自然言語でデータ分析できる「BigQuery データ キャンバス」
はじめに
こんにちは、クラウドエース データソリューション部の坂田です。
先日、アメリカ・ラスベガスで、年に一度の大規模イベント「Google Cloud Next'24」が開催されました。
イベントの最大のテーマはやはり「生成 AI」で、生成 AI に関する様々な新しいサービスや機能が発表されました。
その中でも、今回は BigQuery データ キャンバス という BigQuery の新機能をご紹介します。
Next'24 の発表内容をさくっと知りたい方は ↓ をチェック
読んで欲しい人
- BigQuery を使ってデータ分析をしている方
- 生成 AI × データ分析に興味がある方
BigQuery データ キャンバスとは
BigQuery データ キャンバスとは、BigQuery データに対して、自然言語(日本語や英語)を使ってデータ分析を行うことができる機能です。
主に以下のような機能があります。
- 自然言語を解釈し、
SELECT FROMで表される SQL を生成する - 棒グラフや折れ線グラフ、散布図などのグラフを生成する
- グラフをカスタマイズする
- クエリ結果に対する簡単なサマリーを生成する
- テーブルやクエリ結果の関係性を DAG(有向非巡回グラフ)として表現する
- 作成したキャンバスを Jupyter Notebook としてエクスポートする
裏で Google の生成 AI「Gemini」が使われており、SQL の生成や可視化、サマリーの生成を行っています。

BigQuery データ キャンバスの画面
百聞は一見にしかずということで、実際に触ってみます。
触ってみる
事前準備
BigQuery データ キャンバスを使う前に、各種 API の有効化、ロールの付与が必要です。
以下のドキュメントを参考に、事前準備を行ってください。
BigQuery データ キャンバスにアクセス
Google Cloud Console の画面 > BigQuery > データ キャンバスを作成 をクリック
で、BigQuery データ キャンバスにアクセスできます。

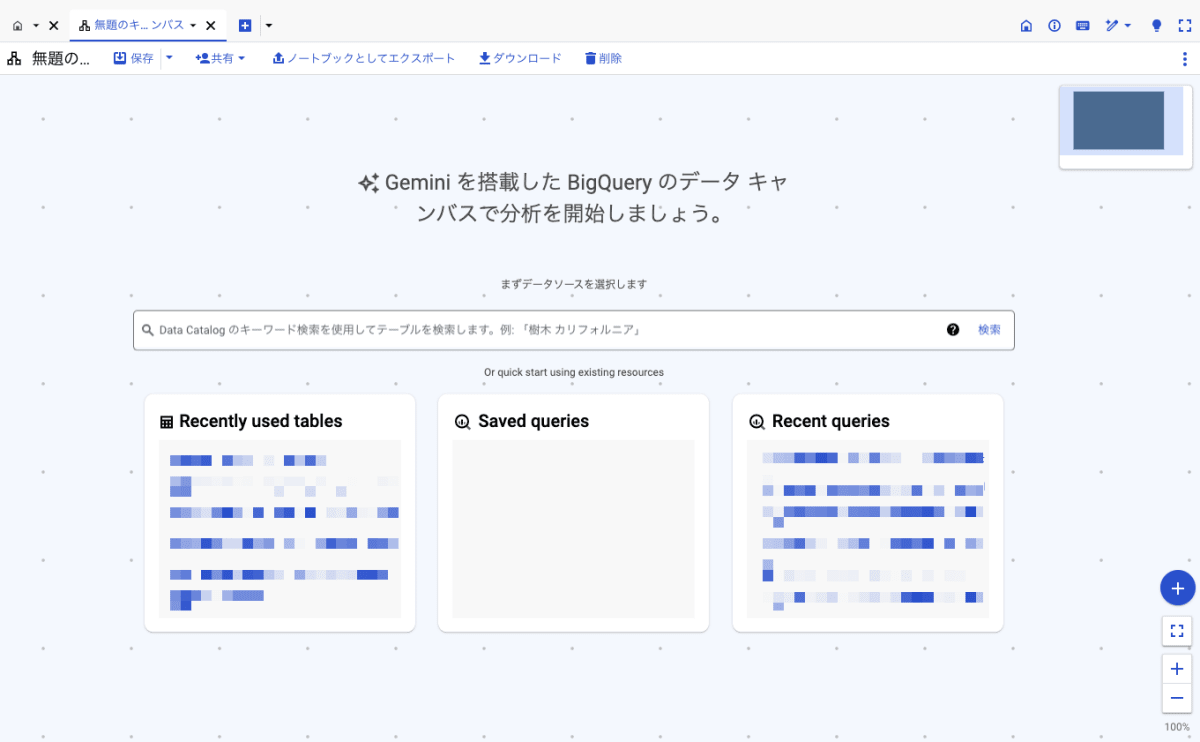
BigQuery データ キャンバスの画面
テーブルを検索
まず、どのテーブルに対してクエリを実行するかを決定します。
画面中央の検索バーから、キーワード検索でテーブルを検索します。
今回は、BigQuery で一般公開データセットとして提供されている「NYC TLC Trips」を使います。
