BigQuery の検索インデックスを試す
TL; DR
- BigQuery には、検索インデックス機能というものがあります
- この機能を用いると、大容量のテーブルから文字列を抽出する際に、処理するデータ量と処理完了までの時間が大幅に削減されるかもしれません
検索インデックスとは
こんにちは、クラウドエース データML ディビジョン所属の田中です。
クラウドエースの データML ディビジョンは、クラウドエースの ITエンジニアリングを担うシステム開発部の中で、特にデータ基盤構築・分析基盤構築からデータ分析までを含む一貫したデータ課題の解決を専門としています。
先日機会があって BigQuery の検索インデックス機能を試してみましたので、今回の記事ではこの機能の概要とその結果をご紹介します。
BigQuery の検索インデックス機能は 2022 年 10 月 27 日のリリースにて GA(Generally Available: 一般提供)になった機能です。
BigQuery の検索インデックスを使うことで、テキストのような非構造化データやJSONファイルのような半構造化データから特定のデータを検索・抽出する場合のパフォーマンスが向上します。「インデックス」と聞くとリレーショナルデータベース(以下、RDB) におけるインデックスを想像される方もいらっしゃるかもしれませんが、BigQuery の検索インデックス機能は RDB におけるインデックスとは少し違ったものになります。
例えば公式ドキュメントでは、次のようなユースケースが紹介されています。
- BigQuery テーブルに保存されているシステムログ、ネットワーク ログ、またはアプリケーション ログを検索する。
- 規制プロセスに準拠するために削除するデータ要素を特定する。
- デベロッパーのトラブルシューティングをサポートする。
- セキュリティ監査を実施する。
- 選択力に優れた検索フィルタを必要とするダッシュボードを作成する。
- 前処理されたデータを完全一致で検索する。
たとえば公式ドキュメントにもあるように、EU における一般データ保護規則 (GDPR) の報告用にユーザーに関連付けられたデータの行を識別することに本機能を利用できます。
特徴
BigQuery における検索インデックスの特徴を紹介していきます。
BigQuery の検索インデックスと RDB におけるインデックスの違う点としては、次の2点が挙げられます。
- 検索インデックスが作成できる列のデータ型に制限がある
- BigQuery が検索インデックスを更新する
検索インデックスを作成できる列は次の4つのデータ型のみである旨が公式ドキュメントに記載されています。
STRINGARRAY<STRING>STRING型またはARRAY<STRING>型のネストされたフィールドを 1 つ以上含むSTRUCTJSON
また、検索インデックスは BigQuery によって完全に管理される旨が、公式ドキュメントに記載されています。検索インデックスの更新については、BigQuery が自動で実行します。
また、この記事を執筆した 2023年 8 月 22 日時点では、検索インデックスを GA で利用できるのは SEARCH 関数のみです。実は 2023 年 7 月 19 日のリリースで検索インデックスを =、IN、LIKE 演算子や STARTS_WITH 関数でもプレビューで使えるようになっているのですが、こちらはまだ試せていないので、別記事にてご紹介できたらと思っております。
(2023-11-09 追記)
記事を公開いたしました。こちらもぜひご覧ください。
料金体系
組織内部にある検索インデックスを作成したテーブルの総サイズがリージョンの制限以下の場合、検索インデックスを作成したり更新したりする際に発生する処理には料金がかかりません。
