Introduction
Hello, I'm Hirakawa(@h__must__) from ELYZA Research and Development team.
Since May 2024, ELYZA has been engaged in research and development of Japanese large language models (LLM) under the "Generative AI Accelerator Challenge (GENIAC)
" project, led by the Ministry of Economy, Trade and Industry. This project has provided us with computational resource support. In this article, I will introduce the "Depth Up-Scaling" approach we've been investigating and the resulting "Llama-3-ELYZA-JP-120B" model.
The research and development for this blog was conducted by Nakamura (@tyo_yo_), Sasaki (@hikomimo), Sam (@SamPassaglia), Oba (@dai0NLP), and myself, with me taking the lead on writing this post. The development environment for the project was set up by Horie (@eemon18) and Takahashi from our development team. These results were obtained through a grant from the "Research and Development Project of the Enhanced Infrastructures for Post-5G Information and Communication Systems" (JPNP 20017) by the New Energy and Industrial Technology Development Organization (NEDO).
Background
Since Meta released "Llama 2" in July 2023, ELYZA has been working on adapting this global model for Japanese language use through continual learning.

Adapting the model for Japanese through continual learning involves two steps, as shown in the figure: "continued pre-training" and "post-training." During continued pre-training, we use Japanese corpora to add knowledge about Japan and the Japanese language to the existing model, enabling it to generate fluent Japanese. Post-training consists of Supervised Fine-Tuning (SFT), which trains the model to generate expected responses to specific instructions, and Reinforcement Learning from Human Feedback (RLHF), which improves the model responses using human feedback. These steps enhance the model ability to understand and follow instructions.
The advantages of continual learning over developing an LLM from scratch include inheriting the high capabilities of existing models and achieving high performance with fewer training resources. This allows for quicker improvement cycles and easier transitions when more powerful models emerge. Additionally, during pre-training, continual learning tends to be more stable with fewer loss spikes compared to training from scratch.
However, development through continual learning has drawbacks, such as being constrained by the number of parameters, architecture, and vocabulary in the original model. To address vocabulary issues, ELYZA has been working on vocabulary expansion, adding new Japanese vocabulary during pre-training (details are available in this blog post). Yet, the parameter count, a significant factor in LLM performance, remains fixed, limiting the potential performance achievable through continual learning to what's possible with the existing model size.
To tackle this challenge, we've explored the Depth Up-Scaling approach. Proposed in "SOLAR 10.7B: Scaling Large Language Models with Simple yet Effective Depth Up-Scaling" (Kim, et al., 2024), this method aims to improve model performance by scaling up existing model depth.

Using this approach, we first scaled up the base model before applying continual learning, aiming to raise the performance ceiling achievable from existing models. We've extended the original research in two key areas:
- 1. Verification at a larger scale: While the original paper scaled a 7B model to 10.7B, we've tested this method at a much larger scale, creating a 122B model from a 70B base model.
- 2. Combination with multilingual adaptation: The original paper continued English-language training after scaling up, whereas we've conducted training in Japanese. This allows us to verify whether model up-scaling is also effective for acquiring other languages.
Method: Depth Up-Scaling
Overview
Depth Up-Scaling is a technique that scales up the model depth by adding new layers to an existing model. This approach aims to increase the model capacity and enable learning of more complex patterns and knowledge while preserving the original model's knowledge and performance.
In our case, we applied Depth Up-Scaling to Meta Llama 3 ("meta-llama/Meta-Llama-3-70B-Instruct") as a base, developed the "Llama-3-ELYZA-JP-120B" with 122 billion parameters.
Implementation
We used mergekit to scale up the model. The mergekit is a toolkit that simplifies "model merging," combining multiple models with various merging algorithms implemented. We utilized the paththrough algorithm in mergekit, which allows specified layers to be stacked without modifications.
