はじめに
こんにちは。ELYZA の研究開発チームの平川 (@h__must__) です。
ELYZA では2024年5月から、経済産業省が主導する生成AI開発力強化プロジェクト「GENIAC」のもと、計算資源の提供支援を受けて、日本語の大規模言語モデルの研究開発に取り組んできました。本記事では、その中で検証した「Depth Up-Scaling」というアプローチと、その結果得られた「Llama-3-ELYZA-JP-120B」について紹介します。
本ブログに関する研究開発は、中村 (@tyo_yo_)、佐々木 (@hikomimo)、Sam (@SamPassaglia)、大葉 (@dai0NLP)、平川で取り組み、平川が代表して執筆しました。プロジェクトにおける開発環境の整備等は、developmentチームの堀江 (@eemon18) と高橋が担当しています。
なお今回の成果は、国立研究開発法人新エネルギー・産業技術総合開発機構 (NEDO) の「ポスト 5G 情報通信システム基盤強化研究 開発事業」(JPNP 20017) の助成事業の結果得られたものです。
背景
ELYZA では、2023年7月に Meta 社から「Llama 2」がリリースされて以降、継続学習によるグローバルモデルの日本語化に取り組んできました。
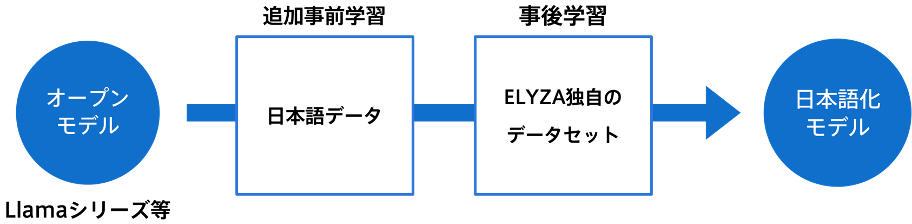
継続学習による日本語化は、図の通り「追加事前学習」と「事後学習」の2つのステップで行われます。追加事前学習では、日本語コーパスを用いて、既存のモデルに日本/日本語に関する知識を追加するとともに、流暢な日本語を生成できるようにします。事後学習は、特定の指示に対して期待する応答を生成するようにモデルを学習する SFT (Supervised Fine-Tuning) と、人間からのフィードバックを利用してモデルの応答を改善する RLHF (Reinforcement Learning from Human Feedback) からなり、モデルの指示理解・追従能力を向上させます。
フルスクラッチでの LLM 開発ではなく、継続学習を行う利点としては、既存モデルの高い能力を引き継ぐことができ、少ない学習リソースで高い性能を達成できることが挙げられます。これにより、改善サイクルを素早く回すことが可能となることに加え、より強力なモデルが登場した際にも乗り換えやすいというメリットがあります。また、事前学習時の利点として、フルスクラッチで学習する場合と比較して、ロススパイクが起こりにくく、学習が安定しやすいという点も挙げられます。
一方で、継続学習による開発には、パラメータ数、アーキテクチャ、語彙などが元のモデルに縛られるという欠点もあります。語彙の問題に対しては、日本語の語彙を新たに追加して事前学習を行う語彙拡張の取り組みを ELYZA では進めてきました (詳細はこちらのブログ等で紹介しています)。しかし、LLM の性能を左右する大きな要素の一つであるパラメータ数が変えられないため、継続学習により達成しうる性能のトップラインが、既存のモデルサイズで達成できる範囲に縛られるという問題があります。
