はじめに
本記事では、研究開発チームの最近の取り組みとして「日本の医療分野に特化した日本語医療LLMの開発」について紹介します。
ELYZAは、内閣府戦略的イノベーション創造プログラム(SIP) 第三期 「統合ヘルスケアシステムの構築」 の「日本語版医療 LLM の開発ならびに臨床現場における社会実装検証」 にて、大規模言語モデルの開発部分を担当させていただきました。具体的には、日本国内で起きている医療従事者の不足・過重労働、さらには少子高齢化に伴う医療需要の増大に対する一つの解決策を示すべく、日本の医療分野を想定した様々な実応用タスク(ユースケース)群において、国内外最高水準の性能を発揮する大規模言語モデルの開発を行いました。
本記事は、ELYZAが貢献した研究開発の内容を解説する、第1回目の記事です。具体的には、研究開発の概要と、各ユースケースの根幹となる汎用医療LLMの開発について解説します。
- 研究①: 日本語版汎用医療LLMの開発(本記事で紹介)
- 研究②: ユースケース1 - 電子カルテ標準化のための情報変換タスク
- 研究③: ユースケース2 - 診療報酬明細書の作成を補助する情報推薦タスク
なお、本ブログは、大葉 (@dai0NLP)、佐藤 (@shoetsu_sato)、中村 (@tyo_yo_) が執筆しました。
また、本ブログで紹介する成果は、「戦略的イノベーション創造プログラム (SIP)」「統合型ヘルスケアシステムの構築 JPJ012425」 の補助により得られたものです。
プロジェクト概要
日本では、少子高齢化も相まって医療従事者の不足や過重労働が問題になっています。本プロジェクトではその解決策として、質問応答や文章読解において高度な水準に達している大規模言語モデル(LLM)に着目しました。例えば、米国医師国家試験において合格点を超える成績を収める海外製LLMも登場しており、日本の医療分野からも実用化を期待する声が高まっています。
一方で、海外製のLLMを日本における医療の現場に適用するにあたってはプライバシーや安全保障上のリスクがつきまとうため、日本国内での利用にそのまま転用することには問題があります。また、LLMをはじめとする深層学習モデルは学習データの性質に強く影響されるため、主に海外・英語のデータを用いて学習された海外製モデルは日本の法規制や医療制度を遵守できないリスクがあると考えられます。
本ブログで紹介するSIPの取り組みでは、日本の医療従事者が実際に遭遇し、かつ多くの労力を要しているユースケース群を高精度に解くことを目指した、日本語版医療LLMを開発するための取り組みを紹介していきます。
研究開発内容について

前提として我々のプロジェクトでは、下記の理由から、より多くのユースケースに対応可能にするためにオープンモデルの継続事前学習により日本語版汎用医療LLMを開発し(研究①)、それをベースに各ユースケースへ都度適合するアプローチを採用しました。(研究②, ③)その理由として、以下の点が挙げられます。
- 医療という専門的なドメインにおいて要件定義やデータ整備を行うことは容易ではない。そのため、各ユースケースで共通で必要になる基本的なドメイン知識は継続事前学習の時点で共通して学習しておくのが望ましい
