2025年の年始に読み直したいAIエージェントの設計原則とか実装パターン集
はじめに
ビックテックからも次々とエージェント関連プロダクトがリリースされて、盛り上がりを感じる今日この頃です。
(バズワードと化してるともいう)
この盛り上がりの中で、1年前と比べるとAIエージェントをどう設計すべきか、そのパターンや知見も蓄積されつつあるように感じます。
今回は年始の時間を活かして、大抵の場合で共通に観測されるハイレベルなデザインや構造(計画・行動・評価のサイクル、メモリ/記憶、ツール連携など)ではなく、もう一歩踏み込み、軽量DDDのように実装に応用しやすいパターンやガイドラインの類を探してみました。
Building effective agents - Anthoropic
まずは、Anthropicが公開している「Building effective agents」です。LLMを活用したエージェント開発において、複雑なフレームワークに頼らず、シンプルで再利用性の高いパターンを組み合わせる方が効果的だと強調しています。
- エージェントの設計をシンプルに保つ: LLM + ツール呼び出し + フィードバックループが本質
- 計画ステップを明示的に示し、透明性を確保する: 計画ステップや意思決定プロセスを見える化
- エージェントの外部環境とのインターフェース(ACI: Agent Computer Inteface)を慎重に設計する
また「会話 + 行動」が同時に求められるケースで特に顕著ですが、各種ガードレールや検証体制がセットで組み込まれることが多く、人間による最終レビューやテスト結果のフィードバックを適切に取り入れることが、現実運用での成功要因と指摘しています。
(1/19追記) Anthropicの記事に登場するパターンを図・サンプルコードもセットで解説してくれるサイトがあります。
エージェントとワークフローの違い
Anthropicは「エージェント」について、以下の2つを広義の“エージェント的システム”と定義しながらも、構造上は分けて考えています。
- ワークフロー型 (workflow)
- LLMや外部ツールがあらかじめ定義されたコードパスで連携する
- どのようにタスクが流れていくかを、開発者が事前に設計
- エージェント型 (agent)
- LLMが動的に推論を行い、ツールを呼び出しながらタスクを遂行
- 必要に応じてタスク分割や意思決定の流れを自律的に変化させる
基本的には、シンプルなワークフローで十分な場面も多いが、複雑かつ予測不可能なステップを踏むタスクでは、エージェント型が力を発揮するとのことです。
使いどころとトレードオフ
Agenticシステムは、処理速度・コストといったリソースを多めに消費する代わりに、柔軟なタスク遂行や高いタスク成功率を得られるメリットがあります。
- シンプルなアプローチを優先: まずは単純なLLM呼び出しや最小限のリトリーバルなどを組み合わせ、十分な成果が得られるか試す
- 本当に必要な場合のみ複雑化: タスクが多ステップで高度化し、ワンショット推論ではカバーしきれないときに限り、ワークフロー型やエージェント型を導入する。
- コスト・速度 vs. 成功率: エージェント的システムはリソースを多く使う一方、タスク達成率の向上が期待できる。
