Snowflakeパフォーマンス最適化機能クラスタリングキー & Search Optimization & Query Acceleration
はじめに
SnowVillageのUnConference第五回イベントで、けびんさんのSOS検証記事の解説LTを聞いた事が、この記事を書くきっかけとなりました。
その際に紹介いただいた以下の記事とその際の質疑応答を通じて自分の不勉強さを痛感し、自分でもちゃんと学ぼうと思い、改めて仕様の理解と実際の検証結果と共にこの記事にしました。
各機能の詳細な説明はけびんさんや諸先輩方の記事を参考にいただく事でより深く理解が出来ると考えています。この記事ではそれらの各機能を理解しつつ、その全体像を自分なりの考え方で体系化し、またそれらについてTPC-Hのデータを用いたハンズオン形式にすることでステップバイステップで、どのような効果があるかを比較した結果を加えています。
各機能を含めた全体像やそのパフォーマンス効果について、皆様の理解の助けになればと考えています。
Snowflakeパフォーマンス最適化機能の比較と活用戦略
Snowflakeのアーキテクチャと最適化機能の基本概念と特徴比較
Snowflakeは「Cloud Services」「Query Processing」「Database Storage」の三層アーキテクチャで構成されており、パフォーマンス最適化機能もこの構造に沿って実装されています。最適化機能の特徴と相互関係を理解することで、効果的なパフォーマンスチューニングが可能になります。
個々の機能を描いた記事がある一方で、これらの全体像やその関係性は分かりづらい点もあり、各公式ドキュメントを参考に以下のような図表にまとめました。
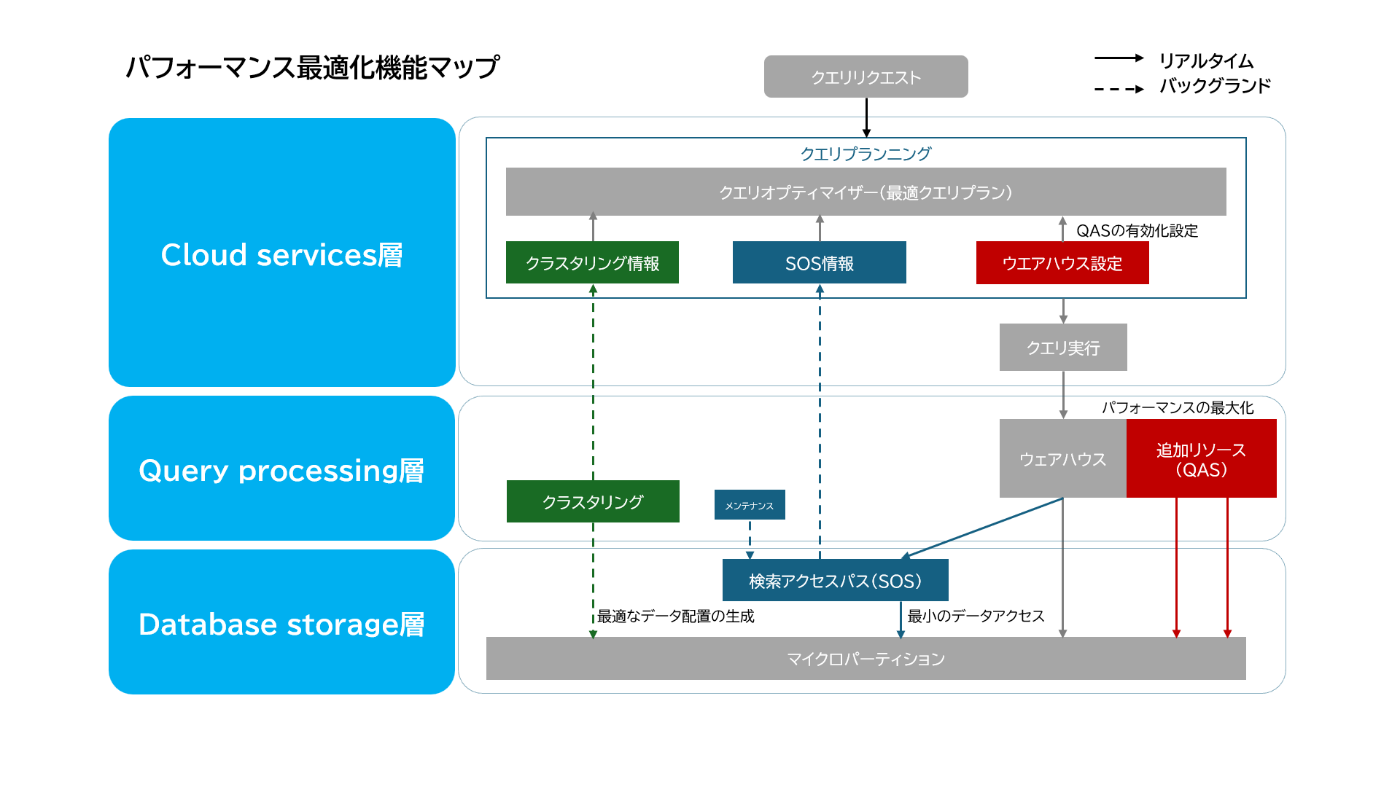
主要特性比較表
| 比較項目 | クラスタリングキー | Search Optimization (SOS) | Query Acceleration (QAS) |
|---|---|---|---|
| Cloud Services層 | クラスタリング情報をオプティマイザが活用 | SOS情報をオプティマイザが活用 | ウェアハウス設定とQAS適用判断 |
| Query Processing層 | 再クラスタリング処理 | メンテナンス処理 | 追加リソースによる実行支援 |
| Database Storage層 | マイクロパーティションの物理的配置 | 検索アクセスパスの構築・格納 | - |
| 最適化対象 | マイクロパーティション構造 | ポイントルックアップ | 大規模スキャン処理 |
| データ量目安 | 1TB以上/10億行以上 | 100GB以上 | 任意のサイズ |
| 主な用途 | 範囲検索/結合処理 | 等価検索/部分文字列検索 | アドホック分析/複雑な集計 |
| 設定単位 | テーブル単位 | テーブル/列単位 | ウェアハウス単位 |
| 主な作用対象 | データの物理的配置 | 検索アクセスパス構造 | コンピュートリソース |
| 最適化特性 | 静的(物理構造最適化) | 準静的(アクセスパス最適化) | 動的(実行リソース最適化) |
| コスト要因 | 自動再クラスタリング | ストレージ+構築コスト | スケールファクター |
| 効果持続性 | 高(データ更新時のみ再構築) | 中(メタデータ随時更新) | 低(クエリ毎に調整) |
| メンテナンス | 自動再クラスタリング | データ変更時に自動更新 | 完全自動管理 |
