レコメンドシステム—— DeepFM(Deep Factorization Machine)
シリーズの目次
レコメンドシステムのシリーズをここにまとめています。
はじめに
本稿では、レコメンデーションシステム分野における重要な研究論文「DeepFM: A Factorization-Machine based Neural Network for CTR Prediction」について詳しく解説します。
DeepFMは、Factorization Machine(FM)とDeep Neural Network(Deep)を革新的に統合したモデルです。従来のWide & Deepモデルが使用していたLogistic Regression(LR)をFMに置き換えることで、モデルのwide部分における特徴抽出能力を大幅に向上させています。DeepFMの理解を深めるためには、事前にFMとWide & Deepの基本概念を把握しておくことを推奨します:
論文のリンク:
DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
DeepFMの特徴
DeepFMは、FMを基盤として発展したアルゴリズムと位置付けられます。このモデルは、FMとDeep Neural Networkを効果的に組み合わせることで、以下の重要な特徴を実現しています:
-
特徴間の相互作用を複数のレベルで捉える:
- FM部分:低次元での特徴間の相互作用を学習
- Deep NN部分:高次元での複雑な特徴間の相互作用を学習
-
実用的な利点:
- 事前学習不要:潜在ベクトルの獲得にFMの事前トレーニングが不要
- 特徴エンジニアリングの自動化:人工的な特徴設計が不要
- 統合的学習:低次元と高次元の特徴相互作用を同時に学習
- 効率的な学習:FMモジュールとDeepモジュールで特徴埋め込み層を共有することによる、トレーニングの高速化と精度向上
DeepFMのアーキテクチャ
まず、DeepFMの全体構造を概観しましょう。モデルは大きく2つのコンポーネントから構成されています:左側のFM層と右側のDeep層です。両コンポーネントは同一の特徴入力を共有することで、効率的な学習を実現しています。

Sparse Features(スパース特徴層)

カテゴリカル特徴をニューラルネットワークで処理するためには、まず数値表現に変換する必要があります。この過程は以下のように行われます:
-
特徴のフィールド化:
各カテゴリカル変数は「フィールド」として扱われます。例えば、「星座」というフィールドには、「おひつじ座」「おうし座」などの値が含まれます。 -
エンコーディング:
通常、まずLabelEncoderを使用して各カテゴリ値を整数に変換します(例:天秤座→10)。その後、必要に応じてOne-hotエンコーディングを適用して二値ベクトルに変換します。
このアプローチにより、カテゴリカル特徴を効率的に処理できる形式に変換しつつ、元の情報を保持することができます。
Dense Embeddings(密な埋め込み層)
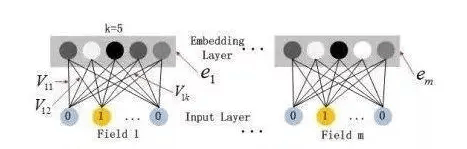
埋め込み層は、高次元のスパースな特徴ベクトルを低次元の密なベクトル表現に変換する重要な役割を果たします。この層には以下の特徴的な性質があります:
- 統一された表現:
- すべての特徴フィールドは、入力の次元に関係なく、同一の長さK(埋め込み次元)のベクトルに変換されます。
- これにより、異なる特徴タイプを統一的に扱うことが可能になります。
- パラメータ共有:
- FMで学習された潜在ベクトルVikが埋め込み層の重みとして利用されます。
- この共有により、モデルの学習効率が向上し、より robust な特徴表現が可能になります。
埋め込みプロセスの流れ:
- 各特徴フィールドの入力を独立して処理
- 低次元の密なベクトルに変換
- 変換されたベクトルを横方向に連結
- 数値特徴と組み合わせてDeepとFMの両方の入力として使用
FM Layer(FM層)
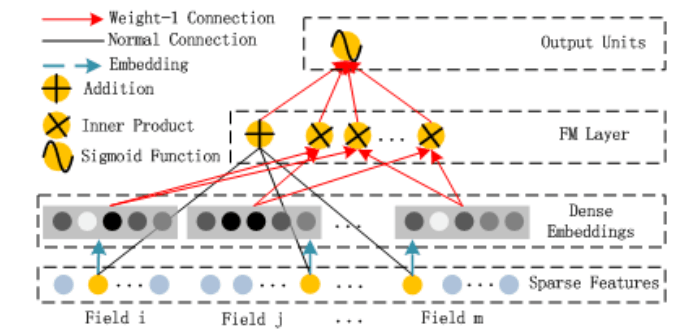
FM層は、特徴間の相互作用を効率的に学習するために、2つの重要なコンポーネントを持っています:
-
線形部分(図中の黒い線):
- 各特徴に対して個別の重みを学習
- これらの重み付けられた特徴値の総和を計算
- 一次の特徴効果を捉える役割
-
交差部分(図中の赤い線):
- 特徴を2つずつペアにして掛け合わせる
- 各ペアに対して重み付けを行う
- これらの重み付き積の総和を計算
- 二次の特徴間相互作用を捉える役割
FM部分の数学的表現は以下の式で与えられます:

