はじめに
TROCCO&COMETAを触ってみた!を書いていたら、dbtメタデータ連携の機能がリリースされていたため早速試してみました!
dbtメタデータを連携したことでテーブルのアセット情報やリネージが反映され
よりCOMETAが使いやすくなります!
dbtメタデータ連携前
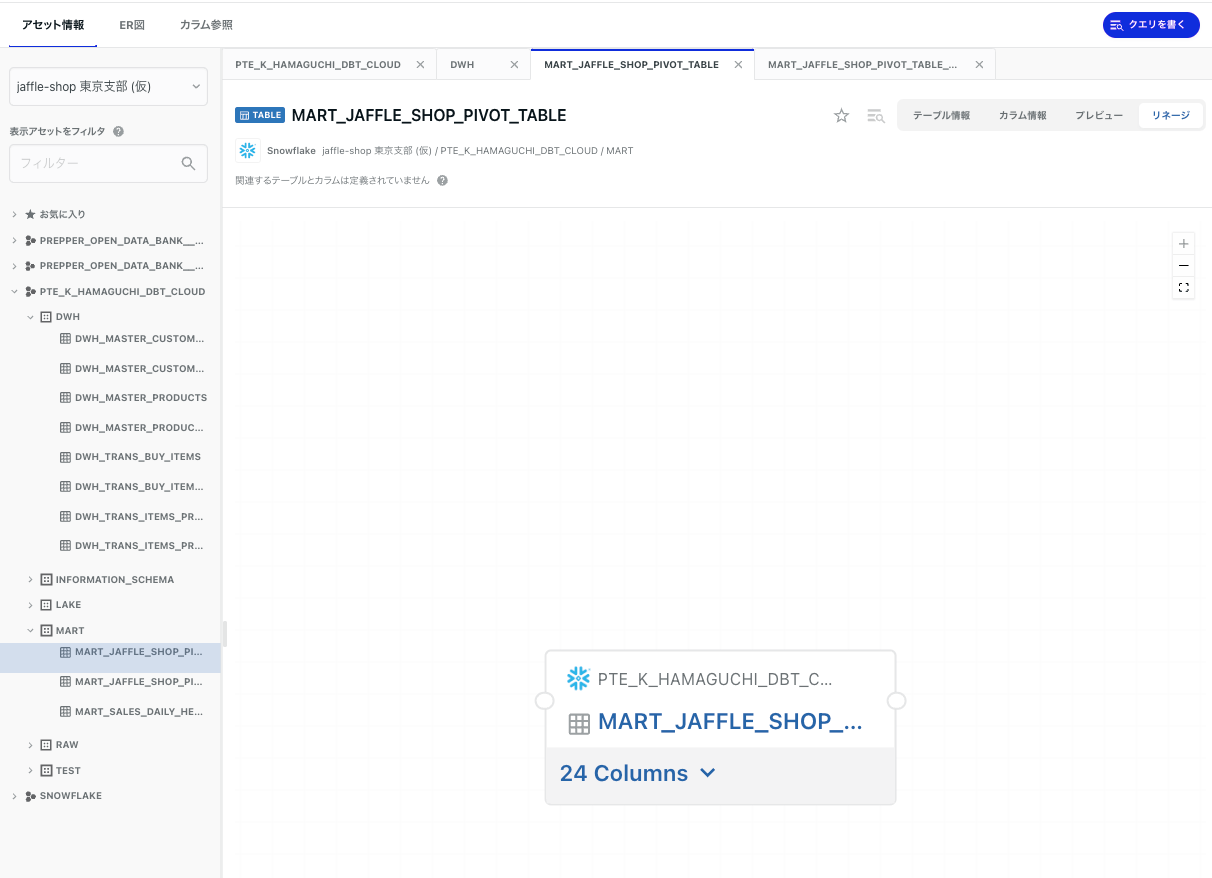
dbtメタデータ連携後
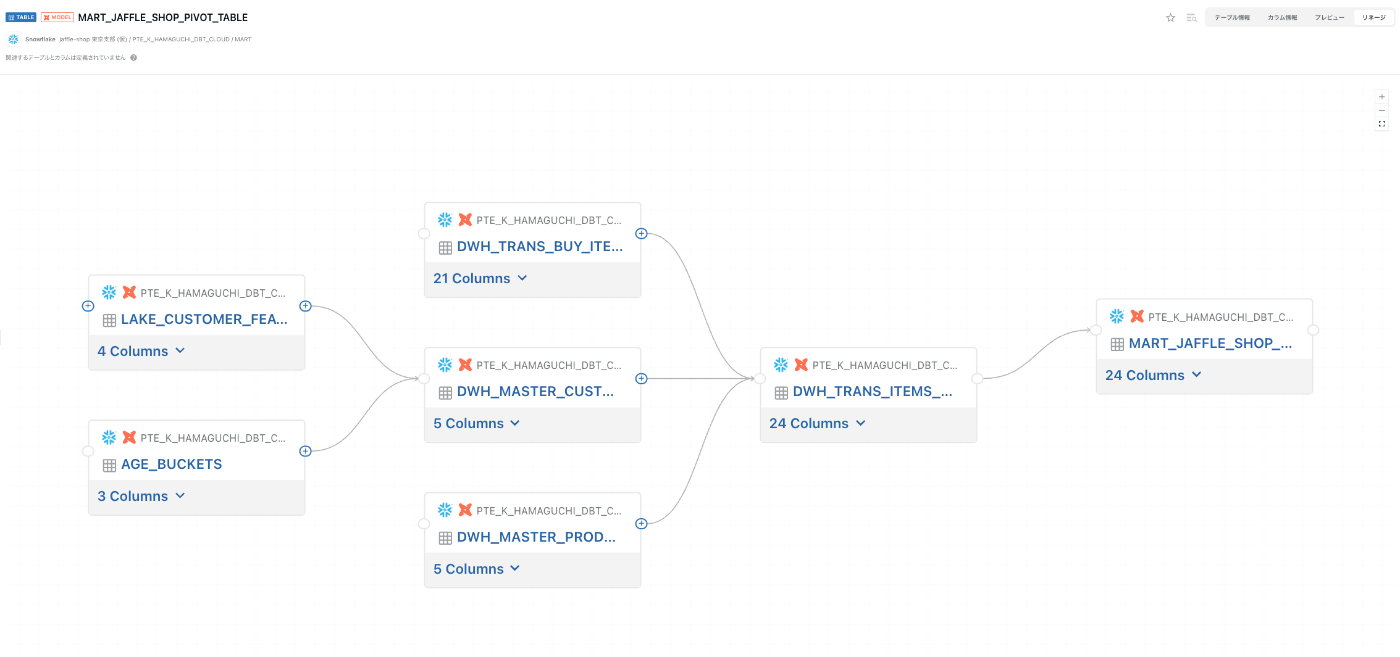
dbtを使っていてCOMETAを試そうかなと考えている方は是非試していただけると幸いです☕
事前準備
- COMETA
- データストア作成済み
- dbtで管理しているテーブルを連携済み
- S3
- dbtの
catalog.json・manifest.jsonを配置するのに必要
- dbtの
- dbt or dbt Cloud
-
dbt docs generateができる環境であればOK - dbt Cloudの場合はRun結果のArtifactsからダウンロードできます
-
- Snowflake (任意のDBやDWH)
- ユーザ・RSAキーペア作成済み
- ダミーデータ
- Streamlit in Snowflake + dbt Cloudでデータの可視化をしてみる!で使用したデータを使います。
S3の準備
公式ドキュメントに手厚く手順が載っているため、見つめながら進めていきます。
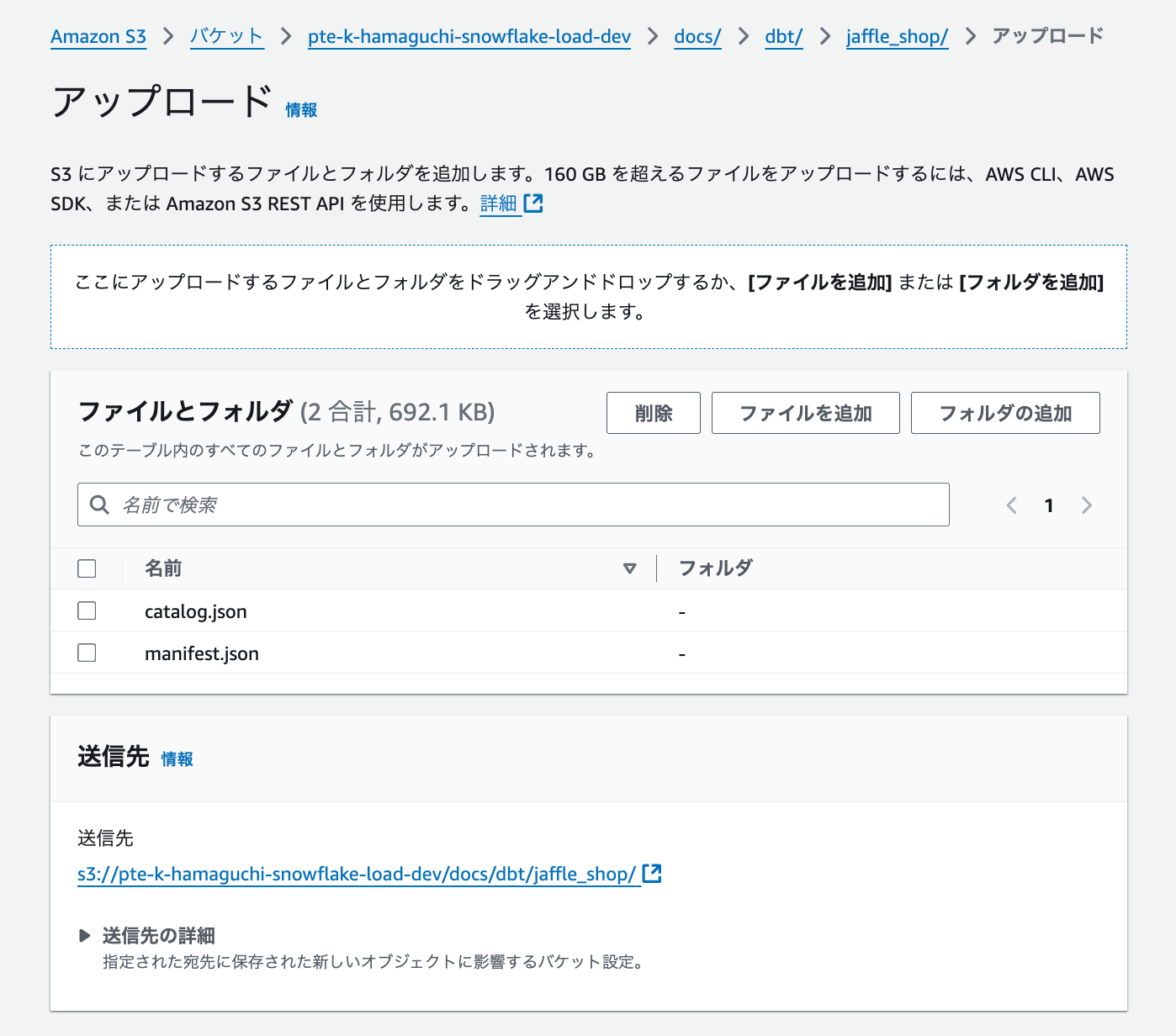
バケットへの格納
