CUDA PythonではじめるCUDAプログラミング
1.はじめに
筆者はGPUプログラミングの勉強を進めています。GPU処理の背景にある仕組みを理解し、より効率的にGPUを利用できるようになることを目指しています。学習を進めながら並行して記事化を進めたいと思っており、同じような状況の人たちの役に立てると嬉しいです。
教科書は「Programming Massively Parallel Processors」(PMPP)を中心とします。この本の流れに沿って理論的な理解をすすめつつ、実験等を交えて一緒に理解を深められたら嬉しいです。
今回はGPUプログラミングの基本的な概念を整理のうえ、CUDAを用いた計算のコアとなる部分(CUDA Kernel)のシンプルな例であるベクトルを書いて、CUDA Pythonにより実行する手順を解説します。
本記事は今後の記事作成や私の理解の進展に応じて徐々に拡充・改修していきたいと思います。
2025/09/28追記
次回記事を作成しました、Grid-Block-Threadのマッピングを深掘りしています。こちらもぜひご参照ください。
2025/10/10追記
第3回記事を作成しました、GPU演算の本丸である行列積を解説・実装しています。
想定読者
- 本記事では、Pythonコーディングの経験を前提とします。
- C/C++やCUDAコーディングの知識は前提としませんのでご安心ください。
実行環境
- 筆者はUbuntu24.04LTS + RTX5060Ti 16GBの環境で検証しています
- NVIDIA GPUを所持している方は、CUDA実行環境を準備してください
- 環境整備方法はネットで複数見つかると思いますので、適宜ご参照ください
- NVIDIA GPUマシンが手元にない人向けに、AzureのVMで学習環境を用意する方法を別記事で紹介していますので、必要な場合ご参照ください(このAzure VM環境でも本記事のコードの動確をおこなっています)
CUDAプログラミング学習環境をAzureで構築する
2. 「GPUをうまく使う」とはどういうことか?
