BigQuery の検索インデックスがさらに便利になりそうです
TL; DR
- BigQuery の検索インデックス機能を使えば、大規模なデータセットからごく少量のデータを取得する際の処理時間と課金されるバイト数がかなり削減できます
- この機能を一般的によく使われる演算子でも実行できるようになれば、日々の分析やログ検索におけるコスト削減に大きく貢献しそうです
はじめに
こんにちは、クラウドエース データML ディビジョン所属の田中です。
データML ディビジョンでは、Google Cloud が提供しているデータ領域のプロダクトについて、新規リリースをキャッチアップするための調査報告会を毎週実施しています。
新規リリースの中でも、特に重要と考えるリリースを記事としてまとめ、本ページのように公開しています。
今回紹介するリリースは、2023 年 7 月 19 日にリリースのあった、「 BigQuery の検索インデックスを、=、IN、LIKE 演算子や STARTS_WITH 関数でも使えるようになった」件についてです。
検索インデックスとは
BigQuery には、特定のデータ型(具体的には、下記の4つ)の列に対して作成できる、検索インデックスという機能があります。これを使うことで、クエリの処理時間が非常に高速化される、課金対象になるデータの処理量が削減されるなどの効果があります。
- STRING 型
- ARRAY<STRING> 型
- STRING 型または ARRAY<STRING> 型のネストされたフィールドを 1 つ以上含む STRUCT 型
- JSON 型
もちろん制限もあり、例えば最低 10 GB 以上のサイズがあるテーブルでないと利用できない、ビューやマテリアライズドビューに対してインデックスを作成できない(元になるテーブルには作成可能)などがあります。
検索インデックス機能については別の Zenn 記事でも説明・検証しておりますので、お読みいただけたら幸いです。
リリースの概要
再度申し上げますと、今回のリリースは、そんな検索インデックスを使ったクエリの最適化機能が、=、IN、LIKE 演算子や STARTS_WITH 関数でもプレビューで使えるようになった、というものです。
現在 GA(一般提供) で検索インデックス機能を使用できるのは、 WHERE 句に SEARCH 関数を用いている場合のみです。しかし、このプレビュー機能を有効化すれば、一般的によく使われる演算子や関数を使用している時でも、検索インデックスの恩恵を受けられます。