dbt docs generateやdbt Cloudでcatalog.json・manifest.jsonを取得し、アップロードしていきます。
私は以前のバケット階層に docs/dbt/<source_data_name> を掘って配置しています。
後に docs/dbt/<source_data_name>は使用するのでメモです📝
IAMロール作成 & 権限付与
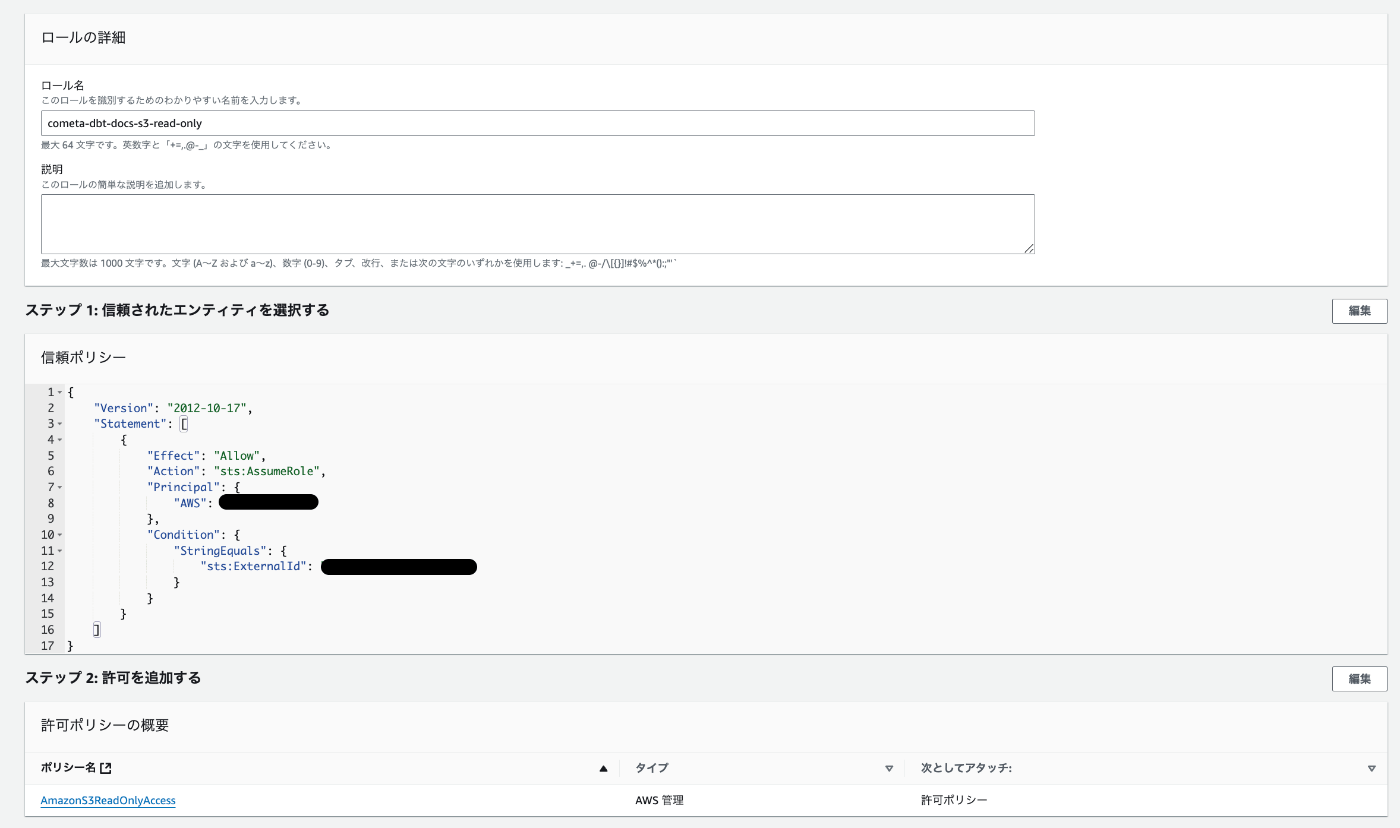
コンソール→IAM→ロール→ロールを作成を選択します。
下記の項目を埋めていきます。
- 信頼されたエンティティタイプ:AWSアカウント
- 元はTrusted entity type
- AWSアカウント:別のAWSアカウント
- アカウントID:COMETAのAWSアカウントID
-
データストア連携管理→<データストア名>→dbtメタデータ連携→+追加を開いて確認する必要があります。
-
- 外部ID:任意の文字列
- 任意の文字列ですが特殊記号(
!&<>)をいれる場合は注意が必要です。私は何故か&を入れて通らなかったため
- 任意の文字列ですが特殊記号(
- MFA:使いません

次へをクリックと権限付与に遷移するため下記を満たす権限を付けましょう。
- s3:GetObject
今回はポリシーを作ってないのでAmazonS3ReadOnlyAccessで代用します。

次へをクリックして任意のロール名を付けてロールを作成しましょう
(今回は命名ルールも特にないので自由に付けてます)
dbtメタデータ連携
