Gemini in BigQuery でできること
はじめに
こんにちは、クラウドエース株式会社 第一開発部所属の工藤です。
本記事では、執筆時点(2024年12月6日)において Gemini in BigQuery で何ができるのかをまとめました。Gemini が Duet AI(旧名)の頃(2023年10月あたり)に以下の記事を書いたのですが、当時よりもできることがかなり増えていました。
ちなみに上記記事のタイトルですが、今後は Duet AI(現 Gemini)を使いこなさないとデータエンジニアとして生き残れないかも、という意味を込めたのですが、今のところ BigQuery を使うだけであれば Gemini を使わなくても大丈夫な気がしています。
ただ、Gemini in BigQuery がさらに進化して、業務に必要不可欠な存在になるかもしれないので、この記事で何ができるのかを押さえておきましょう。
Gemini in BigQuery とは
Gemini in BigQuery は、Google Cloud が提供するデータウェアハウスである BigQuery に Google が開発している生成 AI の Gemini が統合されたものです。Gemini in BigQuery では、BigQuery で動作する SQL の生成や BigQuery を効率的に利用するための推奨事項の提供など様々な機能を提供しています。
利用開始方法
Gemini in BigQuery は、以下のいずれかの方法で利用可能になります。
- BigQuery Editions の Enterprise Plus Edition の予約を、組織またはフォルダ、プロジェクトのいずれかに割り当てる
- Gemini Code Assist の Enterprise サブスクリプションを購入し、ライセンスをユーザーに割り当てる
上記それぞれの手順については、以下のドキュメントをご参照ください。
BigQuery Editions の Enterprise Plus Edition の予約をプロジェクトに割り当てる
Gemini Code Assist の Enterprise サブスクリプションを購入し、ライセンスをユーザーに割り当てる
料金
Gemini in BigQuery の利用料金は、前述の利用開始方法によって違いがあります。
BigQuery Editions の Enterprise Plus Edition の予約
