論文解説|DETRs with Collaborative Hybrid Assignments Training

識別スコアの可視化。
Co-Deformable-DETRが提案手法でより物体にスコアが集中している事を示している。
DETRs with Collaborative Hybrid Assignments Training
1. はじめに
DETR(DEtection TRansformer)[1]はObject Detectionの(たぶん)最初のTransformerモデルとして非常に有名だと思います。今回の論文はDETRを改良する論文で推論時の計算コストは変わらないのにも関わらず精度を向上させる手法を提案している論文です。
従来のObject Detection手法(例えばFaster-RCNN[2])は、予測に対するラベルは一対多になるように割り当てを行い、学習をします。しかしDETRは一対多のマッチングを行わず一対一で学習を行うため、従来の検出手法よりも精度が低下すると筆者は言っています。
これを軽減するため、本研究では新しい訓練方法であるCo-DETR(Collaborative Hybrid Assignments Training)を提案しています。この学習方法は、ATSS[5]やFaster RCNN[2]などの一対多学習の検出ヘッドを追加で訓練することで、エンコーダの学習能力を向上させます。推論時には検出ヘッドはDETRのヘッドのみが使われるため、追加のパラメータや計算コストは発生しません。
2. 事前知識
最初にOjbect Detectionにおける予測とラベルの学習方法について解説します。Object Detectionでは予測とラベルをマッチングさせ、ラベルに近づけるように学習させます。一対一マッチングではハンガリアン法などを用いて予測とラベルの対応関係が一対一になるようにし、予測がラベルに近づくように学習します。対して一対多のマッチング法ではマッチングしなかったものに対して遠ざけるような学習を行い、学習のサポートをさせます。この考え方は対照学習に似ており、一対多の学習のほうが多様性があり、精度が上がりやすいという特徴があります。
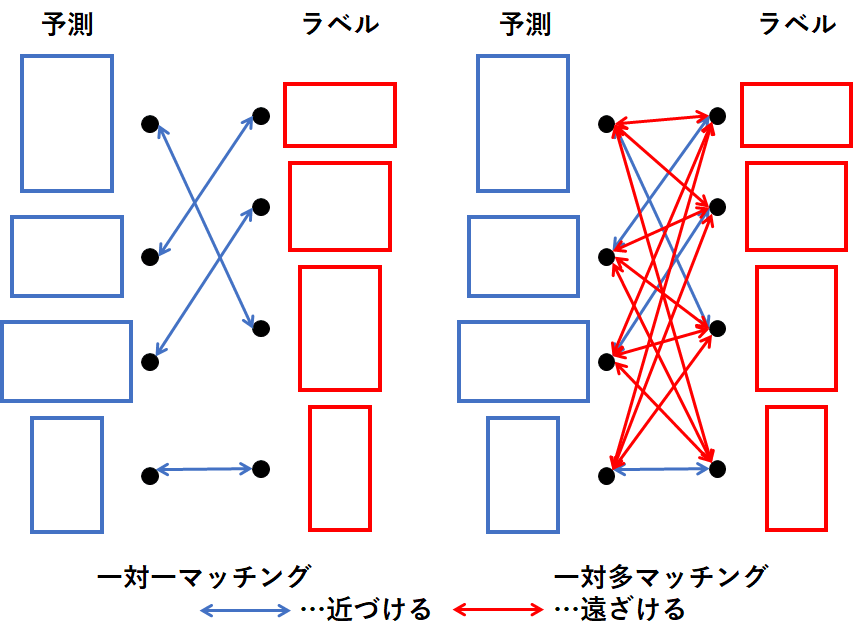
また、本論文では非常に多くの従来手法を用いています。全てを解説していると記事の量がとんでもなく増えるため、概要だけまとめます。
2.1 DETR[1]
Transformerを用いた(たぶん)最初のObject Detectionモデル。Encoderで得られた特徴と物体の情報をもつqueryとの関係を学習し物体を検出するアンカーフリーな手法を提案しています。
2.2 Deformable DETR[3]
DETRの改良。DETRの問題点であった小さい物体の検出が難しい点をマルチスケールの特徴を使うことで解決しました。また、学習の収束に時間が掛る問題点があったため、それを解決するためにより帰納バイアス[1]が高いDeformable Attention Moduleを提案し、学習効率を向上させました。
2.3 DINO Deformable DETR[4]
Deformable DETRの改良。DETRの出力は1つの物体に対して重複するという問題点がありました。それに対しContrastive DeNoising Trainingという手法を提案しており、ポジティブ(ラベルに少しノイズを加えた物)サンプルとネガティブ(ラベルに大きなノイズを加えたもの)サンプルの両方を使用し、モデルがより識別力のある特徴を学習できるようにしています。また、queryを位置情報とコンテンツ情報(物体の情報など)に分け学習することでより位置情報を考慮するように学習するMixed Query Selectionを提案しています。他にもLook Forward Twiceという学習を安定化させる手法も提案しています。
2.3 Faster RCNN[2]
Object Detectionの代表モデル。Fast RCNNという手法の改良で特徴マップに対してROI pooling(サイズが違う特徴を同じサイズにする手法)を行うことで高速に推論を可能にした手法です。
2.4 ATSS[5]
ATSSはObject Detectionの根本的な学習方法の改善をしている。トレーニングサンプルを自動的に選択する手法や一対多のマッチングのためのポジティブサンプルの選択方法を提案し、Object Detectionは学習方法が重要であることを示している(本論文の考え方に似ている)。
3. 提案手法
手法を簡単に説明するとATSSやFaster RCNNなどの一対多学習を行う検出ヘッドを追加し学習の補助をさせます。その後推論の時はDETRの検出ヘッドのみを使い、学習補助ヘッドは破棄します。そのため、推論時間や使用メモリは増えずに高精度に推論を行うことができます。提案手法は様々な手法に組み込むことができ、汎用性が高い物になっています。
概要は非常に簡単ですが、詳しく話すと非常に長いです。

