はじめに
こんにちは!ナウキャストのデータエンジニアのけびんです。昨年に引き続き今年も Snowflake Summit 2025 に参加しております。
4日目に "Best Practices for Boosting Your Snowflake Query Performance" というセッションに参加しました。様々なパフォーマンス向上のプラクティスが紹介される密度が濃いセッションで、非常に勉強になりました。
本ブログではこのセッションの内容を紹介するとともに、筆者が知っていることを補足していこうと思います。
Snowflake Query Engine Overview
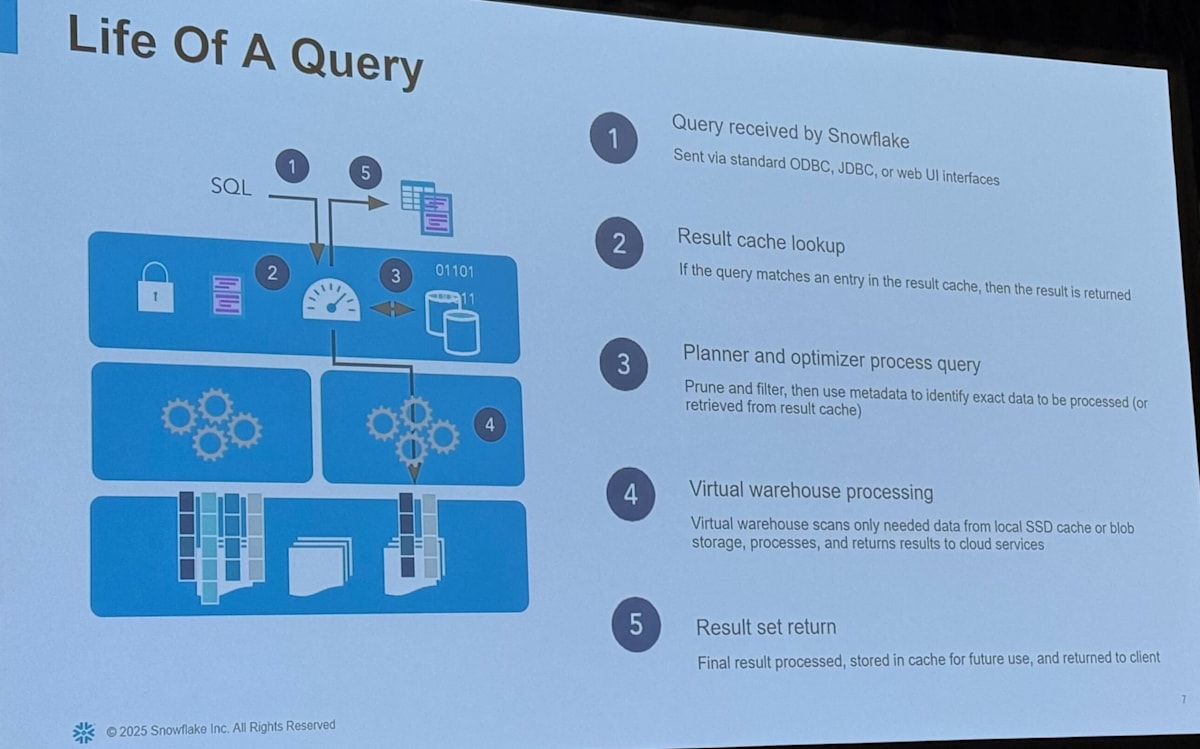
まず最初に Snowflake の Query Engine に関する概要の確認がありました。
- クエリが投げられて結果を返すまでのアーキテクチャ
- クエリコンパイル
- クエリ実行
これらの構成を踏まえた上でパフォーマンス改善案を考えることが重要です。

Query Plans Deep Dive and Automatic Plan Stability
Query Plan Terminology & Query Profile
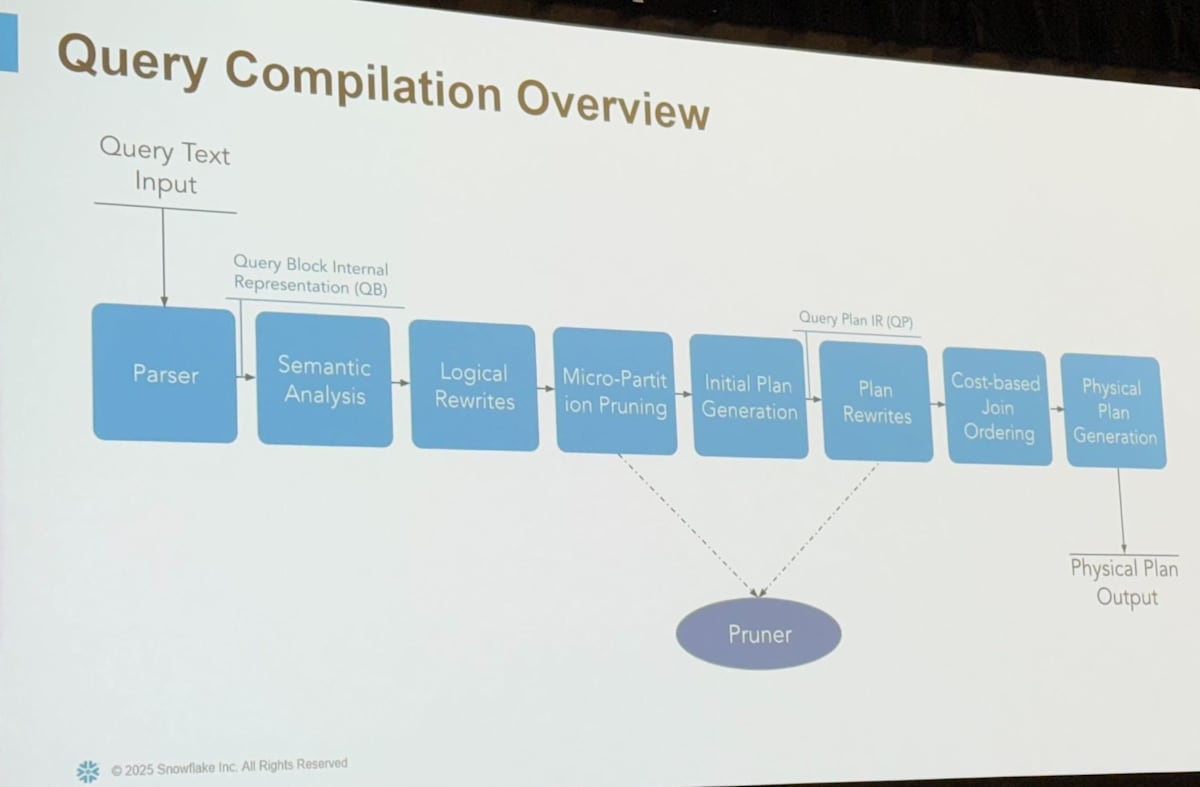
クエリのパフォーマンスを改善するためにはクエリの実行計画を確認し、ボトルネックを特定し、それに対処するという流れで進めるのが大事です。本セッションではまずクエリの実行計画に関連する用語が紹介されました。
クエリの実行計画は有効非循環グラフ(DAG)ですが、これは operator が link によって繋げられる形で表現されます。
- Operators
- 一連の行を処理する
- 具体的には Scan や Filter、 Join、Aggregation などがある
- 詳細はこちら
- Links
- Operator 間のデータのやりとりを担う
- 必要であれば、実行時に並列処理するためのデータの再分配なども担う
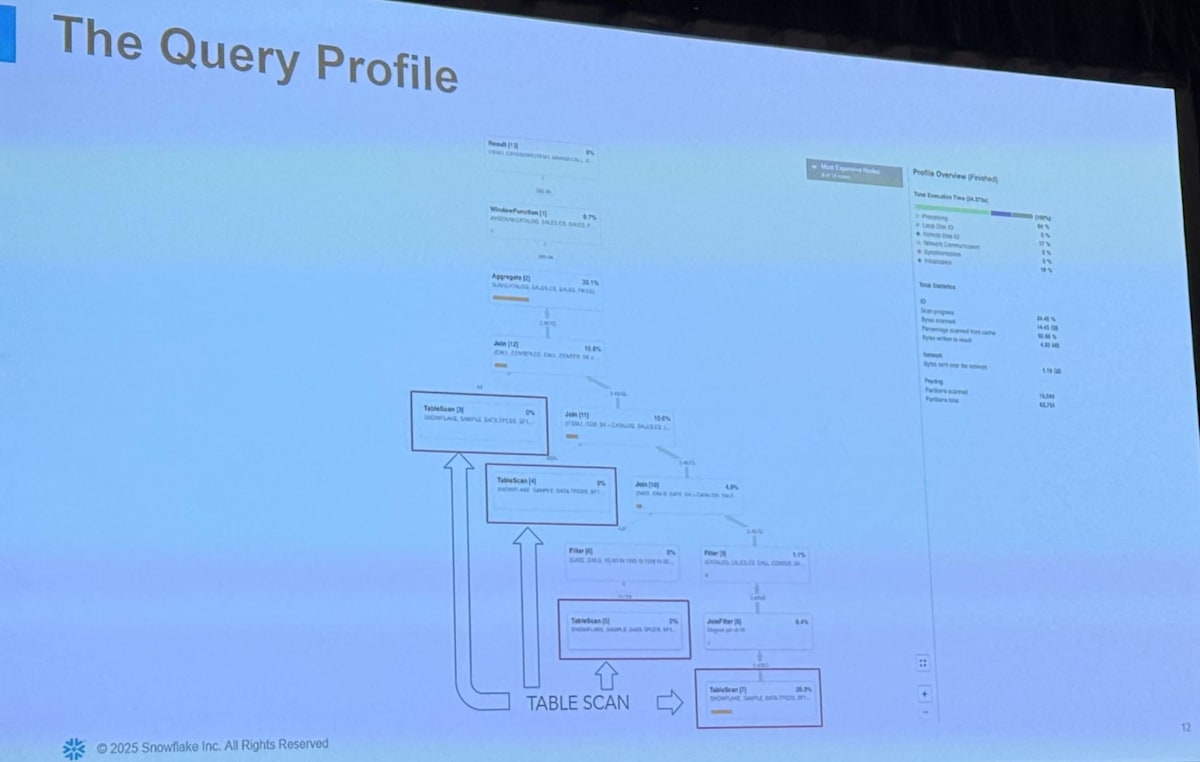
クエリの情報に関しては Snowsight において Query Profile のページを見ればグラフィカルに情報がまとめられており分かりやすいです。また、 get_query_operator_stats() 関数や account_usage の query_history ビューを確認することでも具体的な情報を得ることができます。Query Profile については以下のスライドでも紹介しているのでご覧ください。