BigQuery Editions の Enterprise Plus Edition の課金体系に従って BigQuery の分析料金が発生します。また、BigQuery のストレージ料金が格納しているデータ量に応じて発生します。
Gemini Code Assist の Enterprise サブスクリプション
Gemini Code Assist のサブスクリプションのライセンス料が発生します。こちらの具体的な料金は契約形態によって変わりますので、ドキュメントよりご確認ください。
また、BigQuery の分析料金が、各利用形態(オンデマンド or BigQuery Editions)の課金体系に従って発生します。上記に加えて BigQuery のストレージ料金が格納しているデータ量に応じて発生します。
BigQuery の料金については、ドキュメントからご確認ください。
Gemini in BigQuery でできること
2024年12月6日現在、Gemini in BigQuery には以下の機能があります。
- データ分析情報の生成
- データキャンバスの提供
- SQL と Python のコード生成
- データ準備機能によるデータ加工処理の作成
- BigQuery の効率的な利用方法の提供
- Apache Spark ジョブの最適化
- クエリトランスレータの補助
以降では、各機能を簡単に紹介していきます。
なお、本記事では、使い方には詳しく触れませんので、気になる方は各機能のドキュメントからご確認ください。
データ分析情報の生成
この機能は、Gemini によって特定のテーブルのデータを解釈するためのサンプルクエリが生成されるものになります。普段の業務で BigQuery テーブルを扱わないデータアナリスト等のユーザーがこの機能を使うことで、生成されたサンプルクエリを利用し仕様のわからないテーブルのデータを把握しやすくなり、データ分析の作業にいち早く取り掛かることができるようになります。
以下の画像は、一般公開データであるアイオワ州の酒類販売データが格納されている sales テーブルに対して、このデータ分析情報の生成を実行した時のものになります。
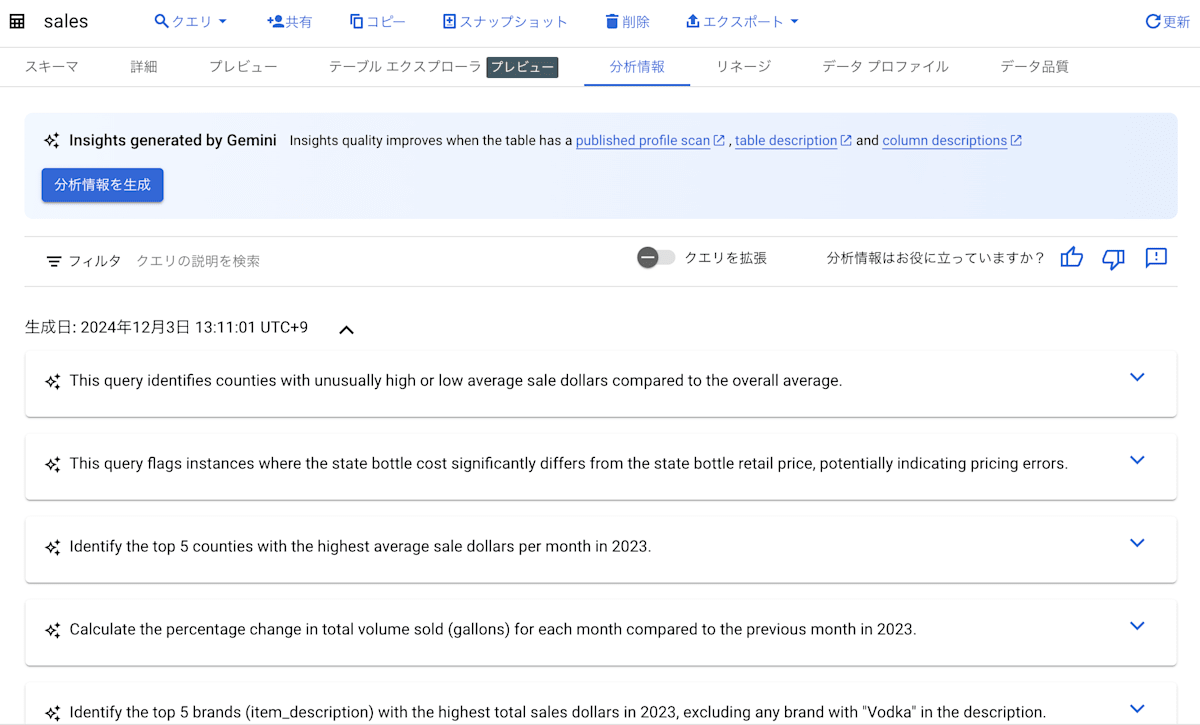
データ分析情報が生成されると、クエリの説明と共にサンプルクエリが生成されていることがわかります。