| エディション要件 | 全エディション | Enterprise以上 | Enterprise以上 |
各機能の技術特性
クラスタリングキー
- アーキテクチャ上の位置: Database Storage層(物理構造)+ Cloud Services層(メタデータ)
- 動作メカニズム: 指定した列の値に基づいてマイクロパーティションを最適配置
- 評価指標: クラスタリング深度(平均スキャン深さ)、パーティション重複率
- 最適なカーディナリティ: 中程度(日付、カテゴリなど)
- 注意点: 高カーディナリティ列(顧客ID等)は再クラスタリングコストが高くなる
Search Optimization Service (SOS)
- アーキテクチャ上の位置: Database Storage層(検索構造)+ Cloud Services層(メタデータ)
- 動作メカニズム: 検索アクセスパス(値とマイクロパーティションの関連付け)を構築
- タイプ: EQUALITY(等価)、SUBSTRING(部分一致)、FULL_TEXT(全文検索)、GEO(地理空間)
- 評価方法: SYSTEM$ESTIMATE_SEARCH_OPTIMIZATION_COSTS関数でコスト見積もり
- 適用シナリオ: 高カーディナリティ列での等価検索、部分文字列検索が多い場合
Query Acceleration Service (QAS)
- アーキテクチャ上の位置: Query Processing層(実行)+ Cloud Services層(判断)
- 動作メカニズム: 大規模スキャンの一部を追加コンピュートリソースにオフロード
- 制御方法: QUERY_ACCELERATION_MAX_SCALE_FACTOR でリソース上限を設定
- 対象クエリ: 大規模スキャン + 選択的フィルター/集計処理を含むクエリ
- 判定方法: SYSTEM$ESTIMATE_QUERY_ACCELERATION関数で効果予測
最適化機能の選択指針
ユースケース別の推奨アプローチ
| シナリオ | クラスタリングキー | SOS | QAS | 推奨理由 |
|---|---|---|---|---|
| 日付範囲フィルタリングが主 | ✅ | ❌ | ✅ | 日付列のクラスタリングでスキャン量削減、QASで大規模集計高速化 |
| IDによるルックアップが主 | ❌ | ✅ | ❌ | 高カーディナリティID検索はSOSが最適、他の最適化は効果薄い |
| 複合条件(範囲+等価) | ✅ | ✅ | ✅ | 範囲条件はクラスタリング、等価条件はSOSで最適化、QASで処理加速 |
| アドホック分析が多い | ✅ | ❌ | ✅ | 基本的なクラスタリングでスキャン効率化、QASで予測不能クエリに対応 |
| 頻繁なデータ更新あり | ❌ | ❌ | ✅ | 更新が多いとクラスタリング/SOS維持コストが高く、QASのみ推奨 |
| BI/ダッシュボード用途 | ✅ | ✅ | ❌ | 予測可能なクエリパターンはクラスタリング/SOSで対応可能 |
機能選択のための意思決定フロー
-
大規模テーブル(1TB超/10億行超)か?
- YES → クラスタリングキーを検討
- NO → 次の判断へ
-
頻繁に使用される検索条件は?
- 範囲条件(日付範囲等)→ クラスタリングキー
- 等価条件(ID/コード等)→ SOS
- 複合条件 → 両方検討
-
ワークロードの特性は?
- アドホック/予測不能 → QAS
- 定型/予測可能 → クラスタリング+SOS
-
更新頻度は?