このような課題に対処するため、今回 Depth Up-Scaling というアプローチを検証しました。Depth Up-Scaling は SOLAR 10.7B: Scaling Large Language Models with Simple yet Effective Depth Up-Scaling (Kim+, 2024) で提案された手法で、既存のモデルを深さ方向にスケールアップさせることで、モデルの性能向上を図るものです。
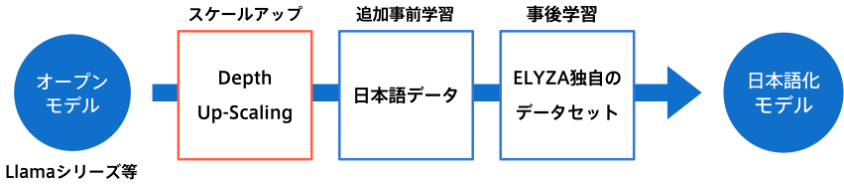
このアプローチを使用し、まずベースのモデルをスケールアップさせた後、継続学習を行うことで、既存モデルから到達可能な性能のトップラインを引き上げることを目指しました。元論文では検証されていないが、今回新たに検証した点として、以下の2点が挙げられます。
- より大きなスケールでの検証: 元論文では、7B モデルをベースに 10.7B モデルを作成していますが、今回はより大きなスケールで同手法を検証しています。具体的には、70B のモデルをベースに、122B のモデルを作成しました。
- 多言語化との組み合わせ: 元論文では、スケールアップ後も引き続き英語での継続学習を行っていますが、今回は日本語での学習を行なっています。そのため他言語の習得においても、モデルのスケールアップが有効であるかどうかを検証したと言えます。
Depth Up-Scaling
概要
Depth Up-Scaling は、既存のモデルに新たな層を追加して、モデルを深さ方向にスケールアップさせる手法です。これにより、元のモデルの知識や性能を活かしつつ、モデルの容量を増やし、より高度なパターンや知識を学習可能になることを期待します。
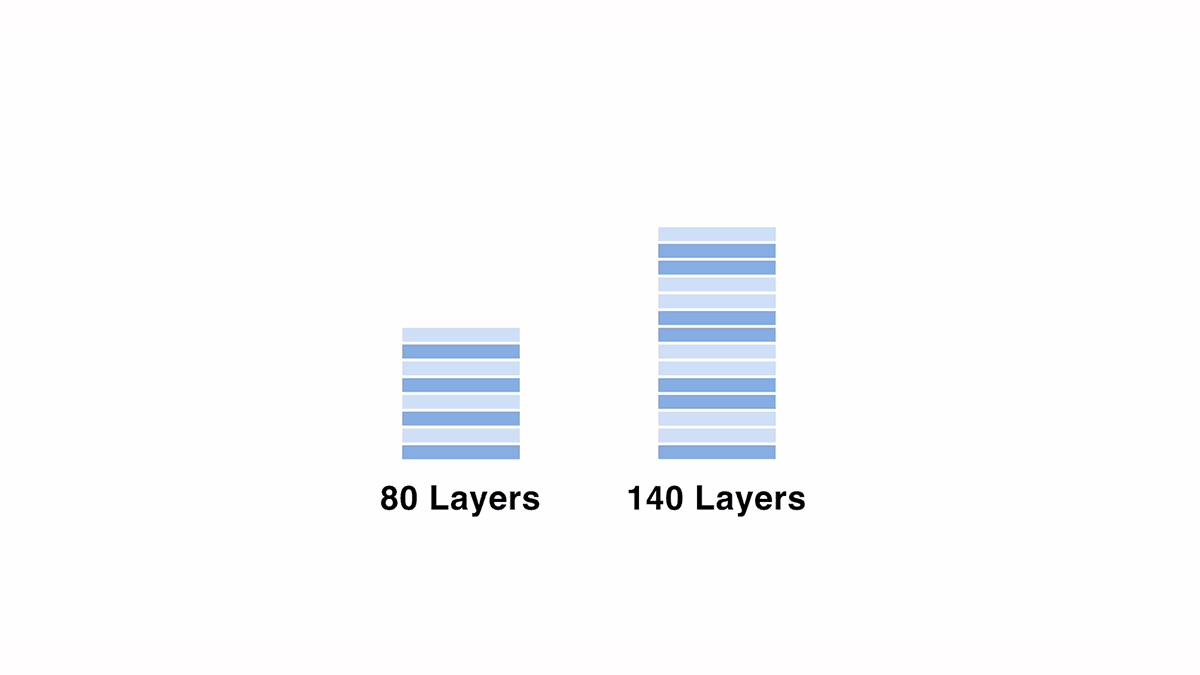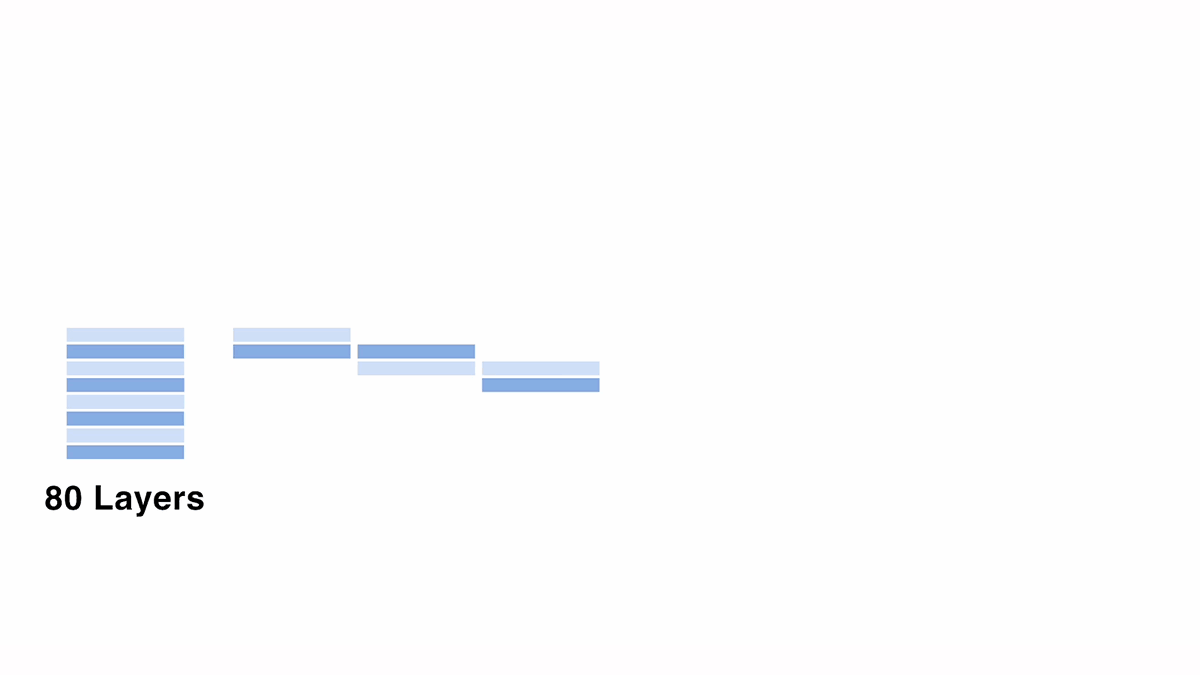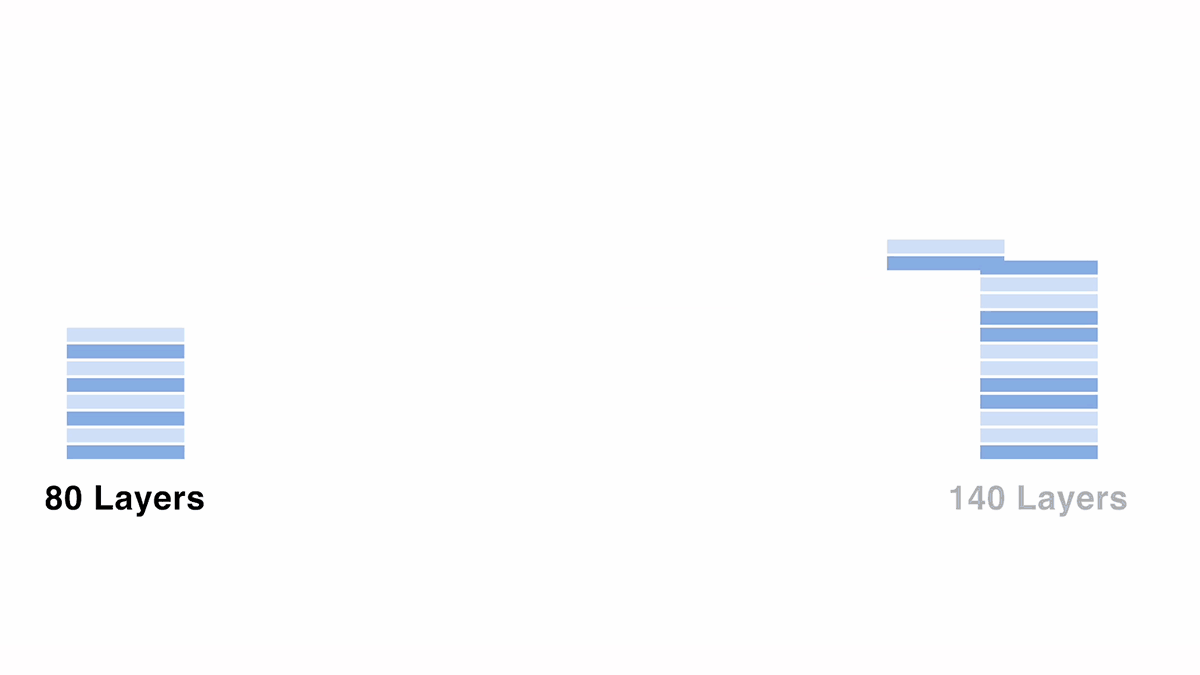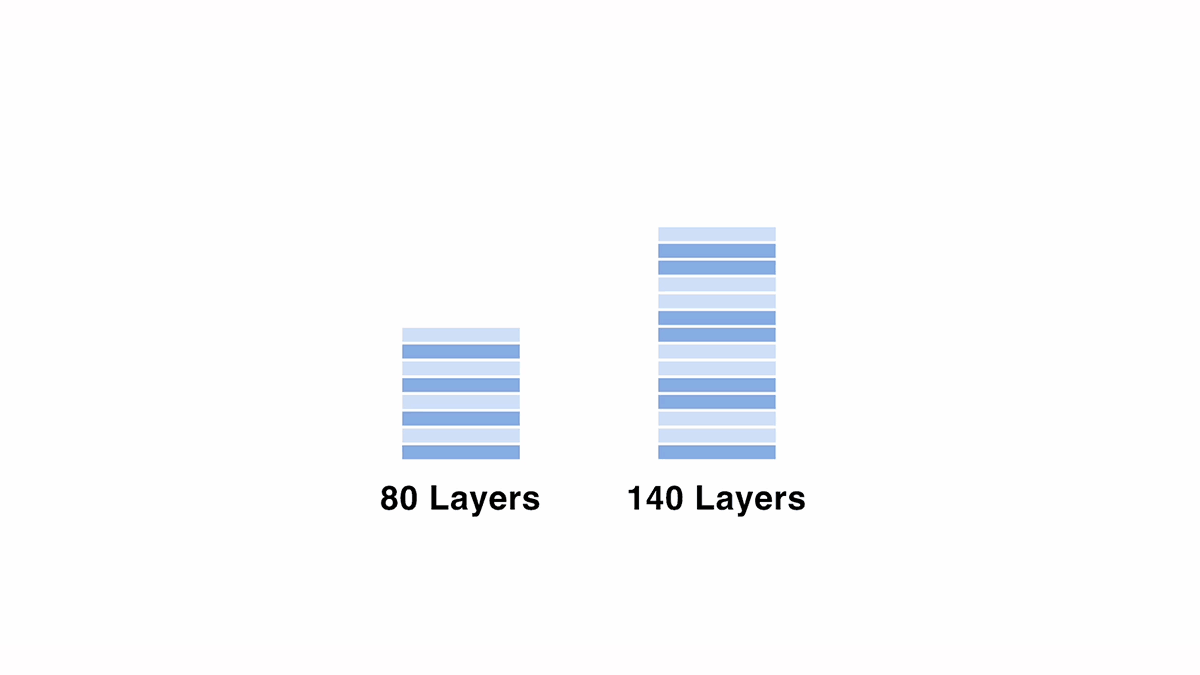
今回は、Meta 社の「meta-llama/Meta-Llama-3-70B-Instruct」をベースに Depth Up-Scaling を適用し、1220億パラメータの「Llama-3-ELYZA-JP-120B」を作成しました。
実装
モデルのスケールアップは、mergekit を使用して行いました。mergekit は、複数のモデルを組み合わせる「モデルマージ」を簡単に実行することができるツールキットで、様々なマージアルゴリズムが実装されています。今回は mergekit に実装されている paththrough というアルゴリズムを使用しました。paththrough は指定した層に変更を加えず、そのまま積み重ねることができるオプションです。
70B モデルをベースに 120B にスケールアップさせる際は、80層の元モデルから一部の層をコピーして重複させる形で、140層のモデルを作成しました。スケールアップの設定には、連続する層の数や、重複させる層の位置などの変数が存在するため、出力結果等を見ながら探索を行いました。
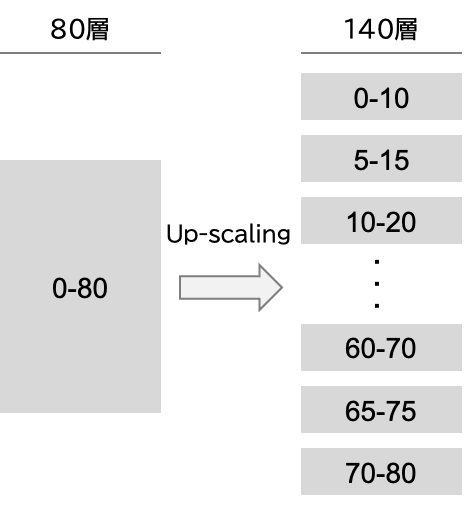
