はじめに
Streamlit in SnowflakeがPrivateLinkでも使えるようになるよ〜という記事を見かけ、そもそもStreamlit in Snowflakeはなんぞや・・・
触ってないなというお気持ちになったので、今回はPublic経由でStreamlit in Snowflakeとdbt Cloudを触りながら簡単なデータ基盤を作ります。
Streamlitの構成→ダミーデータの選定→SOURCE/RAW→LAKE→DWH→MARTの順序で作成していくので良ければ参考にしてください。
事前準備
下記の準備を事前に完了していることが前提で進みます。
- GitHub
- アカウントとリポジトリの作成
-
Account settings->Personal profile->GitHubからdbt CloudとGiHubの連携
- Snowflake
- User (+ Key pair)の発行
- DB/Schemaの作成
- Warehouseの作成
- Roleの作成
- dbt Cloud
- Connectionの設定
- Projectの設定
- Connection、GitHubリポジトリの設定
- Environments
- dbt Exploreを使うためにPRODを選択
- (任意) Cloud IDEからリポジトリ連携 or dbt init
Streamlitの構成
今回は軽く触りたいのでピボットテーブルを作成していきます。
下記の理由により少し使いづらくなってしまいますがそれっぽいものを作ります。
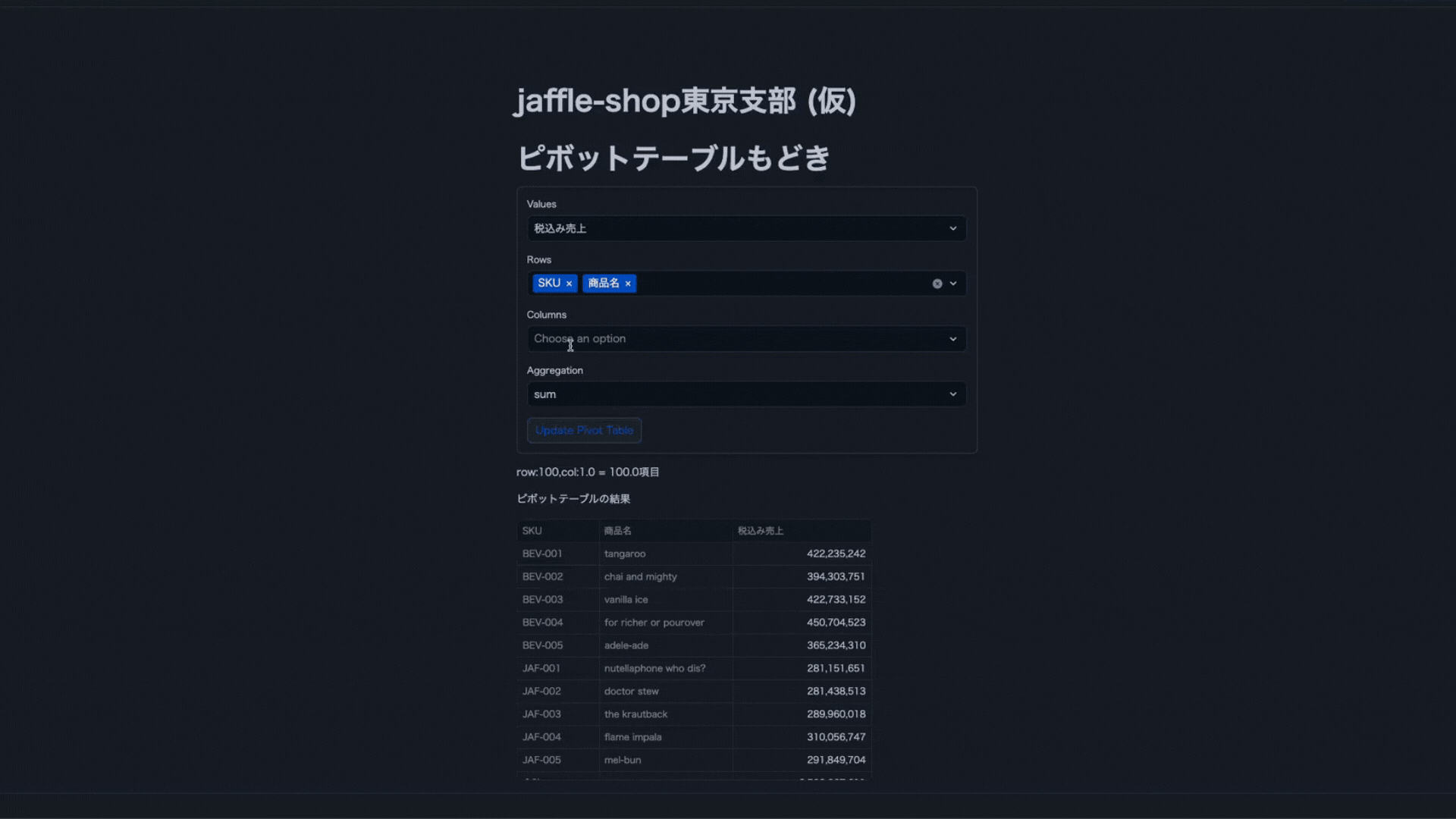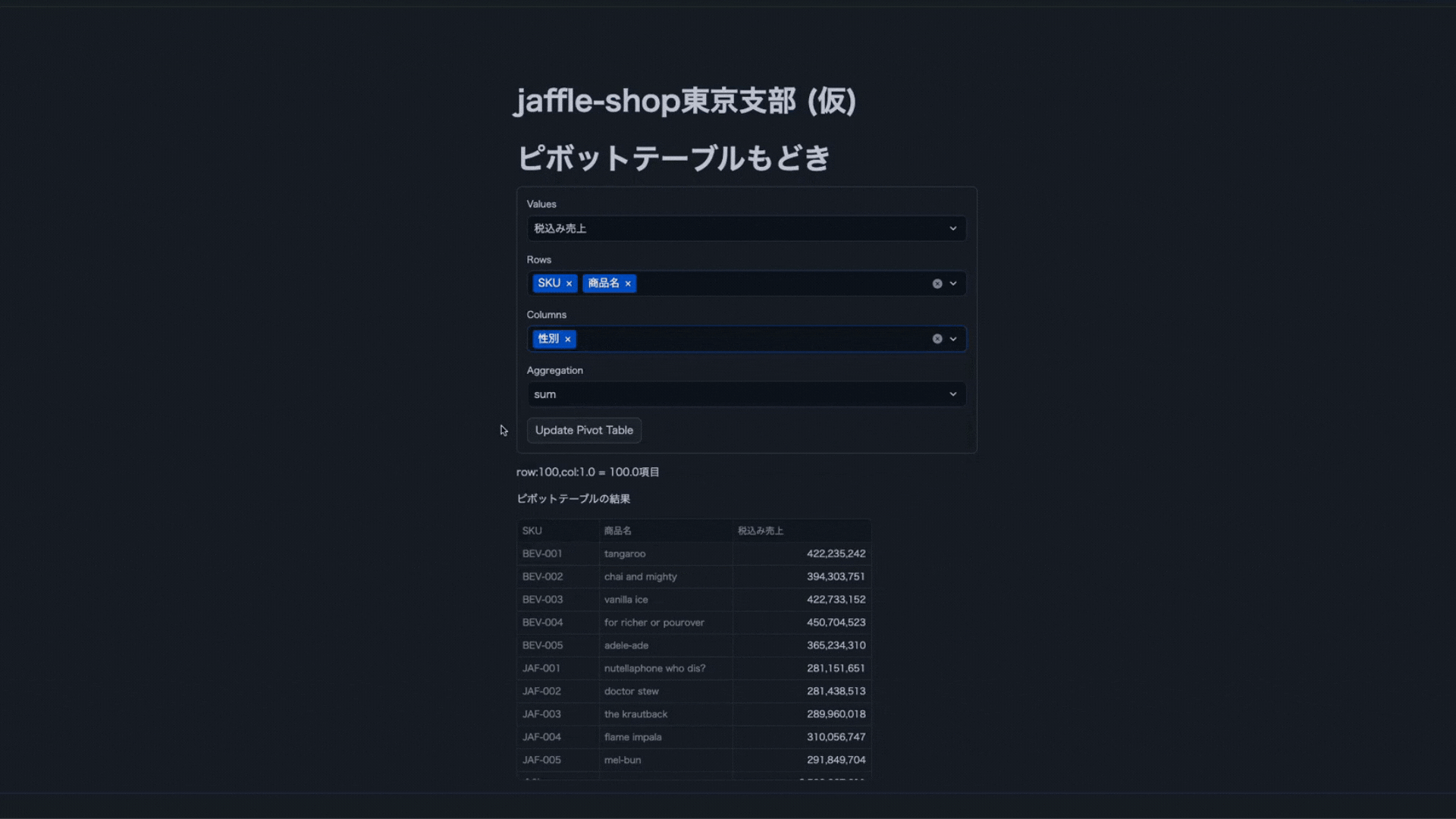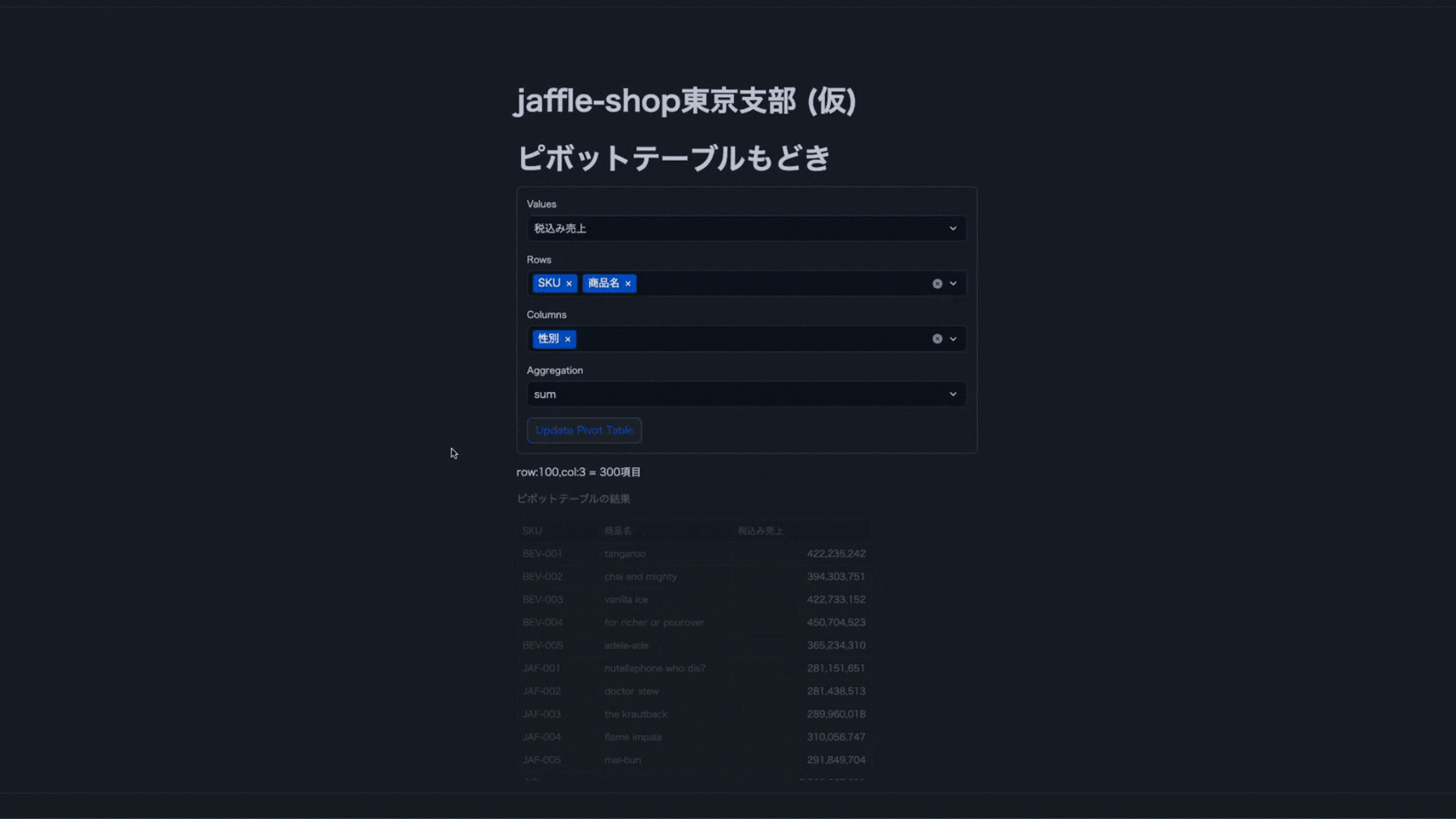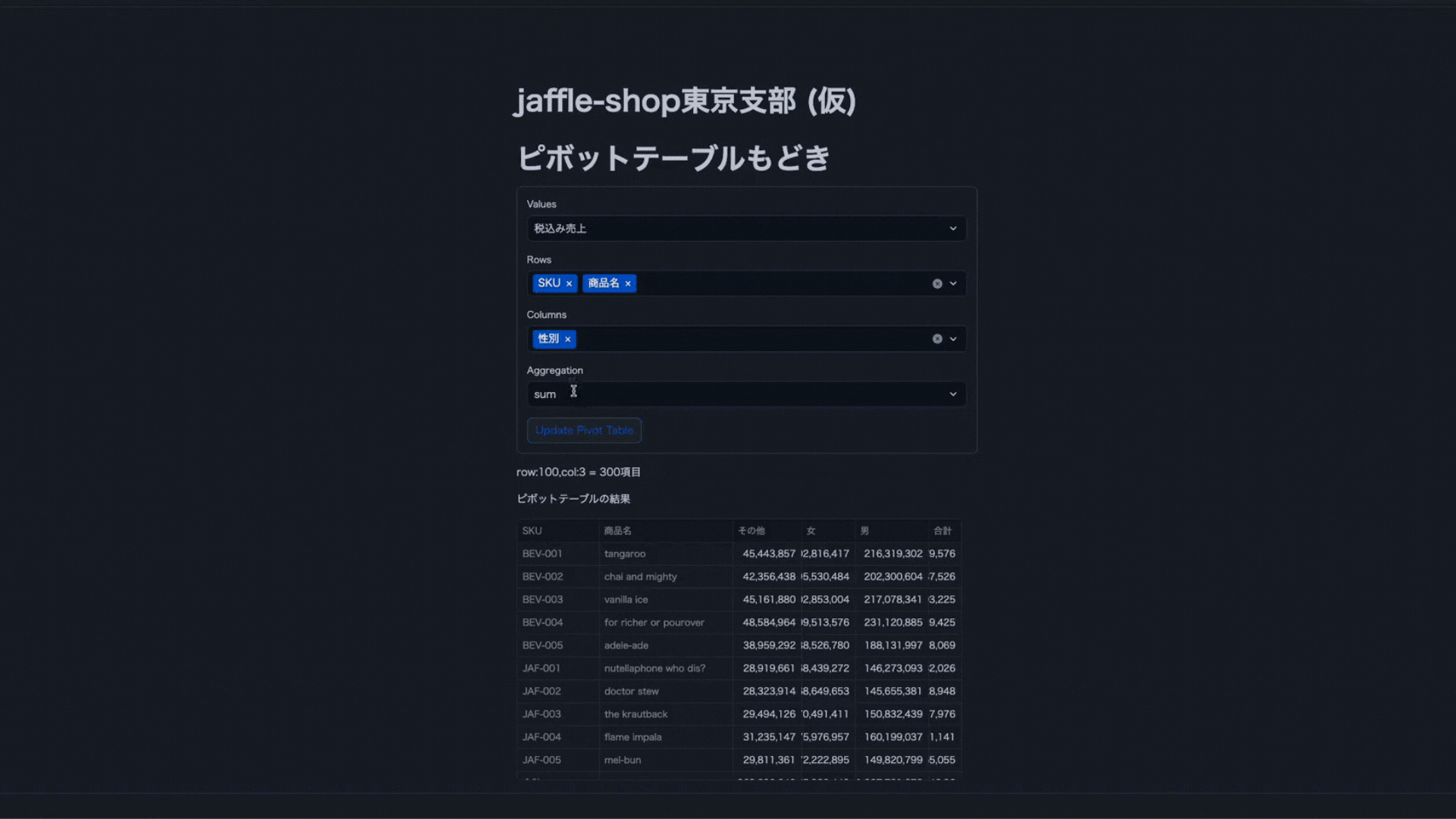
Streamlitに記載したコード
# Import python packages
import streamlit as st
from snowflake.snowpark.context import get_active_session
from snowflake.snowpark.session import Session
import pandas as pd
# Get the current credentials
session = get_active_session()
# Get Data
@st.cache_data
def get_data_from_snowflake():
return session.table("<db_name>.mart.mart_jaffle_shop_pivot_table").to_pandas()
df = get_data_from_snowflake()
st.title("jaffle-shop東京支部 (仮)")
########################################################################################
# #
########################################################################################
st.title("ピボットテーブルもどき")
# 型に応じたカラムの選別
numeric_columns = df.select_dtypes(include=["int16"]).columns.tolist() # ピボットテーブルの値用カラム
categorical_columns = df.select_dtypes(include=["object", "bool", "category","int8"]).columns.tolist() # ピボットテーブルの属性用カラム
# フォームでインタラクティブにピボットテーブルの設定を選択
with st.form("pivot_form"):