- 高頻度更新 → QASのみ
- 低頻度/読取主体 → クラスタリング+SOS
最適化戦略の実装ガイドライン
相互連携による最適化効果
これらの最適化機能は互いに補完し合うことでパフォーマンスを最大化します。
- クラスタリングキー + SOS: 範囲検索(クラスタリング)と等価検索(SOS)の両方に対応
- クラスタリングキー + QAS: データ量を削減(クラスタリング)し処理を高速化(QAS)
- SOS + QAS: 選択的検索(SOS)と複雑な集計(QAS)の両方を効率化
Snowflakeのパフォーマンス最適化は、データの物理的配置(クラスタリングキー)、アクセスパス構造(SOS)、実行リソース(QAS)という異なるアプローチで実現されており、それぞれが三層アーキテクチャの中で連携して機能します。
データ特性、クエリパターン、更新頻度などを考慮した上で、これらの機能を適切に組み合わせることで、最も効果的なパフォーマンス最適化を実現することが可能です。
各パフォーマンス機能の検証
それでは、実際にテスト環境を構築し、各最適化機能のパフォーマンスを検証していきましょう。
前提条件
- Snowflakeアカウント(Enterprise Edition以上)
- テスト用のデータベースとスキーマを作成する権限
- ウェアハウスを作成・変更する権限
まずはテスト用の環境を準備します。
-- 環境準備
USE ROLE SYSADMIN;
CREATE DATABASE PERFORMANCE_TEST;
USE DATABASE PERFORMANCE_TEST;
CREATE SCHEMA TEST;
USE SCHEMA TEST;
-- テスト用ウェアハウスの作成
CREATE WAREHOUSE PERFORMANCE_TEST_WH
WAREHOUSE_SIZE = 'SMALL'
INITIALLY_SUSPENDED = TRUE
AUTO_SUSPEND = 60;
USE WAREHOUSE PERFORMANCE_TEST_WH;
クラスタリングキーのパフォーマンス評価
まずは、クラスタリングキーの効果を検証します。Snowflakeのサンプルデータを使用して、クラスタリングキーの有無によるパフォーマンスの違いを測定します。
テスト準備
-- サンプルデータのクローン(TPCH SF1000:約1TB)
CREATE OR REPLACE TABLE LARGE_ORDERS
AS SELECT * FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF1000.ORDERS;
-- シャッフル版テーブル(クラスタリング未適用)
CREATE OR REPLACE TABLE LARGE_ORDERS_SHUFFLED
AS SELECT * FROM LARGE_ORDERS ORDER BY RANDOM();
-- クラスタリング適用版テーブル
CREATE OR REPLACE TABLE LARGE_ORDERS_CLUSTERED
CLUSTER BY (O_ORDERDATE)
AS SELECT * FROM LARGE_ORDERS_SHUFFLED;
クラスタリング状態の確認
クラスタリングの効果を確認するために、Snowflakeが提供するsystem$clustering_information関数を使用します。
SELECT
SYSTEM$CLUSTERING_INFORMATION('LARGE_ORDERS_CLUSTERED', '(O_ORDERDATE, O_CUSTKEY)') AS CLUSTER_INFO;
この関数は、テーブルのクラスタリング状態に関する詳細情報を返します。クラスタリング深度が低いほど、データが効果的にクラスタリングされていることを意味します。
クラスタリング状態の比較と解釈
初期状態(クラスタリング直後)の特徴
{
"total_partition_count" : 2621,
"total_constant_partition_count"
"average_overlaps" : 2620.0,
"average_depth" : 2621.0,
}
最終状態(最適化後)の特徴
{
"total_partition_count" : 2502,
"total_constant_partition_count" : 27,
"average_overlaps" : 7.976,
"average_depth" : 5.2398,
}
クラスタリング状態の比較分析
クラスタリング設定前後の主要指標比較
| 指標 | 適用前 | 適用後 | 改善率 |
|---|---|---|---|
| 総パーティション数 | 2,621 | 2,502 | 4.5%削減 |
| 最適化済みパーティション数 | 0 | 27 | 新規形成 |
| 平均パーティション重複率 | 2,620.0 | 7.976 | 99.7%改善 |
| 平均スキャン深さ | 2,621.0 | 5.2398 | 99.8%改善 |
各指標の技術的解釈
1. 平均スキャン深さ(average_depth)
- 適用前:2,621 → クエリ毎に平均2,621個のパーティションをスキャン