Optimizer Philosophy
Optimizer の哲学についてまず紹介がありました。


Snowflake の Optimizer は2つの種類があります
- Cost-based Optimizer (CBO)
- CBO は高度な Optimizer で、テーブルや Micro partition の統計情報、データの分布などの情報をもとに、実行計画を立てる
- 複数の実行計画の中から、最適なものを選んだ利する
- Non-cost-based Optimizer
- CBOと違いシンプルな Optimizer で、ルールベースやヒューリスティックなアプローチで最適化を行う
Snowflake の記事ではないですが、以下がわかりやすかったです。
Cost-based Optimization に関する工夫についても紹介がありました。複数のplanから最適なものを選んでいくわけですが、実行時間の予測には不正確さがつきものです。哲学のところでもあった通り、planの安定性をSnowflakeは重視しており、不安定なplanを無闇に取り込まないような工夫をしているようです。
ここのスライドのグラフの見方がわからなかったところ @indigo13love さんが補足してくださいました!!
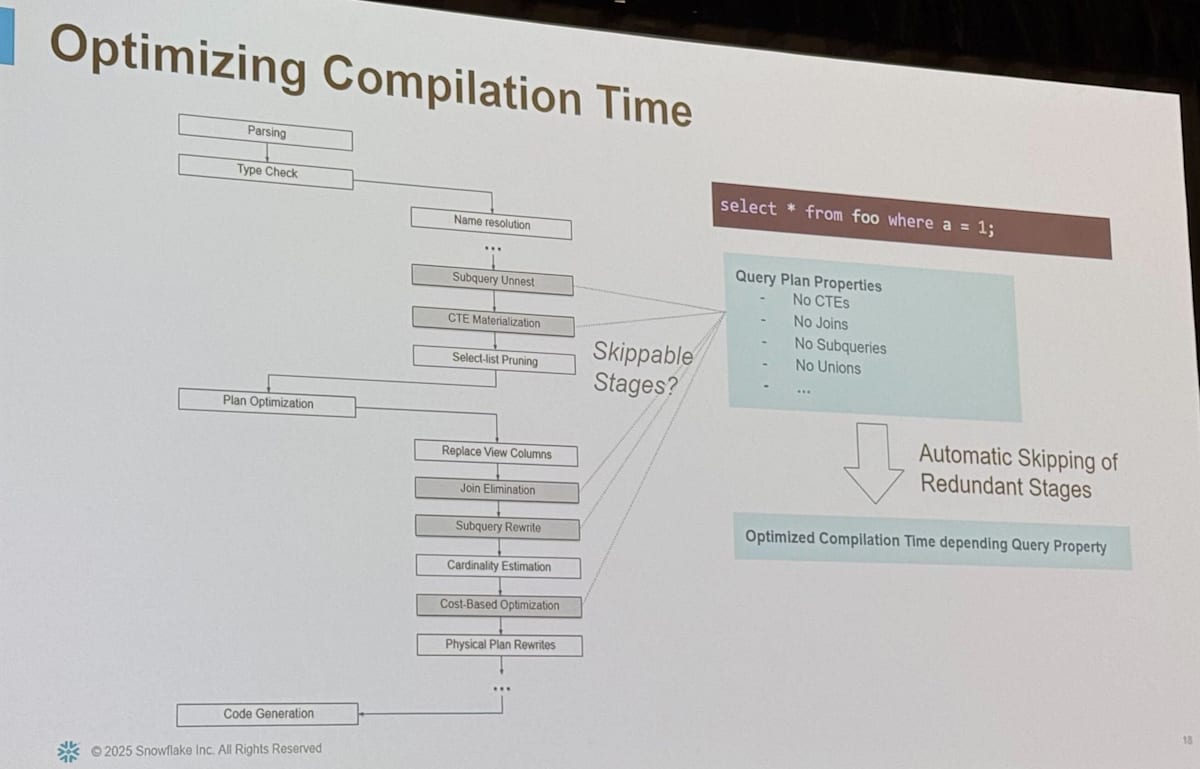
また、クエリのコンパイル時間を最適化するための工夫も紹介されました。最初に見た通り、クエリのコンパイルは複数のステージからなりますが、その一部はスキップ可能になっているようで、自動的に余分なステップはスキップされるような構成になっているようです。
Partitions and Pruning Optimizations
具体的なパフォーマンス改善のプラクティスを見ていく前に、 Snowflake の重要な仕組みや機能が簡単に紹介されました。
Micro Partition おさらい
Snowflake の重要な要素の一つである Micro Partition (MP) についてまずは確認しましょう。
- Micro partition は immutable で大体10MB以下の小さなファイル
- PAX (Hybrid columnar) storage
- それぞれのカラムの値がまとめられ、データ型に適した圧縮がなされる
-
メタデータがカラムごとに取得される
- 取得される内容としては「最大値・最小値」「Nullの数」「NDV (Num of Distinct Value)」など
- これらはプルーニングの際に適宜参照される
Pruning と Clustering