values = st.selectbox("Values", numeric_columns,index=numeric_columns.index("税込み売上"))
rows = st.multiselect("Rows", categorical_columns, default=["SKU","商品名"])
cols = st.multiselect("Columns", categorical_columns,default=["性別"])
aggfunc = st.selectbox("Aggregation", ["sum", "mean", "count"], index=0)
# フォームの送信ボタン
submit = st.form_submit_button("Update Pivot Table")
if submit:
row_combinations = df[rows].nunique().prod() # 行ラベルのユニークな組み合わせ数
col_combinations = df[cols].nunique().prod() # 列ラベルのユニークな組み合わせ数
total_combinations = row_combinations * col_combinations
st.write(f'row:{row_combinations},col:{col_combinations} = {total_combinations}項目')
# ピボットテーブルの作成中にスピナーを表示
with st.spinner("ピボットテーブルを更新中です..."):
# ピボットテーブルの作成
if aggfunc == "sum":
pivot_df = pd.pivot_table(df, values=values, index=rows, columns=cols, aggfunc="sum", margins=True, margins_name="合計")
elif aggfunc == "mean":
pivot_df = pd.pivot_table(df, values=values, index=rows, columns=cols, aggfunc="mean", margins=True, margins_name="合計")
elif aggfunc == "count":
pivot_df = pd.pivot_table(df, values=values, index=rows, columns=cols, aggfunc="count", margins=True, margins_name="合計")
# ピボットテーブルの表示
st.write("ピボットテーブルの結果")
st.dataframe(pivot_df)
Streamlitを触っているうちに下記のデータがほしいと思ったので次はダミーデータを集めていきます。
(一般公開されている生データも使います。)
- 商品の売上・購買履歴
- 天気
- カレンダー
- 顧客情報
ダミーデータの選定
jaffle-shopが有名なのでこちらのデータを使いつつ、
- 天気
- カレンダー
- 顧客の属性
を作成していきます。
jaffle-shop
jaffle-shopからは下記の情報を取り出します。
- 商品情報
- 売上・購買履歴
- 顧客情報
jafgenを使い、4年分のデータを作成します。
(任意)仮想環境作成
python -m venv venv
source venv/bin/activate
jafgenのインストール&4年分のデータダウンロード
pip install jafgen
# check
# jafgen --help
# load data of 4 year & ./jaffle-data/sample_raw_[file_name]
jafgen 4 -pre sample_raw
今回はprefixでsample_rawと付けているため下記のファイルが作成されます。
# tree
.