あらかじめ、自分のプロジェクトの BigQuery データセットに「tlc_green_trips_2022」テーブルを作成しておいたので、このテーブルを使用します。
このテーブルは、2022 年のニューヨークのグリーンタクシーの乗車情報が格納されています。
「new york」というキーワードを入れるとテーブルがヒットしたので、ADD TO CANVAS を押します。
テーブルのスキーマやデータのプレビューを確認できます。
もし複数テーブルにまたがった分析を行いたい場合は、対象テーブルにチェックを入れ、左下の JOIN を押すと、複数テーブルを JOIN した SQL を生成できます。
クエリを生成
テーブル情報の左下の クエリ を押すと、入力欄が表示されます。
ここに「どのような分析を行うか」というプロンプトを入力すると、それを実現するための SQL が生成されます。
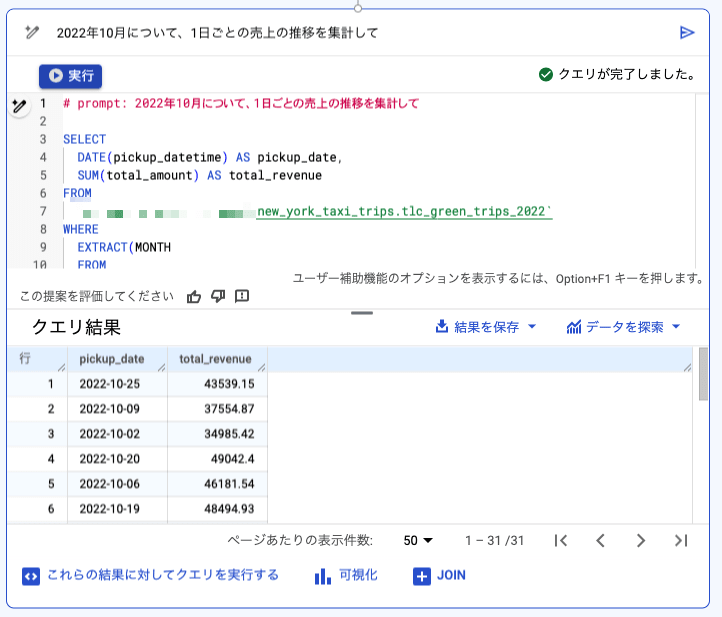
例えば、「1日ごとの売上の推移を集計して」と入力したところ、以下のように生成されました。
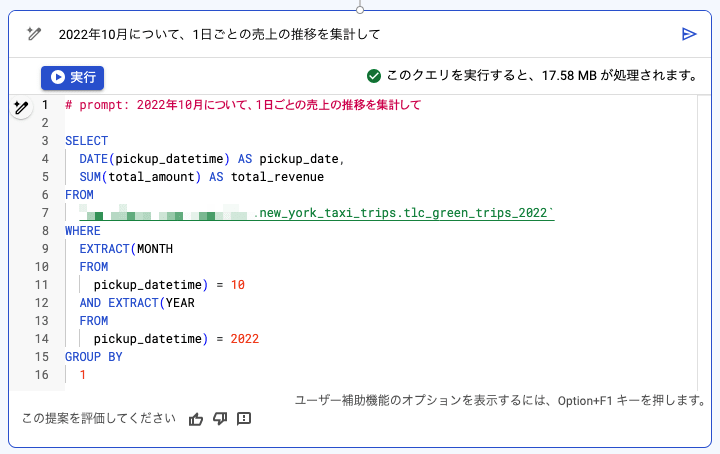
良い感じに SQL が生成されています。
このまま 実行 を押すと、クエリが実行され、結果が表示されます。
もし期待しない SQL が生成された場合は、文章を変えて再び生成させることもできますし、SQL を直接編集することも可能です。
クエリ結果の下側のボタンにあるように、クエリ結果に対する SQL を生成させたり、クエリ結果に対してテーブルを JOIN させることも可能です。
グラフを生成
クエリ結果の下側の 可視化 を選択すると、グラフを生成できます。
以下のような種類のグラフを生成できます。
- 棒グラフ
- ヒートマップ
- 折れ線グラフ
- 円グラフ
- 散布図
上記のようないずれかを選択して自動的に生成させるほか、自然言語を使って可視化の方法を指定することも可能です。
今回は自然言語で指定してみます。クエリ結果の下側の 可視化 をクリックし、カスタマイズされた可視化の作成 を選択します。
「折れ線グラフを作成して。線は緑色にして。」と入力すると、以下のように折れ線グラフが生成されました。

左下の EDIT を押すと、グラフのカスタマイズができます。
また、(英語ですが)グラフの特徴についてのサマリーも表示されます。
クエリをつなげる
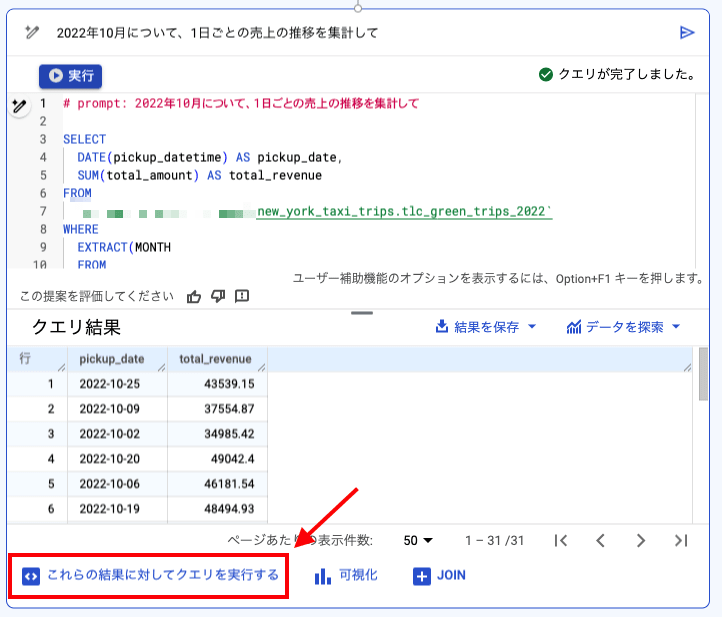
