はじめに
TROCCOを運営しているpN社からデータカタログツールのCOMETAがリリースされたため触ってみました〜。
TROCCOは基本的な機能のワークフロー/転送設定/データマート定義を触りつつ、
COMETAは気になった機能のアセット情報/カラム参照・ER図/JOIN分析を触っています。
COMETAを触った結果もう少し連携の自動化が進めば、
従来のテーブル定義書・DFD・ER図といった部分をCOMETAで置き換えられるかも・・・と感じたので、
同じように気になった方は是非見ていただけると幸いです。
事前準備
- Snowflake
- TROCCOと接続するユーザ・Key pairの作成が完了している
- 転送するオブジェクトにアクセスできる権限・ロールが付与されている
- (任意)前回の記事で作成したSIS(Streamlit in Snowflake)のコードがある
- AWS S3
- IAMロールの発行手順より、S3へとアクセスできるロールの作成が完了している (MFAは設定していない)
- ダミーデータ
- 前回の記事で使用したデータを使います
TROCCOで接続設定をする
Snowflake
接続情報→新規作成→DWH→Snowflakeを選択します。

下記の項目を設定していきます。
- ホスト:
[account]-[region].aws.snowflakecomputing.com-
https://を付けないこと
-
- ユーザー
- 個人の場合はUSERでもOK,みんなで使う場合はSYSTEMUSERを作成したほうが良いです。
- 秘密鍵
- キーペア認証とキーペアローテーションを参考に作成・紐づけをします
- ロール
- アクセス制御を入れないならSYSADMIN,アクセス制御をいれるならRBACを用いたロール管理を付与したほうが良いです。
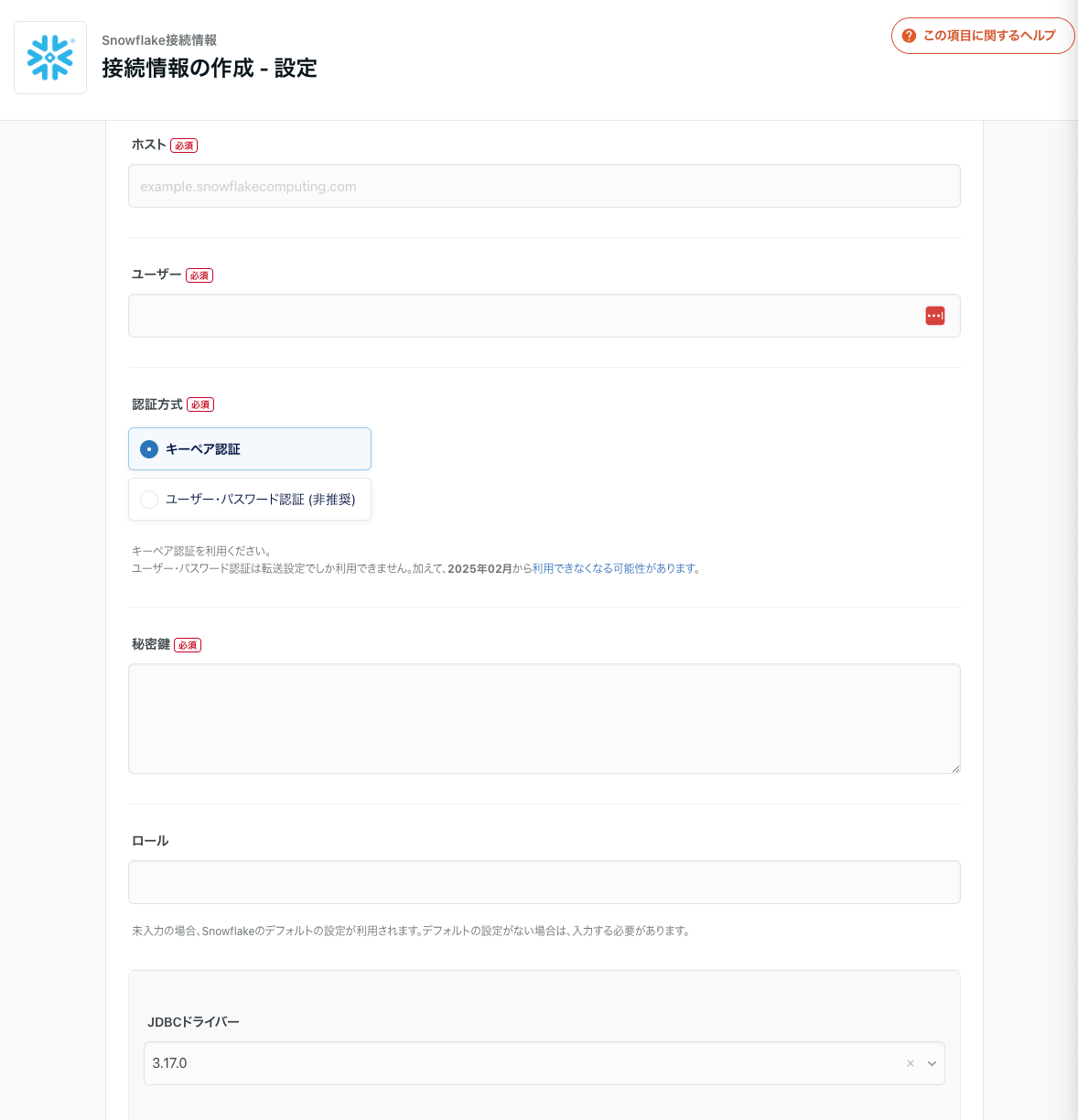
接続を確認ボタンをクリックしてホストの疎通確認と表示されれば接続完了です。
参考:https://documents.trocco.io/docs/connection-configuration-snowflake
S3
接続情報→新規作成→ファイル・ストレージサービス→AmazonS3を選択します。
下記の項目を設定していきます。
- AWSアカウントID:S3のバケットを作成したAWSのアカウントID
- コンソール画面右上で確認できます
- IAMロール名
- 事前に準備したロール名
TROCCOのAWSアカウントID、外部IDはコピーしてロール作成時に使うだけなので入力は無しです。
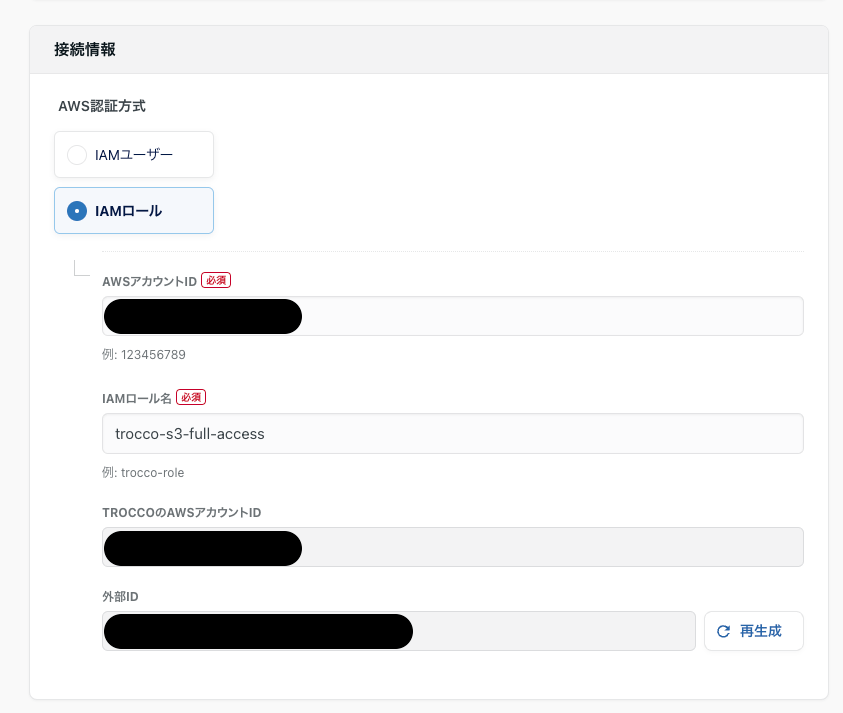
接続を確認ボタンをクリックして認証の確認と表示されれば接続完了です。
参考:https://documents.trocco.io/docs/connection-configuration-s3
データ準備
前回の記事で利用したデータをS3に投入します。
パスプレフィックスは raw_data/jaffle_shop/*.csvとします。