└── jaffle-data
├── sample_raw_customers.csv
├── sample_raw_items.csv
├── sample_raw_orders.csv
├── sample_raw_products.csv
├── sample_raw_stores.csv
├── sample_raw_supplies.csv
└── sample_raw_tweets.csv
Snowflakeへの取り込みは楽をしたいのでSnowsightで直接取り込みます。
取り込み場所は <db_name>.raw配下です。
顧客情報
jaffle-shopの顧客情報には顧客の名前しか属性が無いため、下記を追加します。
- 性別
- 年齢
後にdbtバージョンを載せますが、SQLにするとrandomを用いて下記のようなクエリを作成しています。
SQL参考例
-- テーブルの構造に合わせて顧客情報を生成
-- 顧客情報を一致させるため、random_seedは42とする。
with
customers as (select * from <db_name>.raw.customers),
generated_customer_features as (
select
customers.id as customer_id,
-- 性別をランダムに生成 (NULLも考慮)
case
when random(42) < 0.33
then '男'
when random(42) < 0.66
then '女'
when random(42) < 0.99
then 'その他'
else null -- NULL値
end as gender,
-- 年齢をランダムに生成、20%の確率でNULLにする
case
when random(42) < 0.2 then null else floor(uniform(10, 110, random(42))) -- 10歳以上110歳未満
end as age,
-- ランダムなemailアドレス生成、15%の確率でNULL
case
when random(42) < 0.15
then null
else lower(randstr(10, random(42))) || '@example.com'
end as email
from customers
),
transfer_type as (
select
generated_customer_features.customer_id::varchar as customer_id,
generated_customer_features.gender::varchar as gender,
generated_customer_features.age::varchar as age,
generated_customer_features.email::varchar as email
from generated_customer_features
),
final as (
select
transfer_type.customer_id,
transfer_type.gender,
transfer_type.age,
transfer_type.email
from transfer_type
)
select *
from final
天気データ
Prepper Open Data Bank JAPANESE WEATHER DATA
を利用します。
SnowflakeのMarketPlaceにも来ているのでGetします。
(気軽にデータを取り扱えることに感謝・・・!)
カレンダーデータ
同じくPrepper Open Data Bank JAPANESE CALENDAR DATAを利用します。
こちらもSnowflakeのMarketPlaceにも来ているのでGetします。

SOURCE/RAW→LAKE→DWH→MARTの作成
ここからはdbt Cloudで作成をしていきます。
作成するのは下記のモデルです。
(dbt coreでも作成可能ですが、dbt Exploreが良すぎたのでdbt Cloudを使います。)

フォルダ構成は下記の感じです。
.
├── README.md
├── dbt_project.yml
├── docs
│ └── pull_request_template.md
├── macros
│ └── get_custom_shcema.sql
├── models
│ ├── 1_raw
│ │ └── __sources.yml
│ ├── 2_lake
│ │ └── jaffle_shop
│ │ ├── lake_customer_features.sql
│ │ └── lake_customer_features.yml
│ ├── 3_dwh
│ │ ├── master
│ │ │ ├── dwh_master_customers.sql
│ │ │ ├── dwh_master_customers.yml
│ │ │ ├── dwh_master_products.sql
│ │ │ └── dwh_master_products.yml
│ │ └── transaction
│ │ ├── dwh_trans_buy_items.sql
│ │ ├── dwh_trans_buy_items.yml
│ │ ├── dwh_trans_items_products_customers.sql
│ │ └── dwh_trans_items_products_customers.yml
│ └── 4_mart
│ └── streamlit
│ ├── _exposures.yml
│ ├── mart_jaffle_shop_pivot_table.sql
│ └── mart_jaffle_shop_pivot_table.yml
└── seeds
├── age_buckets.csv
└── age_buckets.yml
SOURCE/RAW
models/1_raw/__sources.ymlを作成して下記を埋めていきます。
この段階で連携データのエラーが無いかdata_testsで固めるのもありです。
基本的に加工はできないのでYAMLのみでカラムを定義していきます。
(書く内容が多いのでコピペができない場合、基本機械に任せるか、VSCodeのマルチカーソルを駆使することをおすすめします。)
ソースコード
version: 2
sources:
- name: jaffle_shop
schema: raw
description: E-commerce data for the Jaffle Shop
tables:
- name: customers
tags: [raw, jaffle_shop, js]
description: 顧客情報
columns:
- name: id
description: 顧客id
data_tests:
- not_null
- unique
- name: name
description: 顧客名
- name: orders
tags: [raw, jaffle_shop, js]
description: 注文履歴
columns:
- name: id
description: 商品のオーダーid
data_tests:
- not_null
- unique
- name: customer
description: 顧客id
- name: ordered_at
description: オーダー日付時刻
- name: subtotal
description: 購入金額 (税抜き)
- name: tax_paid
description: 消費税
- name: order_total
description: 購入金額 (税有り)
- name: items
tags: [raw, jaffle_shop, js]
description: 各オーダーで売れた商品履歴
columns:
- name: id
description: 各オーダーで売れた商品履歴