- 汎用オープンモデルに関する国内外の開発状況を踏まえると、モデルの基本性能については定期的に大幅なアップデートが起きる可能性が高い。そのため日本語汎用医療LLMの開発に継続事前学習を採用し、今期のプロジェクトではベースとなるモデルを更新しつつ医療特化の能力を付与するための知見獲得・基礎開発に注力すべきである
結果、本プロジェクトにおけるELYZAの取組みは以下の3つとなりました。本記事ではそのうち研究①を解説します。
研究①: 各ユースケースの基盤となる日本語版汎用医療LLMの開発
各国共通の医療知識については既に十分な知識を得ているであろうオープンなLLMをベースに、日本語医療関連コーパスを用いた継続事前学習を行うことで、日本医療に精通した基盤モデルを作成します。基盤モデルの性能を測る指標として、日本の医師国家試験 (IgakuQA) を採用しました。実験では海外のGPTシリーズやベースにしたモデルなどと比較し、どの程度日本の医療知識に精通した基盤モデルを学習できたかを評価します。また、実際の目標は後段のユースケースにおける性能向上であるため、この時点でIgakuQAなどに特化した指示学習は行わず、プレーンな状態での性能を評価しました。
研究②: ユースケース1 - 電子カルテ標準化のための情報変換タスク
日本の医療機関は、3文書6情報(例: 診療情報提供書や、傷病名・病状などの情報)と呼ばれる、診療情報提供書患者の診療において特に重要とされる基本的な医療情報を厚労省指定の標準形式で記録するよう求められている一方で、実際の現場では各医療機関特有の呼び名・コードを用いた運用が続いており、医療機関を跨いだ情報共有や公的な情報提出の際にその変換が大きなコストとなっています。本ユースケースでは、3文書6情報を、医療機関固有の名称から厚労省指定の標準形式に変換することに取り組みます。具体的には各病院でばらつきが大きく、特に需要が高いと想定される検査・感染症・薬剤アレルギーの3情報を対象としました。
研究③: ユースケース2 - 診療報酬明細書の作成を補助する情報推薦タスク
レセプト(診療報酬明細書)は、通常レセプトコンピュータ(レセコン)を使って電子カルテや医事会計情報から自動変換されますが、その変換結果(ドラフト)が不完全な場合もあるため、医療事務員が内容を確認し、必要に応じて修正を行っています。この作業では、診療録や看護録等の情報を適切に参照し、かつ複雑な診療報酬制度に準拠することが求められるため、医療知識を持ったAIによる補助が効果的に働くタスクであると考えられます。本ユースケースではレセプトのドラフトに対して、確認修正箇所の判断と、確認修正内容・理由・情報参照先の提案に取り組みました。
研究① 各ユースケースの基盤となる日本語版汎用医療LLMの開発
【予備実験1/3: オープンデータの価値検証】
オープンモデルが既に存在するとはいえ、LLMの継続事前学習にはなるべく大規模な学習データが必要となります。ただ本プロジェクトで想定していた数十億〜数百億トークン規模のオープンな日本語医療コーパスは現時点で存在しないので、質の良い大規模な汎用コーパスや医療テキストを中心に抽出したもの、あるいは他言語の医療コーパスを使ってデータ量を増やす必要があります。
