UDF、テーブル関数といったルーティンのオブジェクトを含めることが可能となりました。これによって共有されたデータの再利用性の向上、そして分析の一貫性を保てるようになったことにより、以下のユースケースが考えられます。
-
組織内および組織間のコラボレーション: Analytics Hub は組織内または組織間でのコラボレーションを促進します。UDF やテーブル関数を含むデータセットを共有することで、一貫したビジネスロジックと分析を共有できるため、協力して問題解決を進めることが可能になります。
-
知識の共有とスキルアップ: 自身の分析手法やビジネスロジックを公開することで、他者からフィードバックを得たり、新たな視点を学ぶことができます。自身や自社のブランド認知度の向上させることもできるため、コミュニティの形成や新たなビジネスチャンスに繋がる可能性もあります。
-
教育とトレーニング: 教育者やトレーナーは、特定のテーマやトピックを教えるために設計されたデータセットを作成し、UDF やテーブル関数を使用して分析例を提供することができます。学生やトレーニーはこれらのデータセットを実際に BigQuery 上で動かすことによって、データに対する分析スキルを磨くことができます。
このようにパブリッシャーとサブスクライバーの両方にメリットがあると考えられます。
6. まとめと今後の展望
本ページでは Analytics Hub で BigQuery のルーティンが対応したことを紹介しました。Analytics Hub は非常に便利なサービスですが、まだ BigQuery の全ての機能をサポートしているわけではありません。しかし、先日の Google Cloud Next 2023 で発表されたデータクリーンルームのプレビュー提供開始により、Analytics Hub を用いたデータ共有がますます盛んになることが予想されます。これに伴い、今回紹介したルーティンのように、今現在サポートされていない機能も順次対応されていくでしょう。ますます便利になっていく BigQuery と Analytics Hub に今後も注目していきたいです。
7. 参考
- Google Cloud 公式ドキュメント: Analytics Hub の概要
- Google Cloud 公式ブログ: 安全なデータ交換が可能な Analytics Hub の一般提供を開始
- Google Cloud Japan 公式ブログ: Analytics Hub で加速するデータシェアリング
Discussion