DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
最新でSoTAのEnd to End 物体検出モデル
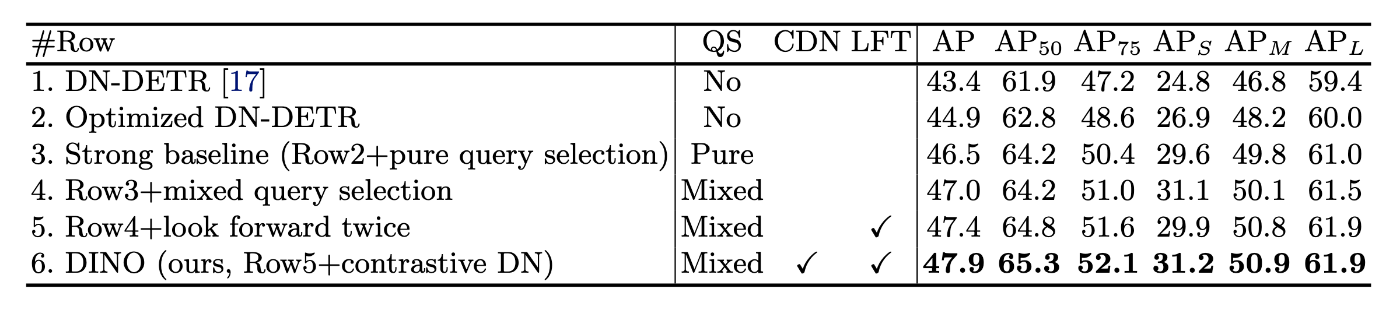
DETR系のモデルで、Denoising trainingによるContrastive法、アンカー初期化のための混合クエリー選択法、Box予測による2重先読み (look forward twice sheme)
ResnetからSWinLへのバックボーンの変更で容易にスケール
DETRは、物体検出を集合予測タスクとしてモデル化し、二分割グラフマッチングによってラベルを割り当てる。
=> 予測した結果と正解の2部マッチング(ハンガリアン法) => loss計算

object queries (物体クエリ)とは、画像内から物体検出と分類をするために学習される値
ここを学習することで、Decoderの入力と使用でき、パラレルDecoderとして扱うことができる。
解析の結果、Object queriesの1つ1つが別々のエリアやボックスサイズに特化して学習されている。
FFN後の推論結果 (クラス、BBox)
DETR系のモデルは、バックボーンの大きさやデータセットの大きさでスケーリングしないという課題があった。
これの解決を目指したのがDINO!
Denoising training, query initialization, box predictionの改善をしたものがDINO


Conditonal DETR, DAB-DETRで、クエリ部分が、位置部分とコンテンツ部分の2つから形成されることがわかり、それぞれ、位置クエリ、コンテンツクエリと呼ばれる。
DAB-DETRは、各位置クエリを4Dのアンカーボックス(x,y,w,h) (x,wはBox中心) として定式化し、アンカーボックスによるデコーダの各レイヤーの動的変更が容易になった。 (アンカーボックスは、位置クエリのことで学習パラメータ)
DN-DETRは、DETRモデルの学習収束を加速するため、denoising (DN)学習法を導入した。
DETRの収束遅い問題は、二分割マッチングの不安定性によって引き起こされたことを示し、ノイズの入ったGT(クラスラベル+BBox)もデーコーダのクエリに追加し、GTを再構成するように訓練させた。学習の安定化に寄与し、高速に収束することを示した。
Deformable DETRは、DETRの収束を早めるための初期研究の一つです。
Deformable Attentionは、変形可能なself attentionを提案。(Deformable Convlutionの導入)
特徴マップの重要な領域に対して、Attentionを行うことで、効率よくトークン間の関係性をモデリング
オフセットネトワークによるクエリから学習された変形可能なサンプリングポイントを利用することでAttention領域を決定 (特徴選択)
クエリ選択により、デコーダの入力として、エンコーダ出力から特徴と参照BBoxを選択.
2つのデコーダ層間の慎重な勾配切り離し設計による、反復的BBoxの洗練化。この勾配切り離し技術をlook forward onceと呼ぶ

Contrastive DeNoising Training
DN DETRは、近くに物体がないアンカーに対して「物体なし」と予測する能力がない。この問題を解決するために、無駄なアンカーを排除するContrastive DeNoising (CDN) アプローチを提案