このテーブルでは、分析情報としてサンプルクエリが 20 個程度生成されていました。なお、生成されたクエリをいくつか確認しましたが、クエリの説明と実装内容が正しいものもあれば、間違っているものもありました。そのため、この機能を実際に利用するときは生成された結果を鵜呑みにせず、自分の目でクエリが正しいか確認した方がよさそうです。
この機能の詳しい使い方は、以下のドキュメントをご確認ください。
データキャンバスの提供
この機能は、テーブルの検索から SQL の生成および実行、その実行結果の可視化までの一連の作業を BigQuery エディタ上で完結できるデータキャンバスを提供するものになります。
データキャンバスを使うことで、上記の一連の作業は自然言語のみで行うことができ、SQL に馴染みのないユーザーでも簡単にデータ分析を行うことができるようになります。
この機能の使い方については、以下の弊社記事で詳しく書いておりますので、興味のある方はご覧ください。
データキャンバスの特徴としては、実行した SQL とその SQL で参照しているテーブル、SQL の実行結果を可視化したグラフが BigQuery エディタ上にまとめて表示され、さらにそれらの関係性が視覚的に表現されている点です。
以下の画像は、BigQuery で用意されているデータキャンバスのサンプルになります。SQL で参照しているテーブルが何なのか、どの SQL の実行結果を可視化しているのか等、実行した SQL とその SQL で参照しているテーブル、SQL の実行結果を可視化したグラフが一つの画面で確認できることがわかります。
SQL とその SQL で参照しているテーブルの関係性が図示されている様子
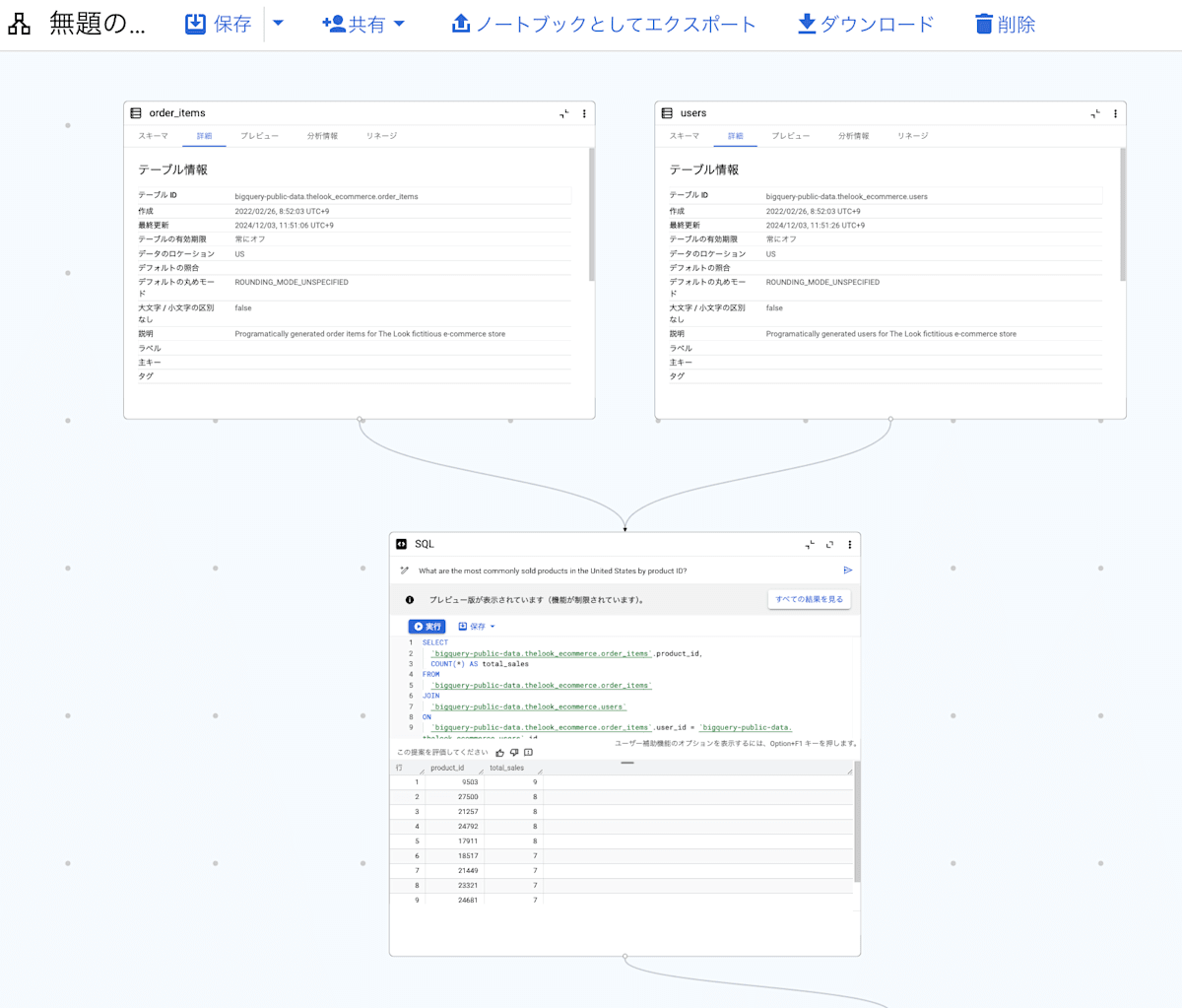
SQL とその SQL の実行結果を可視化しているグラフの関係性が図示されている様子

従来、テーブルと SQL、その SQL の実行結果を可視化したグラフの関係性は、それぞれの画面を切り替えながら確認する必要があり面倒でした。この機能を使うことで、一つの画面で上記それぞれの関係性を簡単に確認することができますので、これらの確認に煩わしさを感じている方は、この機能を試してみる価値はあると思います。
この機能の制限事項などは、以下のドキュメントに記載されていますので、気になる方はご覧ください。
SQL と Python のコード生成
本機能は、クエリエディタもしくは Python ノートブックでコーディングする際に、Gemini によって SQL と Python のコード生成および補完が行われるものになります。この機能は、Gemini in BigQuery が発表された時からあるものなので、ご存じの方も多いと思います。