data_tests:
- not_null
- unique
- name: order_id
description: オーダーid
- name: sku
description: 商品の管理id (単品管理id)
- name: products
tags: [raw, jaffle_shop, js]
description: 単品管理idに紐づく商品の詳細
columns:
- name: sku
description: 単品管理id
data_tests:
- not_null
- unique
- name: name
description: 商品名
- name: type
description: 商品の取り扱い元のタイプ
- name: price
description: 商品価格
- name: description
description: 商品説明
- name: podb_weather_data
database: prepper_open_data_bank__japanese_weather_data
schema: j_podb
description: PODBの天気データ
tables:
- name: j_wt_md
tags: [raw, podb]
description: 47都道府県の日時天気データ
data_tests:
- not_null:
column_name: ' "日付" || "地点番号" '
- unique:
column_name: ' "日付" || "地点番号" '
columns:
- name: 地点番号
quote: true
description: 観測地点のID
- name: 観測所名
quote: true
- name: 気象台・測候所_アメダス
quote: true
- name: 観測データ
quote: true
- name: 都道府県コード
quote: true
- name: 都道府県名
quote: true
- name: 都道府県名コード付
quote: true
- name: 都府県・振興局表示番号
quote: true
- name: 都府県・振興局名
quote: true
- name: 緯度
quote: true
- name: 経度
quote: true
- name: 日付
quote: true
description: 観測日
- name: 平均気圧_現地
quote: true
- name: 平均気圧_海面
quote: true
- name: 最低気圧_海面
quote: true
- name: 最低気圧_海面_時分
quote: true
- name: 降水量
quote: true
- name: 降水量_1時間最多
quote: true
- name: 降水量_1時間最多_時分
quote: true
- name: 降水量_10分間最多
quote: true
- name: 降水量_10分間最多_時分
quote: true
- name: 平均気温
quote: true
- name: 最高気温
quote: true
- name: 最高気温_時分
quote: true
- name: 最低気温
quote: true
- name: 最低気温_時分
quote: true
- name: 最低気温_時分
quote: true
- name: 平均蒸気圧
quote: true
- name: 平均湿度
quote: true
- name: 最低湿度
quote: true
- name: 最低湿度_時分
quote: true
- name: 平均風速
quote: true
- name: 最大風速
quote: true
- name: 最大風速_風向
quote: true
- name: 最大風速_時分
quote: true
- name: 最大瞬間風速
quote: true
- name: 最大瞬間風速_風向
quote: true
- name: 最大瞬間風速_時分
quote: true
- name: 最多風向
quote: true
- name: 日照時間
quote: true
- name: 全天日射量
quote: true
- name: 降雪量
quote: true
- name: 最深積雪量
quote: true
- name: 最深積雪量_時分
quote: true
- name: 平均雲量
quote: true
- name: 天気概況_昼
quote: true
- name: 天気概況_夜
quote: true
- name: 気象台・測候所ポイント
quote: true
- name: 都道府県代表気象台
quote: true
- name: podb_calendar_data
database: prepper_open_data_bank__japanese_calendar_data
schema: j_podb
description: PODBのカレンダーデータ
tables:
- name: j_japan_calendar
tags: [raw, podb]
description: PODBのカレンダーデータ
data_tests:
- not_null:
column_name: ' "日付" '
- unique:
column_name: ' "日付" '
columns:
- name: 日付
quote: true
- name: 曜日コード
quote: true
- name: 曜日
quote: true
- name: 祝日
quote: true
- name: 祝日名
quote: true
- name: 土日
quote: true
- name: 土日祝
quote: true
- name: 日祝
quote: true
- name: 振替休日
quote: true
- name: 休前日
quote: true
- name: 翌日が土祝となる平日
quote: true
- name: GW
quote: true
- name: GW_中間も休み
quote: true
- name: 年末年始
quote: true
- name: 連休
quote: true
- name: 当日からの連休数
quote: true
- name: 翌日からの連休数
quote: true
- name: 平日
quote: true
- name: 日祝明けの平日
quote: true
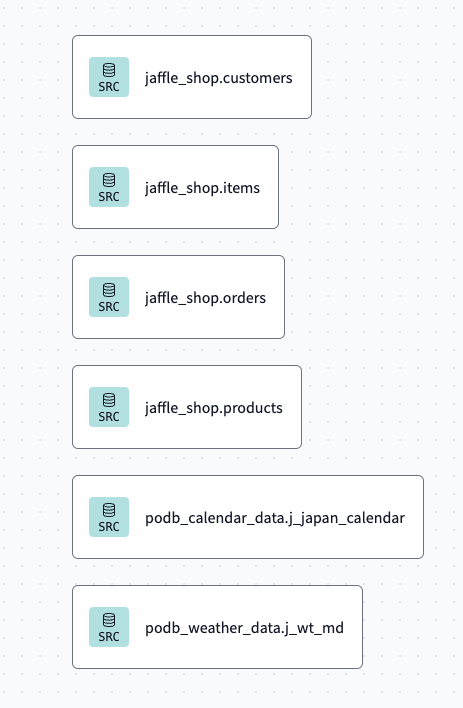
LAKE
LAKEでは顧客情報にダミーデータを付与します。
本来は顧客情報があると思うのでこのステップは無いと思います。
(できれば、SOURCE/RAWのテーブルたちをselect *で引っ張って来るのが理想です。)
端折ったので後のDWHまで作ると、dbt Explore→Reccommendationsでsourceを2つ以上joinするんじゃない!っとSeverity=Highで怒られてます笑
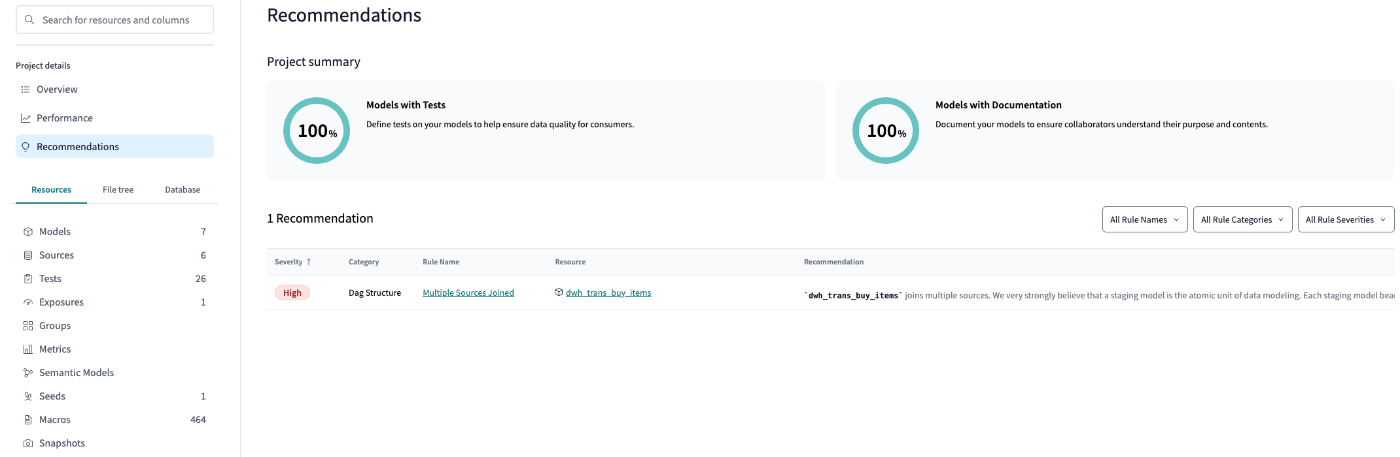

macros/get_custom_shcema.sql #カスタムスキーマのみ作成できるように変更
models/2_lake
└── jaffle_shop
├── lake_customer_features.sql
└── lake_customer_features.yml
ソースコード
macros/get_custom_shcema.sql
参考:https://docs.getdbt.com/docs/build/custom-schemas#how-does-dbt-generate-a-models-schema-name
(default_schemaがいらない。)
{% macro generate_schema_name(custom_alias=none, node=none) -%}
{%- if custom_alias is none -%}