ワークフロー/エージェントパターン
Prompt chaining:
- タスクを複数のステップに細分化し、順次LLMに処理させる。
- 使用例:マーケティングコピーの生成→他言語への翻訳
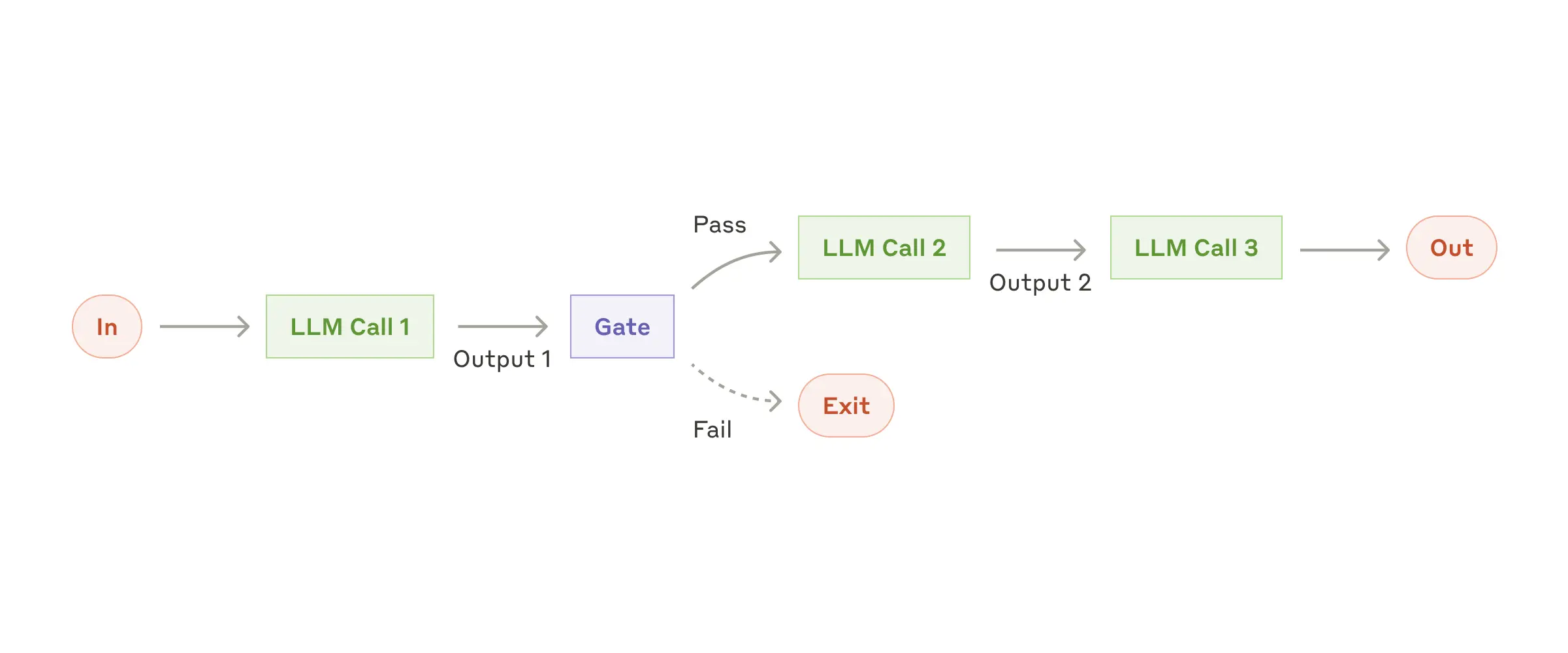
引用: https://www.anthropic.com/research/building-effective-agents
Routing:
- 入力を分類して、それぞれに特化したプロンプトやモデルへルーティングする。
- 使用例:カスタマーサービスの問い合わせ種別による振り分け
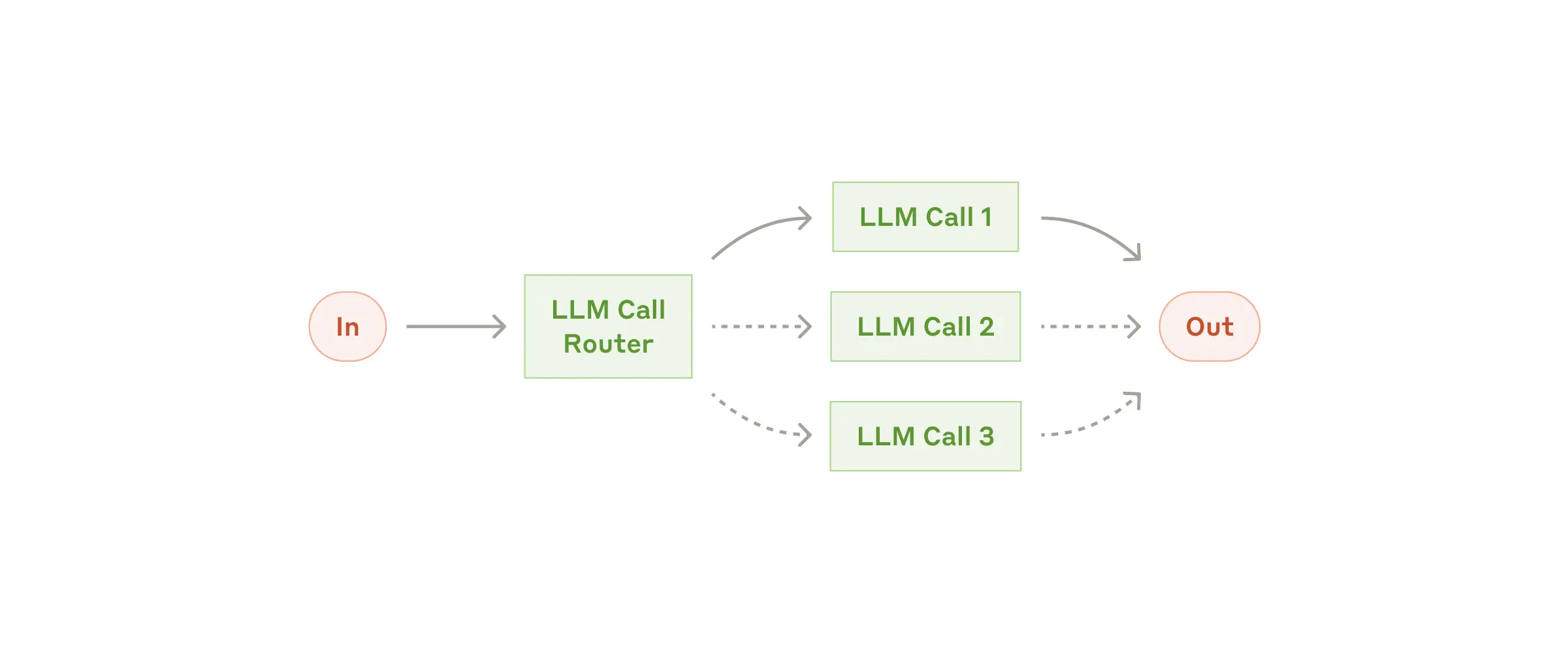
引用: https://www.anthropic.com/research/building-effective-agents
Parallelization:
- 複数のLLMコールを同時に走らせ、結果を集約する。
- Sectioning: タスクを独立した小タスクに分割して並列実行
- Voting: 同じタスクを複数回実行して多様な出力を取得
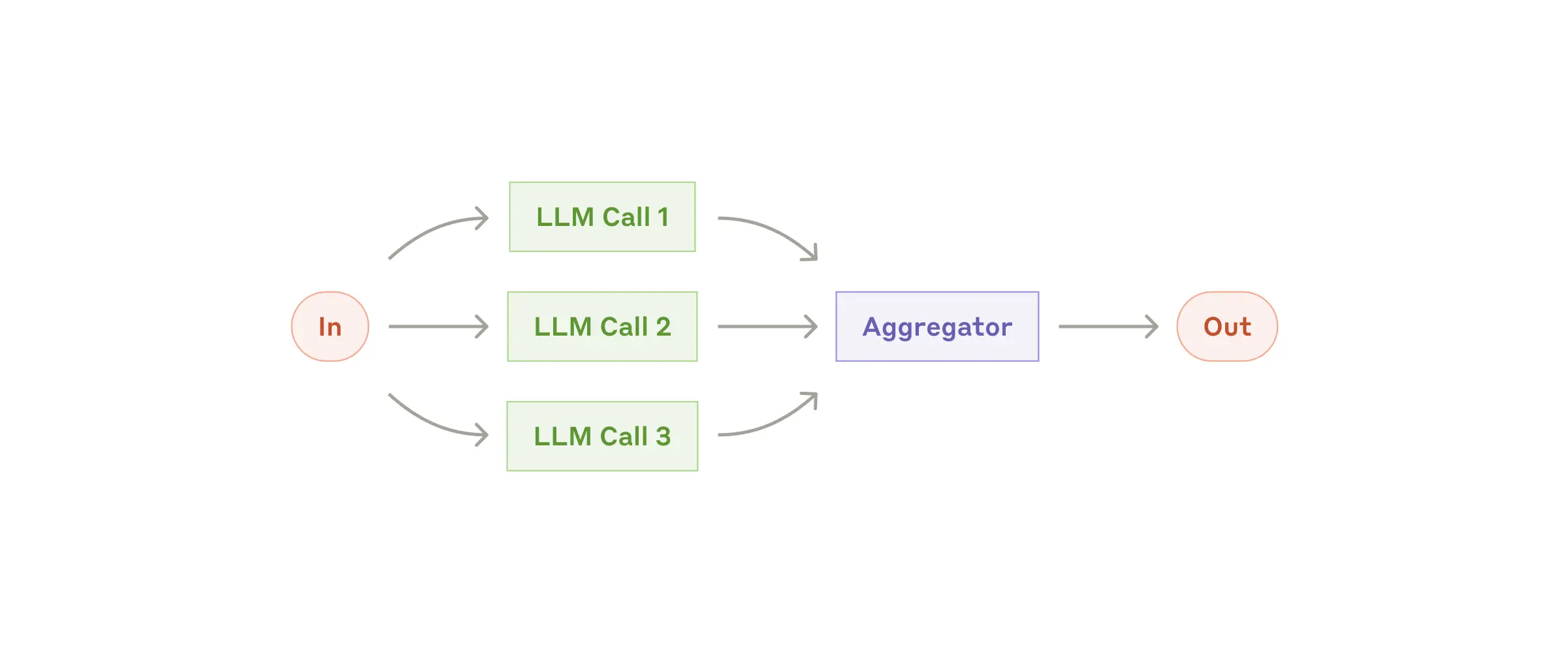
引用: https://www.anthropic.com/research/building-effective-agents
Orchestrator-workers:
- “オーケストレータ”となるLLMがタスクを分解し、必要に応じて他のLLMに割り振る
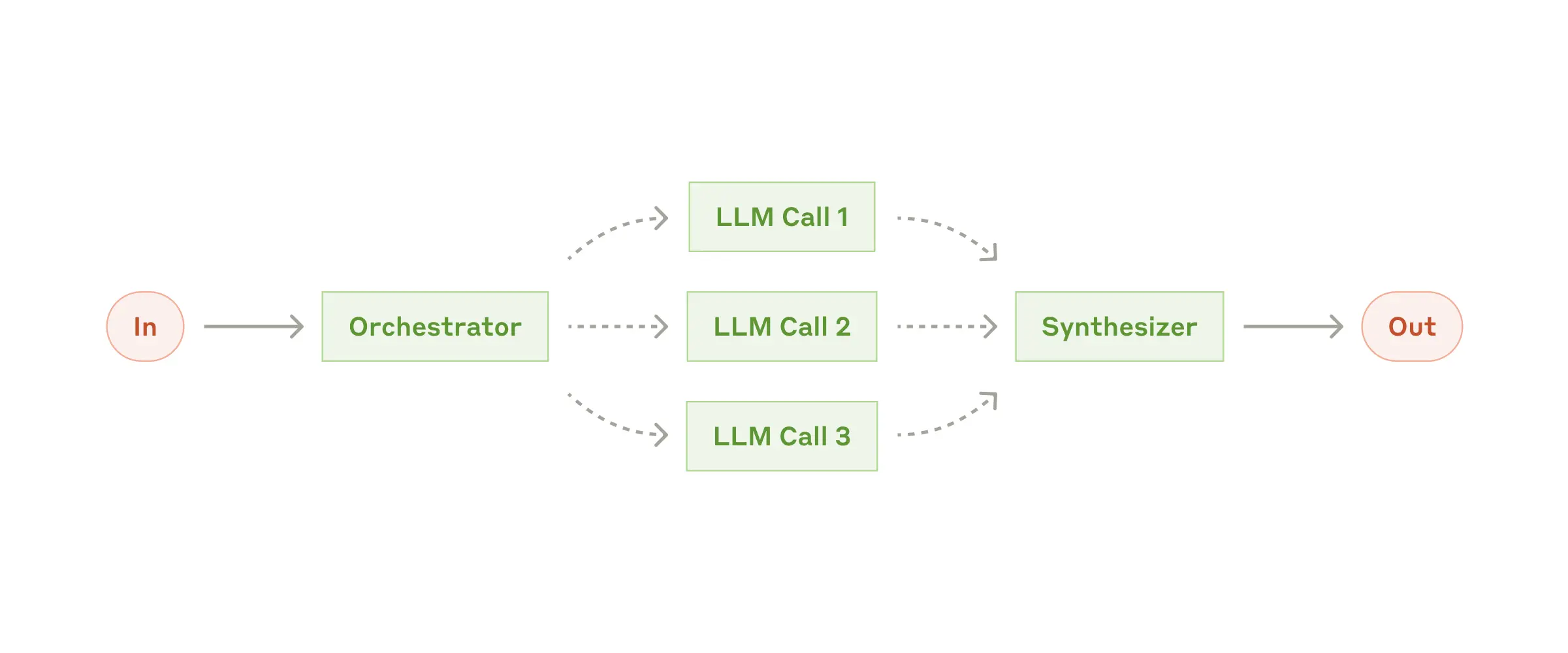
引用: https://www.anthropic.com/research/building-effective-agents
#Evaluator-optimizer:
- 一つのLLMが応答を作成し、もう一つのLLMが評価・フィードバックを与えて品質を高める
- 明確な評価基準があり、反復的な改善が価値を生む場合に効果的
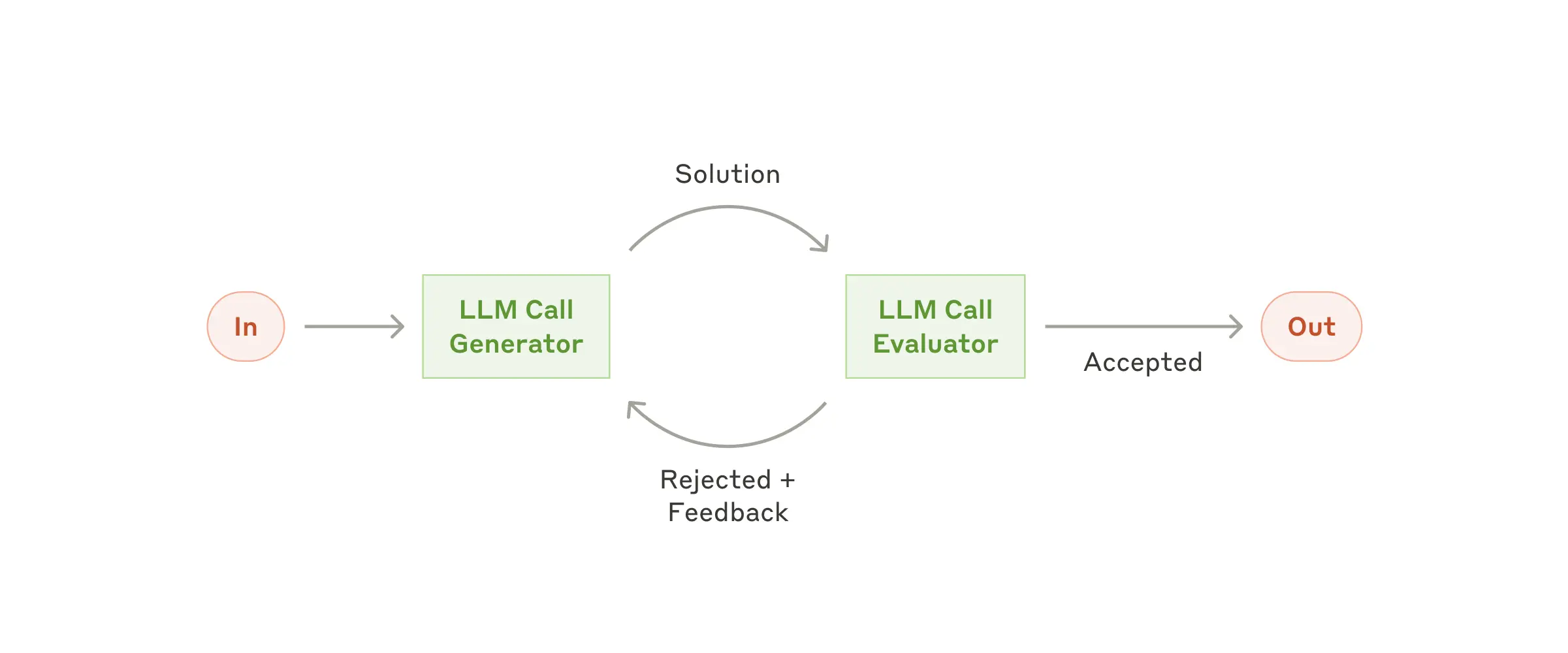
引用: https://www.anthropic.com/research/building-effective-agents
関連リソース
Agentic Design Pattern
Agentic Design Patternsは、Andrew Ng氏が提唱しているLLMベースのAIエージェントの設計指針や実装パターンを整理・体系化したものです。
ゼロショット推論(1回の出力生成)と比較し、エージェントワークフロー(反復型の推論+ツール活用など) により性能向上が期待できるとした上で、4つのデザインパターンを紹介しています。
- Agenticワークフロー:LLM が反復的にタスクをこなし、出力を改善するプロセスであり、一度で出力を生成するゼロショットモードよりも高度なタスク処理が可能とされています。
-
4つのデザインパターン:
- Reflection:LLM が自身の出力を検査し改善点を見つける自己改善プロセス。
- Tool Use:外部ツールとのインタラクションによって情報収集やデータ処理能力を拡張。
- Planning:目標達成のために多段階計画を立て実行する能力。