申し込みを済ませ、それが正常に受理されたならば、数日後に Google からプレビュー機能を有効化した旨のメールが届きます。私のところには、BigQuery Search Optimizations Preview enrollment successful といったメールが届いておりました。
これでプレビュー機能を使う準備はできました。
検証してみた
では、さっそく検証してみましょう。
下記の手順で検証を行います。
- 検索インデックスを作成する
- 検索インデックス有効化前後で、
=演算子を使用したクエリの実行速度と課金されるバイト数を比較する - 現在 GA で利用できる
SEARCH関数を使用したクエリと、=演算子を使用したクエリの実行速度と課金されるバイト数を比較する
2 では、検索インデックスを有効化する前後の違いを観察することで、検索インデックスそのものの効果を確認します。3 では SEARCH 関数を利用したクエリと = 演算子を利用したクエリの違いを観察することで、プレビュー機能の効果を確認します。
今回も以前の記事と同じく、検証には bigquery-public-data に収録の Wikipedia データセットの中にある、2022 年の Wikipedia ページビューデータを使います。
このデータは各国語の Wikipedia においてどのページがいつ何回アクセスされたのかを保持しており、論理サイズで約 2.13 TB、圧縮後の物理サイズでも約 360 GB ほどのデータが格納されています。
このテーブルを自身のプロジェクトのデータセットにコピーします。今回の記事では、コピーしてきたテーブルの名前を index_default_pageviews_2022 としています。
このデータを格納しているテーブルのスキーマは以下の通りです。
- datehour: TIMESTAMP
- wiki: STRING
- title: STRING
- views: INTEGER
この中で検索インデックスを作成できるのは wiki 列と title 列のみであり、今回はどちらの列にも検索インデックスを作成します。
検索インデックスの作成
では、検索インデックスを作成していきます。その際は、DML の CREATE SEARCH INDEX 句を利用します。
実際に実行したのは下記のクエリです。今回は wiki 列と title 列に検索インデックスを作成しました。
