agent調査
MSのagent UX
その解説
結構抽象的な話だった
論文ベースでめちゃくちゃいい資料
やっぱりLLMで信頼性を担保するのむずそう
ファインチューニングやプロンプトエンジニアリングでLLMが安定稼働するイメージが湧いてないだけかもしれない
信頼性に関しては機械学習全般の話かもしれない
全部参考になる



ちゃんと公式ドキュメントベースをまとめている記事でよかった
やっぱエージェントをちゃんと運用するのは辛そう
今何やってるかがわかる
出力の評価を見れる
エラーがちゃんとわかる
出力を再実行しやすい、人手で修正しやすい
↑のサイクルを回せるか
最新のベンチマーク
デザインパターン
LLMが反復的、段階的、自律的にタスクをこなすもの
自己改善 Reflecttion
ツール使用 Tool Use
計画 Planning
複数エージェントの協調 Multi Agent
論文ベース
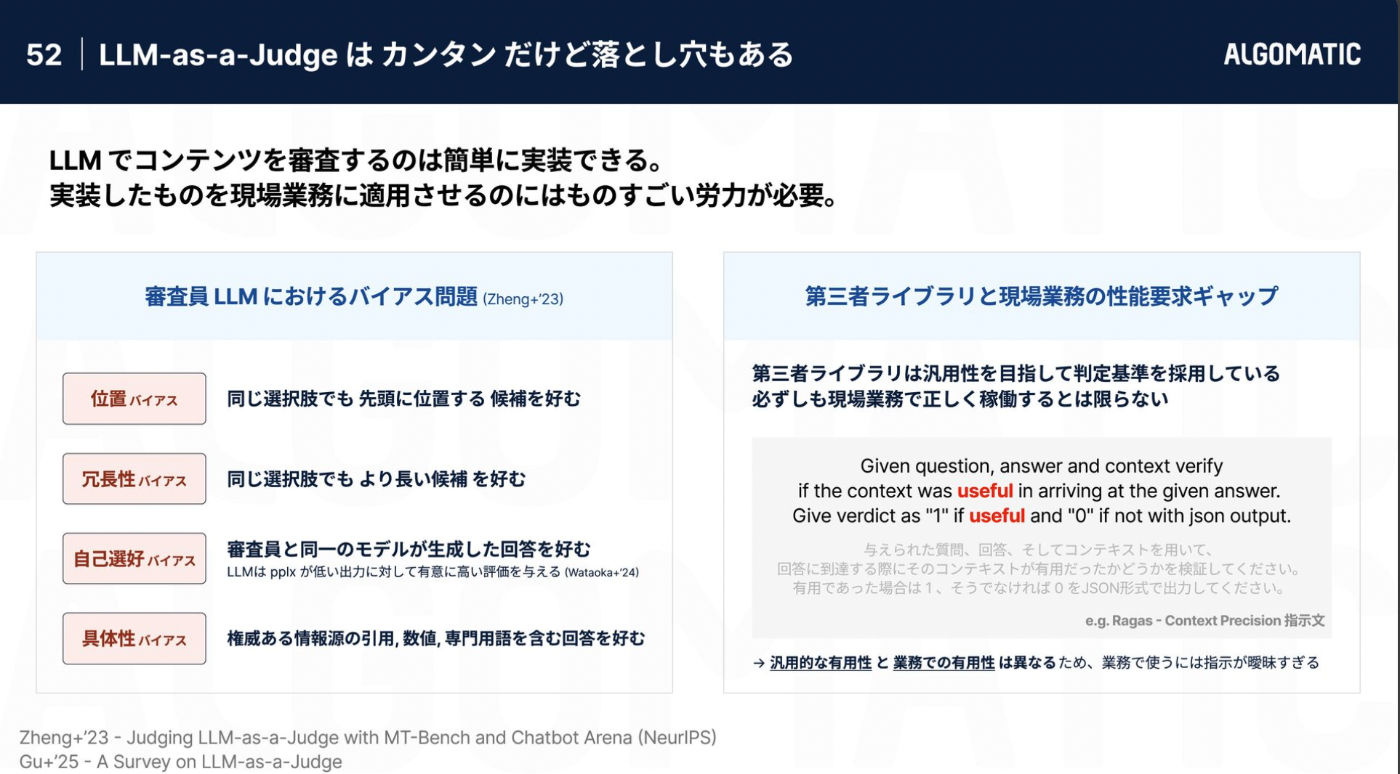
デザインAIのLLM as Judge
指標ごとに評価