クエリのパフォーマンスを上げるためには「余計なファイルは読み込まないこと(= Partition Pruning)」が非常に重要です。
Snowflake では Partitioning は Micro Partition として自動的に行われるため、 Clustering をいかに行うかがポイントとなります。 Clustering は要はデータをソートした上で保存しておくということですが、 Snowflake の場合はいかの3つのパターンが存在します。
- 何もしない
- Natural Clustering
- Micro Partition は immutable なため、Table への insert が適切であれば自然と Clustering された状態が実現されることがある
- Auto Clustering
- 指定した Key で定期的にソートし直して Micro Partition を再構成してくれる機能
- 明示的かつ定期的に実行されるため確実に Clustering された状態が維持し続けられる
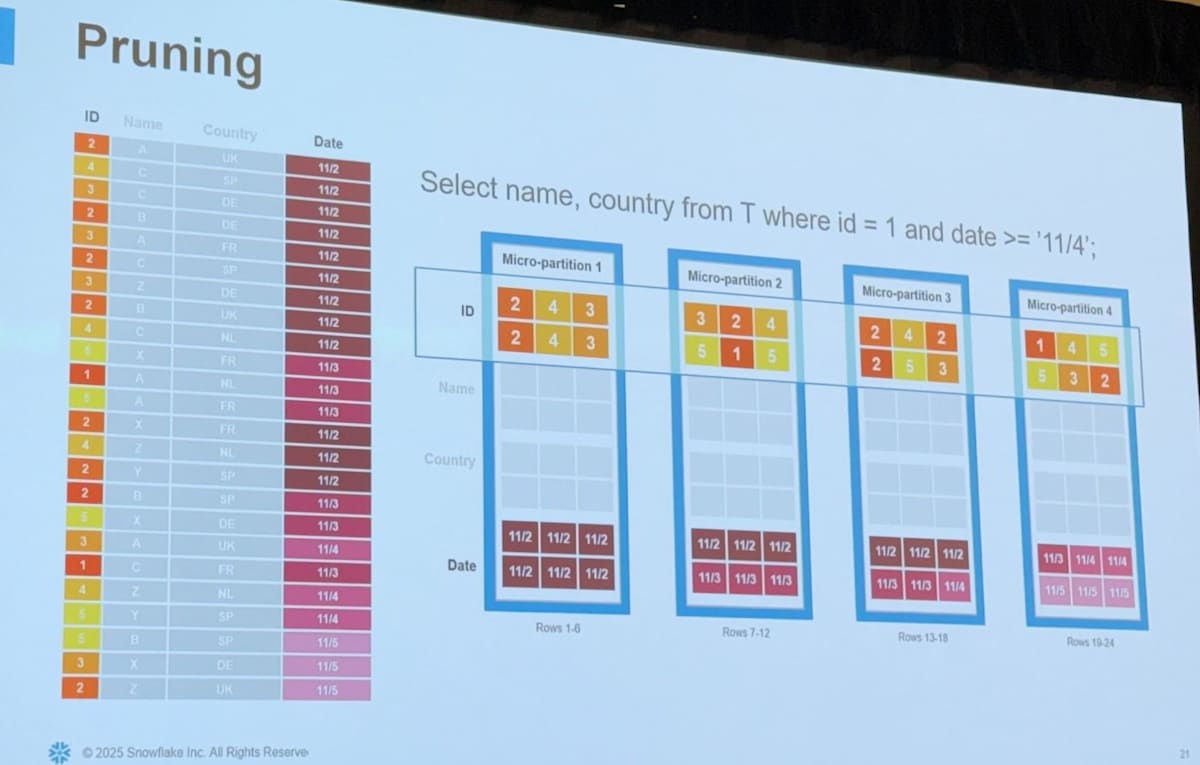
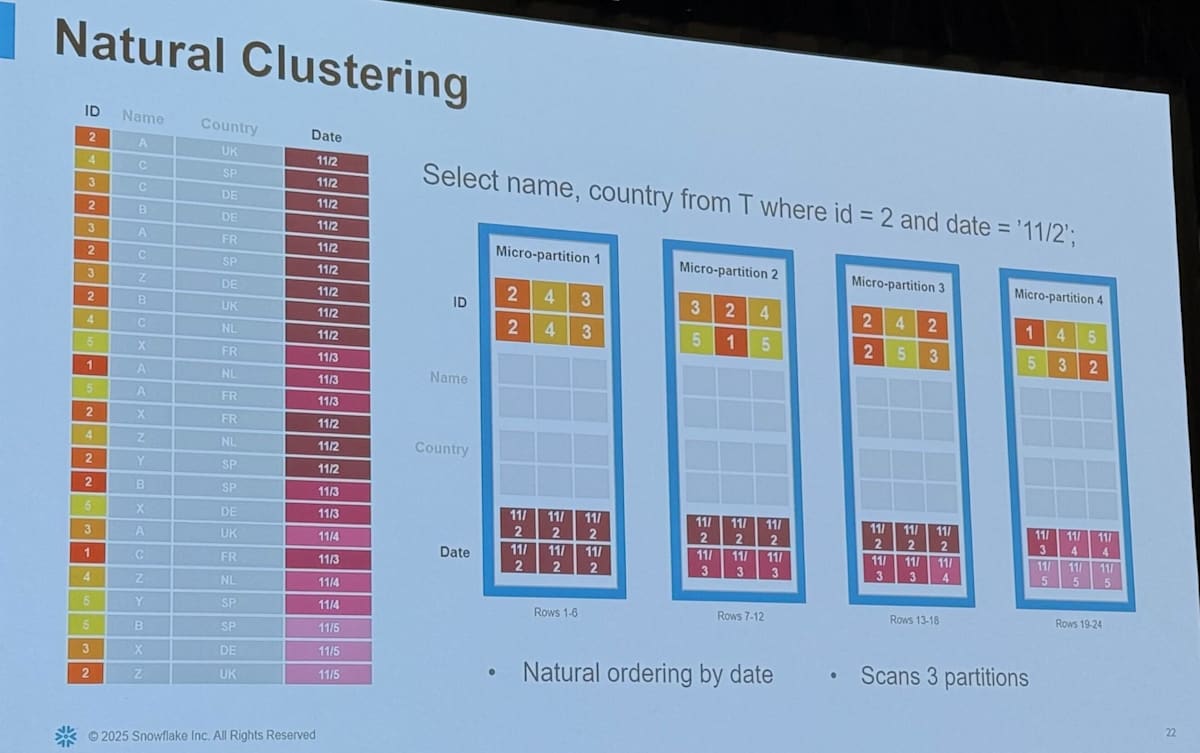
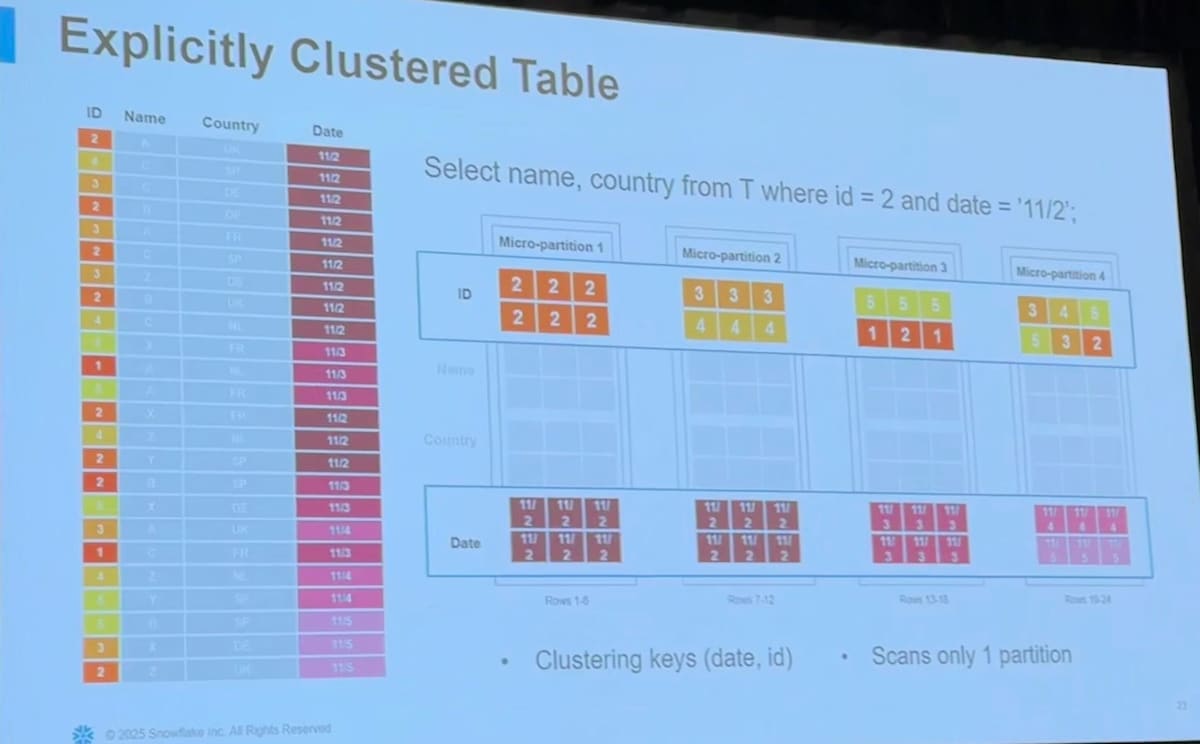
適切な Clustering が Partition Pruning に役立つことがよくわかると思います。
Search Optimization Service
Search Optimization Service (SOS) は大規模なテーブルに対する選択的な検索などのクエリのパフォーマンスを向上させるための仕組みです。Search Access Path という別のデータ構造を維持管理するようにすることで、検索クエリで Partition Pruning を可能としパフォーマンス向上することを目指します。

詳細は以下のブログでまとめているのでこちらをご覧ください。
Query Acceleration Service
Query Acceleration Service (QAS) は warehouse size を変更することなく、動的にウェアハウスをスケールアウトさせることで並列実行によるパフォーマンス向上を目指す機能です。 "oversized" なクエリの影響を減らすことができます。

Query Performance Common Patterns
クエリパフォーマンスに問題が発生するパターンとしてはいろいろありますが、まず大きく分けると「コンパイルが長い」パターンと「実行時間が長い」パターンがあります。
