はじめに
はじめまして、株式会社D2C(以下D2C)で内定者アルバイトをしている井上です。
今年の4月から就職予定のD2Cで、現在生成AIの調査を行っています。
この記事では、Flowベース生成モデルに関する論文を紹介します。
記事は3つに分け、以下の内容で執筆します。
1. GAN, 拡散モデルの調査
2. Flowベース生成モデルの調査
3. 画像生成モデルの比較
この記事では、"2. Flowベース生成モデルの調査"についてです。
背景
昨今、ChatGPTの登場を皮切りに生成AIといった単語が広く一般層にも認知されるようになりました。
生成AIには、画像生成、テキスト生成、動画生成、音声生成など、いくつかの種類があります。このうち、画像生成AIに着目した場合、Stable DiffusionやDALL・E3などの登場により、誰でも簡単に高品質な画像の生成を行うことが可能になりました。一方で、この画像生成AIが将来的にクリエイターの仕事を奪うのではないか、AIの学習に大量にイラストが登用されるのでないかなどの問題があり、ネット上で議論になっていたりもします。
さて、そんな生成AIですが、なぜこれほどまでに高品質な画像を生成可能になったのでしょうか。それは GANやDiffusion modelなどをはじめとした様々な画像生成モデルが提案されたことにあり、これらのモデルは日々加速度的に提案されています。
画像生成AIは実に様々なアプローチから高品質な画像を生成するモデルが提案されていますが、皆さんは、Flowベース生成モデル(以下、Flowモデル)というモデルはご存知でしょうか。
Flowモデルとは、尤度を直接計算可能でその尤度を最大化することで学習が可能なモデルになります。特に、ICLR2023に採択された「Flow Matching for Generative Modeling」は、Diffusion Modelよりも効率的に訓練・サンプリングができるモデルとして、ICLR2023のSpotlightに選ばれています。本記事では、「Flow Matching for Generative Modeling」の紹介をメインに行いますが、前提知識として理解しておいた方が良い「正規化Flow」及び「CNF: Continuous Normalizing Flows」の解説も簡単にですが行います。
目的
理想の生成モデルとは、高品質で多様な画像を生成できることとされています。
生成モデルである"GAN"、"拡散モデル"および"Flowモデル"について、どのモデルが高品質で多様な画像を生成できるか調べたなかから、この記事では、Flowモデルについて説明します。また、実際に実装、訓練および生成した結果を報告します。
またこの記事は、D2Cの内定者アルバイト生の活動内容を社外の方に知っていただくことを目的としています。
機械学習や深層学習について詳しくない方に読んでいただくために、各モデルの仕組みについては簡単な説明を心がけています。
記事の要約
本記事では大まかに3種類のFlowベースモデルを紹介しています。
正規化Flow
- 単純な確率分布を非線形で可逆な変換fを繰り返し適用し複雑な分布に変換する
- データ分布
p_x(x) - MNISTやTFDはそれなりに生成できているがSVHNやCIFAR-10の精度はイマイチ
CNF: Continuous Normalizing Flows
- 単純な確率分布から複雑な分布への変換を連続的(時刻0~1)な変換とし常微分方程式(ODE)を用いて解く
- 画像の品質が向上し、より複雑なデータ分布を捉えることが可能になるといったメリット
- 計算コストが高い
Flow Matching
- CNFを時刻ごとの学習が可能
- Diffsion modelのように計算プロセスを簡略化している
- OT(Optimal Transport)pathを利用すると少ないサンプリング数で生成可能(効率的に学習が可能)
Flowモデル
正規化Flowの仕組み
正規化フローで代表的な論文として、NICE(NON-LINEAR INDEPENDENT COMPONENTS ESTIMATION) Laurent Dinh et al. 2015 が挙げられます。NICEとは、ICLR2015に採択された論文であり、Flow系論文の始祖的な論文に位置しています。
正規化Flowの手法としては、簡単な形(ガウス分布など)の確率分布
ちなみに、このfによる
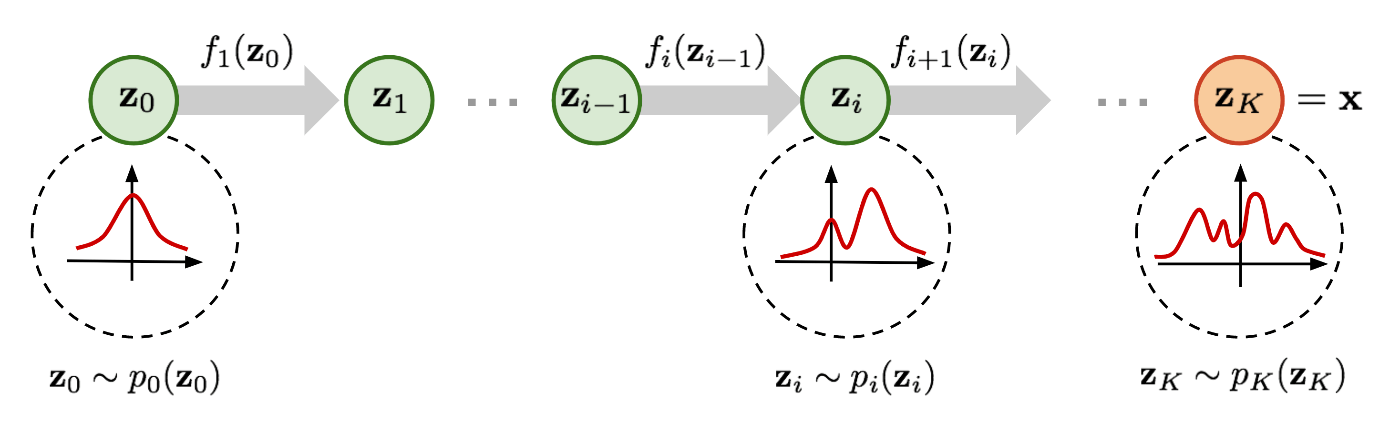
図1:単純な分布
生成モデルのアプローチとして、真の分布(データ分布)