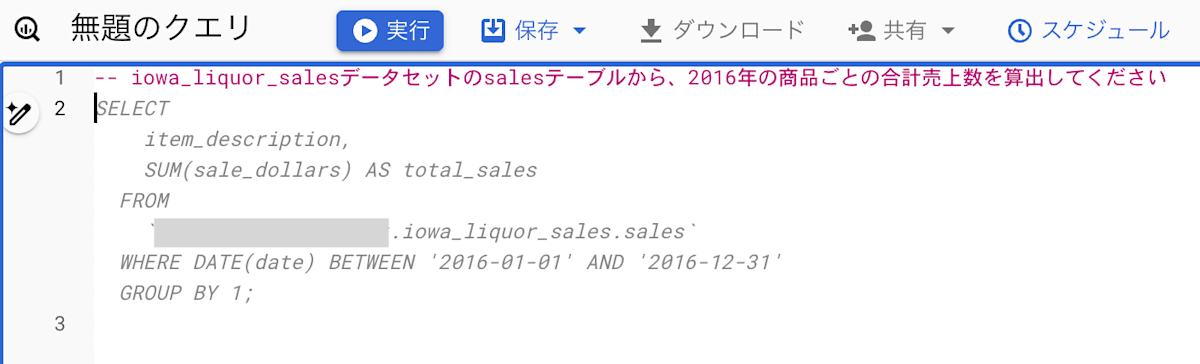
SQL を生成する方法は、クエリエディタにプロンプトをコメントアウトする形で記述する方法とコード生成専用のツールを使う方法の 2 種類あります。Python のコードは、プロンプトを入力するエディタから生成します。
以下の画像は、上記の方法で SQL と Python のコードをそれぞれ生成した時のものになります。
クエリエディタにプロンプトをコメントアウトする形で記述し、SQL を生成する
コード生成専用のツールから SQL を生成する

プロンプトを入力するエディタから Python コードを生成する

主にコーディング時に力を発揮するので、SQL と Python にあまり馴染みのないエンジニアにとっては嬉しい機能ではないでしょうか。この機能の詳しい使い方は、以下のドキュメントをご確認ください。
データ準備機能によるデータ加工処理の作成
本機能は、BigQuery のテーブル情報から Gemini によって提案されたいくつかのデータの加工内容を用いて、データ加工処理を作れるものになります。この機能は、ドキュメントで「データ準備(data preparation)」と呼ばれています。なお、こちらは 2024年12月6日現在、プレビュー機能となっています。
以下の画像は、本機能を使う対象のテーブルを選択したときにデータの加工内容が Gemini によって提案された時のものです。ここでは、データの型変換やデータの抽出条件などの内容が提案されました。

Gemini による提案直後の状態の加工処理は、「データの読み取り」と「別テーブルへの書き込み」の 2 つのステップしかありませんが、Gemini によって提案された加工内容から「適用」ボタンを押下すると、その加工内容が新しいステップとして追加されます。
以下の画像では「store_name カラムの NULL 値の除外」を加工内容として追加し、加工処理が「データの読み取り」「store_name カラムの NULL 値の除外」「別テーブルへの書き込み」の 3 つのステップで構成されている様子になります。

画面下部にある「ステップを追加」ボタンからデータの加工内容を明示的に定義することもできます。以下の画像は、上記画像の加工処理に抽出条件として date カラムが 2024 年のものだけにするステップを追加した時のものになります。