{{ target.schema }}
{%- else -%}
{{ custom_alias | trim }}
{%- endif -%}
{%- endmacro %}
lake_customer_features.sql
{{ config(schema="lake", materialized="table", tags=["lake", "jaffle_shop", "js"]) }}
-- テーブルの構造に合わせて顧客情報を生成
-- 顧客情報を一致させるため、random_seedは42とする。
with
customers as (select * from {{ source("jaffle_shop", "customers") }}),
generated_customer_features as (
select
customers.id as customer_id,
-- 性別をランダムに生成 (NULLも考慮)
case
when random(42) < 0.33
then '男'
when random(42) < 0.66
then '女'
when random(42) < 0.99
then 'その他'
else null -- NULL値
end as gender,
-- 年齢をランダムに生成、20%の確率でNULLにする
case
when random(42) < 0.2 then null else floor(uniform(10, 110, random(42))) -- 10歳以上110歳未満
end as age,
-- ランダムなemailアドレス生成、15%の確率でNULL
case
when random(42) < 0.15
then null
else lower(randstr(10, random(42))) || '@example.com'
end as email
from customers
),
transfer_type as (
select
generated_customer_features.customer_id::varchar as customer_id,
generated_customer_features.gender::varchar as gender,
generated_customer_features.age::varchar as age,
generated_customer_features.email::varchar as email
from generated_customer_features
),
final as (
select
transfer_type.customer_id,
transfer_type.gender,
transfer_type.age,
transfer_type.email
from transfer_type
)
select *
from final
lake_customer_features.yml
version: 2
models:
- name: lake_customer_features
description: >
customersの情報に性別・年齢・Eメールを紐づけたデータ。
性別・年齢・Eメールの情報はランダムでデータが欠損している。
config:
contract:
enforced: true
columns:
- name: customer_id
description: 顧客id
data_tests:
- not_null
- unique
data_type: varchar
- name: gender
description: 性別 (男・女・その他)
data_type: varchar
- name: age
description: 年齢 (10 <= x < 110)
data_type: varchar
- name: email
description: Eメール
data_type: varchar
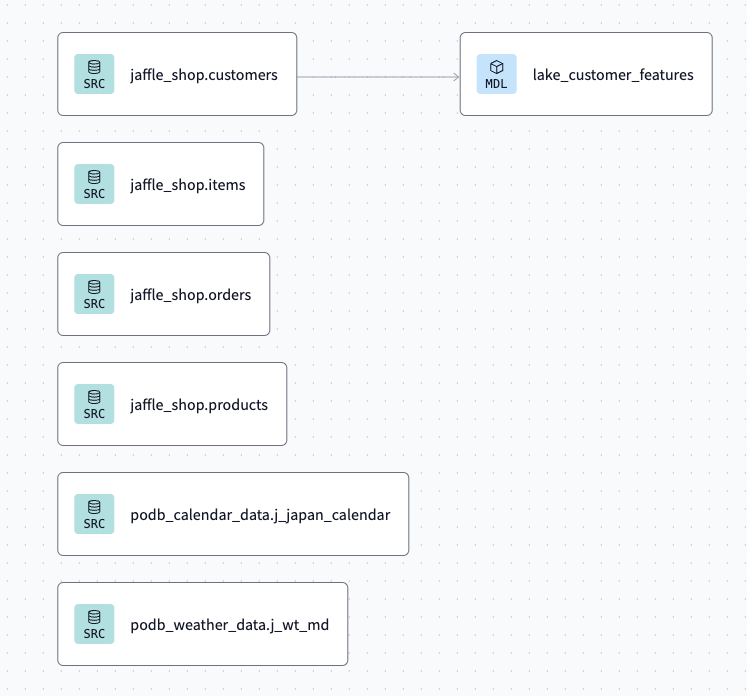
DWH
DWHではマスターデータとトランザクションデータの切り分けてテーブルを作成します。
今回はsnapshotやincremental等の難しいことはせず、
必要なテーブルを洗替で作成していきます。
また、dwh_trans_items_products_customersに関しては非正規形でテーブルを作成します。
models/3_dwh
├── master
│ ├── dwh_master_customers.sql
│ ├── dwh_master_customers.yml
│ ├── dwh_master_products.sql
│ └── dwh_master_products.yml
└── transaction
├── dwh_trans_buy_items.sql
├── dwh_trans_buy_items.yml
├── dwh_trans_items_products_customers.sql
└── dwh_trans_items_products_customers.yml
seeds
├── age_buckets.csv
└── age_buckets.yml
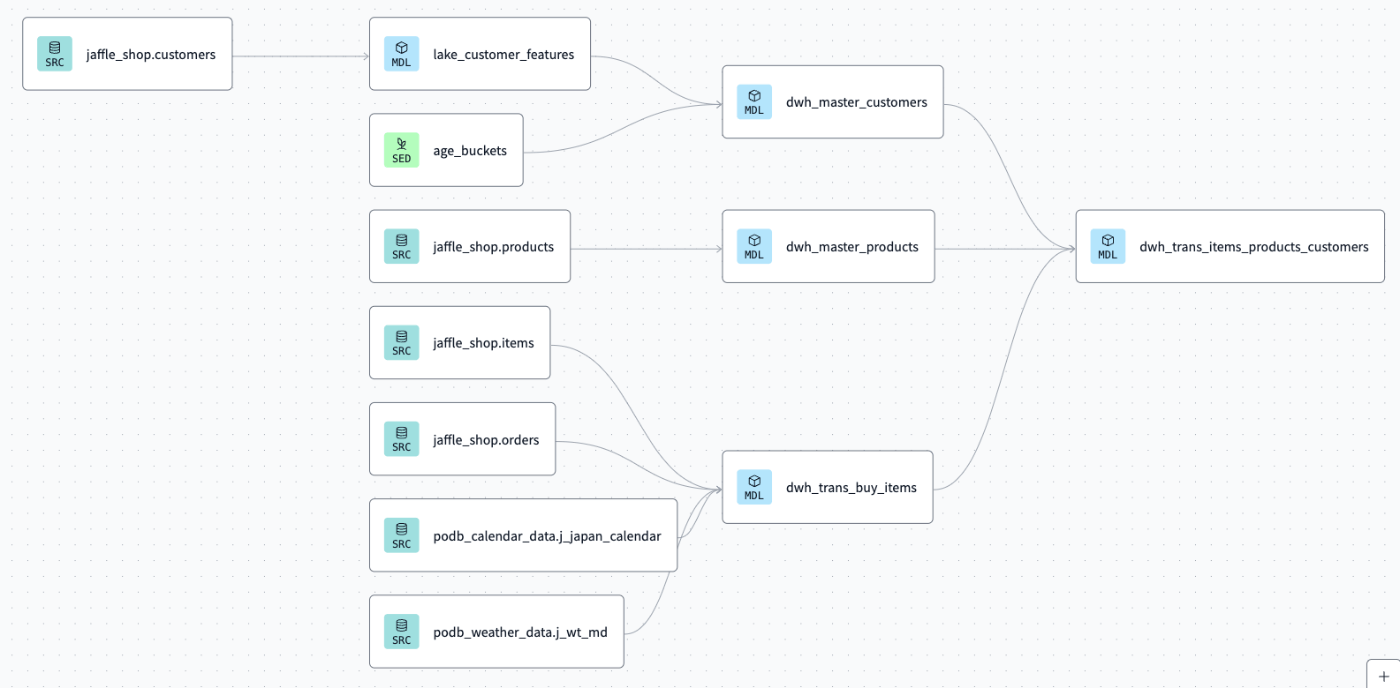
ソースコード
dwh_master_customers.sql
{{ config(schema="dwh", materialized="table") }}
with
/* import ctes*/
customer_features as (select * from {{ ref("lake_customer_features") }}),
age_buckets as (select * from {{ ref("age_buckets") }}),
make_age_buckets as (
select
customer_features.customer_id,
customer_features.gender,
customer_features.age,
customer_features.email,
age_buckets.age_group,
from customer_features
left join
age_buckets
on customer_features.age::number
between age_buckets.age_min and age_buckets.age_max
),
final as (
select
make_age_buckets.customer_id,
make_age_buckets.gender,
make_age_buckets.email,
make_age_buckets.age_group,
make_age_buckets.age,
from make_age_buckets
)
select *
from final
dwh_master_customers.yml
version: 2
models:
- name: dwh_master_customers
description: >
customer_idに紐づく顧客の詳細情報があるマスタテーブル
config:
contract:
enforced: true
columns:
- name: customer_id
description: >
顧客id
data_tests:
- not_null
- unique
data_type: varchar
- name: gender
description: 性別 (男・女・その他)
data_type: varchar
- name: age
description: 年齢 (10 <= x < 110)
data_type: varchar
- name: email
data_type: varchar
- name: age_group
description: >
10歳ごとの年齢グループ (例: 10-19, 20-29 ...)