一方で、データの量が増える事が必ずしも良い結果に繋がるとは限らず、他言語や別ドメインのデータがノイズとして働いてしまう可能性も考えられます。特に最終的な訓練は長期間にわたるため、途中で些細なランダム性によってモデルの性能が大きく落ちてしまった場合訓練のやり直しが必要になり、スケジュール・コスト面で問題となることから、どのデータの組み合わせで学習すると安定してモデルを改善し続けられるのかの検証が重要と考えました。
オープンデータから有望なものを調査し、候補データソースとして用いたのは以下のデータです。
- 英語_医学論文: peS2o (約 76.4B tokens)
- 日本語_汎用: llm_jp_v3 (約 757.6B tokens)
- 日本語_汎用_医学科学サブセット: llm_jp_v3_extracted (約 130.7B tokens)
- llm_jp_v3から医学・科学に関連があるものを抽出したもの
- 英語_汎用: fineweb (約 56.2B tokens)
これらを以下の5つの設定で組み合わせて15B tokens 程度の小規模なデータセットを作成しました。括弧内は各データの比率となります。
- baseline1: 英語_医学論文 (peS2o 50%) + 日本語_汎用 (llm_jp_v3 50%)
- baseline2: 英語_医学論文 (peS2o 100%)
- baseline3: 英語_医学論文 (peS2o 50%)+ 日本語_汎用 (llm_jp_v3 25%) + 英語_汎用 (fineweb 25%)
- extract1: 日本語_汎用_医学科学サブセット(llm_jp_v3_extracted 100%)
- extract2: 英語_医学論文 (peS2o 50%) + 日本語_汎用_医学科学サブセット (llm_jp_v3_extracted 50%)
Llama-3.1-70B をベースモデルとした上で、ハイパーパラメータを統一した上でこれらのデータセットでそれぞれ継続事前学習を行い、IgakuQAで評価した結果が下図1です。評価尺度はIgakuQAにおける予測結果の正解数を全データ数で割ったAccuracyを用いています。また注意点として、IgakuQAには画像を見て答えることを前提とする設問も含まれていますが、本研究時点でのベースモデルはテキストのみを扱うモデルを用いているため、手がかりが不十分な状態で回答している設問も数割存在しています。
図1: データ (15B) の配合比率の変化とIgakuQAの精度変化
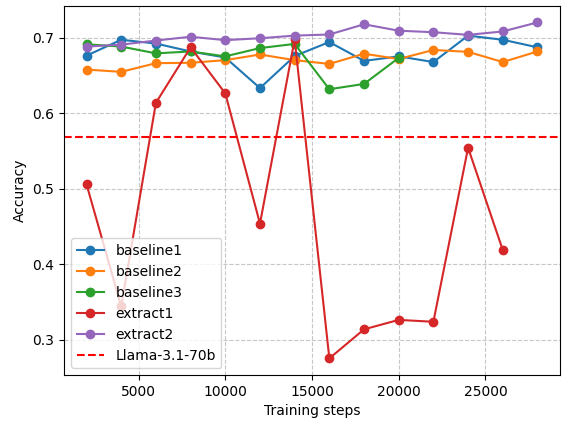
結果としては、英語の医学論文と日本語の汎用コーパスから医学・科学系のテキストだけを抽出したものを組み合わせた、extract2の設定が最も良い性能を発揮しました。
- baseline1, baseline3, extract1: 汎用的な日本語コーパスを混ぜると、ベストの結果と比べて安定性や性能の劣化が起きた。(baseline1, 3) x予想に反して、医学科学関連サブセットの抽出を行い、それだけを使用した場合は大きく安定性が損なわれた (extract1)
- baseline2: 英語のデータ (pes2o) を使用することで、日本語ベンチマークにおける性能劣化が起きる可能性を危惧していたが、予想に反して訓練は安定して改善を見せた
