罰則項付きSynthetic Control法
前回の続き:https://zenn.dev/falconnnmmm/articles/ecf333ba18b2f7
今回はAbadie et al. (2021)で提案された手法"A Penalized Synthetic Control" (罰則付き合成コントロール法)について解説していきます。
モチベーションと定式化
基本的な設定や記号は前回と同様とします。
この論文のモチベーションは 集計前のデータ (disaggregated data) に対してsynthetic controlを適用するための方法を提示することにあります。Part 1で紹介した方法、および応用先は国レベルや州レベルなどで集計 (aggregate) されたデータを対象としていますが、もう少し細かいレベルでデータが見れるならそのレベルで推定したほうがバイアスが減らせるはずです。
例えばPart 1で紹介したカリフォルニア州にタバコ税を導入したことによるタバコの売上への影響はカリフォルニア州全体で見ていますが、元々のデータは小売店単位で売上が発生していて、それをどんどん集計したものをデータとして見ています。しかしカリフォルニア州の中でもサンフランシスコとロサンゼルスでは影響の大きさが異なるかもしれません。
集計前のデータでsynthetic controlを考える場合、処置を受ける人が複数存在しうることになります。ですが考え方は同じで、各処置群の人に対してアウトカムをコントロール群のアウトカムの加重平均で再現することを考えます。このときweightは処置を受ける人によって異なると考えます。
これを数式で表現すると次のようになります。
-
i=1,2,\cdots,N - 処置群は
n_{1} N-n_{1}
- 処置群は
-
\alpha_{i,j} i j - perfect fit assumption: 各
i=1,\cdots,n_{1} \bm{\alpha}_{i}=(\alpha_{i,n_{1}+1},\cdots,\alpha_{i,N})
この論文ではweightを求めるための最適化問題を次のように定めています。
Part 1で紹介した最適化問題と比較すると第2項が追加されていることが分かると思います。
推定されたweightを使うと処置群一人ひとりに対する処置効果
が推定でき、例えば
は処置群に対する(時刻
なぜ罰則項が必要なのか
さて、上の最適化問題に罰則項があるわけですが、この項が存在する主な理由は解が一意に定まらない可能性が高いからです。処置群のアウトカムを完全に再現するようなweightの組み合わせが複数ある場合、どのweightの組み合わせが相応しいでしょうか?
重要な点として、処置前のデータではちゃんとperfect fitが達成されているか確認することができますが、処置後のデータでは
もしはじめから得られる解(組み合わせ)が一つに定まっていればそのweightを使えばいいので上記の懸念点は払拭されます。この問題を解決する方法が罰則項の存在になります。Abadie et al. (2021)のTheorem 1は上の最適化問題から得られる解は一通りに定まり、かつ疎(変数の数に対して0が多い)になることを示した定理です。
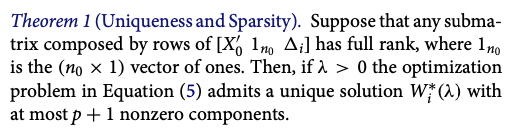
\lambda
罰則の強さは
Leave-One-Out Cross-Validation
ここでは
- 各コントロール群
i=n_{1}+1,\cdots, N t=T_{0}+1,\cdots,T \alpha_{ij}(\lambda) \lambda i
- 様々な
\lambda \lambda
を求め、それを最小にするような
何をやっているかと言うと、コントロール群のデータから1人分だけのデータを除いて推定して、その人のアウトカムとの誤差を最小にするように
参考文献
Abadie, A., Diamond, A., & Hainmueller, J. (2010). Synthetic control methods for comparative case studies: Estimating the effect of California’s tobacco control program. Journal of the American statistical Association, 105(490), 493-505.
Discussion