はじめに
こんにちは。ELYZAの研究開発チームのSam (@SamPassaglia)、佐々木 (@hikomimo)です。
今年の3月に我々は、日本語に特化した700億パラメータの大規模言語モデル「ELYZA-japanese-Llama-2-70b」を開発し、日本語タスクにおいてグローバルモデルに比肩する性能を達成することに成功しました。
この際の知見は、今年6月にリリースした「Llama-3-ELYZA-JP」にも活かされています。
700億ものパラメータを持つ大規模言語モデルを開発することは国内でも前例が少なく、開発を通して多くの学びがあった一方で、思わぬ対応に迫られる場面も少なくありませんでした。
本記事では国内における大規模言語モデル開発のコミュニティに貢献するべく、「ELYZA-japanese-Llama-2-70b」の開発の過程で得られた知見を紹介いたします。
取り組みの概要
ELYZAでは、最先端のオープンモデルをベースに日本語特化モデルを構築することが、日本におけるAIへの多様かつ急速に進化する需要に応えるための、最速かつ実現可能性の高い手段であると信じています。この考えに基づき、我々はいくつもの日本語大規模言語モデル (以下、LLM) を開発してきました。2023年夏には、Meta社の「Llama-2-7b-chat」をベースとした日本語LLMの「ELYZA-japanese-Llama-2-7b」をリリースしました。続く2023年冬には「Llama-2-13b-chat」をベースにした日本語LLMの「ELYZA-japanese-Llama-2-13b」をリリースし、日本語LLM評価用ベンチマーク「ELYZA Tasks 100」において、当時オープンな日本語LLMとしては初めてOpenAI社の「text-davinci-003」を超える性能を叩き出しました。
これらの日本語LLMは、「Llama 2」のベースモデルに対し、およそ20B (200億) トークンの日本語テキストを用いて追加事前学習したのち、指示追従能力と知識網羅性の向上を目的とした事後学習を施したものです。事後学習には、ELYZAが独自に構築した内製データセットを使用しました。なお重要な点として、我々はOpenAI社のGPTシリーズのような「出力を他モデルの学習に利用することが禁じられているモデル/API」の出力は一切学習に利用しておりません。そのため、我々の開発した上記日本語LLMはOpenAI社の規約などにも抵触することはなく、Llama 2ライセンスに従う限りは商用利用も可能となっております。
これらの活動を通じて、オープンモデルに基づいて一定高性能な日本語能力を持った日本語LLMを開発できたものの、グローバルモデル (例: ChatGPT) の性能差と比較するとまだまだ改善の余地がありました。そこで、こと英語単体の性能について言えば、700億パラメータ以上の規模を持つ一部オープンモデルがグローバルモデルに匹敵する性能を達成している現状 (ベンチマーキングプラットフォームである LMSYS Chatbot Arenaを参考) を受け、より大規模なオープンモデル「Llama-2-70b-chat」をベースに日本語タスクにおいてグローバルモデルに比肩するような日本語LLMを構築することに取り組みました。実現にあたっての主な技術的課題を以下に示します:
- 「Llama-2-70b-chat」という大きなパラメータサイズのモデルを扱うための学習基盤の整備
- 日本語追加事前学習におけるトークン数の増加
- 質・量の両面でより優れたフィードバック学習の実施
これらの課題を解決しつつ上記の目標を達成するためにはより多くの計算資源が必要となりましたが、幸いなことに我々は産総研の第2回大規模言語モデル構築支援プログラムに採択され、AI用スパコン「ABCI」上で実験を遂行できました。
モデル構築にあたって、以下のように3つのフェーズに分けて実施をしました。
- フェーズ1: テスト・予備実験 -- 6日間
- フェーズ2: 事前学習 -- 20日間
- フェーズ3: 事後学習 (SFT、フィードバック学習など) -- 31日間
本記事では上記のうち主にフェーズ2の事前学習の部分に重きを置いて紹介いたします。なお期間中にはA100 (40GB) を8枚積んだノード (rt_AFノード) を40ノード利用しました。
事前学習用のコードと性能
事前学習の目標としては具体的には 「Llama-2-70b-chat」を少なくとも100B (1,000億) トークンの日本語で追加事前学習する と設定しました。ここで、「Llama 2」以外のオープンモデルをベースとすることも検討しましたが、今回は過去の取り組みとの親和性などを鑑みて「Llama 2」シリーズを引き続き利用しました。
