RAGの概要とその問題点
本記事では東京大学の松尾・岩澤研究室が開発したLLM、Tanuki-8Bを使って実用的なRAGシステムを気軽に構築する方法について解説します。最初に、RAGについてご存じない方に向けて少し説明します。
RAGは、簡単に説明すると外部知識(ナレッジ)をもとにLLMに回答させる技術です。特徴として、LLMが学習していないような知識に関してLLMに回答させることができます。回答も、外部知識を元とするため、事実に基づかない回答の生成(ハルシネーション)を減らす効果も期待できるため、ChatGPTをはじめとした大規模言語モデル(LLM)のユースケースとして、よく話題になっています。
具体例としては、会社の製品情報をナレッジとすることで、カスタマーサポートのチャットボットを作ったり、社内のノウハウやガイドをナレッジとすることで、社内サポートのチャットボットを作ることができます。
RAGの構成と処理の流れとしては、下図の通りです。
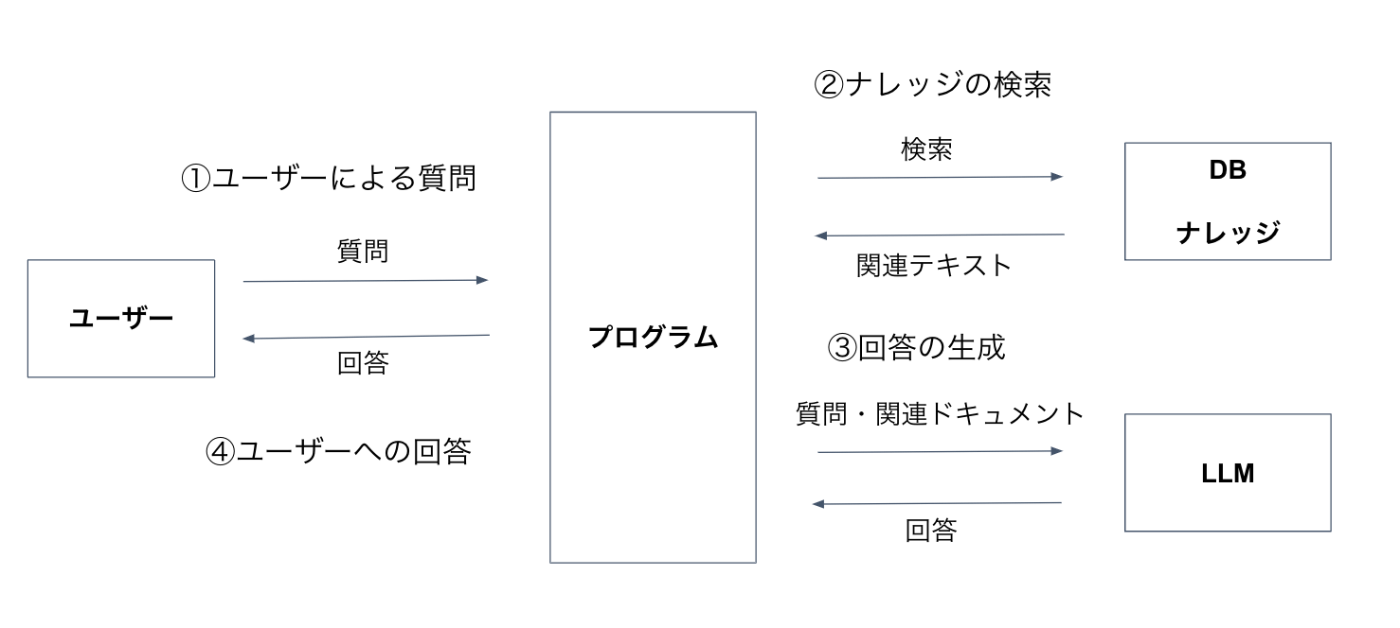
RAGは大きく以下の4つのプロセスで実現されます。
- ユーザーによる質問
- ナレッジの検索
- 回答の生成
- ユーザーへの回答
LLMは、回答の生成のところで使われます。RAGですが、自分の会社で試してみたいという人に、以下の点に課題があると言われることが何度かありました。
- セキュリティ
- コスト
- システム構築
セキュリティに関しては、データの機密性が高い会社は、ナレッジを外部に置いたり、LLMを使う際に外部にデータを送付する点がネックになるようです。
コストに関してもトータルでどれだけのコストになるか、見積もるのが難しかったり、RAGを実現するためのシステム構築にもハードルの高さを感じている人も多いようです。
上記の課題を解決するための方法として、ローカルで安価なLLMを使ってノーコードでRAGを構築できれば良さそうです。そのための手段として、今回はTanuki-8B、Ollama、Difyを使います。
それぞれについて簡単に説明しておきます。
Tanuki-8B
Tanuki-8B[1]は、経産省及びNEDOが進める日本国内の生成AI基盤モデル開発を推進する「GENIAC」プロジェクトにおいて、東京大学の松尾・岩澤研究室が開発したLLMです。詳細はこちらの記事を参照ください。
下図の通り、パラメータ数8Bと軽量ながら、Tanuki-8Bは日本語の対話、作文能力を評価する指標「Japanese MT-Bench」にてGPT3.5-Turboに匹敵する性能を示しています。
ちなみにモデル名のTanukiという名称は、「日本らしく、親しみを覚える動物の名前」とのことです。

Ollama