図2:
2項目の対数尤度関数の期待値を最大化して分布に近づくように学習を行います。
この様にして学習された正規化Flowモデルの生成例は図3の様になります。MNISTやTFDはそれなりに生成できているのに対してSVHNやCIFAR-10は精度良く生成できていないことがわかります。特に、CIFAR-10に関しては、正規化Flowよりも前に発表されたGANの方が高精度に生成できています。




図3:NICEモデルの生成例(出典: https://arxiv.org/pdf/1410.8516.pdf )
CNF: Continuous Normalizing Flowsの仕組み
「CNF: Continuous Normalizing Flows」の代表的な論文として、「Continuous-Time Flows for Efficient Inference and Density Estimation(Changyou Chen et al. 2017)」 や「Neural Ordinary Differential Equations(Ricky T. Q. Chen et al. 2018 )」(以下、Neural ODE)などが挙げられます。
Neural ODEは、ニューラルネットワークで常微分方程式 (ODE)を解く手法です。
このNeural ODEの論文内で「CNF: Continuous Normalizing Flows」が触れられています。
正規化Flowでは、非線形で可逆な変換fを繰り返し適用することで複雑な分布
メリットとして、NNで採用できる層が不可逆変換でもよくなりモデルの自由度が上がる他、画像の品質が向上し、より複雑なデータ分布を捉えられる点が挙げられます。一方で、ODEの解法の計算コストが高く、実用的な応用においては不便といったデメリットも存在します。
生成された画像例が図4のようになります。正規化Flowと比較し生成画像の品質が向上していることが確認できます。
図4:CNFの画像生成例(出典:https://arxiv.org/pdf/1709.01179.pdf )
Flow Matchingの仕組み
Flow Matchingでは、CNF(Continuous Normalizing Flow)を各時刻の条件付フローで学習します。
目的確率密度分布
ここで、θはCNFベクトル場
流れは以下のようになります。
例えば、ある未知のデータ分布
ここで、
特に時間
条件付きベクトル場を「周辺化(marginalization)」することで、conditional vector fieldsを定義できます。(全ての
条件付き確率分布
しかし、境界確率分布(marginal probability path)とベクトル場の定義(式4と式6)には、扱いにくい積分があるため、
FMの目的変数とは異なり、CFMの目的変数では、
これにより、境界確率分布(marginal probability path)や境界ベクトル場(marginal vector field)にアクセスすることなく、境界確率分布
条件付き確率分布とベクトル場
条件付き確率分布がガウシアンで与えられたとき、条件付きベクトル場は以下のように表せます。
ここで、
任意の特定の確率分布を生成するベクトル場は無限に存在しますが、これらの大部分は、基礎となる分布を不変のままにしておく成分の存在によるものです。例えば、分布が回転不変である場合の回転成分など、不必要な計算につながります。筆者らは、ガウス分布の正準変換(canonical transformation)に対応する単純なベクトル場を使用しています。
ガウス条件付き確率分布の実例
例1:拡散条件付きベクトル場(Diffusion conditional Vector Fields)
拡散モデルは、データに徐々にノイズを付加する拡散過程と、徐々にノイズを除去する逆拡散過程を考慮することで高精度な画像を生成することが可能なモデルです。詳しくは、前回の記事をご参照ください。
例えば、ノイズからデータのVariance Exploding (VE)分布は、次のような形になります。
ここで、
逆(ノイズからデータ)Variance Preserving (VP) は、
この条件付きVF
例2:最適輸送条件付きベクトル場(Optimal Transport conditional VF)
これは、最適輸送(OT:Optimal Transport)の displacement interpolantMaCann(1997)にあたるベクトル場みたいです。

