はじめに
本記事は、ELYZA が参加している内閣府SIP第三期プロジェクト「統合ヘルスケアシステムの構築」に関する連載の第二弾として、前回に引き続き「日本語医療LLM」の研究開発内容をご紹介します。
前回は、各種医療ユースケースに共通する基盤技術として、医療知識に精通した日本語版汎用医療LLMの開発について詳しくお伝えしました。
今回はその応用編として、開発した基盤モデルを活用し、実際の医療現場を想定した2つのユースケース、すなわち「電子カルテ標準化のための情報変換」と「レセプト修正提案」タスクにモデルを適合させていく取り組みについて紹介します。
- 技術①: 各ユースケースの根幹となる日本語版汎用医療LLMの開発
- 技術②: ユースケース1-電子カルテ標準化のための情報変換 (本記事の焦点)
- 技術③: ユースケース2-レセプトの確認修正内容の提案
なお、本ブログは、大葉 (@dai0NLP)、平川 (@h__must__) が代表して執筆しました。また、本ブログで紹介する成果は、「戦略的イノベーション創造プログラム (SIP)」「統合型ヘルスケアシステムの構築 JPJ012425」 の補助により得られたものです。
研究開発内容の詳細: ユースケース1 - 電子カルテ標準化のための情報変換
医療DXを牽引する技術基盤として期待される実ユースケースの一つとして、3文書6情報変換タスクに取り組みました。本タスクは、3文書6情報にあたる医療情報を厚労省指定の標準形式へ変換するものです。今年度は特に、検査・感染症・薬剤アレルギーの3情報に対する検証を行いました。
方法論としては、複数医療機関の協力のもと当該タスクを体現する fine-tuning 用データを作成し、技術①で得られた日本語版汎用医療 LLM を fine-tuning しました。
以下では、まず本ユースケースのタスク定義を説明し、次にタスク遂行に必要なデータ整備方法(アノテーション)を述べます。続いて、本ユースケースを解くためのモデルの適合方法および評価について説明します。
【タスク定義: 検体検査名称の標準化】
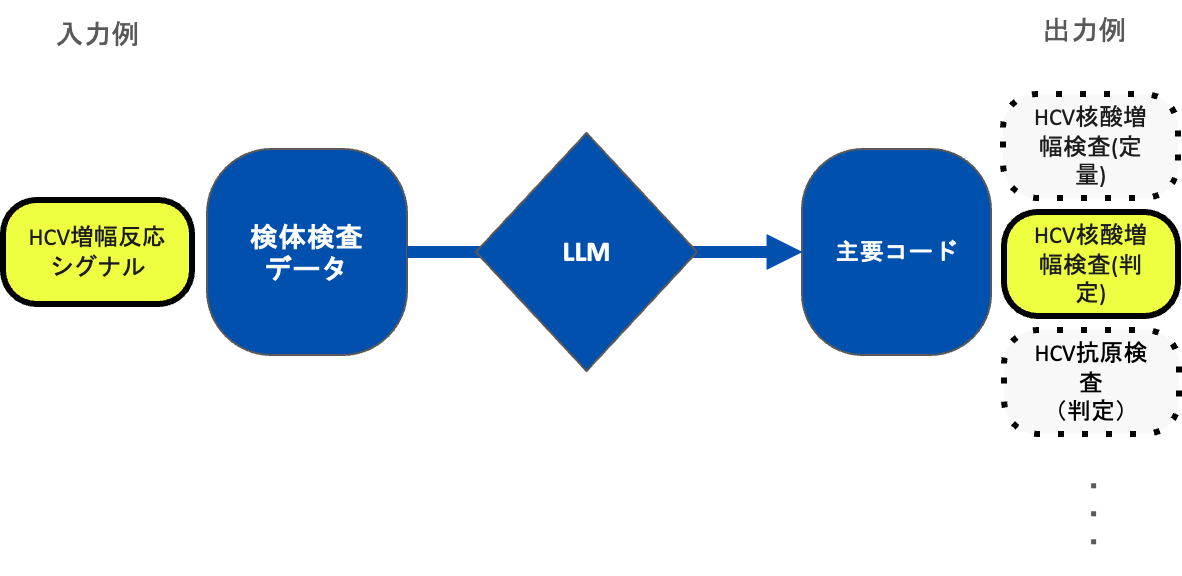
本タスクは、上図に示すように、カルテや医事会計情報に含まれる主要な情報(3文書6情報)を厚労省指定の標準形式(標準コード)へ変換することを目的としています。本研究課題では、カルテおよび医事会計情報に記載された検体検査名称の集合から、3文書6情報に対応する名称を抽出し、標準コードへ変換するタスクに取り組みました。
あるカルテが与えられた場合、検体検査名称の集合はルールベースにより抽出できるため、本質的な課題は次の二点に集約されます。
- 各検体名称が標準コードに変換可能な3文書6情報に該当する名称かを判定すること
- 該当する場合、どの標準コードへ変換するかを決定すること
したがって、本タスクは各カルテに含まれる検体検査名称リストを入力とし、それに対応する標準コードリストを正確に再現するという問題設定に落とし込むことができます。例えば、a → x, b → y, c → z, d → N/A (d は3文書6情報に該当しない) のように検体検査名称から標準コードへとマッピングされる場合、下記のような入出力となります。