- Multi-agent collaboration:複数エージェントが協力してタスク解決策を導き出す。
関連リソース
Agent Design Pattern Catalogue
Agent Design Pattern Catalogueは、LLMを活用したAIエージェントの設計パターンを体系的にまとめた論文です。
先に述べたAgentic Design Patternでは、「Reflection」「Tool Use」「Planning」「Multi-agent collaboration」といった大きなくくりでアプローチを示していました。
一方、このAgent Design Pattern Catalogueでは、より粒度の細かい18パターンを提示し、それぞれの文脈やトレードオフを解説しています。
主なカテゴリ例
- ゴール・プラン生成: LLMがタスクを分解し、中間目標を設定していく流れをどう実装するか
- 複数エージェントの協調: Voting-based cooperationやRole-based cooperationなど、エージェント同士の協働パターン
- 守るべき安全・倫理的観点: Guardrailsによる入出力の制御やアダプターによるインタフェース調整など、LLM特有のリスク緩和策をパターン化
- 評価と継続的な改善: Agent evaluatorでエージェントの性能を定期的に確認・修正する仕組みを組み込む
パターンは大きく以下のようなカテゴリに分類されます:
- ゴール設定: 受動的/能動的なゴールクリエーター
- 入出力最適化: プロンプト/レスポンス最適化、RAG
- 計画生成: シングル/マルチパスプランジェネレーター
- 振り返り: セルフ/クロス/ヒューマンリフレクション
- 協調: 投票/役割/ディベートベースの協力
- システム設計: ガードレール、レジストリ、アダプター、評価者
18のデザインパターン一覧
| カテゴリ | パターン名 | 概要 |
|---|---|---|
| ゴール設定 | 受動的なゴールクリエーター | ユーザーの明示的な指示からゴールを設定 |
| 能動的なゴールクリエーター | ユーザーの行動や履歴から自動的にゴールを提案 | |
| 入出力最適化 | プロンプト/レスポンス最適化 | 入出力の内容と形式を標準化・最適化 |
| RAG | 外部知識を活用して回答の質を向上 | |
| 計画生成 | ワンショットモデルクエリ | 単一のクエリで計画を生成 |
| インクリメンタルモデルクエリ | 段階的なクエリで計画を精緻化 | |
| シングルパスプランジェネレーター | 単一の実行パスで計画を生成 | |
| マルチパスプランジェネレーター | 複数の選択肢を含む計画を生成 | |
| 振り返り | セルフリフレクション | 自己の出力を評価・改善 |
| クロスリフレクション | 他のエージェントからフィードバックを取得 | |
| ヒューマンリフレクション | 人間からのフィードバックを活用 | |
| 協調 | 投票ベースの協力 | 複数エージェントの投票で意思決定 |
| 役割ベースの協力 | 役割分担による協調作業 | |
| ディベートベースの協調 | 議論を通じた合意形成 | |
| システム設計 | マルチモーダルガードレール | 入出力の制御による安全性確保 |