事前学習にあたり、我々は早い段階で40ノード中の32ノードをメインの事前学習に利用することを決めました。これは、ABCI上の計算ノードには特に稼働時間の保証がされている訳ではないことや、どうしてもGPUを利用した実験では意図しない故障が発生しうると考えられたことから、8ノードは予備として残しておきたかったためです。これらの予備ノードについては、空いているタイミングではモデルチェックポイントの評価に利用したり、その他関連する実験のために利用しました。
このため、32ノード (256GPU) での分散学習も実行でき、かつ100Bトークンの追加事前学習をするにあたって十分に早く、また改善サイクルを極力簡易に回せるような手段が必要となりました。そこで候補に挙がったのは以下2つの選択肢です。
- Megatron-LMやその派生のGPT-NeoXのような、十分な機能を持った既存のライブラリ
- PyTorchに組み込まれているFully Sharded Data Parallel (FSDP)を用いた、シンプルかつより普段から使い慣れている、PyTorchベースのコード
先述のフェーズ1 (テスト・予備実験) の間に、我々はFSDPでもフェーズ2の20日間で160Bトークン程度の学習が可能であると見積もりました。これは障害等によるノード停止が発生しないことを前提とした理論値ではありますが、目標とする100Bトークンの学習は余裕を持って達成できるという見込みとなります。このフェーズ1の間の結果に基づき、我々は上記の選択肢のうちFSDPを利用することに決めました。
テスト・予備実験を踏まえてフェーズ2で計測したところ、GPUあたりの性能は380 tokens/s/GPUとなりました。こちらについては、直近PyTorchの公式ブログで公開されていた結果でも、同様の設定で極めて近い性能となることが示されています。また別途36ノードでも計測しましたが、その場合はGPUあたりの性能が350 tokens/s/GPUに低下することも確認しました。
tokens/s/GPUは学習効率を最大化するにあたって内部的には良い指標となりました。しかしながら、異なるモデルサイズやGPU枚数に依存しない学習効率を測るためには、GPU上で実行される浮動小数点演算の回数 (FLOPS) を計測することもまた重要です。このためには例えば
上記の注意点が前提としてはありつつも、理論値に対して67%というFLOPSは非常に高い部類と言えます。このような成功の背景にはABCIのハードウェア構成、特にInfiniband HDRによる高性能なノード間通信があると考えられます。またその他にも、PyTorch等のソフトウェアに含まれる多くの最適化も寄与していると思われます (backward prefetch、効率化されたアテンションの計算、activation recomputation、fused optimizersなど)
また学習自体の速度に加えて、チェックポイントの保存にかかる時間も考慮すべき事項のひとつです。それぞれのチェックポイントはおよそ800GB程度で、我々はおよそ3時間おきに保存することと決めました。ここではFSDPの StateDictType.SHARDED_STATE_DICT の形式で保存することにより、各GPUはそれぞれが保持するstateを、GPU間の通信を極力せずに独立して保存できます。これにより、800GB程度のチェックポイントの保存時間は3分程度に収まりました。加えて、学習時のノード数を32ノード (256GPU) に固定することにより、チェックポイントからの復帰時に各分割ファイルを結合するといった手間を省けるように考慮しております。なおチェックポイントの評価については、メインの学習が遅くならないように予備ノードで実行していました。
ただしFSDPの利用も順風満帆であったわけではありません。例えば試行錯誤のひとつとして、我々の実験ではデバイスあたりのバッチサイズが小さいほうがより高速な学習に繋がることを確認したため、結果として元の「Llama 2」モデル学習時のバッチサイズよりも小さな値で学習しました。その他に、GPT-NeoXのようなすでに実績のあるライブラリを使った場合には遭遇しなかったであろう多くのバグや課題にもぶつかり、都度対処することとなりました。このうちのひとつとして、後述のモデル保存時のCUDA OOMが挙げられます。また、学習速度がPyTorchのバージョンにより大きく変動することも確認しており、最終的に我々はstableブランチのものでなくNightly 2.3.0.dev20231214のバージョンを利用しました。