データストア連携管理→<データストア名>→dbtメタデータ連携→+追加を選択します。
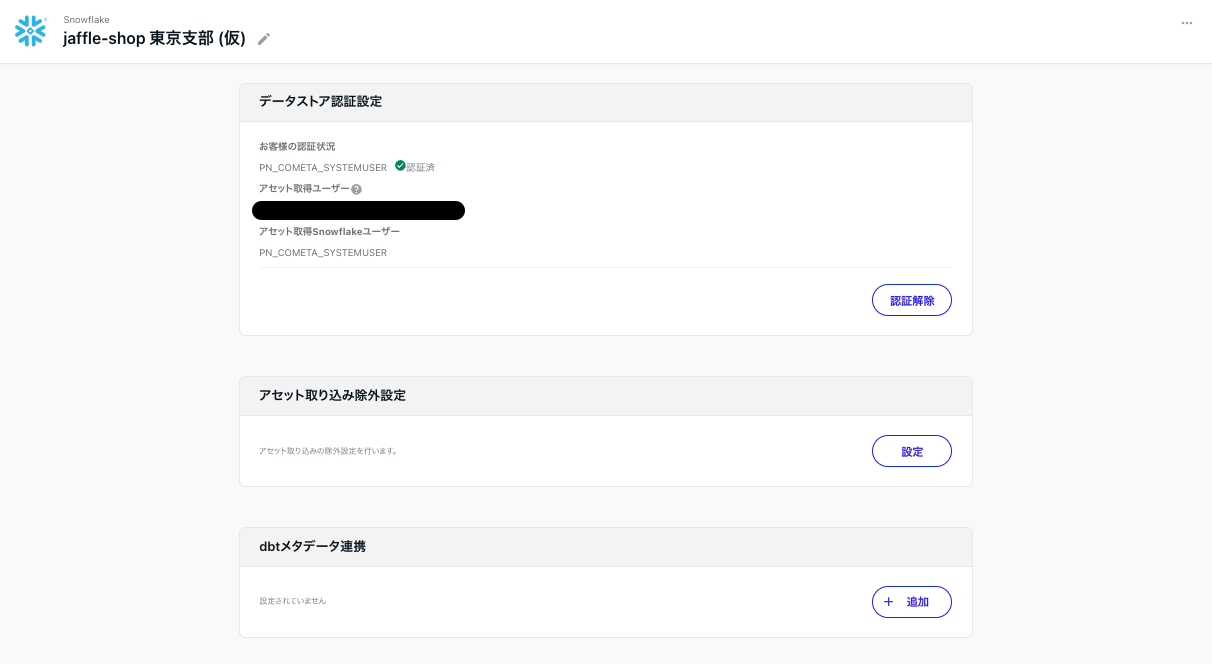
下記の項目を埋めていきます
- dbtメタデータ連携名:任意です (複数の連携が可能なのでdbtのPJ名がわかりやすいと思います。)
- ロールARN:IAMロールのARNをコピー&ペーストしてください
arn:aws:iam::<your_aws_account_id>:role/<role_name>
- 外部ID:IAMロールで作成した外部IDをコピー&ペーストしてください
- もし忘れた場合は
ロール名→信頼関係を見るとsts:ExternalIdの項目に書いてあります
- もし忘れた場合は
- バケット:S3のバケット名
- dbtの
catalog.json・manifest.jsonを配置したS3のバケット名を入れてください
- dbtの
- パスプレフィックス:
docs/dbt/<source_data_name>- バケット直下に
catalog.json・manifest.jsonを配置していない場合はパスを入力してください
- バケット直下に
保存をクリックするとdbtメタデータの連携が始まります。
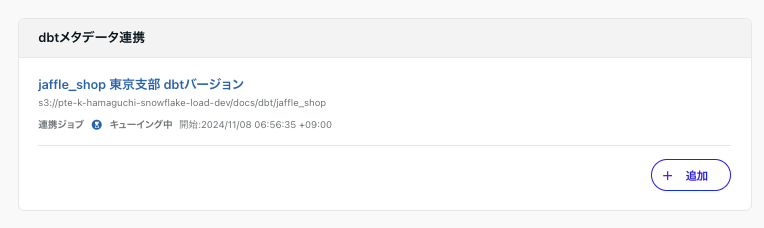
実行完了になると連携完了です。
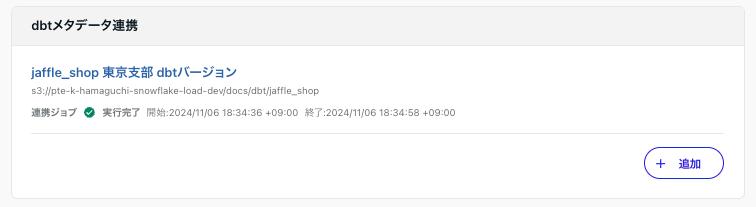
全ての連携が完了したのでCOMETAのデータベースを見ていきましょう!