GPUはCPUと組み合わせて使うことが大前提です。CPU+GPUのように、複数種類のプロセッサを組み合わせた処理のことを異種混合コンピューティング(Heterogeneous Computing)と呼びます。よく述べられているCPUとGPUの差異は以下の具合かと思います。
- CPUは一連の処理を可能な限り高速に実行し、レイテンシを最小化
- GPUは数千の処理を並列で実行し、全体のスループットを最大化
これは、CPUとGPUのチップ設計に反映されています。以下はNVIDIA CUDA C++ Programming Guideに示された概念図です。
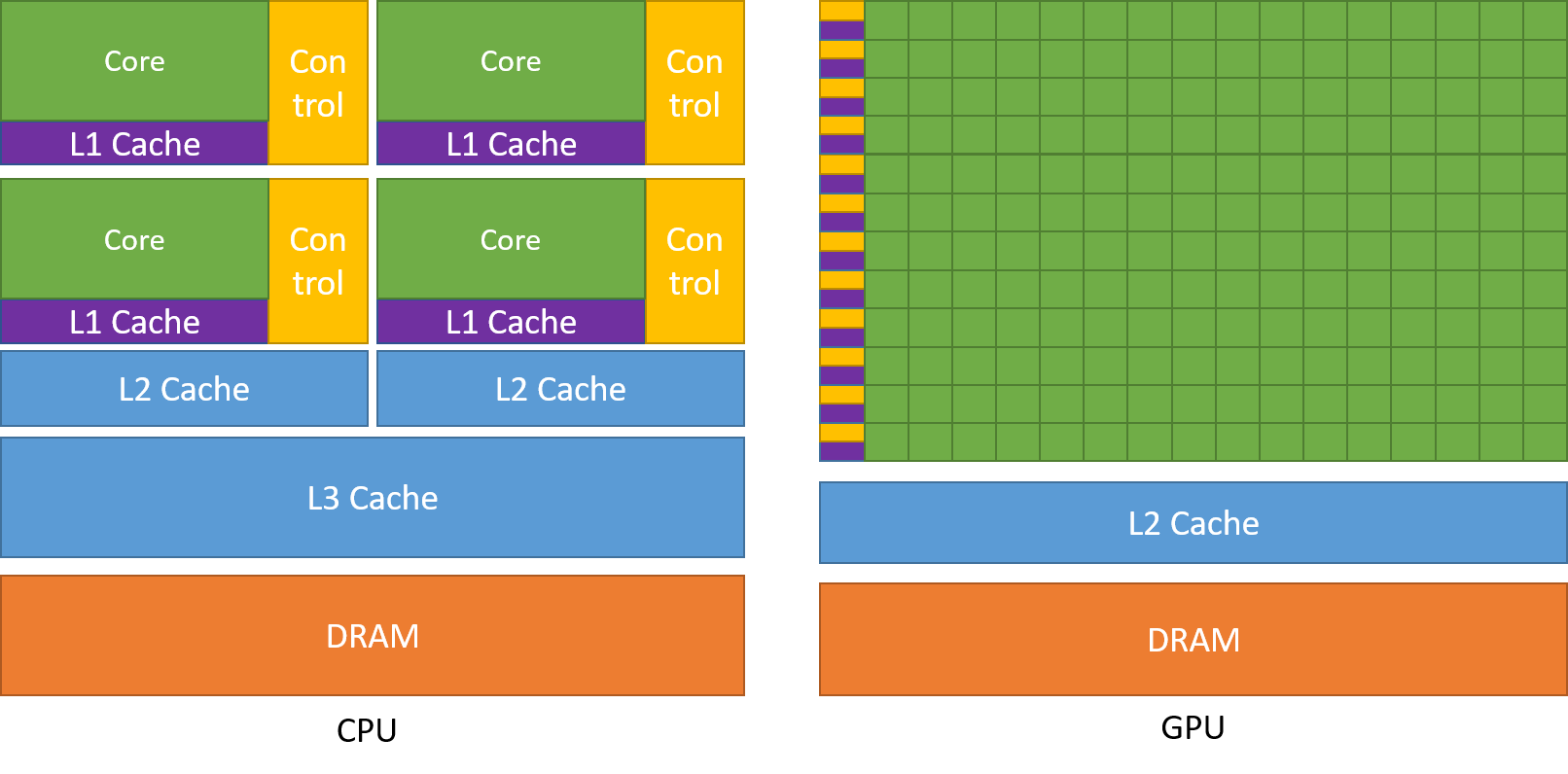
同程度のコスト(同程度のチップサイズ、トランジスタ密度)で比較する場合、チップの面積を何に割り当てるかがアーキテクチャ設計の鍵となります。上図を比較すると、CPUは以下の特徴があります
- 大きな制御ユニット(黄色)
- 分岐予測により、if文等の判定を待たずに先行して処理実行
- アウトオブオーダー実行により、処理実行順序を最適化
- より大きな演算コア(緑)
- 高いクロックサイクルの実現
- 複雑な演算を、専用回路により短サイクルで実行
- より大きなキャッシュ(紫、青)
- 大きなキャッシュにより、キャッシュヒット率を向上し、DRAMアクセスを最小化
一方、GPUは上記の点でCPUに劣るものの、画像からわかるとおり圧倒的な演算コア数を持ち、CPUと比較すると以下の点で優れています
- 同時実行できる処理数
- これはコア数が多いので自明でしょう
- 大きなメモリ(DRAM)バンド幅
- メモリ(DRAM)アクセスも処理の一つであり、並列実行できるのでアクセス全体のスループットも大きくなります
上記の設計の差異をふまえると、GPUをうまく使うということを一言で表すと
「メモリバンド幅を最大限活用しながら、大量の単純かつ均質な演算を、できる限り並列に実行させる」
ということになります。
3. CUDA Pythonとはどういうものか
3.1 なぜCUDAなのか?