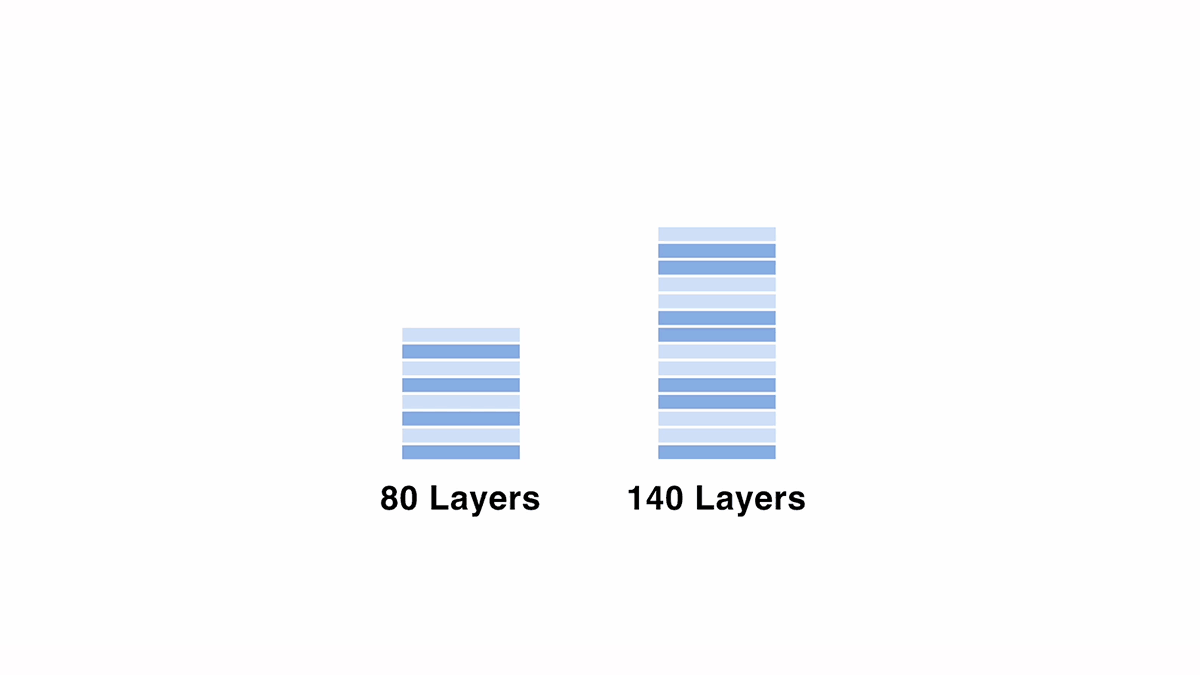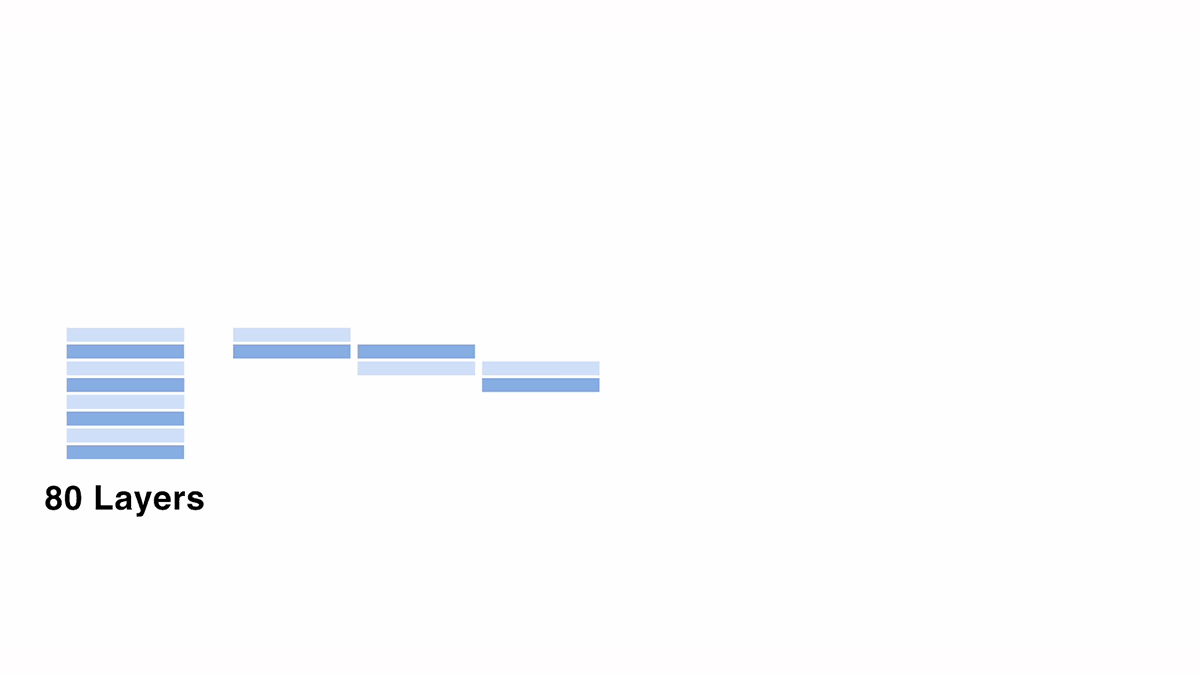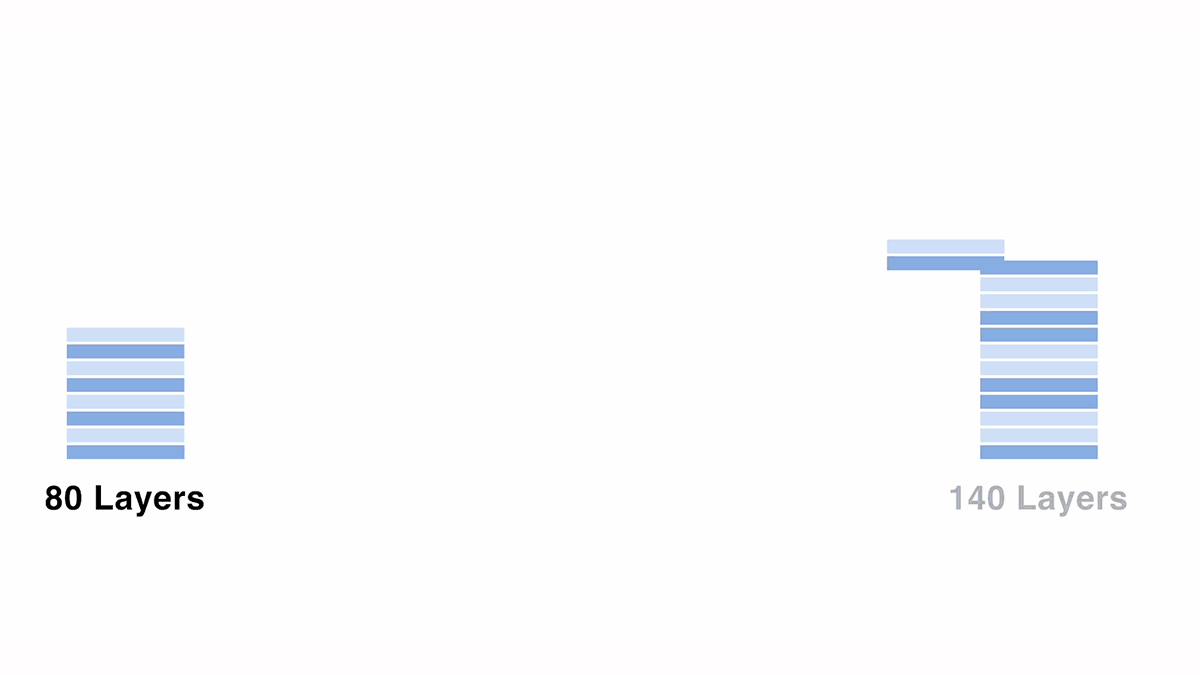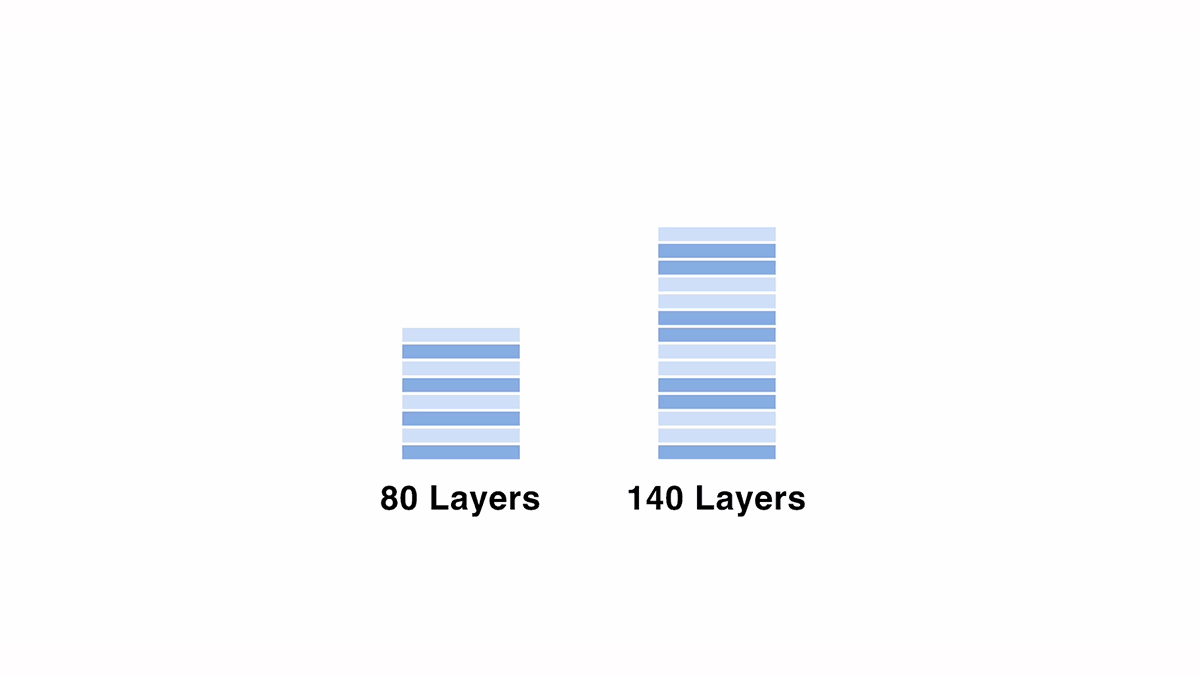
To scale up from the 70B model to 120B, we created a 140-layer model by copying and duplicating some layers from the original 80-layer model. We explored various configurations, adjusting variables such as the number of consecutive layers and the positions of duplicated layers, while monitoring the output results.

Evaluating the model with the final configuration, we observed a performance degradation of roughly 3.7% (based on a 5-point scale in ELYZA-Tasks-100 evaluation dataset) from the base "meta-llama/Meta-Llama-3-70B-Instruct" model. This result was obtained without additional training, and it is interesting to note that the model can generate text output without grammatical collapse, despite the fact that some layers are simply copied and stacked with identical parameters.
As a reference to similar work, another study conducting comparable experiments has reported performance improvements over the original 70B model through scaling up. However, in our experiments, scaling up alone did not result in Japanese benchmark scores exceeding those of the original model.
Layer Initialization
Initialization method for newly added layers significantly impacts model performance in Depth Up-Scaling. While random initialization could be considered as an approach, we chose to copy parameters from existing layers. This decision was based on the following two considerations:
- 1. Concerns about learning identity mappings: The Transformer Decoder architecture used in LLMs incorporates skip connections (Residual Connections). We were concerned that training might concentrate solely on the high-performing layers from the original model, causing the randomly initialized layers to converge to identity mappings during the training process.
- 2. Preservation of initial performance: While adding randomly initialized layers tends to degrade model performance, using parameters from the original model can maintain performance levels, as mentioned earlier. We adopted this method to prioritize high performance from the initial training stage.
Failed Approaches
Through verification of various up-scaling configurations, we found that pre-trained LLMs are robust to copying and rearranging layers within the model, but vulnerable to averaging between different layers.
