レコメンドシステム—— Wide&Deep モデル
シリーズの目次
レコメンドシステムのシリーズをここにまとめています。
はじめに
本稿では、レコメンデーション分野において画期的な影響を与えた論文「Wide & Deep Learning for Recommender Systems」について詳しく解説します。この論文は、2016年にGoogle Play Storeのレコメンデーションチームによって発表されました。ディープラーニングが実用化され始めた黎明期において、レコメンデーションシステムのCTR(クリック率)予測にディープラーニングを効果的に応用した先駆的な研究として高く評価されています。この研究は、レコメンデーションシステムにおけるディープラーニング活用の成功事例として、現在も多くの実務者や研究者に参照されています。
論文のリンク:https://dl.acm.org/doi/pdf/10.1145/2988450.2988454
レコメンドシステムの概要
以下の図は、レコメンドシステムの基本的なアーキテクチャを示しています。
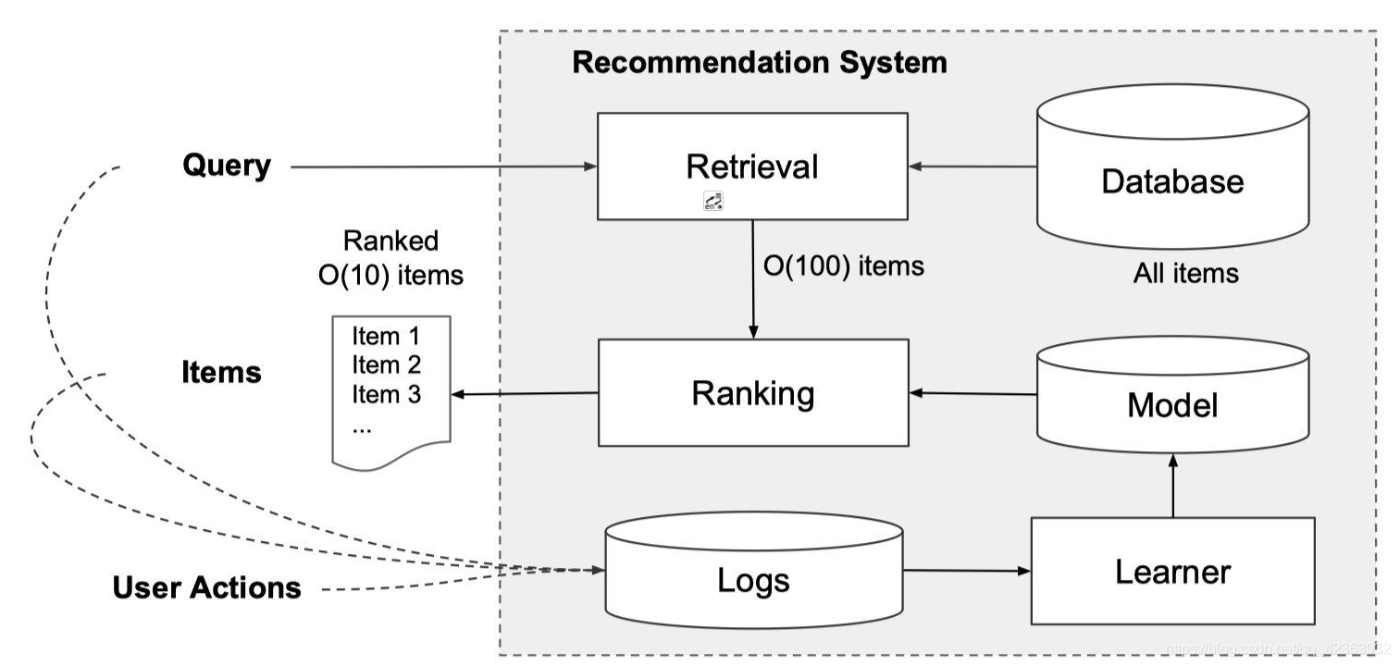
システムの処理フローは以下の通りです:
-
ユーザーがアプリケーションにアクセスすると、ユーザー情報とコンテキスト情報(利用環境、時間帯など)を含むリクエストが生成されます。
-
レコメンドシステムは、このリクエストに対して、ユーザーが最も興味を示す可能性が高い(クリックや購入につながりやすい)アイテムを選定し、提示する必要があります。
-
しかし、候補となるアイテムプールは数百万件に及ぶ場合があり、限られた応答時間(通常100ミリ秒)内にすべてのアイテムをスコアリングし、ランキング付けすることは技術的に困難です。
-
そこで、まず Retrieval(検索)フェーズで候補アイテムの絞り込みを行います。この処理は、機械学習モデルベースのアプローチやルールベースのアプローチなど、複数の手法を組み合わせて実施されます。
