1. はじめに
Doclingは、PDF、Word、PowerPointといった多様なドキュメント形式から、テキストと構造情報を取得するOSSのライブラリです。多く分けると、2つの機能があります。
- ドキュメントを統一された表現(DoclingDocument)に変換する機能(下画像のDocumentConverter部分)
- 1の結果をchunk化する機能(下画像の右下部分)
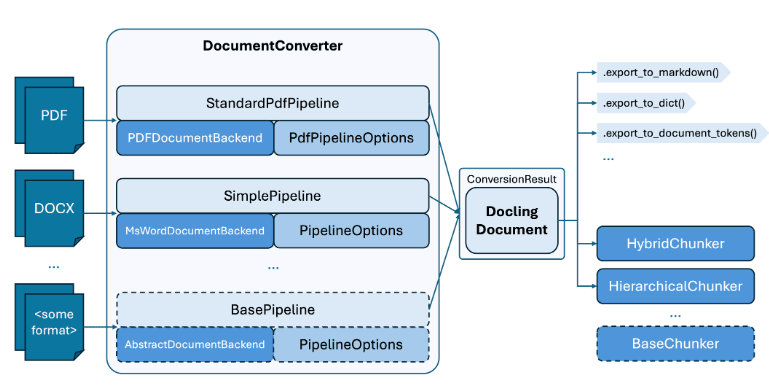
本記事では、2のchunking機能に焦点を当て、その基本的な使い方を解説します。
1に関しては、下記の記事に詳しく記載していただいているので、ご覧ください。
- 検証環境
- docling v2.37.0
- python 3.12
2. Doclingのchunking機能
Doclingは、主に2つのchunking機能があります。
-
HierarchicalChunker: ドキュメントの構造(見出し、段落、リスト、表など)に基づいてchunkingを行います。ドキュメントの論理的な区切りを維持するのに長けています。 -
HybridChunker:HierarchicalChunkerの構造ベースのアプローチに加え、トークン数でChunkを分割・統合するアプローチを取ります。RAGではchunkをベクトルデータベースに格納するため、一定のトークン数制限を考慮する必要があります。HybridChunkerは構造を保持しつつトークン数制限にも対応できるため、RAG用途に適しています。
3. 使用する資料とその変換
この記事では、政府CIOポータルのPDF資料を使用します。
なおこの記事では、PDFからDoclingDocumentへの変換部分の解説はいたしません。これらの記事を参照してください。 変換時には、以下のコードを実行しました。
PDFからDoclingDocumentへの変換コード
from pathlib import Path
from docling.datamodel.base_models import InputFormat
from docling.document_converter import DocumentConverter, PdfFormatOption
from docling.datamodel.pipeline_options import (
PdfPipelineOptions,
EasyOcrOptions
)
pipeline_options = PdfPipelineOptions()
pipeline_options.do_ocr = True
pipeline_options.images_scale = 2.0
pipeline_options.do_table_structure = True
pipeline_options.table_structure_options.do_cell_matching = True
pipeline_options.generate_picture_images = True
pipeline_options.generate_page_images = True
pipeline_options.ocr_options = EasyOcrOptions(lang=["ja"])
converter = DocumentConverter(
format_options={
InputFormat.PDF: PdfFormatOption(pipeline_options=pipeline_options)
}
)
pdf_path = "https://cio.go.jp/sites/default/files/uploads/documents/dp2021_11.pdf"
result = converter.convert(pdf_path)
doc = result.document
【入力PDF】

出典:ゼロトラストネットワークを実現するための政府職員のアカウントやアセットの管理(ディスカッションペーパー)
【出力Markdown】
## 要旨
ネットワークに対する攻撃の高度化や多様化が進む現在、セキュリティ境界に依存しな いセキュリティアーキテクチャの構築が必須である。そのために、ネットワーク全体で「ゼ ロトラストネットワーク」という考え方を取り入れ、多層的な防御により未知の攻撃も含め て対処できる仕組みにしていくことが望まれる。
ゼロトラストネットワークでは、存在するすべての'利用者や機器などの状態'を個別に 確認しながら、信頼できるものを判断して動作するため、ネットワーク全体として多層的な 防御の仕組みが実現できる。この仕組みの前提として、 '利用者や機器などの情報を信用で きるものにすること'が必要であり、その機能を実現するのが、政府職員のアカウントやア セットを管理するマスターディレクトリである。
本ディスカッションペーパーでは、新しいガバメントネットワークの構築における「政府 職員のアカウントやアセットの管理」を主な論点とし、ゼロトラストネットワークを実現す るための仕組みやその運用についての検討を示す。
本ディスカッションペーパーは、政府 CIO 補佐官等の有識者による検討内容 を取りまとめたもので、論点整理、意見・市場動向の情報収集を通じて、オー プンで活発な議論を喚起し、結果として議論の練度の向上を目的としていま す。そのため、ディスカッションペーパーの内容や意見は、掲載時期の検討内 容であり、執筆者個人に属しており、内閣官房 情報通信技術(IT)総合戦略 室、政府の公式見解を示すものではありません。
4. HybridChunkerの使用方法
HybridChunker を使ってchunkingを行い、中身を見ていきます。
