1. はじめに
PDFファイルから要素を抽出する作業は、多くの開発者や研究者が直面する課題です。特に、画像やテーブルの抽出といった非テキスト系の処理には多くの困難が伴います。最近、IBM Researchが開発したオープンソースツール「Docling」人気が高まっています。DoclingはPDFだけでなく、Word、PowerPoint、画像など様々な形式の文書を統一的に処理できる点が特徴的です。
本記事では、Doclingを使って実際に日本語PDFをOCR変換し、Doclingがサポートされている3つのOCRエンジン(EasyOCR、Tesseract、RapidOCR)のコンテンツ別精度を比較してみました。PDF処理ツールを探している方や、Doclingを使って日本語PDFをMarkDownに変換してみたい方の参考になれば幸いです。
2. Doclingとは
DoclingはIBM Researchが開発した、文書変換のためのオープンソースライブラリです。2024年にリリースされ、以下のような特徴を持っています:
- 多様な入力形式のサポート: PDF、DOCX、PPTX、XLSX、画像(PNG、JPG)、HTMLなど
- 構造化された出力: Markdown、JSONなど、後処理しやすい形式で出力
- 高度なレイアウト解析: テーブル、画像、段落などの文書構造を保持
- OCR対応: スキャン済みのPDFおよび画像ファイルに対して、包括的なOCRサポートを提供
3. DoclingのPDF処理
3.1 PDF Pipeline

Doclingのパイプラインと利用モデルの概要
出典: Docling: An Efficient Open-Source Toolkit for AI-driven Document Conversion(https://arxiv.org/html/2501.17887v1)
画像が示すように、Doclingは、PDFや画像ベースのファイル、またはMicrosoft Officeなどのテキストベースのファイルを処理する際に、それぞれ異なるパイプライン設定を使用しています。
PDF形式のドキュメントを処理する際には、OCR機能を利用して内容を解析することが可能です。各ページに含まれる要素のレイアウトおよび表の構造を分析し、「Docling Document」と呼ばれる中間形式を生成します。その後、提供されている関数を使うことで、MarkdownやJSONなどの構造化データの形式へ簡単に変換することが可能です。
実際に、コンテンツ別の抽出は以下のようになります:
| コンテンツ | 抽出形式 |
|---|---|
| テキスト領域 | 直接抽出またはOCR |
| 画像領域 | Base64エンコードまたは外部ファイルとして保存 |
| 表領域 | 構造を保持したまま抽出 |
3.2 OCRエンジン
OCRとは、画像やスキャンした書類に含まれる文字をコンピューターが読み取り、編集可能なテキストデータに変換する技術です。この技術により、紙媒体の情報を手入力することなく、効率的にデジタル化して活用できます。Doclingでは、以下のOCRエンジンをサポートしています。
- EasyOCR
- Tesseract
- Tesseract CLI
- OcrMac
- RapidOCR
- OnnxTR
今回は、以下の3種類のOCRエンジンについて検証を行います。主な目的は、各エンジンを用いて日本語文書を処理した際の認識精度を比較・確認することです。ちなみに、DoclingはデフォルトでEasyOCRを使用しているようです。
| OCRエンジン | 特徴 | 日本語対応 | GPU使用 |
|---|---|---|---|
| EasyOCR | Deep Learning(Pytorch)ベース、80言語以上対応 | 〇 | 〇 |
| Tesseract | Google開発、C++ベース、100言語以上対応 | 〇 | 〇 |
| RapidOCR | ONNXRuntime, OpenVINO, PaddlePaddle および PyTorch ベース、軽量で高速なOCR | 〇 | 〇 (rapidocr_paddleを使用することが推奨) |
rapidocr_paddle パッケージは、PaddlePaddle フレームワークをベースとした推論エンジンであり、CPU と GPU の両方に対応しています。特に GPU 環境では、ONNXRuntime や OpenVINO よりも適しているため、GPU での使用が推奨されます。一方、CPU 環境では rapidocr_onnxruntime や rapidocr_openvino のほうが一般的です。PaddlePaddle の CPU 上での動作は比較的重いためです。
https://rapidai.github.io/RapidOCRDocs/install_usage/rapidocr_paddle/usage/
4. 検証準備
4.1 検証環境
- python: 3.12
- docling: v2.37.0
4.2 使用する資料
今回の検証では、EDINETの「書類閲覧 操作ガイド」を使用しました。ただ、このファイルは100ページを超えるため、全体を処理すると時間がかかりすぎてしまいます(筆者はCPUを使って処理する)。そのため、先頭の10ページを対象として処理・検証を行いました。この文書を選んだ理由は以下二点です:
- 公開されている日本語文書である
- テキスト、画像、表が混在している
その中に以下のようなコンテンツが含まれています。
- 書類閲覧 操作ガイド - テキストの例