- 適用後:5.24 → スキャン数が約1/500に減少
理想値:5.0以下
2. パーティション重複率(average_overlaps)
- 適用前:完全重複状態(値=パーティション数-1)
- 適用後:8.0以下に改善
理想値:1.0以下
3. 最適化済みパーティション(total_constant_partition_count)
- 27個のパーティションが完全最適化状態
増加傾向が良好な状態
この状態変化から、クラスタリングキーの基本的な効果は確認できたと考えています。
クエリパフォーマンス測定
次に、日付範囲でのフィルタリングクエリを実行し、パフォーマンスを比較します。
-- キャッシュをクリア
ALTER SESSION SET USE_CACHED_RESULT = FALSE;
-- クラスタリング未適用テーブル
SELECT
COUNT(*) AS order_count,
SUM(o_totalprice) AS total_sales,
AVG(o_totalprice) AS avg_order_value
FROM large_orders_shuffled
WHERE
o_orderdate BETWEEN '1995-01-01' AND '1998-12-31'
AND o_custkey BETWEEN 1000 AND 50000;
-- クラスタリング適用テーブル
SELECT
COUNT(*) AS order_count,
SUM(o_totalprice) AS total_sales,
AVG(o_totalprice) AS avg_order_value
FROM large_orders_clustered
WHERE
o_orderdate BETWEEN '1995-01-01' AND '1998-12-31'
AND o_custkey BETWEEN 1000 AND 50000;
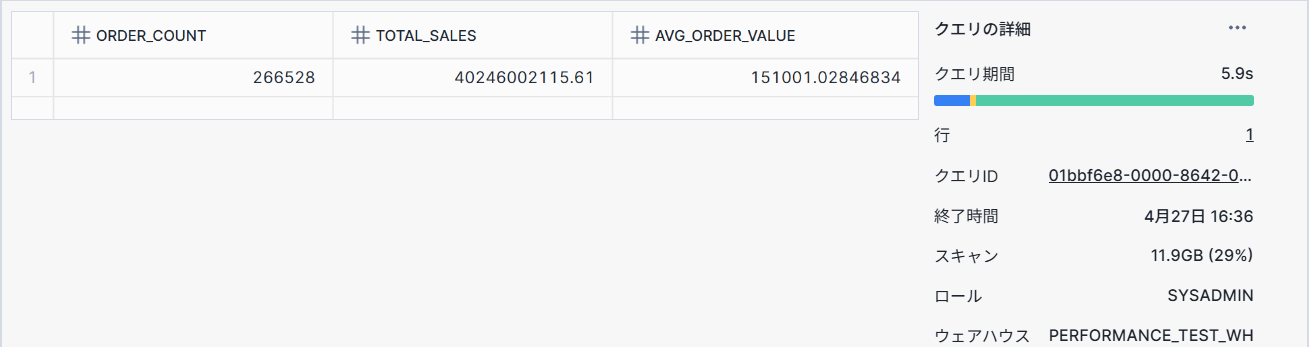

測定結果例:
- クラスタリングなし:5.9秒
- クラスタリングあり:2.5秒
クラスタリングキーを設定することで、2倍以上のパフォーマンス向上が見られました。またスキャンデータ量も大幅に減っていることも分かります。
これは、クラスタリングキーにより、不要なマイクロパーティションのスキャンを回避できたためと思われます。
注意:クラスタリングキーの5Byte制約
クラスタリングキーについてVARCHAR型項目に対する重要な制約があります。
それはVARCHAR型、BYNARY型の場合、先頭5byteのみに適用されるため、プルーニング効率が下がるという仕様です。
弊社もこれでパフォーマンス課題を出したこともあり、注意事項の一つです。
たとえば日付の文字型項目(YYYYMMDD)の場合、その先頭5Byteでソートされるため、プルーニング効率が下がってしまいます。
例:20250429 ⇒20250でソートされるため、2020501~09までが分割されない
DATE型等に変更すればよいのですが、そう簡単に定義変更出来ないケースも多いため、このような場合は、SUBSTRINGを用いる事で回避出来ます。
SUBSTRING(日付,3) YYMMD や SUBSTRING(日付,4) YMMDD など
またこの辺りの詳しい仕様は、Snowflakeの松崎さんの解説記事を読んでください。
Snowflake: クラスタリングの 5 バイト制限を正しく理解する
複合クラスタリングキー追加ケースの注意事項
たまに会員IDにクラスタリングキーを貼ると速くなるんじゃないか?と勘違いする社内メンバーもいるため、啓蒙の一つとしてバッドパターンとして紹介しておきます。
またこの辺りの詳しい仕様は、Snowflakeの松崎さんの解説記事を読んでください。
Snowflake: 複合クラスタリングキーの選定テクニック
-- 複合キー追加(日付+顧客ID)
ALTER TABLE large_orders_clustered CLUSTER BY (o_orderdate, o_custkey);
select system$clustering_information('large_orders_clustered', '(o_orderdate ,o_custkey)');
{
"notes" : "Clustering key columns contain high cardinality key O_CUSTKEY which might result in expensive re-clustering. Please refer to https://docs.snowflake.net/manuals/user-guide/tables-clustering-keys.html for more information.",
"total_partition_count" : 2599,
"total_constant_partition_count" : 0,
"average_overlaps" : 6.0385,
"average_depth" : 4.2135,
}
警告メッセージの技術的意味
"Clustering key columns contain high cardinality key O_CUSTKEY..."
