【Next.js】生成AIによる「お絵描きサポートWebアプリ」を作りたい!【全くわからない人】
はじめに
ここ数ヶ月間、いろいろな生成AIに触ってきて、Google Colabを使って実行することをしてきました。
(これまでの軌跡はこちらから)
そこでせっかくだから動くWebアプリでも作りたいなあと思ってきましたので実際に作ってみたお話です。(普段の息抜きで作っているので、コードも記事も雑ですがご容赦)
著者について
私は、生成AI関係に関しては、業務でいろいろ触っていることもあり、ある程度動かすことはできると思っています。(記事も空き時間にそこそこ書いています)
Pythonに関しては、大体6-7年くらい触り続けています。
フロントエンドに関しては、全く触ってこなかったので無知です。
一方で、業務では、フロントエンドを触り込んでいるメンバーが多いチームに所属しているため、情報だけはちょっと入ってくる環境です。
「どうも、今はNext.jsが熱いらしい」、「App Routerというやつで作るといいらしい」、「Tailwind CSSというのがあるらしい」、そんな感じの知識レベルなのが著者になります。
ただ、Webアプリを作る上でフロントエンドは避けては通れないので、ChatGPTを最大限活用して、とにかく動くものを作ろうと思っています(デザインなどは二の次、どうせ外に出すものではないので)。
つくるWebアプリ
どんなWebアプリを作ろうかなと思った時に、せっかくなので絵が壊滅的な私でも、可愛い女の子の絵を描いてみたいと思い、画像生成AIを利用したWebアプリを作ろうと思います。
とは言っても、ただ「プロンプトを入力して絵を出力させる」、だけのアプリを作っても、自分が絵を描いた感覚にならないので、下記のようなフローを考えています。
- Apple Pencilを使って、自分でタブレットに落書きを書いてみる
- 自分が描いた絵を元に、プロンプト情報から、画像生成AIに絵を出力してもらう
- 自分が想定している絵と違った場合、変更したい場所を範囲選択して、その範囲だけ別のプロンプトを適用して修正してもらう。
上記のようなフローを達成することで、限りなく自分が描きたい絵に近い絵を出力することができ、また、自分が書いた絵が前提となっているので、自分で絵を描いている感覚になれるかなと思いました。
(しかも、自分で下書きを書けるので、より状況や構図を指定してAI絵を出力できるのでは?と思っています)
外に出すようなものではないので、色々雑に作りました。
(とりあえず、動けばいいと思って)
技術選定・動作環境
技術選定
下記の通り選定しました
フロントエンド:Next.js(App Router)
バックエンド:Python
画像生成AI:Stable Diffusion XL(SDXL) + ControlNet(Scribble, Inpaint) + LCM-LoRA
モデル:ANIMAGINE XL 3.1
フロントエンドはチーム内で主に使われている技術のため、ちょっと勉強がてら使ってみようかなという感じ、バックエンドは、Stable DiffusionをDiffusersライブラリを利用して動かす関係上、やむなしという感じです。
また、画像生成AIに関しては、現時点でローカルで利用できて、高画質なアニメ絵を生成できるSDXLのANIMAGINE XL 3.1を利用します。
(風景画を描きたいとか、リアルな人物の絵を描きたいとか、用途に応じてモデルは変更してください)
また、少しでも画像生成をする速度を向上させるために、LCM-LoRAという技術を利用します。
こちらを利用することで、通常28 Step必要な生成処理を4 Stepで生成することができるようになるため、かなり高速に処理ができるようになります。
なお、バックエンドでSDXLを利用する方法は、下記の記事で記載した内容をベースに作っています。興味があればご一読ください。
LCM-LoRAに関しては、まだ私の方で解説記事を書いていませんが(いずれ書きます)、基本的には、上記の記事のLoRA部分をLCM-LoRAに入れ替えて、Step数とスケジューラをLCM用のものに変更するだけで綺麗に動作すると思います。
動作環境
動作環境は下記です。
端末:Ipad 無印 第8世代
フロントエンドサーバ:M2 Mac
バックエンドサーバ:Ubuntu 20.04 (GPU:RTX3060 12GB RAM:64GB)
(もしくは、Google Colabでも動作確認済みです。ちょっと遅いですが。GPUが利用できるPCを利用してください)
できたもの
勿体ぶっていても仕方がないので、現時点でどんな感じのものができているのか、動画で用意しています。
フロントエンドのUIUXや機能など、全く至らない点は多いですが、一応動いているのでまあいいかなと思っています。
(画像生成AIの質に関しては、今さら言うまでもないですね。技術の進歩は本当にすごいです)