(今回はdbt seedで作成したデータも一緒にjaffle_shop配下に投入します。分ける場合はutilフォルダを作っても良いかも)

TROCCOで転送設定を作る
前回の記事で手動投入やdbt seedで投入していたデータをS3経由でSnowflakeに転送します。
対象は下記の5つです。
- age_buckets
- customers
- products
- items
- orders
S3→Snowflakeを作る
今回はデータは全件洗替、文字列で転送します。
接続情報→新規転送設定作成→転送元:S3・転送先:Snowflakeを選択します。
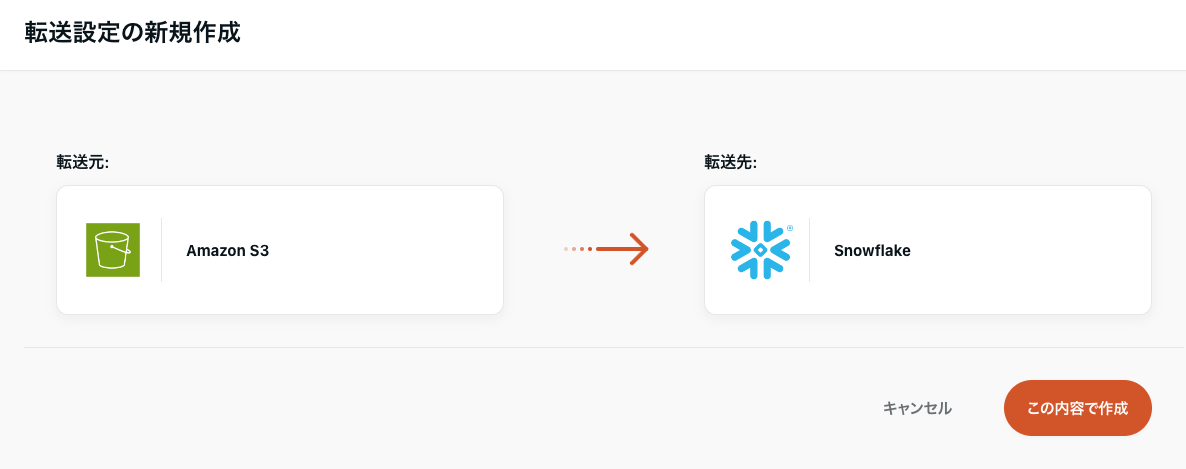
共通
- 名前:
[転送元]→[転送先] [転送先の作成テーブル名]で記載すると検索しやすいと思います- DEV,STG,TEST,PROD等の環境名を名前に入れ込むと長くなるのでラベルで管理すると楽です
転送元:S3
下記の項目を設定していきます。
- Amazon S3接続情報:先ほど作成したS3の接続情報を入れます
- リージョン:バケットを作成したリージョンと同じにしてください
- バケット:S3のバケット名
- パスプレフィックス:
raw_data/jaffle_shopを入力します。 - パスの正規表現:転送したいファイル名を入れます
- 複数ある場合は正規表現を入れます
- 自動データ設定・カラム定義の再読み込み・スキーマ変更検知で使用するファイル:ヘッダー付きCSVなのでデフォルトでOK
- 解凍形式:今回は非圧縮
- 入力ファイル形式:CSV/TSV (ヘッダー付きCSVなのでデフォルトでOK)
- 転送方法:全件転送 (全件洗替のため)
- 詳細設定→指定のパスにファイルが存在しなかった場合に転送を続行するか:転送を続行するでOK
- 後のワークフローで0件転送を許容するかどうかで変わります
- 0件転送で毎度エラー落ちするのが困るなら続行を選びましょう
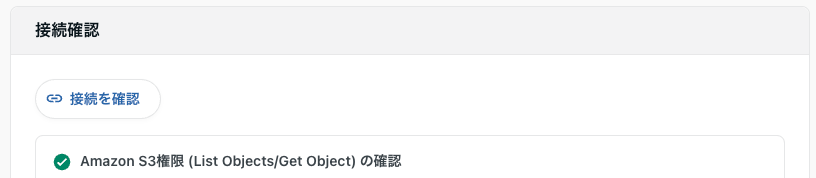
接続を確認ボタンをクリックしてAmazon S3権限 (List Objects/Get Object) の確認と表示されれば設定完了です。
転送先:Snowflake
下記の項目を設定していきます。
- Snowflake接続情報:先ほど作成したSnowflakeの接続情報を入れます
- ウェアハウス:Snowflakeで利用可能なWHを選択します
- スキーマ:
RAW→LAKEなのでLAKEを入力します - テーブル:前回の記事と同じスキーマを使うのでテーブル名で間違えないよう
LAKE_AGE_BUCKETS_TROCCOのようなプレフィックスを付けます - 転送モード:全件洗い替え REPLACE (全件洗替のため)
- Snowflakeでは
OWNERSHIPの関係で後に別ロールに変えるとテーブルが消せないみたいなことが起こります。その際はOWNERSHIPの移し替え or 一旦削除 or 全件洗い替え TRUNCATE INSERTでの実行をおすすめします。
- Snowflakeでは
- 詳細設定→空文字をNULLに置換する:デフォルトのまま