黄色の部分、各GTに対応した(BBox, Label)に少しノイズを乗せたもの
茶色の部分、各GTに対応した(BBox, Label)に大きなノイズを乗せたもの
CDNの各グループはGT個のPositive, Negative queryを持つ。
1つの物体に複数のアンカーが近接している場合に発生する混乱を抑制する効果
この場合、モデルはどのアンカーを選択すべきかを判断することが難しくなる。このような混乱は、2つの問題を引き起こす可能性がある。一つ目は、予測の重複である。DETRのようなモデルは、Attentionの助けを借りて重複ボックスを抑制することができるが、この能力には限界がある。
2つ目は、GTボックスから遠い不要なアンカーが選択される可能性があることである。
CDNではさらに遠方のアンカーを拒否するようにモデルを教育することにより、この能力を向上させる。
Mixed Query Selection

DETR, DN-DETRは(a)で、アンカークエリは学習、コンテンツクエリは0ベクトル
Deformable DETRは(b)でアンカークエリとコンテンツクエリの両方を学習 + 最後のレイヤからK個のエンコーダ特徴を選択するクエリー選択を行いデコーダクエリを強調。
(選択した特徴の線形変換 => BBoxを予測 => 位置クエリの初期値に使用)
Efficient DETRなどでは、各エンコーダ特徴から得られるクラススコアに基づいて上位K個を選択
Mixed Query Selection (c)は、選択されたトップK特徴に関連する位置情報を用いてアンカーボックスのみを初期化し、コンテンツクエリは従来通り静的なままとする。
選択された特徴は、さらに洗練されることなく予備的な内容特徴であるため、デコーダにとって曖昧で誤解を招く可能性がある。例えば、選択された特徴量は複数のオブジェクトを含んでいたり、オブジェクトの一部分だけであったりすることがある。これに対し、Mixed Query Selectionアプローチは、上位K個の選択特徴を用いて位置クエリを強化するだけで、内容クエリは従来通り学習可能なままとする。これにより、モデルがより良い位置情報を使って、エンコーダからより包括的なコンテンツ特徴を学習することができるようになる。
Look Forward Twice
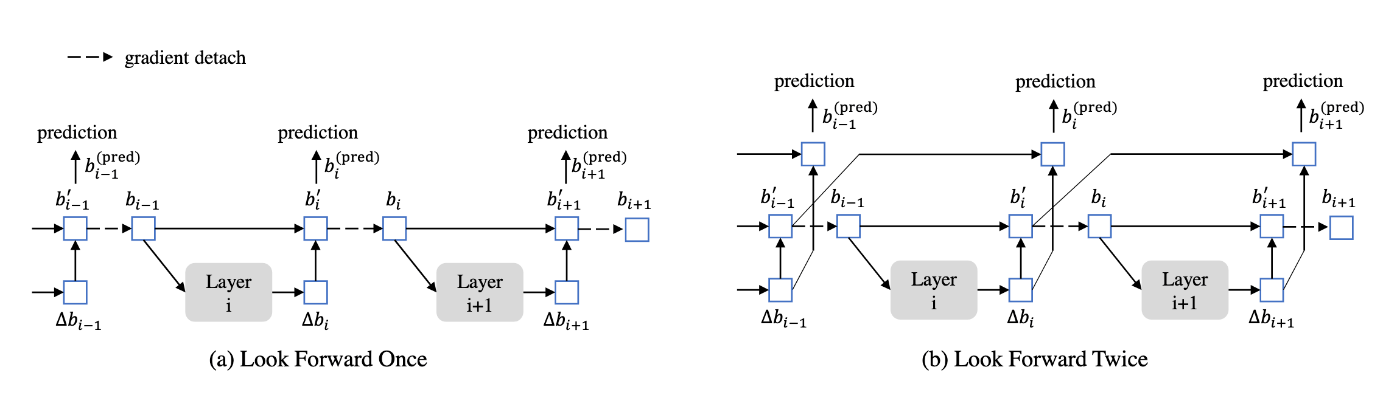
(a)Deformbale DETRでは、学習を安定化されるため、逆伝搬をブロック化(Detach)
しかし、後の層から改善された箱の情報は、隣接する初期の層の予測を修正するのに有益と考えられる。
(b)のように、(i+1)の層の損失の影響も受けるように修正