Deformable DETRの解説
概要
DETRには以下の弱点がある。
- 高解像度の画像を扱うことができない。
- 収束に非常に長い時間がかかる。like 10x ~20x slower than Faster R-CNN.
高解像度画像を扱うことができないのは計算量が
この2つの課題を緩和するためにDeformable DETR = 画像の一部にのみ注目するTransformerを提案する。
Method
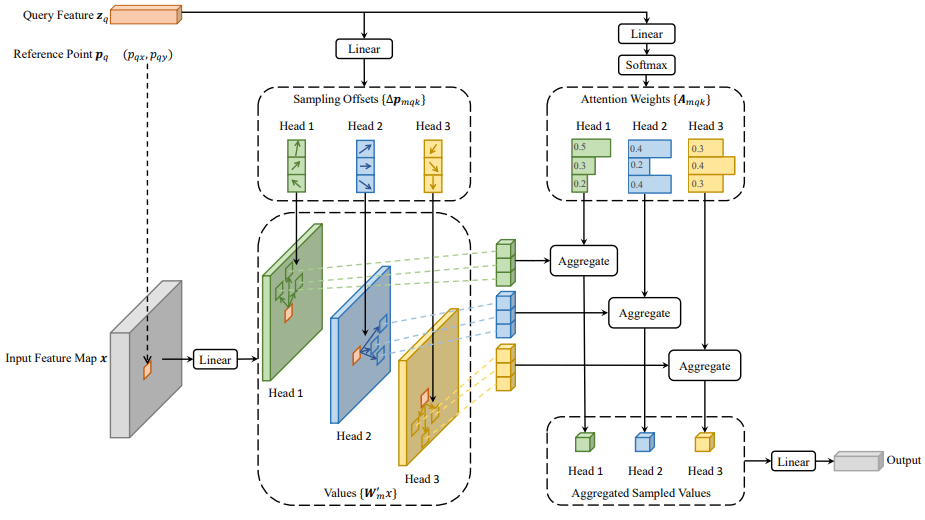
Deformable ConvolutionにInspireされ、画像のスパースな一部の点まわりからのみ情報を受け取るDeformable Attention Moduleを提案。
Deformable Attention Module
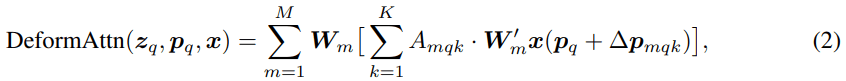
このModuleはK個の可変な位置
具体的には図の上部にあるように
Multi Scaleへの拡張
マルチスケールな情報を使うことは近年のObject Detectionで基本になっている。Deformable Attentionも自然にマルチスケールへ拡張することができる。
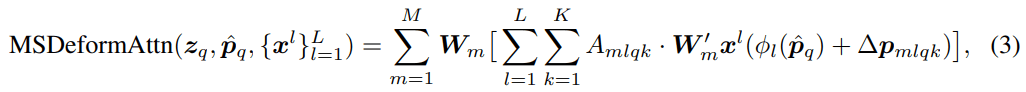
のようにしてMulti-Scale Deformable Attention Moduleを定義できる。
Deformable Convolutionとの違い
つまりDeformable Convolutionはシングルスケールの入力画像に対してAttention Headあたり1つのReference Pointを持つDeformable DETRと考えることができる。
評価
定性的評価

図では出力を画像で微分した値が大きい点を赤く塗ったものである。モデルはBounding Boxの中心
定量的評価
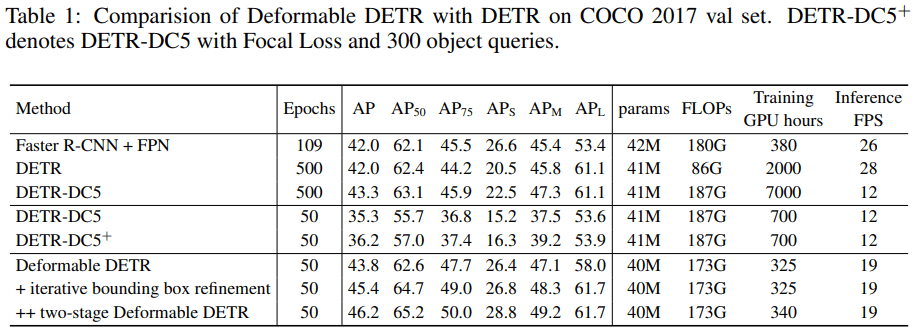
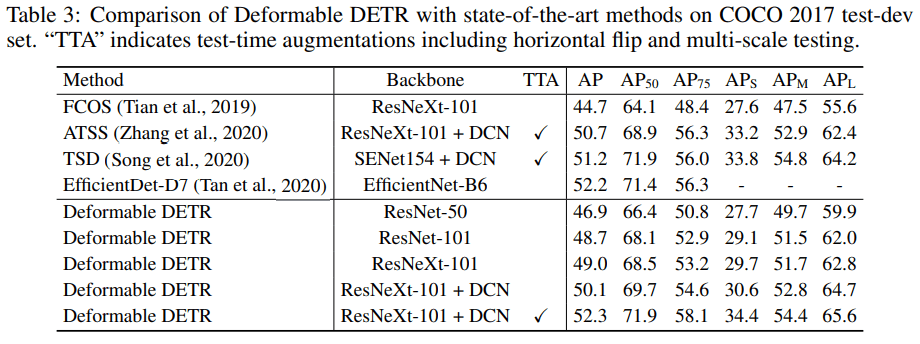
DETRと比べて同等以上。速度はFaster R-CNNとDETRの間。学習Epochsが1/10になっている点にも注目。
まとめ
End2EndなObject DetectionモデルであるDETRの弱点を克服し、推論も学習の収束も早く性能も改善したDeformableなTransformerが誕生した。MMDetectionを使えばこんな感じで簡単に実装もできるよう。
Discussion