GPUプログラミングを行える言語はCUDAに限らず、OpenCLやMetal(Mac用)など複数ありますが、少なくとも教育コンテンツの充実具合でいうならCUDAにかなうものはないでしょう。そのため、GPUプログラミングの学習環境としてはCUDA+NVIDIA GPUを当面想定します。
ただ、GPUプログラミングに必要なエッセンスは言語(環境)でおおよそ似通っていると言われています。そのため、ある程度基礎的な概念をカバーした後は、他の言語にもターゲットを広げたいと思っています。
具体的には、私はApple Silicon Macも所有しているので、MetalによるGPUプログラミングもゆくゆくは紹介したいと思います。
3.2 Python×CUDAの選択肢
PythonでGPUを利用する方法は複数存在します。一番よく使われるのはPyTorchなどディープラーニングのフレームワークだと思います。ただ、ここではGPUプログラミングを深掘りするために、より低いレイヤーのライブラリを用いたいと思います。
ここでは、CUDAコードをPythonから利用できるCUDA Pythonエコシステムを取り上げたいと思います。CUDA Pythonは、以下のような抽象度の異なるインターフェースを提供しています
| ライブラリ | 特徴 | 抽象度 |
|---|---|---|
| CuPy | NumPy互換のAPIで、NumPyと同様にコードを記述し実行することで、NumPyによる処理をGPU処理に置き換えることができる | 高 |
| Numba CUDA | PythonコードをCUDAコードに逐次コンパイルし、GPU実行できる | 中 |
| CUDA Python | NVIDIA GPU APIへ直接アクセスできる。また、プログラマが作成したCUDAカーネルを読み込んで実行できる。 | 低 |
CuPyやNumba CUDAは抽象化レベルが高く、Pythonの記載ほぼそのままでGPUが利用できます。ただし、抽象度が高いことの裏返しで、内部で何が起きているか見えにくくなります。そのため、当面はCUDAプログラミングのココロを理解するため、あえて低レベルなCUDA Pythonを使ってCUDA Kernelを実装することで、GPUプログラミングの本質に迫りたいと思います。
3.3 なぜCUDA Pythonなのか
今度は逆に、なぜフルCUDAではなく、Pythonと組み合わせる方法を採用したのかを説明したいと思います。
Peachモデル:効率的な最適化の考え方
PMPPで紹介されるPeachモデル(私が勝手に名付けました)を紹介します。これは、GPUプログラミングで効率化すべきターゲットを見定める上で示唆的な経験則です。以下の画像はPMPP図1.2の引用です。(A〜Dの記号は筆者追加)

この桃の実全体はプログラムの実行時間を示しており、その内訳がA〜Dに分かれているイメージです。教科書中では完全に解説されているわけではないので、各部分について筆者の想像も加えつつ解釈を記載します。
- A: CPUにより実行される領域で、本質的に直列(Sequential)な実行が必要領域。「齧っても固くて美味しくない種」の部分
- B: 並列化可能だが、CPUにより実行されているパート。「食べることはできるが、量は大したことがない、種にまとわりつく果肉」の部分
- C: 並列化が可能で、量が多い(実行時間の大部分を占める)部分。「齧ると美味しく、量も多いオイシイ果実」の領域で、ここがCUDA化し並列化するターゲット
- D: GPGPU(補足参照)でカバーされていた領域
話をシンプルにするために、B,Dの領域を無視して、桃がAとCの領域で構成されているとします。PMPPではさらに以下の重要な経験則が示されています
- 大抵のコードはAのパートが大半の行数を占めている割に、実行時間に占める割合はわずか
- Cのパートは実行時間の大半を占める割に、コード行数としては僅か
すなわち、コード行数としてはわずかなCのパートの部分を並列化することで、大きな果肉(実行時間の大幅な縮小)を食べられるということを示しています。
補足: GPGPU
従来のグラフィックス領域を超えて、汎用的な目的(General Purpose)で利用されるGPUの意図ですが、PMPPではさらに限定的に「グラフィックス用の命令セットを流用して汎用計算を行うこと」という趣旨で記載されています。歴史的な経緯なのでスルーで良いですが、興味がある場合は調べてみてください。
「なぜCUDA Pythonなのか」への回答
フルPythonのコードの改善を考えていくとき、上記のPeachモデルに照らすと、並列化可能な果実の領域はコード全体のうちごくわずかな行数のみで、そこを改善するだけで大きな効果が得られます。逆にコードの大部分を占める種の領域の時間短縮(C++やRustなどより早い言語へ書き換える、アルゴリズムを最適化する等)については、労力に見合わない可能性が高いです。
そのため、この果実の部分だけ集中的に並列化し効率化する方法が、学習効率に対して得られる効果が大きいと考えられます。また、GPUプログラミングの本質もこの果実の領域をいかに効率化するかなので、GPUプログラミングの本質の理解という意味でも効率的と想定されます。
上記の理由から、Pythonで一式記載されたコードをスタートとして、実行時間の大半を占め並列化可能な果実のコード部分について、CUDA PythonによりCUDAコードに置き換える方法を採用します。