- 根本原因: 顧客ID(O_CUSTKEY)のカーディナリティが極めて高い(ほぼユニークな値)
-
影響:
- クラスタリングのコスト増加
- データ更新時の再クラスタリング頻度が上昇
- ストレージ使用量も増加
上記のようなカーディナリティが高い項目についてのクラスタリングキーは効果が薄いことが多いです。
このような項目に対してはクラスタリングキーではなく、Search Optimization Service(SOS)の適用がより効果的と考えています。
と偉そうに言いながら、今回の検証でこのような'note'が付くことを初めて知ったのでクラスタリングキーを貼ったら、ちゃんとクラスタ情報は確認しようと思います。
Search Optimization Serviceのパフォーマンス評価
それでは、そのSearch Optimization Service(SOS)の効果を検証したいと思います。大規模なテーブルに対するポイントルックアップクエリを使用して、SOSの有無によるパフォーマンスの違いを測定します。
詳しい解説はけびんさんの記事を参照ください。
-- SOS適用版テーブルの作成
CREATE OR REPLACE TABLE LARGE_ORDERS_SOS CLONE LARGE_ORDERS_CLUSTERED;
ALTER TABLE LARGE_ORDERS_CLUSTERED ADD SEARCH OPTIMIZATION ON EQUALITY(O_CUSTKEY);
-- キャッシュをクリア
ALTER SESSION SET USE_CACHED_RESULT = FALSE;
-- クラスタ未適用テーブル
SELECT
COUNT(*) AS ORDER_COUNT,
SUM(O_TOTALPRICE) AS TOTAL_SALES,
AVG(O_TOTALPRICE) AS AVG_ORDER_VALUE
FROM LARGE_ORDERS_SHUFFLED
WHERE
O_ORDERDATE BETWEEN '1995-01-01' AND '1998-12-31'
AND O_CUSTKEY = 31756;
-- クラスタのみ適用テーブル
SELECT
COUNT(*) AS ORDER_COUNT,
SUM(O_TOTALPRICE) AS TOTAL_SALES,
AVG(O_TOTALPRICE) AS AVG_ORDER_VALUE
FROM LARGE_ORDERS_CLUSTERED
WHERE
O_ORDERDATE BETWEEN '1995-01-01' AND '1998-12-31'
AND O_CUSTKEY = 31756;
-- クラスタ+SOS適用テーブル
SELECT
COUNT(*) AS ORDER_COUNT,
SUM(O_TOTALPRICE) AS TOTAL_SALES,
AVG(O_TOTALPRICE) AS AVG_ORDER_VALUE
FROM LARGE_ORDERS_SOS
WHERE
O_ORDERDATE BETWEEN '1995-01-01' AND '1998-12-31'
AND O_CUSTKEY = 31756;
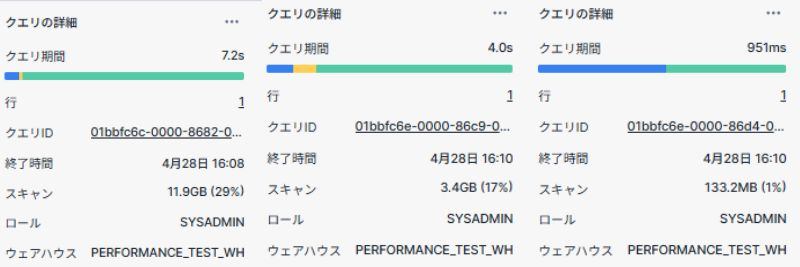
パフォーマンス検証結果
| 最適化手法 | ポイントルックアップ |
|---|---|
| 最適化なし | 7.2秒 |
| クラスタリングのみ | 4.0秒 |
| クラスタリング+SOS | 1.0秒 |
上記の結果を見るとクラスタリグキーを設定した上で、SOSを適用することで無地のテーブルに比べ、7倍以上速くなっていることが分かります。
もちろんコスト面などは充分に評価する必要がありますが、これは充分な効果と言えるのではないでしょうか?
適用ケースについて
Search Optimization Service(SOS)の詳細設定:カラム単位の最適化パターン
SOSはテーブル全体だけでなく、個々のカラムに対してきめ細かな最適化設定が可能です。ここでは主要な設定パターンとその実装方法を解説します。
カラム別最適化設定パターン一覧
| 最適化タイプ | 対象データ型 | 主なクエリパターン | 設定例 |
|---|---|---|---|
| EQUALITY | 数値/文字列 | WHERE col = value |
ADD SEARCH OPTIMIZATION ON EQUALITY(order_id) |
| SUBSTRING | 文字列 | WHERE col LIKE '%pattern%' |
ADD SEARCH OPTIMIZATION ON SUBSTRING(product_name) |
| GEO | GEOGRAPHY | WHERE ST_CONTAINS(geo_col, point) |
ADD SEARCH OPTIMIZATION ON GEO(location) |
| VARIANT | VARIANT | WHERE data:user.id = '123' |
ADD SEARCH OPTIMIZATION ON EQUALITY(data:user.id) |
ちなみにALTER TABLE customers ADD SEARCH OPTIMIZATION;としてパラメータを付けなかった場合、すべての項目についてEQUALITYで設定されてしまいます。結果として不要な項目への設定や適切ではない設定を行う事になり、無駄なストレージコストやメンテナンスコストが発生するため、項目ごとに適切な値を設定するようにしましょう。
1. 等価検索向け設定(EQUALITY)
実装例:
-- 単一カラム
ALTER TABLE sales
ADD SEARCH OPTIMIZATION ON EQUALITY(product_id);
-- 複数カラム
ALTER TABLE customers
ADD SEARCH OPTIMIZATION ON EQUALITY(last_name, email);
効果的なケース:
- 顧客IDや注文番号での検索
- 複合キーでの結合処理
- 高カーディナリティなカラムの検索
注意点:
- カーディナリティが低い(<100)カラムでは効果が限定的
- 頻繁に更新されるカラムはストレージコストが増加
2. 部分文字列検索向け設定(SUBSTRING)
実装例:
-- 特定カラム
ALTER TABLE product_descriptions