概要図を使いながら詳しく説明します。青枠の部分は学習と推論時に実行される部分で、赤枠の部分は学習時のみ行われる部分です。
- CNNモデルから得られた特徴マップとTransformer encoderを用いて画像の特徴を取得します。ここの流れはDETRと同様です。
- その後objectを表すqueryとencoderから得られた特徴を用いて物体検出を行います。1.→2.の流れはDETRと同様です。
- ここではencoderから得られた特徴マップをマルチスケールに変換します。ViTDet[6]の手法を用いており、1つのスケールの特徴マップにダウンサンプリングやアップサンプリングをしてマルチスケールにしています。

ViTDetから引用 - Auxiliary HeadはFaster RCNNやATSSなどの従来手法の検出ヘッドの事を示しており、
k \mathcal{A}_1 \mathcal{A} G \hat{P} P^{\{pos\}} P^{\{neg\}} B^{\{pos\}}
下の表にはマッチング方法

Auxiliary Headでは様々な種類の従来手法で学習を行うことでencoderの特徴抽出能力を向上させています。
- ここでは従来手法で得られた位置情報
B^{\{pos\}}
PEはPositional Encodingを表しており、
3.1 なぜCo-DETRが機能するのか
筆者はなぜCo-DETRが機能するのかを論文内で考察しています。DETRはハンガリアン法によって予測とラベルを一対一で結び付け、学習を行います。そのためにクエリは少なくなるように設定されており[2]、少ないポジティブクエリによって学習効果が薄まってしまうと筆者は言っています。一方で、一対多ラベル割り当て方式でのポジティブサンプルは、より多くの影響を受けるため、潜在的な特徴学習を強化するのに役立つようです。
また、筆者はハンガリアン法の不安定性についても言及しています[3]。下の図は従来手法(青色)と提案手法(オレンジ色)のハンガリアン法の不安定性を評価しています。横軸が学習回数、縦軸がハンガリアン法の不安定性を表しています(高ければ不安定)。提案手法では学習補助ヘッドによって安定した学習を行えているため、結果的にハンガリアン法が安定した出力になっていることを示しています。