また、本当は落書きをしながら、リアルタイムに絵を生成して、横に逐次表示をしたかったのですが、SDXLだと流石にリアルタイムで処理をするのは難しかったので、実行ボタンを押すことで絵が生成されるように設計を変更しました。
機能としては下記の通りです。機能を最低限にした、シンプルなWebアプリですが、書き出すと結構多いですね。
- PromptとNegative Pronptを入力して「適用」ボタンを押し、バックエンドに送信
- 左側の黒いキャンバス内で落書きを行う。(色は白のみ、増やしていきたい)
- 書き直したい場合は「clear」ボタンを押すと最初からにできる(消しゴム機能はつけたい)
- キャンバスのサイズは正方形固定です(サイズを変更できる機能は欲しい)
- 絵を描き終わったら「実行」ボタンを教えて、バックエンドに情報を送信
- バックエンド側で画像生成AIを実行し、生成結果をフロントエンドに送信
- 受け取った画像をフロントに表示。
- 「save」ボタンを押せば画像を保存可能、「clear」ボタンを押すことでリセット可能
- 生成された画像を長押しすることで、保存も可能
- 「Inpaintモード」のボタンを押すことで、モードを変更
- 左側に写った画像から選択範囲をフリーハンドで設定
- 設定された選択範囲に基づいて、Inpaintマスクを生成
- やり直したい場合は、再度左側の画像で、範囲を設定し直すことで再設定可能
- 選択範囲における修正要件をPromptとして再度入力し、「適用」ボタンを押して、バックエンドに送信
- 「実行」ボタンを押して、バックエンド側に元画像とマスク画像を送信
- バックエンド側で画像生成AIを実行し、生成結果をフロントエンドに送信
- 受け取った修正後の画像をフロントに表示
- 「save」ボタンを押せば画像を保存可能、「clear」ボタンを押すことでリセット可能
- 生成された画像を長押しすることで、保存も可能
- 「OK」ボタンを押すことで、今回生成された修正画像をベースに、再度修正範囲を設定することで、再修正が可能
- 「NG」ボタンを押すことで、今回の修正結果をリセットし、修正前画像と、前回マスク画像を再度ロードする。したがってPromptだけ再度適用しなおせば、同じ範囲でもう一度修正が可能
- もちろん、再度修正範囲を再設定して、同様に修正が可能
今回、フロントエンドについては全く知識がない状態から、ChatGPTだけを頼りに進めました。
ChatGPTは本当にすごいです。
どのくらいすごいかというと、上記の必要最低限な機能を持つフロントエンドを、ほとんどChatGPT任せで
全く知識がない状態から、一晩で、作成しました。
(Pythonはわかるので、バックエンドは自分で作りました)
副作用としては、今でも私はNext.jsについて全然わかっていないです(勉強にはなりませんでした笑)
需要があれば、ChatGPTを利用して、どうやって作ったのかの記事も書こうと思います。
ここで簡単に書くと、一度に全部作ってもらうのではなく、大枠のハリボテから少しずつ機能を追加してもらう形で作成していきました。
(「sketchモードのハリボテ」→「Inpaintモードのハリボテ」→「APIの導入」と言う流れ)
あと、バックエンドも動けばいいと思って、かなり雑に作っています。
(複数端末からの同時接続など、全く考慮していないです)
また、お絵かき端末のダークモードにも対応してません。
どうせ、外に出すようなものではないからいいかなと。
成果物
下記のリポジトリに置いてあります。
動作方法
環境構築
フロントエンドとして、Next.js+pnpm、
バックエンドとしてPythonが利用できる環境(もしくはGoogle Colabが利用できる環境)になっていれば問題ありません。
既に、利用できる方は下記のステップは飛ばしてください。
環境構築
フロントエンド、バックエンド両方
gitを導入している方は下記のコマンドで、リポジトリをクローンしてください
git clone https://github.com/personabb/drow_ai_app_nextjs_public.git
gitを導入していない場合は、下記のページで緑色の「Code」ボタンをクリックして、下の方にある「Download ZIP」をクリックすることでダウンロードできます。
この後は、このリポジトリをカレントディレクトリとして、コマンドなどの実行をしてください。
このリポジトリ自体は、Desktopにおいても良いですし、そのままDownloadにおいておいても良いですが、ターミナルのカレントディレクトリだけ、このディレクトリを指定しておいてください。
フロントエンド (Next.jsの環境構築)
フロントエンドではNext.js(+ pnpm)を利用しています。
下記の通り、環境構築をしてください。(Macを想定しています。Windowsの方申し訳ございません)