Ollamaは、ローカル環境でLLMを使うことができるツールです。Linux, Mac, Windowsなどの様々なプラットフォームで手軽にLLMを動かすことができます。量子化と呼ばれるモデルを軽量化するテクニックを使うと、Tanuki-8Bを省スペックのPCで動かすことが可能です[2]。私はRaspberry Pi 5(メモリ8GB)という小型のシングルボードコンピュータ上でOllama上でのTanuki-8Bの動作を確認しています。
Dify
Difyは、手軽に高度なAIアプリケーションを構築できる、オープンソースのLLMアプリ開発プラットフォームです。ノーコードで、RAG環境を構築することができる上に、Ollamaとの連携が可能なので、DifyとOllamaを使うことで、手軽にローカルでRAG環境を構築可能です。Difyに関しては、東京大学松尾・岩澤研究室のLLMコミュニティの動画でも取り上げているので興味ある方は参考にしてみてください。
RAGシステムセットアップ
ここからRAGシステムを構築していきます。以下の2つのステップでセットアップを行います。
- OllamaとTanuki-8Bのセットアップ
- Difyのセットアップ
PCとしては、GPUメモリとしてNVIDIA RTX 3060を搭載したLinuxマシンで動作を確認しました。Mac, Windowsでは、Ollama(Tanuki-8B)およびDifyの単体での動作のみを確認しました。
OllamaとTanuki-8Bのセットアップ
最初はDockerをセットアップしてください。Dockerのセットアップは以下記事を参照してください。
Ollama自体のセットアップは、以下の記事を参考にしてください。
以降は、Docker、Ollamaがインストールされて、Dockerの基礎知識がある上での説明となります。
Ollamaを起動します。GPU無し(CPU)で起動する場合は以下コマンドを実行してください。
$ docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
GPU有りの場合は、以下のように--gpus=allオプションをつけて実行します。
$ docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
続いて、6bitで量子化されたTanuki-8BのモデルをダウンロードしてからOllamaで動かします。
$ docker exec ollama ollama pull 7shi/tanuki-dpo-v1.0:8b-q6_K
$ docker exec -it ollama ollama run 7shi/tanuki-dpo-v1.0:8b-q6_K
ここまできて、以下のようにTanuki-8BとおしゃべりできるようになったらLLM(Ollama)の準備はOKです。
=> % docker exec -it ollama ollama run 7shi/tanuki-dpo-v1.0:8b-q6_K
>>> こんにちは
こんにちは!お元気ですか?何かお手伝いできることがあれば教えてくださいね!