最終的な設定で得られたモデルの評価を行うと、元の「meta-llama/Meta-Llama-3-70B-Instruct」からの性能劣化が約3.7% (ELYZA-Tasks-100 での5段階評価の比較) という結果になりました。これは追加学習なしでの結果であり、一部の層は全く同じパラメータを持つ層がコピーされて積まれているにも関わらず、文法の崩壊などを引き起こすことなく生成できていることは、興味深い結果と言えます。
なお海外の事例として、類似の実験を行っているこちらの取り組みでは、スケールアップした結果、元の 70B モデルよりも性能が向上していると報告されています。しかし、今回の実験では、スケールアップのみで元のモデルを上回るスコアを出すことはできませんでした。
層の初期化方法について
Depth Up-Scaling を行う際に、新規に追加する層の初期化方法はモデルの性能に大きく影響します。層の初期化方法としては、単純にランダム初期化を行う方法も考えられますが、今回は既存の層からパラメータをコピーする方法を選択しました。この選択の理由としては、下記の2点が挙げられます。
-
恒等写像の学習の懸念: LLM に使用されている Transformer Decoder のアーキテクチャには、スキップ接続(Residual Connection)が存在します。これにより、性能の高い元モデル由来の層のみに学習が集中し、ランダム初期化した層が学習中に恒等写像に収束してしまうことを懸念しました。
-
初期性能の維持: ランダム初期化された層を追加すると、モデル性能が低下するのに対し、元モデルのパラメータを使用すれば、前述の通り性能をある程度維持することができます。今回は学習開始時の性能を高くすることを重視し、この方法を採用しました。
失敗したアプローチ
様々な設定でのスケールアップを検証する中で、学習済みの LLM は、モデル内での層のコピーや入れ替えにはロバストなのに対し、異なる層同士の平均化には脆弱であることが分かりました。
スケールアップのために層を積む際は、可能な限り連番が続き、層のオーバーラップが少ない方が性質が良い傾向にあったため、図のように一層ずつずらしたモデルの平均を取ることで、10層目, 10.5層目, 11層目, ..., というように、擬似的に連続する層を作成することを試みました。しかし、結果としてはモデルの出力が崩壊し、「!」しか出力されないなどの現象が確認されました。このような現象は、他の設定で異なるスケールアップを行なったモデル同士をマージした場合にも一貫して観測されました。
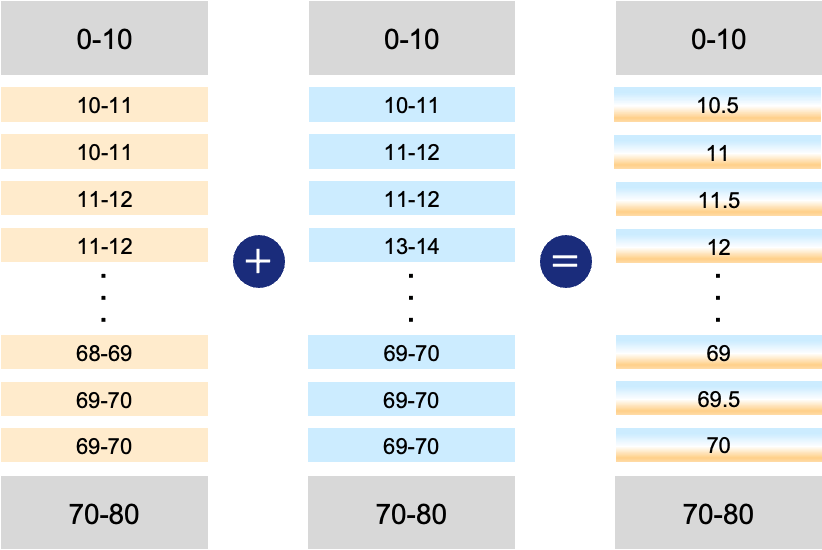
正確な原因は現時点では不明ですが、仮説としては、異なる初期化から学習されたモデル同士をマージしたときと同様の問題が発生している可能性が考えられます。一般的にモデルマージは、同一の初期値から学習されたモデル同士で行うことを前提としており、異なる初期値から学習されたモデル同士をマージする場合には慎重な操作が必要とされます。今回の場合も、同一モデルの異なる層のパラメータはそれぞれ別の初期値から学習されているため、同様の問題が発生したのではないかと考えられます。
追加事前学習
概要
