はじめに
本記事は、ELYZAが参加している内閣府SIP第三期プロジェクト「統合ヘルスケアシステムの構築」に関する連載の第三弾をご紹介します。
前回は、医療ユースケースとして、電子カルテ標準化のための情報変換をあげ、日本語版汎用医療LLMを当該ユースケースへ適応させる方法論について詳しくお伝えしました。
今回はことなる医療ユースケースとして、「レセプト修正提案」タスクを対象にご紹介します
- 技術①: 各ユースケースの根幹となる日本語版汎用医療LLMの開発
- 技術②: ユースケース1-電子カルテ標準化のための情報変換
- 技術③: ユースケース2-レセプトの確認修正内容の提案(本記事の焦点)
なお、本ブログは大葉 (@dai0NLP)、佐々木 (@hikomimo) が執筆しました。また、本ブログで紹介する成果は、「戦略的イノベーション創造プログラム (SIP)」「統合型ヘルスケアシステムの構築 JPJ012425」 の補助により得られたものです。
研究開発内容の詳細: ユースケース2 - レセプトの確認修正内容の提案
医療DXを牽引していく技術基盤として対応が期待される実ユースケースのひとつとして、レセプトの確認修正内容の提案に取り組みました。本ユースケースは、医療事務員の作業負荷軽減および業務の質の均一化を目的とし、レセプトに含まれる確認・修正箇所の特定と、対応する修正内容・理由・参照情報の提案という2つのタスクで構成されます。本研究では、複数の医療機関の協力のもと、当該タスクを再現する入出力データを構築し、技術①で構築した日本語版汎用医療LLMを用いて微調整を行いました。
以下では、まず本ユースケースにおけるタスク定義を説明し、次にタスク遂行に必要な学習・評価用データの整備方法について述べます。続いて、このユースケースに対応するためのモデルの適合方法およびその評価手法を示します。最後に、自動評価では評価できない自由記述形式部分を多角的に評価するための人手評価について報告します。
【タスク定義: レセプトドラフトの修正】
図1のように、電子カルテや医事会計情報から半自動で作成されたレセプトドラフトの算定項目それぞれに対し、確認修正の要否を判断することと、確認修正する場合の確認内容・理由・参照するべきソースを自由記述で生成するというものです。
図1: タスクの概念図

-
入力: レセプト、レセプトを作成するために用いた医事会計情報
-
出力: レセプトに記載されている診療行為・傷病名それぞれへの確認修正提案
- 医事データやカルテでの違和感のあるポイント
- 確認修正が必要な理由
- 確認時に優先的に参照すべき情報や手順
※ 確認修正点がない診療行為・傷病名については、空文字を出力
【実験設定】
本ユースケースの学習・評価データは存在しません。そこで、技術②の6情報変換ユースケースと同様、適切に匿名加工された電子カルテデータを用いて、本ユースケースを体現する入出力データを作成しました。
具体的には、まず、匿名加工済みの医事データに対し、観測可能な情報のみに基づいて作成可能な「最善のレセプト」を作成しました。次に、そのレセプトを最終提出版へ仕上げる過程で確認・修正が必要と判断された場合、該当する診療行為または傷病名の単位でコメントを付記しました。なお、確認修正の必要がない診療行為・傷病名については、コメントは付記しておりません。最終的に、1患者1ヶ月分のレセプトを1件とカウントし、合計3,721件のアノテーションデータを獲得しました。
続いて、レセプトの傷病欄および摘要欄に記載された傷病名または診療行為名と、それに対する確認修正提案とをペアデータとして構築しました。確認修正が不要と判断された場合には、提案内容として空文字を割り当てています。
モデル開発においては、これらのペアデータをLLMに学習させます:
-
入力: あるレセプトの傷病欄・摘要欄における個別レコード(i.e., 個別の傷病名・診療行為名)、およびそのレセプト作成に使用した医事データ
-
出力: 傷病欄・摘要欄における個別レコードへの確認修正提案
- 医事データやカルテでの違和感のあるポイント