| ツール/エージェントレジストリ | ツールやエージェントの管理・選択機能 | |
| エージェントアダプター | 外部ツールとの接続インターフェース | |
| エージェント評価者 | エージェントの性能評価機能 |
関連リソース
- Agent Design Pattern Catalogue: A Collection of Architectural Patterns for Foundation Model based Agents
- 【論文紹介】LLMベースのAIエージェントのデザインパターン18選
- 基盤モデルを用いたAIエージェントの設計パターン
The Landscape of Emerging AI Agent Architectures for Reasoning, Planning, and Tool Calling: A Survey
The Landscape of Emerging AI Agent Architectures for Reasoning, Planning, and Tool Calling: A Survey
は、「AIエージェントのアーキテクチャ」について、シングルエージェントからマルチエージェントまで幅広く概観・評価しているサーベイ論文、2024年4月にIBMとMicrosoftにより公開されています。
AIエージェントが複雑な目標を達成するための推論(Reasoning)、計画(Planning)、およびツール呼び出し(Tool Calling) の能力に注目しています。
- シングル vs. マルチエージェントのどちらを選ぶかは、タスクの複雑さや必要なツールの数、そしてコミュニケーションの重要度によって変わる。
- いずれの方法でも、「推論 → 計画 → ツール呼び出し → フィードバック」のループをうまく設計することで、LLMを“ただのチャットツール”以上の存在にできる。
- 今後の課題として、動的ベンチマークや倫理・安全面のルール整備、複雑なマルチエージェントの管理方法などが挙げられる。
シングルエージェント vs. マルチエージェント
-
シングルエージェント:
- 1つのLLMが担当し、すべての計画・ツール呼び出し・意思決定を行う。
- メリット: 実装がシンプル、他のエージェントへの無駄な情報共有が不要
- デメリット: 複雑なタスクや並列作業には不向き、自己評価(Reflection)が弱いとエンドレスループに陥るリスク
-
マルチエージェント:
- 複数のエージェントが連携しながらタスク遂行。縦型(リーダー制)や横型(対等な協働)など、構造のバリエーションが多い。特に「専門分野が異なるエージェント同士でタスクを分割する」場面に向いている
- メリット: 専門分野の異なるエージェントが並行して作業を分担できる、相互フィードバックで精度向上
- デメリット: 過剰な対話(“chatter”)や指示の混乱が起きやすく、リーダーシップや情報共有の設計(“vertical”または“horizontal”な連携)が求められる
Reasoning, Planning, Tool Callingの重要性
-
Reasoning(推論):
人間が複雑な意思決定をするプロセスに近い形で、LLMが推論できるか