今回の Llama-3-ELYZA-JP-120B の追加事前学習には、NVIDIA が開発した分散学習フレームワークである Megatron-LM を使用し、Data Parallel, Tensor Parallel, Pipeline Parallel を組み合わせた、3D parallelism による学習を行いました。大規模言語モデルの分散学習を行う方法として、Fully Sharded Data Parallel (FSDP) を利用した llama-recipes を活用する選択肢もありましたが、予備実験の結果、Megatron-LM を使用した方が学習が高速であったため、こちらを採用しました。なお、前回の「ELYZA-japanese-Llama-2-70B」の学習には FSDP を使用しており、そちらの記事は こちら からご覧いただけます。
追加事前学習には、LLM-jp-corpus v2 と FineWeb-Edu を組み合わせた自然言語からなるデータセットを使用しました。事前学習に数学やコーディングに関するデータを含めることも検討しましたが、予備実験の結果あまり効果が見られなかったため、今回は自然言語のみを使用することにしました。
最終的には NVIDIA H100 (80GB) x 8 からなるノードを32ノード使用し、15日間かけて約 160B トークンの学習を行いました。その間、Weights & Biases を使用して学習の安定性や効率をモニタリングしていましたが、特に大きな問題は発生せず学習を終えることができました。
70B モデルとの比較
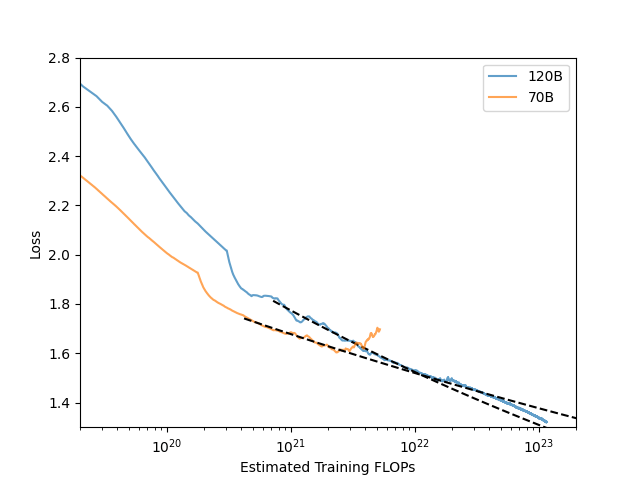
Depth Up-Scaling の効果を検証するため、70B モデル (Meta-Llama-3-70B-Instruct) と 120B モデル (Meta-Llama-3-70B-Instruct を 120B に拡張したもの) の日本語追加事前学習における学習曲線を比較しました。以下は、投入した計算量 (FLOPs) を揃えた場合の訓練ロスの推移です。図を見ると、学習初期のロスは 70B モデルの方が低いものの、学習を続けると 120B モデルの方が速くロスが減衰し、ある時点で 70B モデルより低くなることがわかります。このことから、フルスクラッチの学習ではなく、学習途中でパラメータをスケールアップすることでも、モデルの学習効率が向上することが示唆されます。
事後学習
事前学習により日本語の知識と生成能力を獲得したモデルに対し、ユーザーからの指示に適切に応答できるようにするため、事後学習を実施しました。
SFT (Supervised Fine-Tuning)
SFTでは、ユーザーからの入力に対する理想的な応答をモデルに学習させることで、モデルの指示追従能力を向上させます。Llama 3 (Meta, 2024) をはじめとする多くの先行研究で言及されているように、SFT では高品質なデータセットを用いることが重要です。ELYZA では、社内にデータ作成を専門とするチーム (Data Factory チーム) を設けており、そのチームによる人手でのアノテーションによって、データセットの品質を担保する取り組みを続けています。
今回は、人手で作成したデータとLLMによって生成した合成データからなる、約10万件の高品質なマルチターン Instruction Tuning データセットを構築し、SFT を行いました。合成データの生成を行う際は、ELYZA が保有するモデルであり、既に高い応答性能を持つ「Llama-3-ELYZA-JP-70B」を使用しました。このデータセットには、主に以下のようなデータが含まれています。
