はじめに
はじめまして、株式会社D2C(以下D2C)で内定者アルバイトをしている大橋です。
今年の4月から就職予定のD2Cで、現在生成AIの調査を行っています。
今回はその調査結果を記事としてまとめる機会を頂きました。
記事は3つに分け、以下の内容で執筆します。
- GANと拡散モデルの調査
- Flowモデルの紹介
- 画像生成モデルの比較
この記事は、"1. GANと拡散モデルの調査"についてです。
背景
現在あらゆる場面で目にすることが多い"AI"ですが、AIブームはこれ以前に2度あるため、現在のブームは第3次AIブームといわれています。この第3次AIブームが始まったきっかけの1つが2012年に開催された画像認識の競技会 ILSVRC(ImageNet Large Scale Visual Recognition Challenge) です。
従来ではサポートベクトルマシン(SVM)が画像認識分野で主要な機械学習手法でした。SVMを用いても毎年1~2%の改善しか出せませんでしたが、2012年の本競技会で、トロント大学のチームが開発した AlexNet という深層学習を用いたモデルは前年の誤差率を10%以上改善し勝利したことが第3次AIブームの火付け役となったと言われています。
この時脚光を浴びた深層学習はその後さまざまな分野で応用され、最近ではデータの生成についての研究が盛んに行われています。
2014年にIan Goodfellow氏により Generative Adversarial Network(GAN) が発表されました。GANは生成モデルを訓練するための革新的なアーキテクチャで、2つのネットワーク、生成器と識別器を使用します。生成器は識別器を騙すためのデータを生成し、識別器は生成されたデータと本物のデータを識別します。訓練が進むにつれて生成器は本物のデータに近いデータを生成するようになります。
2015年以降は 拡散モデル(Diffusion Models) が注目を集めており、現在も研究が盛んに行われています。拡散モデルはデータの確率分布をモデル化する手法で、データにノイズを付加する拡散過程と徐々にノイズを除去する逆拡散過程を考えます。拡散モデルはGANで問題であった訓練の不安定性を解決しながら高品質な画像を生成することができます。
2018年以降は Flowモデル の研究が進んでいます。Flowモデルは確率密度関数の変換を利用してデータの生成を行う手法です。この手法は確率密度関数が逆関数を持つ場合、データの生成が効率的に行えるというアイデアに基づいています。2022年には"Flow matching"という学習手法が提案され、従来より効率的にモデルの学習、データの生成を行えるようになり再び注目を集めています。
この記事の目的
理想の生成モデルとは、高品質で多様な画像を生成できることとされています。
本調査では、生成モデルである"GAN"、"拡散モデル"および"Flowモデル"について、どのモデルが高品質で多様な画像を生成できるか調べました。この記事では、"GAN"と"拡散モデル"について説明します。また、実装、訓練および生成した結果を報告します。
またこの記事は、D2Cの内定者アルバイト生の活動内容を社外の方に知っていただくことを目的としています。
機械学習や深層学習について詳しくない方に読んでいただくために、各モデルの仕組みについては簡単な説明を心がけています。
GANと拡散モデル
GANの仕組み
GANとは、生成器と識別器からなる生成モデルの一種です。
図1に、GANのネットワーク構造を示します。
生成器Gは、ランダムノイズを入力として受け取りデータを生成します。
識別器Dは、データを入力とし、そのデータがリアルなデータか生成器によって生成されたデータかを識別します。リアルデータに対しては1、生成されたデータに対しては0をラベル付けして学習します。
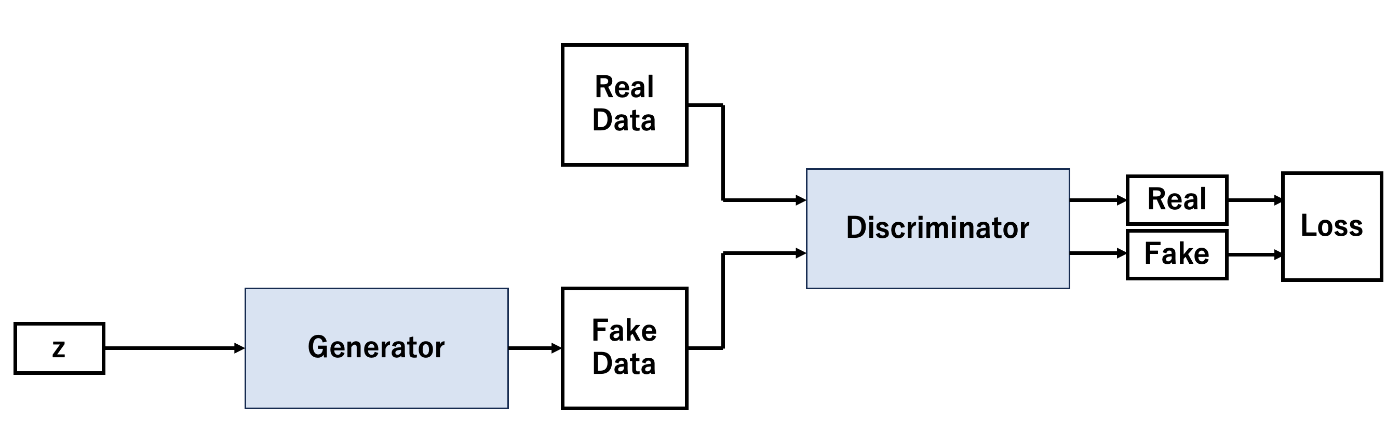
図1:GANのネットワーク構造
生成器Gは識別器Dを騙し、識別器Dは生成器Gを見破るというように、2つのニューラルネットワークを競わせて学習させることから敵対的生成ネットワークと呼ばれます。
損失関数は以下の式で表せられ、学習はミニマックス法を用いて行います。
ここで、
まず生成器Gを固定して、
次に識別器Dを固定して、
拡散モデルの仕組み
拡散モデルは、データに徐々にノイズを付加する拡散過程と、徐々にノイズを除去する逆拡散過程を考えます(図2)。
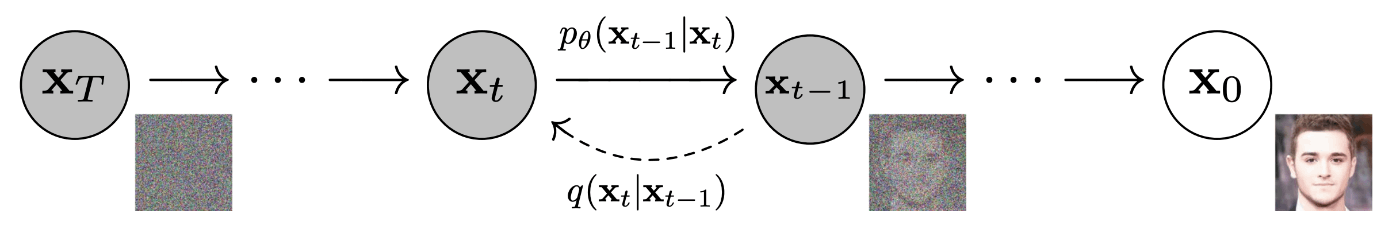
図2:拡散課程と逆拡散過程(出典:https://arxiv.org/pdf/2006.11239.pdf)
拡散モデルは
ここで、
訓練および生成アルゴリズムを表1に示します。