(去年の環境構築に使った資料やスクリーンショットを引っ張ってきているので、古いかもしれません。最終的にNext.js(+ pnpm)を利用できるようになっていればいいので、他の方法で環境構築しても構いません)
Brewの導入(導入済みの方はスキップ)
バッケージインストーラであるbrewを導入します。
ターミナルを起動して、下記コマンドを実行してください。パスワードを求められるので入力してください。
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
途中でEnterキーを押すことを求められます。押してください。
下記のコマンドで環境変数にパスを通します(一行ずつ実行してください)
echo 'eval "$(/opt/homebrew/bin/brew shellenv)"' >> ~/.zshrc
eval "$(/opt/homebrew/bin/brew shellenv)"
PATH=/usr/local/bin:$PATH
export PATH
下記のコマンドを実行して、brewのバーションが表示されれば成功です。
brew -v
Node.jsの導入(nodebrewの導入)
下記コマンドでnodebrewをインストールします
brew install nodebrew
下記の画像の赤枠部分の記載されているコマンドを実行します(人によっておそらく違うのでよく見てください)

上記の画像なら下記コマンドです
/opt/homebrew/opt/nodebrew/bin/nodebrew setup_dirs

続いては、上記の画像の、赤枠の部分に記載されているPathを環境変数に追加します。
上記の画像なら、下記のコマンドで環境変数を追加できます。
echo export PATH=$HOME/.nodebrew/current/bin:$PATH >> ~/.zshrc
ただし、export PATH=$HOME/.nodebrew/current/bin:$PATHの部分は、皆様の実行画面(の赤枠の部分)に合わせて変更してください。
その後、設定した環境変数を適用するために下記コマンドで更新します。
source ~/.zshrc
Node.jsの導入(Node.jsの導入)
導入したnodebrewを使ってnodeのvarsion 19.6.1をインストールします。
(インストールするバージョンは、おそらくなんでもいいです。私が上記の環境のため書いていますが、基本は最新のバージョンをお勧めします)
下記のコマンドを実行します
nodebrew install v19.6.1
Installed successfullyと表示されればOKです。
続いて、インストールしたnodeのvarsion 19.6.1を利用できるように下記コマンドを実行します。
nodebrew use v19.6.1
use v19.6.1と表示されればOKです。
nodebrewを利用することで、複数のバージョンをインストールして、用途ごとにバージョンを使い分けることができるようになっています。
(もちろん、最終的にNext.js(+ pnpm)が利用できればいいので、他の方法でインストールしても良いです)
pnpmのインストール
下記コマンドでpnpmをインストールします
npm install --global pnpm@8.6.0
以上で、Next.jsとpnpmが利用できるようになりました。
バックエンド(ローカルPCを利用)
カレントディレクトリを./drow_ai_app_nextjs_public/drow_ai_backendに設定するために、下記のコマンドを実行します。
cd drow_ai_backend
pythonの導入
前提として、pythonのバージョンは3.10もしくは3.11を利用します。
pythonはpyenvを利用して、バージョンを指定しながら導入します。
pythonのバージョンはpyenvで指定します。
pyenv自体の導入については下記をご覧ください。
pyenvが導入できていれば、下記のコマンドでpythonのバージョンを指定できます。
pyenv install 3.10.14 #もしくは3.11.9など
pyenv local 3.10.14 #もしくはpyenv global 3.10.14
これでpythonのバージョンが指定できます。
pyenv globalはシステム全体に、このバージョンを反映させたい時に利用してください。
pyenv localは現在のカレントディレクトリでのみ、このバージョンを反映させたい場合に利用します。
下記コマンドを実行して、pythonのバージョンが変更されているかを確認してください。
python -V
# Python 3.10.14
pythonの仮装環境の設定
続いて、必要なパッケージをインストールするために仮想環境を構築します