-
候補の絞り込みが完了した後、最終段階として Wide & Deep モデルを適用し、各アイテムの CTR を予測します。予測された CTR に基づいて最終的なランキングが決定され、ユーザーに提示されます。
本稿では、このプロセスの中でも特に Wide & Deep モデルの実装に焦点を当て、詳細な解説を行います。他の技術的要素については、本質的な理解を妨げない範囲で説明を省略します。
Wide&Deepとは
レコメンデーションシステムは、本質的にアイテムのランキングシステムとして捉えることができます。システムはユーザー情報および閲覧コンテキスト情報を入力として受け取り、優先順位付けされたアイテムシーケンスを出力します。このプロセスにおいて、記憶力(memorization)と汎化性(generalization)のバランスが重要な課題となります。
記憶性は、特定のアイテムペアや特徴の組み合わせを直接学習する能力を指します。特にユーザーの過去の行動履歴は非常に強力な予測因子となるため、記憶性の高いモデルは優れたパフォーマンスを発揮できます。しかし、これは同時にモデルの汎化性能の低下というリスクをもたらします。
一方、汎化性能は主に特徴間の相関関係と推移性に基づいています。特徴間の関係性には、特徴AやBが直接ラベルと関連する場合や、特徴A→特徴B→ラベルという間接的な関連性(推移性)が存在する場合があります。この特徴間の推移的な関係性を活用することで、訓練データには出現頻度の低い特徴の組み合わせに対しても適切な予測が可能となり、高い汎化性能を実現できます。
大規模なオンラインランキングシステムでは、ロジスティック回帰などの線形モデルが広く採用されています。これは、これらのモデルが以下の利点を持つためです:
- 実装の単純さ
- 優れたスケーラビリティ
- 高いパフォーマンス
- 解釈可能性の高さ