- 詳細設定→エラー時に一時ステージを削除する:オンにすることを強くおすすめします
- デフォルトだと転送失敗時にstageが消されないため、のちのゴミ掃除が大変です
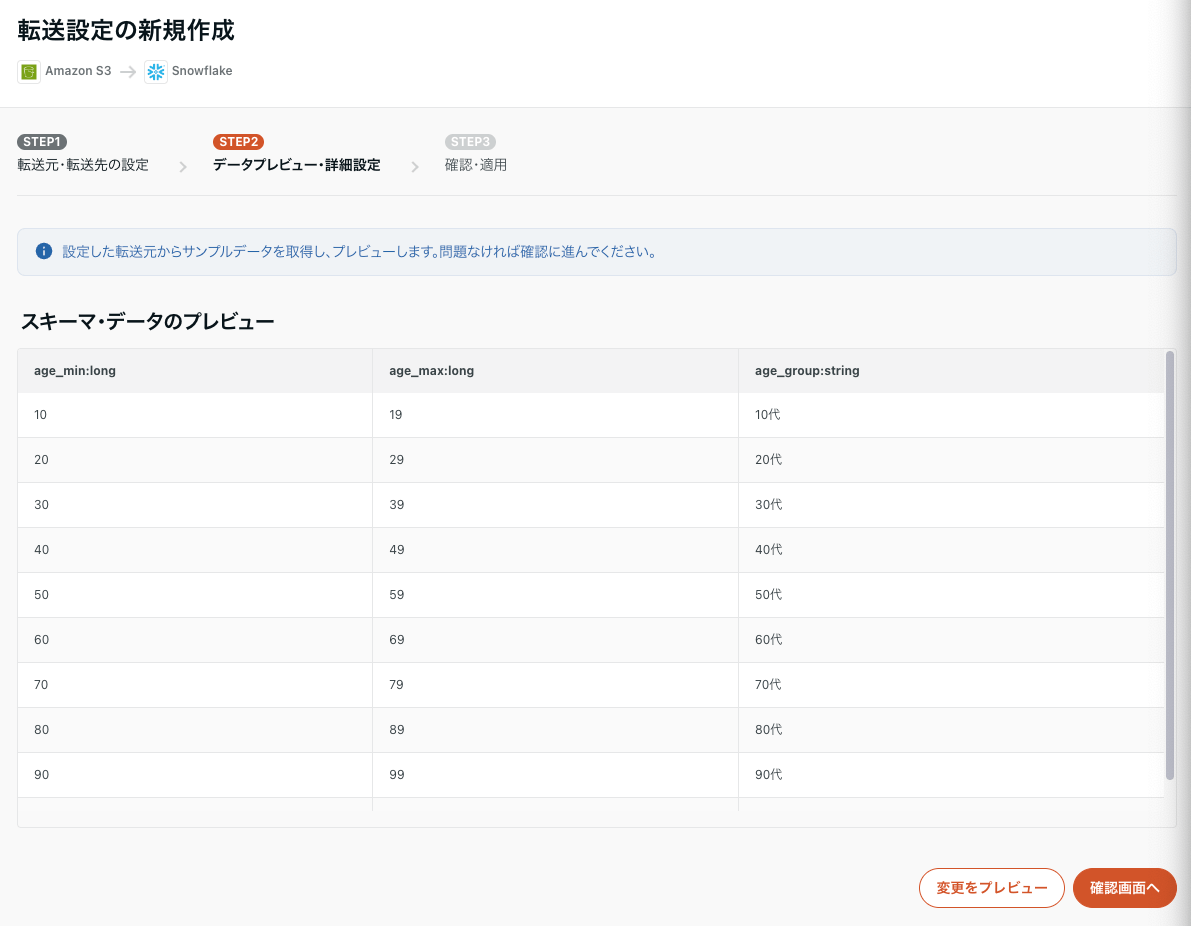
カラム設定
テーブルのプレビューをしつつ、カラム定義で全て文字列に変換していきます。
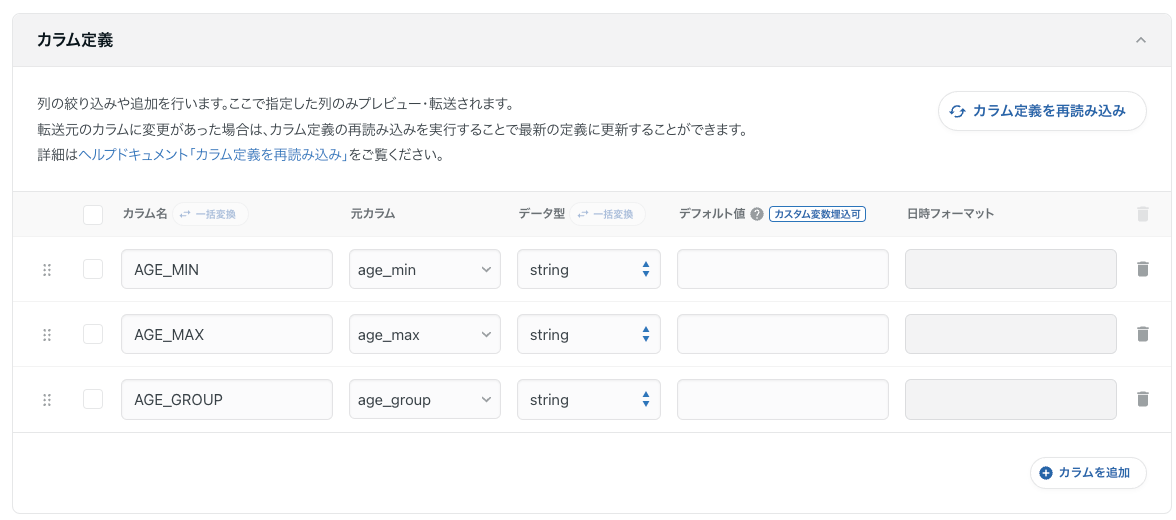
転送設定が全て完了したら最後にEmbulkを動かすためのYAMLが出力されるので確認してGUIとの設定に齟齬がなければ保存して適用を押してください。
動作確認
転送設定→S3→Snowflake age_buckets→実行→実行を選択します。
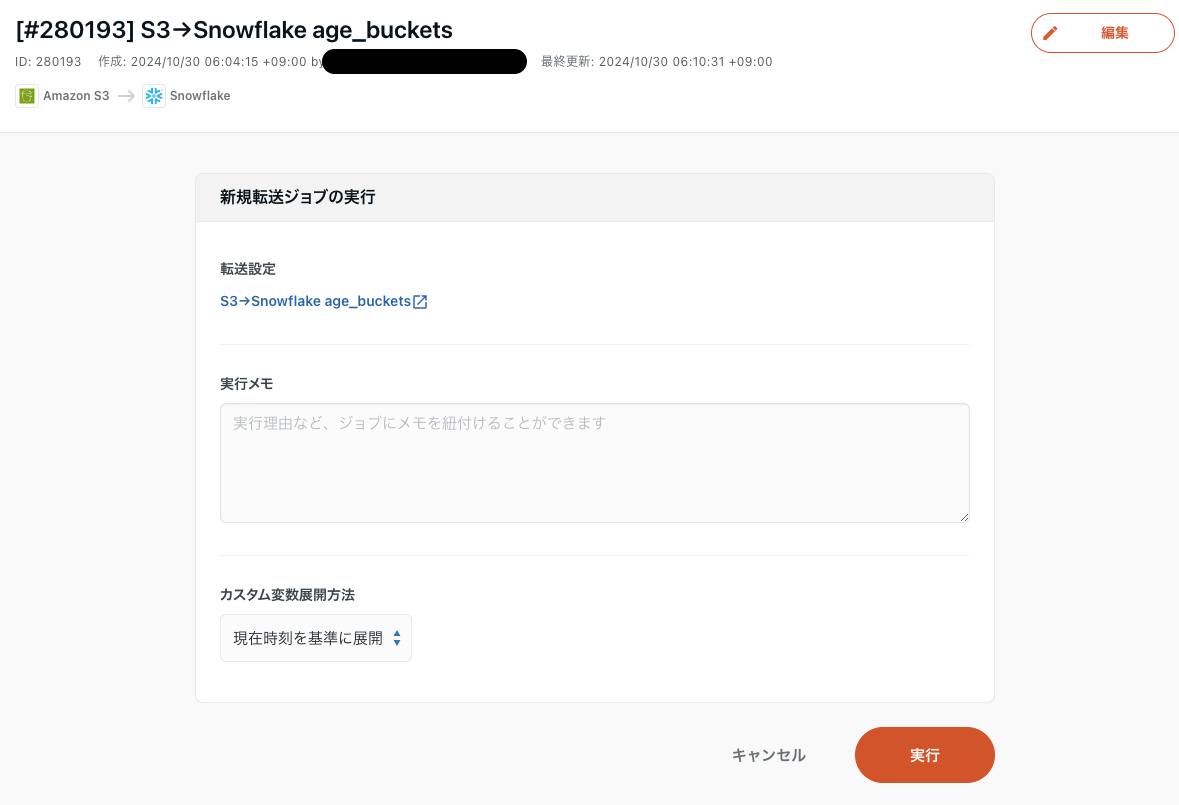
転送ジョブが実行されるため、少々待って完了すればOKです。
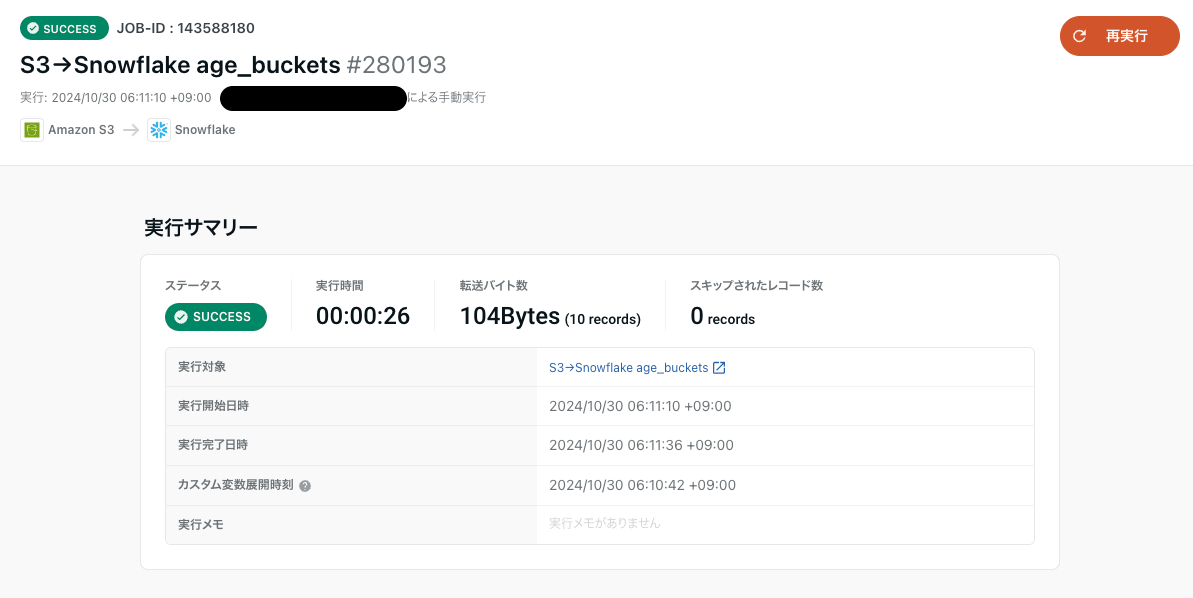
Snowflake側での確認
残りの4つに関しても同様に作成します。
- customers
- products
- items
- orders
TROCCOでデータマート定義を作る
dbt Cloudで実装した時と同じようにLAKE、DWH、MARTのテーブルを作っていきます。
各テーブルは全件洗替です。
対象は下記の6つです。
- LAKE_CUSTOMER_FEATURES
- DWH_MASTER_CUSTOMERS
- DWH_MASTER_PRODUCTS
- DWH_TRANS_BUY_ITEMS
- DWH_TRANS_ITEMS_PRODUCTS_CUSTOMERS
- MART_JAFFLE_SHOP_PIVOT_TABLE
dbtで作成したテーブルと混ざらないように後ろに_TROCCOのプリフィックスを付けます。
データマート定義作成例
作業としてはほぼ同じなのでLAKE_CUSTOMER_FEATURESを例にデータマート定義を作ります。
データマート定義→新規データマート定義作成→Snowflakeを選択します。
下記の項目を設定していきます。
- データマート定義名:[DWH][テーブル名]
- Snowflake接続情報:先ほど作成したSnowflakeの接続情報を入れます
- ウェアハウス:Snowflakeで利用可能なWHを選択します
- クエリ設定→クエリ実行モード:全件洗替のため、データ転送モード
- 出力先データベース:転送設定で転送したDBと同じ
- 出力先スキーマ:LAKE
- 出力先テーブル:LAKE_CUSTOMER_FEATURES_TROCCO
- 出力先テーブルの書き込み設定:全件洗い替え REPLACE
- ジョブ起動設定:並列でのジョブ実行はしない
クエリ結果をプレビューし、問題がなければ保存します。
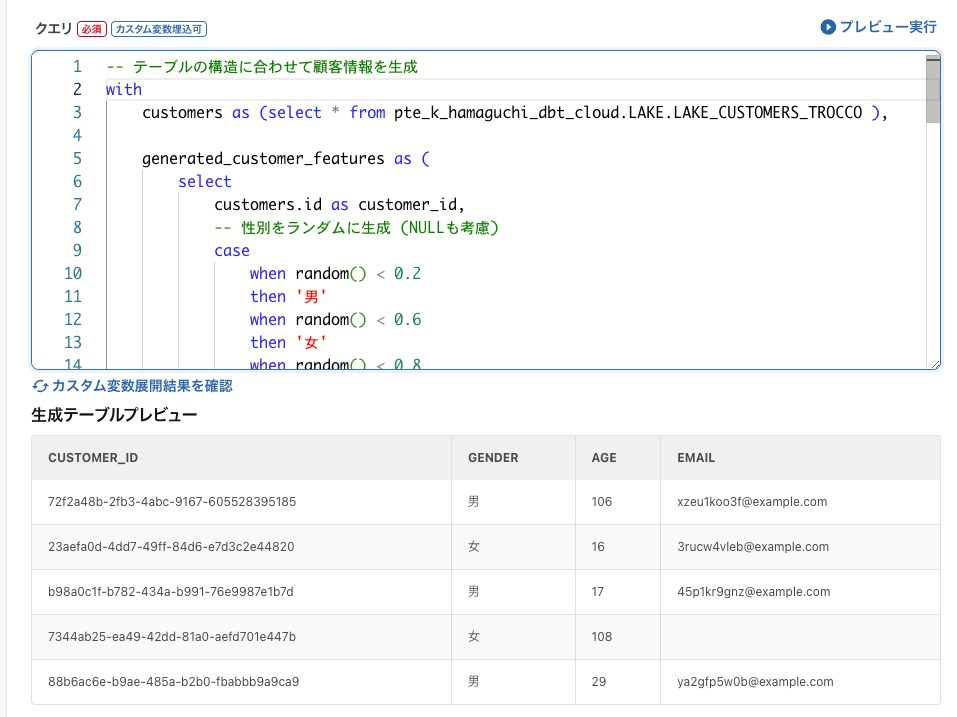
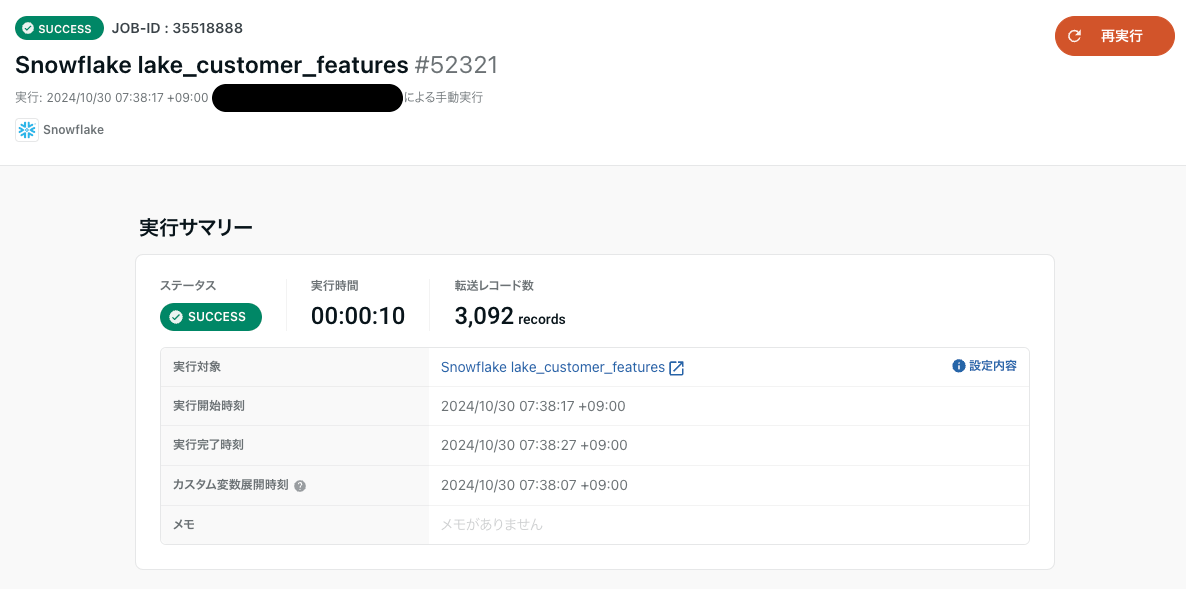
動作確認
データマート定義→Snowflake lake_customer_features→シンク→シンクジョブを実行を選択します。
シンクジョブが実行されればOK!