ただし、検索インデックスを保存するためにはストレージが必要であり、それに対しては費用がかかります。インデックスのストレージサイズを確認する際は、INFOMATION_SCHEMA.SEARCH_INDEXES ビューを利用します。
料金についての詳細は、公式ドキュメントも併せてご参照ください。
制限
この記事を執筆した 2023 年 8 月 22 日現在、検索インデックスには下記のような制限があります。詳しくは検索インデックスの概要や、割り当てと上限のリファレンスをご確認ください。
- ビューやマテリアライズド・ビューには検索インデックスを作成できません
- ビューやマテリアライズド・ビューの元テーブルに検索インデックスが作成されているならば、ビューに対して
SEARCH関数を実行することで、検索インデックスを利用したクエリが行えます
- ビューやマテリアライズド・ビューの元テーブルに検索インデックスが作成されているならば、ビューに対して
- 検索インデックスの作成後にテーブルの名前を変更すると、作成されたインデックスは無効になります
- 組織ごとに、インデックスを作成したテーブルの総サイズの上限が設定されています。US や EU マルチリージョンにテーブルが存在する場合の上限は 100 TB、 その他のリージョンであれば 20 TB です
- インデックス管理ジョブ(インデックスの作成・更新などのジョブをまとめた言い方のようです)に対して BigQuery のスロットを予約しておくことで、この制限は回避できます
-
SEARCH関数を利用しているクエリは、BigQuery BI Engine によって高速化されません- 日本語版公式ドキュメントには記載がございませんが、英語版公式ドキュメントの制限事項セクションに記載があります
- 1つのテーブルのサイズが 10 GB 未満の場合、検索インデックスは作成されません
- 検索インデックスは大規模なテーブルのための機能だからです
- もし検索インデックスを作成したテーブルのデータを削除しサイズが 10 GB 未満になった場合も、検索インデックスは利用不能になります。この際、作成された検索インデックスのためのストレージ料金はかからなくなるとのことです。再度データが増えてテーブルが 10 GB 以上のサイズになったら検索インデックスは利用可能になります
- こちらは公式ドキュメントの制限事項セクションには記載がありませんが、公式ドキュメントの「インデックスの更新について」に記載があります
本当に早くなるのか、試してみた
では、実際に検索インデックス機能を使ってパフォーマンスが向上するのか、試してみます。
今回はテキストがたくさん含まれたデータセットが必要なので、bigquery-public-data に収録の Wikipedia データセットの中にある、2022 年の Wikipedia ページビューデータを使ってみます。このデータは、各国語の Wikipedia においてどのページがいつ何回アクセスされたのかを保持しています。
このテーブルには論理サイズで約 2.13 TB、圧縮後の物理サイズでも約 360 GB ほどのデータが格納されています。
このテーブルのスキーマは以下の通りです。
- datehour: TIMESTAMP
- wiki: STRING
- title: STRING
- views: INTEGER
まず、こちらに対して検索インデックスを作成せずにフルスキャンをかけてみます。
今回は以下のフルスキャンをかけてみました。datehour 列でパーティション分割されたテーブルのため、WHERE 句で指定しています。