Hidden Layer(Deep部分)
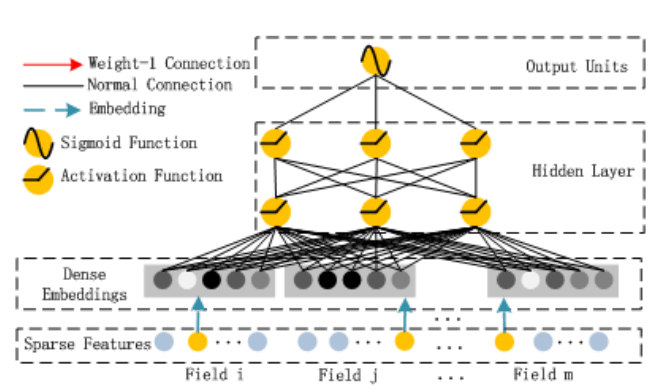
Deep部分は、より複雑な特徴間の相互作用を学習するためのフィードフォワードニューラルネットワークです。その処理フローは以下の通りです:
-
入力層(a₀):
- すべての密な埋め込みベクトルを横方向に連結
- これにより、特徴間の高次の相互作用を学習するための基礎を形成
-
隠れ層:
- 複数の層を通じて非線形変換を適用
- 各層で特徴の抽象化レベルを段階的に高める
- 最終的に1次元の出力に変換(FM部分との統合のため)
Deep部分の数学的表現:


Output Units(出力層)
出力層では、FM層とDeep層からの情報を統合して最終的な予測を生成します。具体的には:
- FM層とHidden層の出力を結合
- 低次と高次の特徴相互作用を融合
- シグモイド関数による非線形変換
- 最終的な確率値の出力
この過程は以下の式で表現されます:
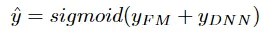
実践効果
DeepFMのCTR(クリック率)予測タスクにおけるパフォーマンスを、他の推薦アルゴリズムと比較した実験結果が以下の図に示されています:
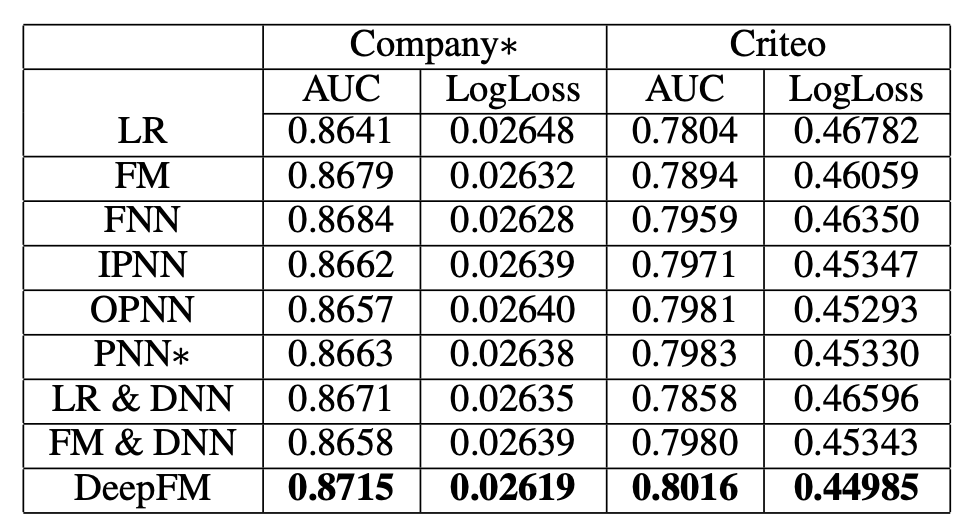
この実験結果からは、DeepFMが従来手法と比較して優れた予測精度を実現していることが分かります。この成功は、低次元と高次元の特徴相互作用を効果的に組み合わせたアーキテクチャによるものと考えられます。
まとめ
最後に、DeepFMとWide & Deepモデルの比較を通じて、DeepFMの特徴を整理しましょう。
共通点:
両モデルとも、線形モデルとディープニューラルネットワークを組み合わせることで、異なる特徴表現能力を統合しています。これにより、単一のアプローチでは捉えきれない複雑なパターンの学習を可能にしています。
相違点:
-
特徴共有の方式:
- DeepFMは両コンポーネント間で入力特徴を共有します。ただし、Wide側ではスパースな入力を、Deep側では密な入力を使用します。
- Wide & Deepは各コンポーネントが独立した入力を持ちます。
-
特徴エンジニアリングの要件:
- DeepFMは人工的な特徴設計が不要で、エンドツーエンドでの学習が可能です。これにより、オンライン環境への展開が容易になっています。
- Wide & Deepは手動で設計した特徴を追加することでモデルの表現能力を向上させる必要があります。
このように、DeepFMは特徴学習の自動化と効率的な学習構造により、実用的で高性能なレコメンデーションモデルを実現しています。特に大規模なオンラインシステムにおいて、その利点が効果的に活かされることが期待されます。
データサイエンス君のAI教材シリーズ(未経験OK)
教材のターゲット層:
- 初心者: Pythonとデータ分析の基本を学びたい人
- 中級者: より高度な分析手法や機械学習を習得したい人
- レコメンド(推薦)エンジニア: レコメンデーションエンジンを作り、キャリアアップを目指したい人
AI領域に携わりたい方はぜひ!
datasciencekunのAI教材シリーズ
LINE公式アカウント
データサイエンス君のLINE公式アカウント友達募集中!
今登録すれば、下記の内容をプレゼントします!
- 特典資料:AI教材の一部を無料でお送りします!
- 専門家との相談:メッセージでデータサイエンス領域の不明点が相談できます!
一人で学ぶより、仲間と一緒に成長しませんか?
今すぐ友達登録して、データサイエンスの旅を始めましょう!
LINE公式アカウント:https://line.me/R/ti/p/@datasciencekun?from=page&accountId=datasciencekun

Discussion