はじめに
はじめまして、株式会社D2C(以下D2C)で内定者アルバイトをしている大橋です。
今年の4月から就職予定のD2Cで、現在生成AIの調査を行っています。
今回はその調査結果を記事としてまとめる機会を頂きました。
記事は3つに分け、以下の内容で執筆します。
- GANと拡散モデルの調査
- Flowモデルの紹介
- 画像生成モデルの比較
この記事は、“3. 画像生成モデルの比較“についてです。
調査に至る背景と目的
前回と前々回の記事では、GAN、拡散モデルおよびFlowモデルに焦点を当て、それぞれのモデルの仕組みおよび利点と欠点について解説し、訓練した結果をまとめました。
この記事ではこれまで紹介してきたGAN、拡散モデルおよびFlowモデルの比較調査を行います。
調査内容
本記事では、画像生成モデルであるGAN、拡散モデルおよびFlowモデルについて、どのモデルが高品質で多様な画像を生成できるかという観点で比較をします。
評価指標としては、GANの評価指標としてよく使われる Inception Score(IS)、ISを改良した Frechet Inception Distance(FID)、StyleGAN2で潜在変数と画像の対応関係の滑らかさとして提案された Perceptual Path length(PPL) を使用しました。
GANおよび拡散モデルについての説明は、"1. GAN、拡散モデルの調査"、Flowモデルについては"2. Flowモデルの紹介"をご参照ください。
データセット
学習にはCifar-10データセットを利用しました。Cifar-10は画像認識を目的としたチュートリアルで使われるデータセットです。データセットは5万枚の訓練データと1万枚のテストデータ、合計6万枚から構成されます。各画像のサイズは

図1:Cifar-10データセットの内容
前処理
