はじめに
株式会社ファースト・オートメーションCTOの田中(しろくま)です!
弊社では製造業向けのRAGを使ったチャットボットの開発を行っていますが、RAGが普及してきた昨今においてまだまだ課題があるなと感じているのが、 マニュアルのような画像と文書の複合したドキュメントの読み取り です。
例えばPC操作の説明書などは良い例かなと思うのですが、画面スクショに矢印が入っていたり、それに対して説明が入っている文書は通常のRAGとの相性が悪いです。
以下は経産省が提供しているgBizINFOというサービスの操作説明資料を抜粋したものです。
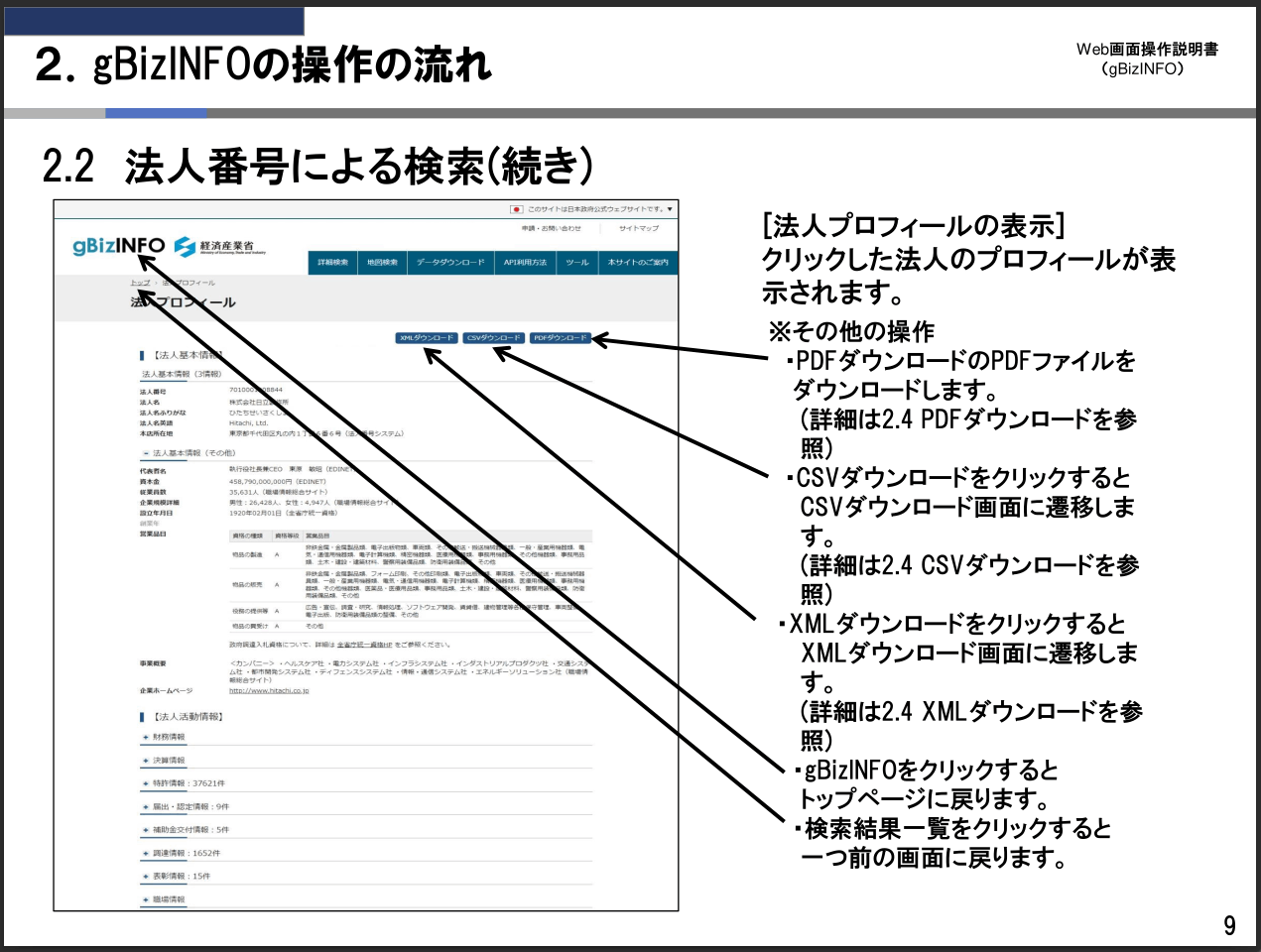

