はじめに
最近話題のMCP(Model Context Protocol)記事です。MCPに関しては、同僚の李さんが素晴らしい記事を書いてくださいましたので、MCP自体の概要に関しては以下記事参照ください(お約束)。
今回は、LLMの代表的なユースケースとも言えるRAG(Retrieval-Augmented Generation)です。RAGはドキュメントから関連情報を検索し、AIの回答生成に活用する技術で、専門知識や最新情報を必要とするタスクに使われます。以前にTanuki-8BとOllamaとDifyを使って日本語ローカルRAG構築という記事でローカルRAGの構築について説明したので詳しくはそちらを参照してください。簡単なRAGの構成図としては以下となります(記事より引用)。
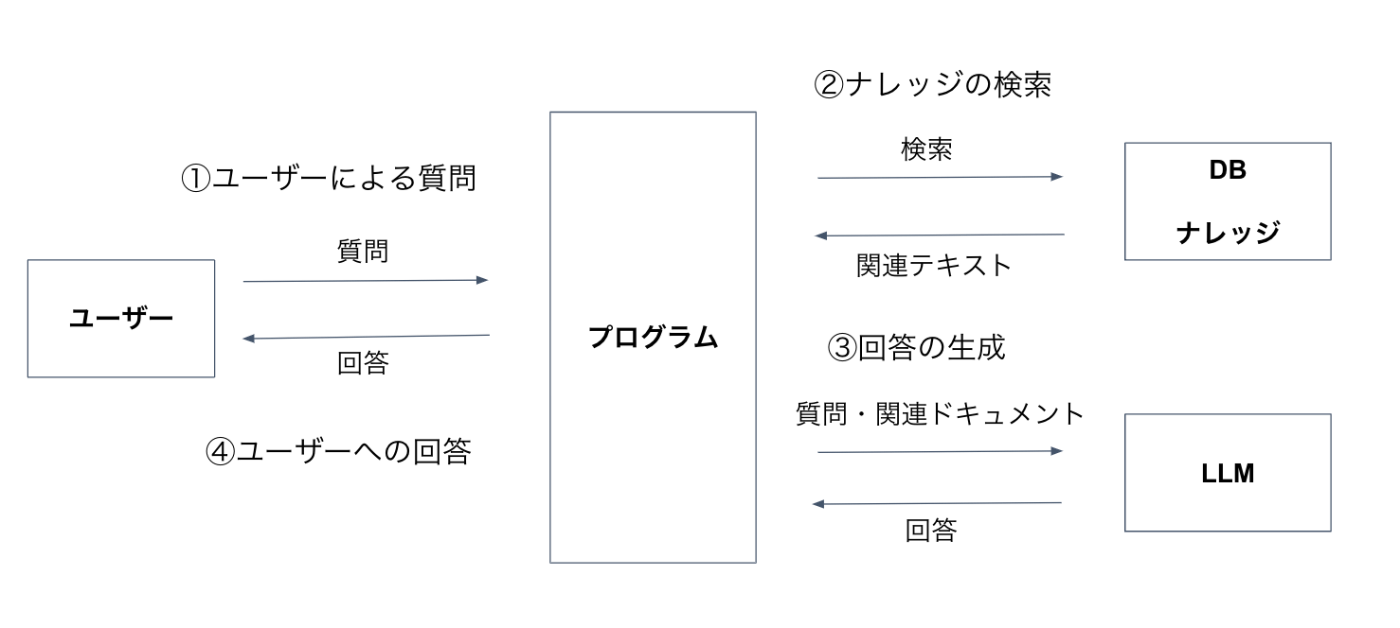
今回は、このRAGをMCPを使って実現します。つくるMCPサーバの中身としてはPostgreSQLでベクトル検索ができるpgvectorという機能とMarkItDownライブラリによるドキュメントのマークダウンへの変換を用いています。今回作成するMCPサーバ自体は、あくまでベクトル検索とその結果を返す機能しか持っていません。MCPホストでLLMがMCPサーバの結果を元に回答を生成することでRAGシステムとなります。
MCPサーバでベクトル検索を実現するモチベーションとしては、CursorやWindsurfなどのAIコーディングツールだとベクトル検索の機能が標準でついていますが、Cline(Roo Code)だとそのような機能がないので手軽にベクトル検索を実現したかったことがあります。
また、ポイントとして、今回つくるMCPサーバはOpenAI等のAPIを使用しないため、完全にローカルで運用することが可能です。なので、MCPホストに使うLLMをローカルLLMにしてこのMCPサーバと組み合わせれば、手軽に完全にローカルなRAGシステムを構築することができます。
作成した「MCP RAG Server」はGitHubでOSSとして公開しています。
MCP RAG Serverの概要
MCP RAG Serverの概要は以下です。言語は慣れているPythonを使いました。
-
多様なドキュメント形式対応:マークダウン、テキスト、パワーポイント、PDFなど複数の形式のドキュメントを処理できます。
-
ベクトル検索:PostgreSQLのpgvectorを使用して、ベクトル検索を実現しています。
-
多言語対応:multilingual-e5-largeモデルを使用しているため、日本語を含む多言語のドキュメントに対応しています。
-
差分インデックス化:新規・変更ファイルのみを処理する差分インデックス化機能により、大量のドキュメントを効率的に管理できます。
-
CLIとMCPの役割分担:インデックス化などの管理操作はCLIツールで、検索などのクエリ操作はMCPインターフェースで行います。
-
特定ライブラリに依存しない :LangChainなどの変化の激しいライブラリに依存していないので、比較的バージョン関係に悩まされず安定して動かすことができます(MCP自体の大幅な仕様変更の可能性はありますが)。
システム構成
MCP RAG Serverのシステム構成およびシーケンスは以下の通りです。最初にインデックス化してからRAG検索をします:
インデックス化のシーケンス
インデックス化の処理フローは以下のようになっています:
※ RAG Service, Document Processor, Embedding GeneratorはMCP RAG Serverの持つ機能で、それぞれRAGのサービス提供、ドキュメントの処理、インデックス化処理を担当します。
RAG検索のシーケンス
RAG検索の処理フローは以下のようになっています:
セットアップ方法
MCP RAG Serverのセットアップ方法について説明します。Macで動作確認をしています。LinuxやWindows(WSL2)でもほぼ同じ手順で動くと思いますが、動作は未確認です。
uvのセットアップ
Pythonのパッケージ管理、仮想環境構築にはuvを使用します。uvの概要・インストール方法は以下の記事を参照してください。
uvが入っていれば以下コマンドで環境をセットアップできます。
$ git clone https://github.com/karaage0703/mcp-rag-server
$ cd mcp-rag-server
$ uv sync
あとは、mcp-rag-serverフォルダで以下コマンドを実行すれば仮想環境に入れます。
$ source .venv/bin/activate
PostgreSQLとpgvectorのセットアップ
Dockerを使用します。Dockerの概要とセットアップ方法は以下記事参照してください。
以下コマンドでpgvectorを含むPostgreSQLコンテナを起動します。
$ docker run --name postgres-pgvector -e POSTGRES_PASSWORD=password -p 5432:5432 -d pgvector/pgvector:pg17
