はじめに
こんにちは!ナウキャストのデータエンジニアのけびんです。
Snowflake での select のクエリを最適化するためには「不要なファイル(partition)を読み込まないようにする」、つまり "partition pruning" をいかに活用できるかが大事なポイントの一つです。
実は where 句の条件でサブクエリを利用しているとプルーニングが効かないという事象が知られています。本記事ではこの現象がなぜ起きるのかを解説するとともに、対策方法を2つ紹介します。
まとめ
- クエリコンパイルは Cloud Service Layer で行われる
- Partition Pruning はクエリコンパイルの中で実行される
- 一般にサブクエリは計算しないと結果が分からないため、サブクエリによる絞り込みは Partition Pruning と相性が悪い
- サブクエリを使わないようにクエリを分割し変数などを使うと Pruning が効くようになる
- またサブクエリを使った条件であっても Metadata Cache を利用できるものであれば Partition Pruning が可能
dbt incremental model とサブクエリ
まずはどういった場面で where 句の条件でサブクエリを利用していたのかを簡単に紹介します。
dbt incremental model では
select
*
from {{ ref('app_data_events') }}
{% if is_incremental() %}
where data_date > (select max(data_date) from {{ this }} )
{% endif %}
というようなクエリを書くことがよくあります。
(select max(data_date) from {{ this }} ) のサブクエリで対象のテーブルの最新の日付を取得し、元テーブルのうちそれよりも最新のデータのみ参照して差分更新する、というわけです。
差分更新なので使うべきデータは全体ではなく、最新のデータのみになります。そのためテーブルはフルスキャンではなく、 partition pruning を効かせ必要なデータだけを読み込めば良いはずです。
しかし以下の記事などに書かれているように、サブクエリを利用すると partition pruning が効かなくなってしまうことがあることが知られています。
Not all predicate expressions can be used to prune. For example, Snowflake does not prune micro-partitions based on a predicate with a subquery, even if the subquery results in a constant.
https://docs.snowflake.com/en/user-guide/tables-clustering-micropartitions#query-pruning
This happens when the evaluation of a constant expression can not be performed at the compile time, in which the partition pruning is performed. This is due to the complex subquery against the clustered key TR_CALENDAR_D_KEY in the WHERE clause.
Snowflake Knowledge Base Articles - Pruning is not happening when using Subquery
検証データ・設定
まずは現象を再現するために検証用のデータを用意しましょう。以下のような POS データを模したテストデータを利用します。
| data_date | store_id | sales |
|---|---|---|
| 2020-01-01 | 12 | 5288091600886742778 |
| 2020-01-01 | 28 | 3308066933530881735 |
| ... | ... | ... |
ある日付にある店舗でいくら売れたか、という簡単なトランザクションデータです。このテーブルから、最新の日付の総売上を取得したい場合、以下のようなクエリを書くことになるでしょう。
select
data_date,
sum(sales)
from pos_sample_1
where data_date = (select max(data_date) from pos_sample_1)
group by data_date;
dbt incremental model とは厳密には違いますが、「サブクエリでフィルタリングする」という点で構造は同じです。
このクエリは最新の日付が含まれる partition のみ読み込めば良いはずなので、 partition pruning が効いてほしいですよね。しかし実際には細かい条件によって pruning が効いたり効かなかったりします。
pruning が効かない状況を再現
data_date 列を varchar で用意していると pruning が効きません。
まずは実際にこれを確認しましょう。以下のクエリで pos_sample_1 というテーブルを用意します。
create or replace table pos_sample_1 (data_date varchar, store_id int, sales int) as
select
to_char(dateadd(day, trunc(seq4()/100000), '2020-01-01'::date)) as data_date,
seq4()%100000 as store_id,
abs(random(123)) as sales
from table(generator(rowcount => 100000*1000))
order by data_date, store_id;
これに対して以下のように最新の日付に対する総売上を求めるクエリを実行して Profile を見てみましょう。
select
data_date,
sum(sales)
from pos_sample_1
where data_date = (select max(data_date) from pos_sample_1)
group by data_date;
すると、以下のように2つの step で実行されていることがわかります。

- 左側 Step1: サブクエリ
(select max(data_date) from pos_sample_1)の部分 - 右側 Step2: 集計のクエリ
-
Filter [2]のノードは以下の通り step1 の結果でフィルターする感じになっています