監視システム・体制
今回の取り組みでは大規模な学習をするということもあり、安全に進行できるように監視システムや体制を工夫しました。
インシデントが起こった時にできるだけスムーズに学習を再開できるようにするには、以下のような点が重要です。
- チェックポイントを学習の効率を下げないように確実に保存し、止まった際にすぐに再開できるようにすること
- 異常が起こった際にすぐに通知が来るようにすること
ABCIには公式ページに記載されている通り5種類のストレージがあります。
その中でも我々は特にホーム領域、グループ領域、グローバルスクラッチ領域、ローカルストレージの4種類を活用しました。各領域の我々の使い方は以下の通りです。
- ホーム領域: 永続領域ですが、容量が200GiBとそこまで大きくないこともあり、ソースコードや軽めのデータを配置しました。
- グループ領域: 永続領域かつ容量も追加すれば大きくできるため、モデル、データ、またログなどの大きめのデータを配置しました。ただしこの領域の読み込み・書き込みはグローバルスクラッチ領域などと比べて遅めのため、実験中の読み書きは極力グローバルスクラッチ領域から行い、グループ領域は基本的にバックアップ用途で利用しました。
- グローバルスクラッチ領域: 永続領域ではなく、アクセスされないものから順に削除されていくような領域です。ただしこの領域の読み書きは高速であり、かつホーム領域やグループ領域と同様に各ノードからアクセス可能というメリットもあるため、実験中の読み書きにあたってはこちらを主に利用しました。
- ローカルストレージ: 各ノードに紐づいたストレージのため、複数のノードを扱う今回の実験中には直接は読み書きしていません。ただし、グループ領域→グローバルスクラッチ領域へのコピーよりもローカルストレージ→グローバルスクラッチ領域へのコピーのほうが高速という点があり、監視システム中の一部で利用しました。
監視システムではこれらのうちグループ領域、グローバルスクラッチ領域、ローカルストレージを用いました。フローとしては以下のような形となります。なお便宜上、学習を実行するノードを学習ノード、監視を実行するノードを監視ノードと呼称します。
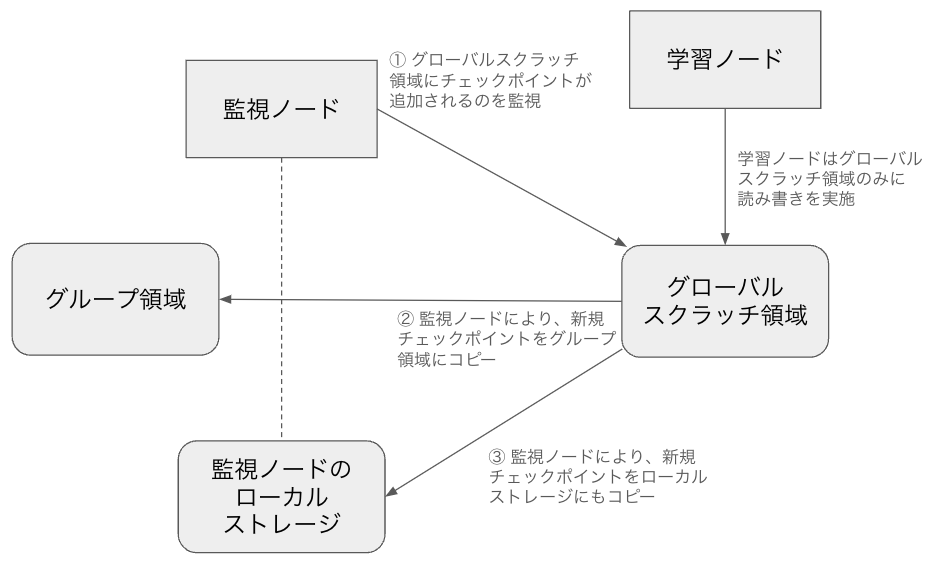
ポイントは以下の点です。
- 学習ノードからはグローバルスクラッチ領域のみに読み書きすることで、比較的高速に、かつノードごとに処理を切り分けるなどすることなく、シンプルな動作を実現しています。
- 監視ノードが学習とは非同期にグローバルスクラッチ領域を監視してコピーの対応をすることで、学習ノードがそれらの対応に時間を割く必要をなくし、GPUが極力暇にならないようにしています。
- グローバルスクラッチ領域は同一グループであってもユーザーごとに独立になっていますが、グループ領域や監視ノードのローカルストレージは同一グループの全員が同様に扱える仕様となっています。この仕様をもとに、別のユーザーが実行した実験を引き継ぐ際に、グループ領域や監視ノードのローカルストレージから実行ユーザーのグローバルスクラッチに、最新のチェックポイントを自動的に持ってくるというフローを構築しています。
学習中は、事故が起きても極力迅速に復旧出来るように5人体制でローテーションしながらベビーシッティングしました。この際は、Weights & Biases上でlossなどの様子を見つつ別途計算ノードのログも見る、といった手順をとりました。なお別途、異常が検知された際にSlackに通知する仕組みも整備し、ベビーシッティング中でないメンバーも (必須参加ではないですが) 気付き次第すぐに障害対応に合流するといった良い流れも出来ていました。LLMの学習には多くの計算ノードが必要であったり、以下のセクションで述べるように様々な障害が起きうることもあり、このように可能な限り複数人で対応するという仕組みが作れていたのも振り返ると重要であったと感じています。
学習期間中の障害等の記録
こちらのセクションでは、期間中に直面した問題について時系列順に並べ、それぞれどのように解決したかを含め紹介します。なお、以下の内容は全期間のうち、フェーズ1のテスト・予備実験の期間、フェーズ2の事前学習の期間に絞って記述しています。
2023/12/14-2023/12/20: 事前準備済みの学習コードの動作確認
障害発生時の復帰対応などの動作確認もここで実施しました。
またこの際に、モデル保存時にGPUのOOMが発生するという課題も発生しました。ここでの対応としては、メモリ上から解放されていない不要な勾配情報を削除したり、 torch.cuda.empty_cache() したりといった手順を踏むことによって解決に至りました。