Difyのセットアップ
以下の記事を参考に、Difyのセットアップと動作確認までを実施してください。
以降はDifyが起動して、ブラウザでアクセスしている前提で説明します。
ナレッジの準備と読み込み
続いて、RAGに使うナレッジとなるデータを準備しましょう。テキストデータ、PDFデータ、PPTXデータなどをナレッジとして読み込ませることができます。
ただ、Difyは標準だと15MBまでのデータしか読み込むことができないので、設定を変更して最大サイズを大きくしておくのがよいとおもいます。設定の変更に関してはDifyの記事のナレッジの容量を増大するを参考にしてください。
ソフトウェアに関しては、以下の記事を参考にするとリポジトリごとLLMによませることができます。
今回は例としてDifyのソースコードをナレッジとして読ませてみましょう。
以下コマンドを実行すると、Difyのソースコードをdify.txtというファイルに書き出すことができます。
$ git clone https://github.com/mpoon/gpt-repository-loader
$ cd gpt-repository-loader
$ git clone https://github.com/langgenius/dify
$ python3 gpt_repository_loader.py dify -o dify.txt
Difyへのナレッジの読み込みは「ナレッジの作成」から以下のようにドラッグ&ドロップで可能です。

テキストの前処理は、今回は以下の通りとしました。


以下のようにdify.txtがナレッジとして追加されたらOKです。

Ollamaとの連携
続いて、Ollamaとの連携です。右上のドロップダウンメニューから設定を選んでください。

モデルプロバイダーからOllamaを選択します。
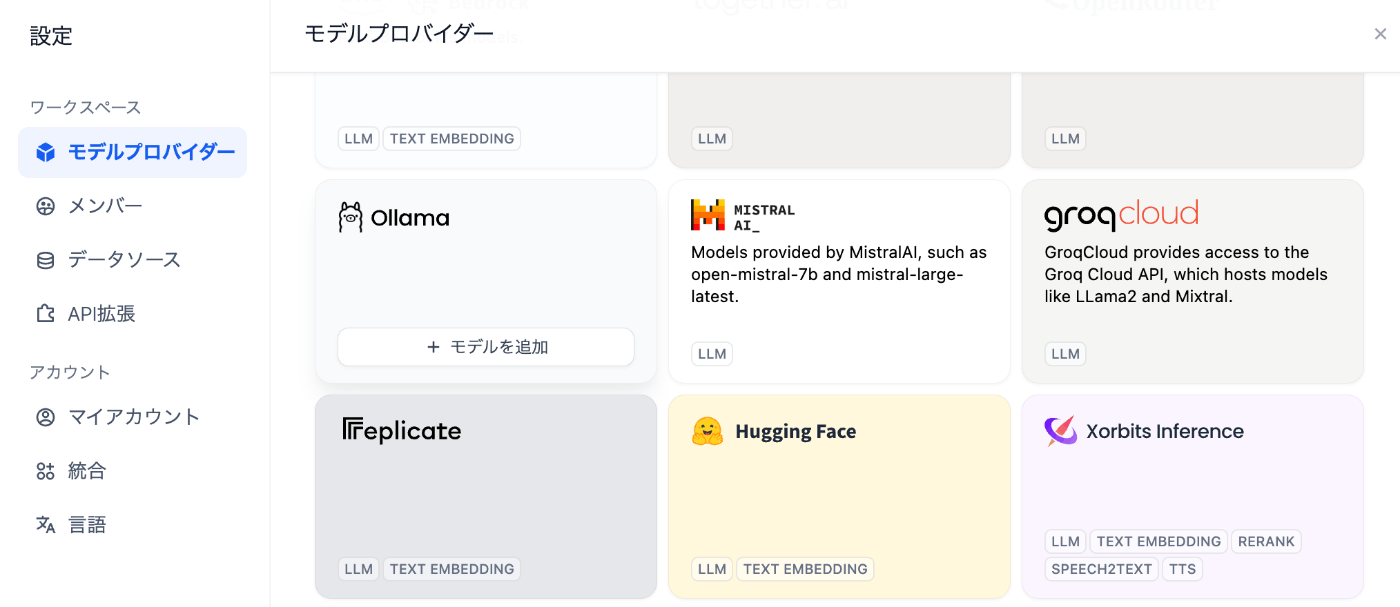
Ollamaの設定は下図のようにModel Nameとして7shi/tanuki-dpo-v1.0:8b-q6_K、Base URLとしてhttp://172.17.0.1:11434を設定します。