-
この Profile を見ると、パフォーマンス的に問題になるのは以下の二点です。
- Step2 において partition pruning が効いていない
- 64/64 全ての partition がスキャンされていることがわかります
- 今回のテストテーブルは小さいですが、大きいテーブルだとここで時間がかかることになります
- Step1 において集計処理がされていること
- よく「Snowflakeではパーティションごとに最小値・最大値などのメタデータ・統計情報を収集している」と言いますが、テーブルの
data_dateの最大値を求めるというのはまさにこのメタデータを利用できそうです - しかし実際には集計の計算が動いてしまっています
- よく「Snowflakeではパーティションごとに最小値・最大値などのメタデータ・統計情報を収集している」と言いますが、テーブルの
なぜこの二点が起きてしまっているかを理解することで、どうすればこれを解決しクエリを最適化できるかがわかるようになります。
Pruning と Compile
まずはなぜ Step2 で Pruning が効かなかったのか?を見ていきます。
Snowflake のクエリコンパイル
Snowflake がクエリを実行する流れを確認しましょう。

https://www.linkedin.com/pulse/query-lifecycle-snowflake-minzhen-yang-7mbfc/ より
-
- Query を Snowflake が受信する
-
- Query Result Cache を確認し、存在したら直ちに結果を返す
-
- Query を Compiler や Planner、 Optimizer が確認し処理する
-
- Virtual Warehouse が実際にクエリを実行する
-
- 計算結果を返す
このようにクエリのコンパイルや最適化は Step3 として Cloud Service Layer で実行されていることがわかります。
次にクエリのコンパイルの中身も見てみましょう。以下のような手順で実行計画が作られます。
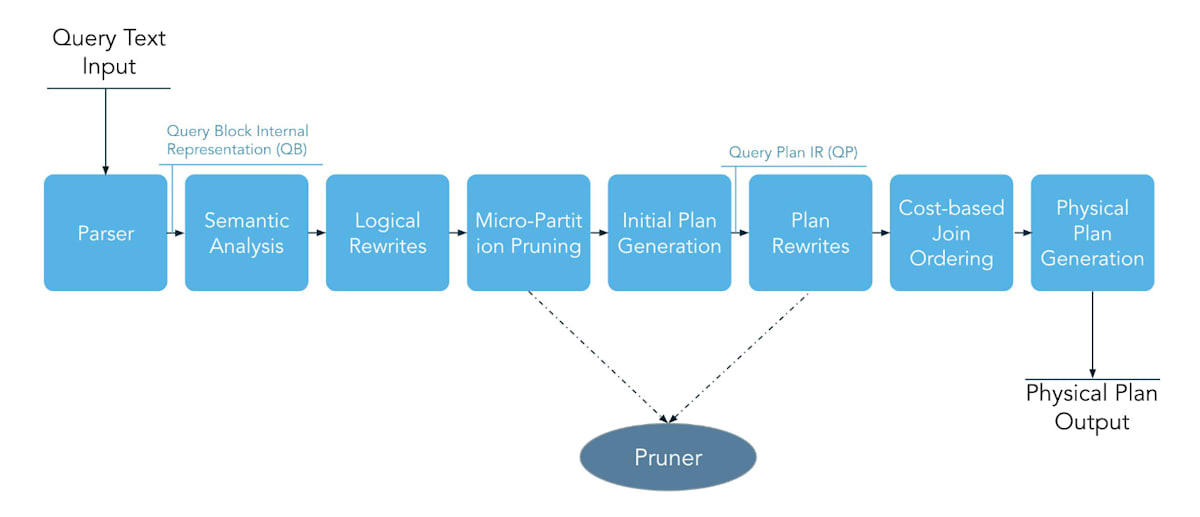
https://youtu.be/CPWn1SZUZqE?si=vpirhGjKmnT-OCE9&t=1549 より
これらの重要なポイントは
- クエリコンパイルは Cloud Service Layer で行われること
- コンパイルの一部として "Micro Partition Pruning" が含まれる
という点です。
つまり、 partition pruning を行うためには Cloud Service Layer でコンパイル時(実際の計算前)にそれに足る情報が得られる必要がある ということになります。
実験:定数で条件指定
Pruning と Compile の関係を踏まえると、「サブクエリを使っていたため、クエリコンパイル時にはフィルター条件が定まらず、Partition Pruningを行えていなかった」と理解できます。
実験として、最新の日付をリテラルで指定してみましょう。
select
data_date,
sum(sales)
from pos_sample_1
where data_date = '2022-09-26'
group by data_date;
このようにすることで、クエリコンパイル時に pruning する条件が分かるようになるため、partition pruning が効くことになります。実際に Profile で以下の通り確認できます。