新しい情報・フィードバックを得る度にプランを修正する仕組みが必要 -
Planning(計画):
タスクを小分けにし、どの順番でどのツールを呼び出すかを設計する力。
マルチプランの生成や並列実行(Parallelization)の有効性 -
Tool Calling(ツール呼び出し):
外部データやAPIを呼び出し、エージェントが「モデル以外の能力」を活用できる
ツール連携が十分に抽象化されていないと、挙動が混乱したり、呼び出しミスが増えるリスク
設計のポイント
-
ロールの明確化:
- マルチエージェントにおいて、リーダー(または指揮役) が存在するほうが効率的という指摘
- シングルの場合も、マルチの場合も、エージェントが「何をすべきか」をはっきり決めておくと、不要なハルシネーションや混乱を防ぎやすい。
-
フィードバック・人間監督の活用:
- マルチエージェント間のやりとりだけでなく、人間が適切にレビュー・修正指示を行うと、タスク成功率が大幅に向上
-
評価手法の課題:
- 従来のLLMベンチマークでは、複数ステップタスクや外部ツール呼び出しを前提にした評価が難しく、エージェントの総合評価には複数ステップのタスク成功率、ツール連携の正確性、コミュニケーション効率など多面的な指標が必要
- 実アプリケーションに近い動的なベンチマークや、ユーザー環境に特化した合成ベンチマークなど
関連リソース
- The Landscape of Emerging AI Agent Architectures for Reasoning, Planning, and Tool Calling: A Survey
- 2024年 ビッグテックのAI Agent 動向まとめ
An Evaluation-Driven Approach to Designing LLM Agents: Process and Architecture
最後に紹介するのは、An Evaluation-Driven Approach to Designing LLM Agents: Process and Architectureです。
LLMエージェントに対する評価主導型の設計手法を提案したもので、「継続的な評価と改善」のフレームワークを、プロセスモデルとリファレンスアーキテクチャの両面から提示しています。
オフライン評価とオンライン評価の両立
LLMエージェントの品質やリスクを管理するうえで、オフライン評価(本番投入前のテストやベンチマーク)とオンライン評価(実運用環境でのモニタリングやユーザー・ドメイン専門家からのフィードバック)の両軸を組み合わせる重要性を強調しています。
- オフライン評価: 従来のテスト駆動開発や各種ベンチマークを活用し、エージェントが最低限必要なパフォーマンス・安全性を満たしているかを確認する
- オンライン評価: 本番環境での不確実な入力や連続的なタスク変化に対処するために、フィードバックの収集やログ解析を通じた動的なモニタリングが必要。これにより、新たなリスクの検知やエージェント挙動の変化への追従を可能にする。
また評価の対象として、最終的な出力(成功率やユーザー満足度など)だけでなく、中間パイプラインやアーティファクト(計画、ツール呼び出しの出力、ガードレールの反応など) も評価することが推奨されています。これによって単に「タスク成功・失敗」だけを確認するのではなく、どこでどのような意思決定が行われたのかを可視化し、改善点を特定しやすくするアプローチが紹介されています。