クエリ結果に対して、新たなクエリを生成することができます。
クエリ結果の下側にある これらの結果に対してクエリを実行する を押すと、新たなクエリを生成できます。
この機能を活用し、チェーンつなぎのイメージでクエリをつなげることで、サブクエリや WITH 句を使う場面が少なくなり、
- 探索的にデータ分析を行う(EDA:探索的データ分析を行う)
- 複数のステップから成る処理を行う
- 様々な分析パターンを試して比較する
といったことを直感的に行うことができます。
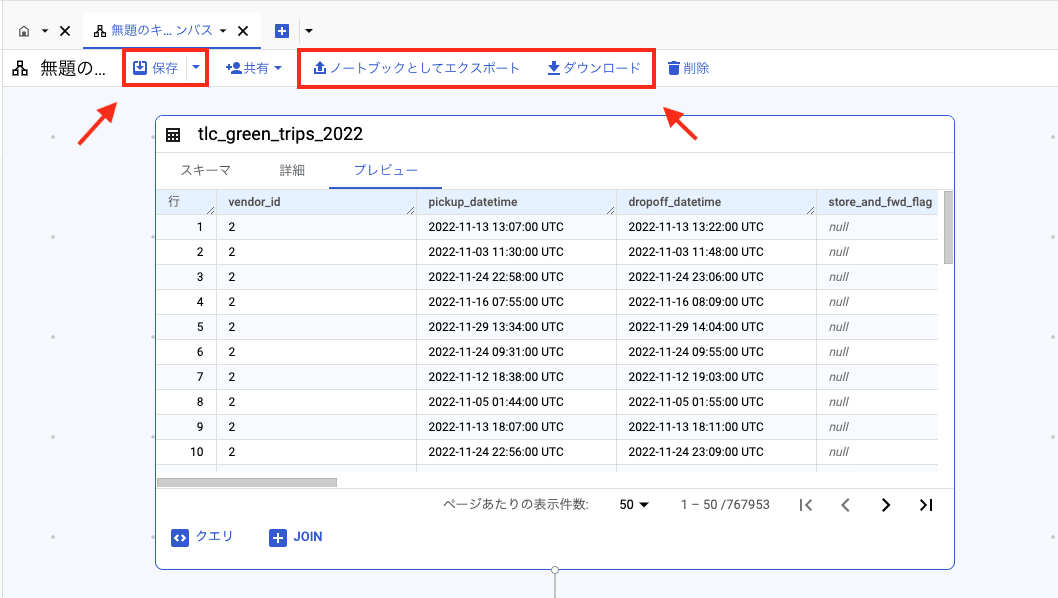
保存
作成したキャンバスは、BigQuery 上に保存できます。
また、Colab Enterprise やローカルに Jupyter Notebook としてエクスポートすることも可能です。
Jupyter Notebook では、キャンバスの内容が Python コードとして再現されます。
SQL 部分は BigQuery クライアントライブラリ、可視化部分は Altair(可視化ライブラリ)が使用されるようです。
精度検証
Gemini による SQL の生成の精度がどれくらいか、いろいろなパターンで試してみます。
検証 ① テーブル・カラムの説明文の有無
公式ドキュメントによると、Gemini は、テーブルのメタデータ(テーブル名、カラム名、データ型、テーブル・カラムの説明文)を元に SQL を生成しているとのことです。
BigQuery の Gemini は、アクセス権限のあるテーブルのメタデータにアクセスできます。これには、テーブル名、列名、データ型、列の説明などが含まれます。BigQuery の Gemini は、テーブル、ビュー、モデルのデータにアクセスできません。
参考:「Gemini と BigQuery のデータ - Google Cloud 公式ドキュメント」
そのため、カラムの説明文(Description)の有無が精度にどれくらい影響するかを検証します。
カラムの説明文が設定されているテーブルと、設定されていないテーブルを用意し、同じ文章を使って SQL を生成させます。
rate_code というカラムは、タクシーの運賃レートの区分(数字のコード)が格納されており、以下のような説明文になっています。
The final rate code in effect at the end of the trip. 1= Standard rate 2=JFK 3=Newark 4=Nassau or Westchester 5=Negotiated fare 6=Group ride