- 入力(検体検査名称リスト): [a, b, c, d]
- 出力(標準コードリスト): [x, y, z]
【実験設定: 学習および評価の方法】
本ユースケースには既存の学習・評価データが存在しないため、国際医療福祉大学および藤田医科大学の協力のもと、匿名加工済み電子カルテデータ(※匿名加工データの入手については技術④の節を参照)を用いて入出力データを作成しました。
具体的には、電子カルテデータの検体検査名称リストから3文書6情報を標準形式(標準コード)でリスト化しました。各検体検査名称と変換後標準コードの対応は記録されていないため、標準コードの特定が困難な場合は「該当なし」とアノテーションしました。また、検体検査名称と標準コードは必ずしも一対一で対応せず、一つの検査名称に複数の標準コードが紐づく場合もあります。
本検証では、検体検査名称と標準コードが一対一となるデータのみに絞り、対応するペアデータを構築しました。最終的に 1 患者 1 日分の検体検査結果を 1 件と数え、計 14,699 件の有効なデータを抽出しました。
モデル開発では、これらのペアデータを用いて各検体検査名称に適切な標準コード(「該当なし」を含む)を割り当てるタスクをLLMに学習させました。評価では、あるカルテを入力として検体検査名称ごとに標準コードを推定し、その標準コードリストを構成しました。評価指標には f1 / precision / recall を用い、推論結果と参照回答の整合性を定量的に評価しました。モデルが「該当なし」と推定したものは空文字として扱い、推論結果から除外しています。
学習・開発・評価スプリットは、次の二つの設定で分割しました。
- 時系列的分割: カルテ単位で検査実施日の時系列順に並べ、最新の日付が開発・評価スプリットに含まれるよう 8:1:1 の割合で分割しました。これは将来データへの予測性能、すなわち時系列的汎化能力を評価するためです。
- 未知データ分割: 学習済みの変換パターンが評価セットに含まれないよう、検体検査名称が重複しない形で分割しました。これにより未観測の検体検査名称に対する推論性能を評価し、未知パターンへの汎化能力を検証します。
未知データ分割では、未観測パターンを十分に確保するため、時系列的分割で用いたデータに加えて開発期間後半の追加アノテーションデータを組み込みました。その結果、約 17,000 件の検体検査名称と標準コードの評価用ペアデータが作成されました。母集団データセットの分布が時系列的分割の場合と異なる点にご留意ください。
本学習では、報告書冒頭で述べた開発アプローチに沿ってアノテーションデータを用い、①で開発した日本語版汎用医療LLMを fine-tuning しました。その際、次の工夫を施しました。
- 推論時のプロンプト設計: Chain-of-Thought を促すプロンプトに加え、判断根拠となるドメイン知識を埋め込みました。
- 学習データの拡張: 推論時に有効だった思考過程を人工的に学習データへ付与しました。
