Duet AI in BigQuery と生きる
はじめに
こんにちは、クラウドエース データ ML ディビジョン所属の工藤です。
クラウドエースの IT エンジニアリングを担うシステム開発部の中で、特にデータ基盤構築・分析基盤構築からデータ分析までを含む一貫したデータ課題の解決を専門とするのがデータ ML ディビジョンです。
データ ML ディビジョンでは活動の一環として、毎週 Google Cloud の新規リリースを調査・発表し、データ領域のプロダクトのキャッチアップをしています。その中でも重要と考えるリリースを本ページ含め記事として公開しています。
今回紹介するリリースは、Duet AI in BigQuery についてです。このリリースにより、生成 AI によるクエリ生成やクエリ補完などが BigQuery の SQL エディタ上でできるようになりました。なお、この機能はプレビュー段階になります。
Duet AI in Google Cloud とは
Duet AI in Google Cloud とは、生成 AI によるアシストを Google Cloud のユーザーに提供するものです。現在は、一部のプロダクトで使うことができ、今後対象のプロダクトは増えると予想されます。Duet AI in Google Cloud の料金は、プレビュー段階ということもあり、追加料金なしで利用することができます(プロダクトの利用料金は発生します)。
詳しくは、公式ドキュメントを参照ください。
今回のリリースについて
今回ご紹介するのは、2023 年 8 月 29 日付に発表されたリリースの一つである Duet AI in BigQuery についてです。
該当リリースノート:BigQuery release notes
Duet AI in BigQuery とは
Duet AI in BigQuery では、BigQuery の SQL エディタ上で生成 AI によるクエリ生成やクエリ補完などができるようになります。本記事執筆(2023 年 9 月 27 日)時点では、以下のことができます。
- SQL クエリの生成
- SQL クエリの補完
- SQL クエリの説明
本記事では、上記の機能を実際に試したいと思います。
Duet AI in BigQuery を利用するには、公式ドキュメントに記載の申込フォームから申請が必要になります。ドキュメントの翻訳言語を日本語にしていると申込フォームは表示されませんので、申請時にはドキュメントの翻訳言語を英語にすることを推奨します。
また、申請の承認後にはプロジェクトで Duet AI を有効化する必要があります。Duet AI を有効化する手順は、公式ドキュメントをご覧ください。
使用上の注意点
Duet AI は初期段階の技術であり、誤った内容を生成する可能性があるため、生成されたものはすべて検証することが推奨されています。また、出力結果やプロンプトは、Duet AI の学習には利用されないとのことです。詳しくは、公式ドキュメントを参照ください。
料金
BigQuery の利用料金が発生します。料金の詳細は、公式ドキュメントを参照ください。
検証
早速 Duet AI の力がどんなものか、お手並み拝見といきましょう。今回は Google の公開データセットを使い、検証していきます。
なお、Duet AI in BigQuery はプレビュー段階であり、生成結果が一定ではない可能性がありますのでご注意ください。
SQL クエリの生成
この機能は、SQL エディタ上にプロンプトをコメントとして記載することで、クエリを自動で生成することができるものです。公式ドキュメントには、2 種類のプロンプト例が記載されており、SELECT や UPDATE などの DML(データ操作言語)に加えて、CREATE TABLE などの DDL(データ定義言語)も生成できるようです。また、プロンプトは複数の行にわたって入力することが可能です。
それでは、実際に使ってみます。
公式ドキュメントに記載されていたプロンプトを使い、クエリ生成から実行までの流れを見ていきましょう。以下のプロンプトでは、"bikeshare_trips" テーブルから加入タイプごとの平均利用時間を計算するように指示しています。
# Using `bigquery-public-data.austin_bikeshare.bikeshare_trips`, calculate the
# average trip length by subscriber type.
プロンプトをコメントとして書きます。この時点ではクエリは生成されません。