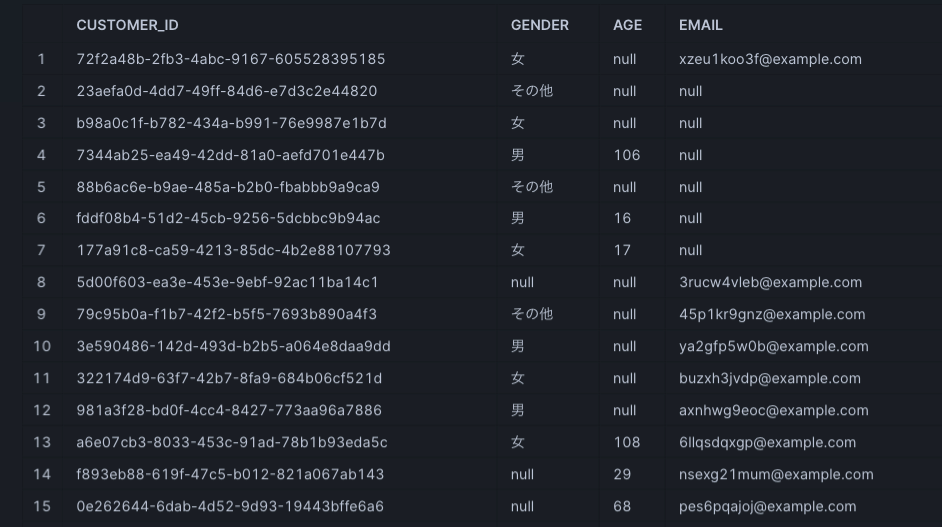
Snowflake側でもData Previewで確認します。
残り5つも同じように設定していきます。。。(ちょっと大変なので複製をうまく使いましょう)
- DWH_MASTER_CUSTOMERS
- DWH_MASTER_PRODUCTS
- DWH_TRANS_BUY_ITEMS
- DWH_TRANS_ITEMS_PRODUCTS_CUSTOMERS
- MART_JAFFLE_SHOP_PIVOT_TABLE
ワークフロー設定を作る
前回作成したdbtのリネージを参考にしながら作成していきます。
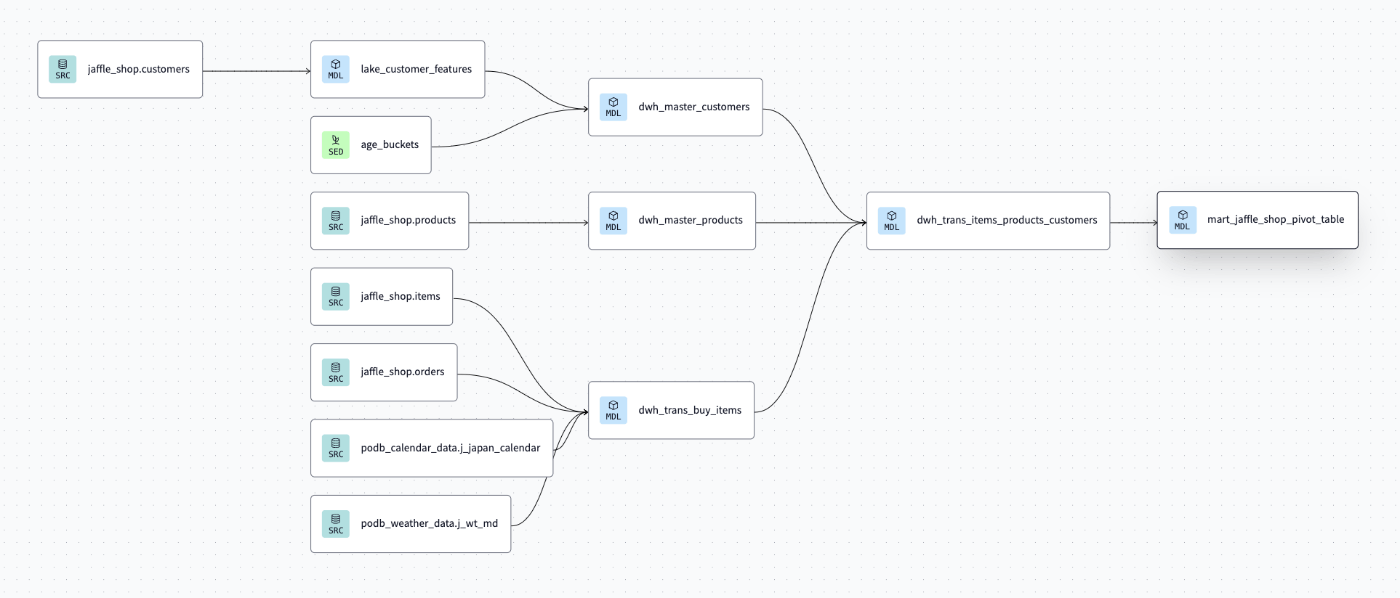
ワークフロー→新規ワークフロー作成を選択します。
下記の項目を設定していきます。
- ワークフロー名:任意
- タスク同時実行上限数:5
- 並列作業が可能な部分が5つだったので5にしました。
- タイムアウト設定:無効にしておきます
- 有効にすると時間内に全てのワークフローが完了しなければタイムアウトのエラーとなります
- リトライ回数:0
- 1回でも失敗したらエラーを吐いてもらいます
- ジョブの重複実行:スキップする
- タスクのエラーハンドリング→エラー時も後続のタスクを続行する:OFF
フローの編集
基本的にGUIベースでタスクを追加し、DAGを手動で作成していきます。
タスクの追加
転送設定やデータマート定義でS3→SnowflakeやSnowflake等の文字列を入れていた理由はここで検索しやすくするためです。
並列でつなげていきます。

作成した結果がこちらになります。
(自動レイアウトがとても便利)
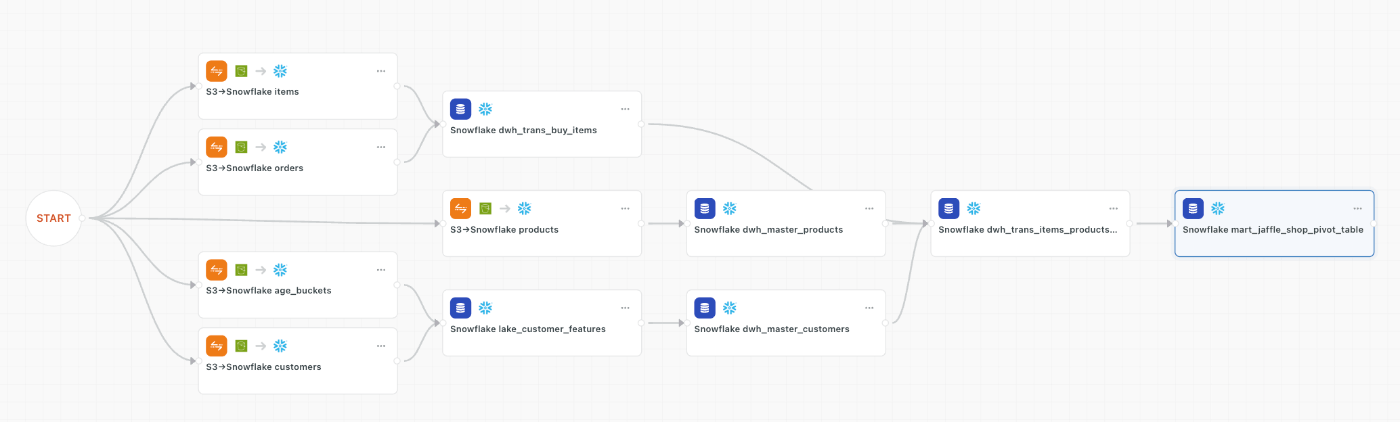
保存→保存して適用をクリックし、ワークフローを保存していきます。
動作確認
ワークフロー→mart_jaffle_shop_pivot_table→実行→実行をクリックしてワークフローを動作させます。

2分ぐらいで全てのワークフローが通ったのでOK
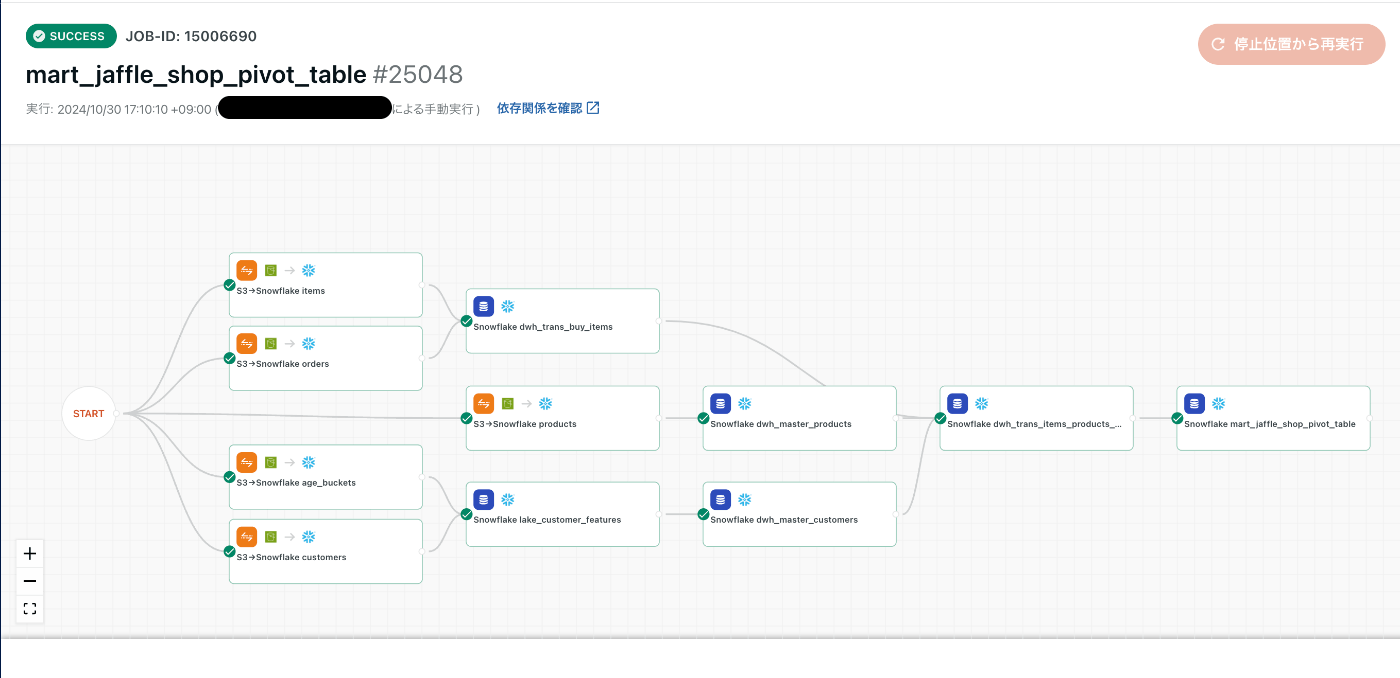
(グラフの途中経過を見ているとちょっとワクワクしますよね〜動いてる感じがして良い)

SIS(Streamlit in Snowflake)で確認する
無事にMARTまで作成できたため、SISで可視化してみます。
こちらで作ったソースコードの一部を変更して作成します。
# Import python packages
import streamlit as st
from snowflake.snowpark.context import get_active_session
from snowflake.snowpark.session import Session
import pandas as pd
# Get the current credentials
session = get_active_session()
# Get Data
@st.cache_data
def get_data_from_snowflake():
## テーブル名をTROCCOに合わせて変更
return session.table("<db_name>.mart.mart_jaffle_shop_pivot_table_trocco").to_pandas()
df = get_data_from_snowflake()
st.title("jaffle-shop東京支部 (仮)")
# 指標探しのピボットテーブルもどき
########################################################################################
# #
########################################################################################
st.title("ピボットテーブルもどき")
# 型に応じたカラムの選別
numeric_columns = df.select_dtypes(include=["int16"]).columns.tolist() # 数値型データのカラム
categorical_columns = df.select_dtypes(include=["object", "bool", "category","int8"]).columns.tolist() # 文字列・ブール型データのカラム
# フォームでインタラクティブにピボットテーブルの設定を選択
with st.form("pivot_form"):
values = st.selectbox("Values", numeric_columns,index=numeric_columns.index("税込み売上"))
rows = st.multiselect("Rows", categorical_columns, default=["SKU","商品名"])
cols = st.multiselect("Columns", categorical_columns,default=["性別"])
aggfunc = st.selectbox("Aggregation", ["sum", "mean", "count"], index=0)
# フォームの送信ボタン
submit = st.form_submit_button("Update Pivot Table")
if submit:
row_combinations = df[rows].nunique().prod() # 行ラベルのユニークな組み合わせ数
col_combinations = df[cols].nunique().prod() # 列ラベルのユニークな組み合わせ数
total_combinations = row_combinations * col_combinations
st.write(f'row:{row_combinations},col:{col_combinations} = {total_combinations}項目')
# ピボットテーブルの作成中にスピナーを表示
with st.spinner("ピボットテーブルを更新中です..."):
# ピボットテーブルの作成
if aggfunc == "sum":
pivot_df = pd.pivot_table(df, values=values, index=rows, columns=cols, aggfunc="sum", margins=True, margins_name="合計")
elif aggfunc == "mean":
pivot_df = pd.pivot_table(df, values=values, index=rows, columns=cols, aggfunc="mean", margins=True, margins_name="合計")
elif aggfunc == "count":
pivot_df = pd.pivot_table(df, values=values, index=rows, columns=cols, aggfunc="count", margins=True, margins_name="合計")
# ピボットテーブルの表示
st.write("ピボットテーブルの結果")
st.dataframe(pivot_df)
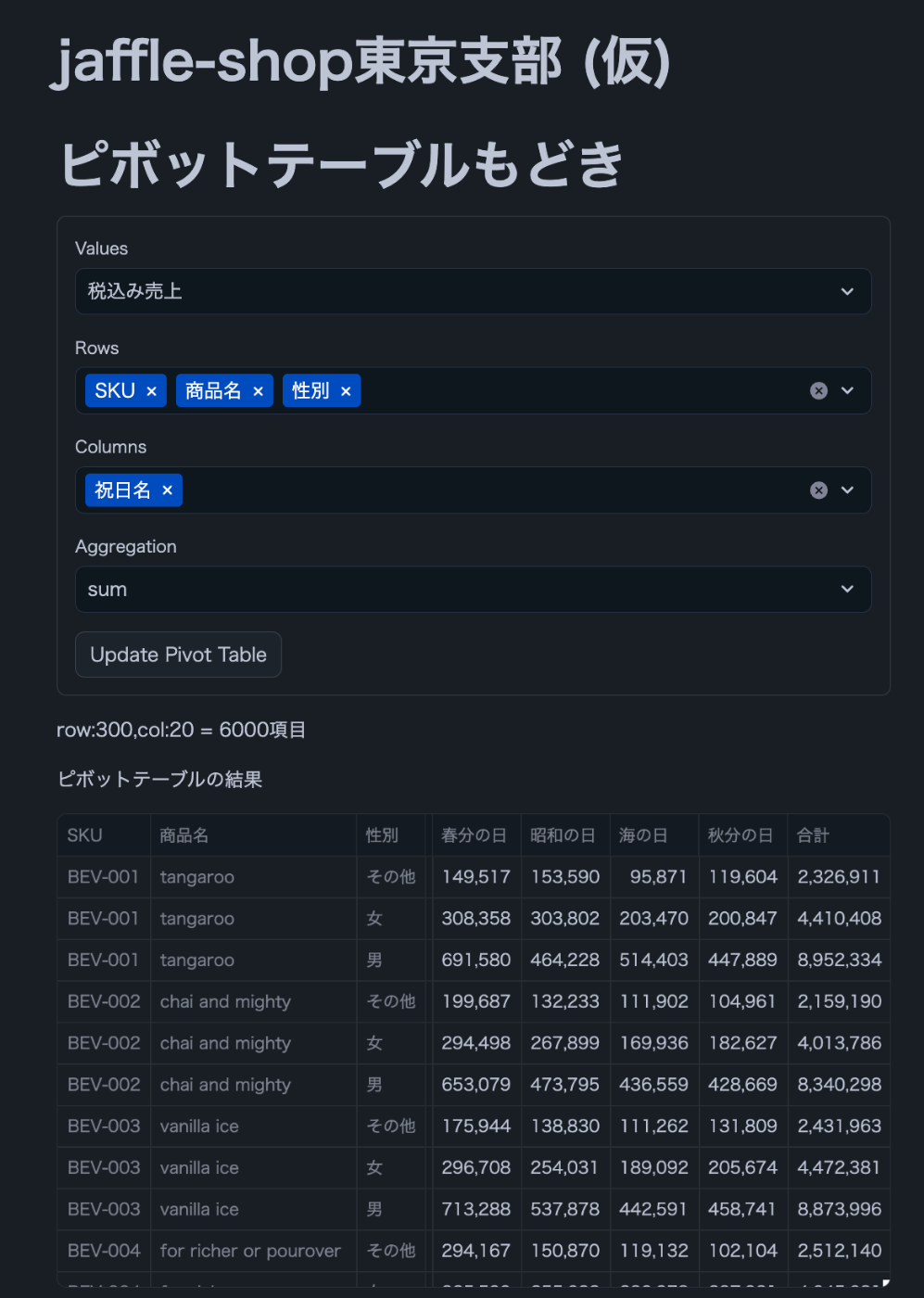
いい感じにピボットテーブルが動けばOKです!