COMETAのデータベースを確認する
dbtメタデータを連携することで下記の項目が追加されてました。
- テーブル情報
- dbtの
SOURCE/MODEL/SEED等の種別 - dbtに関するメタデータ
- dbtの
- カラム情報
- dbtに関するメタデータ
- リネージ
- グラフの生成
試した範囲で情報を記載しておきます。
SOURCE
ドキュメントやタグ情報を見ることができます。
MODELとのリネージは繋がりがなさそうです。
テーブル情報
SOURCEで定義されたアセットは下記のようにYAMLに書いたドキュメントが連携されてました。
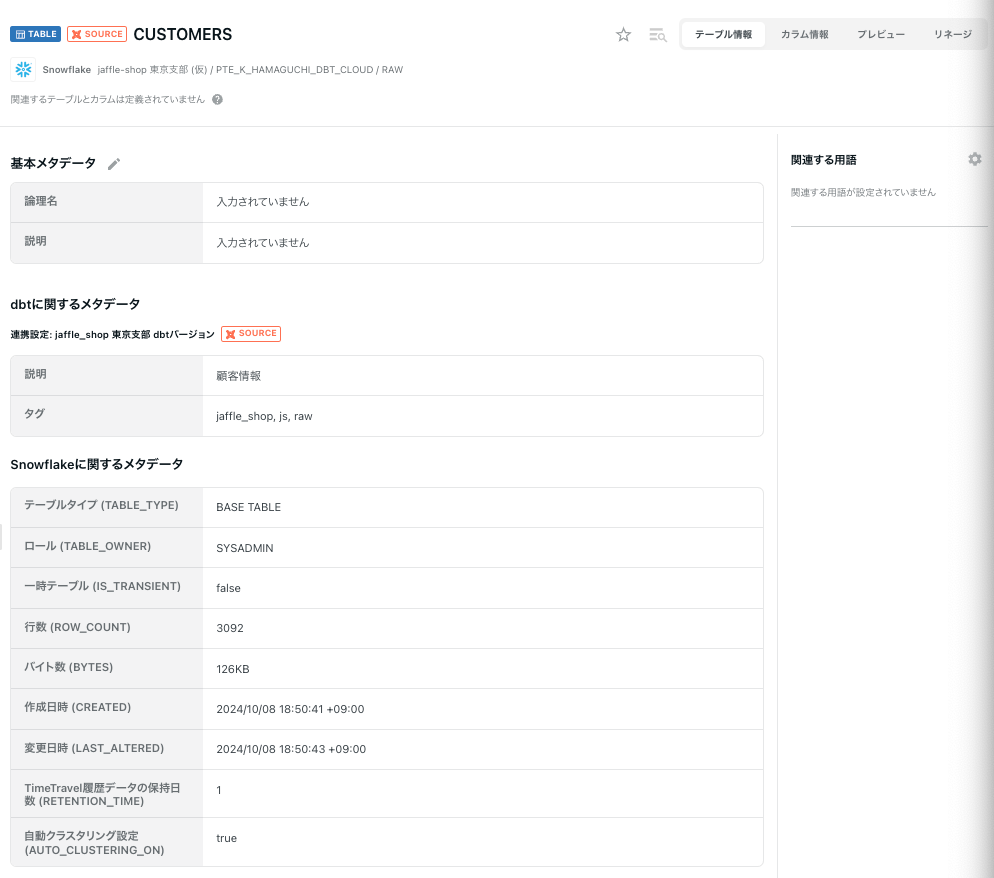
カラム情報
テーブル情報と同じくYAML記載のドキュメントが連携されてます。

リネージ
SOURCEのリネージはつながりがないようです。 COMETA側に修正が入りました!