- extract2: 日本語_汎用_医学科学サブセット単体では安定性が大きく損なわれる一方で、 英語の医学論文コーパス (pes2o) と組み合わせて用いる事で、性能改善に寄与することが確認された。
このような結果になった理由として、以下のように考えています。
- Llama3.1-70Bのような高性能なベースモデルは、すでに一定の日本語理解能力を有しており、医学的内容の割合が低い汎用的な日本語コーパスからは新たに得られる有益な情報量が限定的
- 同じく Llama3.1-70Bのようなベースモデルは、元々英語データを中心に学習しているため、継続学習において英語コーパスも一定量含めることで、モデルパラメータの急激な変化を抑えられ、学習が安定した
【予備実験2/3: 大規模日本語医療コーパスの有用な利用方法】
予備実験1で用いたオープンデータとは別に、本プロジェクトの中で利用した大規模な日本語医学論文データ(約 2.6B tokens)を用いた実験についても解説します。予備実験1では英語の医学論文データが効果的だったことから、日本語の英語論文データにはさらに高い効果が期待される一方で、英語の医学論文データ (~76.4B tokens) と比べるとデータ量が不十分です。そのため、データ拡張の手段として言い換えタスクを用いたデータ合成を試し、その効果についても検証しました。
この実験では予備実験1と同様に、以下に示す候補データソースから組み合わせ・比率を変えて12~15B tokens 規模の小規模データセットを複数の設定で構築し、学習の安定性およびベンチマーク性能への寄与、どのデータをどれくらい使うと良さそうかを比較しました。
- 英語_医学論文: peS2o (約 76.4B tokens)
- 日本語_汎用_医学科学サブセット: llm_jp_v3_extracted (約 130.7B tokens)
- llm_jp_v3から抽出した医学・科学ドメインに関連があるサブセット
- 日本語_医学論文: jstage_raw (約 2.6B tokens)
- 元論文のデータに対して、簡単なルールベースのフィルタリングを行ったもの
- 日本語_医学論文_精製版: jstage_cleansed (約 1.4B tokens)
- jstage_raw をLLMでクレンジングし、ノイズの除去などを行ったもの。元データから内容はそこまで変わっていない。
- 日本語_医学論文_合成版: jstage_synthetic (約 20B tokens)
- jstage_raw をLLMで言い換え合成してデータ拡張したもの。jstage_cleansedと比べて元データからの内容の変化が大きい反面、同じ文書から異なるデータが作れるためデータ量を増やす事に向いている。(データ拡張の詳細は割愛)
比較する設定は以下の通りです。予備実験1と同様に、ベースモデルをLlama-3.1-70B、ハイパーパラメータを同一にした状態で配合比率のみを変えた同規模のデータで学習して比較しています。
- baseline2: 英語_医学論文 (peS2o 100%), 予備実験と同じもの
- jstage1: 英語_医学論文 (peS2o 80%) + 日本語_医学論文 (jstage_raw 20%)
- jstage2: 英語_医学論文 (peS2o 80%) + 日本語_医学論文_精製版 (jstage_cleansed 20%)