この機能を使うことで、SQL に馴染みのない方でも簡単にデータ加工処理を作成できるのではないでしょうか。今はプレビュー機能ですので実運用に使うのはまだ早いと思いますが、提案される加工内容の種類が増える等、機能が拡充される可能性があるため、今後注目しておこうと思いました。
この機能の詳しい使い方は、以下のドキュメントをご確認ください。
BigQuery の効率的な利用方法の提供
本機能は、BigQuery テーブルに対して実行された過去の処理を分析して、パーティショニングとクラスタリング、マテリアライズドビューの適用を推奨事項として提供するものになります。
BigQuery のパフォーマンス改善やコスト最適化には、パーティショニングとクラスタリング、マテリアライズドビューを利用することが推奨されています。これらが適用されていない場合は、この機能によって提案された推奨事項を適用することで、BigQuery をより効率的に運用することができます。なお、マテリアライズドビューに関する情報の提供は、 2024年12月6日現在プレビュー機能となっています。
以下の画像は、この機能によって提供される情報の例(ドキュメントに記載されているもの)になります。
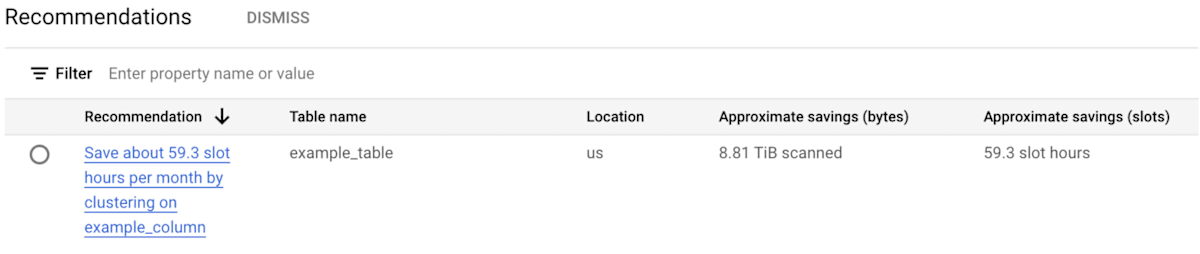
この機能で提供される情報は、単に「このテーブルは、クラスタリングした方が良いと思います」と雑に言うのではなく、「このテーブルの XX カラムをキーにクラスタリングを適用すると、YY スロット時間節約できる可能性があります」のように、具体的な効果も教えてくれます。BigQuery を効率的に運用したい方にとっては、この機能を使わない手はないと思います。
この機能の詳しい使い方は、以下のドキュメントをご確認ください。
Apache Spark ジョブの最適化
本機能は、BigQuery エディタで作成された Apache Spark ジョブ(PySpark プロシージャ)でエラーが発生したり処理時間が遅かったりした時に、Gemini がその改善策を提案もしくは自動チューニングしてくれるものになります。この機能は、2024年12月6日現在プレビュー機能となっています。
以下の画像は、この機能によって提供される情報の例(ドキュメントに記載されているもの)になります。

「What was autotuned?」では、どんな内容で自動チューニングされたかがわかります(上記画像の赤枠)。また、「What is happening now?」では、発生している問題に対する改善策を Gemini に聞くことができるリンクがあることがわかります(下記画像の赤枠)。