表1:訓練および生成アルゴリズム(出典:https://arxiv.org/pdf/2006.11239.pdf)
利点と欠点
それぞれのモデルの特徴について利点欠点を挙げて比較します。GANはstyleGAN2の論文に上げるように高画質の画像を生成でき、一度モデルを通すだけで画像を生成できるので生成が早いことが利点として挙げられます。一方でminmax法による不安定さやモード崩壊などの学習の難しさや生成できる画像の多様性が乏しいことが欠点として挙げられます。拡散モデルはGAN以上の高精度の画像生成が可能で、一つのモデルで多様な画像を生成可能なこととが利点として挙げられます。ところがモデルを複数回通さないといけないので生成速度は遅くなってしまいます。
| モデル | 利点 | 欠点 |
|---|---|---|
| GAN | ・高精度の画像生成が可能 ・生成速度が速さ |
・訓練の不安定性 ・モード崩壊 ・多様な画像生成が難しい |
| 拡散モデル | ・高精度の画像生成が可能 ・多様な画像生成が可能 |
・生成速度の遅さ |
調査内容
ここからは実際にGANと拡散モデルを実装して生成される画像の違いを確認していきたいと思います。
データセット
学習にはCifar-10データセットを利用しました。Cifar-10は画像認識を目的としたチュートリアルで使われるデータセットです。データセットは5万枚の訓練データと1万枚のテストデータ、合計6万枚から構成されます。各画像のサイズは