本稿では、記憶性と汎化性を効果的に両立させた Wide & Deep モデルについて解説します。このモデルの特徴は、線形モデルとニューラルネットワークを統合し、同時に学習できる点にあります。
Wide&Deepの原理
まずモデルの構造図を確認します。

この論文から引用した図は、左からWideモデル、Wide&Deepモデル、Deepモデルの構造を示しています。Wideモデルは線形モデル、Deepモデルはディープニューラルネットワークを表しています。
これら二つのコンポーネントについて、詳細に解説していきます。
Wide部分
Wide部分は、図の左側に示されているように、一般化された線形モデル
- y は予測結果
- x は d 次元の特徴ベクトル
x=[x_1, x_2 ... x_d] - w は d 次元の重みベクトル
w = [w_1, w_2 ... w_d] - b はバイアス項
この形式は基本的な線形回帰モデルと同じであり、多くの実務者にとって馴染み深い構造です。
Deep部分
Deep部分は図の右側に示されているフィードフォワード型ニューラルネットワークです。
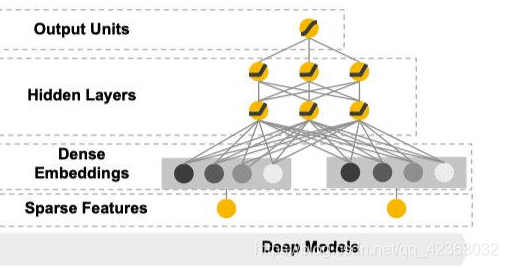
この構造から以下の重要な特徴が読み取れます:
- 入力層ではスパースな特徴量がマルチホット配列として受け取られます。
- ニューラルネットワークの第1層で、これらの入力は低次元の埋め込み(embedding)に変換されます。
- この埋め込み表現はネットワーク自体によって学習されます。
- このモジュールは主に以下のようなカテゴリカル特徴を処理するように設計されています:
- アイテムのカテゴリ
- ユーザーの属性情報(性別など)
従来のone-hot encodingと比較して、embeddingによる表現には以下の利点があります:
- 離散変数をより豊かな情報を持つベクトルとして表現可能
- 表現自体をモデルが学習することによる汎化性能の向上
- ディープニューラルネットワークにおける標準的かつ効果的なアプローチ
Wide&Deepの合併