それぞれ、何が原因でどのように対応が可能かが見ていきましょう。
Large Compilation Time
まず最初にクエリのコンパイル時間が長いパターンが紹介されました
- symptom
- クエリWarehouseの全体のうち、コンパイルが占める割合が多いケース
- 例えば50%以上がコンパイルなど
- How to identify
- account_usage.query_history で execution_time と compilation_time を比較する
- Factors & Causes
- テーブルのデータ量
- 大量の small files
- small inserts を大量に行っている場合、小さいMPが大量に存在してしまう
- 多数のカラム
- ビューのネストが深さ
- ロール階層の深さ
- Expression の数や複雑さ
- Local filter での Pruning
- High concurrent workload in the Multi-tenant Service Cluster
- Best Practice
- Auto Clustering により小さいファイルを大きなファイルに Compaction すると Pruning が改善し得る
- カラム数はなるべく減らす(100以下など)
- ビューのネストはなるべく減らす
- ロールの階層はなるべく浅くする
- クエリをなるべくシンプルにする
- VPS Account を使う
Long Execution Time
次にクエリの実行時間が想定より長かったり、過去の実行履歴と比較して長いパターンです。
こちらはかなり様々なパターンがあるため、それぞれについて深掘って紹介されました。
- Long TableScan
- OOMs & Spillage
- Execution Plan
- Join Explosion
- Join Order
- Cardinality Estimation
Long Table Scan
- symptom
- TableScan Operator がボトルネックになりクエリ実行時間が長いパターン
- TableScan はクエリのライフサイクルの中で最も早く実行されるもので、スキャンが必要なファイル数に比例して TableScan の時間も長くなる
- → 基本的にはMPの数を減らすのが大事
- How to identify
- account_usage.query_history を利用し、
partitions_scannedやpartitions_totalで partition pruning の効率を確認する -