4.1. HybridChunkerのパラメータ
HybridChunkerでは、以下のパラメータを設定できます。
- tokenizer
- テキストをtokenに分割するtokenzierを指定します。
- default:
HuggingFaceTokenizer.from_pretrained(model_name="sentence-transformers/all-MiniLM-L6-v2")- tokenizerのモデルはデフォルトで、
sentence-transformers/all-MiniLM-L6-v2を使用します。(日本語には対応していなさそう参考)
- tokenizerのモデルはデフォルトで、
- chunkをベクトル化するのであれば、使用する埋め込みモデルを指定します。
- max_tokens
- 1chunkの最大Token数を指定します。
- default:
optional, by default derived from tokenizer for HF casと記載されているので、モデルのmax_tokenがセットされます。参考
- merge_peers
- DoclingDocument内で分割されているアイテム(textやlist、imageなど)が、同じセクション内のものであれば、同じchunkに統合するか選択します。
- default:
True
- serializer_provider
- 表や画像などの説明文を生成するカスタムのクラスを指定します。この記事では扱いません。
4.2. HybridChunkerによるchunking
3章で変換したドキュメントをChunkingします。今回は、Tokenizerとして日本語対応のpfnet/plamo-embedding-1bを使用します。
from docling.chunking import HybridChunker
from transformers import AutoTokenizer
EMBED_MODEL_ID = "pfnet/plamo-embedding-1b"
MAX_TOKENS = 4096
tokenizer = AutoTokenizer.from_pretrained(EMBED_MODEL_ID, trust_remote_code=True)
chunker = HybridChunker(
tokenizer=tokenizer,
max_tokens=MAX_TOKENS,
merge_peers=True
)
chunk_iter = chunker.chunk(dl_doc=doc)
4.3. chunk内容の確認
HybridChunker が生成したchunkからは、メタデータと2種類のテキスト表現があります。
-
chunk.meta: スキーマやchunk内のDoclingDocumentの情報、chunkが属するセクションの見出しなどのメタデータです。 -
chunk.text: chunk本体のテキストです。 -
chunker.contextualize(chunk): chunk本体のテキストに、そのchunkが属するセクションの見出しなどを付与したテキストです。
両者の違いを、実際の出力で確認してみましょう。
HybridChunker が生成したchunk(chunk_iter)は、複数のBaseChunkを持つデータです。
for i, chunk in enumerate(chunk_iter):
print(f"\n\n--- chunk.text{i} ---")
print(chunk.text)
print(f"\n--- chunk.metadata{i} ---")
print(chunk.meta)
print(f"\n--- chunker.contextualize(chunk) {i}---")
enriched_text = chunker.contextualize(chunk=chunk)
print(enriched_text)
出力例:先頭を抜粋
--- chunk.text0 ---
2021 年 8 月
待鳥博志 1 、菅原保仁 1 、田丸健三郎 2
--- chunk.metadata0 ---
schema_name='docling_core.transforms.chunker.DocMeta' version='1.0.0' doc_items=[DocItem(self_ref='#/texts/3', parent=RefItem(cref='#/body'), children=[], content_layer=<ContentLayer.BODY: 'body'>, label=<DocItemLabel.TEXT: 'text'>, prov=[ProvenanceItem(page_no=1, bbox=BoundingBox(l=270.12, t=633.6410146484375, r=325.32, b=623.0810146484375, coord_origin=<CoordOrigin.BOTTOMLEFT: 'BOTTOMLEFT'>), charspan=(0, 10))]), DocItem(self_ref='#/texts/4', parent=RefItem(cref='#/groups/0'), children=[], content_layer=<ContentLayer.BODY: 'body'>, label=<DocItemLabel.TEXT: 'text'>, prov=[ProvenanceItem(page_no=1, bbox=BoundingBox(l=212.64, t=597.6410146484375, r=387.84, b=587.0810146484375, coord_origin=<CoordOrigin.BOTTOMLEFT: 'BOTTOMLEFT'>), charspan=(0, 23))])] headings=['ゼロトラストネットワークを実現するための 政府職員のアカウントやアセットの管理 (ディスカッションペーパー)'] captions=None origin=DocumentOrigin(mimetype='application/pdf', binary_hash=3960217920056606063, filename='dp2021_11.pdf', uri=None)