図3:Cifar-10データセットの内容
前処理
データセットの値は0から1をとるため、データセットの平均と分散を0.5と決めて正規化を行いました。
正規化によってデータセットの値0.5は0に、値の取りうる範囲は2倍になります。
生成モデルの生成結果
訓練パラメータ
| モデル | 学習率 | 学習率スケジュール | バッチサイズ | ステップサイズ |
|---|---|---|---|---|
| GAN | 生成器: 5e-5 識別器: 5e-6 |
- | 200 | - |
| 拡散モデル | 1e-3 | epoch < 1000: 1倍 1000 3000 5000 |
1000 | 1000 |
GANおよび拡散モデルのアーキテクチャは以下サイトから拝借しました。
実装はpytorch、最適化手法はAdamを使用しました。
GANの学習率は他2つと比べて低く設定してあるため、
公平な比較とは言えませんが参考程度にご覧ください。
計算機環境
計算機環境はAWS,p3.2xlargeインスタンスを使用しました。
学習時間はGANで約1時間、拡散モデルで約2時間でした。
| CPU | メモリ | GPU |
|---|---|---|
| Intel(R) Xeon(R) CPU E5-2686 v4 @ 2.30GHz x8 | 64GB | Tesla V100 16GB |
訓練結果
上のような手法でそれぞれのモデルを学習した結果は以下のようになりました。
GAN
上記設定で6000エポック学習したときの損失関数の推移を図4に、生成された画像を図5に示します。

図4:損失の推移(青:生成器ロス、オレンジ:識別器ロス)
縦軸はloss、横軸はepochを表しています。
学習が進むにつれて、識別器のlossが小さく、生成器のlossが大きくなっています。
これは、識別器の学習がはやく、生成器が識別器を騙す画像を生成できなくなっているためです。

図5:6000エポック学習したGANの生成した画像
キレイな画像は生成できませんでしたがなんとなく"車"のようなものが生成できているのがわかります。
拡散モデル
上記設定で6000エポック学習したときの損失関数の推移を図6に、生成された画像を図7に示します。
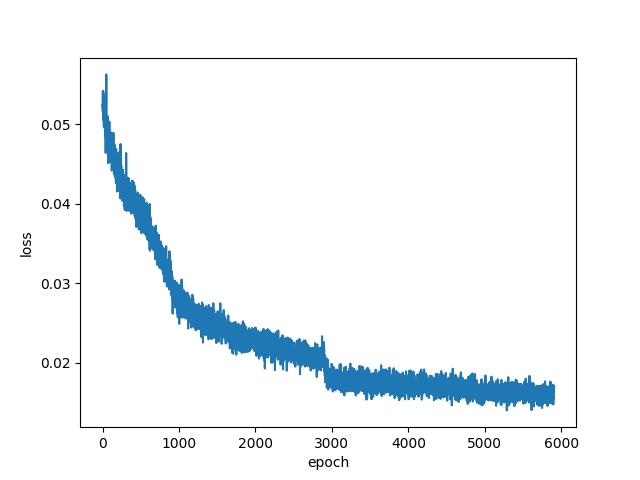
図6:損失の推移
縦軸はLoss、横軸はepochを表しています。学習が進むにつれて、lossが改善しています。
1000、3000、5000エポックで学習率を変更したため、lossの落ち方が変化しています。
このまま6000エポック以上学習を続けるとさらにlossが下がっていきそうです。

図7:6000エポック学習した拡散モデルの生成した画像
ぼやけがまだ少しありますが、一目見て"車"とわかる画像が生成できました。
調査した感想と結び
この記事では、GANと拡散モデルについて調査し、実際に訓練して画像生成を行いました。
GANについては、生成器にノイズを一度流すだけでいいため生成時間が短い一方で、学習が安定するハイパーパラメータを探すのに苦労しました。拡散モデルについては、学習が安定しているものの、学習が収束するまでが長く生成時間も長大でした。
GANの学習安定化手法や拡散モデルを少ないステップ数で生成する手法が提案されていたので、今後調べて実装していきたいと思います。
次回の記事では、Flowモデルについて取り上げます。

株式会社D2C d2c.co.jp のテックブログです。 D2Cは、NTTドコモと電通などの共同出資により設立されたデジタルマーケティング企業です。 ドコモの膨大なデータを活用した最適化を行える広告配信システムの開発をしています。
Discussion