get_query_operator_stats(<query id>)を利用して、operator_statistics:pruning:partitions_scannedやoperator_statistics:pruning:partitions_totalで partition pruning の効率を確認する
- account_usage.query_history を利用し、
- Factors & Causes
- テーブルのMPの数
-
c1 between 100 and 200などのような Local filters の適用- Local filter はテーブルに直接適用するような filter というニュアンスの模様
- 集計後の結果に対する filter などではなく、 TableScan 時に適用できるような Filter のこと
- Local filter の選択性が高いかどうか
- Local filter で使われているカラムでよくクラスタリングされているかどうか
- Filter pushdown が発生するかどうか
- 関係する行が多数のMPに渡って分布しているかどうか
- Warehouse キャッシュからのスキャンができるか
- Best Practice
- Auto Clustering で、 selective local filters に利用されているカラムを clustering key として設定する
- 追加可能な filter は追加する
- local filter で使う expression は複雑なものではなくなるべく simple にする
- これにより filter pushdown が可能になる
- 例えばサブクエリが入っていると pruning ができなかったりする
- クエリを書き換えて、 filter pushdown が encourage/force されるようにする
- QAS (Query Acceleration Service) の利用
- On demand で動的に計算リソースをスケールさせることができるサービス
- TableScanなどを簡単に並列化して実行できるようになる
- Warehouse のサイズを上げることなくクエリの実行時間を短くすることができる
- best use case
- the query is ad-hoc and/or exploratory query
- Its underlying data is unpredictable
- The query has large scans and selective filters
OOMs & Spillage
- symptom
- Query consumes more Memory than what local warehouse can provide, triggering spillage to local and/or remote DISK, which may then hit Out of Memory (OOM) when not respond quick enough to get local/remote disk, often the query is then retried
- How to identify
- account_usage.query_history で
bytes_spilled_to_local_storageとbytes_spilled_to_remote_storageを見れば良い - query stats で spillage に関するところの数値を確認すれば良い
- account_usage.query_history で
- Factors & Causes
- Concurrency of workload/queries
- Large amount of data processed
- Large intermediate results
- Large table joins
- Window functions against large data
- Large aggregations
- Large sorting
- Recursive CTEs
- Warehouse size configurations
- Best Practice
- Warehouse の並列実行数を減らす、Multi Cluster Warehouse でクラスター数を増やす、ワークロードを分ける
- Partition Pruning の効率を上げる
- 適切な Auto Clustering
- Opting in simple expressions on the local filter over complex expressions
- Split the query using temp table to store large intermediate result, i.e., from large table joins
- Increase warehouse size to provide more memory
- Note
- Memory Expensive Operator は具体的には何か?