特に自動チューニングでは、メモリの割り当てや自動スケーリング構成の設定をしてくれるので、手動で設定する手間が減る嬉しい機能だと思います。
この機能の詳しい使い方は、以下のドキュメントをご確認ください。
クエリトランスレータの補助
本機能は、クエリトランスレータで適用する SQL の変換ルールを自然言語で記述することで Gemini がその内容に従ってクエリを変換してくれるものになります。
クエリトランスレータとは
クエリトランスレータとは、BigQuery 以外の DB で使用している SQL を BigQuery で動かしたいときに、その SQL を BigQuery で動作するものに変換してくれるものになります。
クエリトランスレータは、変換ルールがない場合はベストエフォートでの変換となり、BigQuery で動作するものに変換できない可能性があります。
このときに、変換ルールを定義しておくことで変換前のクエリを BigQuery で動作するものに変換できるようになります。
従来、この機能で利用する変換ルールは YAML ファイルで定義する必要があるため、多少の手間が発生してしまいますが、この機能を使うことでその手間がなくなる可能性があります。
以下の画像では、SQL Server のクエリを GoogleSQL に変換した時のものになります。以下は、変換ルールがない状態で変換を行った結果になります。

右側のエディタが変換後のクエリになりますが、BigQuery ではテーブルを作成する際にテーブル名だけでなくデータセット名も設定する必要があります。しかし、上記の変換後のクエリでは「employees」となっており、データセット名が設定されていないので、Gemini を使ってクエリをカスタマイズしようと思います。
画面上部の「サポート」を押下後に表示される「この翻訳をカスタマイズ」を押下することで、変換ルールを定義できる画面が表示されます。以下は、その画面でテーブル名をデータセット名を含んだ形に変換する時のものです。

変換ルールの定義後に「プレビュー」を押下すると、記述した内容を基に Gemini が生成した変換案を確認できます。
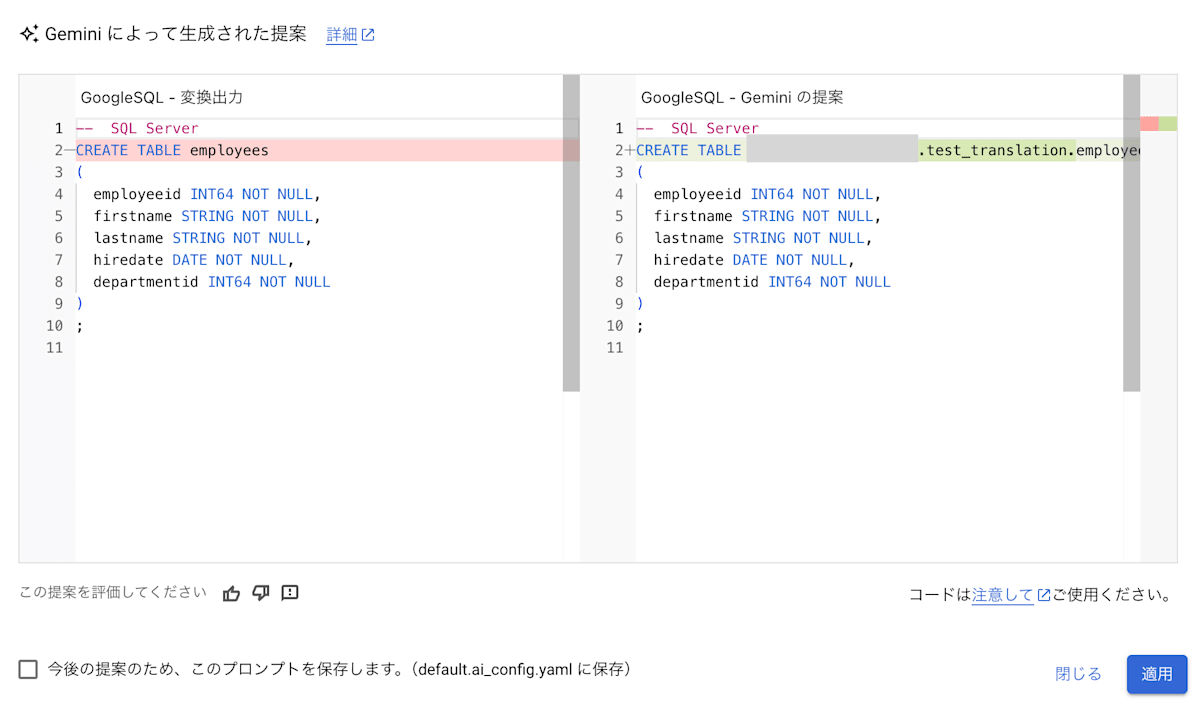
