初めに
はじめまして、Toshikiです!
最近、拡散モデルより高速なFlow Matchingが画像や音声の生成に使用されてきています。
そこで、Flow Matchingの技術を音声合成に初めて適応したMatch-TTSという音声合成モデルを実際に動かしてみました!
本記事では、Match-TTSの各部の処理などに関して、簡単に解説します。論文を読んでみましたが理解し切れていない部分も多く、もし誤りなどあればコメントしていただけると嬉しいです!
拡散モデルとFlowMatching
拡散モデルは、画像生成やモーション生成、音声合成等の幅広い生成タスクにおいて、高品質な生成を達成している今流行りの手法です。拡散モデルでは、例えばデータ分布を正規分布へ段々と変換する等の拡散過程を定義して、その逆過程を辿る処理をベースにサンプルが行われますが、この逆過程を辿る際には多くの繰り返しの処理が必要になり、生成が遅いという欠点があります。
この問題に対して、拡散/逆過程は確率微分方程式(SDE)やそれに対応する常微分方程式(ODE)など数値解手法として書き換えることで、サンプル速度をあげることが可能です。ですが、正確に解くためにまだ多くの繰り返し処理が必要です。
そこで、FlowMatchingという技術が提案されています。
Flow Matchingは、拡散モデルの発展というよりは、Normalizing Flowを連続にしたContinuous Normalizing Flow(CNF)にODEを適用して解くイメージで、CNFの時間変化であるベクトル場を学習します。そして、これを学習データのサンプルから学習できるようにしたものがConditional Flow Matching (CFM) です。
CFMは、既に拡散モデルより効率的なサンプルが出来ますが、最適輸送を用いて分布間のマッピングを効率化し、安定した学習と高速な生成が出来る最適輸送(Optimal Transport; OT)-CNFが提案されています。
このOT-CFMを用いた音声合成モデルであるMatch-TTSを解説します。
Matcha-TTS🍵
Matcha-TTSは、既存TTSモデルであるGrad-TTSを踏襲しつつ、デコーダ部分にFlow Matchingの技術を適応したText-to-Speechモデルです。実際には出力はメルスペクトログラムになるので、音声を出力するためには別途メルペクトログラムから音声を生成するVocoder等が必要になります。また、OT-CFMのベクトル場をモデル化する際にStableDiffusionを参考にした1D U-NETを用いている点も特徴かなと思います。
以下の図はMatcha-TTSの論文より音声合成時の概略図になります。
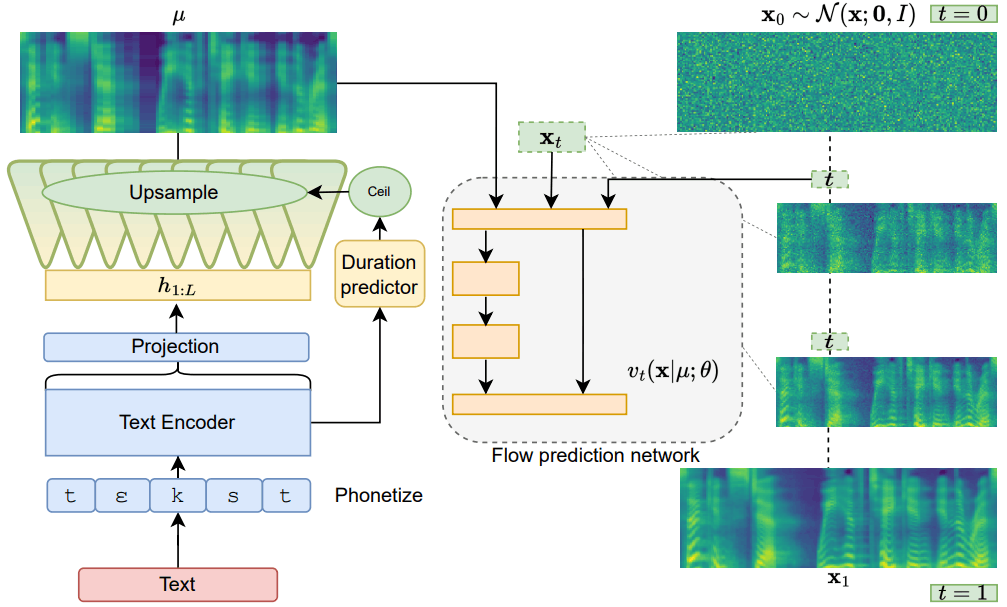
以下、各モジュールが何をしているのか簡単に解説していきます。
Phonetize