4. 実験結果
実験結果のすべてを載せると非常に多くなってしまいますので、抜粋して紹介しています。
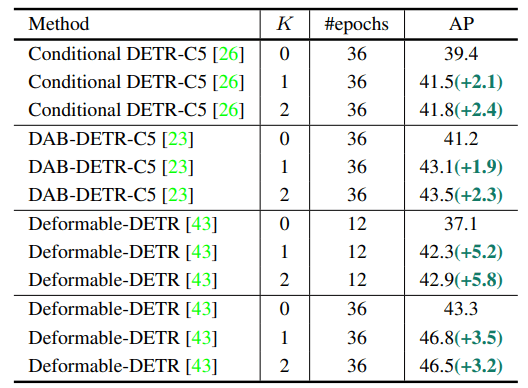
下の表では従来手法に提案手法の学習補助ヘッドを追加した時の精度を示しています。
下の表はどのような従来手法を適用したのかのablation studyになります。ATSS+Faster-RCNNが一番学習時間と精度の効率がよさそうです。ヘッドを増やせば増やすほど精度が上がるわけではなく、2つが丁度いいという結果になりました。筆者の考察では、補助ヘッドの"競合(conflict)"が起こることで学習に悪影響が及ぼされるためと言っています。

この考察を裏付けるために実験が行われています。筆者は、同じ空間座標の予測が各ヘッドによって前景や背景クラスに割り当てられてしまうと矛盾が生じ学習が混乱してしまうと主張しています。この事を確かめるために各補助ヘッドの判断根拠マップのKL divergenceを計測しその値を下の表に示しました。KL divergenceが高いとそれぞれのヘッドが見るところが違う事を示しているため矛盾している事を示しています。

どの手法同士が競合しているのかという実験は補足資料で載せられており、PAA[8]という手法が競合を起こしやすいようです。

他にも補助ヘッドの精度も向上しているという結果もあるのでぜひ論文をお読みください!
5. まとめと感想
本研究では、DETRベースの検出器において一対一マッチングによる学習の効率が悪いという問題に対処するために、複数の検出ヘッドを並列に学習させる手法を提案しました。githubのstarが高いから読んでみたのですが、非常に丁寧な論文で読んでいてすごく読みやすかったです。また、読者が疑問を持つような所を予想しているように痒いところに手が届くablation studyをしていて非常に良かったです。こんな論文を書けるようになりたいですね…。
今回の論文は非常におすすめの論文です!ぜひ読んでみてください!
6. 論文のリクエスト
解説してほしい論文のリクエストを受け付けています!
リクエストから2週間程度で記事を作成したします。
どなたでもお気軽にリクエストしてください!
参考文献
[1]
Carion, Nicolas, et al. "End-to-end object detection with transformers." European conference on computer vision. Cham: Springer International Publishing, 2020.
[2]
Ren, Shaoqing, et al. "Faster r-cnn: Towards real-time object detection with region proposal networks." Advances in neural information processing systems 28 (2015).
[3]
Zhu, Xizhou, et al. "Deformable detr: Deformable transformers for end-to-end object detection." arXiv preprint arXiv:2010.04159 (2020).
[4]
Zhang, Hao, et al. "Dino: Detr with improved denoising anchor boxes for end-to-end object detection." arXiv preprint arXiv:2203.03605 (2022).
[5]
Zhang, Shifeng, et al. "Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020.
[6]
Li, Yanghao, et al. "Exploring plain vision transformer backbones for object detection." European Conference on Computer Vision. Cham: Springer Nature Switzerland, 2022.
[7]
Zhang, Hao, et al. "Dino: Detr with improved denoising anchor boxes for end-to-end object detection." arXiv preprint arXiv:2203.03605 (2022).
[8]
Kim, Kang, and Hee Seok Lee. "Probabilistic anchor assignment with iou prediction for object detection." Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXV 16. Springer International Publishing, 2020.
Discussion