- Hash Join Builds
- Sort
- Aggregation (Grouping Sets)
- Window Functions
- Recursive CTEs
- Memory Expensive Operator は具体的には何か?
Execution Plan: Join Explosion
- symptom
- When the intermediate result on the join operator on 2 tables ( or branches of joins ) produces more output than the large side of the Join.
- How to identify
- get_query_operator_stats で
operator_statistics:output_rows / operator_statistics:input_rowsが 10 以上など大きい値になっているかを確認すればOK
- get_query_operator_stats で
- Factors & Causes
- Join で利用するテーブルのデータが大きさ
- Join filter が無く、 Cartesian Join となってしまているケース
- 100万行のテーブルと100万行のテーブルを Cartesian Join すると1兆行の結果となってしまう
- Local filter がなかったり、filterが selective でない場合
- Non-unique key での Join は爆発して output の行数が大きくなりやすい
- 片方のテーブルの各行が、もう一方のテーブルの複数行とマッチしてしまうため
- 非効率な join order
- Best Practice
- filter を追加し、読み込むデータをなるべく減らす
- join key を追加する
- join key を変更するか、 non-unique key の distinct をなるべく選択する
- small/selective table をまず先に join する
- クエリを書き換える
- filter pushdown を強制できるような書き方をし、読み込むデータを早期に減らす
- Disjunctive join は union にする
- temp table を利用し中間結果を一旦保存する
Execution Plan: Join Order
- symptom
- When the BUILD side of hash join is bigger than PROBE side, the join order usually has slower performance
- これは Spillage や OOMs に繋がったり、Joinが遅くなったりすることにつながってしまう
- How to identify
- Query Profile で Operator のグラフの形を見て見ればOK
- Snowflake の Optimizer は "Right Deep Join Tree" を好みます
- 右下に向かって深くなっていくようなクエリプランの方が良いということ
- Join order heuristics が star schema に最適化されている
- 小さい dimension を build side にし、大きい fact を probe side にするのを好む
- この方法の方がクラスタのメモリを有効活用でき、またクラスターノードをうまく並列に利用しやすい
- 逆に Left Deep Join Tree だとより多くのメモリが必要となり、クラスターノードの並列性?が下がってしまう
- Factors & Causes
- Cardinality estimation being off
- Join explosion
- Small table with big num of MPs
- Mission Join keys
- Best Practice
- 複雑な predicate expressions は見直す(filter pushdown)
- 小さいテーブルの join key を見直す
- 複雑で深くネストされたサブクエリを見直す
- Auto Clustering や SOS が使えるかどうか確認する
- Simplify, Simplify, Simplify
Execution Plan: Cardinality Estimation
- What is Cardinality Estimation?