この状態で Enter キーを押下すると、生成されたクエリがグレー字で出力されます。
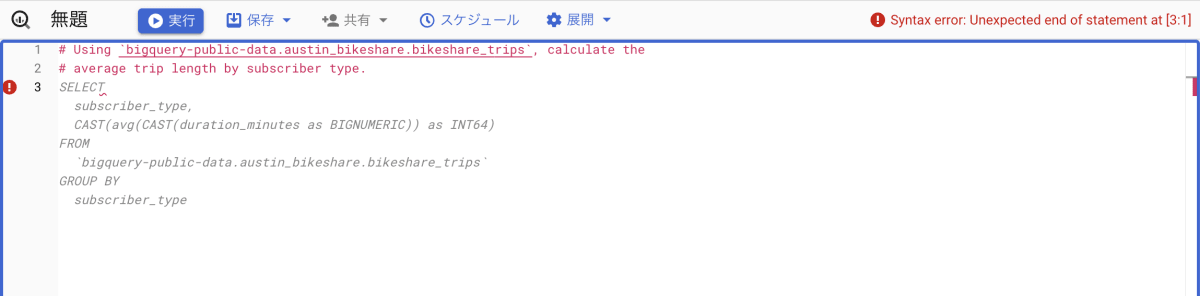
生成されたクエリにカーソルを合わせると、ツールバーが表示されます。このツールバーは、以下の内容を示しています。
- 生成されたクエリの数(今回は 3 つ)。
- 提案されたクエリ全文を受け入れるには、Tab キーを押下すること。
- 提案されたクエリを単語単位で受け入れるには、command キーと右矢印キーを押下すること。
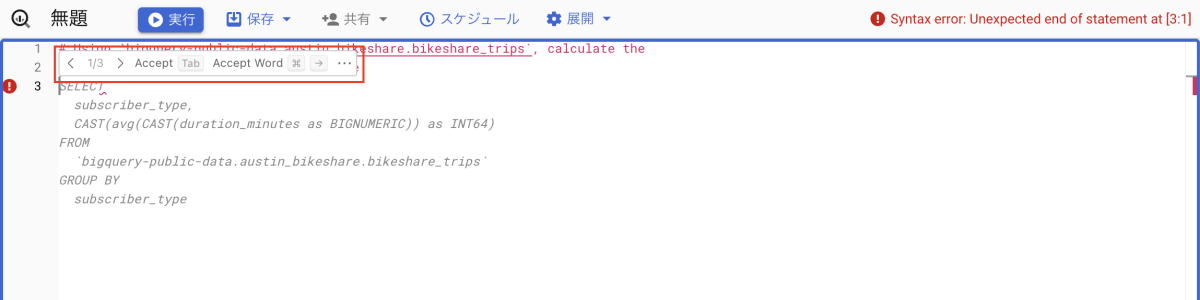
「<」や「>」マークを押下すると、提案されたクエリを確認することができます。

採用したいクエリがあった場合は、Tab キーを押下することでクエリが実際にエディタ上へ生成されます。最初に提案されたクエリで Tab キーを押下します。

実行してみると、きちんとクエリが正常終了しました。

次にテーブルを作成するプロンプトを試します。
以下のプロンプトでは、あらかじめ作成しておいた '1234' という名前のデータセットに、データ型が STRING の 'name' というカラムを含むテーブルを作成するように指示しています。そのため、事前に '1234' という名前のデータセットを作成しておく必要があります。
# Write a query that creates a table in the dataset `1234` with a string column called "name"
上記のプロンプトをエディタに記載し Enter キーを押下すると、クエリが提案されます。

提案されたクエリを受け入れて実行したところ、クエリは正常終了しました。確認すると、'1234' データセットにデータ型が STRING の 'name' というカラムがある 'mytable' テーブルが作成されていました。