CREATE SEARCH INDEX my_index
ON index_default_pageviews_2022(wiki, title)
上記のクエリを実行すると、BigQuery が検索インデックスを作成してくれます。実際に利用可能になるまでは数分かかることがあります。
検索インデックス有効化前と後の比較
検索インデックスの作成も済んだので、クエリを実行して、その結果を比較するところから始めてみましょう。
検索インデックス作成前のデータは、もとの bigquery-public-data 上に存在するテーブルにクエリを実行することで代用します。今回は下記のクエリを実行しました。もとのテーブルが datahour 列でパーティション分割されているため、WHERE 句で指定しています。
SELECT *
FROM bigquery-public-data.wikipedia.pageviews_2022
WHERE title = "青葉区" AND datehour >= "2022-01-01"
結果は以下の通りです。
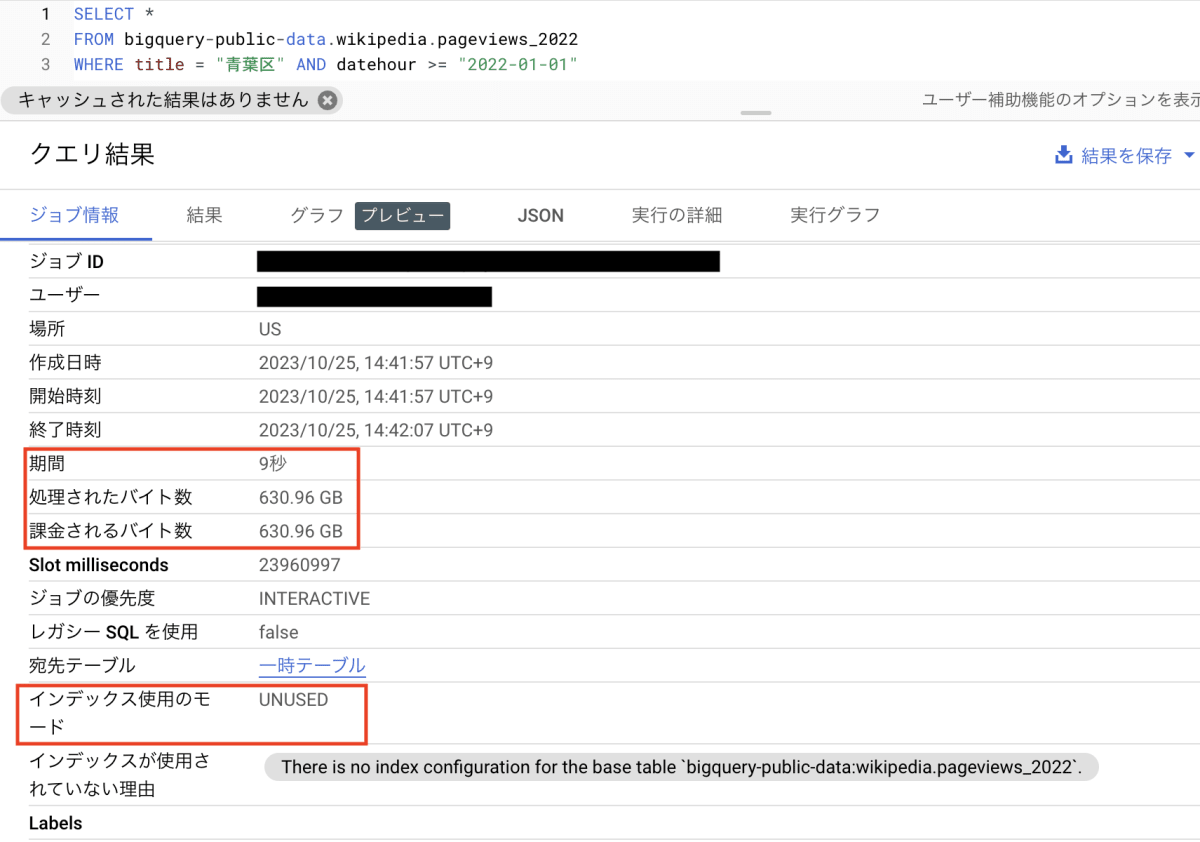
処理時間が 9 秒、課金されるバイト数は 630.96 GBでした。また、検索インデックスを作成していないテーブルに対してクエリを実行したので、「インデックス使用のモード」が UNUSED になっていることも確認できました。
では、検索インデックスを有効化したテーブルへ、FROM 句以外全く同じクエリをかけてみましょう。
結果はこちらです。自分のプロジェクト名が写っている部分だけマスクしています。
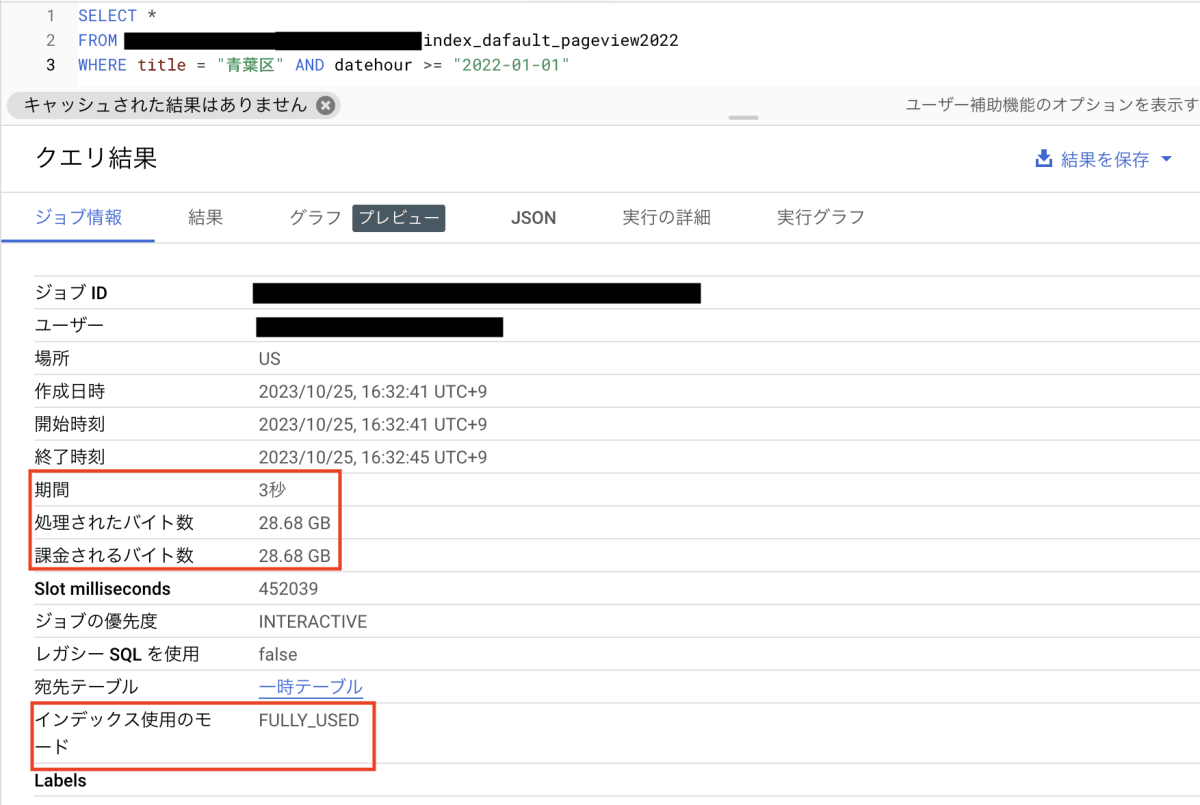
処理時間が 3 秒、課金されるバイト数は 28.68 GBとなりました。
検索インデックス有効化前後で、処理が終わるまでの時間が 1/3 程度に、そして課金されるバイト数はおおよそ 1/20 になりました。なお、何度かこのクエリを実行してみましたが、処理時間はインタラクティブクエリのためか多少変動がありました(ただし、最も処理時間がかかった時で 5 秒でしたが)。
この結果を見るだけでも、検索インデックスの効果がよくわかります。当てはまるユースケースをお持ちの方には、ぜひ使用をお勧めしたい機能です。
SEARCH 関数使用時と = 演算子使用時の比較
ここまでで、検索インデックスの効果はおわかりいただけたと思います。