--- chunker.contextualize(chunk) 0---
ゼロトラストネットワークを実現するための 政府職員のアカウントやアセットの管理 (ディスカッションペーパー)
2021 年 8 月
待鳥博志 1 、菅原保仁 1 、田丸健三郎 2
--- chunk.text1 ---
ネットワークに対する攻撃の高度化や多様化が進む現在、セキュリティ境界に依存しな いセキュリティアーキテクチャの構築が必須である。そのために、ネットワーク全体で「ゼ ロトラストネットワーク」という考え方を取り入れ、多層的な防御により未知の攻撃も含め て対処できる仕組みにしていくことが望まれる。
ゼロトラストネットワークでは、存在するすべての'利用者や機器などの状態'を個別に 確認しながら、信頼できるものを判断して動作するため、ネットワーク全体として多層的な 防御の仕組みが実現できる。この仕組みの前提として、 '利用者や機器などの情報を信用で きるものにすること'が必要であり、その機能を実現するのが、政府職員のアカウントやア セットを管理するマスターディレクトリである。
本ディスカッションペーパーでは、新しいガバメントネットワークの構築における「政府 職員のアカウントやアセットの管理」を主な論点とし、ゼロトラストネットワークを実現す るための仕組みやその運用についての検討を示す。
本ディスカッションペーパーは、政府 CIO 補佐官等の有識者による検討内容 を取りまとめたもので、論点整理、意見・市場動向の情報収集を通じて、オー プンで活発な議論を喚起し、結果として議論の練度の向上を目的としていま す。そのため、ディスカッションペーパーの内容や意見は、掲載時期の検討内 容であり、執筆者個人に属しており、内閣官房 情報通信技術(IT)総合戦略 室、政府の公式見解を示すものではありません。
1 内閣官房政府CIO補佐官
2 内閣官房情報通信技術(IT)総合戦略室 プロジェクトマネージャー
--- chunk.metadata1 ---
schema_name='docling_core.transforms.chunker.DocMeta' version='1.0.0' doc_items=[DocItem(self_ref='#/texts/6', parent=RefItem(cref='#/body'), children=[], content_layer=<ContentLayer.BODY: 'body'>, label=<DocItemLabel.TEXT: 'text'>, prov=[ProvenanceItem(page_no=1, bbox=BoundingBox(l=85.08, t=507.64101464843753, r=510.48, b=443.08101464843753, coord_origin=<CoordOrigin.BOTTOMLEFT: 'BOTTOMLEFT'>), charspan=(0, 146))]), DocItem(self_ref='#/texts/7', parent=RefItem(cref='#/body'), children=[], content_layer=<ContentLayer.BODY: 'body'>, label=<DocItemLabel.TEXT: 'text'>, prov=[ProvenanceItem(page_no=1, bbox=BoundingBox(l=85.08, t=435.64101464843753, r=510.48, b=353.08101464843753, coord_origin=<CoordOrigin.BOTTOMLEFT: 'BOTTOMLEFT'>), charspan=(0, 190))]), DocItem(self_ref='#/texts/8', parent=RefItem(cref='#/body'), children=[], content_layer=<ContentLayer.BODY: 'body'>, label=<DocItemLabel.TEXT: 'text'>, prov=[ProvenanceItem(page_no=1, bbox=BoundingBox(l=85.08, t=345.64101464843753, r=510.48, b=299.08101464843753, coord_origin=<CoordOrigin.BOTTOMLEFT: 'BOTTOMLEFT'>), charspan=(0, 106))]), DocItem(self_ref='#/texts/9', parent=RefItem(cref='#/body'), children=[], content_layer=<ContentLayer.BODY: 'body'>, label=<DocItemLabel.TEXT: 'text'>, prov=[ProvenanceItem(page_no=1, bbox=BoundingBox(l=90.72, t=273.9180146484375, r=504.6, b=171.91801464843752, coord_origin=<CoordOrigin.BOTTOMLEFT: 