初めに
近年、企業における生成AIの導入が加速しています。しかし、ChatGPTのような大規模言語モデル(LLM)をそのまま利用するだけでは、企業固有の専門用語や社内文書に基づいた正確な回答を得ることが難しいという課題があります。
そこで注目されているのが「RAG(Retrieval-Augmented Generation)」というアプローチです。
RAGでは、社内の信頼できる情報源やナレッジを検索・抽出し、それをLLMに与えて回答を生成することで、社内のナレッジに基づいた応答を実現することが可能です。
このようなRAGパターンを実装する上で避けて通れない処理が、社内の情報源やナレッジとなるドキュメントを検索・抽出可能にするチャンキングという操作です。
チャンキングの手法は様々ありますが、Doclingではドキュメントの構造を理解したチャンキングを行うことができます。
本記事では、そんな構造を理解したチャンキングを可能にし、RAGによる回答品質の向上に寄与するドキュメント変換ツール「Docling」を紹介します。
Doclingとは
Doclingとは、スイスのIBM Researchが開発した、様々な形式(PDF, DOCX, PPTX, XLSX, HTML, WAV, MP3,PNG...)のドキュメントを統一された構造化表現(MarkdownやJSON形式)にできるPythonパッケージです。2024年7月にオープンソース化され、GitHubの月間トレンドリポジトリで10,000以上のスターを獲得するなど、AI開発者コミュニティの中で大きく注目を集めました。
最近では、ドキュメント変換ツールとして様々な方法が展開されていますが、代表的なものは、GPT-4oやClaudeなどのように、ドキュメント全体を画像としてVLMモデルに処理させ、直接マークアップに変換させるものがあります。これらはハルシネーションのリスクがあり、ドキュメントに全く関係の無い情報が含まれる可能性や、計算リソースの必要性からコストがかかるデメリットがあります。
しかし、Doclingはすべてのテキストをプログラムによって抽出するか、OCRによって転写されるので、ハルシネーションのリスクはありません。また、Doclingは自己完結型のPythonライブラリとして設計されており、リモートでの大量の計算が必要なSaaSサービスとは異なり、ローカルで簡単に実行することができます。さらに、MITライセンスのOSSなので自由に商用利用することができます。
Doclingのアーキテクチャ
本章では、arxivに公開されたDoclingに関する論文「Docling: An Efficient Open-Source Toolkit for AI-driven Document Conversion」を基に、Doclingのアーキテクチャについて説明します。
Doclingのアーキテクチャは以下の図で表されます。

出典:「Docling: An Efficient Open-Source Toolkit for AI-driven Document Conversion」
Doclingは処理対象のドキュメントのファイル形式を基に、処理パイプラインを選択します。
図の上段は、PDF Pipelineを表し、PDFファイルと画像ファイルを処理の流れを表しています。
図の下段は、Simple Pipelineを表し、マークアップやMS Office系のドキュメントの処理の流れを表しています。(MS Office系ファイルはZIP展開して中身を見ると、マークアップで情報を管理しているので、マークアップの一つといえます。)
Doclingは処理を行うファイル形式によって2つのパイプラインのどちらで処理させるかを判断します。
PDF Pipeline
PDF Pipelineは機能が豊富で、Doclingの醍醐味といえるPipelineです。
PDF Pipelineはざっくりと以下のような流れで処理が行われます。
まず、PDFファイルは、PDFバックエンドというコンポーネントによって処理され、PDF上の文章は文字列コンテンツとして取得され、ページ全体をビットマップ画像にレンダリングされます。
画像形式のファイルの場合は、解析済みの画像としてパイプラインを通過します。
次に、パイプラインを通過してきた画像は、Layout Analysis という処理によって、文章や画像、テーブルの位置を幾何学的に把握されます。(この Layout Analysis では、人間がアノテーションを付けたデータセットを用いて訓練された、DocLayNet と呼ばれるドキュメントレイアウト分析のためのオブジェクト検出器が用いられています。)
その後、Layout Analysis によってテーブルと判断されたオブジェクトは Table Structure Recognition と呼ばれる処理によって、テーブル構造が解析されます。(内部的にはTableFormerモデルと呼ばれる、テーブル構造復元のためのビジョントランスフォーマーモデルによって、与えられたテーブルの行と列の構造を予測し、どのテーブルセルが列ヘッダー、行ヘッダー、またはテーブルボディに属するかを解析します。)