これら二つの工夫を合わせて prompt tuning と呼称します。弊社モデルでは両方を実施していますが、比較モデルは微調整を行わないため、推論時のプロンプト設計のみを prompt tuning としています。
【評価結果: モデルや学習方法が変換精度に与える影響】
表に評価結果を示します。青色は弊社開発モデル、灰色は国内外の競合モデルです。
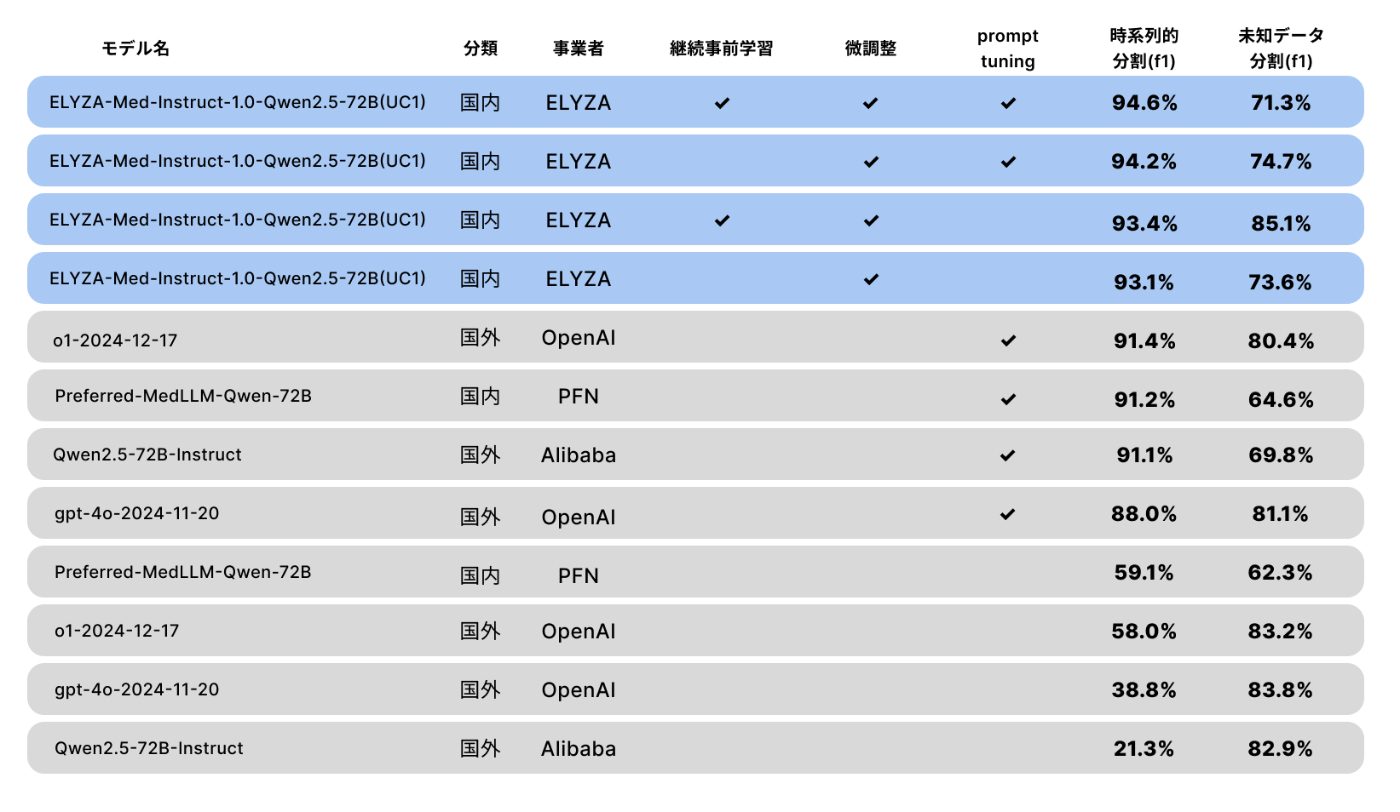
日本語汎用医療LLMをベースに fine-tuning したことで、OpenAI 社の o1 や PFN 社の医療特化モデルをすべての指標で上回りました。主な観察結果は次のとおりです。
- 時系列的分割・未知データ分割のいずれでも、弊社モデルは他の国内外モデルより高性能であり、ユースケース特化型モデルの重要性が示されました。
- 継続事前学習を経た fine-tuning モデルは高性能であり、基礎的な日本医療知識を押さえた後にタスクへ特化するアプローチが有効でした。
- 推論時プロンプト設計と学習データ拡張は時系列的汎化能力を向上させましたが、未知の変換名称には必ずしも効果がありませんでした。
【分析: 問題の類型化】
誤出力を分析すると、次の三つのパターンが確認できました。
1. 学習データが存在しない
出力側標準コードの網羅性が不足している例です。未登場の標準コードが必要となる場合、モデルが「該当なし」と返す傾向があります。
- 変換元名称:クレアチニン換算値
- 標準コード:尿中アルブミン/クレアチニン比
- 予測:該当なし
2. 変換元名称が表層的で手がかりがない
抽象的名称や類似標準コードが複数ある場合に誤判定が起こります。思考過程を収集・付与することで改善が期待されます。
- 変換元名称:DS
- 標準コード:空腹時血糖
- 予測:総コレステロール
3. アノテーション結果が一貫していない
同一入力に対し標準コードが一貫しない例です。データ整合性の向上が必要です。
- 変換元名称:梅毒定量(FTA-ABS)
- 標準コード:
- 梅毒TP抗体(半定量)
- 梅毒STS(半定量)
- 梅毒STS(定量)
- 梅毒TP抗体(定量)
- 梅毒TP抗体(定性)
【発展的検証: ユースケース適合と汎用医療知識の両立】
日本語版汎用医療LLMをユースケースへ適合させつつ汎用知識を保持できれば、他のユースケースへの展開も可能です。本ユースケースに継続事前学習 + fine-tuning + prompt tuning を施したモデルに、医師国家試験過去問で追加 fine-tuning を行い、6 情報変換性能と IgakuQA 精度を検証しました。
結果、6 情報変換の f1 スコアは 94.6% と変わらず、IgakuQA 精度は +0.2% 改善しました。ユースケース適合と汎用知識保持は両立できると確認できました。
おわりに
本記事では、日本語版汎用医療 LLM を活用し、医療現場で直面する課題に取り組むユースケースをご紹介しました。
ここまでお読みいただき、ありがとうございました。ELYZA はリサーチャーはもちろん、ソフトウェアエンジニアや AI コンサルタントなど、様々な職種で一緒に事業を前に進めてくれる仲間を募集しています。詳しくは下記をご覧ください。

Discussion