4. CUDAプログラミングのことはじめ
4.1 CUDAで"Hello, world!"
CUDAによる処理を記載したコードはCUDA Kernelと呼ばれます。Pythonによる処理をGPUに置き換えるさいは、置き換える箇所の処理内容をCUDA Kernelに記載して、PythonプログラムからKernelを呼び出すことになります。並列化可能な極シンプルな例としてベクトル加算を扱いながら、Pythonによる直列処理をCUDA Kerneltに置きかえる流れを解説します。
なお、ベクトル加算はCUDAプログラミングにおける"Hello, world!"に相当するそうです。
Pythonによる逐次処理
ベクトルaとbを加算しその結果をcに格納する処理を、Pythonにてナイーブかつ明示的に記述すると以下のとおりとなります。
def vector_add_cpu(a, b, c, n):
for i in range(n): # 1つずつ順番に処理
c[i] = a[i] + b[i]
この処理に着目すると、各iに関する処理が独立していることがわかります(c[i]の計算にi-1など、i以外の添字が現れない)。直感的に想像できるように、このような処理は容易に並列化可能です。
CUDA Kernelによる並列処理
それでは、上記のPythonコードによる処理をCUDAで記載してみましょう。CUDAはC++を基本として書かれているため、CもしくはC++の経験がないとぱっと見面食らってしまうと思います。ですが、CUDA Kernelの記載のために理解すべきC/C++の文法はごく狭い範囲なので、いくつか例を見ていくことですぐになれると思います。
__global__ void vector_add(float *a, float *b, float *c, int n) {
// どのインデックスを計算すればいいのか確認する
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < n) {
// 実質的な処理の部分
c[idx] = a[idx] + b[idx];
}
}
このCUDA Kernelの本質的な計算処理はそこまで難しくないです。この計算を膨大な数の計算コア(処理ユニット)に割り振って実行します。CUDA Kernelを読み解くさいは、そのうちの1つの計算コアの気持ちになってコードの処理を追うとわかりやすいと思います。
まず、最初の関数名の定義および引数の設定についてです
__global__ void vector_add(float *a, float *b, float *c, int n)
初っ端から面食らうと思いますが、安心してください。どのようなカーネルを記載する場合も同様なので、ほぼ呪文のようなものと思って貰えば良いです。一応箇条書きで簡単に解説します。
-
__global__という識別子は、この関数がGPUで実行されるCUDAカーネルであることを示します。この識別子をつけない関数は普通のC/C++の関数となり、CPUで実行されます。 -
voidという識別子は、この関数自体は何も値を返さないことを意味します。CUDA Kernelの返り値は必ずvoidです。CUDA Kernelで処理する場合、その処理結果をどこに格納するかも明示的に指定する必要があります(本コードの場合は配列c)。そのため、いつも__global__ voidの組み合わせは変わらないので、一式の呪文として認識して問題ないです。 -
vector_addはこのカーネルの名前を定義しています。 -
float *a, float *b, float *cについての解説:- 関数の引数として、加算する配列
a,bと、処理結果の格納先のcをしています。 -
floatは配列の要素の値が浮動小数型であることを示します。 -
a〜cの前についている*は、a〜cの配列すべての値を渡すのではなく、a〜cの配列の開始位置のポインター(メモリのアドレス)を渡すことを示しています。
- 関数の引数として、加算する配列
-
int nは言うまでもなく配列の長さです。上記のとおり配列の開始位置しか渡していないので、配列の長さがわからないと計算コアはどこで処理を終了していいのかわかりません。
次に、計算コアは自分が配列のどのインデックスの計算を行えば良いのかを把握します。並列化された計算処理の最小単位はスレッド(Thread)と呼ばれ、1スレッドによりKernelが1回通して処理されます。あるスレッドは単一のコアにより処理され、一つのスレッドが複数のコアで処理されることはありません。