When stacking layers for scaling up, we observed better characteristics when consecutive layer numbers had minimal overlap. Based on this observation, we attempted to create pseudo-continuous layers (e.g., layer 10, layer 10.5, layer 11, ...) by averaging models with one-layer shifts, as shown in the figure. However, this resulted in model output collapse, manifesting in phenomena such as the model outputting only "!" characters. Similar degradation was consistently observed when merging models that had been scaled up with different configurations.

While the exact cause remains unclear at this point, we hypothesize that similar issues arise as when merging models trained from different initializations. Generally, model merging assumes that the models to be merged were trained from identical initial values, and merging models trained from different initializations requires careful consideration. In our case, we suspect that similar issues occurred because parameters in different layers of the same model were effectively trained from different initial values.
Continued pre-training
Overview
For the continued pre-training of Llama-3-ELYZA-JP-120B, we used Megatron-LM, a distributed training framework developed by NVIDIA. We implemented 3D parallelism, combining Data Parallel, Tensor Parallel, and Pipeline Parallel approaches. While we considered using llama-recipes with Fully Sharded Data Parallel (FSDP) as an alternative method for distributed training of the LLMs, preliminary experiments showed that Megatron-LM provided faster training, so we opted for this approach. It's worth noting that we used FSDP for training the previous "ELYZA-japanese-Llama-2-70B" model, and you can find that article here.
For continued pre-training, we used a dataset combining natural language from LLM-jp-corpus v2 and FineWeb-Edu. We considered including mathematics and coding-related data in the pre-training, but preliminary experiments showed little benefit, so we decided to use only natural language data this time.
We used 32 nodes, each consisting of 8 NVIDIA H100 Tensor Core GPUs (80GB HBM3), and conducted distributed training for 15 days, processing approximately 160 billion tokens. We monitored the training stability and efficiency using Weights & Biases, and we were able to complete the training without encountering any major issues.
Comparison with the 70B Model
To verify the effectiveness of Depth Up-Scaling, we compared the Japanese continued pre-training curves of the 70B model (Meta-Llama-3-70B-Instruct) and the 120B model (Meta-Llama-3-70B-Instruct expanded to 120B). The figure below shows the progression of training loss over the estimated training FLOPs. As seen in the figure, while the 70B model initially has a lower loss, the 120B model loss decreases more steeply as training continues, eventually becoming lower than the 70B model after 3 x 10^21 FLOPs. This suggests that scaling up the parameters during continued pre-training of a model, rather than training from scratch, can improve the model's learning efficiency.

Post-training
After acquiring Japanese language knowledge and generation capabilities through pre-training, we conducted post-training to enable the model to respond appropriately to user instructions.
Supervised Fine-Tuning (SFT)
SFT improves the model's instruction-following ability by training it on ideal responses to user inputs. As mentioned in many preceding studies, including Llama 3 (Meta, 2024), using high-quality datasets is crucial for SFT. At ELYZA, we have a dedicated Data Factory team for data creation, ensuring dataset quality through manual annotation.
For this project, we constructed a high-quality multi-turn instruction tuning dataset of about 100,000 entries, comprising manually created data and synthetic data generated by LLMs. We used our own "Llama-3-ELYZA-JP-70B" model, which already demonstrates high response performance, to generate the synthetic data. The dataset includes:
- 1. ELYZA's original multi-turn dialogue data: Created from scratch by our internal Data Factory team.
- 2. Modified version of ichikara-instruction data: Based on the ichikara-instruction created by RIKEN AIP, with manual modifications.
- 3. Mathematics and logical reasoning data: Obtained through Rejection Sampling, focusing on mathematical problems and logical reasoning.
- 4. User input-based annotation data: Appropriate responses annotated using an LLM, based on actual user inputs.
It's important to note that our training data does not include any outputs from models like GPT-4o whose terms of service prohibit the use of their outputs for training other models.
Reinforcement Learning from Human Feedback (RLHF)
Due to the limited development period under GENIAC, we didn't implement RLHF techniques such as Proximal Policy Optimization (PPO) or Direct Preference Optimization (DPO). However, we're currently annotating preference data necessary for Reward Model and DPO training internally, which we plan to utilize for future model improvements.