- jstage3: 英語_医学論文 (peS2o 90%) + 日本語_医学論文_合成版 (jstage_synthetic 10%)
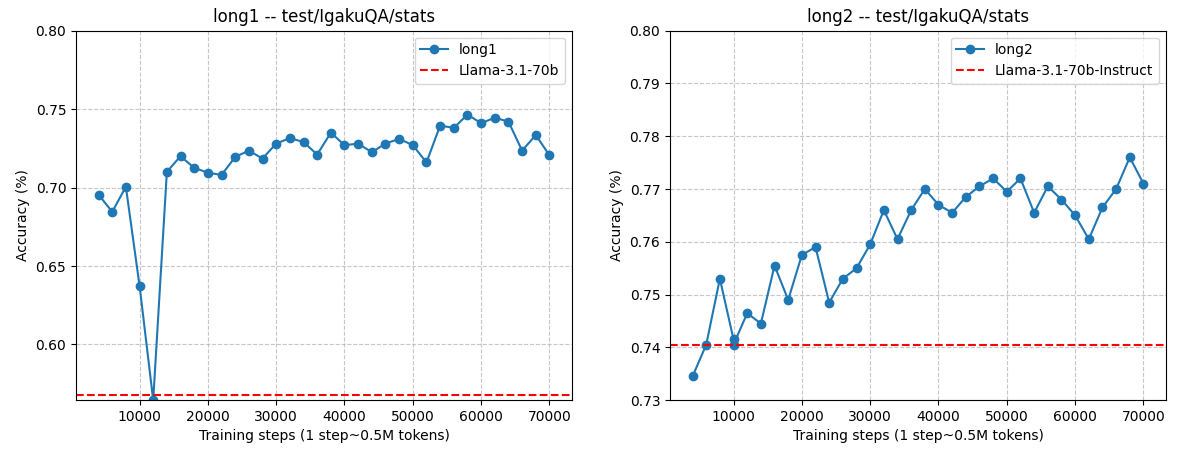
図2: 日本語論文データを異なる設定で使った場合の性能比較

これらを比較した結果が図2になります。傾向としては以下の通りでした。
- jstage1: 日本語の医療論文コーパスをそのまま使った場合には学習が安定せず、学習途中で急な性能劣化が発生する事が確認された
- jstage2: 一方で、LLMを用いてクレンジングを行うと、そうした不安定性は改善され、性能改善にも寄与した
- jstage3: 日本語の医療論文コーパスから言い換え合成した人工データを用いて baseline2 を一部代替しても、性能や安定性について大きな問題は見られなかった。
結論としては、日本語の医療論文データは、適切なクレンジングを施した上で使用することで、予備実験1において最も結果が良かったbaseline2 (=英語医療系論文 + 日本語_汎用_医学科学サブセット) 以上の効果が有ることが確認されました。また、言い換え合成を行ったjstage3の結果はjstage2に僅かに劣るものの、この手法の利点として元データを大きく上回る量のデータが作成可能である事が挙げられます。そのため、この後行う本実験において必要となる学習データが大規模になった際にはより効果が高くなると考えました。
【予備実験3/3: ベースモデルによる改善幅・学習の安定性の検証】
これまでの実験では同じモデルをベースにしていましたが、実際にはモデルの発展に合わせてベースモデルをアップデートしながら医療ドメインに対する学習を行い続ける必要があります。加えて、これまでは性能改善の評価のしやすさからLlama3.1-70Bを採用したものの、Llama3.1-70B-Instructのような指示学習が事前に行われたモデルを採用したほうが最終的な結果は良くなる傾向にあります。
そのため、これまでの実験で得られた有望なデータ設定を用いて、異なるベースモデルでも同様の効果が得られるかを検証しました。また、次の本実験では長期間の訓練を行う事から、その途中で過学習や学習の不安定化が起きないかの検証のために予備実験1, 2 よりも学習ステップ数を大きくしています。ここでは行った実験のうち、Llama3.1-70B, Llama3.1-70B-Instructに絞って以下の2設定の比較結果を紹介します。
- long1: Llama3.1-70B をベースモデルとして採用
- long2: Llama3.1-70B-Instruct をベースモデルとして採用
データセットに関しては予備実験1, 2の結果を考慮し、
- 英語_医学論文: peS2o (約76.4B tokens)
- 日本語_汎用_医学科学サブセット: llm_jp_v3_extracted (約130.7B tokens)
- 日本語_医学論文_精製版: jstage_cleansed (約1.4B tokens)
- 日本語_医学論文_合成版: jstage_synthetic (約20B tokens)
を合わせた約220B tokensのデータを共通して使いました。