複数のコアにより複数のスレッドが並列に処理されますが、それらが好き勝手に配列の要素の処理を行っていたら、重複した処理や処理漏れが発生します。そのような事態を防ぐために、各計算コアに対してGrid, Block, Threadという3つの階層構造のインデックスにより処理を割り当てます。
今回の事例でこの割り当てを行っているのは以下の箇所になります。
int idx = blockIdx.x * blockDim.x + threadIdx.x;
本事例では配列がいくつかのブロックに区分されており、計算コアは「自分が所属するブロックの先頭のインデックスは何で(blockIdx.x * blockDim.x)そのブロックの何番目の要素(threadIdx.x)を計算するのかという情報に基づき、自分が計算すべきインデックス(idx)を計算する」という処理をしています。
blockIdx, blockDim, threadIdxはCUDAの組み込み変数なので、定義なしで使いますし、上書きは不可能です。このうちblockIdx, threadIdxについては、スケジューラーが値を割り振ったうえで、スケジューラーが計算コアに処理を割り振ります。
上記では非常にざっくりとGird, Block, Threadの階層構造について解説しましたが、記事を改めて解説を行いたいと思います。ここでは、計算対象のデータをGird, Block, Threadという階層構造に分けて、逐次GPUに投げて計算を行うことだけ把握しておいてください。
上記でどのインデックスを処理するかを確認しますが、ブロックの大きさblockDim.xは計算効率の観点で設定されるため、必ずしもデータを切りよく分割するようには設定されません。そのため、最後のブロックで計算したidxは一部が配列の大きさnからはみ出てしまいます。このようなインデックスを用いて計算を行ってしまうと、メモリの意図しない領域を読み込み、書き換えてしまう可能性があり危険です。これを防ぐため、idxがnを超えていないかのチェックを行います。
if (idx < n)
このようなチェックは境界チェックと呼ばれています。
境界チェックのあとは実際の計算です。このコードは特に説明不要でしょう。なお、配列の要素へのアクセス方法はPythonと同様です。
c[idx] = a[idx] + b[idx];
ここで注目してもらいたいのが、Pythonコードと比較するとforループがなくなっていることです。これは以下のような置き換えを行なっているためです。
Python: for文による繰り返しで計算
↓
CUDA: 一つの繰り返しをThreadとし、Grid, Block, Threadのインデックスにより多数の計算コアに分配
これが、直列処理をCUDA Kernelに書き換える基本的な考え方です。
4.2 CUDAプログラムの実行
前項ではCUDA Kernelを記載しました。ただ、当然Kernelだけではプログラムは動きません。以下で、Kernelを含む、プログラム全体の処理の流れを説明します。
CUDAプログラミングでは、CPU側のシステム(メインメモリを含む)をホスト、GPU側のシステム(GPUコアとVRAMを含む)をデバイスと呼びます。このようなCPUとGPUを組み合わせたシステムを異種混合(Heterogeneous)システムと呼びます。異種混合システムを概念的に表したのが以下の図です。CPUとGPUがそれぞれメモリを持つことに注目してください。
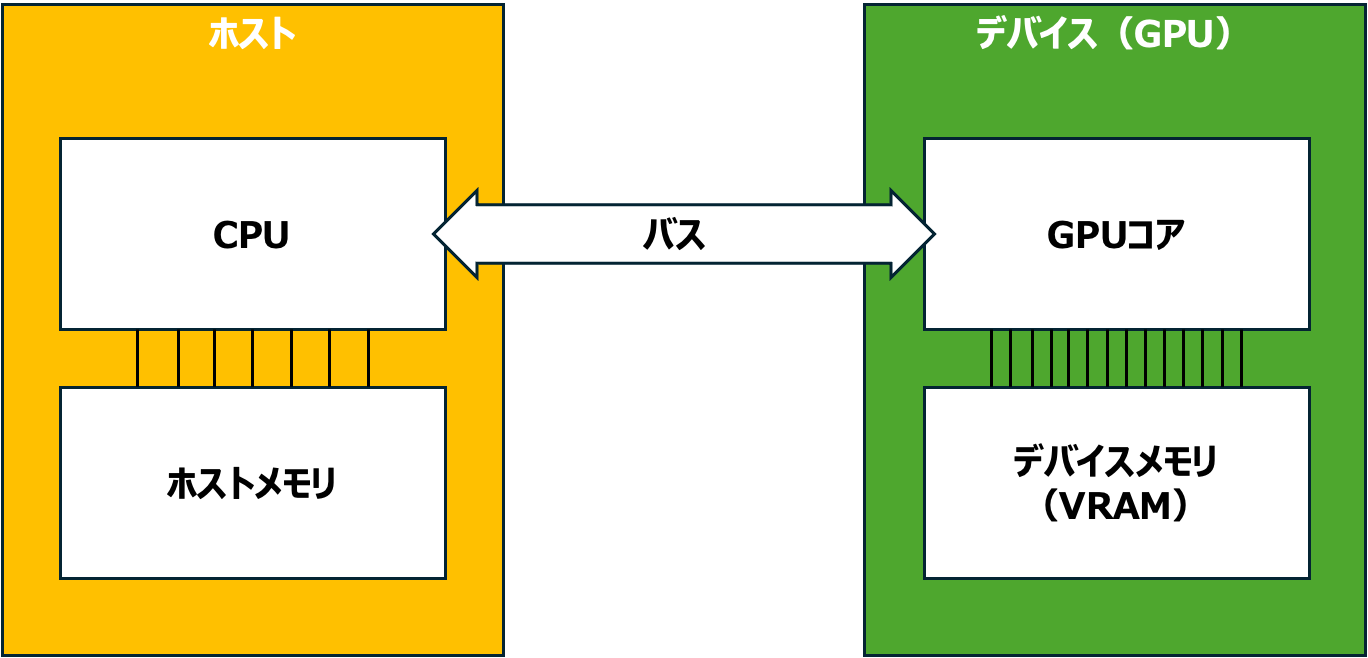
処理の流れ
異種混合システムでは、CPUとGPUがそれぞれ得意領域を担ってタスクを実行します。この典型的な処理の流れを追ってみましょう。
- ①処理の準備
- ライブラリ類のインポート
- デバイス(GPU)の情報取得
- Kernelの定義・コンパイル
- ②データの準備(ホスト側)
- ホストがSSDやファイルシステムから処理対象のデータを読み込み
- 必要に応じてデータの前処理や整形を実行
- ③ データの転送(ホスト→デバイス)
- ホストメモリ上のデータをデバイスメモリ(VRAM)へコピー
- ④カーネルの起動(ホスト側からの指示)
- ホストがGPUに対して実行すべき処理(カーネル関数)と、並列実行の構成(Grid-Block)を指定してGPUを起動
- ⑤ 並列計算の実行(デバイス側)