データセットの値は0から1をとるため、データセットの平均と分散を0.5と決めて正規化を行いました。
正規化によってデータセットの値0.5は0に、値の取りうる範囲は2倍になります。
生成モデルの生成結果
訓練パラメータ
| モデル | 学習率 | 学習率スケジュール | バッチサイズ | ステップサイズ |
|---|---|---|---|---|
| GAN | 生成器: 5e-5 識別器: 5e-6 |
- | 200 | - |
| 拡散モデル | 1e-3 | epoch < 1000: 1倍 1000 3000 5000 |
1000 | 1000 |
| Flowモデル | 1e-3 | epoch < 1000: 1倍 1000 3000 5000 |
1000 | 100 |
実装はpytorch、最適化手法はAdamを使用しました。
GANの学習率は他2つと比べて低く設定してあるため、
公平な比較とは言えませんが参考程度にご覧ください。
計算機環境
計算機環境はAWSのp3.2xlargeインスタンスを使用しました。
学習時間はGANで約3時間、拡散モデルおよびFlowモデルで約6時間でした。
| CPU | メモリ | GPU |
|---|---|---|
| Intel(R) Xeon(R) CPU E5-2686 v4 @ 2.30GHz x8 | 64GB | Tesla V100 16GB |
評価指標
Inception Score (IS)
ISは生成画像の品質と多様性を同時に評価する指標です。ISはInception-V3モデルという学習済み1000クラス分類モデルを使って評価を行います。生成された画像の品質が高い場合、Inception-V3モデルの予測はある1つのラベルのみ高く、他のラベルは低く出力されます。つまり、生成画像
評価式は以下のようになり、スコアが高いほど良いモデルであると言えます。