venvで仮想環境を構築します。
venvはpython公式の仮装環境のため、pythonが利用可能であれば導入の必要なく利用できます。
python -m venv env
source env/bin/activate
以降、バックエンドを実行する場合は、この仮装環境に毎回入って実行してください。
次回以降、仮装環境に入るだけなら下記コマンドだけで大丈夫です
source env/bin/activate
バックエンド(Google Colabを利用)
Google Colabを利用する場合は、環境自体は構築済みなため、特に必要な処理はありません。
強いていえば、Googleアカウントを作成してください。
実行準備
フロントエンド
カレントディレクトリは./drow_ai_app_nextjs_publicを想定しています。
バックエンドのURLを設定
.env.localをリポジトリ直下(./)に作成して、下記の通り設定してください。
URLはバックエンドサーバのURLです。(以下は例です)
NEXT_PUBLIC_API_BASE_URL=http://192.168.0.xxx:8000
(バックエンドサーバのプライベートIPアドレスを予め確認しておいてください。ポートは8000です)
http://192.168.0.xxxの部分は、バックエンドサーバのURLを指定してください。
Next.jsで必要なパッケージのインストールとビルド
下記のコマンドを一つずつ実行してください。
pnpm i
pnpm build
バックエンド(ローカルPCの場合)
バックエンドの準備では、./drow_ai_backendをカレントディレクトリとして、それ以降のコマンドを実行してください。
pythonパッケージのインストール
必要なpythonのパッケージをインストールします。下記コマンドを実行してください。
pip install -r requirements.txt
LoRAファイルの取得
バックエンドサーバ側で利用するLoRAモデルを予め取得してください。
上記2つのLoRAを取得して、DreamyvibesartstyleSDXL.safetensorsとlcm-animaginexl-3_1.safetensorsにリネームして、ローカルフォルダのdrow_ai_backend/inputsフォルダに格納してください。
ちなみに
DreamyvibesartstyleSDXL.safetensorsに関しては、なくても問題ありません。
また、別のLoRAファイルを利用しても問題ありません。
その場合は、設定ファイルを変更する必要があります。
configs/config.iniの下記部分を変更してください。
lora_weight_path = ./inputs/lcm-animaginexl-3_1.safetensors
lora_weight_path2 = ./inputs/DreamyvibesartstyleSDXL.safetensors
lora_scale = 1.0
lora_scale2 = 1.0
trigger_word = None
trigger_word2 = "Dreamyvibes Artstyle"
例えば、DreamyvibesartstyleSDXL.safetensorsのLoRAを解除する場合は、下記のように設定してください。(;でコメントアウトできます。)
lora_weight_path = ./inputs/lcm-animaginexl-3_1.safetensors
;lora_weight_path2 = ./inputs/DreamyvibesartstyleSDXL.safetensors
lora_scale = 1.0
;lora_scale2 = 1.0
trigger_word = None
;trigger_word2 = "Dreamyvibes Artstyle"
一方で、lcm-animaginexl-3_1.safetensorsは絶対に必要です。推論速度を高速化するために利用しています。
こちらはLCM-LoRAという技術です。
このファイルは、SDXLのAnimagine-xl-3.1専用のLoRAモデルになります。
もしモデルを変更する場合(その場合も設定ファイルを変更してください)は、LCM-LoRAも合わせて変更してください。
ちなみに、さまざまなSDXLモデルに汎用的に利用できるLCM-LoRAは下記です。 わからない場合は、こちらを利用すると良いと思います。
バックエンド(Google Colabの場合)
コードのアップロード
まず、必要なコードをGoogle Driveにアップロードします。
drow_ai_backendディレクトリだけを、Google DriveのMyDrive直下においてください。