続いてアプリを選択します。RAGシステムを構築するのでKnowledge Retreival + Chatbotを選択します。
以下のような画面が表示されます。
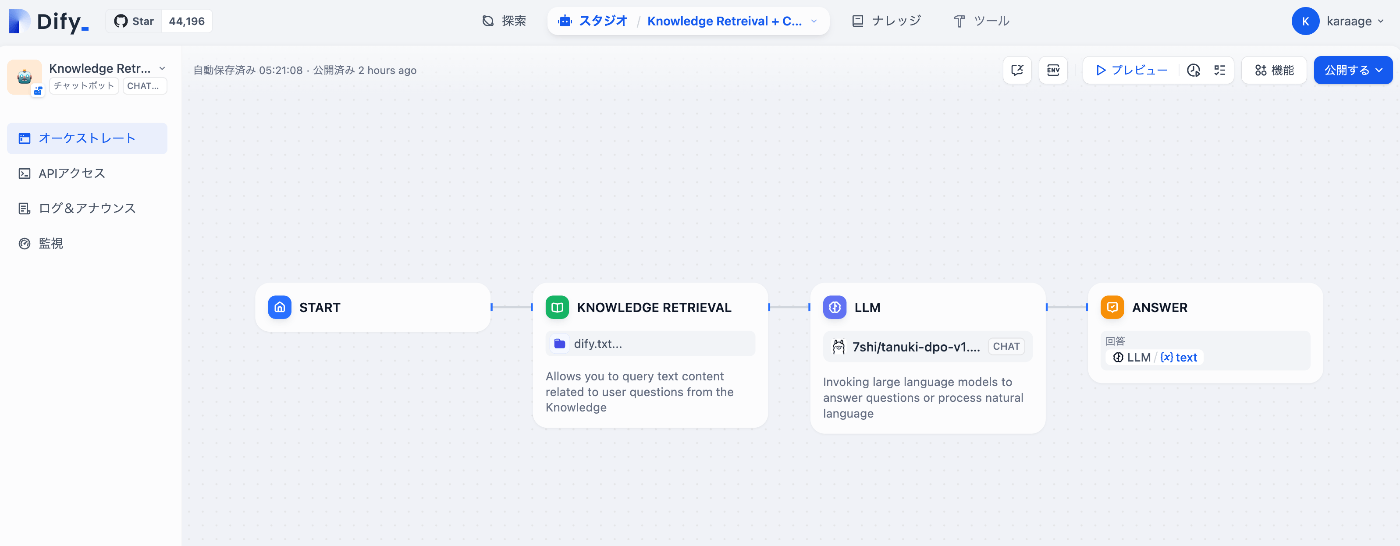
ここでSTART、KNOWLEDGE RETRIEVAL、LLM、ANSWERの4つのブロックがありますが、これらは、最初のRAGの構成と流れで説明した、ユーザーによる質問、ナレッジの検索、回答の生成、ユーザーへの回答にそれぞれ対応します。
それぞれのブロックの設定を確認します。STARTとANSWERは変更の必要がないので、KNOWLEDGE RETRIEVALとLLMのみ確認します。
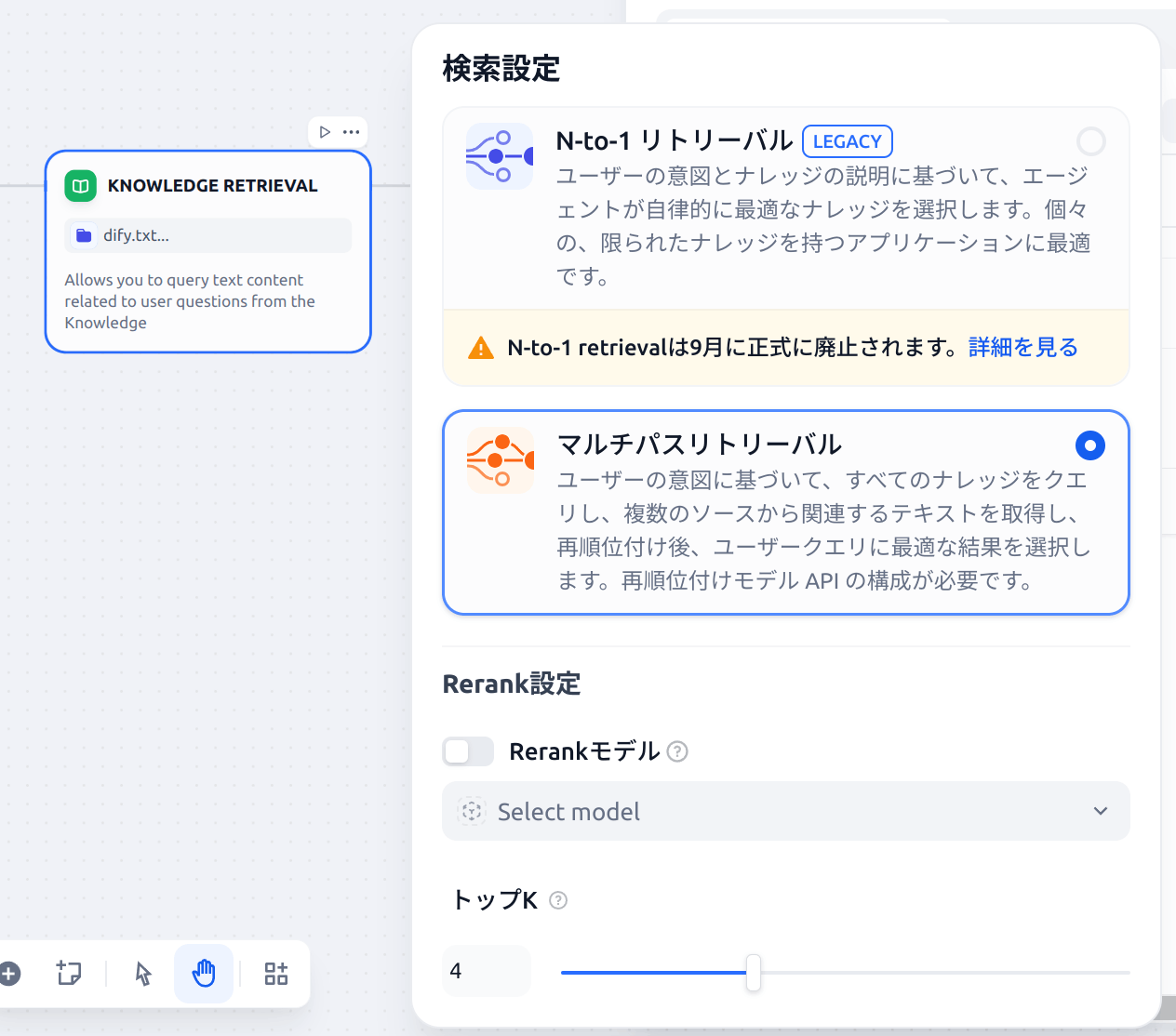
KNOWLEDGE RETRIEVALは、下図のように設定します。先程追加したdify.txtのナレッジを選択します。