図5:Diffusion pathの条件付きスコア関数とOT pathの条件付きベクトル場の違い
青は大きさ、赤は小ささを表す。
(出典: https://openreview.net/pdf?id=PqvMRDCJT9t )
図5は、拡散条件付きスコア関数(典型的な拡散法における回帰ターゲット)すなわち、式14のように定義された
開始点(
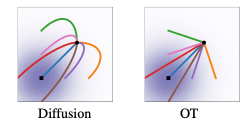
図6:拡散及びOT条件付き軌道(出典: https://openreview.net/pdf?id=PqvMRDCJT9t )
直感的に、OT変位マップ下の粒子は常に直線軌道で一定の速度で移動します。図6は、拡散VFとOT条件VFのサンプリング分布を示しています。拡散パスからのサンプリング軌道は最終サンプルを「オーバーシュート(※最小値を通り過ぎること)」する可能性があります。そのため、不要な後戻りを引き起こす一方で、OTパスでは直線的に進むことが保証されています。
利点と欠点
前回の記事で紹介したGAN及び拡散モデルと本記事にてメインで紹介したFlow Matchingの利点と欠点になります。
| モデル | 利点 | 欠点 |
|---|---|---|
| GAN | ・生成速度が速さ ・高精度の画像生成が可能 |
・訓練の不安定性 |
| 拡散モデル | ・訓練の安定性 ・高精度の画像生成が可能 |
・生成速度の遅さ |
| Flow Matching | ・拡散モデルより効率的に訓練とサンプリングが可能 | ・生成速度の遅さ(拡散モデルより速くGANより遅い) |
実験
本章では、前章までの理論をもとに実際に実装、訓練および生成した結果を紹介します。
データセット及び前処理は、前回と同様です。前回の記事はこちら
訓練パラメータ
| モデル | 学習率 | バッチサイズ | ステップサイズ |
|---|---|---|---|
| Flow Matching | 1e-3 | 1000 | 100 |
Flow Matchingの
実装はpytorch、最適化手法はAdamを使用しました。
訓練結果
生成画像
損失の推移を図7に生成画像例を図8に示します。
図7は縦軸がloss横軸がepochになります。epochが増えるごとにlossが減少していることがわかります。
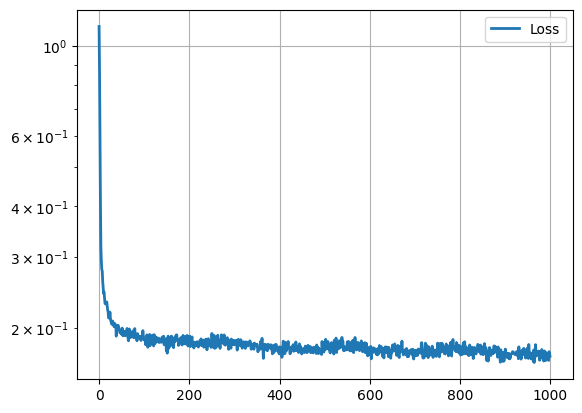
図7:損失の推移
まだ、若干ぼやけていますがそれらしい画像が生成されています。学習時に正規化しているのでその影響でぼやけているかもしれません。なお、Flowモデルの論文内ではもう少し綺麗に画像が生成されています。興味のある方は元論文をご確認ください

図8:学習したFlowモデルの生成した画像
調査した感想と結び
本記事では、Flow Matching for Generative Modelingを中心にFLowモデルの紹介を行いました。
私自身、GANやDiffusion modelなどは知っていたのですが、Flowモデルについては今回の論文調査や実装を通じて理解を深めることができました。今回は、Image to Imageの画像生成について調査しましたが、Stable DiffusionをはじめとするText to Imageでの画像生成では、Difuusion modelベースの画像生成モデルとCLIPと呼ばれる画像にテキストラベルをつけてクラス分けを行うモデルを組み合わせています。今後はこれらTetx to Imageをはじめとした様々な生成AIについて調査を行いたいと考えています。

株式会社D2C d2c.co.jp のテックブログです。 D2Cは、NTTドコモと電通などの共同出資により設立されたデジタルマーケティング企業です。 ドコモの膨大なデータを活用した最適化を行える広告配信システムの開発をしています。
Discussion