Model Averaging
To enhance the performance of the instruction-tuned model, we adopted the Model Averaging technique, also used in the previous research for Llama 3. By linearly merging (averaging) models that was performed SFT with different settings from multiple pre-training checkpoints, we created a powerful model combining the characteristics of individual models.
We used the linear method implemented in mergekit to perform Model Averaging, taking the weighted average of multiple models. When selecting models, we focused on diversity by choosing models with different strengths (e.g., proficient in mathematics, strong in multi-turn conversations). This approach allowed us to elevate the final model's performance.
Evaluation
Benchmark dataset
Japanese MT-Bench
MT-Bench is a benchmark consisting of 80 multi-turn questions. It is designed to test multi-turn conversation and instruction-following ability, covering 8 common categories: writing, roleplay, extraction, reasoning, math, coding, knowledge I (STEM), and knowledge II (humanities/social science).
Japanese MT-Bench is a translated version of the original (English) MT-Bench, created and published by Stability AI. Unlike multiple-choice tests, Japanese MT-Bench requires free-form responses, necessitating the use of powerful LLMs like GPT-4 for automated evaluation as “LLM-as-a-judge”. In our assessment, we utilized the codebase from the Japanese MT-Bench repository and followed the README instructions to conduct automated evaluations using GPT-4.
ELYZA Tasks 100
ELYZA Tasks 100 is a Japanese benchmark designed to measure the ability of LLM to follow instructions and provide useful responses to users. It comprises 100 data samples containing complex instructions and tasks, each evaluated on a 5-point scale. For the evaluation, we used GPT-4o (gpt-4o-2024-05-13) with an automated assessment prompt. This benchmark aims to provide a comprehensive evaluation of Japanese LLM capabilities in understanding and executing a wide range of tasks, offering valuable insights into their practical applicability and performance in real-world scenarios.
Nejumi Leaderboard 3
Nejumi Leaderboard 3 is a leaderboard developed by Weights & Biases to evaluate Japanese LLMs. It aims to comprehensively compare and assess the performance of Japanese LLMs using benchmarks such as Jaster and MT-Bench. Nejumi Leaderboard 3 has adopted vLLM as its inference library, significantly speeding up the evaluation process and enabling more efficient execution.
We conducted our evaluation using the code available at https://github.com/wandb/llm-leaderboard and referred to the General Language Performance (GLP) scores. While Nejumi Leaderboard 3 also includes an Alignment (AVG) metric, we focused solely on the GLP scores for this assessment, as the dataset used for alignment evaluation is not publicly available.
Evaluation results
Table: Benchmark results

Note: Japanese MT-Bench and ELYZA Tasks 100 scores for models other than Llama-3-ELYZA-JP-120B and Llama-3-Swallow-70B-Instruct-v0.1 are referenced from the scores at the time of the "Llama-3-ELYZA-JP" series release.
Note: Nejumi Leaderboard 3 scores for Llama-3-ELYZA-JP-70B/120B are from local evaluations, while scores for other models are from the public leaderboard.
Our newly developed 122 billion parameter Japanese LLM, Llama-3-ELYZA-JP-120B, consistently achieved higher scores across all three benchmarks compared to Llama-3-ELYZA-JP-70B. This demonstrates that expanding the model through Depth Up-Scaling can achieve better performance than continued training of the original model.
Moreover, Llama-3-ELYZA-JP-120B consistently shows superior performance when compared to the base model Meta-Llama-3-70B-Instruct, its Japanese LLM derivative Llama-3-Swallow-70B-Instruct-v0.1, and even OpenAI GPT-4.
Table: Benchmark scores in 8 categories of Japanese MT-Bench

The above results show category-specific scores for Japanese MT-Bench. These results tell that the 120B model significantly outperforms the 70B model, particularly in the Math category. This improvement suggests that the increased model capacity has enhanced reasoning abilities and generalization performance for mathematical problems.
This comprehensive evaluation across multiple benchmarks and categories provides strong evidence for the effectiveness of our Depth Up-Scaling approach in developing high-performance Japanese language models.