以下コマンドでPostgreSQLのデータベースを作成します。
$ docker exec -it postgres-pgvector psql -U postgres -c "CREATE DATABASE ragdb;"
環境変数の設定
.envファイルを作成し、上記で構築したPostgreSQL環境に合わせて環境変数を設定します。以下はデフォルトの設定です。
# PostgreSQL接続情報
POSTGRES_HOST=localhost
POSTGRES_PORT=5432
POSTGRES_USER=postgres
POSTGRES_PASSWORD=password
POSTGRES_DB=ragdb
# ドキュメントディレクトリ
SOURCE_DIR=./data/source
PROCESSED_DIR=./data/processed
# エンベディングモデル
# infloat/multilingual-e5-large
EMBEDDING_MODEL=intfloat/multilingual-e5-large
EMBEDDING_DIM=1024
EMBEDDING_PREFIX_QUERY="query: "
EMBEDDING_PREFIX_EMBEDDING="passage: "
Cline/CursorへのMCPサーバー設定
MCPホストでMCP RAG Serverを使用する設定です。以下は、MCPホストとしてCline/Cursorを使った設定例です。mcp_settings.jsonなどのエディタに対応したMCPサーバの設定ファイルに以下のような設定を追加します:
"mcp-rag-server": {
"command": "uv",
"args": [
"run",
"--directory",
"/path/to/mcp-rag-server",
"python",
"-m",
"src.main"
]
}
/path/to/mcp-rag-serverは、このリポジトリのインストールディレクトリに置き換えてください。
Claude CodeへのMCPサーバー設定
Claude CodeへはコマンドでMCPサーバー設定を追加するのがオススメです。以下コマンドで追加できます。
$ claude mcp add mcp-rag-server \
-- uv run --directory /path/to/mcp-rag-server \
python -m src.main
Claude CodeへのMCPサーバー設定について詳しくは以下記事を参照ください。
使用例
ドキュメントのインデックス化
ドキュメントをインデックス化するには、CLIツールを使用します。mcp-rag-serverディレクトリで以下のコマンドを実行することでインデックス化できます。
# 全件インデックス化
python -m src.cli index
# 特定のディレクトリをインデックス化
python -m src.cli index --directory ./path/to/documents
# チャンクサイズとオーバーラップを指定してインデックス化
python -m src.cli index --directory ./data/source --chunk-size 300 --chunk-overlap 50
追加したファイルだけインデックス化したいときは差分インデックス化を使用できます。:
# 差分インデックス化(新規・変更ファイルのみを処理)
python -m src.cli index --incremental
インデックスのクリア
以下コマンドでインデックスをクリアできます。
python -m src.cli clear
ベクトル検索
MCPホストから、以下のようなプロンプトで検索を行うことができます:
mcp-rag-serverで「トランスフォーマ」について検索した結果をもとに回答をしてMarkdown形式で出力してください。
今回は、あらかじめ松尾・岩澤研究室が公開している勉強会のスライド資料の1部をRAGのDBに格納しました。
回答は長くなるので、以下のトグルの中に入れています。
ベクトル検索の結果
検索結果を確認しました。「トランスフォーマ」というキーワードで検索した結果、5つの関連ドキュメントが見つかりました。これらの検索結果をもとに、トランスフォーマーについての情報をまとめて回答を作成します。
検索結果から以下の情報が得られました:
Pretrained Transformers as Universal Computation Engine(事前学習済みトランスフォーマーを汎用計算エンジンとして使用)に関する情報
言語で訓練したTransformerは別のモダリティにも転移可能
GPT2の構造を利用
Self AttentionとFeed Forwardを固定
FPT(Frozen Pretrained Transformer)に関する実験結果
モデルサイズが大きいほど性能が良い