使い方はある程度わかったので、自分でプロンプトを作ってみたいと思います。
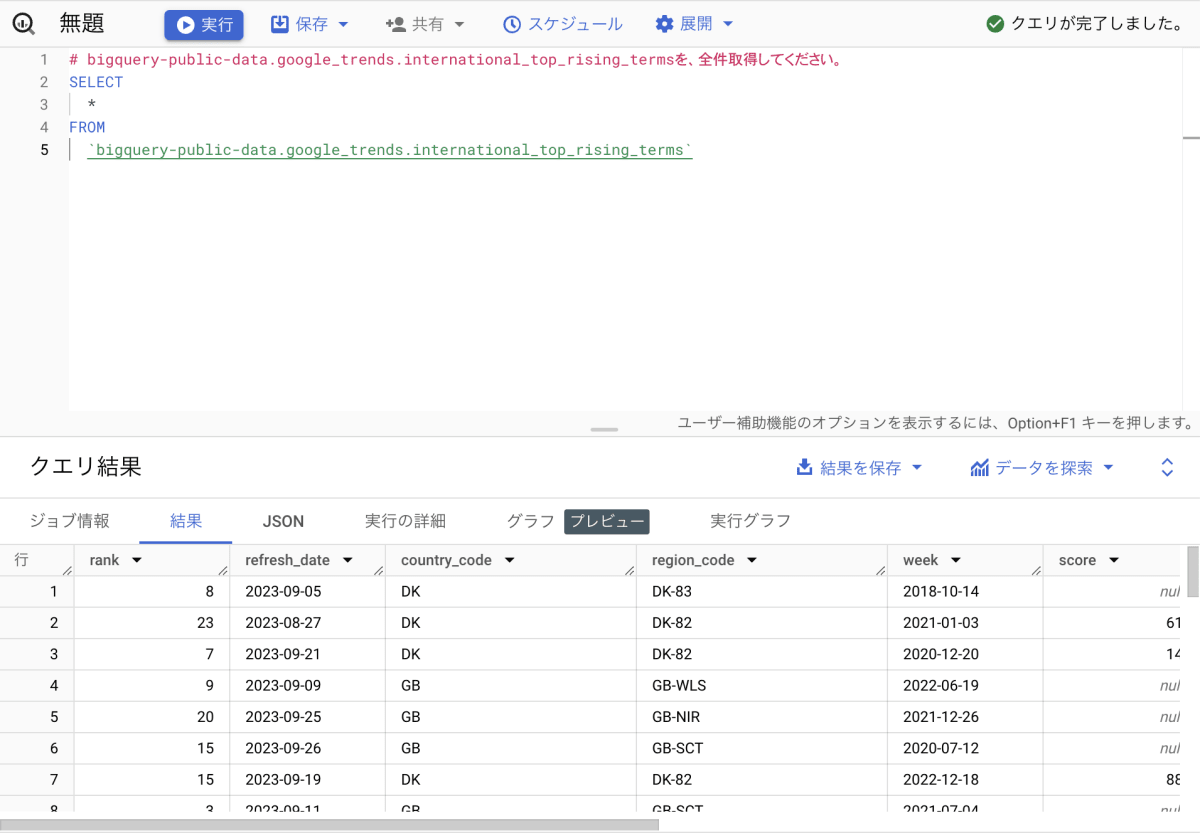
ここでは、Google の公開データセットであるトレンド データを使います。まずは、単純な全件取得処理を指示する以下のプロンプトを試してみます。
bigquery-public-data.google_trends.international_top_rising_termsを、全件取得してください。
上記のプロンプトをエディタに記載し Enter キーを押下すると、クエリが提案されました。日本語のプロンプトでもクエリは生成されるようです。

提案されたクエリは、正常終了することが確認できました。
次は、直近 1 日の日本のトレンドワードを検索したいと思います。
この要件を Chat GPT に日本語で言語化してもらった以下のプロンプトを使用します。
bigquery-public-data.google_trends.international_top_rising_termsを利用して、最新の1日間における日本のトレンドデータを探してみましょう。
このプロンプトをコメントとして書き Enter キーを押下したところ、クエリは生成されませんでした。