先ほど「employees」となっていた箇所が「プロジェクト ID.test_translation.employees」とデータセット名を含んでいるものに変わったことがわかります。プレビューの内容で問題がなければ「適用」を押下することで、その内容がクエリに反映されます。
上記の例では、変換対象の用語と変換後の用語を明示的に設定しましたが、この設定をせずに「Description」に変換内容を文章で記述するだけでも変換ルールを定義できます。以下は、先ほどのクエリにクラスタリングの設定を追加する際の変換ルールになります。

この内容で「プレビュー」を押下した結果は以下の画像であり、文章で記述した変換ルール通りにクラスタリングの設定を追加することができました。
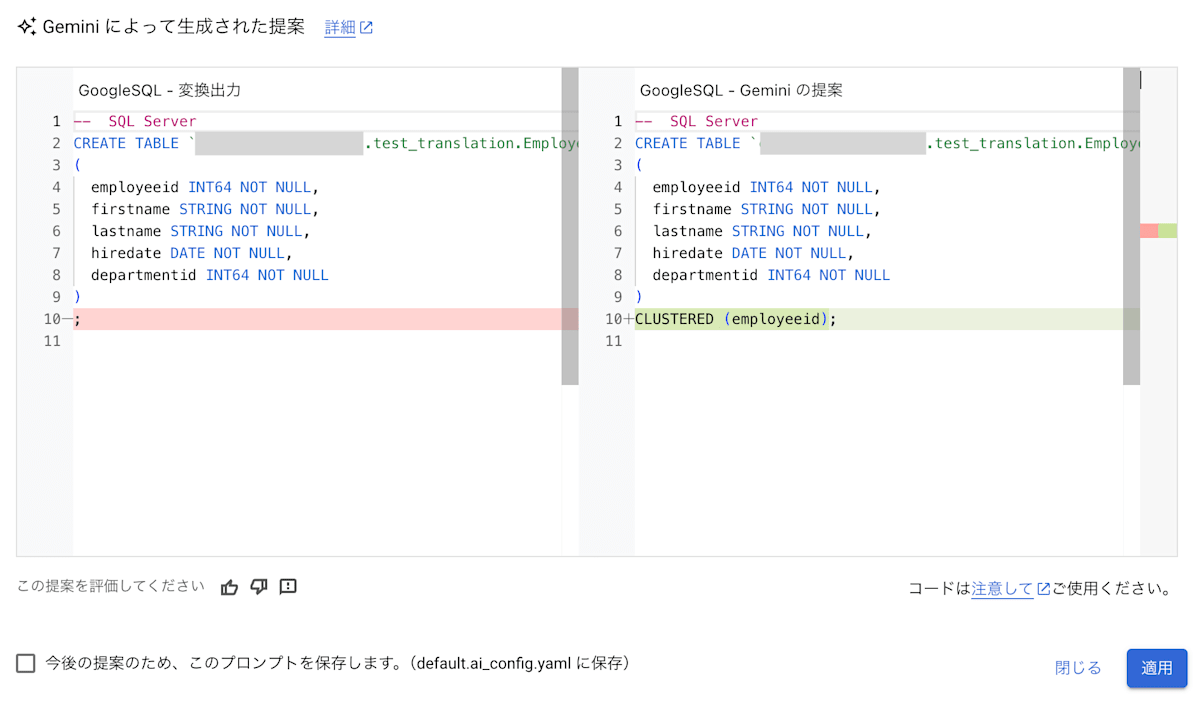
この機能を使うことで、BigQuery のテーブル仕様や GoogleSQL の記述方法に馴染みのない方でも、別の DB で使用しているクエリを BigQuery で動くように変換できると思います。
この機能の詳しい使い方は、以下のドキュメントをご確認ください。
また、クエリトランスレータについては、以下の記事で詳しく書いていますので、興味のある方はご覧ください。
おわりに
Gemini in BigQuery でできることをまとめてみました。およそ1年前はコード生成に留まっていた印象ですが、今では SQL の移行の補助や加工処理の作成からグラフの作成までできるようになり、守備範囲がかなり広がったと思います。来年の今頃にはどんな機能が追加されているか、今後のアップデートが楽しみです。
Gemini in BigQuery に対する筆者個人の所感ですが、開発面では、簡単な処理はある程度正しく生成できるものの複雑な処理になると正しく生成できない場合が多いので、実運用で使うのはもう少し先かなという印象です。一方の運用面では、「BigQuery の効率的な利用方法の提供」として紹介した機能は、エンジニアが一からやると時間がかかりそうな作業がなくなると思うので、実運用で使ってもよいと思いました。とは言っても、人間が最終的な責任を負うことは変わらないので、Gemini in BigQuery はあくまでも補助ツールであることを理解した上で使うのがよいと思います。
Gemini in BigQuery はまだ発展途上ではありますが、すでに BigQuery を使っている人だけでなくまだ使ったことがない人にとっても、今後のために試してみる価値はあるものだと思うので、一度試してみてはいかがでしょうか。
最後までご覧いただき、ありがとうございました。
Discussion