(バックエンドなので、フロントのファイルは不必要です)
下記のようなディレクトリになります。
MyDrive/
└ drow_ai_backend/
ngrokのアクセストークンを取得
ngrokはローカルPC上で稼働しているネットワークサービスを簡単に外部に公開できるサービスです。
この機能を利用して、Google Colab上のサーバで起動したAPIサーバを外部に公開し、フロントエンドサーバから接続します。
アクセストークンは下記の記事を参考にして取得してください。
取得したngrokアクセストークンをGoogle Colabの環境変数に登録
取得したアクセストークンをNGROKという名前で、Colabの環境変数に登録してください 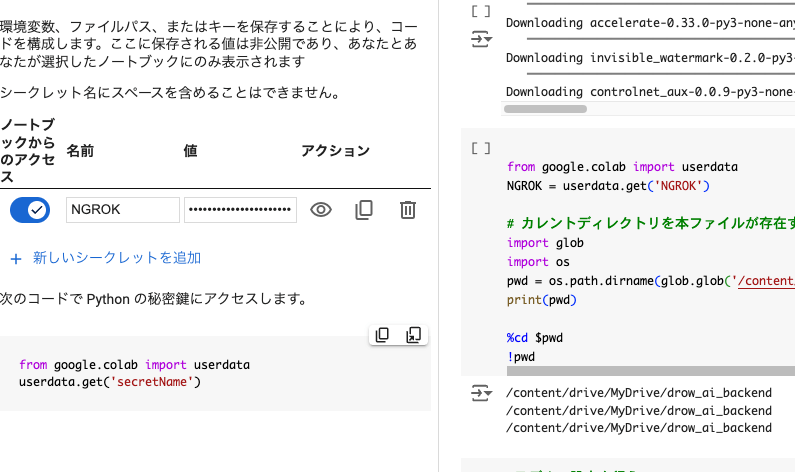
上記のようになっていたら問題ありません。
登録の仕方は下記の記事がわかりやすいです。
LoRAファイルの取得
バックエンドサーバ側で利用するLoRAモデルを予め取得してください。
上記2つのLoRAを取得して、DreamyvibesartstyleSDXL.safetensorsとlcm-animaginexl-3_1.safetensorsにリネームして、Google DriveのMyDrive/drow_ai_backend/inputsフォルダに格納してください。
ちなみに
DreamyvibesartstyleSDXL.safetensorsに関しては、なくても問題ありません。
また、別のLoRAファイルを利用しても問題ありません。
その場合は、設定ファイルを変更する必要があります。
Google Colabの場合は、ノートブックの4セル目で直接上書きするため、そちらの下記部分を変更してください。
lora_weight_path = ./inputs/lcm-animaginexl-3_1.safetensors
lora_weight_path2 = ./inputs/DreamyvibesartstyleSDXL.safetensors
lora_scale = 1.0
lora_scale2 = 1.0
trigger_word = None
trigger_word2 = "Dreamyvibes Artstyle"
例えば、DreamyvibesartstyleSDXL.safetensorsのLoRAを解除する場合は、下記のように設定してください。(;でコメントアウトできます。)
lora_weight_path = ./inputs/lcm-animaginexl-3_1.safetensors
;lora_weight_path2 = ./inputs/DreamyvibesartstyleSDXL.safetensors
lora_scale = 1.0
;lora_scale2 = 1.0
trigger_word = None
;trigger_word2 = "Dreamyvibes Artstyle"
一方で、lcm-animaginexl-3_1.safetensorsは絶対に必要です。推論速度を高速化するために利用しています。
こちらはLCM-LoRAという技術です。
このファイルは、SDXLのAnimagine-xl-3.1専用のLoRAモデルになります。
もしモデルを変更する場合(その場合も設定ファイルを変更してください)は、LCM-LoRAも合わせて変更してください。
ちなみに、さまざまなSDXLモデルに汎用的に利用できるLCM-LoRAは下記です。 わからない場合は、こちらを利用すると良いと思います。
実行
フロントエンド
カレントディレクトリは./drow_ai_app_nextjs_publicを想定しています。
フロントエンドサーバの起動
下記のコマンドを実行してください
pnpm dev
ターミナルに接続用IPアドレス(同じPCからでしか、このアドレスには接続できません)が表示されたら、フロントエンドサーバの準備は完了です。
端末からの接続
その後、フロントエンドサーバと同じネットワーク上の端末(ノートPCやタブレット)から、192.168.x.xxx:3000に接続することで、Webアプリに接続できます。
バックエンド(ローカルPCの場合)
バックエンドでは、./drow_ai_backendをカレントディレクトリとして、それ以降のコマンドを実行してください。
バックエンドサーバの起動
下記コマンドを実行して、バックエンドサーバを立ち上げてください。
python app.py
ターミナルに緑の文字で接続用IPアドレス(このアドレスに接続しても接続できません)が表示されたら、バックエンドサーバの準備は完了です。
バックエンド(Google Colabの場合)
バックエンドサーバの起動
(有料版を利用する場合)
MyDrive/drow_ai_backend/drowai_api_backend.ipynb
もしくは