ADD SEARCH OPTIMIZATION ON SUBSTRING(description);
-- 全文字列カラム
ALTER TABLE documents
ADD SEARCH OPTIMIZATION ON SUBSTRING(*);
対応クエリ例:
SELECT * FROM logs
WHERE error_message LIKE '%connection timeout%';
制約事項:
- 先頭ワイルドカード(
LIKE '%text')には非対応 - 最大パターン長:128文字
3. 地理空間検索向け設定(GEO)
実装例:
ALTER TABLE locations
ADD SEARCH OPTIMIZATION ON GEO(coordinates);
対応関数:
ST_CONTAINSST_INTERSECTSST_WITHIN
効果測定クエリ:
EXPLAIN
SELECT * FROM locations
WHERE ST_DISTANCE(coordinates, target_point) < 1000;
4. VARIANT列向け設定
実装例:
ALTER TABLE json_data
ADD SEARCH OPTIMIZATION ON EQUALITY(data:user.id::string);
ネスト構造対応:
-- ネストされた要素の検索
ALTER TABLE nested_data
ADD SEARCH OPTIMIZATION ON EQUALITY(data:address.zipcode);
設定状態の確認方法
-- テーブル全体の設定確認
DESCRIBE SEARCH OPTIMIZATION ON sales;
-- 詳細な進捗確認
SELECT
"name",
"search_optimization",
"search_optimization_progress"
FROM INFORMATION_SCHEMA.TABLES
WHERE table_name = 'SALES';
設定解除の方法
-- 特定カラムの設定解除
ALTER TABLE sales
DROP SEARCH OPTIMIZATION ON EQUALITY(product_id);
-- 全設定解除
ALTER TABLE sales
DROP SEARCH OPTIMIZATION;
ベストプラクティス
-
段階的導入:
/* 初期設定後、効果を測定して拡張 */ ALTER TABLE sales ADD SEARCH OPTIMIZATION ON EQUALITY(product_id); -- 1週間運用後 ALTER TABLE sales ADD SEARCH OPTIMIZATION ON SUBSTRING(description); -
コスト予測:
SELECT SYSTEM$ESTIMATE_SEARCH_OPTIMIZATION_COSTS('sales'); -
監視の自動化:
CREATE TASK monitor_sos_cost WAREHOUSE = my_wh SCHEDULE = '1 DAY' AS SELECT SUM(search_optimization_bytes) / 1024 / 1024 AS size_mb, SUM(search_optimization_bytes) * 0.000023 AS estimated_cost FROM INFORMATION_SCHEMA.TABLES;
注意事項
- 大規模テーブルでの設定:TB級テーブルでは初期構築に数時間~数日を要する
- ストレージコスト:検索アクセスパスのストレージ使用量が通常の10-20%増加
- 更新頻度:高頻度更新テーブル(1分に1回以上)ではパフォーマンス低下のリスク
これらの詳細設定を活用することで、特定のクエリパターンに特化した最適化が可能になります。ただし、過剰な設定はストレージコストとメンテナンスコストを増加させるため、実際のクエリパターンを分析した上で必要な設定のみを適用することが重要です。
2025年4月のSOS機能のアップデート
2025年4月15日に、SnowflakeはSearch Optimization Service (SOS)の重要なアップデートをリリースしました。このアップデートにより、SOSはスカラー関数を含むクエリのパフォーマンスを向上させることができるようになりました。
機能概要と意義
スカラー関数(各呼び出しに対して単一の値を返す関数)を含む等価述語でもSOSの恩恵を受けられるようになりました。
これにより以下の効果が得られます
-
UPPER(),LOWER(),TO_DATE(),TRIM()など一般的な関数を使ったクエリでもSOSが有効 - データ変換後の検索条件にもインデックス的効果を発揮
- 前処理のないクエリでも直接高速化が可能
SOSアップデート前後の機能比較表
| 機能/対応クエリ | 2025年4月以前 | 2025年4月以降 |
|---|---|---|
等価述語 (=, IN) |
✅ | ✅ |
部分文字列検索 (LIKE, ILIKE) |
✅ | ✅ |
| 正規表現検索 | ✅ | ✅ |
| VARIANT/ARRAY/OBJECT型フィールド | ✅ | ✅ |
| 地理空間関数 | ✅ | ✅ |
| スカラー関数を含む等価述語 | ❌ | ✅ |
| 適用可能なユースケース | 単純条件のみ | 複雑な条件も対応可 |
実用的ユースケース
-
大文字小文字を区別しない検索
WHERE UPPER(customer_name) = 'JOHN DOE' -
日付形式変換後の検索
WHERE TO_DATE(order_date_str, 'YYYY-MM-DD') = '2025-01-01' -
文字列加工後の検索
WHERE TRIM(product_code) = 'ABC-123'
まとめと今後の実装提案
SOSのスカラー関数対応により、より多くのクエリパターンで最適化が可能になりました。既存のTPC-Hデータセットを用いた検証に加え、実際の業務データでも継続的に効果検証を行うことをお勧めします。
まとめ
このようなクラスタリングキーやSOSはデータへのアクセス効率を上げる事でクエリを高速化する機能です。一方で次の章で説明するQuery Acceleration Serviceはデータアクセス効率によるパフォーマンス向上ではなく、実行するウェアハウスにおけるクエリワークロードの向上によるパフォーマンスを向上させる機能です。