解決策①:クエリの分割
直接リテラルで指定できれば苦労はしません。毎回テーブルの最大の日付で動的に絞り込みたい、というケースは多々あるでしょう。
サブクエリを使っていると計算してみないとフィルター条件が定まらない、ということが根本原因なので、事前に計算しておければ問題ないはずです。つまりクエリを分割ししてしまえばよいわけです。
具体的にはサブクエリの結果を一旦変数に代入し、それを where 句で利用すれば良いです。こうすることで、前節の実験と同様に定数で条件を指定したことになり Pruning が効くようになります。
set data_date_max = (select max(data_date) from pos_sample_1);
select
data_date,
sum(sales)
from pos_sample_1
where data_date = $data_date_max
group by data_date;
dbt であれば run_query を用いてサブクエリを事前に実行し、その結果を変数に格納したのちに、メインのクエリからはその変数を参照するように変更すれば良いです。
これらのクエリ分割の対応によりサブクエリを無くすことで、フィルター条件には定数を利用するようになるため、問題が解決します。
Metadata Cache
そもそもサブクエリとして実行していた、 select max(data_date) from pos_sample_1 は単なるカラムの最大値を求めるシンプルなものでした。
これは Cloud Service Layer で収集されているメタデータから取得できそうに思えます。そう考えるとコンパイル時にこのサブクエリの結果は分かってもおかしくないはずで、 partition pruning が効かなかったのも不思議に思えます。
実はこれは Snowflake におけるキャッシュの一つである Metadata Cache の仕様によるものです。
Snowflake の Metadata Cache おさらい
データ型によって "METADATA-BASED RESULT" で cloud service layer で返せるかどうかが変わります。
詳細は以下のブログを参照してください。
データ型によって挙動が変わる事を確認します。まずはテスト用のデータを用意しましょう。
create or replace table cache_test (id int, code varchar, name varchar) as
select seq8(), 'code-' || seq4()%100, randstr(10, random())
from table(generator(rowcount => 1000000));
この時、以下のような Int 型の id 列の最小値・最大値を求める以下のクエリは、 "METADATA-BASED RESULT" となり、 Metadata Cache が使われていることがわかります。つまり Cloud Service Layer でメタデータのみを利用し warehouse を動かさなくても結果が得られるということです。
select min(id), max(id), count(*) from cache_test;

しかし、 Varchar 型の code 列の最小値・最大値を取得するクエリを実行してみると、以下の通り集計のクエリが Warehouse で普通に実行されていることがわかります。
select min(code), max(code) from cache_test;

このように統計情報から計算できそうなクエリでも、データ型によって挙動が変わるのです。
同様な検証を行うと NUMBER, BOOLEAN, DATE, TIME および各 TIMESTAMP 型ではメタデータを利用し結果を得られますが、 VARCHAR, BINARY, FLOAT型ではメタデータを利用できず集計処理が走ってしまうことがわかります。
日付を表すカラムでは VARCHAR 型ではなく DATE 型を利用しておくことで、最適化がされる可能性が増えるわけです。またそもそも DATE 型に特化した演算なども使いやすくなるため、あえて VARCHAR で保持しておく理由もあまりないでしょう。
解決策②:データ型を変更する
実は pos_sample_1 テーブルでは data_date 列を varchar 型で定義されていました。
その結果、 select max(data_date) from pos_sample_1 というサブクエリは "METADATA-BASED RESULT" は利用できず、毎回集計処理が必要だったというわけです。
更にこれがコンパイル時にはフィルター条件が定まらないことに繋がり、 Pruning ができなかったということになります。
そこで、 data_date 列を date 型で定義し直した pos_sample_2 テーブルを作ってみましょう。
create or replace table pos_sample_2 (data_date date, store_id int, sales int) as
select
dateadd(day, trunc(seq4()/100000), '2020-01-01'::date) as data_date, -- to_char を無くす
seq4()%100000 as store_id,
abs(random(123)) as sales
from table(generator(rowcount => 100000*1000))
order by data_date, store_id;
この新しいテーブルで同様なクエリを実行しましょう。
select
data_date,
sum(sales)
from pos_sample_2
where data_date = (select max(data_date) from pos_sample_2)
group by data_date;
するとprofileは以下のようになっており、サブクエリを使っていても Pruning が効いていることが分かります。

まとめ
改めてまとめです。 Partition Pruning はいつでも効くわけではないため、 Query Profile などで状況を確認しながら Snowflake の性能を最大限引き出せるようにしていきましょう💪
- クエリコンパイルは Cloud Service Layer で行われる
- Partition Pruning はクエリコンパイルの中で実行される
- そのため Compile 時にフィルター条件が確定しないと Partition Pruning は実行できない
- 一般にサブクエリは計算しないと結果が分からないため、サブクエリを利用したフィルター条件を利用していると Partition Pruning は実行できない
- サブクエリの結果を変数に代入する形でクエリを分割し、フィルター条件ではその変数を参照する形にすると Pruning が効くようになる
- サブクエリを使った条件であっても Metadata Cache を利用できるようなサブクエリであればその結果はコンパイル時に分かるため、 Pruning は効く
- Min/Maxを取るようなシンプルなクエリであってもデータ型によって Metadata Cache を利用できるかは変わる
- 特に Varchar の場合 Metadata Cache が使えないため、日付を表す文字列は date 型で保存しておくのがおすすめ

Discussion