また、SEARCH 関数を使用することで、検索インデックス作成後に実行するクエリと条件を揃えてみました。ここで SEARCH 関数 の中で wiki 列の中に ja が入っているものを指定することで、日本語の Wikipedia ページの結果のみを抽出しています。
SELECT *
FROM {$my_project}.{$my_dataset}.pageviews_2022
WHERE SEARCH(wiki, "ja") AND datehour >= "2022-01-01"
ちなみに、単純にこちらを実行すると、クエリが失敗してしまう可能性があります。私の場合ですと、レスポンスサイズがクエリ結果を格納する一時テーブルに書き込めないほどのサイズだったため、失敗してしまいました。
この場合もクエリ自体は成功しているので、料金はかかります。

宛先テーブルに出力するように設定を変更し、大容量の書き込みを許容する設定にした上で、再度実行してみます。
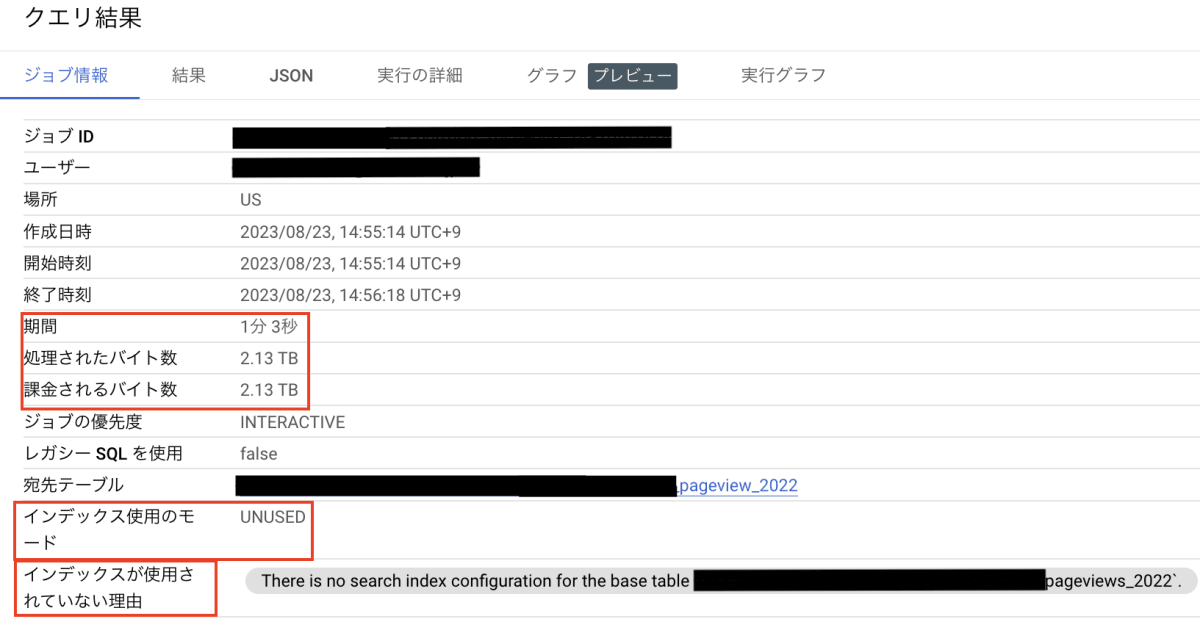
今度は成功しました。しっかり 2.13 TB 処理しています。
また、処理時間は 1 分 3 秒で、インデックスが(まだ作っていないので) UNUSED になっているのも確認できました。
検索インデックスの作成
では、pageview_2022 テーブルに対して検索インデックスを作成してみます。
ここで、検索インデックスを作成できる列にはデータ型による制限があったことを思い出す必要があります。今回は wiki 列と title 列にのみ、検索インデックスを作成できます。
検索インデックスの作成には、DMLの CREATE SEARCH INDEX 句を使用します。
pageview_2022 テーブルの wiki と title 列に検索インデックスを作成する場合、このようなクエリになります(今回実際に実行したクエリはさらに下に記載しています)。
CREATE SEARCH INDEX my_index
ON pageviews_2022(wiki, title)
my_index の部分はインデックスの名前です。ON の部分で対象テーブルの対象列を指定しています。ここでもし <STRUCT> 型の列を指定した場合、全てのネストされたサブフィールドに検索インデックスが作成されるようです。
なお、詳しくは公式ドキュメントを参照していただきたいのですが、CREATE SEARCH INDEX 句を利用する際に使用できるオプションが 2 つあります。
- 1 つめのオプションが
ALL COLUMNSです。ON pageviews_2022(ALL COLUMNS)のように書くことで、対応するデータ型がある全ての列で検索インデックスを作成します- もしテーブルの中の列が全て数値型など検索インデックスを作成できないものだった場合、クエリは失敗します
- 2 つめが
OPTIONSです。ここでは、BigQuery が検索インデックスを作成する際に、どのようなテキスト解析ツールを使うのかを 2 種類の中から選択できます-
LOG_ANALYZERがデフォルトのテキスト解析ツールです。詳細については、上記の「テキスト解析ツール」のリンク先からご確認ください - 2 つめの選択肢は
NO_OP_ANALYZERです。こちらはすでに前処理されたデータがあり、それに厳密に一致するデータを検索したいときに使うのがよいとのことです - (2023-11-09 追記) 3 つめの選択肢として、2023年 11 月 2 日のリリースにて、
PATTERN_ANALYZERが追加されました。
-
今回使用するデータはネストされていないものであるため、 OPTION(analyzer = 'NO_OP_ANALYZER') を指定して以下のクエリを実行します。