検索設定は以下のように必要最低限にしています(モデルが必要なRerank設定はオフにしています)。
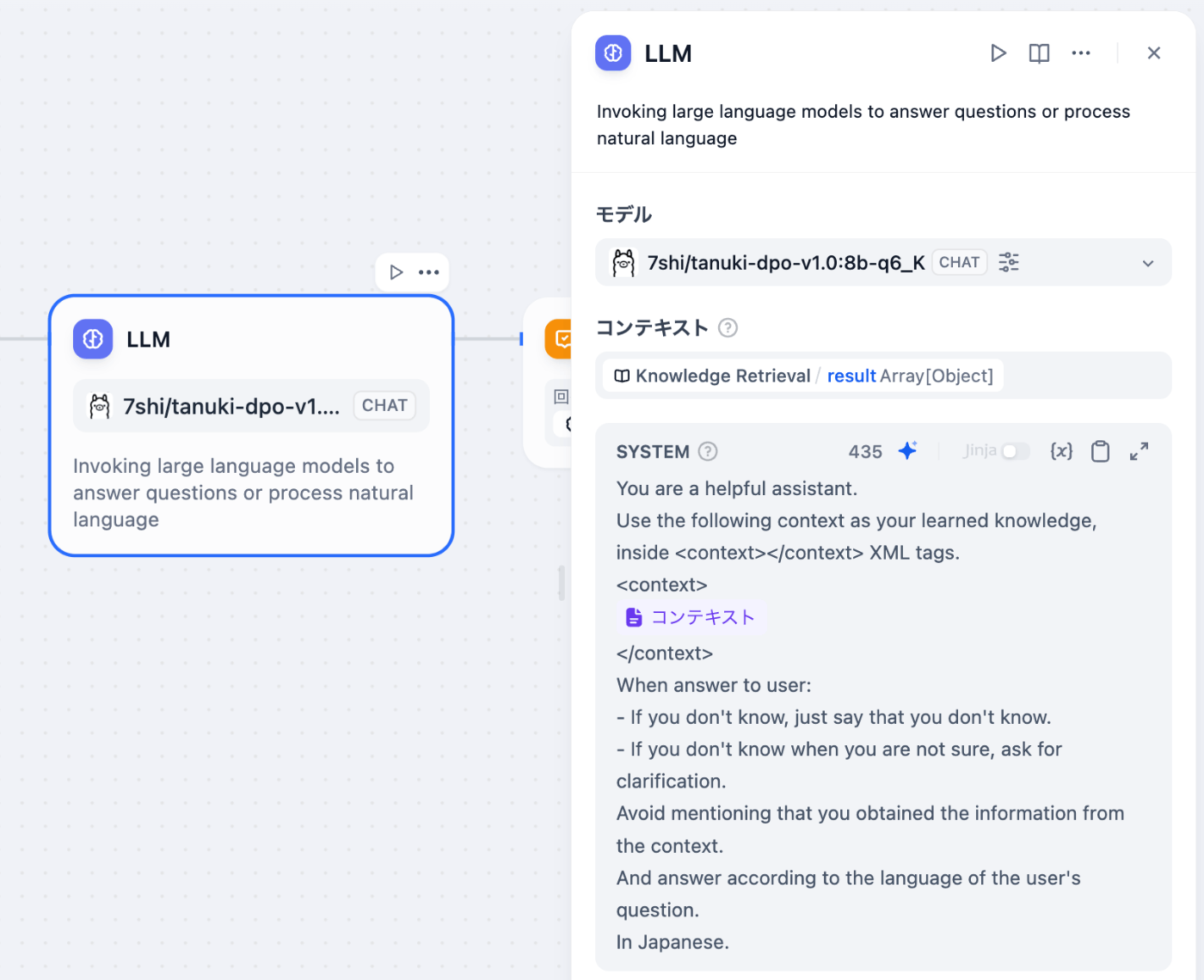
LLMは、先程追加したOllamaのモデルプロバイダーを選択して、コンテキストにはKnowledge Retrievalを設定します。
これでRAGシステムの構築は完了です。
RAGシステムの動作確認
システムが構築できたので、右上の「公開する」のドロップダウンボタンから「アプリの実行」を選択して、チャットボットを動かして動作を確認しましょう。
Difyについて聞いてみます。Difyについて聞くと、知識をもとにそれらしい回答が返ってきました。

ちなみに、ナレッジを使わないシンプルなチャットで同じ質問をしてみると以下のように盛大にハルシネーションをします。

簡単な確認ですが、RAGが機能していることが分かります。
まとめ
Tanuki-8BとOllamaとDifyを使って、手軽にローカルで動く日本語RAGシステムを構築してみました。