100歳を超える場合は100歳以上でグループを作る
data_type: varchar
dwh_master_products.sql
{{ config(schema="dwh", materialized="table") }}
with
/* import ctes*/
products as (select * from {{ source("jaffle_shop", "products") }}),
cast_type_products as (
select
products.sku::varchar as sku,
products.name::varchar as name,
products.type::varchar as type,
products.price::number as price,
products.description::varchar as description,
from products
),
final as (
select
cast_type_products.sku,
cast_type_products.name,
cast_type_products.type,
cast_type_products.price,
cast_type_products.description,
from cast_type_products
)
select *
from final
dwh_master_products.yml
version: 2
models:
- name: dwh_master_products
description: >
skuに紐づく商品の詳細情報があるマスタテーブル
config:
contract:
enforced: true
columns:
- name: sku
description: >
商品を単品で管理するid
ストックキーピングユニット(Stock Keeping Unit)の略
data_tests:
- not_null
- unique
data_type: varchar
- name: name
description: 商品名
data_type: varchar
- name: type
description: 商品の取り扱い元のタイプ
data_type: varchar
- name: price
description: 商品価格
data_type: number
- name: description
description: 商品説明
data_type: varchar
dwh_trans_buy_items.sql
{{ config(schema="dwh", materialized="table") }}
with
/* import ctes*/
items as (select * from {{ source("jaffle_shop", "items") }}),
orders as (select * from {{ source("jaffle_shop", "orders") }}),
podb_weather_data as (
/* jaffle_shopは東京都内にある1店舗と仮定する、観測所は東京*/
select * from {{ source("podb_weather_data", "j_wt_md") }} where "観測所名" = '東京'
),
podb_calendar_data as (
select * from {{ source("podb_calendar_data", "j_japan_calendar") }}
),
join_items_orders as (
select
items.id as buy_items_id,
items.order_id,
items.sku,
orders.customer as customer_id,
/* 時間は不要なのでここで落とす*/
to_date(orders.ordered_at) as ordered_date,
orders.subtotal,
orders.tax_paid,
orders.order_total
from items
left join orders on items.order_id = orders.id
),
join_items_weather as (
select
join_items_orders.buy_items_id,
join_items_orders.order_id,
join_items_orders.sku,
join_items_orders.customer_id,
join_items_orders.ordered_date,
join_items_orders.subtotal,
join_items_orders.tax_paid,
join_items_orders.order_total,
podb_weather_data."観測所名",
podb_weather_data."平均気温",
podb_weather_data."平均湿度",
podb_weather_data."天気概況_昼",
podb_weather_data."天気概況_夜"
from join_items_orders
left join
podb_weather_data on join_items_orders.ordered_date = podb_weather_data."日付"
),
join_items_calendar as (
select
join_items_weather.buy_items_id,
join_items_weather.order_id,
join_items_weather.sku,
join_items_weather.customer_id,
join_items_weather.subtotal,
join_items_weather.tax_paid,
join_items_weather.order_total,
join_items_weather.ordered_date,
podb_calendar_data."曜日コード",
podb_calendar_data."曜日",
podb_calendar_data."土日祝",
podb_calendar_data."祝日名",
podb_calendar_data."GW",
podb_calendar_data."GW_中間も休み",
podb_calendar_data."年末年始",
podb_calendar_data."連休",
join_items_weather."観測所名",
join_items_weather."平均気温",
join_items_weather."平均湿度",
join_items_weather."天気概況_昼",
join_items_weather."天気概況_夜"
from join_items_weather
left join
podb_calendar_data
on join_items_weather.ordered_date = podb_calendar_data."日付"
),
cast_type_items as (
select
join_items_calendar.buy_items_id::varchar as buy_items_id,
join_items_calendar.order_id::varchar as order_id,
join_items_calendar.sku::varchar as sku,
join_items_calendar.customer_id::varchar as customer_id,
join_items_calendar.subtotal::number as subtotal,
join_items_calendar.tax_paid::number as tax_paid,
join_items_calendar.order_total::number as order_total,
join_items_calendar.ordered_date::date as ordered_date,
join_items_calendar."曜日コード"::varchar as "曜日コード",
join_items_calendar."曜日"::varchar as "曜日",
join_items_calendar."土日祝"::boolean as "土日祝",
join_items_calendar."祝日名"::varchar as "祝日名",
join_items_calendar."GW"::boolean as "GW",
join_items_calendar."GW_中間も休み"::boolean as "GW_中間も休み",
join_items_calendar."年末年始"::boolean as "年末年始",
join_items_calendar."連休"::boolean as "連休",
join_items_calendar."観測所名"::varchar as "観測所名",
join_items_calendar."平均気温"::number as "平均気温",
join_items_calendar."平均湿度"::number as "平均湿度",
join_items_calendar."天気概況_昼"::varchar as "天気概況_昼",
join_items_calendar."天気概況_夜"::varchar as "天気概況_夜"
from join_items_calendar
),
final as (
select
cast_type_items.buy_items_id,
cast_type_items.order_id,
cast_type_items.sku,
cast_type_items.customer_id,
cast_type_items.subtotal,
cast_type_items.tax_paid,
cast_type_items.order_total,
cast_type_items.ordered_date,
cast_type_items."曜日コード",
cast_type_items."曜日",
cast_type_items."土日祝",
cast_type_items."祝日名",
cast_type_items."GW",
cast_type_items."GW_中間も休み",
cast_type_items."年末年始",
cast_type_items."連休",
cast_type_items."観測所名",
cast_type_items."平均気温",
cast_type_items."平均湿度",
cast_type_items."天気概況_昼",
cast_type_items."天気概況_夜"
from cast_type_items
)
select *
from final
dwh_trans_buy_items.yml
version: 2
models:
- name: dwh_trans_buy_items
description: >
商品の購入項目(items)単位での履歴を保持するテーブル。
購入時期の天気情報及び休日情報を追加している
config:
contract:
enforced: true
columns:
- name: buy_items_id
description: 商品の購入項目単位を管理するid
data_tests:
- not_null
- unique
data_type: varchar
- name: order_id
description: 商品の注文id
data_type: varchar
- name: sku
description: 商品管理id
data_type: varchar
- name: customer_id
description: 顧客管理id
data_type: varchar
- name: subtotal
description: 税抜き前売上
data_type: number
- name: tax_paid
description: 税金分の売上
data_type: number
- name: order_total
description: 税金込みの売上
data_type: number
- name: ordered_date
description: 商品の取引日付
data_type: date
- name: 曜日コード
quote: true
description: 1:月,2:火,3:水,4:木,5:金,6:土,7:日
data_type: varchar
- name: 曜日
quote: true
data_type: varchar
- name: 土日祝
quote: true
data_type: boolean
- name: 祝日名
quote: true
data_type: varchar
- name: GW
quote: true
data_type: boolean
- name: GW_中間も休み
description: >
GWの中間休みに有給を使った場合のGW休み期間
1,2週間ほどの長期休暇となる
quote: true
data_type: boolean
- name: 年末年始
quote: true
data_type: boolean
- name: 連休
quote: true
data_type: boolean
- name: 観測所名
quote: true
description: >
天候の観測をしている場所の名前。
今回はjaffle_shopが東京にあると仮定しているため、観測所は「東京」を使用している
data_type: varchar
- name: 平均気温
quote: true
description: その日の平均気温
data_type: number
- name: 平均湿度
quote: true
description: その日の平均湿度
data_type: number
- name: 天気概況_昼
quote: true
description: 昼間の天気概要 6時~18時 の時間
data_type: varchar
- name: 天気概況_夜
quote: true
description: 夜間の天気概要 18時~翌6時 の時間
data_type: varchar
dwh_trans_items_products_customers.sql
{{ config(schema="dwh", materialized="table") }}
with
/* import ctes*/
trans_buy_items as (select * from {{ ref("dwh_trans_buy_items") }}),
master_customers as (select * from {{ ref("dwh_master_customers") }}),
master_products as (select * from {{ ref("dwh_master_products") }}),
join_items_customers_products as (
select
trans_buy_items.buy_items_id,
trans_buy_items.sku,
trans_buy_items.customer_id,
trans_buy_items.subtotal,
trans_buy_items.tax_paid,
trans_buy_items.order_total,
trans_buy_items.ordered_date,
trans_buy_items."曜日コード",
trans_buy_items."曜日",
trans_buy_items."土日祝",
trans_buy_items."祝日名",
trans_buy_items."GW",
trans_buy_items."GW_中間も休み",
trans_buy_items."年末年始",
trans_buy_items."連休",
trans_buy_items."観測所名",
trans_buy_items."平均気温",
trans_buy_items."平均湿度",
trans_buy_items."天気概況_昼",
trans_buy_items."天気概況_夜",
master_customers.gender,
master_customers.age_group,
master_customers.email,
master_products.name,
from trans_buy_items
left join
master_customers
on trans_buy_items.customer_id = master_customers.customer_id
left join master_products on trans_buy_items.sku = master_products.sku
),
final as (
select
join_items_customers_products.buy_items_id,
join_items_customers_products.sku,
join_items_customers_products.customer_id,
join_items_customers_products.subtotal,
join_items_customers_products.tax_paid,
join_items_customers_products.order_total,
join_items_customers_products.ordered_date,
join_items_customers_products."曜日コード",
join_items_customers_products."曜日",
join_items_customers_products."土日祝",
join_items_customers_products."祝日名",
join_items_customers_products."GW",
join_items_customers_products."GW_中間も休み",
join_items_customers_products."年末年始",
join_items_customers_products."連休",
join_items_customers_products."観測所名",
join_items_customers_products."平均気温",
join_items_customers_products."平均湿度",
join_items_customers_products."天気概況_昼",
join_items_customers_products."天気概況_夜",
join_items_customers_products.gender,
join_items_customers_products.age_group,
join_items_customers_products.email,
join_items_customers_products.name as product_name,
from join_items_customers_products
)
select *
from final
dwh_trans_items_products_customers.yml
version: 2
models:
- name: dwh_trans_items_products_customers
description: >
itemsとproductsとcustomersをjoinした非正規形のテーブル
mart層から必要分をselectするほうが簡単だと判断したため作成
config:
contract:
enforced: true
columns:
- name: buy_items_id
description: 商品の購入項目単位を管理するid
data_tests:
- not_null
- unique
data_type: varchar
- name: sku
description: 商品管理id
data_type: varchar
- name: customer_id
description: 顧客管理id
data_type: varchar
- name: subtotal
description: 税抜き前売上
data_type: number
- name: tax_paid
description: 税金分の売上
data_type: number
- name: order_total
description: 税金込みの売上
data_type: number
- name: ordered_date
description: 商品の取引日付
data_type: date
- name: 曜日コード
quote: true
description: 1:月,2:火,3:水,4:木,5:金,6:土,7:日
data_type: varchar
- name: 曜日
quote: true
data_type: varchar
- name: 土日祝
quote: true
data_type: boolean
- name: 祝日名
quote: true
data_type: varchar
- name: GW
quote: true
data_type: boolean
- name: GW_中間も休み
description: >
GWの中間休みに有給を使った場合のGW休み期間
1,2週間ほどの長期休暇となる
quote: true
data_type: boolean
- name: 年末年始
quote: true
data_type: boolean
- name: 連休
quote: true
data_type: boolean
- name: 観測所名
quote: true
description: >
天候の観測をしている場所の名前。
今回はjaffle_shopが東京にあると仮定しているため、観測所は「東京」を使用している
data_type: varchar
- name: 平均気温
quote: true
description: その日の平均気温
data_type: number
- name: 平均湿度
quote: true
description: その日の平均湿度
data_type: number
- name: 天気概況_昼
quote: true
description: 昼間の天気概要 6時~18時 の時間
data_type: varchar
- name: 天気概況_夜
quote: true
description: 夜間の天気概要 18時~翌6時 の時間
data_type: varchar
- name: gender
description: 性別 (男・女・その他)
data_type: varchar
- name: age_group
description: >
10歳ごとの年齢グループ (例: 10-19, 20-29 ...)