(一部のカラムは組み合わせによってエラーが出ますが温かい目で見てやってください・・・)
COMETAの接続設定をする
ここからはCOMETAの設定をしていきます。
COMETAでは2024/11月段階で下記2種類の認証方式が提供されています。
- ユーザ・パスワード
- Microsoft Entra ID認証
今回はユーザ・パスワードで認証をしていきます。
(事前準備で既に用意したTROCCOのシステムユーザと同じユーザを使うのであれば下記は飛ばしていただいて問題ありません。)
Snowflakeでユーザの作成
なので、システムユーザは下記のように作っておくと良さそうです。
/* COMETAにRSA認証が無いため、PW認証を設定する */
CREATE OR REPLACE USER PN_COMETA_SYSTEMUSER
TYPE='LEGACY_SERVICE'
DEFAULT_WAREHOUSE='<YOUR_WAREHOUSE>'
COMMENT='pN社のデータカタログのCOMETAへ接続するシステムユーザ。'
;
/* ACCOUNT_USAGEのSELECTも考慮してACCOUNTADMINを付与 */
GRANT ROLE ACCOUNTADMIN TO USER PN_COMETA_SYSTEMUSER;
/* PWの付与 */
ALTER USER PN_COMETA_SYSTEMUSER SET PASSWORD='XXXXXX'
Snowflakeで特定のオブジェクトのみ見れるロールを作る
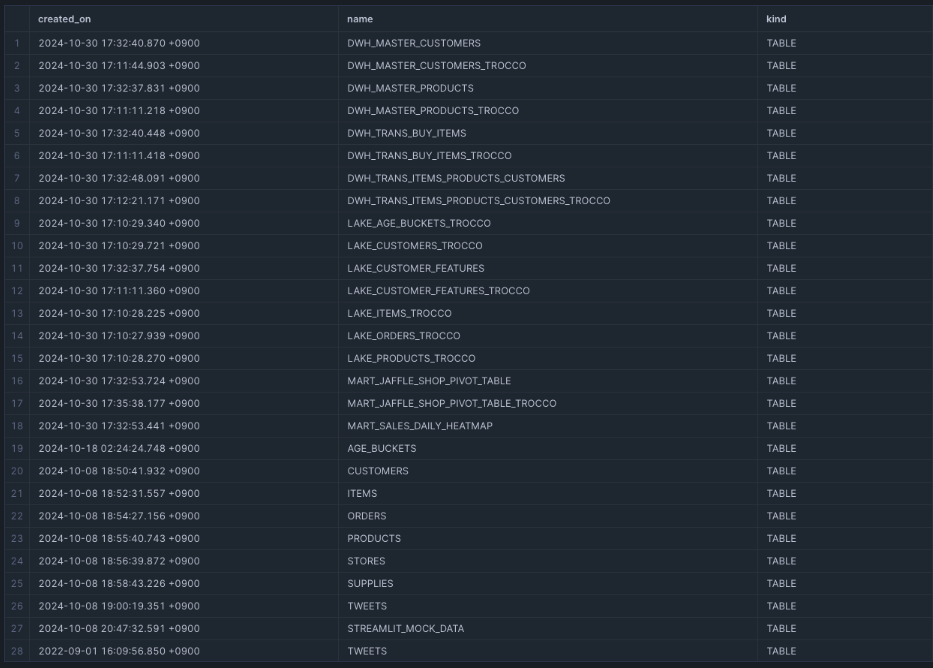
COEMTAではSnowflakeのオブジェクト(DB,Schema,Table,Column)をアセットという単位で管理しています。
そして、COMETAではアセット取り込み除外設定のみ設定可能なため、
みたいアセットが少数の場合除外設定で苦しむことになります。
なので、今回はSnowflake側でみたいDB配下のオブジェクトのみアクセスできる簡易的なロールを作成し、COEMTAの連携時に活用していきます。
除外設定は公式より下記のようなフォーマットで簡単に作成できますが、不要なものを取り込むと除外設定を大量に作成する必要があるためロールで見たい幅を決めてしまうのがおすすめです。
(Starterプランでは連携アセット(テーブル)の上限もあるので連携前の制御がおすすめです)

/* 特定DB配下のオブジェクト閲覧権限付与 */
USE ROLE SECURITYADMIN;
/* 新しい ROLEの作成 */
CREATE OR REPLACE ROLE COMETA_SPECIFIC_DB_ROLE;
/* システムユーザにロール付与 (ACCOUNTADMINを持っているので見えているが一応つける) */
GRANT ROLE COMETA_SPECIFIC_DB_ROLE TO USER PN_COMETA_SYSTEMUSER;
/* WHの権限付与 */
GRANT USAGE ON WAREHOUSE TEST_WH TO ROLE COMETA_SPECIFIC_DB_ROLE;
/* DBのUSAGE権限付与 */
GRANT USAGE ON DATABASE <db_name> TO ROLE COMETA_SPECIFIC_DB_ROLE;
/* DB配下のSCHEMAに対する権限付与 */