'BOTTOMLEFT'>), charspan=(0, 205))]), DocItem(self_ref='#/texts/10', parent=RefItem(cref='#/body'), children=[], content_layer=<ContentLayer.BODY: 'body'>, label=<DocItemLabel.FOOTNOTE: 'footnote'>, prov=[ProvenanceItem(page_no=1, bbox=BoundingBox(l=85.08, t=117.9090146484375, r=210.6, b=105.19801464843749, coord_origin=<CoordOrigin.BOTTOMLEFT: 'BOTTOMLEFT'>), charspan=(0, 15))]), DocItem(self_ref='#/texts/11', parent=RefItem(cref='#/body'), children=[], content_layer=<ContentLayer.BODY: 'body'>, label=<DocItemLabel.FOOTNOTE: 'footnote'>, prov=[ProvenanceItem(page_no=1, bbox=BoundingBox(l=85.08, t=102.42801464843751, r=405.48, b=89.71801464843747, coord_origin=<CoordOrigin.BOTTOMLEFT: 'BOTTOMLEFT'>), charspan=(0, 35))])] headings=['要旨'] captions=None origin=DocumentOrigin(mimetype='application/pdf', binary_hash=3960217920056606063, filename='dp2021_11.pdf', uri=None)
--- chunker.contextualize(chunk) 1---
要旨
ネットワークに対する攻撃の高度化や多様化が進む現在、セキュリティ境界に依存しな いセキュリティアーキテクチャの構築が必須である。そのために、ネットワーク全体で「ゼ ロトラストネットワーク」という考え方を取り入れ、多層的な防御により未知の攻撃も含め て対処できる仕組みにしていくことが望まれる。
ゼロトラストネットワークでは、存在するすべての'利用者や機器などの状態'を個別に 確認しながら、信頼できるものを判断して動作するため、ネットワーク全体として多層的な 防御の仕組みが実現できる。この仕組みの前提として、 '利用者や機器などの情報を信用で きるものにすること'が必要であり、その機能を実現するのが、政府職員のアカウントやア セットを管理するマスターディレクトリである。
本ディスカッションペーパーでは、新しいガバメントネットワークの構築における「政府 職員のアカウントやアセットの管理」を主な論点とし、ゼロトラストネットワークを実現す るための仕組みやその運用についての検討を示す。
本ディスカッションペーパーは、政府 CIO 補佐官等の有識者による検討内容 を取りまとめたもので、論点整理、意見・市場動向の情報収集を通じて、オー プンで活発な議論を喚起し、結果として議論の練度の向上を目的としていま す。そのため、ディスカッションペーパーの内容や意見は、掲載時期の検討内 容であり、執筆者個人に属しており、内閣官房 情報通信技術(IT)総合戦略 室、政府の公式見解を示すものではありません。
1 内閣官房政府CIO補佐官
2 内閣官房情報通信技術(IT)総合戦略室 プロジェクトマネージャー
metadataの深堀(すこしニッチな話になるので、読み飛ばして頂いても構いません。)
chunk[1]のmetadataを、見やすいように整形しています。
schema_name='docling_core.transforms.chunker.DocMeta' version='1.0.0'
doc_items=[
DocItem(self_ref='#/texts/6', parent=RefItem(cref='#/body'), children=[], content_layer=<ContentLayer.BODY: 'body'>, label=<DocItemLabel.TEXT: 'text'>, prov=[ProvenanceItem(page_no=1, bbox=BoundingBox(l=85.08, t=507.64101464843753, r=510.48, b=443.08101464843753, coord_origin=<CoordOrigin.BOTTOMLEFT: 'BOTTOMLEFT'>), charspan=(0, 146))]),
DocItem(self_ref='#/texts/7', parent=RefItem(cref='#/body'), children=[], content_layer=<ContentLayer.BODY: 'body'>, label=<DocItemLabel.TEXT: 'text'>, prov=[ProvenanceItem(page_no=1, bbox=BoundingBox(l=85.08, t=435.64101464843753, r=510.48, b=353.08101464843753, coord_origin=<CoordOrigin.BOTTOMLEFT: 'BOTTOMLEFT'>), charspan=(0, 190))]), DocItem(self_ref='#/texts/8', parent=RefItem(cref='#/body'), children=[], content_layer=<ContentLayer.BODY: 'body'>, label=<DocItemLabel.TEXT: 'text'>, prov=[ProvenanceItem(page_no=1, bbox=BoundingBox(l=85.08, t=345.64101464843753, r=510.48, b=299.08101464843753, coord_origin=<CoordOrigin.BOTTOMLEFT: 'BOTTOMLEFT'>), charspan=(0, 106))]),