Wide部分とDeep部分の統合は、図の中央に示されているように重み付けによって実現されます。
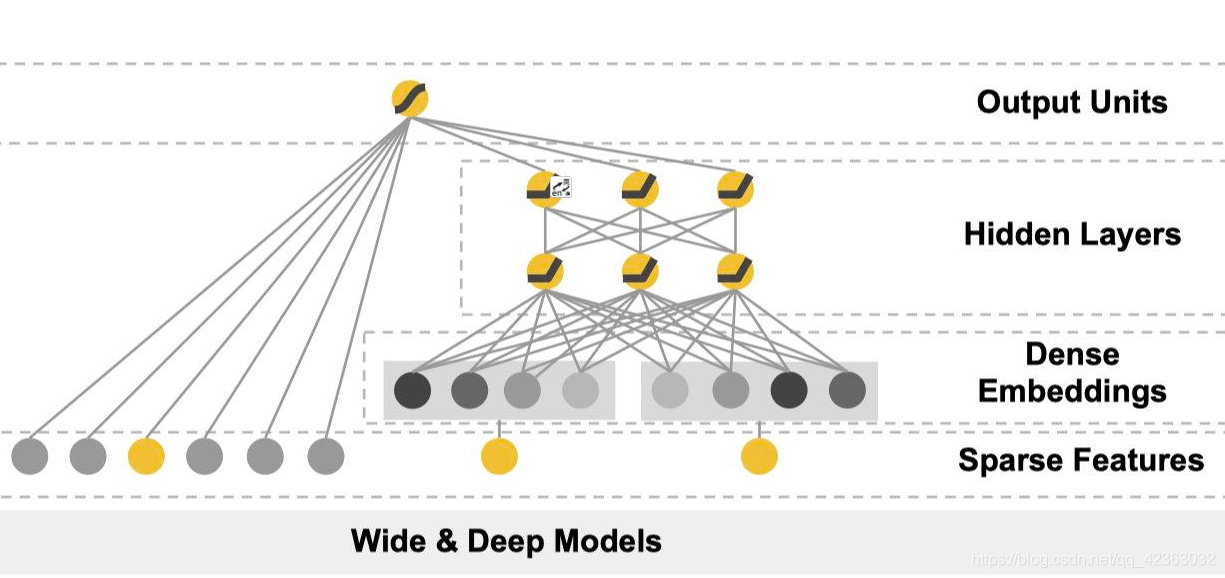
この統合には以下の特徴があります:
- 最終出力層では、sigmoidまたは線形活性化関数を持つ単純な線形結合器が使用されます。
- 各サブモデルが独立したパラメータ空間を持つことで、より効果的な学習が可能になります。
- 線形部分とディープラーニング部分の分離により:
- 各モデルの短所を相互に補完
- より優れた予測性能を実現
- 人為的なパラメータ増加を回避
モデルの学習
レコメンデーションシステムのデータパイプラインは、以下の3つの主要なフェーズで構成されています:
- データ生産(Data Generation)
- モデルトレーニング(Model Training)
- モデルサービング(Model Serving)
以下の図は、これらのフェーズを統合的に示しています:
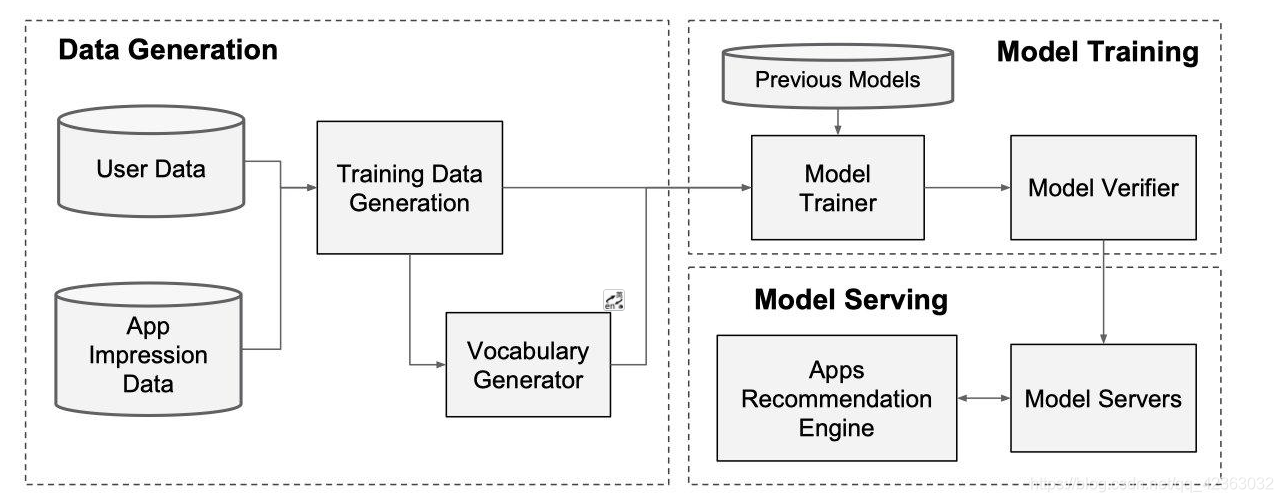
データ生産
データ生産フェーズでは、以下のプロセスが実行されます:
-
サンプリング:
- 一定期間にユーザーに表示されたアイテムをサンプルとして収集
- ユーザーの行動に基づくラベル付け(購入/クリック:1、非アクション:0)
-
特徴量エンジニアリング:
- カテゴリカル特徴の数値ID変換
例)ジャンル:エンターテインメント→1、フォト→2
価格帯:有料→0、無料→1 - 数値特徴の正規化([0,1]の範囲にスケーリング)
- カテゴリカル特徴の数値ID変換
トレーニング
モデルの学習構造は論文中で以下のように図示されています:
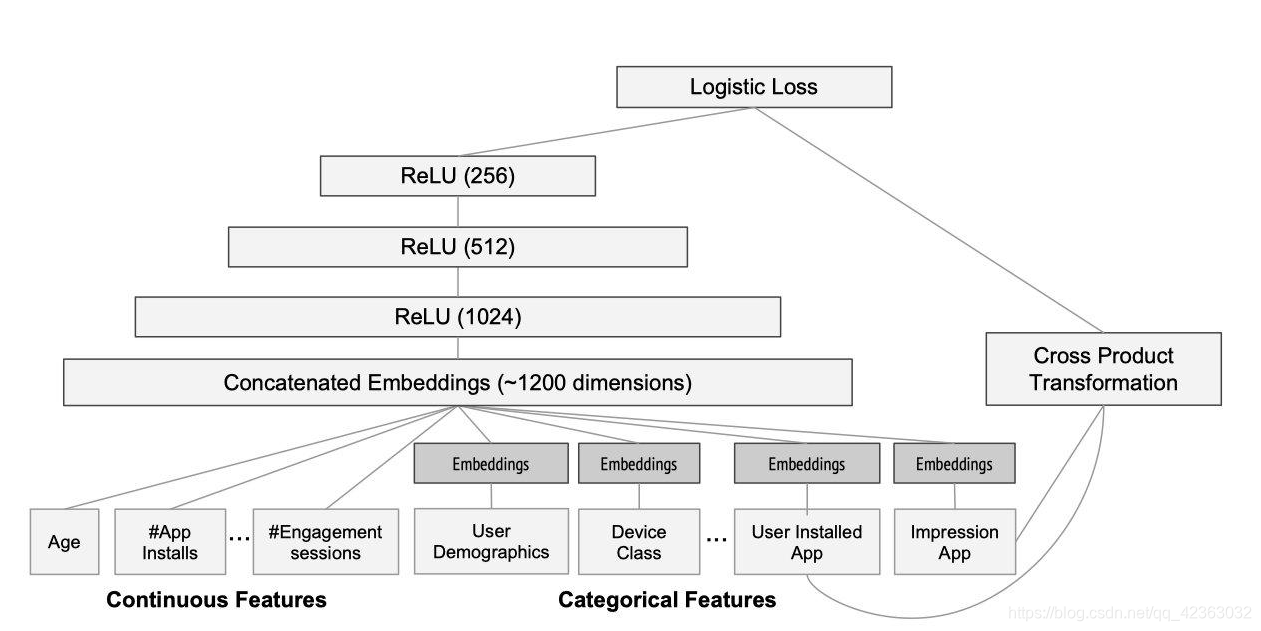
モデルは2種類の特徴を処理します:
-
連続的特徴(左側):
- ユーザーの年齢
- インストール済みアプリ数
- その他の数値データ
-