結果としては図3のように、どちらのモデルをベースにしても安定して右肩上がりの性能向上が得られました。Llama3.1-70B-Instructのような指示学習済みのモデルについては、継続事前学習を行う事で性能劣化が発生する懸念もありましたが、我々の試した範囲ではその問題は小さく、最終的には指示学習済みのモデルの方が優れた結果となったため、以降の実験では指示学習済みのモデルを採用しています。
図3: Llama3.1-70B (左), Llama3.1-70B-Instruct (右)における学習ステップと精度の関係
【本実験: 大規模な継続事前学習】
これまでに得られたデータおよびベースモデル設定に関する知見を踏まえ、最終的な継続事前学習を実施しました。ベンチマークには、予備実験と同様にIgakuQAを採用し、指標としては予測結果の正解数を全データ数で割ったAccuracyを用いています。加えて、日本の医療制度における安全性も評価するため、本実験では医師国家試験における禁忌肢の選択数(試験5年分)も算出し、重大な誤りについての誤答傾向を確認しました。
データセットとしては予備実験3に近い以下の
- 英語_医学論文: peS2o (約76.4B tokens)
- 日本語_汎用_医学科学サブセット: llm_jp_v3_extracted (約130.7B tokens)
- 日本語_医学論文_精製版: jstage_cleansed (データを追加し、約3.9B tokensに増量)
- 日本語_医学論文_合成版: jstage_synthetic (データを追加し、約70.3B tokens に増量)
を合わせた約280B tokensのデータを使っています。
比較・分析はLlama3.1-70B-InstructおよびQwen2.5-72B-Instructをそれぞれベースモデルとして用いた、以下の2つの設定で行いました。
- Llama-3.1-ELYZA-Med-Base-1.0-70B: Llama3.1-70B-Instructをベースモデルに採用したもの
- ELYZA-Med-Base-1.0-Qwen2.5-72B: Qwen2.5-72B-Instructをベースモデルに採用したもの
この2つの結果に加えて、2つのベースモデル、さらに過去に日本語向け医療LLMとして開発された同程度のパラメータ数を持つモデル、Llama3-Preferred-MedSwallow-70Bを比較したグラフが下図4となります。
図4: IgakuQA 5年分の平均正答率 (左) と 合計禁忌肢選択数 (右)
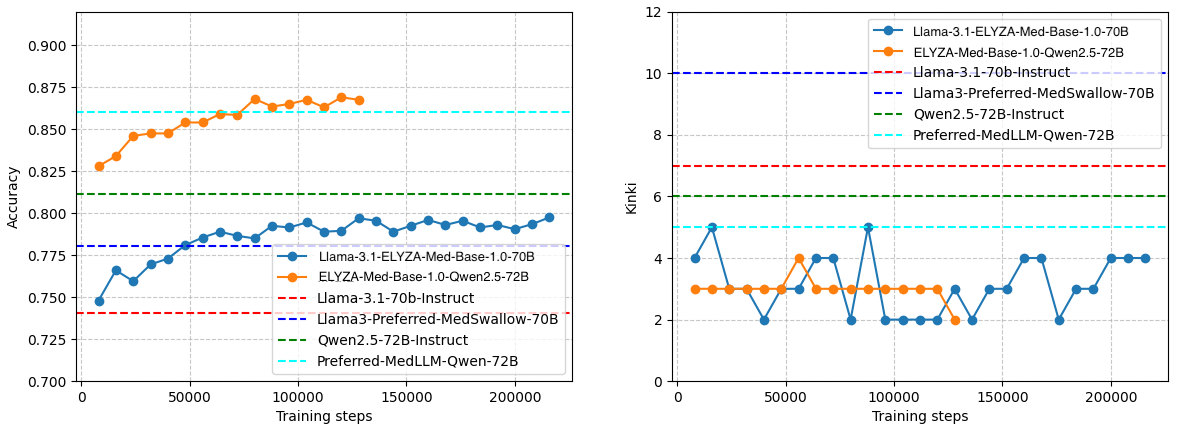
まず、図4 (左)に示すように、日本語医療コーパスを用いた継続事前学習により、汎用医療LLMの性能が向上することが確認されました。この傾向は予備実験の結果も含め、複数のベースモデルにおいて一貫して観測されています。また、一定のステップまでは、データ量に対する性能のスケーリング効果も確認されています。Llama3.1-70B-Instructをベースとした場合と比べると、Qwen2.5-72B-Instructの優秀さからベースモデルの変更による改善幅が非常に大きい一方で、既に高い汎用性能を持つベースモデルに対しても、継続事前学習による右肩上がりの性能改善が確認できたことから、日本語の医療関連データを今後も継続的に整備・拡充していくことの重要性を強く示していると考えられます。