GRANT USAGE ON ALL SCHEMAS IN DATABASE <db_name> TO ROLE COMETA_SPECIFIC_DB_ROLE;
GRANT USAGE ON FUTURE SCHEMAS IN DATABASE <db_name> TO ROLE COMETA_SPECIFIC_DB_ROLE;
/* DB配下のTABLEに対する権限付与 */
GRANT SELECT ON ALL TABLES IN DATABASE <db_name> TO ROLE COMETA_SPECIFIC_DB_ROLE;
GRANT SELECT ON FUTURE TABLES IN DATABASE <db_name> TO ROLE COMETA_SPECIFIC_DB_ROLE;
/* DB配下のVIEWに対する権限付与 */
GRANT SELECT ON ALL VIEWS IN DATABASE <db_name> TO ROLE COMETA_SPECIFIC_DB_ROLE;
GRANT SELECT ON FUTURE VIEWS IN DATABASE <db_name> TO ROLE COMETA_SPECIFIC_DB_ROLE;
/* Marketplaceで特定のDBを見れるようにする(GET方法によってはACCOUNTADMINが必要) */
GRANT IMPORTED PRIVILEGES ON DATABASE PREPPER_OPEN_DATA_BANK__JAPANESE_CALENDAR_DATA TO COMETA_SPECIFIC_DB_ROLE;
GRANT IMPORTED PRIVILEGES ON DATABASE PREPPER_OPEN_DATA_BANK__JAPANESE_WEATHER_DATA TO COMETA_SPECIFIC_DB_ROLE;
/* SYSADMIN配下に付与してSYSADMINを持っている人はこのロールが見れるようにする*/
GRANT ROLE COMETA_SPECIFIC_DB_ROLE TO ROLE SYSADMIN;
/* 確認 */
USE ROLE COMETA_SPECIFIC_DB_ROLE;
SHOW TERSE TABLES;
下記のように特定のDB配下にあるオブジェクトが見れればOK
データストア設定
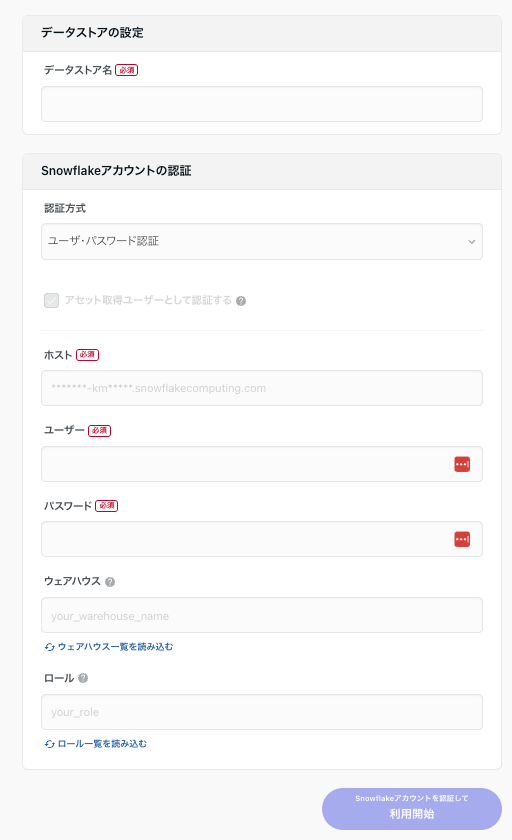
データストア管理ページ→連携を追加→Snowflakeで始めるを選択します。

Snowflakeで作成したユーザ・ロールを元に下記の項目を埋めます。
- データストア名:任意 (BI名を入れたり基盤名をいれるとわかりやすいかも)
- 今回はBIと同じように
jaffle-shop 東京支部(仮)で作成
- 今回はBIと同じように
- 認証方式:ユーザ・パスワード認証
- ホスト:[account]-[region].aws.snowflakecomputing.com
-
https://を付けないこと
-
- ユーザー:先ほど作成したシステムユーザ名 (PN_COMETA_SYSTEMUSER)
- パスワード:システムユーザに設定したPW
- ウェアハウス:システムユーザが使用できるWH
- ロール:アクセス権限を絞ったロール
- 除外設定で全て制御する場合、より上位の権限でも可