- 書類閲覧 操作ガイド - テーブルの例

- 書類閲覧 操作ガイド - 画像の例

- 書類閲覧 操作ガイド - 図形の例
4.3 パイプラインオプション
Doclingのパイプラインオプションを使用すると、変換パイプライン中のモデル実行をカスタマイズできます。今回は主に以下のパイプラインオプションを使用します。
pipeline_options = PdfPipelineOptions()
pipeline_options.do_ocr = True
pipeline_options.do_table_structure = True
pipeline_options.table_structure_options.do_cell_matching = True
pipeline_options.table_structure_options.mode = TableFormerMode.ACCURATE
pipeline_options.images_scale = 2.0
# optional
pipeline_options.generate_page_images = True
pipeline_options.generate_picture_images = True
各オプションの解説
-
pipeline_options.do_ocr = True
OCR(光学的文字認識)機能を有効にします -
pipeline_options.do_table_structure = True
テーブルの構造解析を有効にします -
pipeline_options.table_structure_options.do_cell_matching = True
表のセルを認識する際に、視覚的な情報(レイアウト)に基づいてマッチングを行います。 -
pipeline_options.table_structure_options.mode = TableFormerMode.ACCURATE
表認識モデルを「高精度モード」に設定します -
pipeline_options.images_scale = 2.0
OCR処理の前に、抽出した画像の解像度を2倍に引き上げます。 -
pipeline_options.generate_page_images = True
PDFの各ページ全体の画像を生成して保存します。 -
pipeline_options.generate_picture_images = True
PDF文書内に埋め込まれている図を、個別の画像ファイルとして抽出して保存します。
5. 結果
5.1 OCRエンジン別結果まとめ
各OCRエンジンの性能に大きな差は見られなかったため、事前に各エンジンが異なるコンテンツに対して示した処理精度および処理速度(※主観あり)について整理しました。
| エンジン名 | テキスト、表、画像、テーブル精度 | 画像OCR精度 | 速度 |
|---|---|---|---|
| EasyOCR | ほぼ同じ結果 | ✖ | やや早い |
| Tesseract | ほぼ同じ結果 | ✖ | 一番早い |
| RapidOCR | ほぼ同じ結果 | △ | 一番遅い |
テキスト、表、画像、図形、そしてDoclingがOCR処理を必要と判断した画像について、それぞれの処理精度を検証しました。その結果、テキスト、表、画像および図形は、3つのエンジンによる変換結果に差は見られませんでした。具体的な結果の例については、5.2節「コンテンツ別結果のまとめ」をご参照ください。
一方、画像として保存されている表など、画像OCRが行われた結果については、3つのエンジンで変換結果に大きな違いが見られました。その結果、どのエンジンを使用しても満足のいく結果が得られないことが分かりました。以下にその例を示します。
画像OCRの例
ドキュメント内に画像形式で含まれている以下の表に対してOCR認識を行いましたが、精度的に良くないことが分かりました。
- 入力:

各エンジンの認識精度は以下のとおりです。
- EasyOCR結果:
| I@ | |
|------|----|
| | kl |
- Tesseract結果:
| | | 7 tes » |
|------------|-------------------------------------------------------------------|-----------------------|
| | RRLFMEANLET. MG, BRAS ACHRFMERDY) EF CARI FR 1 EBAK— AYR FI 2). « | IE LR, smn RIF 80 MFo |
| 7B |
- RapidOCR結果:
| 项目 | 明 | |
|--------------|--------------------------------------------------------------|-----------------|
| ①文字列 | 場合、半角各文字列区切(例:索文 字列1【半角一】索文字列2)。 | 必须 劝十80文字 |
| ④情報指定 | ④情報指定 | |
| | ()。 先頭「G」半角大文字力。 | 半角英数字 |
| 名称 | 名称力。 | |
| 特定有俩证券 | 「特定有券区分指定」 、特定有 | |
まとめると、3つのOCRエンジンはいずれも、画像内の表に含まれる内容の認識において十分な精度を発揮することができませんでした。
中でも、RapidOCRは一部の文字情報を保持できたものの、Tesseractは内容を英字として誤認識し、EasyOCRに至っては情報の大半を抽出できませんでした。
今回の変換対象となった画像は表で構成されています。そのうえで、画像の解像度が低かったり、コントラストが不鮮明であったりすると、OCRによるテーブル構造の正確な認識が困難になることが、主な課題だと思われます
5.2 コンテンツ別結果のまとめ
| コンテンツ | よがった点 | 問題点 |
|---|---|---|
| テキスト | - 基本的には正確に認識できる | - 改行はスペースに置き換えられる |
| テーブル | - 基本的には正確に認識できる | - ファイルの目次部分が表として認識される *1 - 表内の画像が、表の外に配置される *2 |
| 画像と図形 | - 基本的には正確に認識できる - imageは基本的にPictureとして認識される |
- 画像OCRの精度が良くない |
まとめるとこんな感じになります。以下では、良かった点と課題点(*1,*2)について、それぞれ説明いたします。
良かった点
テキスト、テーブル、画像、および図形は基本的に正しく認識されました。その結果は以下のとおりです。
テキスト
- 入力
- 出力
## EDINET を御利用いただくために
EDINET で開示書類等を閲覧するための前提知識として、一般的な Web ブラウザを使用 し、インターネットが御利用いただける方を対象としています。
また、 EDINET を御利用いただくためには、御利用いただいているコンピュータの事前 準備が必要です。事前準備の詳細は『 書類閲覧 利用環境 』を参照してください。
テーブル
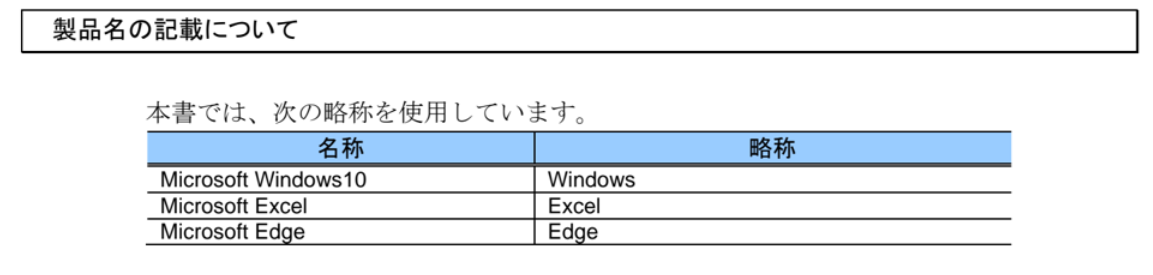
- 入力
- 出力
## 製品名の記載について
本書では、次の略称を使用しています。
| 名称 | 略称 |
|---------------------|---------|
| Microsoft Windows10 | Windows |
| Microsoft Excel | Excel |
| Microsoft Edge | Edge |
画像および図形
基本的に、PDF 内の画像や図形は正しく認識されます。これらの画像は、以下の 2 通りの形式で Markdown に保存することが可能です:
- 画像ファイルをファイル外に出力し、Markdown 内で参照する形式(Markdown with externally referenced pictures)
- 画像を Base64 形式でエンコードし、Markdown ファイル内に埋め込む形式(Markdown with embedded pictures)
保存形式は、save_as_markdownメソッドのImageRefModeパラメータを設定することで指定できます。
# externally referenced pictures
md_filename = output_dir / f"{doc_filename}-with-image-refs.md"
conv_res.document.save_as_markdown(md_filename, image_mode=ImageRefMode.REFERENCED)
# embedded pictures
md_filename = output_dir / f"{doc_filename}-with-images.md"
conv_res.document.save_as_markdown(md_filename, image_mode=ImageRefMode.EMBEDDED)
-
Markdown with externally referenced pictures
- 出力例
- 画像は別ファイルとして保存
- Markdownファイルのサイズが小さくなる
-
Markdown with embedded pictures
- 出力例
- 画像がBase64形式でMarkdown内に直接埋め込まれる
- ファイル管理が不要で、単一ファイルで完結
問題点
以下では、変換していく際に含まれるいくつかの課題点について解説します。
*1 目次が表として認識される
-
入力

-
出力
| 1 | 章 | EDINET の基本操作 | 1 |
|-------------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------------------------------|
| 1 EDINET への接続と終了 | 1 EDINET への接続と終了 | 1 EDINET への接続と終了 | 2 |
| | 1-1 EDINET への接続····································································································································· | 1-1 EDINET への接続····································································································································· | 3 |
| | 1-2 EDINET への接続の終了······················································································································ | 1-2 EDINET への接続の終了······················································································································ | 5 |
上記のとおり、今回使用したファイルに含まれる目次部分が表として認識されてしまいました。(目次内の項目配置が表の構造に類似していることが原因と推測します)
*2 表内の画像が、表の外に配置される
-
入力

-
出力

こちらの現象について:
- force Full page OCRというpipeline optionを指定しても同じ結果になります。
- GitHub Issue #285で対応中らしいので、今後改良される可能性あると考えられます。
5.3 そのほかの試し
今回は、DoclingのVlmPipelineを使用し、ibm/granite-vision-3-2-2bというモデルを検証してみました。
まず、VLM(視覚言語モデル)とは何かを説明すると、画像とテキストの両方を同時に扱えるマルチモーダルAIモデルです。画像を見てその内容を文章で説明したり、画像に関する質問に答えたりするなど、視覚情報と言語情報を統合した高度なタスクを実行できます。
素材として、同じく「書類閲覧・操作ガイド」を検証してみたが、その結果、正しく認識されたのはテキストのみであり、画像や表の認識精度は低いという結果となりました。
今後は、今回のOCRエンジンの検証と同様に、より多くのVLMモデルを用いた比較検証も行っていきたいと考えています。
6. 終わりに
本記事では、文書変換ツール「Docling」を使用し、日本語PDFに含まれるテキストや表、画像などをどの程度正確に抽出できるか、3つのOCRエンジン(EasyOCR、Tesseract、RapidOCR)で比較・検証を行いました。
テキストや構造化された表の抽出精度は高く、文書のレイアウトを維持できる点は非常に魅力的ですが、画像として保存された表のOCR精度は、どのエンジンを使ってもまだ大きな課題が残る結果となりました。
本記事が、PDF処理ツールを探している方や、Doclingを使って日本語PDFを構造化データに変換してみたい方の参考になれば幸いです。
Discussion