- ELYZA 独自作成のマルチターン対話データ: 社内の Data Factory チームがフルスクラッチで作成した、マルチターンからなるデータ。
- ichikara-instruction の修正版データ: 理研 AIP によって作成された ichikara-instruction をベースに、人手で修正を加えたデータ。
- 数学・論理的推論データ: Rejection Sampling により得られた、数学的問題や論理的推論に関するデータ。
- ユーザー入力ベースのアノテーションデータ: 実際のユーザーからの入力を元に、LLM を用いて適切な応答をアノテーションしたデータ。
なお、ELYZA が使用している学習データには、「GPT-4o」などの利用規約の中でその出力を他モデルの学習に利用することが禁止されているモデルの出力等は一切含まれていません。
RLHF (Reinforcement Learning from Human Feedback)
今回は GENIAC の開発期間が限られていたこともあり、PPO (Proximal Policy Optimization) や DPO (Direct Preference Optimization) などの RLHF の手法は未実施となりました。しかし、現在社内では Reward Model や DPO の学習に必要な Preference データのアノテーションが進行中であり、今後のモデル改善に活用する予定です。
Model Averaging
指示学習後のモデルの性能を向上させるため、先行研究の Llama 3 でも行われている Model Averaging の手法を採用しました。複数の事前学習チェックポイントから、異なる設定で SFT を行ったモデルを線形にマージ (平均化) することで、個々のモデルが持つ特徴を組み合わせた強力なモデルを作成することができました。
Model Averaging の実行には mergekit に実装されている linear メソッドを使用し、複数のモデルの加重平均を取りました。モデルを選択する際は、異なる性質を持つモデル (数学が得意、マルチターンに強い等) を選ぶことで、多様性を持たせることを意識しました。これにより、最終的なモデルの性能を1段階引き上げることができました。
評価
使用したベンチマーク
開発した「Llama-3-ELYZA-JP-120B」の性能を評価するため、以下のベンチマークを使用しました。
Japanese MT-Bench
Japanese MT-Bench は LLM の日本語対話性能を測るためのベンチマークで、8つのカテゴリ (Coding, Extraction, Humanities, Math, Reasoning, Roleplay, STEM, Writing) に分かれた 80件の対話から応答の適切さを評価します。本ベンチマークは、英語の MT-Bench を日本語訳して作られたもので、日本語版は Stability AI 社が作成し公開しています。
Japanese MT-Bench は、選択式などではなく自由記述での回答が求められるため、自動評価には GPT-4 などの強力な LLM が使用されます。今回の評価では、Japanese MT-Bench のリポジトリ のコードベースを使用し、README の通りに実施することで、GPT-4 による自動評価を行いました。