このように解析されたデータは、最終的にDoclingDocumentと呼ばれる表現に統一されます。
PDFパイプラインでは、OCRオプションを選択することが可能です。OCRオプションでは、サードパーティのOCRライブラリを自由に選択し、PDF上の画像からコンテンツを抽出することができます。
Simple Pipeline
Simple Pipelineはマークアップ言語によって記述されたドキュメントを処理することができるパイプラインです。処理対象のファイル形式は、PDF, DOCX, PPTX, XLSX, HTML, CSV, MDなどがあります。これらのファイルは、マークアップ言語によって記述され、文書の構造的な意味合い(ヘッダーやリストなど)は明らかなので、PDF PipelineのようなLayout Analysisなどは行われず、ファイル形式に応じたバックエンドを経て、直接DoclingDocument形式に変換されます。
執筆時のDoclingの最新バージョン「2.37.0」では、OCRオプションを選択することはできず、今後の開発が期待されます。
DoclingDocument
DoclingDocumentとは、各パイプラインが実行されることによって最終的に得られる統一された表現です。これには、テキスト、テーブル、リストなど、様々なドキュメント要素がドキュメント構造と共に保存されています。DoclingDocumentは、Pydanticデータモデルとして実装されており、ソースドキュメントの形式に関わらず、ドキュメントコンテンツを統一された方法で表現することを可能にします。また、DoclingDocumentクラスは、様々な形式にエクスポートするAPIを定義しており、このDoclingDocument形式をMarkdown形式に変換したり、JSONにシリアライズすることが可能です。
さらに、チャンカークラスにDoclingDocument形式を渡すことによって、チャンクを生成することができます。
各入力ファイル形式と出力結果
ここでは、代表的なファイル形式に対するDoclingの処理例と、実際にチャンキングを適用した記事をご紹介します。
これらの記事では、文章、表、画像、図形を含む日本語で記述されたドキュメントを実際にDoclingの処理にかけ、出力結果を観察しています。
DoclingでPDFをOCR変換してみた - 日本語文書での精度比較
この記事では、日本語のPDFファイルをDoclingを用いてMarkdownに変換処理を行った結果のまとめと、PDF Pipeline オプションを解説をしています。
MS Office
DoclingでOffice文書から情報の読み取りを行う(Word・Excel・PowerPoint)
この記事では、MS Office文書をDoclingを用いてMarkdownに変換処理を行った結果をまとめています。
Simple Pipelineでは選択できるオプションは少なく、OCRも使用できません。
Hybrit Chunker
DoclingのHybridChunkerの調査
この記事では、PDFをDoclingDocumentに変換した後に、DoclingのChunkクラスに渡すことでChunkに変換しています。
ドキュメント構造をもとにChunkが行われていることが分かります。
まとめ
ご紹介したの記事の内容を以下の表にまとめました。(詳細な結果は各記事を参照してください)
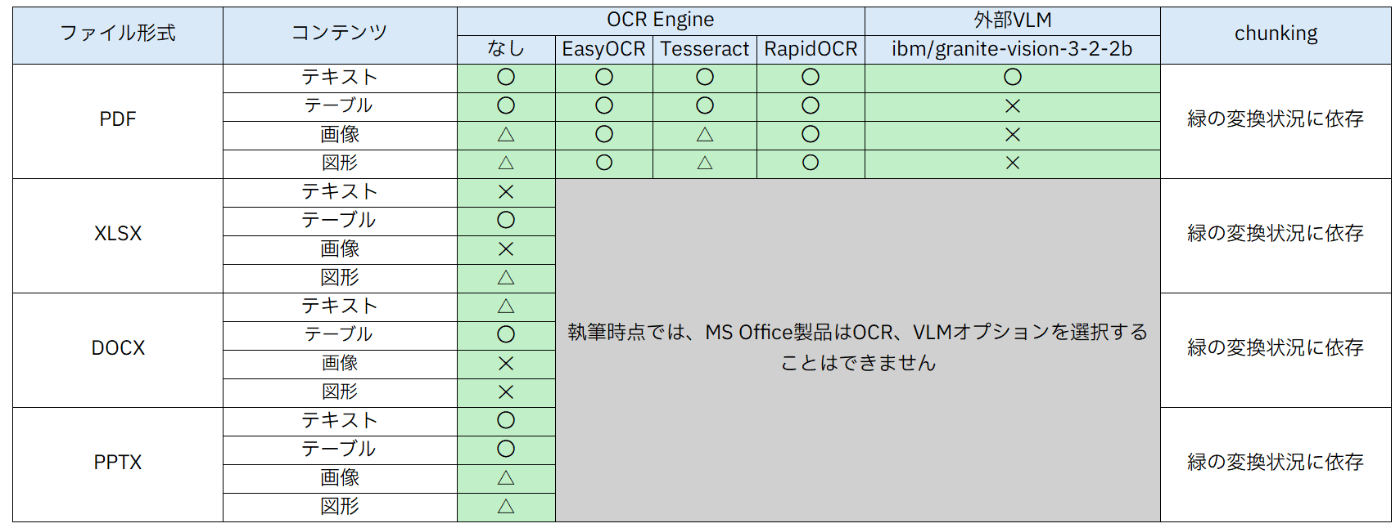
〇 … ロスなく出力可能
△ … 出力されるが期待通りではない
✕ … ロスあり
MS Office製品に対しては、選択できるオプションが少なく、出力は期待通りに行われないものが多いです。これに対して、PDFに関しては、OCRエンジンなどを使用することができ、OCRエンジンによっては、期待通りに出力さることが多いです。
PDFの変換について、画像は基本的に正確に認識されますが、テーブルを画像にしたものを取り込もうとした場合に、期待通りに出力されないことがあります。
最後に
本記事では、生成AIの回答精度を高めるために欠かせないRAGのチャンキング処理の選択肢の一つとなる、文書構造を理解した変換を実現するツール「Docling」を紹介しました。
筆者の所感ですが、PDFの処理はオプションが豊富で、出力結果も満足できますが、MS Office 製品の出力結果はロスの存在や期待通りに出力されないことがあり、さらなる機能開発に期待したいところです。
読んでいただき、ありがとうございました。
Doclingを活用した、より良いAI活用の第一歩になれば幸いです。
参考文献
Discussion