例えば、1 であれば「標準レート」で運賃計算されたことを意味します。説明文がなければ、運賃レートのコードの対応付けがわからないため、正しい SQL が生成されない可能性があります。
では、「2022年10月について、1日ごとに、標準レートの料金の合計を算出して」という文章でリクエストしてみます。
説明文ありテーブル
以下のように生成されました。

WHERE 句に rate_code = '1' が設定されており、正しい SQL が生成されています。
説明文なしテーブル
以下のように生成されました。

rate_code = '1' がなく、「標準レートの料金」という条件を反映できていません。
おそらく、カラムの説明文がないため、「標準レート」→ rate_code = '1' という対応付けがわからないためだと思われます。
結果
テーブルやカラムに説明文を設定することで、SQL の生成精度が向上すると思われます。
検証 ② 様々な SQL のパターン
様々な SQL のパターンを検証します。
なお、検証 ① の説明文ありテーブルを使いました。
JOIN
JOIN を行うために、まずはキャンバス上に複数のテーブルを追加します。
はじめのテーブル選択において、対象テーブルをすべて選択し、JOIN を押すと、以下のような形でプロンプト入力欄が表示されます。

今回は、new_york_taxi_trips データセットの taxi_zone_geom テーブル(ニューヨークの地理情報)を追加し、JOIN してみます。
「pickup_location_id と zone_id をキーとして内部結合する。乗車場所ごとに売上を合計し、乗車場所の名前、ID、売上合計について、売上の昇順で表示する。」という文章でリクエストしてみます。
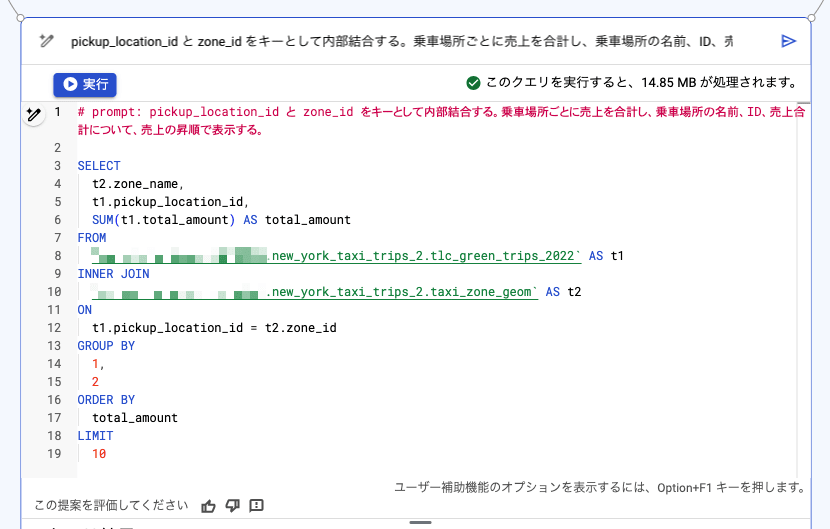
JOIN が正しく行われ、集計も正しく行われていることがわかります。
ウィンドウ関数
「すべての列とレートコードごとの平均を出して」という文章でリクエストしてみます。

「レートコードごとの平均」をウィンドウ関数を使って求めていることがわかります。
サブクエリ・WITH 句
「まず、ベンダーと日付ごとに売上を合計する。その結果に対して、ベンダーごとに売上を平均する。」という文章でリクエストしてみます。
一日の合計売上のベンダーごとの全体平均を求めるため、まず、「ベンダーと日付ごとに売上を合計する」をサブクエリ・WITH 句で求める必要があります。