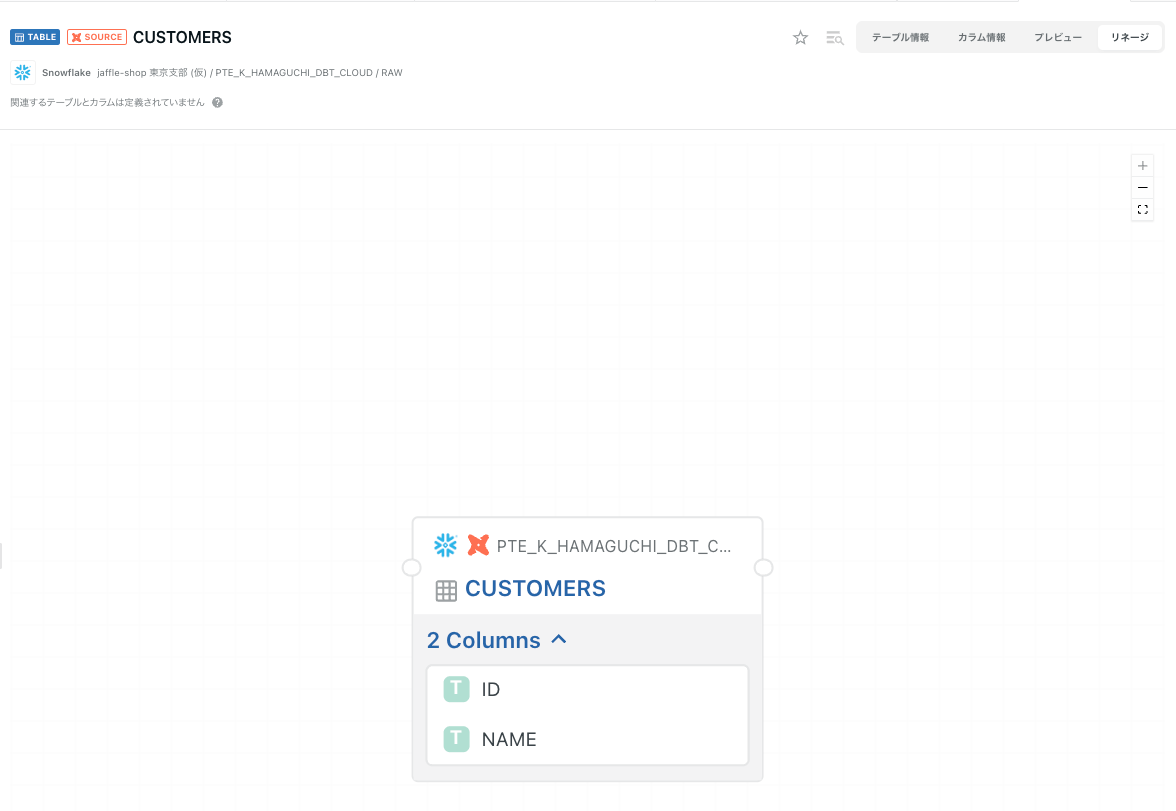
本家だとこんな感じです。(lake_customer_featuresと関連があります。)
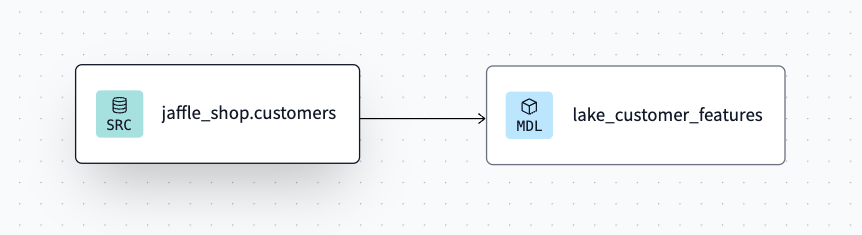
2024/11/13追記
COMETAに修正が入り下記の通りリネージでダウンストリームが確認できます 🎉
(素早い対応に感謝です!)

MODEL
テーブル情報
SOURCEの情報に加えてコンパイルされたSQLも見ることが可能です。
(クエリエディタで確認もできるので何かと便利ですね!)
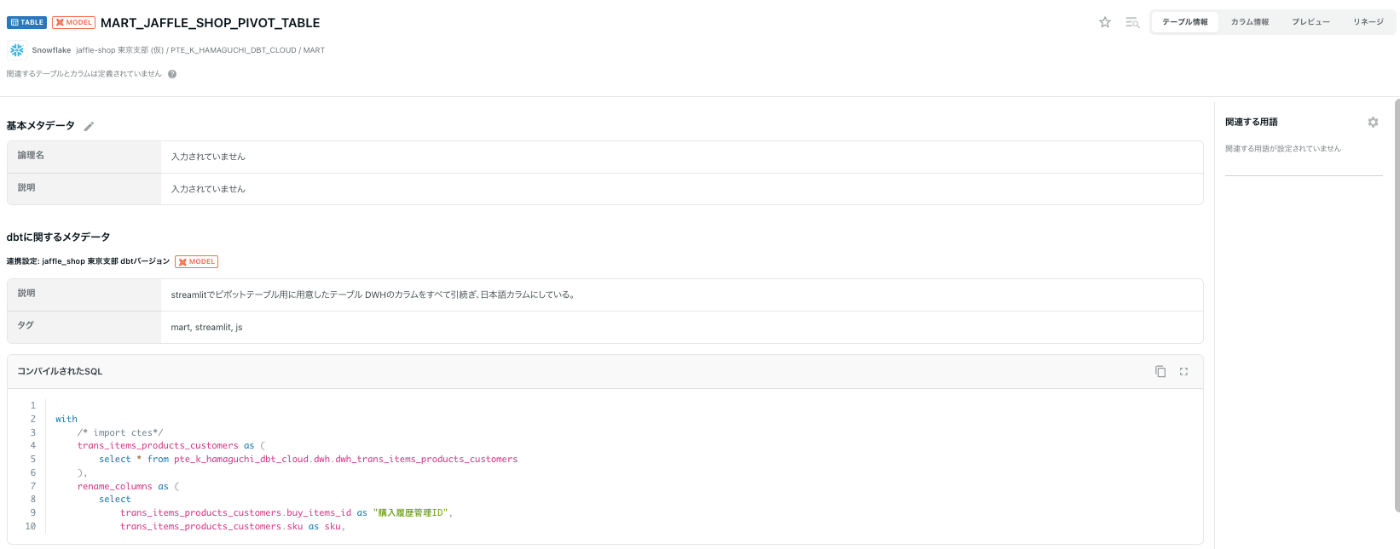
全画面のアイコンを押すとソースコードが全て見れます。
(長いため一部表示)

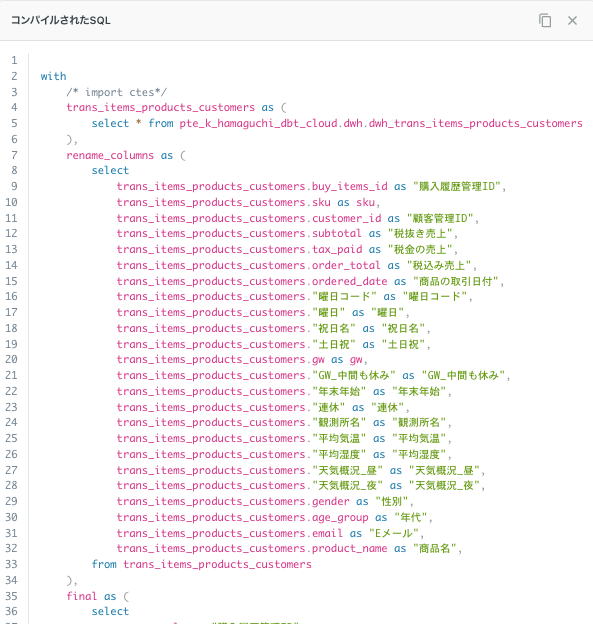