Query Acceleration Serviceの適用基準
QASを導入する前に、クラスタリングキーやSOSを適用する事が重要です。その上で各クエリに適切なサイズのウェアハウスを割り当てた上で、発生する長時間クエリを解決するためにQASを利用しましょう。
公式ドキュメントを読むとQASのメリットを受けるワークロードは以下と定義されています。
- アドホック分析。
- クエリごとのデータ量が予測できないワークロード。
- 大規模なスキャンと選択フィルターを使用したクエリ。
それならば、ウェアハウスを上げる方法でも良いように映りますが、私自身の考え方としては、そのユーザーやロールに割り当てられたワークロードから逸脱したクエリをウェアハウスやロールを分けるのではなく、その状態のままパフォーマンスを上げる方法と考えています。
ウェアハウスを上げてしまうと一部のワークロードのために全体の消費コストが上がりますし、ウェアハウス自身のサイズを動的に変えるのも運用作業が増えてしまいます。逆に恒常的にワークロードが上がっている場合は、素直にウェアハウスを上げたり、クラスタリングキーやSOSの出番と考えています。
ウェアハウスサイズ変更 vs QAS比較
とはいえ、コストの明確化で言えばウェアハウスベースで管理したくなる事も多いため、例えば以下のような判断基準でどちらを採用するかを検討すると良いかと思います。
| 項目 | QASスケールファクター8 | ウェアハウスサイズUP | ベストプラクティス |
|---|---|---|---|
| リソース拡張 | 動的(クエリ単位) | 静的(セッション中固定) | 予測可能ワークロードはサイズ変更 |
| コスト透明度 | 変動的(使用量に比例) | 固定(時間単位) | 厳密な予算管理が必要な場合はサイズ変更 |
| 適用クエリ | アドホック/不定期 | 定常的/高頻度 | 良くある80/20ルールなら双方併用 |
| パフォーマンス | 最大8倍加速 | ウェアハウスサイズで倍加速 | クリティカルクエリはQAS優先 |
| メンテナンス | 自動管理 | 手動調整必要 | 一時的な対応であればQAS優先 |
このような判断基準を設けつつも、どのように評価すべきかについて手探りになる事も多いですが、Snowflakeはこのような適用要否を判断するためのビューや関数を提供してくれています。
これらを利用することでQASの適用を安心して行えるようになります。
QUERY_ACCELERATION_ELIGIBLE ビューの活用
QUERY_ACCELERATION_ELIGIBLEはQASから最もメリットを受ける可能性のあるクエリとウェアハウスを識別します。ビューには、クエリごとに、Query Acceleration Serviceの対象となるクエリ実行時間が含まれます。
利用ケース
-- クエリベースでのQAS対象リスト
SELECT QUERY_ID,
QUERY_TEXT,
START_TIME,
END_TIME,
WAREHOUSE_NAME,
WAREHOUSE_SIZE,
ELIGIBLE_QUERY_ACCELERATION_TIME, -- QAS適用で短縮可能と推定される時間(秒)
UPPER_LIMIT_SCALE_FACTOR, -- ASが使用可能な最大スケールファクター(リソース拡張倍率)
DATEDIFF(SECOND, START_TIME, END_TIME) AS TOTAL_DURATION,
ELIGIBLE_QUERY_ACCELERATION_TIME / NULLIF(DATEDIFF(SECOND, START_TIME, END_TIME), 0) AS ELIGIBLE_TIME_RATIO --クエリ総実行時間に対する加速可能時間の比率
FROM
SNOWFLAKE.ACCOUNT_USAGE.QUERY_ACCELERATION_ELIGIBLE
WHERE
START_TIME >= DATEADD(DAY, -30, CURRENT_TIMESTAMP())
AND ELIGIBLE_TIME_RATIO <= 1.0
AND TOTAL_DURATION BETWEEN 10 AND 600
ORDER BY
ELIGIBLE_TIME_RATIO DESC
LIMIT 10;
-- ウェアハウスベースでのQAS対象リスト
SELECT
WAREHOUSE_NAME,
SUM(ELIGIBLE_QUERY_ACCELERATION_TIME) AS TOTAL_ELIGIBLE_TIME QAS適用で短縮可能と推定される合計時間(秒)
FROM SNOWFLAKE.ACCOUNT_USAGE.QUERY_ACCELERATION_ELIGIBLE
WHERE START_TIME >= DATEADD('DAYS', -1, CURRENT_DATE())
GROUP BY WAREHOUSE_NAME
ORDER BY TOTAL_ELIGIBLE_TIME DESC
LIMIT 10;
SYSTEM$ESTIMATE_QUERY_ACCELERATION 関数の活用
過去14日間に実行されたクエリに限り、この関数は、クエリが Query Acceleration Service のメリットを受ける資格があるかどうかを指定する JSON オブジェクトを返します。クエリがクエリアクセラレーションの対象である場合、出力には、クエリアクセラレーションのスケールファクターの推定クエリ実行時間が含まれます。
実際に弊社の本番環境でリストアップされたクエリの結果をサンプルとして紹介しておきます。
SELECT PARSE_JSON(SYSTEM$ESTIMATE_QUERY_ACCELERATION('01bbd36b-0000-8541-0000-27b92820dd7e'));
SELECT PARSE_JSON(SYSTEM$ESTIMATE_QUERY_ACCELERATION('01bbe9e0-0000-863f-0000-0f69ccb2e9ca'));
{
"estimatedQueryTimes": {
"1": 382,
"2": 275,
"3": 222 --スケールファクターの数値に応じて改善させるクエリ時間の推計
},
"originalQueryTime": 718.274,
"queryUUID": "01bbd36b-0000-8541-0000-27b92820dd7e",