- torchmetrics.image.inceptionを使用
- torchvision.transforms.functional.resizeを使用してバイリニア法で
299\times 299
Frechet Inception Distance (FID)
FIDはリアル画像セットと生成画像セットの分布がどのくらい類似しているかを示す指標です。FIDはInception-v3モデルを使ってリアル画像セットと生成画像セットの埋め込み表現を計算し、それぞれの平均と共分散を比較し、その距離が小さいほど良いスコアということになります。
計算手順を以下に示します。
- リアル画像セットから抽出された特徴量の分布をガウス分布で近似する. 平均
m_r C_r - 生成画像セットから抽出された特徴量の分布をガウス分布で近似する。
m_g C_g - 以下の式で表されるFrechet Distanceを計算
- torchmetrics.image.fidを使用
- torchvision.transforms.functional.resizeを使用してバイリニア法で
299\times 299
Perceptual Path Length (PPL)
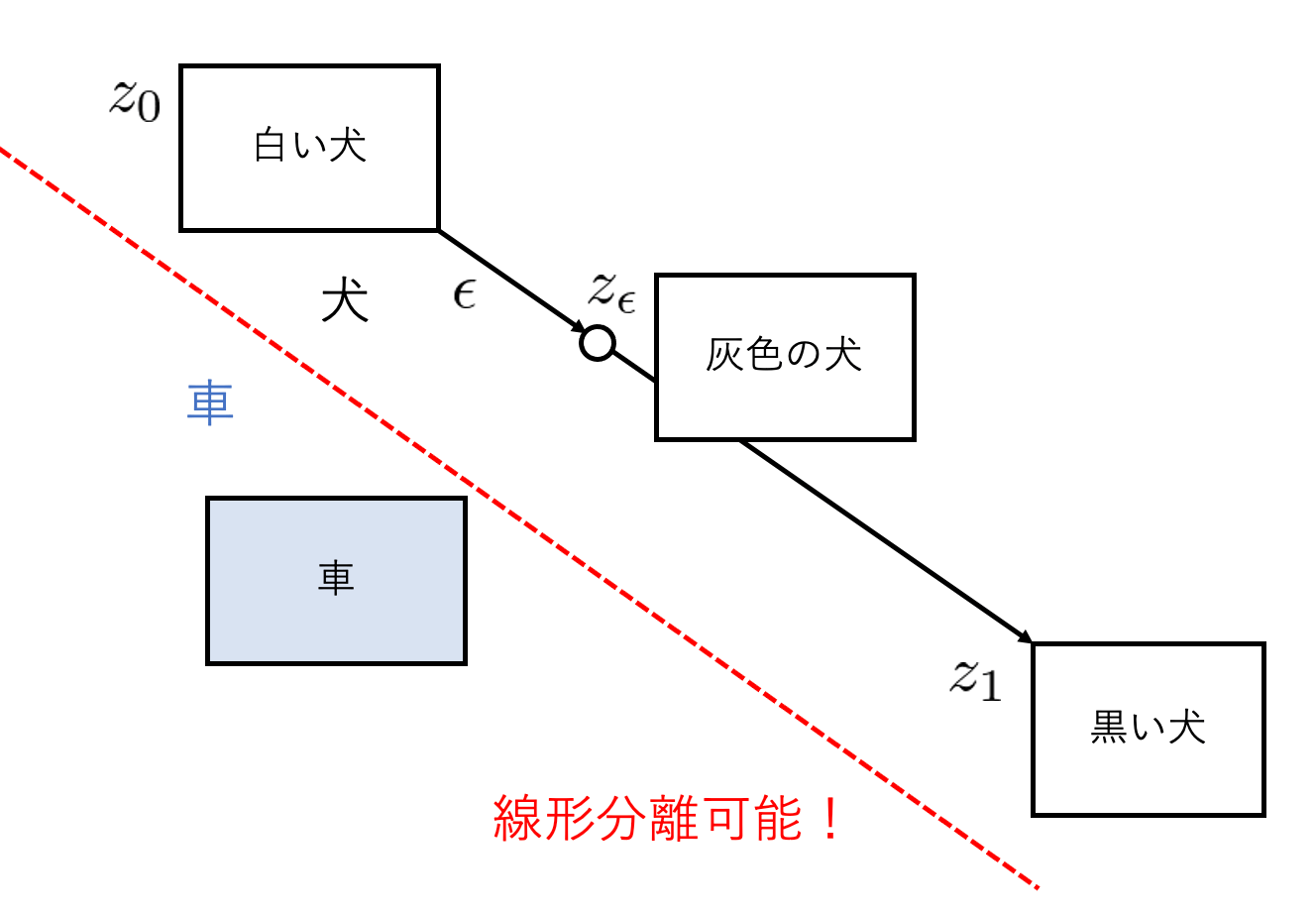
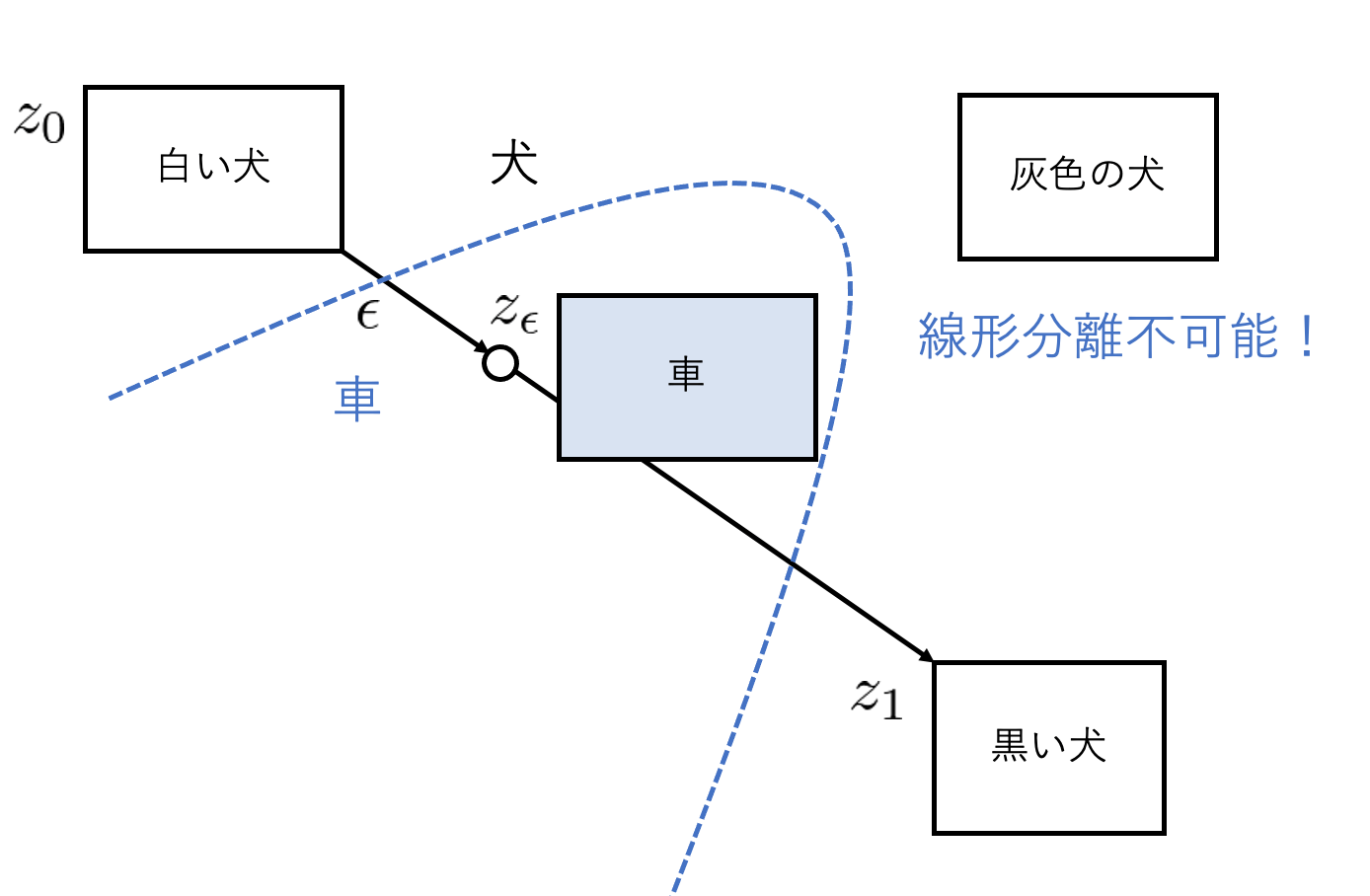
PPLは潜在空間と画像の対応関係の滑らかさを測定する指標です。
生成モデルは、潜在変数の空間内で生成画像の特徴が分離できることが理想とされています。
例えば、白い犬の画像を生成する潜在変数
 |
 |
|---|---|
| 図1(a):潜在変数の空間内で生成画像の特徴が分離できる | 図2(b):潜在変数の空間内で生成画像の特徴が分離できない |