- 確認修正が必要な理由
- 確認時に優先的に参照すべき情報や手順
※ 確認修正点がない診療行為・傷病名については、空文字を出力
なお、LLMの入力長制限を超える長さの医事データが存在する場合には、データをN分割し、それぞれに対して個別に推論を実行しました。その後、N個の推論結果の中から最も文字列長が長い出力を選択しました。これは、長文にはより多くの情報が含まれる可能性が高く、正解の判断に適していると考えられるためです。
評価では、二つの観点から性能を測りました。
- 修正確認の要否判断力: 確認修正が必要かどうかの判断精度を評価。具体的には、出力された修正提案が空文字か否かで0/1のラベルを付与し、f1/precision/recallを用いて分類精度を測定する。
- 修正確認提案コメントの質: 生成されたコメントの内容の質を評価。具体的には、参照回答と推定回答の両方をgpt-4o-miniに入力し、5段階でのスコアリングを行う。なお、要否判断とは独立に評価するために、評価対象の全モデルが空文字以外のコメントを生成した共通事例に限定して性能比較を行う。
学習・開発・評価スプリットの分割においては、対象患者が排他的に、かつ開発および評価セットに入院レセプトがそれぞれ最低30件を含むという制約を設け、8:1:1 の割合で分割しました。
技術②のユースケースと同様に、本タスクにおいてもアノテーションデータを用いて日本語版汎用医療LLMの微調整を行いました。その過程で、アノテーションデータだけではカバーできない情報を補完するため、説明文の付与を実施しました。具体的には、診療報酬点数表から診療行為名と対応する説明文のペアを作成し、確認修正対象となる診療行為名に対応する説明文をプロンプトに挿入する形式でのプロンプトチューニングを行いました。さらに、診療報酬点数表ではカバーできない情報の一例として医薬品に着目し、Web上の情報から医薬品の説明文を収集・構築しました。これにより、医事データ中の医薬品名にも対応する説明文を併記し、モデルの理解を補助しました。
【評価結果:修正要否の判定】
表1に評価結果を示します。青色の行が本研究で開発した独自モデル、灰色の行が競合モデルです。
表1: 修正要否判定の性能比較
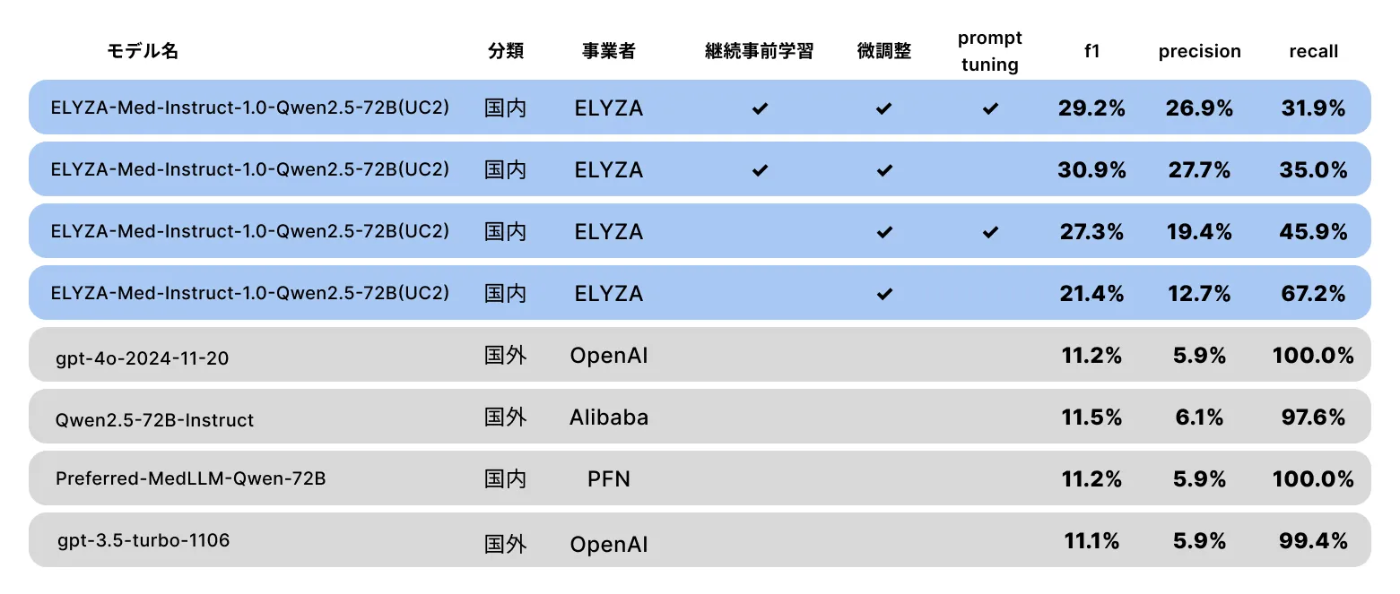
上記のように、日本語汎用医療LLMをベースに当該タスクに対して微調整することで、OpenAI社のgpt-4oやPFN社の医療特化モデルを全ての評価指標で上回ることができました。主な観察事実を以下に述べます。
- 微調整によって修正要否の判断能力が大きく向上させられることが示され、ドメインの専門家と作成した学習データの価値が伺えます。
- 継続事前学習を経ていることも修正要否の判断能力向上に寄与していて、共通する日本医療の知識を先に押さえた上で、個別のタスクに特化させる我々の開発アプローチが有用であることが確認できました。
- gpt-4oやQwen2.5-72B-Instructなどのrecallは著しく高いものの、precisionはかなり低い結果となっていました。これは、無差別に要修正と判断してしまっていることを示していて、レセプトの修正要否判定モデルとしては機能していないことが示唆されます。
- prompt tuningにおける説明文の付与には大きな効果は感じられませんでしたが、微調整対象のモデルが継続事前学習を経験していない場合には、説明文の付与が有用に働いていました。
- gpt-4oの推論能力を持ってしてもf1が11.2%、今回作成したモデルのベストな設定であってもf1が30.9%ということから、医療事務員がどのような箇所に懸念を持つかがいかに職人芸/暗黙知に依存するものであるかが伺えます。
【評価結果:コメントの質】
確認修正内容の提案テキスト部分は自由記述であるため、gpt-4o-miniを用いた自動評価に加え、医療事務による人手評価を実施しました。
自動評価については、各参照回答と推論結果を見比べた際の推論結果の質を5段階でスコアリングするよう gpt-4o-miniに指示しました。以下では gptscore と呼称します。