クエリエディタでどんな感じで加工しているのか中間部分がサクッと見れるので良さそうです👍
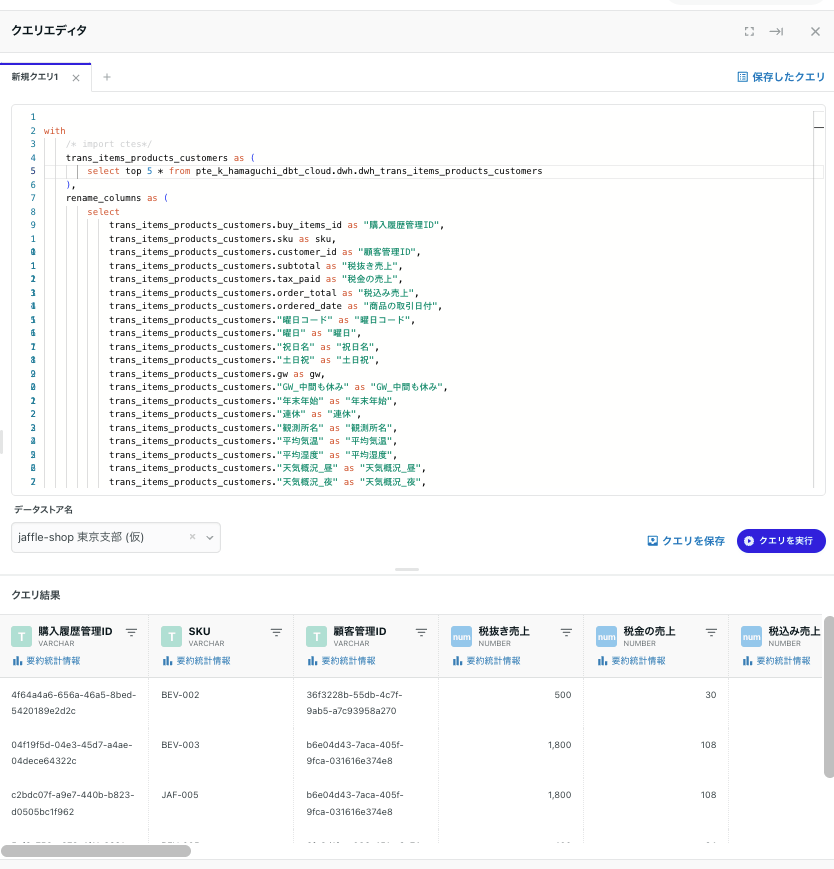
カラム情報
説明の情報が見えてます。
dbt側でpersist_docsの設定をしているため、Snowflakeのコメントにも同じ内容が記載されていることがこれでわかりますね〜

ちょっとだけ横道にそれるんですが、
TRANデータでSKUの含有率とかわかるなら、
これだけで売れ筋の商品をチラ見できますね〜💳
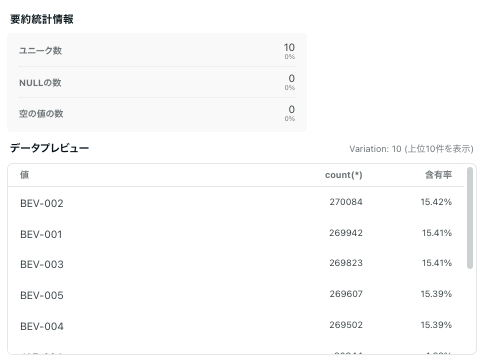
リネージ
期待していた部分!
「+」を押していくとアップストリームの情報が全て見れます。
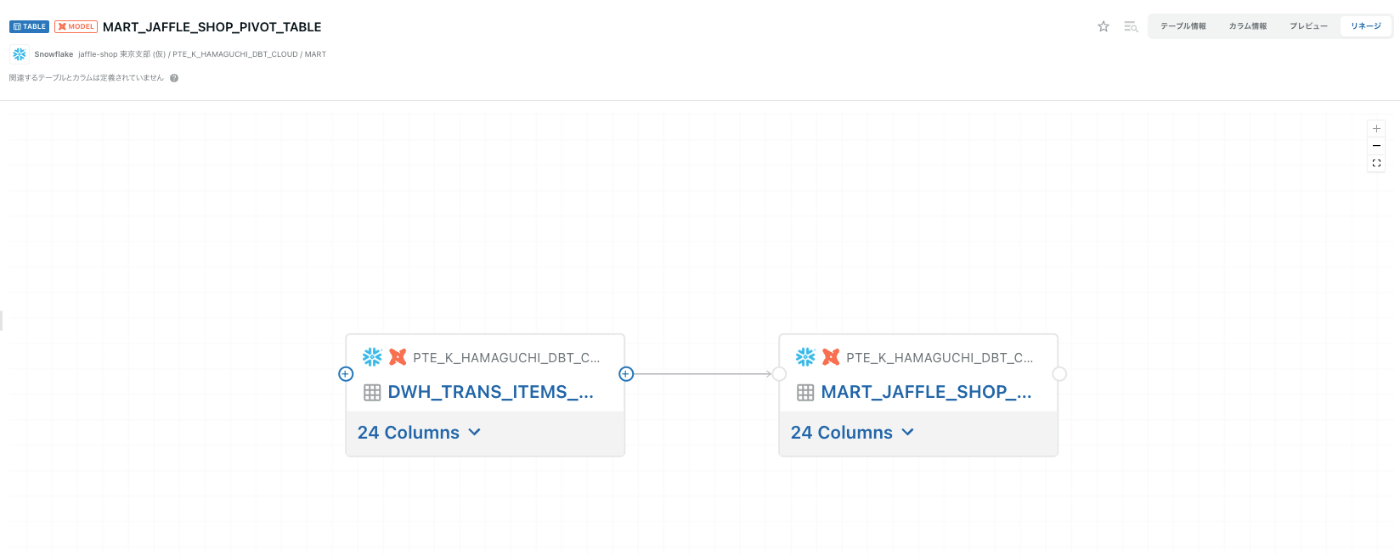
情報量が少し多くなりますが、カラム一覧で次々とリネージが見れるのはとても便利ですね〜