Phonetize部では、入力された文を音素単位へと変換する処理を行います。しばしばg2p(Grapheme To Phoneme)とも表記されています。日本語での処理の具体例を挙げると、「こんにちは」を入力すれば「k o N n i ch i w a」という音素列に変換されるイメージです。
文字列のままではモデルに入力することができないので、実装では各音素に対応する整数値を割り当てて、音声合成モデルの入力として処理をさせます。学習対象のパラメータはありません。
TextEncoder
Phonetize部から受け取ったテキスト情報は、最初にTextEncoder内のnn.Embeddingsによって埋め込まれ、Transformer部で各テキストやその前後関係を考慮した潜在表現へとエンコードされます。TextEncoderには、TransformerのEncoderとほぼ同様のものを用いていますが、全結合ではなく畳み込みベースの処理で射影を行い、通常のsincos位置埋め込みではなく位置情報を回転させることでより効果的にエンコードするRoPEを使用して位置埋め込みしています。最後にTransformer部から出てきた潜在表現は射影され、テキスト潜在表現として出力されます。
Monotonic Alignment Search
学習時のみ必要なため、音声合成時の概略図には載っていませんが簡単に解説します。
学習データとして発話テキストと音声データを与えていますが、音声のどの時刻にどの音素が発声されているのか、教師データとして与えていません。Matcha-TTSでは、モデル内部で音素の区間を判定する手法の一つであるMonotonic Alignment Search(MAS)を用いています。
MASの処理としては、今回はメルスペクトログラムを→列(len_mel)として、テキスト潜在表現を↑行(len_text)にとり、各々に対応する対数尤度を計算してlen_text×len_melの行列を取得します。下の図では、一つ一つの〇に対数尤度が格納されているイメージです。
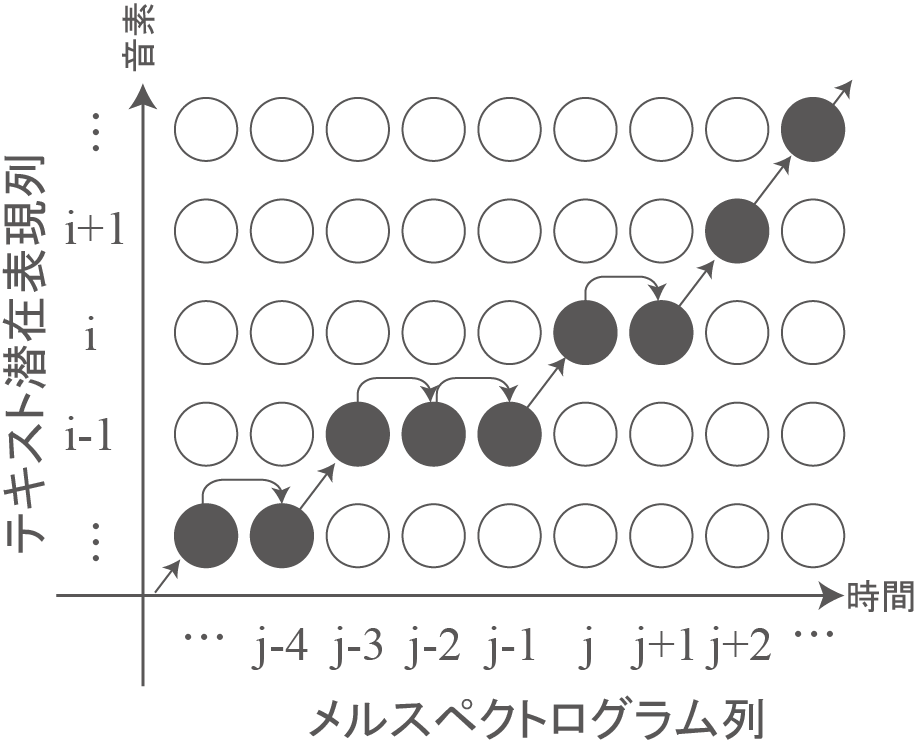
その後、進める方向を→(1,0)方向か↗(1,1)方向のみに制限して、スタート(1,1)からゴール(len_text,len_mel)への経路を探索したときに、対数尤度の合計が最大になるような経路を取得します。
学習時はMASを用いて取得した経路から各音素が話されていた長さを判定し、判定された長さを用いて、テキスト潜在表現はメルスペクトログラムの長さにUpsampleされ、次のFlowPredictionNetworkへと渡されます。MASは各音素の区間を探索する手法であり、学習パラメータはありません。
DurationPredictor
推論時の入力はテキストのみです。そのため、MASを使用して各音素が話されていた長さを求める事が出来ません。これに対応するために、射影前のテキスト潜在表現を入力として、各音素が話されていた長さを予測するDurationPredictorもモデル内部で学習しておきます。これにより推論時にもテキスト潜在表現をUpsampleすることができます。