プロンプトが日本語だと良くないのかと思い、プロンプトを英語にしてみました。すると...
Let’s use the bigquery-public-data.google_trends.international_top_rising_terms dataset to find the trending data in Japan for the most recent day
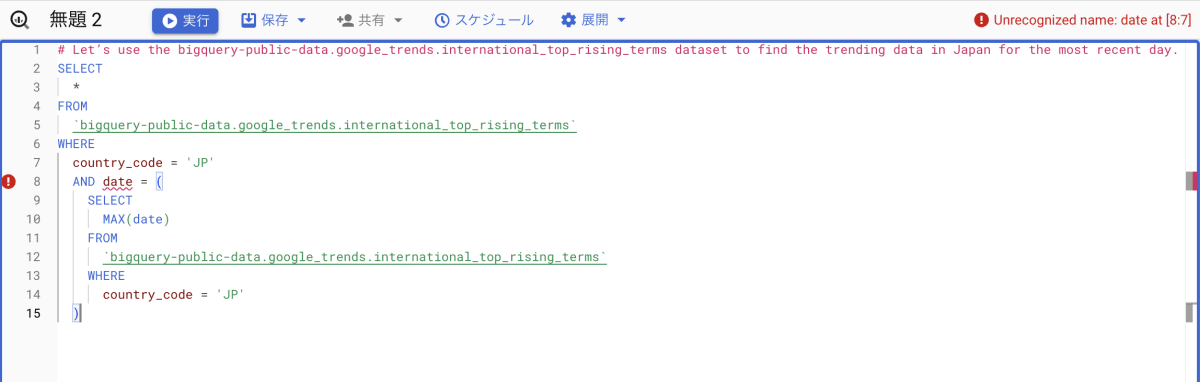
クエリが生成されました!
ですが、提案されたクエリは直近 1 日を指定するためのカラムとして、"refresh_date" とするべきところを存在しないカラム "date" を採用してしまっています。それでは、正しいカラムを使うようにプロンプトを修正してみましょう。今度は、日付のカラムは "refresh_date" であることを明示する形でプロンプトを修正しました。
Let’s use the bigquery-public-data.google_trends.international_top_rising_terms dataset to find the trending data in Japan for the most recent day. Note that the column for the date is refresh_date
このプロンプトで生成されたクエリは、以下の画像のとおりです。
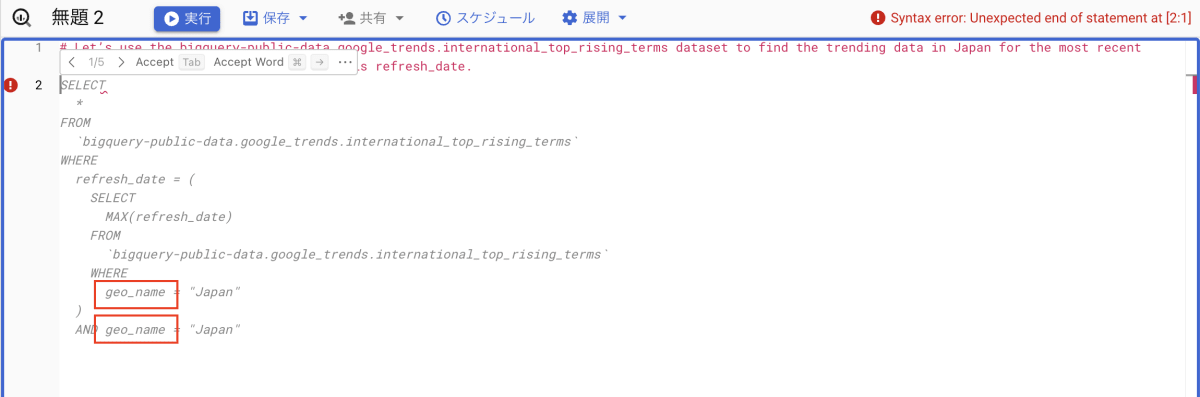
プロンプトで指示したカラムは正しく使われていますが、今度は別のカラム名が間違っています(赤枠のところ)。なお、提案された 5 つのクエリのうち、2 つは正しいカラム名を設定しているため実行できるもの、残り 3 つは誤ったカラム名を使っているものでした。トレンドワードのトップ 25 を抽出しようと思っていましたが、かなり時間がかかりそうなので諦めました。
Tips
生成されるクエリの正確さを改善するためには、以下の要素が有効であると公式ドキュメントに書いてありました(色々検証した後にこの存在に気づきました)。
- テーブルの各スキーマに説明( description )を入力すること。
- プロンプトに顧客生涯価値や粗利益などの用語を含める場合は、関連する列の情報を提供すること。
今回の検証で使用したデータセットは、Google の公開データセットであり、テーブルの各スキーマには説明が入力されていません。お手元のテーブルで試す場合は、各カラムの説明を設定するとよい結果が得られる可能性が高くなりそうです。