- Cardinality Estimation とは、 query optimizer が利用するプロセスの一つです
- クエリもしくはクエリの一部が返す行数を予測するために使われます
- データの統計と、ヒューリスティックなルールを用いて予測はおおなわれます
- Cardinality Estimation が行われるオペレーターには以下があります
- TableScan
- Local filter: equal, inequality, range, expression
- Join filter
- Aggregation
- Variant subcolumn
- symptom
- cardinality estimation がうまくいかず、特定のオペレーターの返す行数が過小もしくは過大評価され、クエリが非効率になる
- 具体的には Join Order やリソースの配分などが最適で無くなってしまうおそれが出てきます
- Best Practice
- Local filter で利用されている列で Clustering する
- これにより MP でより意味のあるデータの統計が取れるようになる
- Expression はなるべくシンプルに
- String よりも Numeric などのデータ型を使う
- データ型を変換すると、Expressionの評価が速くなったり、NDVの推定がよくなる
- Variant の要素よりも relational なカラムを利用する
- Join を複数に分割する
- Simplify
- Local filter で利用されている列で Clustering する
Query Performance Best Practices
後半ではパフォーマンス改善のベストプラクティスのサマリーが紹介されました。
キャッシュの利用
適切なキャッシュの利用はパフォーマンスに大きな影響があるため、非常に重要になります。
Snowflake には
- Query Result Cache
- Data Cache / Warehouse Cache
- Metadata Cache
の3つがあるため、それぞれの精子を利用して理解することが大事です。
こちらについては別の記事で解説しているので詳細はそちらに譲ろうと思います。
適切な機能の利用
Snowflake においてパフォーマンス向上に役立つ機能がたくさんあります。
- Auto Clustering
- Materialized View
- Search Optimization Service (SOS)
- Query Acceleration Service (QAS)
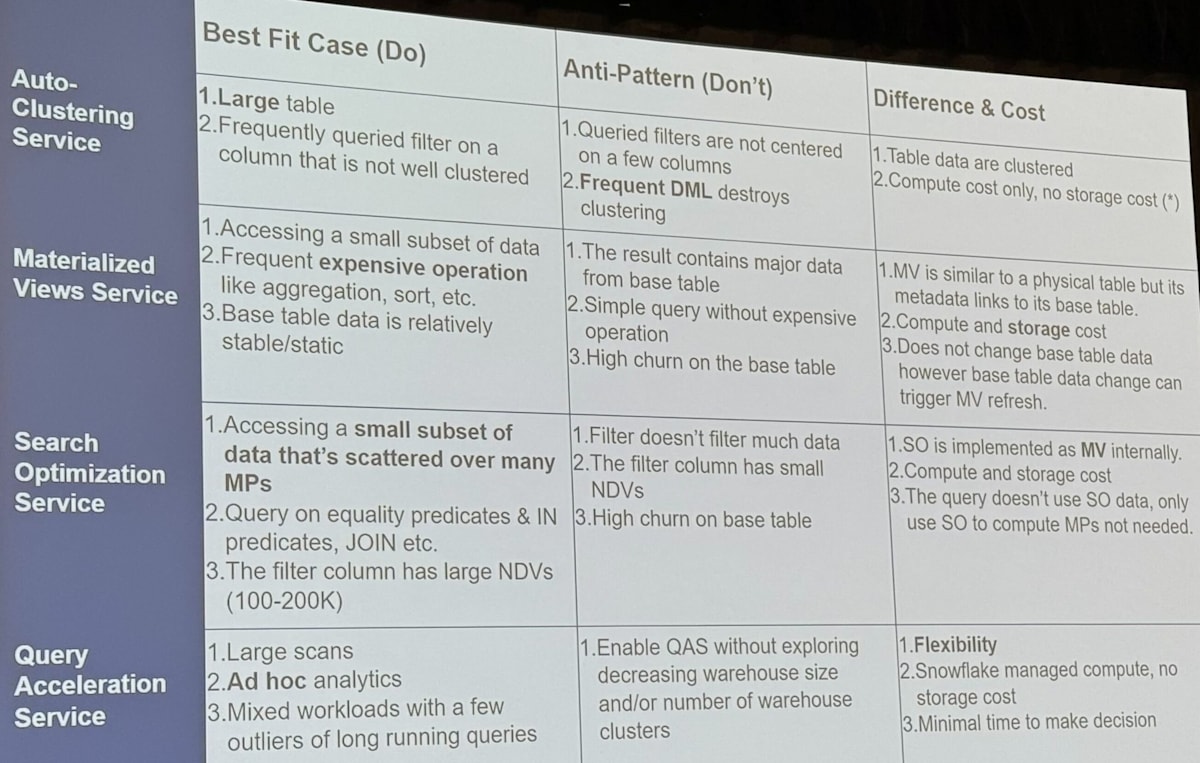
ただどれも銀の弾丸ではなく適切に性質を理解して利用することが大事で、 Best fit cast と Anti-pattern が紹介されました。
これらの機能の比較については @Taro_CCCMK さんがすでにわかりやすい記事を書いてくださっているので、こちらもぜひご覧ください。
Best Practices
最後にパフォーマンス改善のベストプラクティスとして
- Schema/RBAC Design
- Pruning - Apply Predicates Early
- Skew Handling
- Known Anti-Patterns
- Other Considerations
にわけて紹介されました。

Recap & Summary
そして最後にまとめとして "S.I.M.P.L.E" の原則としてまとめられました。
パフォーマンス改善においても "Simplify" が大事だよということが非常に強調されていました。

まとめ
Snowflake における Query のパフォーマンス改善のためのプラクティスが幅広く紹介された非常に面白いセッションでした!
最後に "Simplify, simplify, simplify" と、パフォーマンス改善のためにもシンプルさが大事というメッセージが強調されていたのが印象的です。本セッションで紹介された知見を身につけ Snowflake を最大限に活用していきましょう!!

Discussion