実際に試してみると、Tanuki-8Bがサイズが小さいのに、日本語の性能が高いので、今回のようなローカルで日本語RAGシステム構築したいときにはピッタリだと感じました。
Ollama、Difyを組み合わせることで、ノーコードで手軽にRAGシステムができるのもとても手軽で便利だなと感じました。
松尾研究所では、以下の図で示す通り、松尾・岩澤研究室の研究結果を活用し、新たな価値創造をし、次世代研究や人材育成に還元していくエコシステムの実現を目指しています。
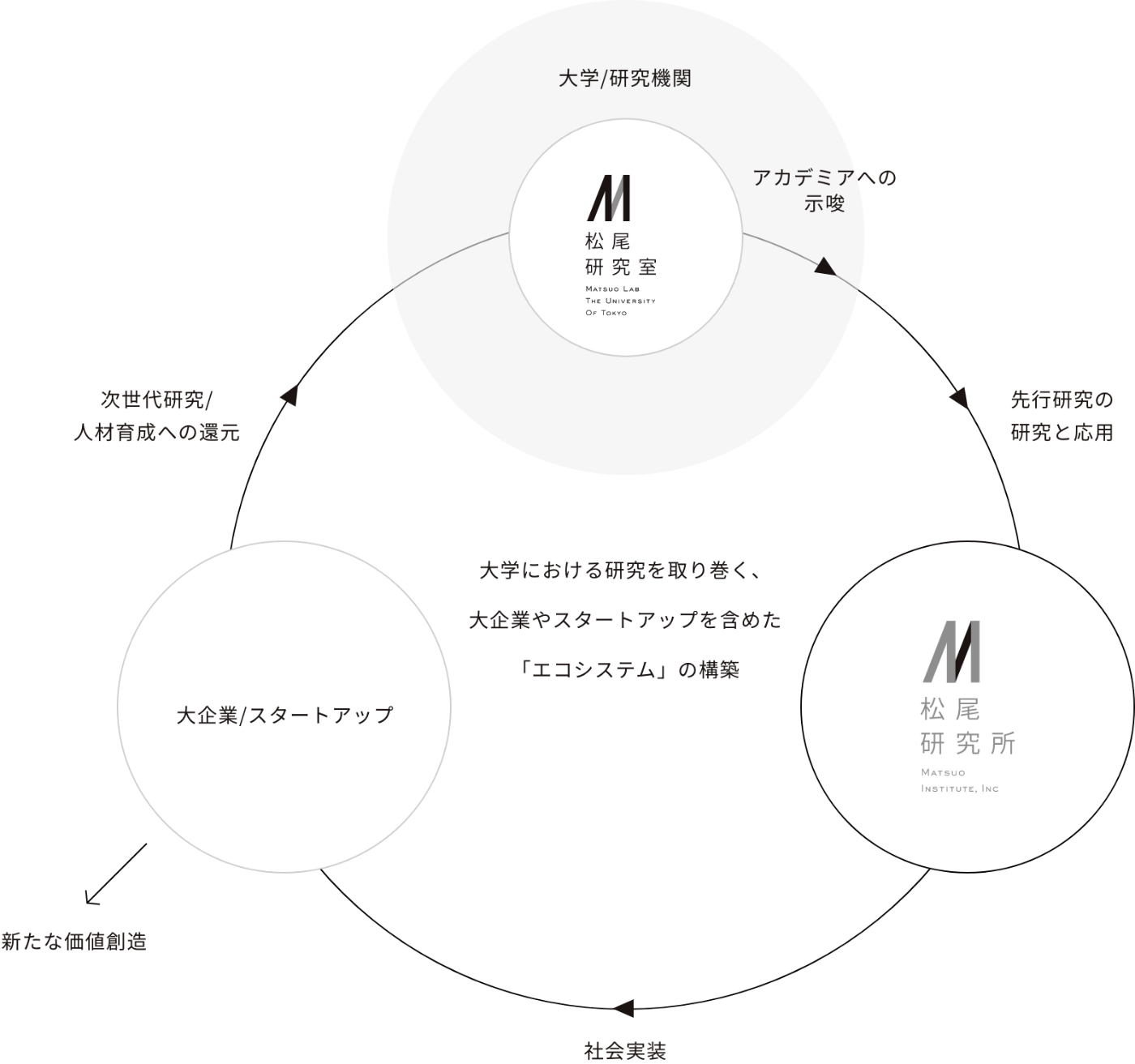
今回は簡単な例ですが、松尾・岩澤研究室の成果であるTanuki-8Bの活用方法を紹介しました。RAGシステム1つとっても、性能向上の手法は多数あり非常に奥が深いものです。今後もテックブログでは、社会実装に役立つ、様々なLLMの活用方法・テクニック等について発信していきたいと思いますので、今後ともよろしくお願いいたします。
参考リンク

Discussion