プロセスモデルの4ステップ
エージェント開発~運用全体で評価を継続的に組み込むためのプロセスモデルとして、以下の4つのステップを提示しています。
- Step 1: Define Evaluation Plan(評価計画の定義)
- ユーザーのゴールとガバナンス要件を踏まえて評価の範囲や目的を明確化
- エージェントが生成・活用するアーティファクト(例:ツール呼び出し結果、計画、メモリ構造など)をどこまで評価対象に含むかもあらかじめ検討
- 必要に応じて安全ケース(Safety Cases) の初期バージョンを策定し、どんなリスク要素を重点的に見るかを整理
- Step 2: Develop Evaluation Test Cases(評価用テストケースの作成)
- 事前のベンチマークや既存フレームワークを活用しながら、エージェントが想定される幅広いタスク・状況に対応するテストケースを整備
- ドメイン専門家との協力や、LLMを使った合成データ生成などにより“現実的かつ多様”なシナリオを準備
- 「エージェントが最終的に出す出力」だけでなく、「中間プロンプトや計画、ツール利用ステップ」などを評価できるよう工夫
- Step 3: Conduct Offline and Online Evaluations(オフライン評価とオンライン評価の実施)
- オフライン評価: 実運用前にテストケースを用いてエージェントの性能やリスクレベルを検証
- オンライン評価: 実際のユーザーや動的な入力環境の中で、ログ収集・フィードバック取得などを行い“運用中に生じる課題”を検知
- 「最終アウトプット」と「中間パイプライン/アーティファクト」の両面を評価することが鍵
- Step 4: Analyze and Improve(分析と改善)
- オンライン評価結果をもとにエージェントの実行パイプラインやアーティファクトをリアルタイムで改善(例えばツール選択ロジックを切り替える、メモリをアップデートするなど)
- オフライン評価で重大な問題が判明した場合は、エージェントのアーキテクチャ自体を再設計したり、LLMの選択/ファインチューニングを見直すなど、より本質的な改善を行う
- 改善結果を再び安全ケースに反映し、継続的にアップデートしていく
「評価駆動」を実現するリファレンスアーキテクチャ
さらに著者らは、“評価”をアーキテクチャのコア要素として設計し直すことで、LLMエージェントが自律的に動き続ける中でも、継続的な改善とリスク制御を可能にすると提案しています。
- Supply Chain Layer(デザイン・開発層): ユーザーの要求やガバナンス要件を踏まえてオフラインでの検証を行い、評価基準やテストケースを整備する。
- Agent Layer(エージェントのコア機能層): エージェントが外部環境(ユーザー、他エージェント、ツール、知識ベース)とやり取りするためのモジュール群(Context Engine、Reasoning & Planning、Workflow Executionなど)を配置。