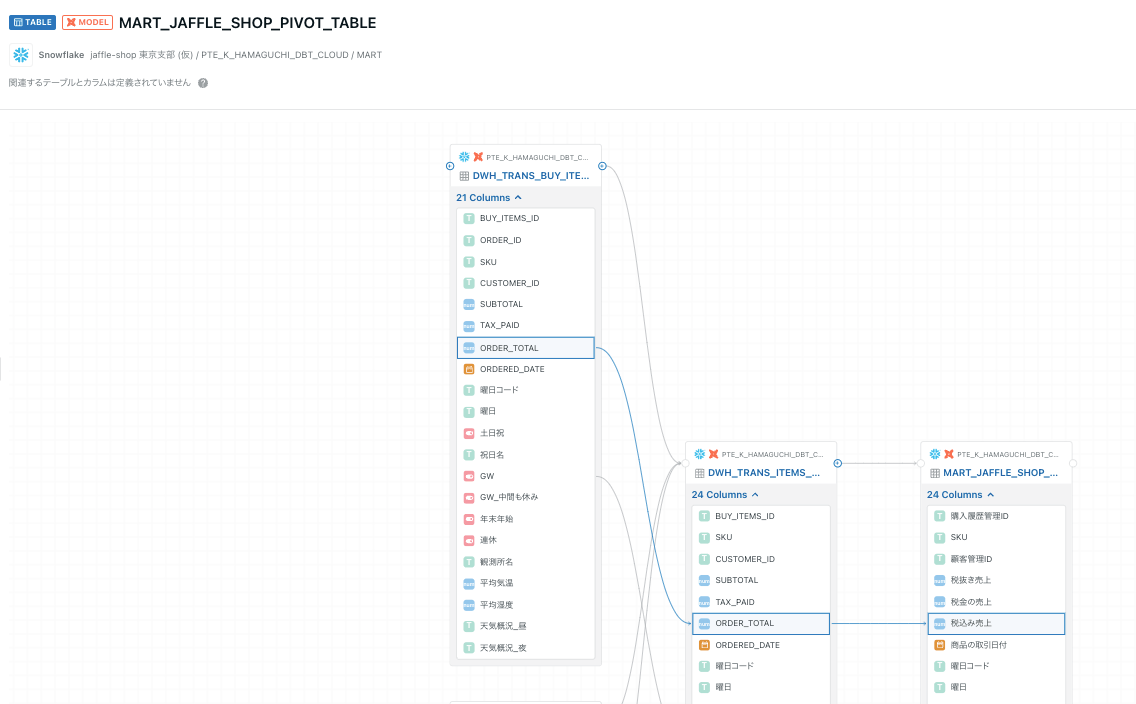
便利
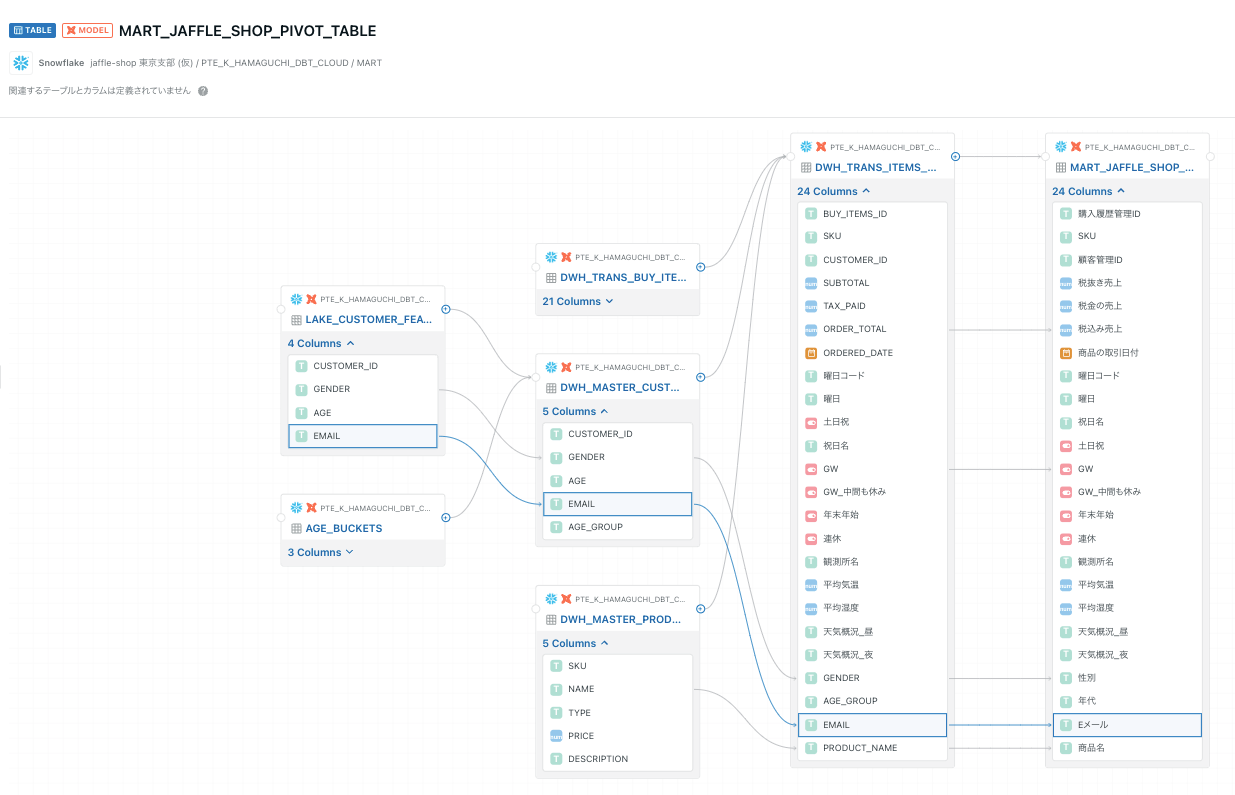
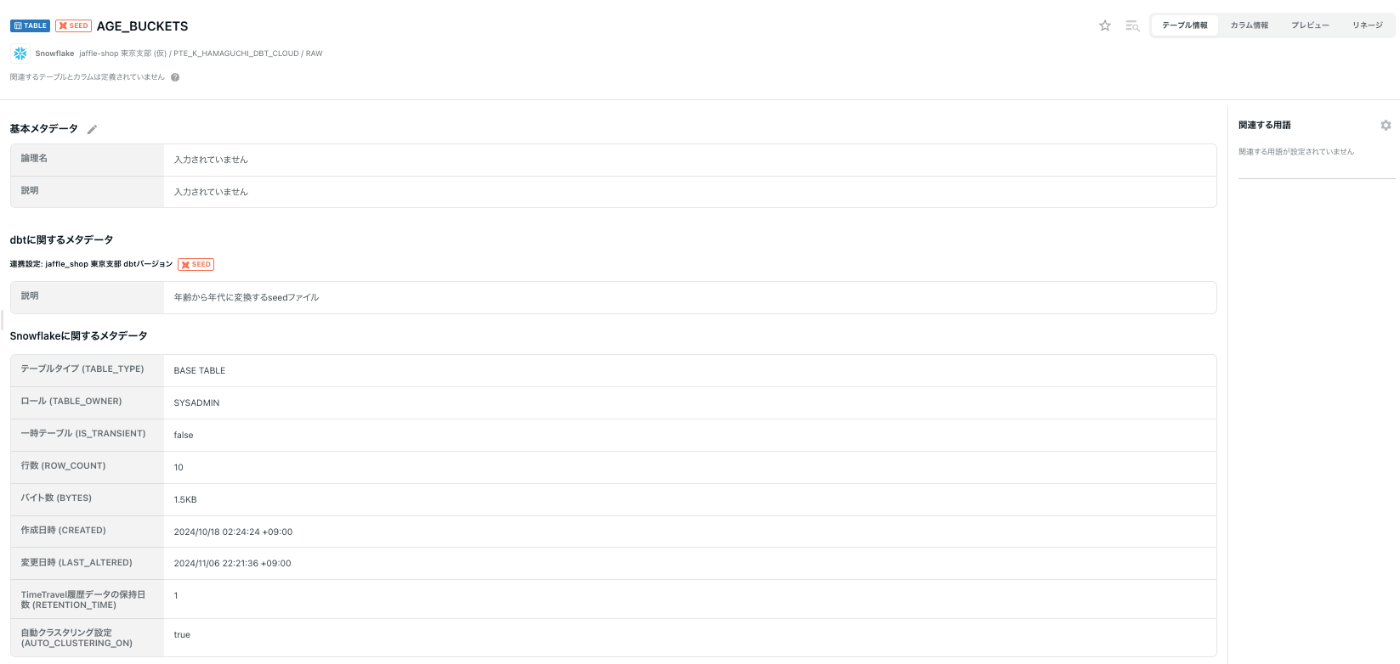
SEED
テーブル情報
SOURCE/MODELと同じような感じです。
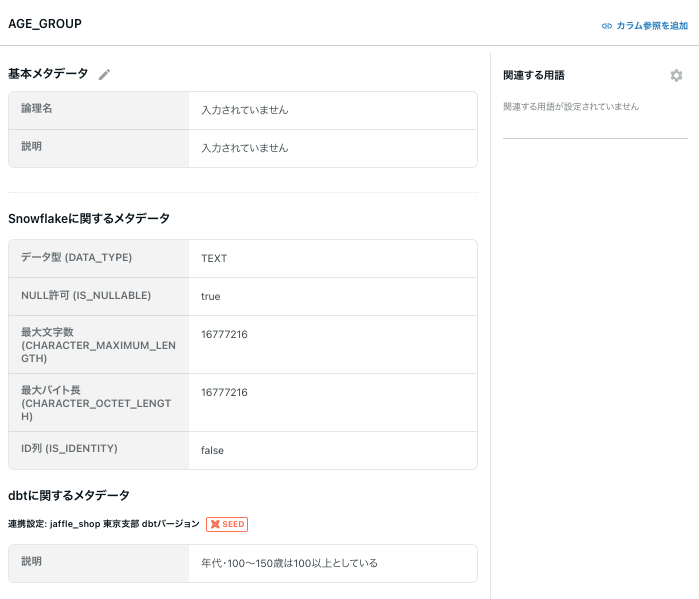
カラム情報
説明内容も確認できます。
(SOURCEと合わせてですが、このあたりはpersist_docsが効かないはずなのでdbt側からメタ情報を見れるのはありがたいです。)
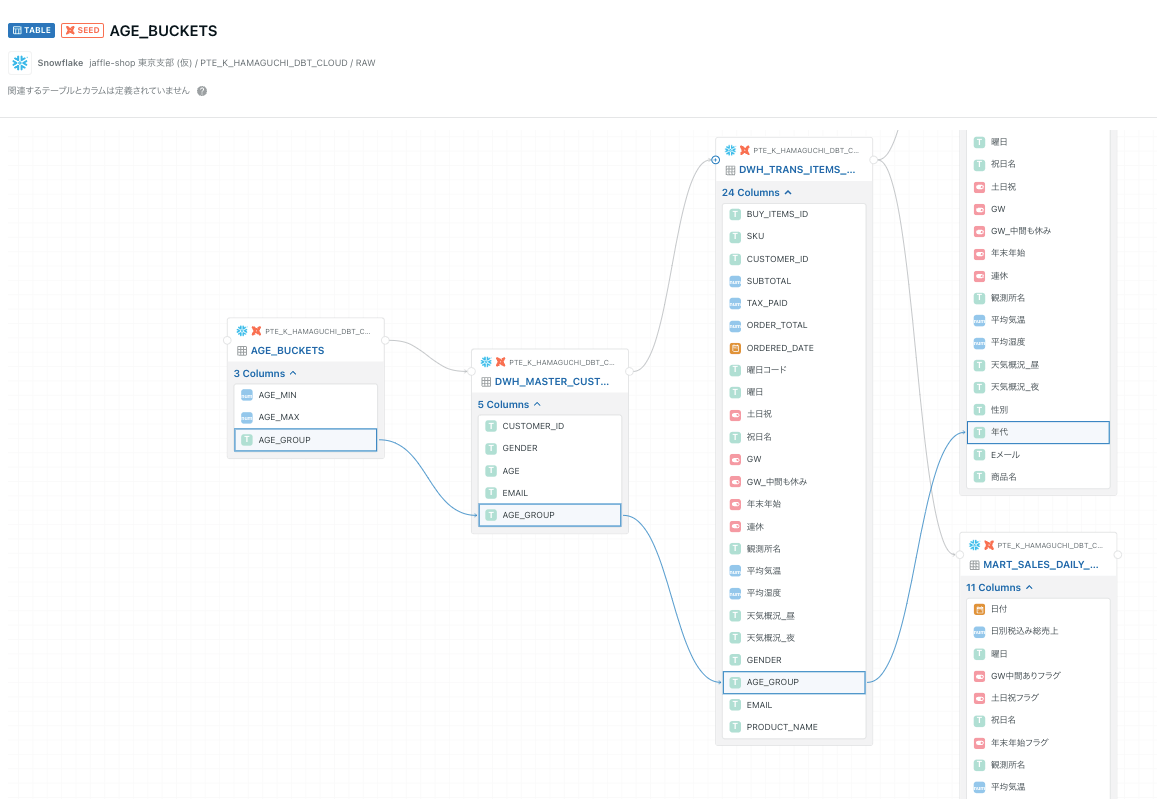
リネージ
こちらはダウンストリームで確認できました!
(上流から特定のカラムに着目して下流モデルを確認していくことにも使えそうです!)
さいごに
今回はCOMETAのdbtメタデータ連携を試してみました。
最も嬉しかったのはdbtで作成したモデルもメタデータを連携することでリネージできることですね!
(TROCCO側でもdbt連携が存在するので、合わせるとサーバ側でスケジュールキックもできて、リネージも見る状態になります!便利🎉)
dbtメタデータの更新は、
dbt docs generate→S3へのアップロード→COMETAのdbtメタデータ連携ジョブを実行という流れになります。
なので更新頻度が高い場合、dbt docs generate→S3へのアップロードまで自動化されているとより使いやすさが上がりますね。
ドキュメントも日本製だけあって読みやすく、初めて触る方もとっつきやすいイメージですので興味があれば是非試してみてください。
以上hamaでした〜

Discussion