Snowflakeアカウントを認証して利用開始をクリックし連携します。
初回連携前の除外設定が出てくるため、
ここでできる限り連携が不要なテーブルを除外していきます。
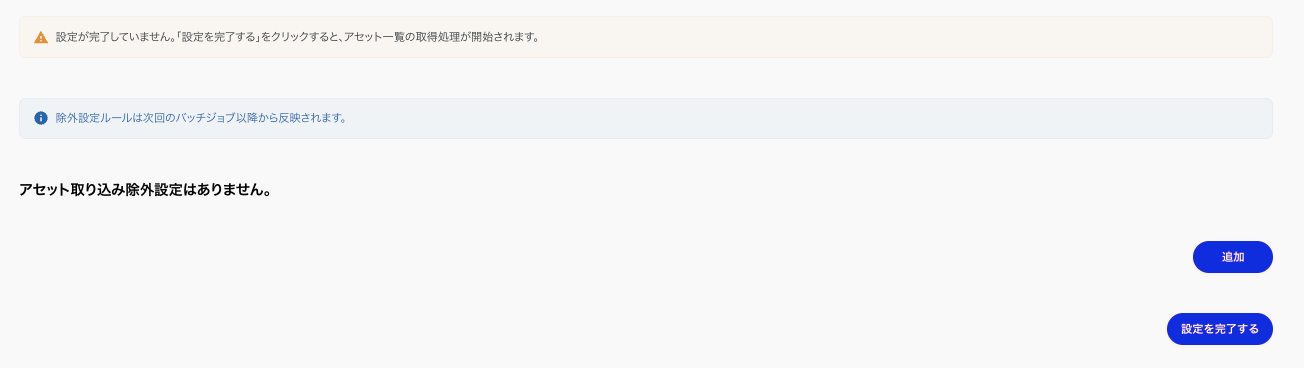
今回はロールで連携する範囲を限定しているので設定を完了するをクリックします。

COMETAのアセット情報を確認する
COMETAではSnowflakeもデータベース系データストアに分類されるため使える機能一覧はこちらで確認できます。
今回は下記の機能を確認していきます。
- テーブルのアセットの情報
- テーブル情報
- カラム情報
- プレビュー(生データ)&クエリを書く
- リネージ
テーブル情報
テーブル情報を確認していきます。
ここでTROCCOの転送設定やデータマート定義を作成していると 関連する{転送設定/データマート定義}で表示されます。

オブジェクトの基本情報に加えて下記4つが一覧で見れるのは嬉しいポイントです。
- テーブルのオーナー
- 一時テーブルの有無
- TimeTravel保持日数
- 変更日次
- 自動クラスタリングの有無
意図しない課金や知らない間にテーブルが消えたみたいな事故を防げますね。
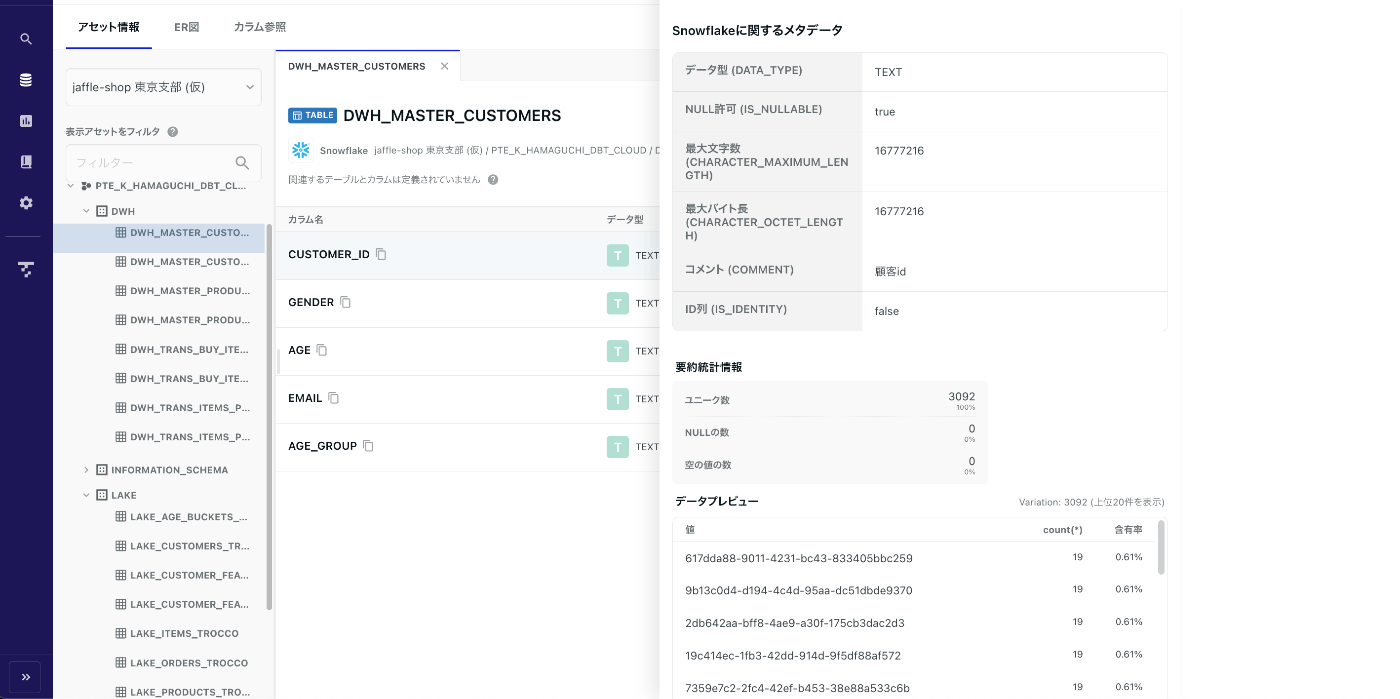
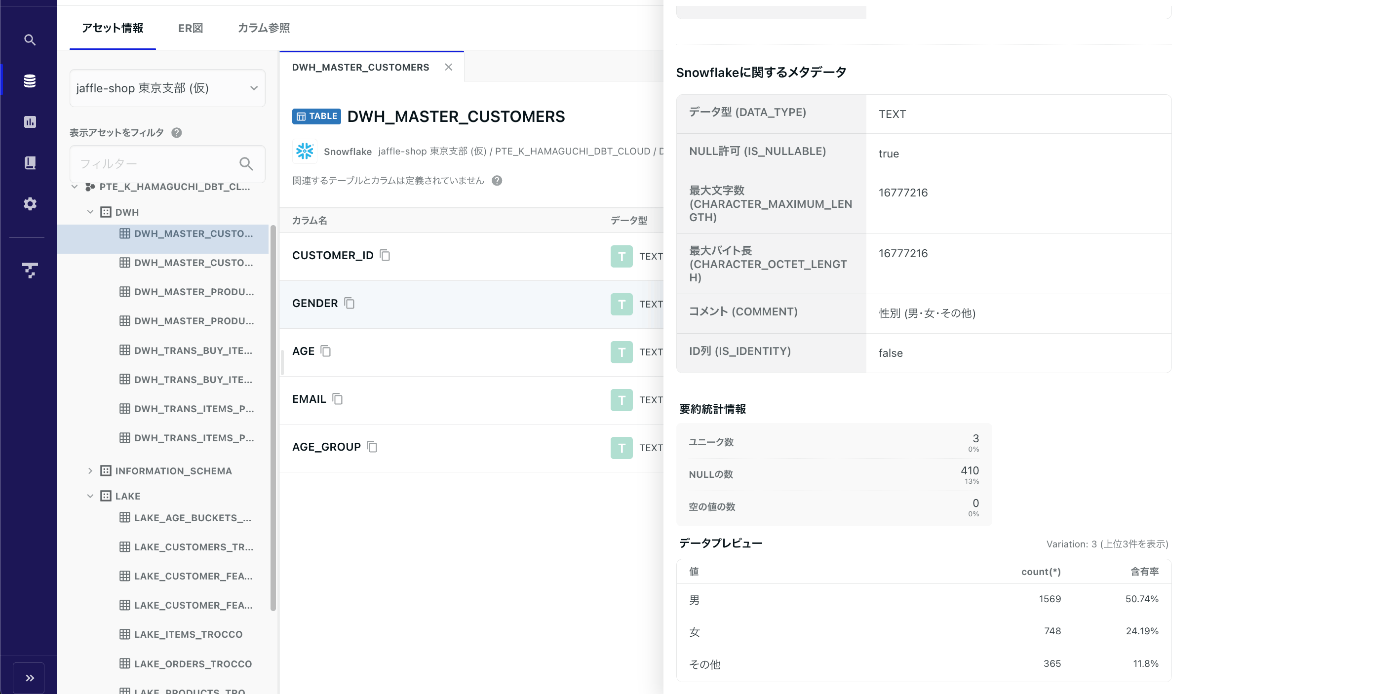
カラム定義
テーブルに定義されたカラム情報が見れるほか、
要約統計情報やデータプレビューが一画面で見れるため、
新しいタブを開いて確認してどのタブか忘れて探して・・・のような状態にならずとても楽でした。
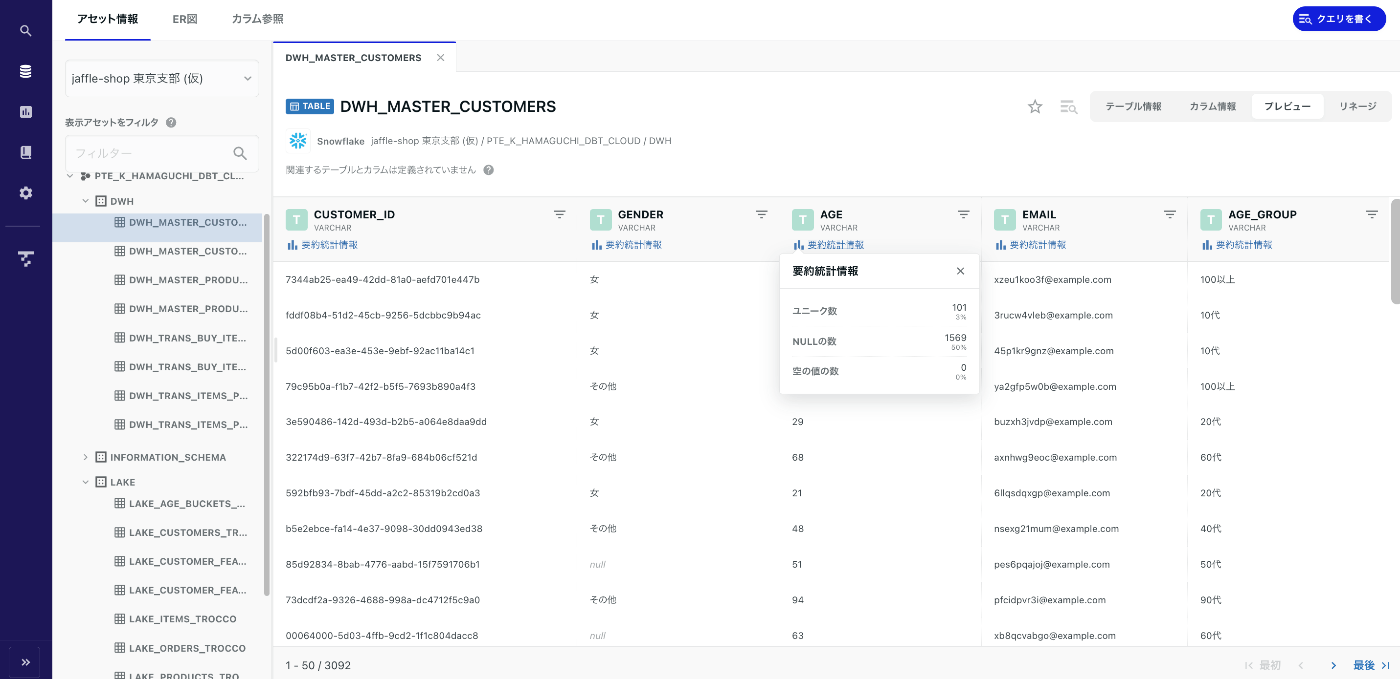
プレビュー(生データ)&クエリを書く
Snowflakeにわざわざログインしなくともこちらからデータを気軽に確認できます。
カラムの型が視覚的にわかりやすく要約統計情報もクリックすれば見れるため、
「どんなデータがあるのかな?」と気軽に調べることもできそうです。
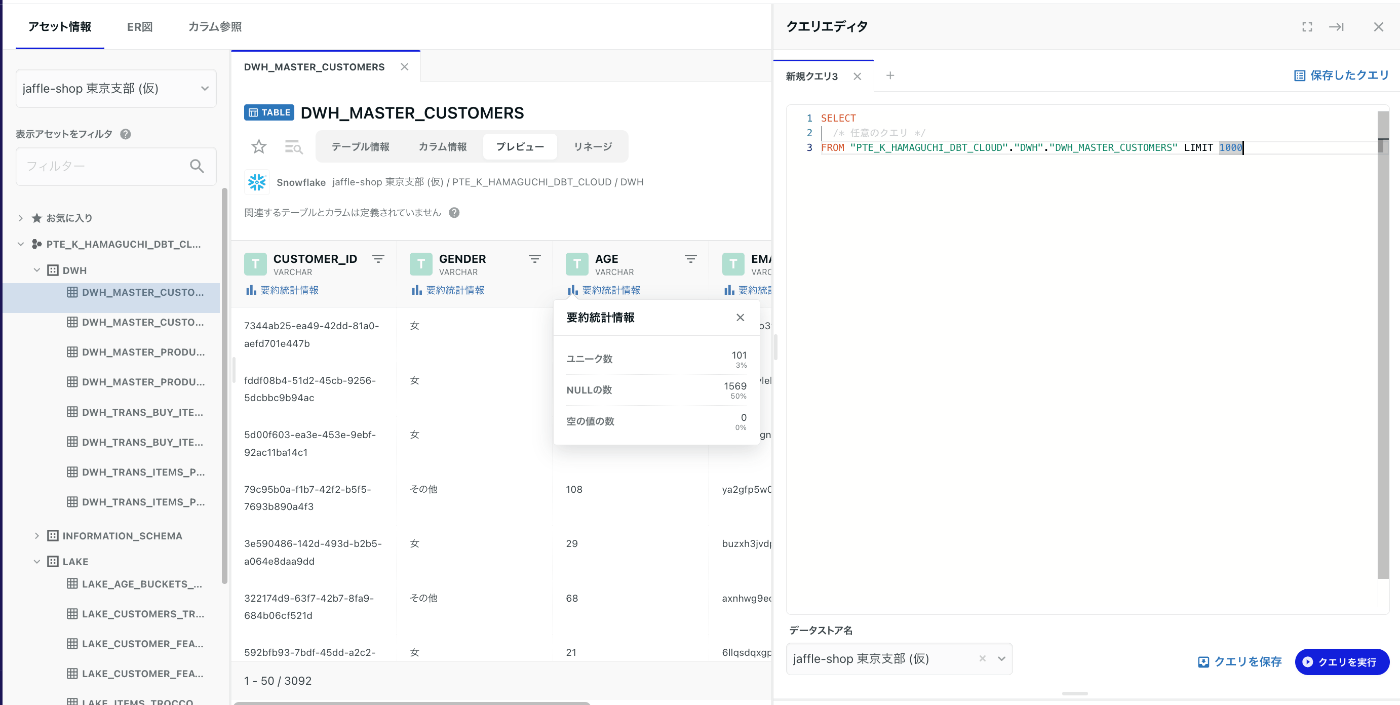
また、必要であれば このテーブルのクエリを書く から直ぐにクエリエディタを起動させることができるため、ちょっとした集計処理を書きたい際にも役立つと思います。

リネージ
MART層で作成した MART_JAFFLE_SHOP_PIVOT_TABLE_TROCCOのアップストリームを表示します。
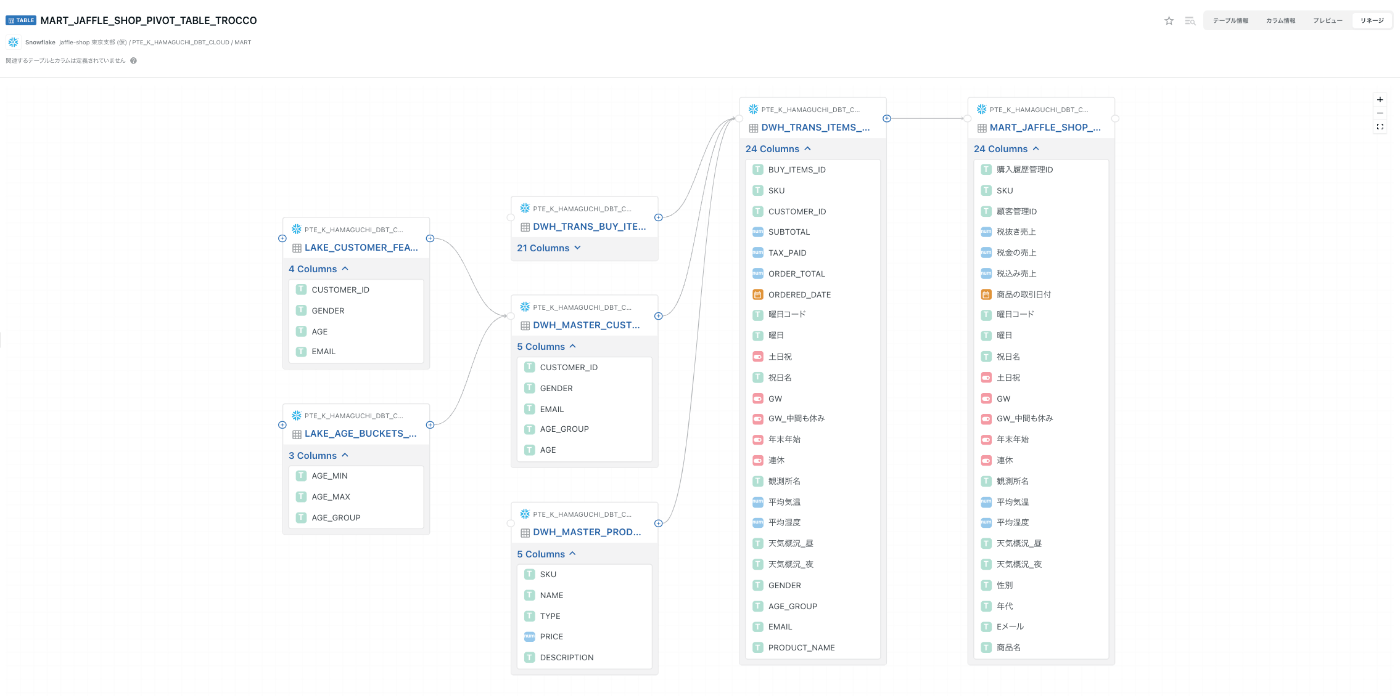
カラムリネージも使ってみます。
例えば「年代ってどのテーブルから作成してただろうか。」と、
MART層からLAKE層のテーブルまで遡ることができます。
これで、カラムのリネームが複数回挟まってもカラム名やテーブル名を間違えずに追うことができます。
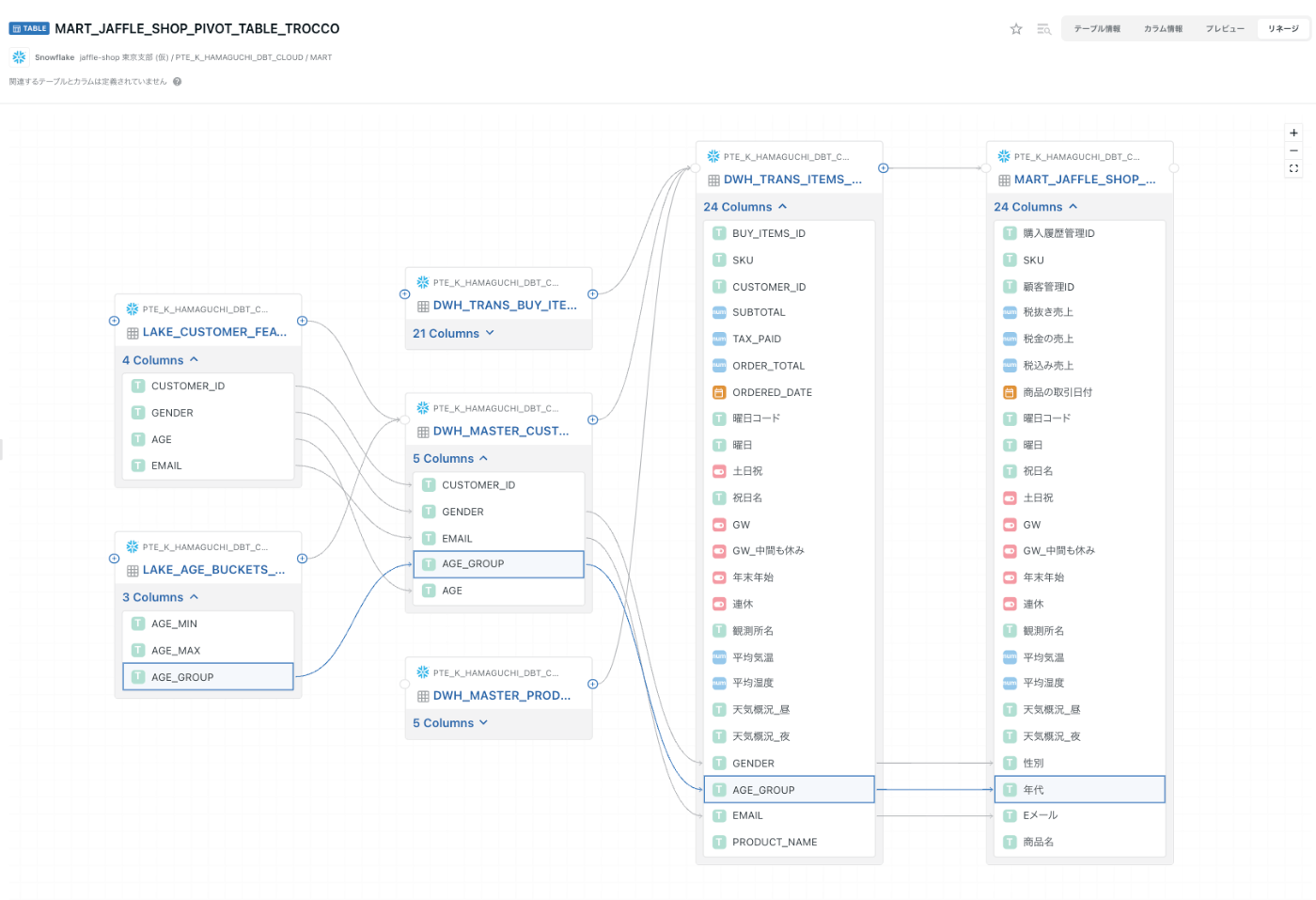
COMETAのER図を確認する
ER図を確認するためにはカラム参照が必要なため、手動で作成していきます。
カラム参照の情報はcsvによるインポートが可能なため、下記の部分をお試しで作ってみます。
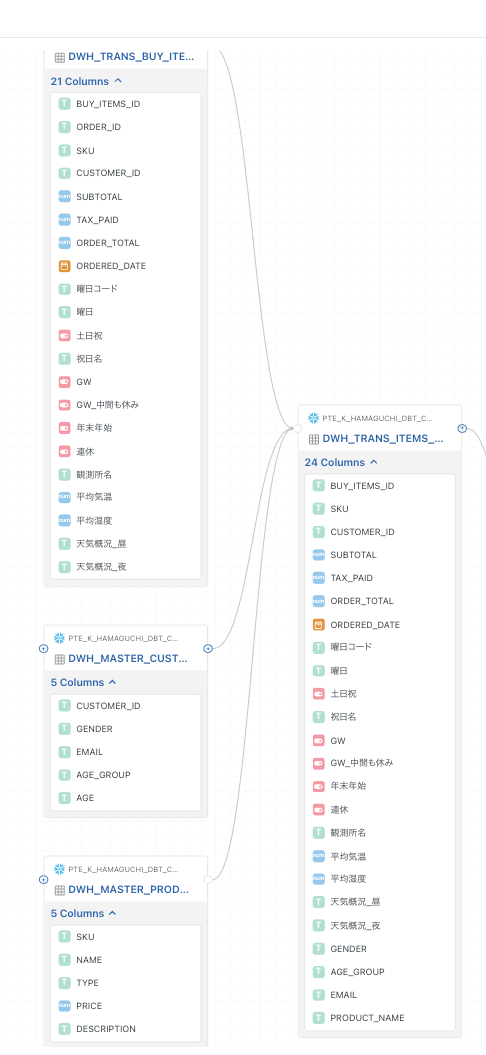
src_database_name,src_schema_name,src_table_name,src_column_name,dst_database_name,dst_schema_name,dst_table_name,dst_column_name