- GPUが多数のコアを使って並列に計算を実行
- ⑥結果の転送(デバイス→ホスト)
- デバイスメモリ上の計算結果をホストメモリへコピー
- ⑦後処理(ホスト側)
- 必要に応じて結果の集約や保存などの後処理を実行
この処理の流れにおいて、特にホストとデバイス間のデータの転送が必要になることを抑えておいてください。また、このホストとデバイス間のデータの移送は非常に時間がかかり、計算のボトルネックになりうることを覚えておいてください。
4.3 CUDA PythonによるCUDA Kernelの実行
それでは、前項で説明した典型的な処理の流れを、ベクトル加算の実例で実行してみましょう。
環境準備
CUDAの実行環境は用意されているものとします。環境がない場合は以下の記事等を参照ください。
CUDAプログラミング学習環境をAzureで構築する
最初に、CUDAのバージョンを確認します。
nvidia-smi
出力から「CUDA Version: XX.x」といった具合の表記を確認してください。上記のXXを以下のステップで指定します。
次にCUDA Pythonをインストールします。
pip install cuda-core[cu12] #「CUDA Version: 12.x」の場合
バージョン確認で「CUDA Version: 13.x」だった場合はcu13を指定してください。(指定しない場合は最新のcu13になるようです)
cuda.core公式サイト
また、ホストメモリ⇄デバイスメモリのデータ輸送にあたり、3.2で紹介したCuPyを使用します。
pip install cupy-cuda12x #「CUDA Version: 12.x」の場合
こちらも、CUDA Version: 13.x」だった場合はcuda13xを指定してください。
CuPy公式サイト
実行コード
コードは以下のようになります。コメントの①〜⑥は4.2の実行の流れと紐づけているので、見比べながら確認してみてください。また、ここまでで解説していない部分については丁寧にコメントを付与しましたので、読解に役立ててください。特に「①処理の準備」において初出のコードが多いですが、基本的にどのような処理でも同様な記載のため、何をおこなっているかの概念的理解で十分かと思います。
# ①処理の準備
## ライブラリのインポート
from cuda.core.experimental import Device, Program, ProgramOptions, LaunchConfig, launch
import cupy as cp
import numpy as np
import math
import time
## CUDAデバイスの初期化
device = Device() #インスタンスの生成。()内はデバイス番号を付与(省略の場合はデフォルト)
device.set_current() #ここでGPUをアクティブにする。
stream = device.create_stream() #ストリーム = GPU上で実行される処理の順序を管理するキュー
## CUDA Kernelのソースコード(先ほど解説したもの)
kernel_source = """
__global__ void vector_add(
float *a, float *b, float *c, int n
) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < n) {
c[idx] = a[idx] + b[idx];
}
}
"""
## カーネルのコンパイル
### コンパイル設定
capa = device.compute_capability #GPUの計算能力のバージョンを抽出
# CUDA Kernelで記載したC++のバージョンと、GPUアーキテクチャの指定
program_options = ProgramOptions(std="c++17", arch=f"sm_{capa.major}{capa.minor}")
program = Program(kernel_source, "C++", options=program_options) #コンパイル対象のCUDAコードをオプションとともに指定
module = program.compile("cubin", name_expressions=("vector_add",)) #コンパイル
kernel = module.get_kernel("vector_add") #カーネルの取得