人手評価については、各推論結果(提案テキスト)を以下4つの観点で評価するよう医療事務員へ依頼しました。各指標は、いずれも4段階 (1〜4) での評価値を扱います。
- 正確性:提案テキストの内容が、医学的・制度的にどれだけ妥当であるか。
- 有用性:提案テキストの内容が、「医療事務員は次に何をすべきか」、すなわちNext Action をどれだけ明確に示せているか。
- 分かりやすさ:提案テキストの内容が、どれだけ明瞭に記述されているか、および医療事務員にとってどれだけ理解可能な内容であるか。
- 感覚的な悪さ:提案テキストの内容に対する感覚的な印象に基づいたとき、比較モデルの相対的な順位(悪い順)はどのようになるか。なお、同順位も許容した。
人手評価の実施にあたっては、医療機関、および業務委託として募集した医療事務経験者13名に協力を仰ぎました。使用した評価データはレセプト100件分のアノテーションデータであり、各モデルごとに同一のものを用いました。
表2に評価結果を示します。青色の行が本研究で開発した独自モデル、灰色の行が競合モデルです。
表2: コメントの質の比較

上記のように、日本語汎用医療LLMをベースに当該タスクに対して微調整することで、OpenAI社のo1やPFN社の医療特化モデルを全ての評価指標で上回ることができました。主な観察事実を以下に述べます。
- 我々の開発モデルは確認修正の要否判断能力についてだけでなく、確認修正に係る提案テキストの質も優れていました。自動評価と人手評価の両方の観点から、本事業で開発したモデルが全ての指標で優れた性能であることが確認できます。
- 継続事前学習を経験したモデルは、提案テキストの質に大きな差分を生み出していて、汎用的な医療知識を持つモデルがより有益なコメントを生成することが確認できます。
【分析: 問題の類型化】
我々の開発したモデルは、OpenAI社の gpt-4o や PFN社の MedLLM などよりも優れた性能を示しました。一方で、全モデルの性能到達ラインが低い傾向にあり、本ユースケースは非常に難しいタスクであることを示しています。そこで、後学のために、アノテーションデータの定性分析による問題の類型化を行いました。
提案コメントがついている代表的なタイプは以下となっていました:
- 医事データなどから、診療行為名を細分化できるケース
- レセプト中の診療行為について、ある条件が当てはまればさらに加算できるケース
- 診療行為を満たすか否か判断するための情報が不足していたり、算定できないと思われる項目が医事データに含まれているケース
- 処方量・使用量・規格・時間等の詳細が不明なケース
- 処方データと医事データに齟齬があるケース
- 医療施設の仕様が分からないと判定できないケース
次いで代表的なタイプは以下となっていました:
- 病名データと照らし、医事データに違和感があるケース
- 医事データ中の診察日に関する違和感があるケース
- 外来レセプト・入院レセプトのいずれかによって分岐するケース
上記整理から分かるように、代表的な事例には、診療行為名の分岐に係る条件など診療行為自体の理解が必要であったり、医療施設による分岐など診療報酬点数表への深い理解が必要となるものが多いです。一方で、診療報酬点数表に自然文で記載された情報は、限られたアノテーションデータでは網羅できず、実際の医療機関で実際にどのような指摘・返戻を受けているのかもアノテーションデータでは網羅できません。今後は、アノテーションデータとは別に、レセプト業務に係る知識源を整備することが必要になると考えています。
おわりに
本記事では、日本語版汎用医療LLMを活用し、実際の医療現場で直面する課題に取り組む2つ目のユースケースについてご紹介しました。
ここまでお読みいただき、ありがとうございました。ELYZA はリサーチャーはもちろん、ソフトウェアエンジニアや AI コンサルタントなど、様々な職種で一緒に事業を前に進めてくれる仲間を募集しています。詳しくは下記をご覧ください。

Discussion