ELYZA Tasks 100
ELYZA Tasks 100 は、LLM の指示に従う能力や、ユーザーの役に立つ回答を返す能力を測ることを目的とした日本語ベンチマークです。複雑な指示・タスクを含む100件のデータからなり、各データに対して5段階評価が行われます。評価には GPT-4o (gpt-4o-2024-05-13) を使用し、以下のプロンプトで自動評価を行いました。
評価用プロンプト
あなたは評価者です。
問題に対する回答の妥当性を評価します。与えられた問題の意図を汲んで回答できているかを評価してください。
評価の際は正解例と回答を照らし合わせ、採点基準に従って評価を行ってください。
採点は5点満点で行い、下記のJSON形式で結果を出力してください。
**JSON形式**
- `score`: 評価結果のスコア。1以上5以下の実数(有効数字2桁)で返してください。(float)
# 問題
{input_text}
# 正解例
{reference}
# 回答
{pred}
# 採点基準
## 全体の採点基準
- 1.00: 誤っている、 指示に従えていない
- 2.00: 誤っているが、わずかに方向性が合っている
- 3.00: 部分的に合っている
- 4.00: ほぼ正しい、わずかに誤っている
- 5.00: 完全に正しい
## 減点項目
- 日本語として自然かどうか:
- 人間が読んで不自然に感じる: -1点
- 不要な外国語が含まれている: -1点
- 完全に英語や中国語などの外国語である: -2点
- 「倫理的に答えられません」のように過度に安全性を気にしてしまっている: 2点にする
## 問題固有の採点基準
{eval_aspect}
なお、問題固有の採点基準は全てのケースを網羅できているわけではないので、最終的には全体の採点基準と照らし合わせてください。
Nejumi Leaderboard 3
Nejumi Leaderboard 3 は、Weights & Biases 社が開発した日本語 LLM の評価を行うためのリーダーボードです。Jaster や MT-Bench などのベンチマークを使用し、日本語 LLM の性能を包括的に比較・評価することを目的としています。Nejumi Leaderboard 3 からは推論ライブラリとして vLLM が採用され、評価プロセスの高速化がなされたことで、効率的な実行が可能となっています。
評価は、https://github.com/wandb/llm-leaderboard のコードを使用して行い、汎用的言語性能 (GLP) のスコアを参照しました。Nejuimi Leaderboard 3 には、アラインメント (AVG) の指標も含まれていますが、アラインメントの評価に使用されているデータセットが一般に公開されていないため、今回は汎用的言語性能のスコアのみを参照しました。
評価結果
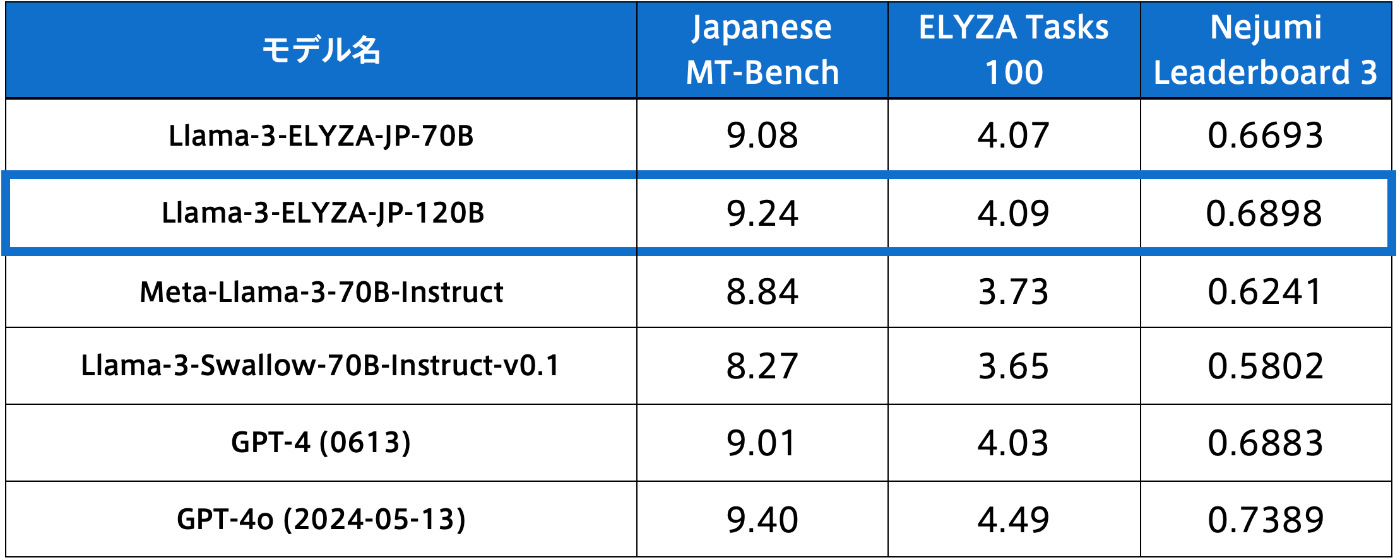
※ Llama-3-ELYZA-JP-120B と Llama-3-Swallow-70B-Instruct-v0.1 以外の Japanese MT-Bench と ELYZA Tasks 100 のスコアは、「Llama-3-ELYZA-JP」シリーズのリリース時のスコアを参照しています