"status": "eligible",
"upperLimitScaleFactor": 3 --最大効果が得られるスケールファクター上限値
}
{
"estimatedQueryTimes": {
"1": 196,
"10": 70,
"2": 145,
"4": 104,
"8": 76 --スケールファクターの数値に応じて改善させるクエリ時間の推計
},
"originalQueryTime": 343.301,
"queryUUID": "01bbe9e0-0000-863f-0000-0f69ccb2e9ca",
"status": "eligible",
"upperLimitScaleFactor": 10 --最大効果が得られるスケールファクター上限値
}
1つ目のクエリはスケールファクターを3で実行すれば、元のクエリ時間718秒に対し、
222秒(3.2倍)の性能向上が見込めます。
2つ目のクエリはスケールファクターを8で実行すれば、元のクエリ時間343秒に対し、
76秒(4.5倍)の性能向上が見込めます。
それぞれ環境が異なるのですが、1つ目の環境はワークロード別に細かくウェアハウスを分けた社内分析環境のため、大きなスケールファクター値が出る事はなかったのだと推測しています。
2つ目の環境は 2B向けの提供している分析サービス のため、入力条件次第では突出したワークロードが生まれやすい環境でしたので、スケールファクター値や効果期待値も大きな値が出たのだと判断しています。
上記より、1つ目の環境は設定しても良いですが、100名ぐらいのユーザーが常時アクセスしているため、キュー待ちにでもならない限り、コストを増やしてまでクエリパフォーマンスの最大化する事のメリットは薄く、このまま様子見でも良いかなと考えています。
一方で2つ目の環境は2B向けサービスであり、クエリパフォーマンスはユーザー満足度にも影響するため、即時適用し、パフォーマンス向上を図るのが適切と判断しました。
上記は一例ですが、ある程度QASの判断基準もあった方が良いと思いますので、参考としてQASの適用推奨をまとめてみました。
SYSTEM$ESTIMATE_QUERY_ACCELERATION関数に基づくQAS適用推奨ケース
推奨ケース一覧表
| ケースタイプ | 判定基準 | 推奨アクション | 具体例(関数出力例) |
|---|---|---|---|
| 即時適用推奨 |
eligible_time_ratio ≥ 0.7 かつ upperLimitScaleFactor ≥ 8
|
最大スケールファクターで即時適用 | {"estimatedQueryTimes":{"8":120}, "originalQueryTime":300, "status":"eligible", "upperLimitScaleFactor":10} |
| 段階的適用 | 0.4 ≤ eligible_time_ratio 200% |
スケールファクターを制限した適用 | {"estimatedQueryTimes":{"8":80}, "originalQueryTime":150} |
上記は結果からの機械的な判断基準ではありますが、上述の通り、どのような環境なのか、コストが多少増えてもクエリパフォーマンスを優先するのか、事業性の観点でも採否を見極める事が重要です。
総括:QASとウェアハウスサイジングのバランス
最後に一つ、QASのスケールファクターとウェアハウスサイズ変更は相互補完的な関係にあります。
重要な判断ポイントとしては以下と考えています。
- 予測可能性:定常ワークロードはサイズ変更、変動ワークロードはQAS
- コスト管理:厳密な予算管理が必要な場合はサイズ変更優先
- 柔軟性:突発的な負荷変動に対応するにはQASが有効
一元的な判断基準はなく、データエンジニアとしてその事業やそのサービスの特性を鑑みて、恒常的なスペックアップが必要であれば、ウェアハウス変更やウェアハウス分割とするのが良いと思いますし、突発的な事象であれば、QASを適用が良いと思います。
いずれにせよ、効果的な運用のためには、WAREHOUSE_METERING_HISTORYとQUERY_ACCELERATION_HISTORYを組み合わせた監視が不可欠です。例えば週次や月次レポートでCPR(Cost Per Response)を追跡し、最適なバランスを見極めることが重要です。
このようなユースケースやパターンは企業やサービスごとに優先順位や考え方も変わると思いますので、自社それぞれに合った選択基準でSnowflakeのパフォーマンス最適化機能を活用していきましょう。
まとめ
本記事では、Snowflakeの三大パフォーマンス最適化機能(クラスタリングキー、Search Optimization Service、Query Acceleration Service)をそれぞれ検証しました。各機能の基本概念から実際のハンズオンテストや弊社での事例も含め、パフォーマンスへの効果測定を行いました。
各機能はいずれも非常に優れた機能であり、適切に活用することで自分たちの分析基盤のパフォーマンスを大きく向上させることが出来ます。一方でそれらはコストとトレードオフがあるため、ワークロードの特性とパフォーマンス要件に基づいて適切な選択と組み合わせを行うことが重要です。定期的にクエリパフォーマンスをモニタリングし、必要に応じて最適化戦略を調整することをお勧めします。
最後に、本記事のテスト結果はあくまで例示であり、実際のパフォーマンス向上は環境やデータ特性によって異なる点にご注意ください。自身の環境で同様のテストを行い、最適な構成を見つけることをお勧めします。
またこのような記事を書くきっかけとなったのは、SnowflakeのユーザーコミュニティであるSnowVillageのイベント参加を通じた新たな発見や気付きがあったからです。
コミュニティに参加するだけで様々な知見や学びを得られますし、イベントに参加することでより実践的で深い技術やノウハウを学ぶことが出来、それらを通じてデータエンジニアとして成長する機会も大きく増えると思いますので、ぜひ皆さんもご参加ください。
SnowVillage
イベント案内

Snowflake データクラウドのユーザ会 SnowVillage のメンバーで運営しています。 Publication参加方法はこちらをご参照ください。 zenn.dev/dataheroes/articles/db5da0959b4bdd
Discussion