これは潜在変数を変化させたときに、生成画像がどれだけ変化するのかを測定することで数値化できます。
この数値は小さいほど潜在空間と画像の対応関係が滑らかで良いスコアであるといえます。
式を以下に示します。
- torchvision.models.vgg16の学習済みモデルを使用
\epsilon=1e-4
調査結果
それぞれのモデルの学習過程で指標がどう変化していくのか確認します。
IS

各モデルのISの推移
いずれのモデルも学習が進むごとにISが高くなり精度が改善されて行っている様子が確認できます。拡散モデルだけ途中から下がりました。6000epoch時点だと拡散モデル、Flowモデル、GANの順番で高くなりました。
FID

各モデルの対数FIDの推移
いずれのモデルも学習が進むごとにFIDが低くなり精度が改善されて行っている様子が確認できます。Flowモデルだけ途中から上がりました。6000epoch時点だとFlowモデル、拡散モデル、GANの順番で良い結果となりましたが、学習を進めることで拡散モデルはより精度の改善が期待できそうです。
PPL
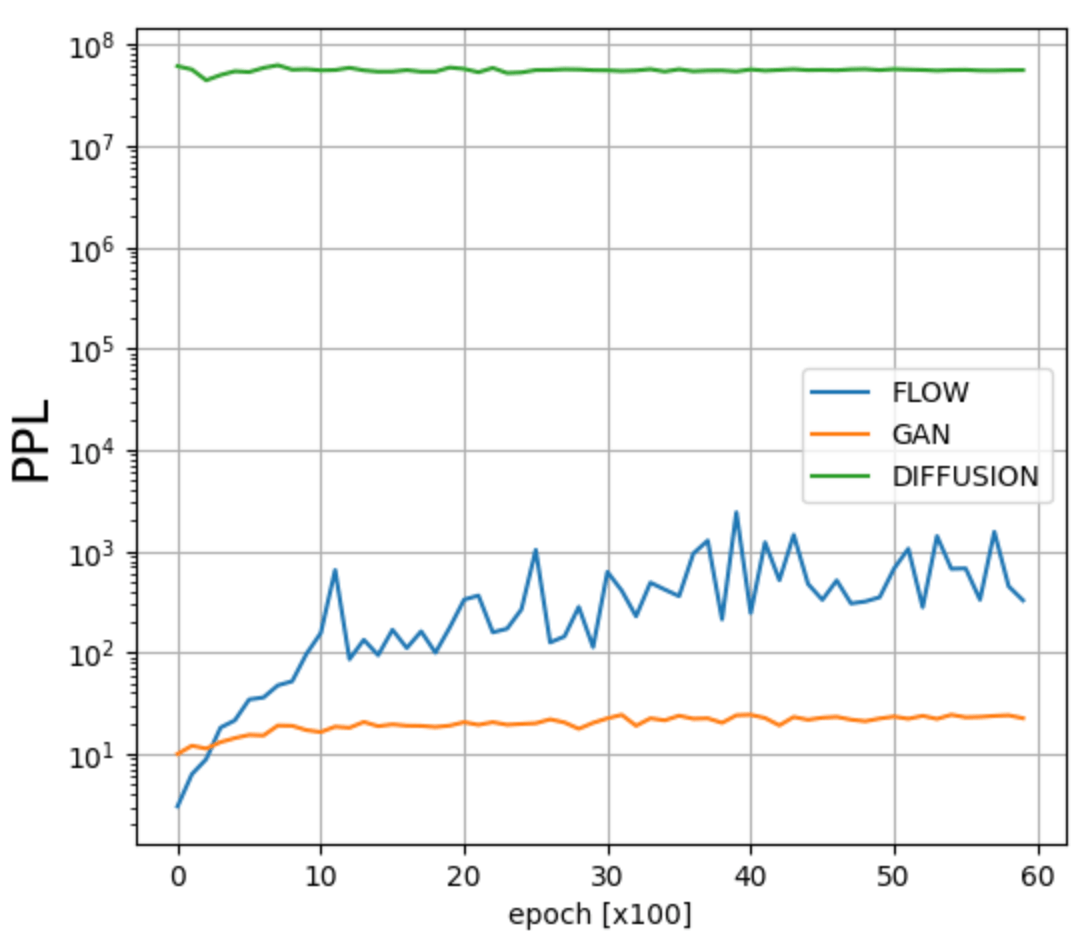
各モデルの対数PPLの推移
6000エポック時点のPPLの評価は、GAN、Flowモデル、拡散モデルの順番で高くなりましたが、学習が進むにつれて良化しているようには見えません。これはPPLが提案されたStyleGANでは、入力ノイズを線形な空間に写像する工夫をしていましたが、今回の調査ではそのようなことはしていないからだと思います。
学習初期は、どんな入力ノイズに対しても意味のない画像を生成するのでPPLは低く、学習が進むと入力ノイズに対して何かしら意味のある画像を生成するためPPLは高くなります
1バッチ16枚の画像生成にかかる時間