100歳を超える場合は100歳以上でグループを作る
data_type: varchar
- name: email
data_type: varchar
- name: product_name
description: 商品名
data_type: varchar
age_buckets.csv
age_min,age_max,age_group
10,19,10代
20,29,20代
30,39,30代
40,49,40代
50,59,50代
60,69,60代
70,79,70代
80,89,80代
90,99,90代
100,150,100以上
age_buckets.yml
version: 2
seeds:
- name: age_buckets
description: 年齢から年代に変換するseedファイル
columns:
- name: age_min
data_tests:
- unique
- not_null
- name: age_max
data_tests:
- unique
- not_null
- name: age_group
data_tests:
- unique
- not_null
MART
MARTでは変換を集計やカラム名の変更程度に留めています。
(できる限りDWH:MARTの関連を 1:多 で収めたい。)
フォルダ構造は今後複数のOutput先があると仮定してサービス名/ツール名を入れてます。
models/4_mart
└── streamlit
├── _exposures.yml
├── mart_jaffle_shop_pivot_table.sql
└── mart_jaffle_shop_pivot_table.yml
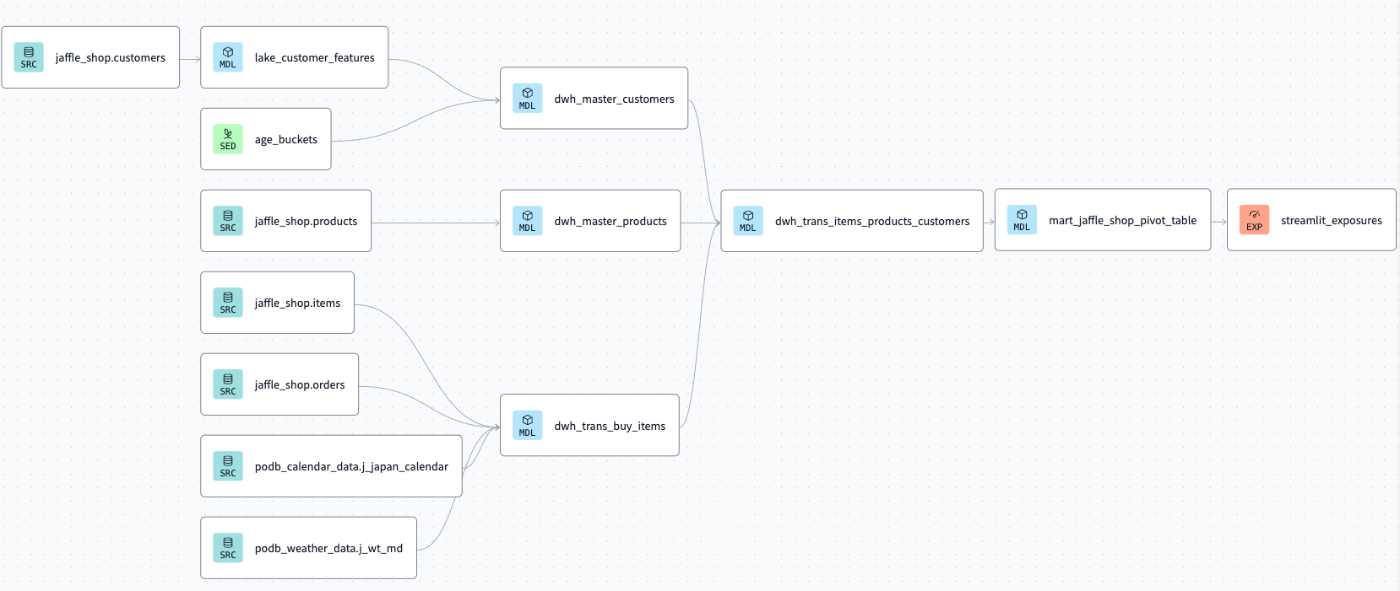
ソースコード
_exposures.yml
version: 2
exposures:
- name: streamlit_exposures
type: dashboard # ここはdashboard, analysis, mlなど用途に応じて指定
owner:
email: ''
description: >
Stremalitとサンプルデータを用いたデータ開発の例
jaffle_shopというショップが東京に存在するという架空の話で、
顧客の購買履歴のデータを分析したダッシュボードを作成している
depends_on:
- ref('mart_jaffle_shop_pivot_table') # mart層のテーブルやモデルへの参照
maturity: low
url: '' # ダッシュボードやリポジトリのリンク
tags: ['output','streamlit','jaffle_shop','js']
mart_jaffle_shop_pivot_table.sql
{{ config(schema="mart", materialized="table", tags=["mart", "streamlit", "js"]) }}
with
/* import ctes*/
trans_items_products_customers as (
select * from {{ ref("dwh_trans_items_products_customers") }}
),
rename_columns as (
select
trans_items_products_customers.buy_items_id as "購入履歴管理ID",
trans_items_products_customers.sku as sku,
trans_items_products_customers.customer_id as "顧客管理ID",
trans_items_products_customers.subtotal as "税抜き売上",
trans_items_products_customers.tax_paid as "税金の売上",
trans_items_products_customers.order_total as "税込み売上",
trans_items_products_customers.ordered_date as "商品の取引日付",
trans_items_products_customers."曜日コード" as "曜日コード",
trans_items_products_customers."曜日" as "曜日",
trans_items_products_customers."祝日名" as "祝日名",
trans_items_products_customers."土日祝" as "土日祝",
trans_items_products_customers.gw as gw,
trans_items_products_customers."GW_中間も休み" as "GW_中間も休み",
trans_items_products_customers."年末年始" as "年末年始",
trans_items_products_customers."連休" as "連休",
trans_items_products_customers."観測所名" as "観測所名",
trans_items_products_customers."平均気温" as "平均気温",
trans_items_products_customers."平均湿度" as "平均湿度",
trans_items_products_customers."天気概況_昼" as "天気概況_昼",
trans_items_products_customers."天気概況_夜" as "天気概況_夜",
trans_items_products_customers.gender as "性別",
trans_items_products_customers.age_group as "年代",
trans_items_products_customers.email as "Eメール",
trans_items_products_customers.product_name as "商品名",
from trans_items_products_customers
),
final as (
select
rename_columns."購入履歴管理ID",
rename_columns.sku,
rename_columns."顧客管理ID",
rename_columns."税抜き売上",
rename_columns."税金の売上",
rename_columns."税込み売上",
rename_columns."商品の取引日付",
rename_columns."曜日コード",
rename_columns."曜日",
rename_columns."祝日名",
rename_columns."土日祝",
rename_columns.gw,
rename_columns."GW_中間も休み",
rename_columns."年末年始",
rename_columns."連休",
rename_columns."観測所名",
rename_columns."平均気温",
rename_columns."平均湿度",
rename_columns."天気概況_昼",
rename_columns."天気概況_夜",
rename_columns."性別",
rename_columns."年代",
rename_columns."Eメール",