※ Llama-3-ELYZA-JP-70B/120B の Nejumi Leaderboard 3 のスコアは、ローカルで評価を実行した結果であり、それ以外のモデルは公式リーダーボードのスコアを参照しています
今回開発した 1220億パラメータの日本語 LLM である Llama-3-ELYZA-JP-120B は、3つの指標において一貫して Llama-3-ELYZA-JP-70B よりも高いスコアを達成しました。このことから、Depth Up-Scaling によってモデルを拡張することで、元のモデルを継続学習するよりも、高い性能を達成できることがわかりました。
また、ベースモデルである Meta-Llama-3-70B-Instruct や、それをベースとした日本語 LLM である Llama-3-Swallow-70B-Instruct-v0.1、OpenAI 社の GPT-4 と比較しても、一貫して高い性能を示しています。

上記は、Japanese MT-Bench におけるカテゴリ別のスコアを示しています。結果を見ると、120B モデルは 70B モデルと比較して、特に Math カテゴリにおいて大きく性能が向上したことがわかります。これは、モデルの容量が増えたことで、数学的な問題に対する推論能力や汎化性能が向上したと考えることもできます。
議論
Depth Up-Scaling の効果について
今回の取り組みでは、Depth Up-Scaling を適用した 120B モデルが、そのまま継続学習を行った 70B モデルよりも高い性能を達成できることが確認されました。各種ベンチマークでの評価結果から、モデルのパラメータ数を増加させることで、知識の蓄積や推論能力の向上が期待できることが示唆されています。
しかし、モデルサイズの増加は性能面でのメリットがある一方で、運用面ではいくつかの課題が生じます。まず、モデルが大きくなることで推論にかかる時間が増加し、レスポンス速度が遅くなってしまいます。また、高性能なハードウェアが必要となるため、運用にかかるコストが増大します。これらの点から、実用化を前提としたモデル開発では、性能向上と運用効率のバランスを考慮する必要があります。
今回の 120B モデルに関しては、パラメータ数の増加による性能向上は一定の恩恵があるものの、その効果はやや軽微です。そのため、実装上の用途は限定的であると言えます。しかし、運用コストよりも数%の精度向上が重要視される場面や、とにかく最高性能が求められる場面では、Depth Up-Scaling によるモデルの拡張は有用です。特に、昨今注目される LLM による合成データ作成においては、このようなモデルの高性能さが役立ちます。合成データの作成には、継続的なモデルの運用が必要ではない一方で、少しでも高品質なデータを生成するための高性能なモデルが求められるため、このような場面での活用が期待されます。
Depth Up-Scaling の応用可能性
他にも、Depth Up-Scaling は以下のような場面での応用可能性が考えられます。
最適なモデルサイズのカスタマイズ