SQL クエリの補完
次にクエリの補完を試します。クエリを書いている途中で Space キーや Enter キーを押下すると、クエリが補完されます。SQL エディタに以下の内容を書きます。
SELECT
subscriber_type
, EXTRACT(HOUR FROM start_time) AS hour_of_day
, AVG(duration_minutes) AS avg_trip_length
FROM
`bigquery-public-data.austin_bikeshare.bikeshare_trips`

この状態で Enter キーを押下すると、WHERE 句の内容が提案されます。

提案された内容を Tab キーを押下して受け入れ、再度 Enter キーを押下します。すると、GROUP BY 句と ORDER BY 句の内容が提案されます。
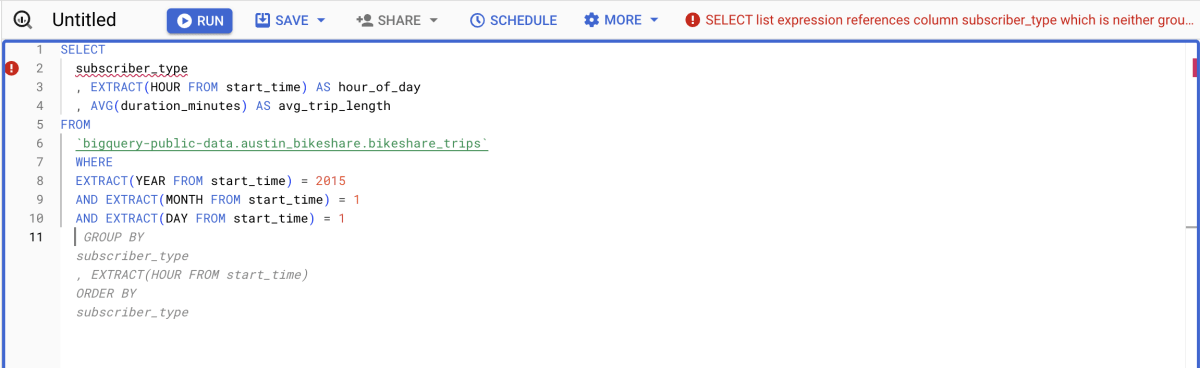
提案された内容を受け入れたところ、何やらエラーが出ています。このエラーは、GROUP BY 句での start_time の扱い方に原因があるので、修正する必要があります(今回は、hour_of_day に変更しました)。このように、生成された内容には誤りを含むことがあるので、正しい内容かきちんと確認する必要があります。
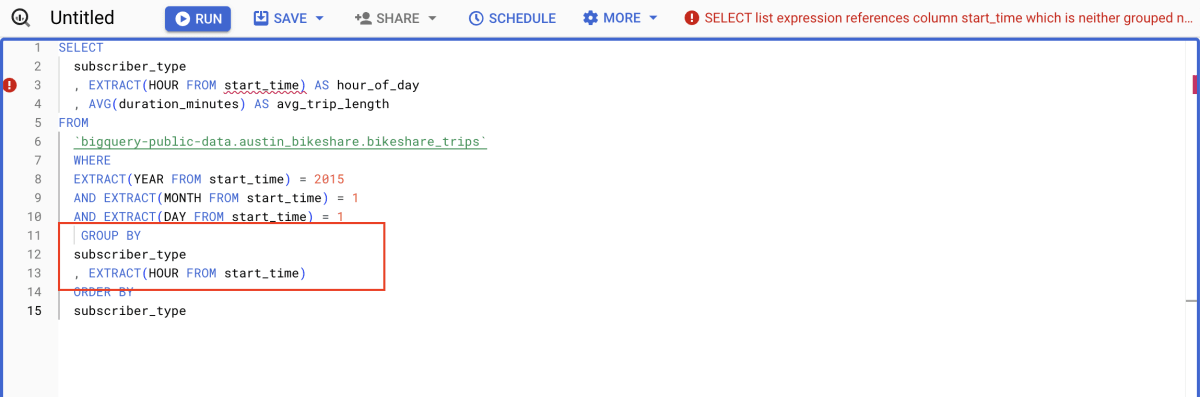
修正したクエリは、以下のようになります。