次に、検索インデックスを使用できるもの同士の比較を行ってみます。現在 GA で検索インデックスを利用できるのは、SEARCH 関数です。これと = 演算子のパフォーマンスを比較し、そこに違いはないのかを確認してみます。
SEARCH 関数を使用したクエリを実行します。この場合、例えば下記のようなクエリになります。
SELECT *
FROM {my_project}.{my_dataset}.index_default_pageviews_2022
WHERE SEARCH(title, '青葉区') AND datehour >= "2022-01-01"
SEARCH 関数の第1引数には検索対象を、第2引数で検索する語句や文章を指定します。今回の例では、pageviwes_2022 テーブルの title 列の中に 「青葉区」 が入っているものを指定しているということです。
上記のクエリの実行結果はこちらです。
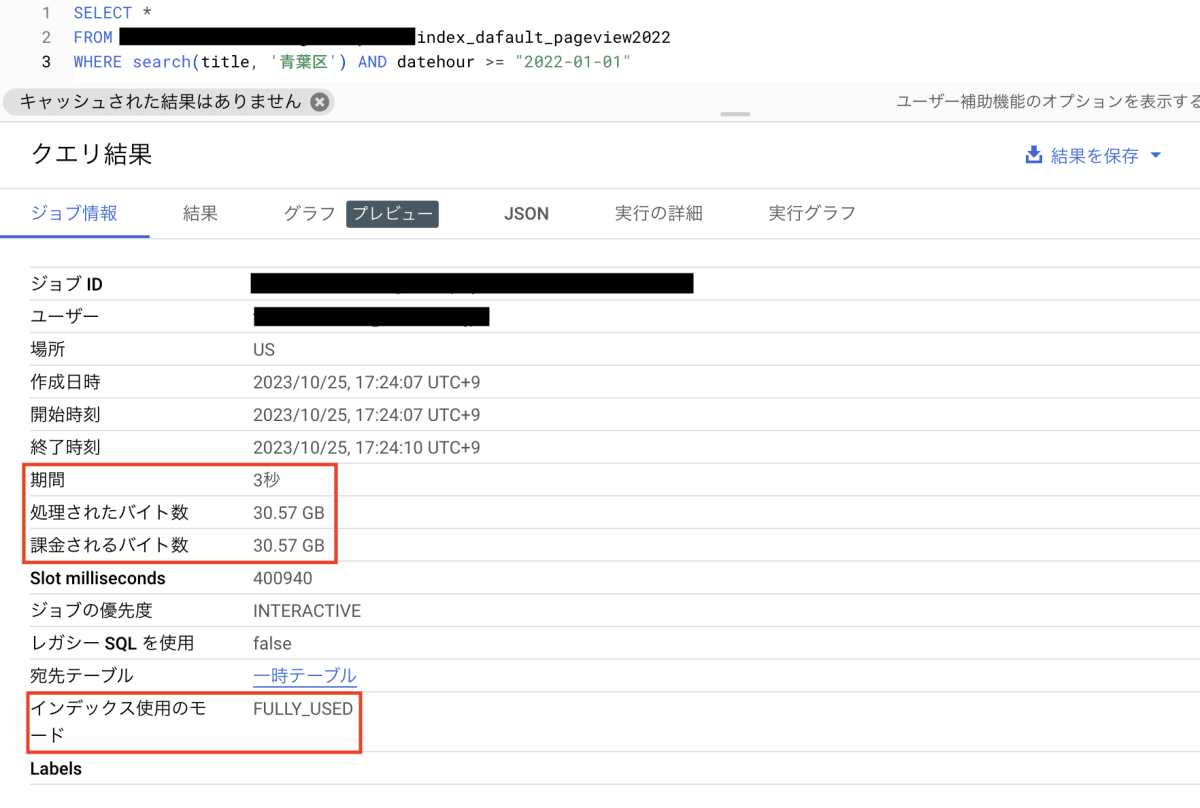
処理時間は 3 秒、課金されるバイト数は 30.57 GB となりました。検索インデックスは = 演算子の時と同じように FULLY_USED となっているのですが、課金されるバイト数に少し違いが出ています。同じ検索インデックスを利用しているはずなのに、どうしてこのような違いが生まれるのでしょうか。
個人的にとても不思議だったのですが、それには SEARCH 関数のしくみが関係していました。この話は検索インデックスの話からは少し外れるので、記事の最後に補足として記載しておきます。
まとめ
巨大なテーブルからごく少量のデータだけ欲しい時、そんな時に刺さる機能がこの検索インデックスです。
そのような機能が必要な場面としてパッと思い浮かぶのが、ログテーブルからある条件を満たすごく少量のログだけをピックアップしたい時です。例えば特定のユーザーの行動だけを確認したいときなどには、検索インデックスが大いに役立つと思います。
また、今回のプレビュー機能によって検索インデックスの効果を利用できる範囲が広がりました。わざわざ SEARCH 関数を使わなくてもよくなり、またそれによって色々なデータ抽出のニーズにも対応できるようになりました。個人的には、この機能の GA (一般提供) 化がとても楽しみです。
お読みいただきありがとうございました。この記事が何かの役に立てば幸いです。
補足: SEARCH 関数のしくみ