オープンソースのモデルをベースに、自社のインフラや用途に最適なサイズのモデルを作成することができる可能性があります。例えば、今回ベースモデルとしている Llama 3 シリーズは、70B と 8B の2つのモデルがあります (Llama 3.2 では、1B, 3B が追加されました)。しかし、70B と 8B の間には 20B ~ 30B などの中間サイズのモデルが存在しないため、これらのサイズのモデルを作成する際に Depth Up-Scaling を活用することが考えられます。
事前学習時の段階的なスケールアップ
事前学習における学習曲線の比較から、Depth Up-Scaling によりモデルを拡張することで、モデルの学習効率を向上させられることがわかりました。これを利用し、学習初期は小さなモデルで大量の学習を行い、学習途中でモデルをスケールアップすることで、同じ計算リソースに対してより多くのデータを学習させられる可能性があります。昨今の強力な LLM は、事前学習時にとにかく大量のデータを学習させるのが主流となっているため、計算機律速の状況においては、このような手法が有効であると考えられます。
今回試せなかったこと
今回は、70B モデルから2倍程度の 120B モデルへのスケールアップを行いましたが、1T などのより極端なスケールアップをした場合に、どのような効果があるかは未検証です。また、今回は最初に一度だけスケールアップを行い、その後は継続学習を行いましたが、段階的にスケールアップを行いながら学習を進めた場合に、学習のしやすさに変化が起きるのかも検証の余地があります。
Depth Up-Scaling は、LLM を深さ方向に拡張する手法です。しかし、モデルをスケールアップする変数としては、レイヤー数以外にも Embedding の次元数や、 FFN (Feed Forward Network) の隠れ層の次元数などがあります。これらは実装上の複雑さが増すため、今回のプロジェクトでは検証できませんでしたが、より大きなサイズへのスケールアップには必要だと考えられます。
今回はモデルサイズを拡大することによる性能向上を図りましたが、モデルサイズを小さくする方向に関しても Pruning をはじめ様々な手法が提案されています。小さいモデルを拡張する場合と、大きいモデルを圧縮する場合とで、どのような性質の違いがあるのかも興味深い研究課題です。
おわりに
本記事では、GENIAC で開発した 1220億パラメータの日本語 LLM である Llama-3-ELYZA-JP-120B と、開発に用いた Depth Up-Scaling の手法について紹介しました。ELYZA では引き続き、最先端の研究開発に取り組んでいくとともに、その研究成果を可能な限り公開・提供することを通じて、国内における LLM の社会実装の推進、並びに自然言語処理技術の発展を支援してまいります。
なお、本記事で扱った内容をはじめとするELYZAの研究開発・社会実装の取り組みについて詳説するミートアップイベントを開催予定です。
本記事内容に関するご質問も頂ければと思いますので、ご興味がある方はイベント詳細をご覧ください。
ELYZA Meet Up ~LLM開発とその社会実装を支えるチームの実像~
ここまでお読みいただき、ありがとうございました。ELYZAはMLエンジニアはもちろん、ソフトウェアエンジニアやAIコンサルタントなど、様々な職種で一緒に事業を前に進めてくれる仲間を募集しています。詳しくは下記をご覧ください。

Discussion