# ②データの準備
n = 10_000_000 # 1,000万要素
a_host = np.random.rand(n).astype(np.float32)
b_host = np.random.rand(n).astype(np.float32)
# GPU計算時間の計測開始
start_GPU = time.time()
# ③GPUメモリへのデータ転送
a_device = cp.asarray(a_host)
b_device = cp.asarray(b_host)
c_device = cp.empty_like(a_device) # aと同じサイズの空の配列(計算結果の格納用)
# ④カーネルの起動
## カーネルの起動設定
block = 256 #1ブロックあたり256スレッド
grid = math.ceil(n/block) #n個のデータを全て処理するために必要なblockの数
config = LaunchConfig(grid=grid, block=block)
# ⑤計算実行
launch(
stream, config, kernel,
a_device.data.ptr, b_device.data.ptr, c_device.data.ptr,
cp.uint64(n)
)
device.sync() #GPU処理の完了を待つ
# ⑥結果の取得(計算結果をデバイスからホストに移送)
c_host = cp.asnumpy(c_device)
# GPU計算時間の算出
end_GPU = time.time()
time_GPU = end_GPU - start_GPU
# ⑦検証(CPUでも計算を実行し、結果と処理時間を比較)
## CPUで演算実行
start_CPU = time.time()
c_cpu = a_host + b_host
end_CPU = time.time()
time_CPU = end_CPU - start_CPU
print("成功!" if np.allclose(c_host, c_cpu) else "失敗")
print(f"GPU time: {(time_GPU):.4f}")
print(f"CPU time: {(time_CPU):.4f}")
実行結果
上記のコードを筆者のRTX5060Tiの環境で実行すると以下のとおりとなりました(5回実行の平均値)
| GPU[s] | CPU[s] |
|---|---|
| 0.0106 | 0.0015 |
ここまで苦労してCUDA実装を進めましたが、なんとCPU実行より7倍以上時間がかかる悲しい結果となってしまいました。
ただ、これには理由があります。4.2で説明したとおり、GPUによる計算実行のためにはホストメモリからデバイス(GPU)メモリにデータを移送し、また計算完了後には計算結果をデバイスメモリからホストメモリに移送する必要があります。4.2で示しましたが、このやり取りはバスを通じて行われ、他の演算等と比べ非常に時間がかかります。
このようにデータ転送に時間を要するわりに、ベクトルの足し算では移送したベクトルaおよびbの各要素は1回しか演算が行われません。そのため、並列化で演算自体をどれだけ高速化しても、ホスト⇄デバイスのバスを通じたデータのやり取りの時間が減らず、結果CPUに勝てません。
このあたりはメモリアクセスの最適化の紹介にて解説したいと思います。
行列積の場合
上記だとCUDAプログラミングのモチベーションが削がれてしまうので、よい知らせをお伝えしようと思います。
上記はベクトル加算の事例でしたが、同様なコード構成で4,096×4,096行列の積の演算を行うと、しっかりGPUの演算の方が早くなりました!
| GPU[s] | CPU[s] |
|---|---|
| 0.1202 | 0.2459 |
加えて、上記の実装は効率化を全く配慮していない極めてナイーブな実装によるものです。これから紹介していくチューニングにより、もっと効率化できますので、楽しみにしておいてください。
まとめ
本記事で、CUDAによるGPU処理の概要と、Pythonコードの処理の一部をCUDAによるGPU処理に置き換える方法を整理しました。残念ながら紹介したベクトル加算では効率化はできませんでしたが、これからもっと改善できる事例、およびチューニング方法を紹介していきたいと思いますのでご安心ください。
誤り等がありましたらご指摘いただけますと幸いです。
Discussion