ちなみに 2 番目に提案されていたクエリは先ほど修正したものと同じものでした。生成された内容は、一応すべて目を通した方がいいかもしれません。

試しにプロンプトでクエリを補完してくれるか試してみました。ここではトレンドデータを日本のデータで絞り込もうとしました。
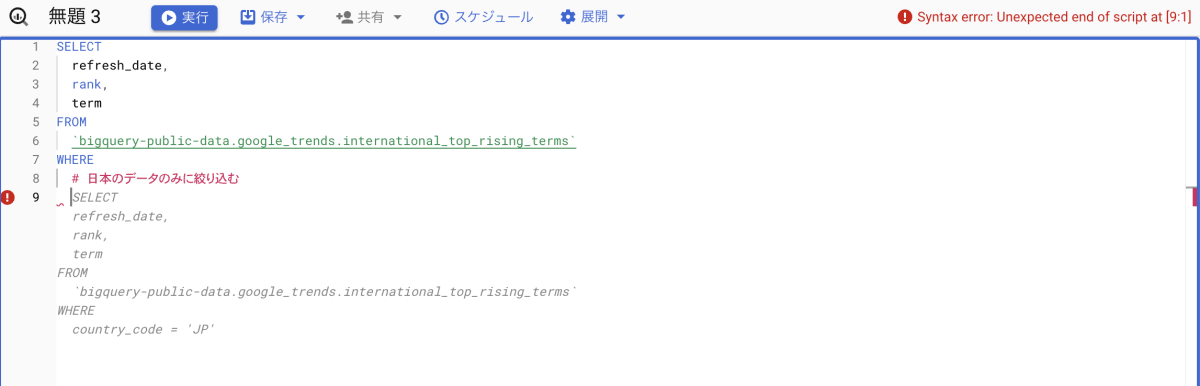
WHERE 句を補完してくれる予想でしたが、クエリ全体を生成するという結果でした。この結果から、プロンプトによるクエリ補完はできないことがわかりました。
SQL クエリの説明
次はクエリを説明してもらいましょう。ちなみにこの機能は、本記事執筆(2023 年 9 月 27 日)時点で環境言語を日本語に設定していると使うことができません。そのため、今回は環境言語を英語に設定して検証しました。
以下のクエリを説明してもらおうと思います。このクエリは、"bikeshare_trips" テーブルから加入タイプごとの平均利用時間を検索しています。
SELECT
subscriber_type,
CAST(avg(CAST(duration_minutes as BIGNUMERIC)) as INT64)
FROM
`bigquery-public-data.austin_bikeshare.bikeshare_trips`
GROUP BY
subscriber_type
クエリを説明してもらうには、説明してほしいクエリを選択した状態で、左側に出てくるペンのマークをクリックするだけです。