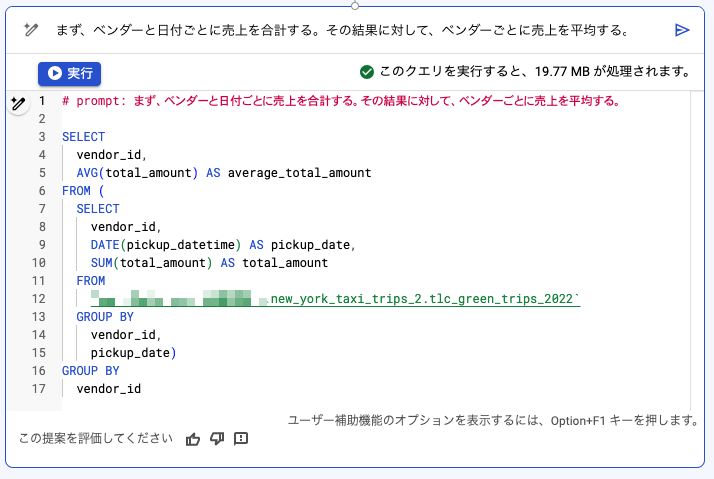
FROM 句の中でサブクエリが使われていることがわかります。
ただし、プロンプトを工夫しないと、サブクエリが必要な処理の SQL 生成は難しい印象でした。
精度を上げるためのコツ
精度検証の際、「期待するものとは違う SQL が生成された」「文法的に間違いのある SQL が生成された」という場合がありました。
精度を上げるためのコツをいくつか紹介します。
テーブルやカラムに説明文を設定する
Gemini はテーブルのメタデータを参照しており、データの中身は見ていません。
分析対象のテーブルにどんなデータが入っているのか、説明文にしっかり記載しておきましょう。
JOIN の条件を明確にする
JOIN を行う際は、「どのカラムをキーとして JOIN するのか」をプロンプトの文章に明記しておきましょう。
キーとなるカラムの名前がテーブルごとに異なる場合、JOIN の条件が明記されていないと正しく JOIN できない可能性があります。
プロンプトの文章を分かりやすい文章にする
感覚的には、SQL に近い文章ほど、生成精度が上がるようです。
ただ、SQL を意識した文章を書くのは本末転倒な感じがあるので、せめて以下のようなことに気をつけると良いと思います。
- テーブル名・カラム名・説明文に出てこないワードは使わない
(特にドメイン特有の用語は Gemini が知らない可能性がある) - 処理内容が明確になるように書く
なお、プロンプトを英語で書いても精度はそこまで変わらない印象でした。
複雑な処理は分割する
複雑な処理が必要なリクエストの場合、SQL の生成精度が落ちる場合があります。
今回の検証では、特に サブクエリや WITH 句を必要とする処理は、精度が落ちる傾向がありました。
BigQuery データ キャンバスには、クエリ結果に対するクエリを生成する機能があります。
この機能を活用し、1 回で複雑な処理を要求するのではなく、基本的な処理 → その結果に対する処理 → その結果に対する処理... という形で、複数のステップに分けることをおすすめします。
まとめ
今回は、BigQuery データ キャンバスをご紹介しました。この機能は、「BigQuery のデータに対して自然言語でデータ分析を行う」という、新しいユーザー エクスペリエンスを提供する機能です。
SQL に慣れていないユーザーでも、日本語を使ってデータ分析を行うことができるため、データ分析のハードルが下がることが期待されます。
ぜひ使ってみてください。
参考文献
Discussion