PTE_K_HAMAGUCHI_DBT_CLOUD,DWH,DWH_TRANS_BUY_ITEMS,SKU,PTE_K_HAMAGUCHI_DBT_CLOUD,DWH,DWH_MASTER_PRODUCTS,SKU
PTE_K_HAMAGUCHI_DBT_CLOUD,DWH,DWH_TRANS_BUY_ITEMS,CUSTOMER_ID,PTE_K_HAMAGUCHI_DBT_CLOUD,DWH,DWH_MASTER_CUSTOMERS,CUSTOMER_ID
管理・連携→メタデータ管理→メタデータインポートを選択します。
下記の項目を埋めてインポートを実行をクリックします。
- データストア:jaffle-shop 東京支部 (仮)
- インポート対象:カラム参照
- インポートファイル:カラム参照のテンプレートに合わせたCSV
成功・失敗にかかわらずインポート履歴が残るため確認できます。
(成功の場合は特にログはなく、失敗した場合のみエラーのログが見れます)

データベース→カラム参照→データストア名から取り込んだカラム参照を確認できます。
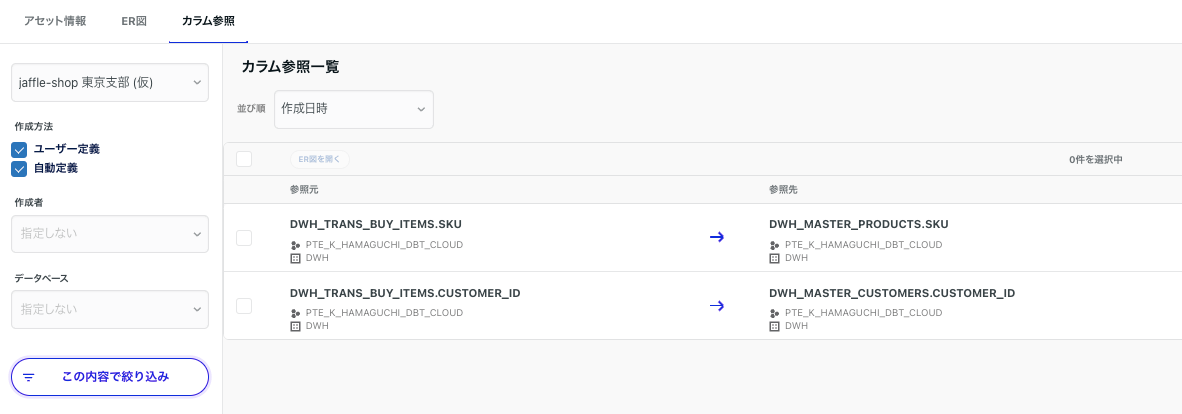
また、ER図でDWH層を確認すると下記のようにマウスを合わせた際に詳細が表示されます。
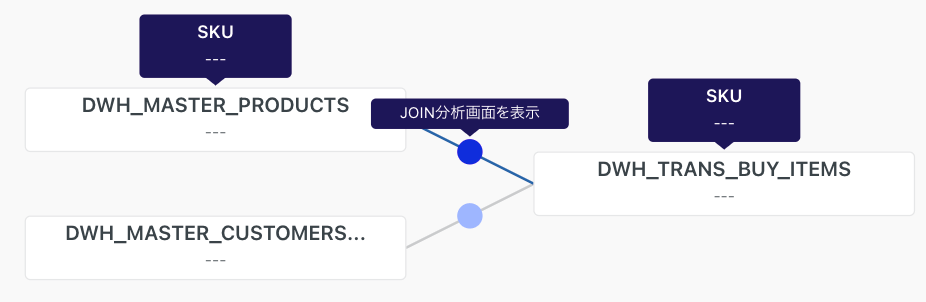
JOIN分析
カラム参照が完了したSKUのカラムに対してJOIN分析をしてみます。
JOIN分析画面表示→JOIN分析を表示するをクリックして結果を見てみます。
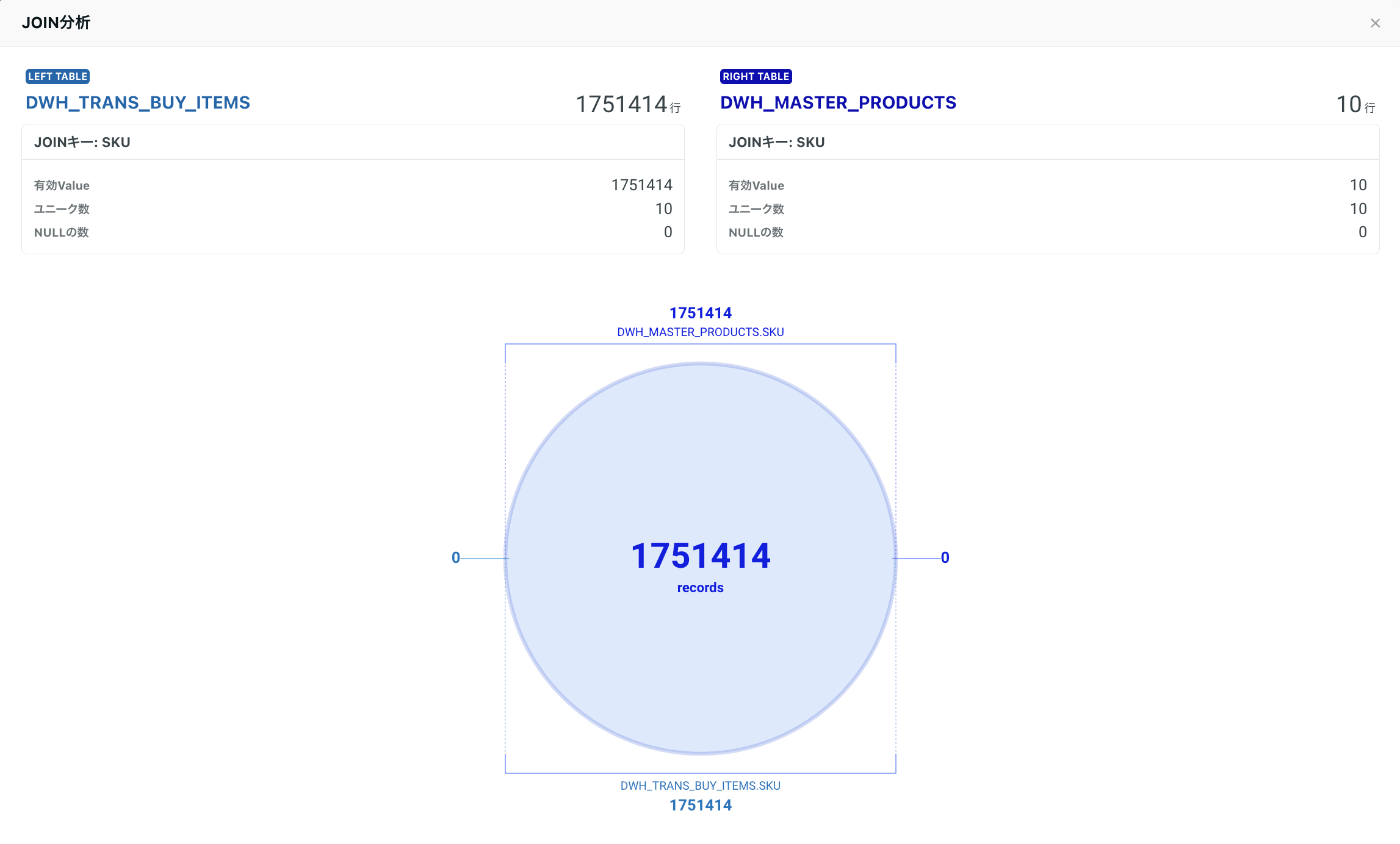
DWH_TRANS_BUY_ITEMS.SKUでNULL無し・10件のユニーク
DWH_MASTER_PRODUCTS.SKUでNULL無し・10件のユニーク
となっているのでJOINすると結合漏れするデータが無いため、ベン図もピッタリと重なります。
さらにベン図で問題ないことが分かれば、JOINプレビューを使い実際にJOINしたらどのようになるか確認することができます。
JOINプレビューは下記の場合に役に立ちそうです。
- ベン図が一部のみ重なる場合
- LEFT/INNER JOIN以外の特殊なJOINをしたい場合
- 不要レコードのJOINがある場合
ベン図のみではわかりにくい部分をJOINプレビューでカバーするのが良さそうです。
さいごに
今回はTROCCOとCOMETAで気になる機能を一通り触りました。
TROCCO側ではワークフロー/転送設定/データマート定義によってより簡単にデータ投入/変換が行えるようになり、
COMETAではTROCCOで作成したテーブルを連携しアセット情報/クエリを書く/カラム参照・ER図/JOIN分析により作成したデータの内容をより簡単に見れるようになりました。
(従来のようなテーブル定義所・DFD・ER図等の別途ドキュメント納品をするのではなく、COEMTAを見てもらうことで工数削減に繋がりそうな感じがしてます!)
カラム参照も一部自動化が進んでいるようなので今後に期待しつつ、
この記事を書いている間にCOMETAでdbtメタデータが取れるようになっていたので試してまた記事にします。
以上hamaでした〜

Discussion