ペンのマークをクリックすると、画面右側に Duet AI ペインが開き、クエリを説明してくれます。出力結果は以下のとおりです。
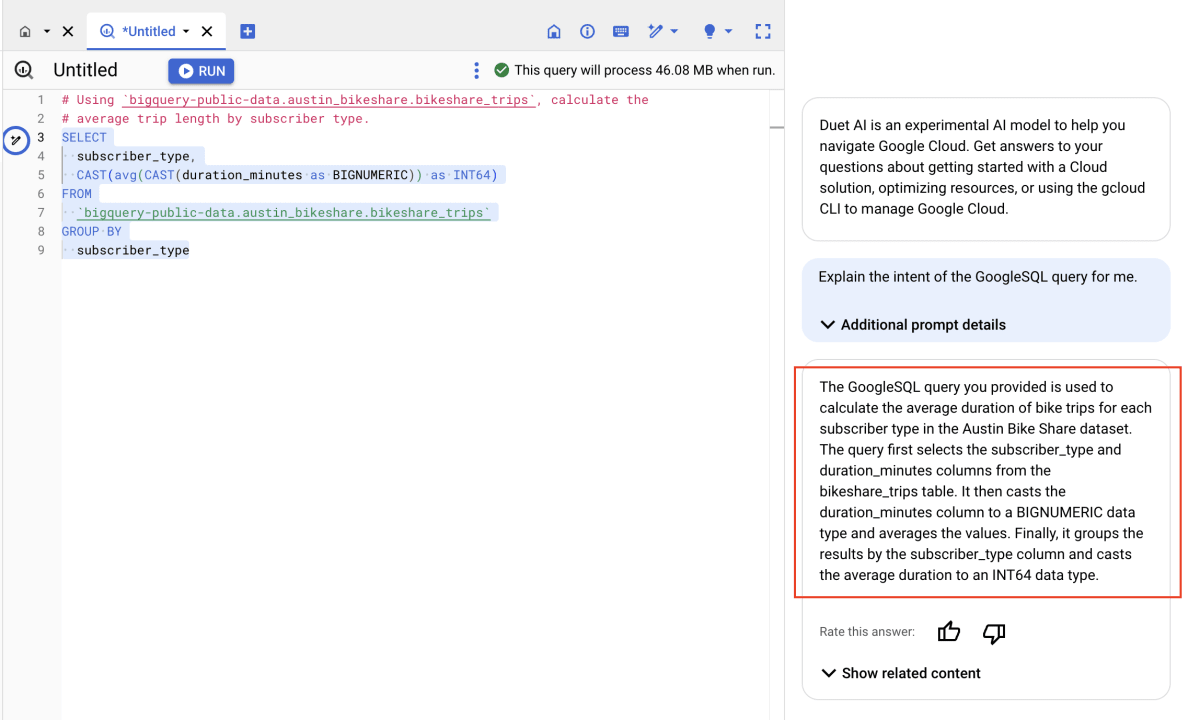
| 出力結果 | 日本語訳 |
|---|---|
| The GoogleSQL query you provided is used to calculate the average duration of bike trips for each subscriber type in the Austin Bike Share dataset. The query first selects the subscriber_type and duration_minutes columns from the bikeshare_trips table. It then casts the duration_minutes column to a BIGNUMERIC data type and averages the values. Finally, it groups the results by the subscriber_type column and casts the average duration to an INT64 data type. | ご提供いただいたGoogleSQLクエリは、Austin Bike Shareデータセットの加入者タイプごとに、自転車旅行の平均所要時間を計算するために使用されます。このクエリはまず、bikeshare_tripsテーブルからsubscriber_typeカラムとduration_minutesカラムを選択します。次に、duration_minutesカラムをBIGNUMERICデータ型にキャストし、値を平均します。最後に、subscriber_type列で結果をグループ化し、平均期間をINT64データ型にキャストします。 |
出力結果を日本語の翻訳にかけてしまったせいで subscriber_type の解釈が「加入者」となっていますが、それ以外は合っていると思います。処理過程も説明してくれているので、親切ですね。
まとめ
今回の記事では、Duet AI in BigQuery についてご紹介しました。
実際に使ってみた所感は、以下のとおりです。
- SQL クエリの生成
- SQL に詳しくなくてもプロンプトを記述することでクエリ発行ができるようになるため、データアナリストの方に活用いただけそうです。ただし期待するアウトプットを出すためには、プロンプトを具体的に書く能力が必要になります。
- SQL クエリの補完
- 自分でクエリを考える手間が省けるため、ある程度 SQL を知っているエンジニア向けの機能と言えそうです。ただし、正しく補完してくれるばかりではないため、SQL に精通しているエンジニアには現時点では必要がないかもしれません。
- SQL クエリの説明
- 例えば保守対象のクエリが読みにくい場合に、この機能に説明してもらうなどで利用できそうです。ただし、説明内容が正しいとは限らないので、自分の目でクエリを確認することは必要です。
Duet AI in Google Cloud 自体がプレビュー段階であり、生成結果に間違いを含んでいるなど性能面で不安が残りますが、GA になる頃にはパフォーマンスが向上しているのではないでしょうか。
特にクエリの生成は、検証しがいがあると思いますので、興味のある方はぜひお試しください。
Discussion