実装としては、"一次元畳み込み⇒ReLU関数⇒正規化処理"の二層を処理したのちに射影するような処理を行っています。
FlowPredictionNetwork
メルスペクトログラムの長さにUpsampleされたテキスト潜在表現を条件付けとして、OT-CNFを用いて、ノイズからメルスペクトログラムへの変換をマッピングします。ベクトル場のモデル化にはStableDiffusionを参考にしたU-NETの構造を使用しますが、条件付けの方法としてはStableDiffusionのTransformer部でのCrossAttentionの手法を取らずに、ノイズとテキスト潜在表現とのconcatで対応します。以下は論文よりMatchaTTSに使われている1D U-NET構造です。
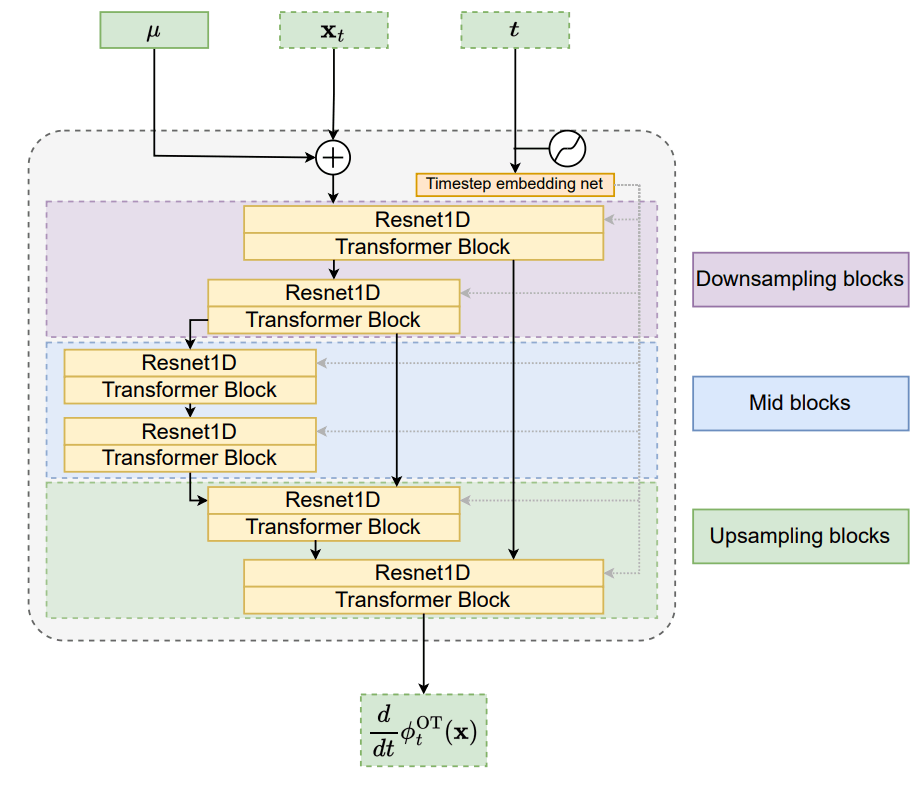
データとノイズから計算したベクトル場をU-NETが真似して出せるように学習し、推論時はモデル化したベクトル場を用いてノイズをメルスペクトログラムへ変換します。
損失関数
損失関数は3つあり、この損失関数の値が小さくなるように各モジュールのパラメータを更新して学習していきます。
- DurationPredictorの部分で、MASから取得した値とDurationPredictorが予測した値との対数スケールでの平均二乗誤差です。これにより、推論時に各音素が話されていた長さを予測できることを主に期待します。
- FlowPredictionNetworkの部分で、データとノイズから計算したベクトル場とU-NETにて予測したベクトル場の平均二乗誤差です。これにより、推論時に、条件付けの値を用いてノイズをメルスペクトログラムへと変換するようなベクトル場を得られることを主に期待します。
- TextEncoderとMASに主に関わる部分で、メルスペクトログラムとUpsampleされたテキスト潜在表現との事前誤差(計算上はほぼ平均二乗誤差)です。これにより、各音素ごとのテキスト潜在表現が対応するメルスペクトログラムの値に寄っていき、MASによって行われている各音素の話されていた長さ判定が改善されていくことを主に期待します。
生成音声確認
今回はLJSpeechの英語音声で学習されたMatcha-TTSの重みが公開されていたので流用できる重みは流用しつつ、日本語学習データとしてITAコーパスより381文を用いてファインチューニングしました。また、Matcha-TTSはメルスペクトログラムを生成するモデルになるので、メルスペクトログラムを音声データに変換するためにVocoderを外付けする必要があります。今回VocoderにはLJSpeechの英語音声で学習したHiFi GAN(LJ_FT_T2_V1)を使用しており、日本語の学習音声でのファインチューニングは行っておりません。
以下生成音声サンプルです。こちらの音声は学習時に使用していないものになります。
- RECITATION324_319 1steps
- RECITATION324_319 5steps