元のPDF資料はこちら
このように、図と文書が混在し、かつ矢印などでそれらが関連付けられているような形になります。
また 製造業ではセキュリティ的な懸念からこういった資料のアップロードやチャットの内容をクラウドに上げたくない企業も多いです。
こういったことから、今回は マニュアルのような図・文書混在ドキュメントをローカル環境でうまく読み込めるようなチャットボット の構築を行ってみたいと思います。
どうやってマニュアルを読み込むのか?
ぱっと思いつくのはVision Language Model(VLM)を用いて、文字と図を分けて読み込ませるという方法があると思いますが、上記のような資料だと図から伸びた矢印に意味があるので、両者を分けずにそのままPDFを画像として読むのが良さそうです。
その際にある程度日本語のOCRに強いVLMが必要になりますが、 最近出たQwen2-VLというモデルはかなり日本語のOCRにも強い ようで、今回チャット用のモデルにはQwen2-VLを使用します。
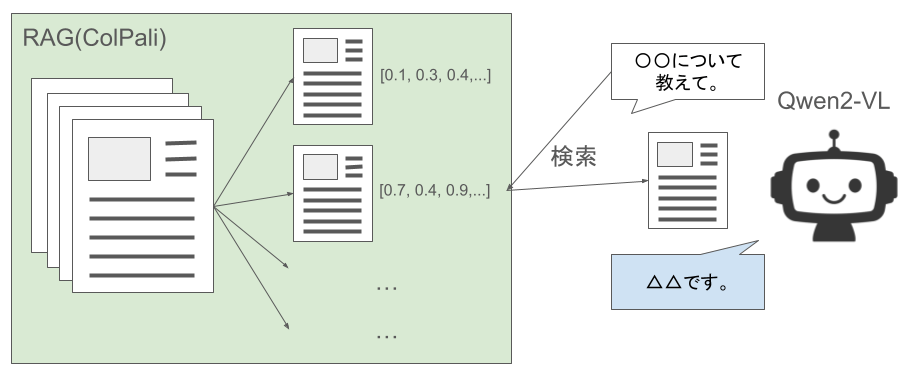
さらにRAGの構築に対しては、ColPaliという文書を画像化してベクトルDBを構築する手法を用います。
ColPaliはPDFの各ページを埋め込みベクトル化し、検索時は関連性の高いものをページ毎に抽出することができます。
またColPaliにはQwen2-VLベースのモデルがあり、こちらも日本語に対する性能がかなり期待できそうです。
ColPaliは画像ベースのRAGという珍しい手法というのもあり、少し前にいくつかの記事で紹介されていました。
今回の手法をまとめると以下の図のようになります。
デモ
上記の手法を実装したものをStreamlitを用いてチャットアプリにしてみました。
以下のリポジトリから試すことができます。
使用しているモデルはQwen2-VLおよびColPaliそれぞれで以下のものを用いています。
上記の経産省のドキュメントに対して、操作方法の質問を行ってみます。
以下が実際のチャットの様子になります。
AIの回答としては参照ページと回答内容を示すようになっています。
この回答では、「PDFファイルのダウンロード方法について教えて。」というクエリに対して、対象の説明を行っているページとAIによる回答が出力されています。

別のクエリで「法人検索結果のプロフィール表示の方法を教えて。」という質問をしてみます。
こちらも適切なページと説明内容が出力されています。

まとめ
Qwen2-VLとColPaliを用いて、マニュアルのような図・文章混在ドキュメントを読み取るローカルで動くチャットアプリを作りました。
ローカルで日本語のOCRに強いモデルは活用の用途が広そうです。
また Qwen2-VLはマルチイメージ入力に対応 しているので、今回のように該当の1ページだけでなく、前後ページや関連ページ含めて入力にすることでより精度の高い回答ができると思いました。
最後までお読みいただきありがとうございました。
最後に宣伝ですが、株式会社ファースト・オートメーションは一緒に働いて下さる仲間を絶賛募集中です!
- ローカルLLMを使ったプロダクトに興味がある
- LLMの社会実装に貢献したい
- 製造業をより良くしたい
といったことに少しでも興味がある方、ぜひ下記応募リンクからご連絡下さい!

Discussion
興味深い内容でした。こちらの構成でVRAMはどれくらい必要だったでしょうか?
コメントいただき、ありがとうございます!
16GBくらい必要になります!