SEARCH 関数は高機能な検索関数です。どういうことかというと、テーブルの中のある 1 列だけではなく、テーブル全体などもっと広い範囲を検索の範囲にすることができます。
この SEARCH 関数では、トークン化された検索(tokenized search)というメカニズムが働いています。ここでのトークン化とは、英語のようにスペースやカンマといった単語と単語を区切る文字がはっきりしている言語において、ある文章を検索する際にそれら文字列を分解する方法だと思っていただければよいかと思います。大文字小文字は関係なく検索範囲の中にそのトークン(=テキスト解析器で分解された単語や文字列)が含まれているならば TRUE を返します。
公式ドキュメントには、トークン化する際のテキスト解析器として 3 つが紹介されています。デフォルトのテキスト解析器は LOG_ANALYZER です。
これを使用している時に、下記のように title 列に「(横浜市の)青葉区」というデータがある行の情報だけが欲しいとしましょう。
SELECT *
FROM {my_project}.{my_dataset}.{my_table}
WHERE SEARCH(title, '`青葉区_(横浜市)`') AND datehour >= "2022-01-01"
この時、検索結果には title 列が「青葉区_(横浜市)」のデータだけが返ってくるのではなく、「Category:青葉区_(横浜市)」や「ノート:青葉区_(横浜市)」といった title のデータも返してきます。
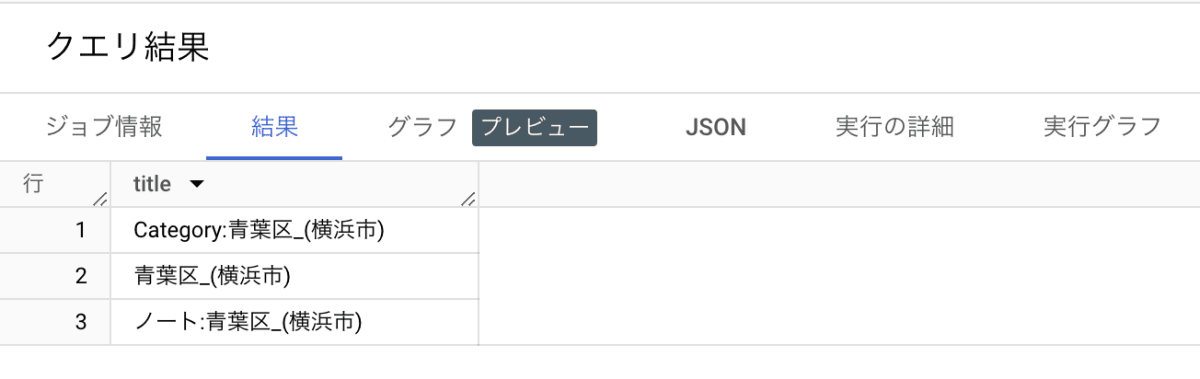
そして LOG_ANALYZER を使う限り、このようなケースで厳密に一致する結果だけを返すようにするのは難しいようです。
SEARCH 関数についてのより詳しい話は、Google Cloud の公式ブログ記事でも触れられておりますので、さらに興味のある方はこちらを読んでみるのもよいかもしれません。
まとめると、SEARCH 関数の場合は検索語句をトークン化し、それに合致するものを見つけます。これに対し、= 演算子では、LOG_ANALYZER を用いていても検索語句と厳密に一致する行のみ TRUE が返り、それらの行がスキャンされて検索結果に反映されます。このような検索時の振る舞いの違いが、SEARCH 関数を使用した時に課金されるバイト数が若干多くなる違いが出た原因だと考えられます。
Discussion