DocItem(self_ref='#/texts/9', parent=RefItem(cref='#/body'), children=[], content_layer=<ContentLayer.BODY: 'body'>, label=<DocItemLabel.TEXT: 'text'>, prov=[ProvenanceItem(page_no=1, bbox=BoundingBox(l=90.72, t=273.9180146484375, r=504.6, b=171.91801464843752, coord_origin=<CoordOrigin.BOTTOMLEFT: 'BOTTOMLEFT'>), charspan=(0, 205))]),
DocItem(self_ref='#/texts/10', parent=RefItem(cref='#/body'), children=[], content_layer=<ContentLayer.BODY: 'body'>, label=<DocItemLabel.FOOTNOTE: 'footnote'>, prov=[ProvenanceItem(page_no=1, bbox=BoundingBox(l=85.08, t=117.9090146484375, r=210.6, b=105.19801464843749, coord_origin=<CoordOrigin.BOTTOMLEFT: 'BOTTOMLEFT'>), charspan=(0, 15))]), DocItem(self_ref='#/texts/11', parent=RefItem(cref='#/body'), children=[], content_layer=<ContentLayer.BODY: 'body'>, label=<DocItemLabel.FOOTNOTE: 'footnote'>, prov=[ProvenanceItem(page_no=1, bbox=BoundingBox(l=85.08, t=102.42801464843751, r=405.48, b=89.71801464843747, coord_origin=<CoordOrigin.BOTTOMLEFT: 'BOTTOMLEFT'>), charspan=(0, 35))])
]
headings=['要旨']
captions=None
origin=DocumentOrigin(mimetype='application/pdf', binary_hash=3960217920056606063, filename='dp2021_11.pdf', uri=None)
メタデータは、主に以下の構成になっています。
- shema情報
-
schema_name,version
-
- Docling Documentの情報
doc_items- ここには、chunkの元となっているDoclingDocumentの情報があります。
- セクション情報
headings
- 元のドキュメントの情報
origin
chunkのメタデータとして様々な情報を持っています。特に、元のドキュメントやセクション情報などは、データソース(データリネージュ)として、管理しておくことで、RAGを使用したUserが、元の文章をさがしやすいようになります。このように、RAGでの回答の説明性を保証する上で、chunkのmetadataは使用できます。
Githubで記載されている通り、このメタデータをよりリッチなものにしていく計画があるようです。
Coming soon
📝 Metadata extraction, including title, authors, references & language
contextualize を使うことで、chunkがドキュメントのどの部分に位置するかの情報(この例ではchunker.contextualize(chunk) 1)が付与されます。
加えて、doc.metaを使用することでchunkのメタデータも保持することができそうです。活用方法としてはデータソースを示す際に、ファイルのみでなく、回答元の文章がどこのセクションに属しているかまで、Userに返すことができそうです。長い文章の場合は、データソースを探すときに活用できます。
5. まとめ
本記事では、Doclingの HybridChunker を用いたchunking方法について解説しました。
-
HybridChunkerは、ドキュメントの構造とトークン数の両方を考慮する。 -
chunker.contextualize()を使うことで、見出し情報を含むchunkを取得できる。
Doclingには、様々なドキュメントを変換し、chunkの作成やMarkdownファイルへの出力も可能です。様々なドキュメントを1つのツールで変換することも魅力的ですし、chunkを作成するための処理も容易に行えます。
まだまだ機能追加がありそうなので、今後が楽しみです。
Discussion