加えて、図4 (右) の禁忌肢の継続事前学習によって日本の医療分野における知識を獲得する過程で、安全性の向上にも寄与することが確認されました。この結果は、日本国内とそれ以外とで医療分野における常識が必ずしも一致していない事が反映されているとともに、日本独自の医療LLMを作ることの大きな動機づけにもなると考えています。
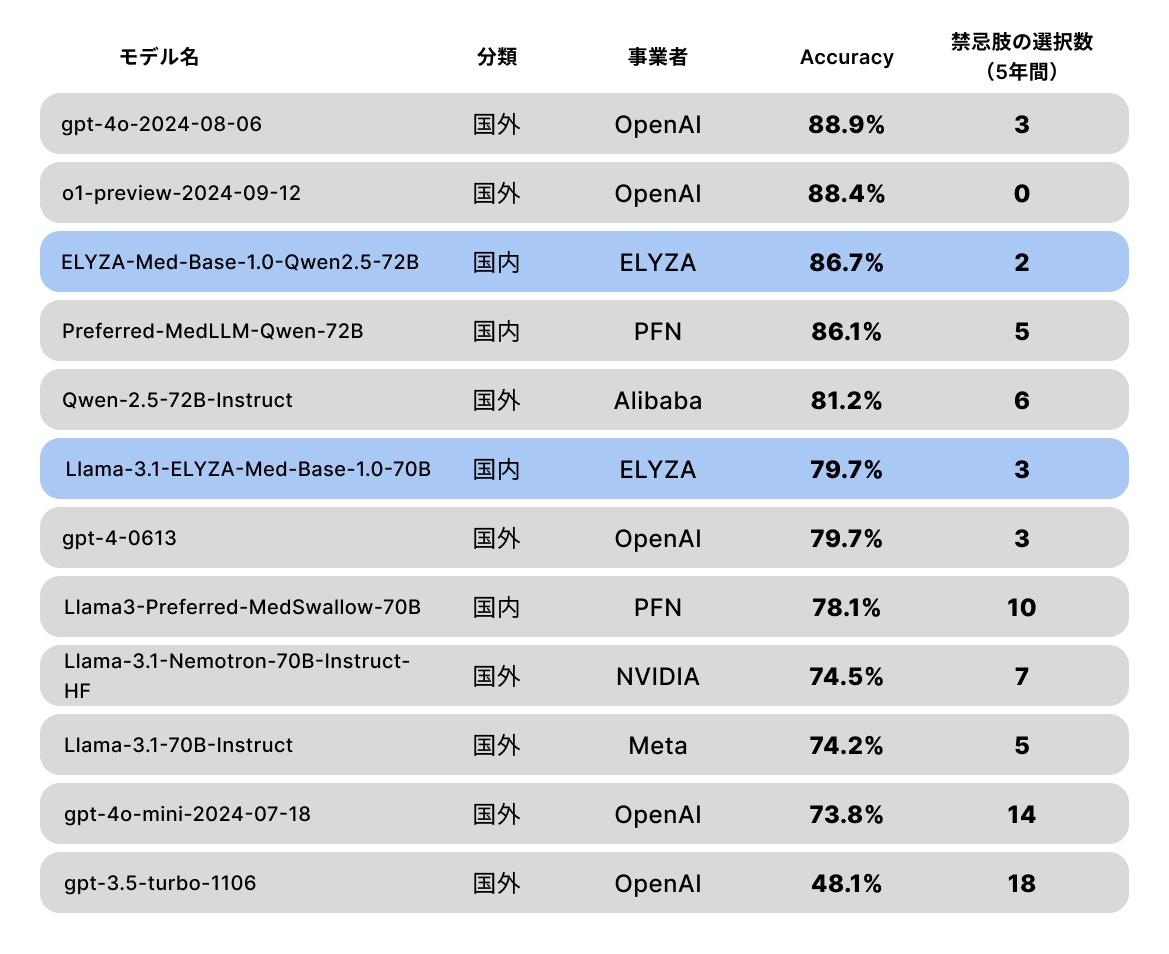
最後に、パラメータ数などが公開されていないクローズドなモデルも含めた結果の比較を表1に示しました。我々が開発したモデルはベースモデルから大幅な性能向上を達成するだけでなく、よりパラメータ数が大きいモデルを採用していると推測されるgpt-4oやo1といった国外の最先端のモデルにも匹敵する結果となりました。(2025年2月時点) 特に、ベンチマークとして用いたIgakuQAに特化した事後学習を行っていない状態でこの水準の性能を達成できている事から、個々のユースケースにおいて有用な基盤となるモデルを開発できたと考えています。
表1:ELYZAが開発したモデルと他モデルの精度・禁忌肢数比較
【追加分析: 継続事前学習がモデルの指示追従能力に与える影響について】
予備実験3によると、Llama3.1-70B-Instructのような指示学習が事前に行われているモデルであってもベンチマークの結果自体は改善される事が確認できましたが、汎用的な指示追従の面で本当に劣化は発生していないのかについて追加の検証を行いました。
具体的には、一般的なドメインのベンチマークであるELYZA-tasks-100 および Japanese-MT-Benchを用いて、指示学習済みのモデルに対する継続事前学習前後における汎用的な日本語性能の変化を調査しました。その結果、Qwen2.5-72B-Instruct において、5点満点のELYZA-tasks-100 で約1.5点の劣化、10点満点の Japanese-MT-Bench で約3点の劣化が見られ、一般ドメインにおいては継続事前学習による指示追従能力の低下を確認しました。
一方でその後、我々が普段使っている指示学習データセットでもう一度小規模な学習を行うことで、医療ドメイン特化の継続事前学習を行う前の水準程度には指示追従能力を回復可能である事も分かりました。そのため、医療ドメインのデータで継続事前学習を行った後、小規模な指示学習を行う事で医療ドメインの知識だけを強化したモデルを後段のユースケースでは用いています。
おわりに
本記事では、SIPプロジェクトにてELYZAが行った研究開発内容の概要と、その1つとして研究① 各ユースケースの基盤となる日本語版汎用医療LLMの開発について紹介しました。
ELYZA では引き続き、最先端の研究開発に取り組んでいくとともに、その研究成果を可能な限り公開・提供することを通じて、国内における LLM の社会実装の推進、並びに自然言語処理技術の発展を支援してまいります。
ELYZA はリサーチャーはもちろん、ソフトウェアエンジニアや AI コンサルタントなど、様々な職種で一緒に事業を前に進めてくれる仲間を募集しています。詳しくは下記をご覧ください。

Discussion