Discussions
Effects of Depth Up-Scaling
Our empirical study demonstrates that the 120B model implemented with Depth Up-Scaling achieves superior performance metrics compared to the 70B model utilizing continual learning. Quantitative evaluations across multiple benchmarks indicate that increasing number of parameters correlates with enhanced knowledge retention and reasoning capabilities.
However, the architectural scaling presents a dual trade-off between performance advantages and operational constraints. The increased model dimensionality results in extended inference latency and degraded response times. Furthermore, the computational requirements necessitate high-performance hardware infrastructure, leading to elevated operational overhead. These factors necessitate careful consideration of the performance-efficiency tradeoff in production-ready model development.
With respect to the 120B model, while there are measurable performance improvements from the increased parameter count, the gains are relatively modest. Consequently, its practical implementation scenarios are limited. However, the model expansion through Depth Up-Scaling proves beneficial in use cases where marginal accuracy improvements of a few percentage points outweigh operational costs, or in applications demanding peak performance capabilities.
A particularly promising application domain for these high-capacity models lies in LLM-based synthetic data generation, an emerging area of focus in the field. This use case presents an optimal deployment scenario as it does not require sustained model deployment but benefits significantly from enhanced model capabilities for high-fidelity data generation. The superior performance characteristics of the scaled model architecture are particularly advantageous in this context.
Potential Application Domains of Depth Up-Scaling
Depth Up-Scaling shows promise in several other scenarios:
Model Size Optimization
Depth Up-Scaling enables precise architectural optimization of open-source foundation models to align with specific infrastructure constraints and deployment requirements. Consider the Llama 3 architecture family, which currently implements 8B and 70B parameter configurations (with subsequent 1B and 3B implementations in Llama 3.2). The significant parameter size gap between 8B and 70B configurations - notably in the 20B-30B range - presents an opportunity for Depth Up-Scaling implementation to synthesize intermediate-scale architectures, thereby enabling more granular optimization of the compute-performance trade-off.
Gradual Model Size Scaling in Pre-training
Empirical analysis of pre-training convergence metrics demonstrates that Depth Up-Scaling facilitates enhanced training efficiency through dynamic model scaling. This finding suggests an optimized training protocol: initializing with reduced-parameter configurations for extensive initial training, followed by architectural scaling-up during the training progression. This method potentially enables increased data throughput given compute-bounded environments.
Limitations and Future Research Directions
Our current implementation focused on scaling from 70B to 120B parameters; however, several research directions remain unexplored.
Extreme Scale Investigation
While we demonstrated successful scaling by approximately 2x, the effects of more aggressive scaling (e.g., to 1T parameters) remain unexamined. Furthermore, our methodology employed a single-step scale-up followed by continual learning, leaving open questions about the potential benefits of incremental scaling protocols during the pre-training phase and their impact on convergence characteristics.
Alternative Scaling Dimensions
Although our Depth Up-Scaling methodology primarily addresses model depth expansion, additional architectural parameters warrant investigation such as Embedding dimension and Feed Forward Network (FFN) hidden layer dimension scaling. These modifications were beyond our current implementation scope due to their architectural complexity but may prove critical for extreme-scale model development.
Analysis of Different Scaling Approaches
While our research focused on architectural expansion, the field has proposed various model compression techniques, including pruning methods. A systematic comparison between bottom-up scaling (expanding smaller model architectures) and top-down scaling (compressing larger model architectures) represents a significant research opportunity for understanding the fundamental trade-offs and characteristics of these opposing approaches.
Conclusion
This article has presented Llama-3-ELYZA-JP-120B, our 122 billion parameter Japanese LLM developed under GENIAC program, and detailed our implementation of the Depth Up-Scaling method. At ELYZA, we maintain our commitment to advancing cutting-edge research and development while making our technical findings publicly accessible, aiming to promote the practical deployment of LLMs in Japan and advance natural language processing technologies.
As a technical note, while this article focused on our latest 120B model development, we're also actively exploring various deployment optimizations. For instance, our previous Llama2 70B based models achieved notable success in production deployment through AWS Inferentia2 accelerators, demonstrating significant inference performance improvements with Speculative Decoding. Such practical deployment considerations remain crucial as we continue to scale our models and services.

Discussion