カテゴリカル特徴(右側):
- デバイス情報
- インストール済みアプリの種類
- その他の離散データ
処理フロー:
- カテゴリカル特徴は32次元のembedding vectorに変換
- 連続的特徴と結合してニューラルネットワークに入力
- 統合的な学習プロセスの実行
モデルサービング
実運用フェーズでは、以下のワークフローで推論を実行します:
-
リクエスト処理:
- Retrievalシステムから候補アイテムの取得
- ユーザー特徴の収集
-
スコアリング:
- 各候補アイテムに対する予測スコアの計算
- スコアに基づく順位付け
-
結果返却:
- TensorFlowやPyTorchを使用した高速推論
- 100ミリ秒以内のレスポンス時間を実現
まとめ
本稿では、記憶性と汎化性を効果的に組み合わせたWide & Deepランキングモデルについて、その理論的背景から実装上の詳細まで解説しました。
データサイエンス君のAI教材シリーズ(未経験OK)
教材のターゲット層:
- 初心者: Pythonとデータ分析の基本を学びたい人
- 中級者: より高度な分析手法や機械学習を習得したい人
- レコメンド(推薦)エンジニア: レコメンデーションエンジンを作り、キャリアアップを目指したい人
AI領域に携わりたい方はぜひ!
datasciencekunのAI教材シリーズ
LINE公式アカウント
データサイエンス君のLINE公式アカウント友達募集中!
今登録すれば、下記の内容をプレゼントします!
- 特典資料:AI教材の一部を無料でお送りします!
- 専門家との相談:メッセージでデータサイエンス領域の不明点が相談できます!
一人で学ぶより、仲間と一緒に成長しませんか?
今すぐ友達登録して、データサイエンスの旅を始めましょう!
LINE公式アカウント:https://line.me/R/ti/p/@datasciencekun?from=page&accountId=datasciencekun

Discussion