- RECITATION324_319 10steps
- RECITATION324_319 100steps
- RECITATION324_243 1steps
- RECITATION324_243 5steps
- RECITATION324_243 10steps
- RECITATION324_243 100steps
繰り返し処理の回数が1回でも悪くない音声になっていると感じます。5stepでもなかなか綺麗な音声が出ていると感じました。
また、MatchaTTSの各繰り返し数におけるRTF(処理時間/音声時間)は以下になります。RTX4060を使用した際の処理速度になります。
- RTF (1steps) : 0.056392 ± 0.023501
- RTF (5steps) : 0.086359 ± 0.027581
- RTF (10steps) : 0.113689 ± 0.035634
- RTF(100steps) : 0.722644 ± 0.232213
おわり
より大規模な日本語データセット等で学習させたり、Vocoder自体も日本語音声でファインチューニングすることで、精度はより上がると思われますが、今回はここまでです。Matcha-TTSのFlowPredictionNetwork部分をConsistencyModels(ConsistencyTraining)に変更して、処理の速度や精度の比較を行う為に色々頑張っていましたが上手く学習してくれず、Matcha-TTSの紹介と生成音声の紹介で終わってしまいました。
次は、大規模な日本語データセットを用いて学習、ConsistencyModelsに変更して失敗した原因を探索、メルスペクトログラムではなく音声を直接出すようEnd-to-Endな形に改造、OT-CFMでのPitchやVolumeの生成、等に挑戦できたら楽しそうだなと思っています。
最後に宣伝になりますが、機械学習でビジネスの成長を加速するために、Fusic学習チームがお手伝いしています。機械学習のPoCから運用まで、すべての場面でサポートした実績があります。もし、困っている方がいましたら、ぜひFusicにご相談ください。問い合わせから気軽にご連絡いただけます!
参考文献
Matcha-TTS: A fast TTS architecture with conditional flow matching
Github : Matcha-TTS
Flow Matching for Generative Modeling
Consistency Models: 1~4stepsで画像が生成できる、新しいスコアベース生成モデル
ZennのMarkdown記法一覧
Grad-TTS: A Diffusion Probabilistic Model for Text-to-Speech
Glow-TTS: A Generative Flow for Text-to-Speech via Monotonic Alignment Search

Discussion