画像生成にかかる時間は、GAN、Flowモデル、拡散モデルの順番で短くなりました。
GANは生成器に正規ノイズを一度通すだけで良いため高速で画像を生成できます。
Flowモデルはステップ数を少なく設定しても生成される画像の品質が落ちにくいという特徴があります。
Flowモデルのステップ数は、拡散モデルのステップ数の10分の1に設定したことで、生成速度も10倍早くなりました。
| モデル | 生成時間[s] |
|---|---|
| GAN | |
| Flowモデル | |
| 拡散モデル |
生成画像
それぞれのモデルで生成された"車"の画像は以下のようになります。GANは崩れていますが、拡散モデルやFlowモデルはなんとなく"車"であることがわかります。
 |
 |
 |
|---|---|---|
| GAN | 拡散モデル | Flowモデル |
調査した感想と結び
この記事では、GAN、拡散モデルおよびFlowモデルについて、生成モデルの評価指標であるIS、FIDおよびPPLを用いて比較しました。
これまで画像生成モデルを使用したことはありましたが、どういったアルゴリズムで学習、訓練しているのか調べたことはありませんでした。今回、調査実装する機会をいただくことができて、生成AIについて少し詳しくなり、また、"stable diffusion"や"midjourney"のようにリアルな画像を生成する難しさを知りました。
今回の調査を通じて、生成AIへのモチベーションが上がったので、次はユーザが設定したプロンプトに沿った画像を生成するモデルの調査実装をしたいと思います。

株式会社D2C d2c.co.jp のテックブログです。 D2Cは、NTTドコモと電通などの共同出資により設立されたデジタルマーケティング企業です。 ドコモの膨大なデータを活用した最適化を行える広告配信システムの開発をしています。
Discussion