CREATE SEARCH INDEX my_index_2022
ON pageviews_2022(wiki, title)
OPTION(analyzer = 'NO_OP_ANALYZER')
問題がなければ以下のように、検索インデックスを作成した旨が表示されます。
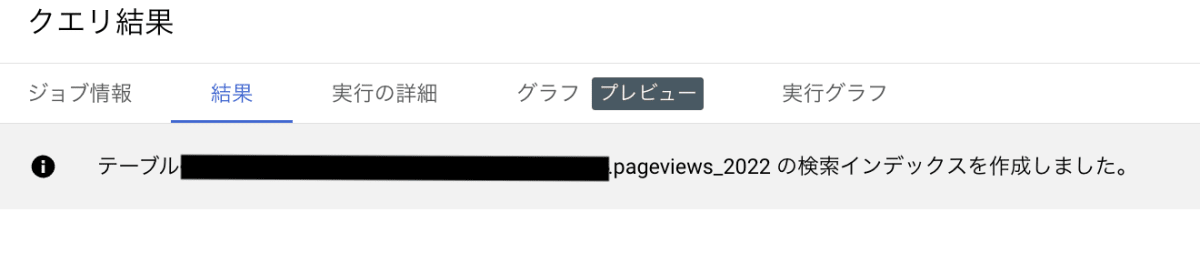
検索インデックス作成
検索インデックスが作成されたことを確認します。
検索インデックスについての情報は、INFORMATION_SCHEMA.SEARCH_INDEX ビューで確認できます。
このビューにどのような列があるのかについては公式ドキュメントをご覧ください。
今回はこちらのクエリを使ってこのビューの情報を確認しました。
SELECT last_refresh_time, table_name, index_name, DDL, analyzer, coverage_percentage
FROM {$my_project}.{$my_dataset}.INFORMATION_SCHEMA.SEARCH_INDEXES
WHERE index_status = 'ACTIVE'
last_refresh_time は検索インデックスが最後に更新された時間を記録し、まだ作られていない場合は null が返ってきます。また、coverage_percentage は、検索インデックスがテーブルデータのうちどれくらいをカバーしているのかを表します。
今回の場合ですと、検索インデックスを作成するクエリを実行してから coverage_percentage が 100 % になるまで、すなわち全ての対象列のデータに検索インデックスが作成され終わるまで、およそ 7〜8 分程度かかるようでした(約 1 分ごとに手動で上記クエリを実行した際の所要時間であるため、あくまで目安としてお考えください)。
検索インデックスの効果検証
さて、ではここで検索インデックスを有効にしたテーブルに対しクエリを発行し、実際に高速化しているのかを確かめます。
実行したクエリは以下のものです。今回は検索インデックス作成時に analyzer を NO_OP_ANALYZER にしている関係上、その指定する部分だけは追加していますが、その他の部分は上で試したフルスキャンと同じものです。
SELECT *
FROM {$my_project}.{$my_dataset}.pageviews_2022
WHERE SEARCH(wiki, "ja", analyzer => "NO_OP_ANALYZER") AND datehour >= "2022-01-01"
実行結果を確認してみましょう。
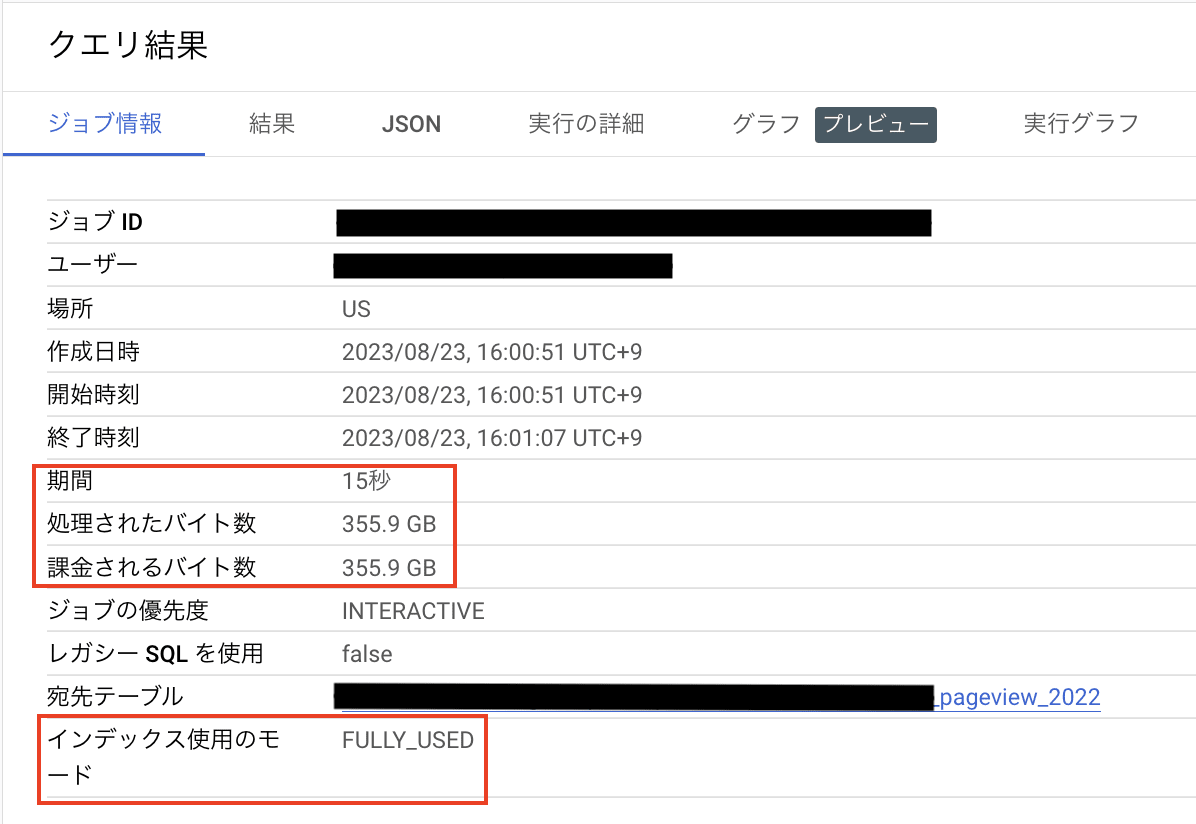
実行時間は 1 分 3 秒から 15 秒に、処理したデータ量は 2.13 TB から 355.9 GB に減少しました。
比較用に、検索インデックスを作成する前の結果を再掲します。
再掲
まとめ
この記事では BigQuery の検索インデックス機能の概要をご紹介し、実際に使ってみました。
検索インデックス機能は小規模なテーブルでは使用できませんが、大規模なテーブルから特定のデータを抽出する時にメリットがあります。今回の検証では、これまで 1 分 3 秒かかっていた処理が 15 秒で終了し、約 76 % 高速になりました。またクエリで処理したデータ量も約 2.13 TB から 355.9 GB と、処理したデータ量は約 83 % 減少しました。
最後までお読みいただきありがとうございました。この記事が何かの役に立てば幸いです。
Discussion