KPI: 推薦枠内で発生する総CV(コンバージョン)数
オフ方策評価: 観測データのみに基づいて指標を推定する
- SNIIPS推定量: 新モデルと現行モデルの比の期待値
- Naive推定量: 新たな推薦モデルが出力するアイテムが観測データ上のアイテムと一致している場合に限り、データを評価に用いる、現行モデルを考慮しない
- DM推定量: 観測CVの発生確率をデータから学習し、明示的に組み込む
- DR推定量: 予測の一致 + 発生確率の予測値
独立性の仮定
自己正規化: 極端に小さい値をとる場合でも、全体の推定値が過大に影響を受けることなく、分散を効果的に抑制
OpenAI best practice
- 種別
- スコープ外の質問を遮断
- システムプロンプト漏洩遮断
- 個人情報流出の遮断
- モデレーション
- 書き込みなど危険なツールは一度人間の承認を挟む- コツ
- フィルターも専門化し、何層にもフィルタリングすることで精度を上げる
参考: https://commmune.notion.site/ML-DS-Casual-Tech-Talk-1d4d641ad082810aa321c3d20888cf13
日本語訳
- プロンプトをテストする
- コンテキストを効率良く使う、整形するコードあり
-
すべてはコンテキストエンジニアリングです - LLMに最良のインプットを提供することに重点を置きます
コンテキストには、プロンプト、指示、RAGドキュメント、履歴、ツール呼び出し、メモリが含まれます。
トークンの効率性とLLMの理解のためにコンテキスト形式を最適化します
標準的なメッセージベースのアプローチを超えたカスタムコンテキスト形式を検討する
最大限の密度と明瞭さを実現する構造情報
LLMの回復に役立つ形式でエラー情報を含める
LLM に渡される情報を制御する (機密データをフィルタリングする)
-
- 状態管理の統一
-
実行状態: 現在のステップ、次のステップ、待機ステータス、再試行回数など。
-
ビジネス状態: エージェント ワークフローでこれまでに何が起こったか (例: OpenAI メッセージのリスト、ツールの呼び出しと結果のリストなど)
-
- 起動/一時停止/再開
Webhook などの外部トリガーを使用すると、エージェント オーケストレーターと深く統合しなくても、エージェントが中断したところから再開できるようになります。
- human as tool
- Webhook, SMS, slackなど
- エラーをコンテキストウィンドウに圧縮する
- 自己修復 や 再実行
- 小規模なエージェント
- 管理可能なコンテキスト: コンテキストウィンドウが小さいほど、LLM のパフォーマンスが向上します。
- 明確な責任:各エージェントには明確に定義された範囲と目的があります
- 信頼性の向上:複雑なワークフローで迷子になる可能性が低くなります
- テストの簡素化:特定の機能のテストと検証が簡素化されます
- デバッグの改善:問題が発生したときにそれを簡単に特定して修正できます
- どこでも起動可能
- 人間以外の要因によって起動する
- 事前に指示する
-
モデルにどのツールを呼び出させたいか既に分かっている場合は、それらを決定論的に呼び出し、その出力をどのように使用するかを判断する難しい部分はモデルに任せましょう。
-
outerloop agent
ベストプラクティスはないけど
各自が疎結合するようにしてる
Adapterパターン
wrapper的な
疎結合
効率的な承認
承認の単位
いかに承認を効率化するか




インターフェースは1つ