振り返ると、以降で発生した障害の際にもそこまで大きなトラブルなく復帰できたのは、このあたりの事前確認・検証を入念に行ったことが寄与していると思われます。
2023/12/22: 学習が極端に遅くなった
特にエラーなどは吐かれていませんでしたが、急に学習ステップが極端に遅くなる現象が発生しました。
この際にnccl-testsにより各ノードのパフォーマンスを測定したところ、特定の計算ノードが他計算ノードに比べて極端に遅い状況になっていることを確認したため、それらのノードを利用せずに学習を実行するという選択肢をとり、正常な速度となりました。
これらのケースや以降でご紹介するケースについても都度ABCIのサポートチームに連絡の上、いずれも数日以内にご対応いただいております。
2023/12/28: ノード不調によりジョブが急に止まってしまった (1)
こちらは2023/12/22のケースと異なり、ジョブ自体が止まってしまいました。先述のnccl-testsを試そうとしたところ、そもそも一部の計算ノードでジョブ自体が投下できなくなっていることを確認したため、2023/12/22のケースと同様に当該計算ノードを避けて再実行する形をとりました。
2023/12/31: ノード不調によりジョブが急に止まってしまった (2)
こちらは2023/12/28とほぼ同様の内容のため割愛します。
2024/01/06: NCCL errorが発生し学習が止まってしまった
NCCL error: remote process exited or there was a network error といったエラーにより学習が回らなくなりました。こちらは2023/12/28や2023/12/31のケースと異なり不調なノードを確認できなかったため、単純なネットワークのエラーと捉えて再実行しました。
2024/01/09: ノード不調によりジョブが急に止まってしまった (3)
こちらも2023/12/28、2023/12/31とほぼ同様の内容のため割愛します。
以上を踏まえた知見
まず前提として、LLMの学習時に通常起こり得るloss spikeについては今回一切見られませんでした。これについては、以前我々が公開した「ELYZA-japanese-Llama-2-7b」の事前学習に関する記事に掲載したloss curveにも当てはまることですが、やはりフルスクラッチの事前学習でなく継続事前学習というアプローチをとっている点が寄与していると考えられます。なお、loss spikeが発生した場合の対処も各種事前に検討・実装はしておりました。
次に、やはり多くのGPUを利用する場合には今回のようなハードウェア障害等は避けられないものと考えられます。2023/12/22のケースなどで我々は「障害の発生したノードを利用しないように設定して再度学習を実行する」という障害対応を実施していますが、このように一定の予備ノードを確保することで即座に再実行できるような状態を保つことが肝要です。
また、上記の対応時はnccl-testsを用いるなどして原因究明にあたりましたが、こういった障害発生時の原因調査のためのフローを事前準備することも重要そうです。
本取り組みの成果物
本取り組みで開発した「ELYZA-japanese-Llama-2-70b」については、以下noteにて性能等を公開しております。
なお冒頭でも述べたように、その後「Llama-3-ELYZA-JP」を開発し、日本語の生成能力に関するベンチマーク評価 (ELYZA Tasks 100、Japanese MT-Bench) で「GPT-4」を上回る性能を達成しました。
最新のモデルについては以下デモで試せます。
おわりに
本記事では「ELYZA-japanese-Llama-2-70b」の開発の過程で得られた知見について解説させていただきました。
株式会社ELYZAは、「未踏の領域で、あたりまえを創る」という理念のもと、日本語の大規模言語モデルに焦点を当て、企業との共同研究やクラウドサービスの開発を行なっております。少しでも興味を持っていただけた方は、ぜひカジュアル面談にお越しください!
■ 【Llama-3-ELYZA-JP-70B公開】LLMの研究開発と実用化に向けた取り組みをお話します

ここまでお読みいただき、ありがとうございました。
ELYZAはMLエンジニアはもちろん、ソフトウェアエンジニアやAIコンサルタントなど、様々な職種で一緒に事業を前に進めてくれる仲間を募集しています。詳しくは下記をご覧ください。

Discussion