- Operation Layer(運用層): 評価コンポーネントを中心として、オンライン評価やログ取得、エラー処理などの仕組み(AgentOps Infrastructure)を組み込み、得られた結果をエージェントへ素早く反映するためのフィードバックループを確立。
このアーキテクチャでは、Offline/Online評価の結果を安全ケース(Safety Cases)やテストケースとして随時更新し、それを再びエージェントの実装・運用に反映するプロセスが示されています。
これにより、エージェントが“継続的かつ段階的に”改修され、外部環境やユーザー要求の変化に応じてアップデートされるサイクルが実現します。
関連リソース
An Evaluation-Driven Approach to Designing LLM Agents: Process and Architecture
(1/12追記) Muilt-agent Systems - LangGraph
記事公開後にLangGraphから、マルチエージェントのアーキテクチャパターンを紹介している記事を見つけたので追記。ざっくり分けると
-
Network(ネットワーク型)
- 各エージェントが他の全エージェントと通信可能
- 次に呼び出すエージェントを各エージェントが自律的に決定
-
Supervisor(中央管理型)
- 各エージェントは単一のSupervisorエージェントと通信
- Supervisorが次に呼び出すエージェントを決定
- tool calling型のバリエーションもあり(エージェントをツールとして実装)
-
Hierarchical(階層型)
- SupervisorのSupervisorを定義可能
- より複雑な制御フローを実現できる
-
Custom Workflow(カスタムワークフロー型)
- エージェント間の通信を部分的に制限
- フローの一部を決定論的に、一部を動的に設計可能

Network型(フラットな協調パターン)
全てのエージェントが対等な立場で直接通信できる構造です。各エージェントはLLMベースの意思決定により、次に実行するエージェントを自律的に選択できます。
これによりエージェント間で柔軟な協力関係を構築できますが、通信の複雑さはO(n^2)で増加します。
- 明確な階層構造を持たず、各エージェントが対等な立場で協調
- エージェント間で直接的な情報共有と意思決定が可能
- 実行順序が動的に変化する柔軟なワークフローを実現
Supervisor型(中央管理パターン)
スーパーバイザーエージェントが他のエージェントを統括する集中管理型の実装パターンです。
各エージェントはスーパーバイザーとのみ通信を行い、次に実行するエージェントの選択もスーパーバイザーが一元的に判断します。
- スーパーバイザーを介した一元的なタスク管理と制御
- ワーカーエージェント間の直接通信を制限し、複雑性を低減
- 実行順序や並列実行の制御が容易
Antrhopicの記事でも登場したOrchestrator-workersと同様の、いわゆるオーケストレーターが存在するパターンの一つです。
Supervisor (Tool-calling)型
Supervisor型をベースとした実装パターンで、各エージェントをツールとして実装し、SupervisorがReActパターンのLLMとして振る舞います。