Transformerが学習しているのは関数というより処理
汎化にはグラフ構造が必要かもしれない
Set Transformerの構造
Set Attention Block (SAB)
Induce Set Attention Block (ISAB)
Pooling by Multihead Attention (PMA)
これらを単層または多層に重ねて構築
Transformerと他のモデル(LSTM)との比較
ランダムに初期化した場合でもTransformerがLSTMより大幅に良い性能
言語での事前学習が他のモダリティ(Bit Memory、ViT)よりも総合的に良い
BigBirdというスパースな注意機構によるモデル
Random Attention + Window Attention + Global Attention
Transformerの持つシーケンス-シーケンス関数のUniversal approximatorとTuring完全の特性を維持
より長い入力(約8倍)を扱えるようになり、質問応答や要約などの長い入力を持つNLPタスクやゲノミクスデータの分析で性能向上
これらの情報をもとに、トランスフォーマーについての包括的な回答を作成します。
作成した回答
トランスフォーマーに関する検索結果の分析
検索結果をもとに、トランスフォーマーに関する重要な知見をまとめました。
1. 事前学習済みトランスフォーマーの汎用性
「Pretrained Transformers as Universal Computation Engine」(Lu, Grover, Abbeel, Mordatch, 2021)の研究によると、言語で訓練したトランスフォーマーは驚くべきことに別のモダリティにも転移可能であることが示されています。この研究では:
- GPT2の構造を基にしたトランスフォーマーを言語タスクで訓練
- Self-AttentionとFeed Forward層を固定(Frozen Pretrained Transformer: FPT)
- 言語以外のタスクにも適用可能であることを実証
2. トランスフォーマーの性能特性
実験結果から以下の特性が明らかになっています:
- モデルサイズが大きいほど性能が向上する傾向がある
- トランスフォーマーはLSTMと比較して大幅に優れた性能を示す
- トランスフォーマーが学習しているのは「関数」というより「処理」の仕方
- 言語での事前学習が、他のモダリティ(BitメモリタスクやViT)での事前学習よりも総合的に優れた転移性能を示す
3. 特殊なトランスフォーマーアーキテクチャ
Set Transformer
集合データを扱うために設計されたトランスフォーマー変種で、以下のコンポーネントで構成:
- Set Attention Block (SAB)
- Induce Set Attention Block (ISAB)
- Pooling by Multihead Attention (PMA)
- これらのブロックを単層または多層に重ねて全体構造を構築
BigBird
長いシーケンスを効率的に処理するためのスパースアテンション機構:
- Random Attention + Window Attention + Global Attentionの組み合わせ
- 通常のトランスフォーマーの計算量O(n²)を線形O(n)にまで削減
- Global Tokenの導入により、Universal approximatorとTuring完全性を維持
- 従来の約8倍の長さの入力を処理可能
- 質問応答、要約、ゲノミクスデータ分析などで性能向上を実証
まとめ
トランスフォーマーは単なる言語モデルの枠を超え、様々なモダリティや問題設定に適用可能な汎用的な計算エンジンとしての可能性を持っています。特に事前学習の転移性、アーキテクチャの柔軟性、長いシーケンス処理能力の向上などが重要な特徴として挙げられます。Set TransformerやBigBirdのような特殊アーキテクチャの開発により、さらに応用範囲が広がっています。
一般的な回答でなく、RAGで参照したドキュメントを元にした回答になっていることが分かります。
まとめ
自作したPostgreSQLのpgvectorを活用したベクトル検索機能を持つMCPサーバーを紹介しました。多様なドキュメント形式に対応し、差分インデックス化機能により大量のドキュメントを効率的に管理できます。
MCPサーバのユースケース実証のために簡易的に作ってみました。よくやるRAG構築をMCPサーバ使うと、うまく過去の資産を流用できるのではないかな?とか思っています。
このMCPサーバを使うと、例えば会社でドキュメントごとにMCPサーバを用意して、手軽に様々な用途のRAGシステムを実現するといったことができたりしないかなと考えています。
他、色々なMCPサーバの活用法を考えていきたいなと思っています。今回作成した「MCP RAG Server」のリポジトリは以下となります。
宣伝
MCPの書籍を出します。よろしければこちらも是非!
参考リンク
関連記事

Discussion