rename_columns."商品名",
from rename_columns
)
select *
from final
mart_jaffle_shop_pivot_table.yml
version: 2
models:
- name: mart_jaffle_shop_pivot_table
description: >
streamlitでピボットテーブル用に用意したテーブル
DWHのカラムをすべて引続ぎ、日本語カラムにしている。
config:
contract:
enforced: true
columns:
- name: 購入履歴管理ID
quote: true
data_tests:
- not_null
- unique
data_type: varchar
- name: SKU
quote: true
description: >
Stock Keeping Unit(ストック・キーピング・ユニット)
一般的には受発注や在庫管理を行う時の、『最小の管理単位』
https://www.kantsu.com/terms/2815/
data_type: varchar
- name: 顧客管理ID
quote: true
data_type: varchar
- name: 税抜き売上
quote: true
data_type: number
- name: 税金の売上
quote: true
data_type: number
- name: 税込み売上
quote: true
data_type: number
- name: 商品の取引日付
quote: true
data_type: date
- name: 曜日コード
quote: true
data_type: varchar
- name: 曜日
quote: true
data_type: varchar
- name: 祝日名
quote: true
data_type: varchar
- name: 土日祝
quote: true
data_type: boolean
- name: GW
quote: true
data_type: boolean
- name: GW_中間も休み
quote: true
description: >
GWの中間休みに有給を使った場合のGW休み期間 1,2週間ほどの長期休暇となる
data_type: boolean
- name: 年末年始
quote: true
data_type: boolean
- name: 連休
quote: true
data_type: boolean
- name: 観測所名
quote: true
description: >
天候の観測をしている場所の名前。
今回はjaffle_shopが東京にあると仮定しているため、観測所は「東京」を使用している
data_type: varchar
- name: 平均気温
quote: true
description: その日の平均気温
data_type: number
- name: 平均湿度
quote: true
description: その日の平均湿度
data_type: number
- name: 天気概況_昼
quote: true
description: >
売上日の天気 (昼)
昼間の天気概要 6時~18時 の時間
data_type: varchar
- name: 天気概況_夜
quote: true
description: >
売上日の天気 (夜)
夜間の天気概要 18時~翌6時 の時間
data_type: varchar
- name: 性別
quote: true
description: 男・女・その他
data_type: varchar
- name: 年代
quote: true
description: >
10歳ごとの年齢グループ (例: 10-19, 20-29 ...) 100歳を超える場合は100歳以上でグループを作る
data_type: varchar
- name: Eメール
quote: true
data_type: varchar
- name: 商品名
quote: true
data_type: varchar
具体的な作業手順は以上です。
所感
- dbt Cloud
- Streamlit in Snowflake (SIS)
の感想を述べていきます。
dbt Cloud
気になるところ
- 事前準備で何度も同じ内容を打ち込むのが大変だった。
- 特にRSAのCredentialを入れ込むのは大変
- dbt Cloudのみでデータ取り込み(data ingestion)ができる機能があれば最高だと思った。
- TROCCO、snowpipe、snowflakeのselect $1 from @stageでも可能だが、dbt CloudでいろんなDWHを交差しながら変換とかできたら面白そうと思いました。
良かったところ
- dbt Exploreの機能が良すぎる
- リネージグラフのノードをクリックすると画面遷移せず、カラム情報やテーブルの詳細情報がすぐに見れるところ
- リネージグラフの検索で候補が出てくれるのが素晴らしい
- リネージグラフに乗せる情報でテストのPASSやモデルのタイプが見れる
- Overviewで何のテーブルをいつ、どのように変更したか履歴が見れる
- PerformanceでPJ内にあるモデルの実行頻度や実行時間をみてボトルネックを探せる
- Recommendationsで開発ルールからモデルの修正推薦を出してくれる
- リネージグラフのノードをクリックすると画面遷移せず、カラム情報やテーブルの詳細情報がすぐに見れるところ


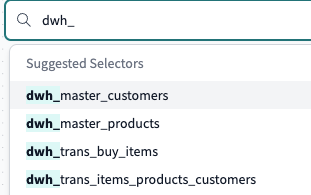
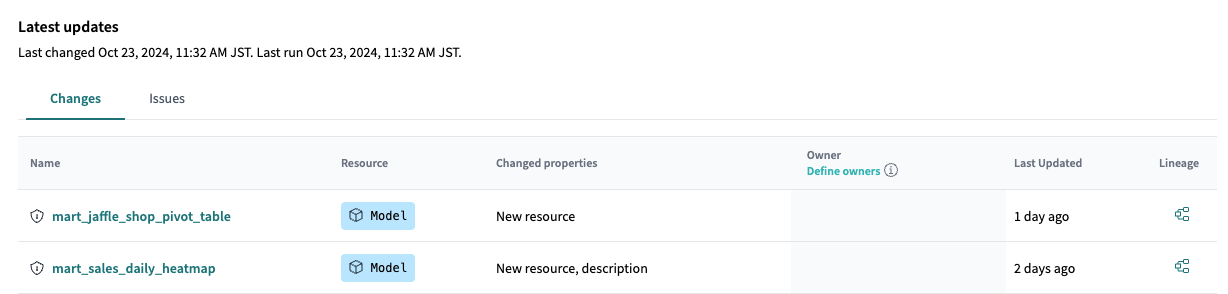
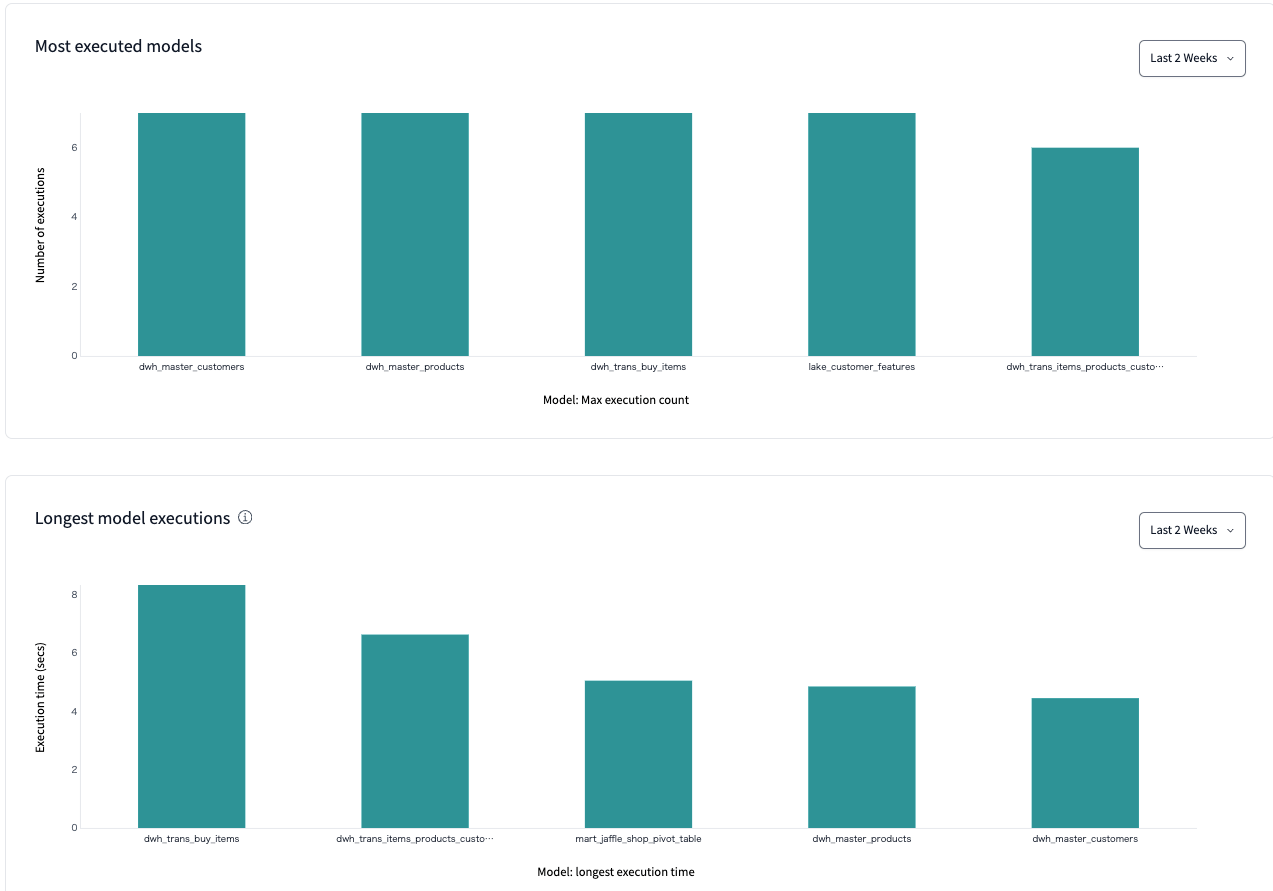
今までdbt docsを使っていましたがこの機能の多さは惚れました。
Streamlit in Snowflake (SIS)
気になるところ
- JavaScriptを使ったインタラクティブな画面が作れないところ
- Warehouseのauto suspendが最小15分なのでXSでもお高い
- 最初はローカルで作成して、SISに乗せるとかがおすすめ
- end session後使ってないのに動いているWarehouseはsuspendしておくと料金が抑えられる
良かったところ
- 新しいBIを追加しなくてもPythonベースで爆速開発ができる
- chatGPTのPython & Streamlit Expertとの親和性も高い
- 認証情報を設定ファイルに書く必要がないので、やらかしがなくなる
- Snowflake内で他ユーザへの共有がとても楽、かつ見せたい人を限定できる
- Snowflakeで認証を通せない人には見せない、みたいな経路を作れる
PrivateLink対応で閉域網開発ができるようになれば更に導入しやすくなりますね〜!
さいごに
ノリと勢いでエイヤと作りましたが、このモックは改良しがいがあるので色々触ってみたいと思いました。
(TROCCOとか組み合わせても面白そう)
あとは、データを公開していただいている全ての方に感謝をしつつ、データ基盤を作っていきたいと思います。
みなさんもこの記事を見て面白そうだったら、ぜひ遊んでみてください。
以上hamaでした〜。

Discussion