- ReActパターンの拡張として実装が可能
- エージェントの入出力をツールスキーマとして厳密に定義
要するにFunction-calling、Tool-callingの実装ですね。
Hierarchical型(階層管理パターン)
複数のSupervisorが階層構造を形成し、より複雑なワークフローを実現する実装パターンです。
システムの規模が大きくなるにつれて、単一のSupervisorでは全エージェントの管理が難しくなるという課題に対応するために生まれました。
Supervisorも結局はLLMベースのエージェントであり、管理対象が増えすぎると:
- 次に呼び出すべきエージェントの判断を誤りやすくなる
- 文脈が複雑すぎて適切な状態管理ができなくなる
- エージェント間の調整に時間がかかりすぎる
と言うことで、「単一エージェントでは文脈が複雑すぎて管理できない」というマルチエージェント導入の初期動機と同じ問題に行き着きます。
これらの課題に対し、Hierarchical型では以下のような階層構造による解決を図ります:
- 専門性や役割でエージェントをチームに分割
- 各チームに独自のSupervisorを配置
- トップレベルのSupervisorはチーム間の調整に専念
個人的には組織設計をする感じが楽しくて、趣味としては一番好きなパターンです。
(ただ実務的にはCustom Workflowみたいなのを作ることが一番多い)
Custom Workflow型(ハイブリッドパターン)
一部のエージェント間のみに通信を許可し、決定論的なフローと動的なフローを組み合わせた実装パターンです。
制御フロー(すなわちエージェント間の通信の順序)を明示的な定義を実現しながら、必要な箇所でのみ柔軟な判断を可能にします。
いわゆるワークフローとエージェントな処理を混在させるパターンと言えるでしょう。
- エージェント間の通信を必要最小限に制限
- フローの一部を決定論的に、一部を動的に設計可能
- 既存のワークフローエンジンとの統合が容易
このパターンは2つの実装アプローチがあります:
-
明示的な制御フロー:
- 通常のグラフエッジとして実行順序を事前定義
- エージェント間の通信経路を静的に制御
- システムの振る舞いが予測しやすく、デバッグも容易
-
動的な制御フロー:
- 一部のエージェントにのみLLMベースの判断を許可
- 特定のステップでのみ柔軟なルーティングを実現
- ビジネスロジックに応じた選択的な動的制御
静的なフローと動的なフローが混在することによる設計の複雑化などはありますが、必要な箇所でのみエージェントの自律性を高めることで制御の複雑さとシステムの柔軟性のバランスを取れるため、実務での利用は多くなりそうな印象です。
関連リソース
まとめ
ほぼ読了済のものを再読した形で終わりました。
The Landscape of Emerging AI Agent Architectures for Reasoning, Planning, and Tool Calling: A Surveyあたりで全然コンセプト変わってきてるなと思い、記事をまとめる手は止めました。
自プロダクトでの実装や、OSS実装を読み込んで自らパターンを提案するぐらい頑張ることにします
今回は以上です!
Discussion