(無料版を利用する場合)
MyDrive/drow_ai_backend/drowai_api_backend_small.ipynb
のどちらかを一番上のセルから全て実行してください。
(Google Driveの認証が入るので、承認してください)

ある程度時間はかかりますが、一番最後のセルにて、上記のような出力があります。
この出力が出たら、バックエンドサーバの準備は完了です。
ここで、下記のようなURLが表示されます。
PUBLIC_URL: https://cefb-xx-xxx-xxx-xxx.ngrok-free.app
このURLを.env.localに下記のように記載してください。
NEXT_PUBLIC_API_BASE_URL=https://cefb-xx-xxx-xxx-xxx.ngrok-free.app
使い方
共通
タブレットやPCなどから、フロントエンドサーバに接続すると下記のような画面が表示されます。

Sketchモード
画面上部にて、Sketchモードのボタンが青色になっている場合、こちらのモードです。
(初期はこのモードです)
また、Sketchモードのボタンを押すことで、このモードに入れます。
(途中でこのモードに戻ると、過去のすべての情報がリセットされます)
- PromptとNegative Promptを入力して、「適用」ボタンを押します。
- 「Sketch Images」の黒色キャンバスの中にて、マウスドラッグ、もしくはタップにて絵を描くことができます。
- 間違えたら「clear」ボタンを押すとリセットします
- 「実行」ボタンを押すと、書いた絵とプロンプトの情報から絵を生成します
- サーバ側のターミナルにて、実行中のプログレスバーが表示されるため、少々お待ちください
- 生成した絵は、長押しすることで保存ができます。(ipad)
Inpaintモード
またInpaintモードのボタンを押すことで、このモードに入れます。
画面上部にて、Inpaintモードのボタンが青色になっている場合、こちらのモードです。
Sketchモードで生成した絵の一部をプロンプトで修正できます。
- 左側の絵に対して、修正したい箇所を範囲選択します。
- 選択箇所の修正希望をpromptに入力して「適用」ボタンを押します。(Negative Promptはそのままでいいです)
- 「実行」のボタンを押すことで、AIが絵を修正します。
- サーバ側のターミナルにて、実行中のプログレスバーが表示されるため、少々お待ちください 。
- 生成した絵は、長押しすることで保存ができます。(ipad)
- 「NG」ボタンを押すことで、再度やり直すことができます。
- 「OK」ボタンを押すことで、修正された絵をベースに再度修正をかけることができます
まとめ
今回は、生成AIによる「お絵描きサポートWebアプリ」をフロントエンド全くわからない人が雑に作ってみたという話でした。
しかしながら、いろいろやってみたものの、あまりにも自分の絵と生成された絵の乖離が激しすぎて、結局「自分が絵を描いている感覚」には、なれませんでした。
(やっぱりちゃんと絵の練習をして描けるようにならないと、自分で描いている感覚はないですね。)
とはいえ、自分で書いた絵をプロンプトに合わせて、綺麗な絵にしてくれて、かつ、範囲選択で修正もできました。
改めて、技術の進歩はすごいなと思いました。
反響があれば、chatGPTによるWebアプリ作成の流れや、バックエンド側の技術・コードの解説、Webアプリの機能追加などに取り組もうと思います。
ここまで読んでくださり、ありがとうございました!
Discussion
すごいですね!Akuma.ai、Stable doodleがやっていることをご自身で実装しなさったんですね!!そのような知識や技術をどのようにして学んだかよければ聞かせていただけませんか?
コメントいただきありがとうございます!
流石に「Akuma.ai、Stable doodle」ほどの質ではないですが、そう言っていただけて嬉しいです。
元々、画像処理が専門分野でしたので、pythonだけなら数年間触っていました。
その上で、画像生成AIに関しては、私も触り始めて四ヶ月くらいしか経っていないので、まだまだ勉強中の身ですが、知識の習得に関しては、基本的にTwitterやDiscordで新しい技術を把握して、あとはDiffusersというライブラリの公式ドキュメントと、先人の実装記事などを読みながら、自分でも実装してみるということを繰り返してきました。
zennの記事は私の学習の忘備録のために記載しているので、記事の流れがそのまま私の学習の軌跡になります。
今後も読んで頂けるような記事を書いていければと思いますので、よろしくお願いいたします!
返信ありがとうございます!asapさんの方法を参考にして自分の手で実装に取り組んでみようと思います。これからの記事も楽しみにしております!